Chapter 26 Ethics In Statistics
26.1 The Milgram Experiment
This might be the most famous (or infamous) experiment from the field of social psychology. I remember it from my general psychology class as an undergraduate back in the late 20th century (and it’s honestly one of the few things I still remember from that course). I believe that the Milgram Experiment is still a pretty standard part of the curriculum for introductory psychology courses, so some of you might have heard about it.
Stanley Milgram was a psychological researcher at Yale University and set up this study in the 1960s in an effort to see how willing people are to following orders from an authority figure, no matter if the orders result in harm to another human being. Remember that this was only about 20 years after World War II and the Holocaust, where many ordinary people had committed horrific crimes in obedience to the Nazi leaders.
_ More details about the Milgram experiment: https://www.simplypsychology.org/milgram.html
Youtube: https://youtu.be/yr5cjyokVUs
It was quite disturbing that a majority of the participants were willing to adminster the electic shocks to the full intensity, despite their distress in doing so, because the “authority figure” (the Ivy League researchers) told them to.
How does this compare with the Rosenthal-Jacobson study, which was based on telling teachers that randomly chosen children were “gifted” and where they saw the so-called “Pygmalion Effect”, with the “gifted” children outperforming the “regular” children? (keep in mind the meta-analysis did not conclude that the Pygmalion Effect was significant, although other analyses show that it might be for young children)
26.2 Informed Consent
Something like the Milgram experiment would be considered unethical by today’s standards due to the stress that was caused to the participatns. It is highly unlikely that the IRB (Instutitional Research Board) of any reputable univerity or other research facility would approve such an experiment today; Milgram didn’t have to submit his research to an IRB for approval.
Almost all experiments with human participants require that the researchers obtain informed consent from those particpants. You need to be told what the research is about and given an opportunity to make an informed choice about whether to participate.
In medical research, the participants also need to be told about alternative treatments. It is not ethical to withhold a treatment that is known to work. Remember in the Physicians Health Study that when it became clear that the aspirin was beneficial, that part of the experiment was broken and all participants (including those that had been in the placebo group) were given the opportunity to start taking aspirin. The other portion, with the beta-carotene pills, was continued as there was no statistical evidence that taking beta-carotene was either beneficial or harmful.
Research involving animals is very controversial, as they cannot give informed consent the way that we as humans can. There has been a lot of research with animals that has been ultimately beneficial for us as humans, but some of it has been undeniably cruel to the animals.
The American Psychological Association’s Code of Ethics regarding animal research is clearly not the same as for humans, as it does allow for some situations where animals could be subjected to pain or stress if the goal is justifiable (PETA would certainly disagree!), and provides provisions for how to euthanize animals when needed.
26.3 Data Snooping/Fishing and \(p\)-hacking
XKCD: https://www.xkcd.com/882/

https://www.scientificamerican.com/article/the-mind-reading-salmon/
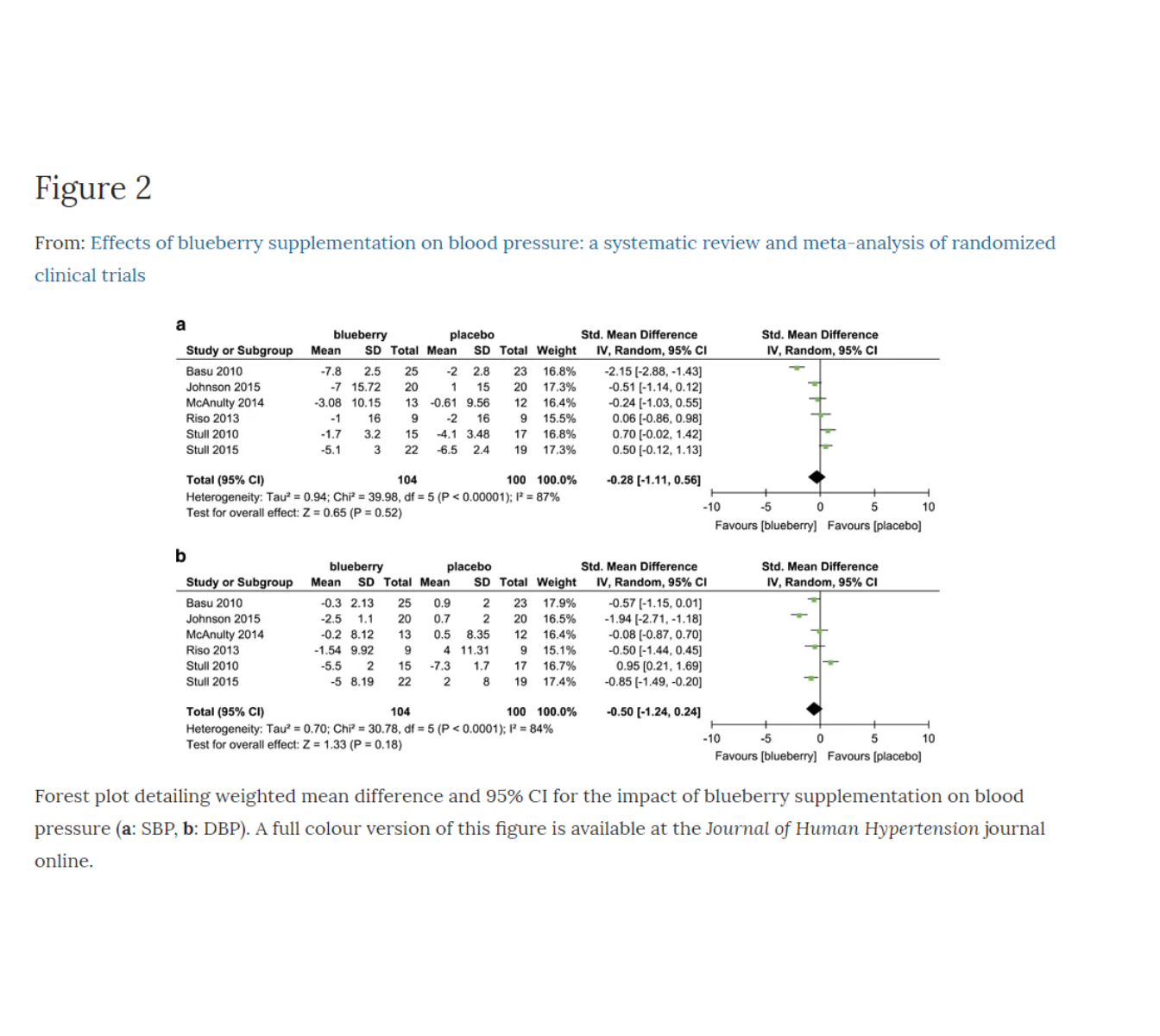
- The Scientific American article discussed a paper in a nutrition journal that found a statistically significant link between eating blueberries and a reduced risk of having high blood pressure. That sounds good, I like blueberries but I don’t like high blood pressure.
Basu A, Du M, Leyva MJ, Sanchez K, Betts NM, Wu M et al. Blueberries decrease cardiovascular risk factors in obese men and women with metabolic syndrome. Journal of Nutrition 2010; 140 (9): 1582–1587.
https://academic.oup.com/jn/article/140/9/1582/4600242
Unfortunately (as in the jelly bean cartoon) dozens of substances had been studied, using \(\alpha=0.05\), so the researchers were bound to find a couple of significant results that might actually be Type I errors. It’s likely green jelly beans don’t cause acne (or at least not to any greater extent than other colors of jelly beans) and it’s likely that blueberries aren’t a magic elixir for preventing hypertension.
There are adjustments for multiple testing; the simplest, the Bonferroni adjustment, merely divides \(\alpha\) by the number of tests being run on the same data. More advanced and complicated procedures have more power, as the Bonferroni method is way too conservative when dozens or hundreds of tests are being performed, which is now commonplace in certain fields such as genetics. The “false discovery rate” is a method used in these circumstances. Some sort of adjustment should have been used with the jelly beans or with the blueberries.
Maybe there’s a meta-analysis for blueberries like the one we saw for consuming small amounts of wine and its association with heart disease? After a quick Google Scholar search, I did find such a meta-analysis, published in 2017. The results are that blueberries are NOT linked with a reduction in high blood pressure. Notice the Basu et al. paper was one of the six studies included in the meta-analysis.
Zhu, Y., Sun, J., Lu, W. et al. Effects of blueberry supplementation on blood pressure: a systematic review and meta-analysis of randomized clinical trials. Journal of Human Hypertension 31, 165–171 (2017) doi:10.1038/jhh.2016.70
https://www.nature.com/articles/jhh201670
The book goes through an elaborate hypothetical example of a researcher named Jake (Section 26.3) who did some data-snooping in an attempt to show a significant difference in memory skills between males & females. By the way, this example is treating gender as a strictly binary variable and it is questionable whether using gender as a factor in this study is necessary or useful.
I’ll try to recreate Jake’s data-snooping with statistical software. The score is how many words (out of 100) that the participants remembered being on or not on a list presented the previous day. Notice that the males contain 2 outliers; the lowest score of 61 and the highest score of 100 (a perfect score, which no one else got within 20 words of).
## gender min Q1 median Q3 max mean sd n missing
## 1 Female 64 70.0 72 75.0 80 71.60000 4.747932 15 0
## 2 Male 61 67.5 70 71.5 100 70.73333 8.729807 15 0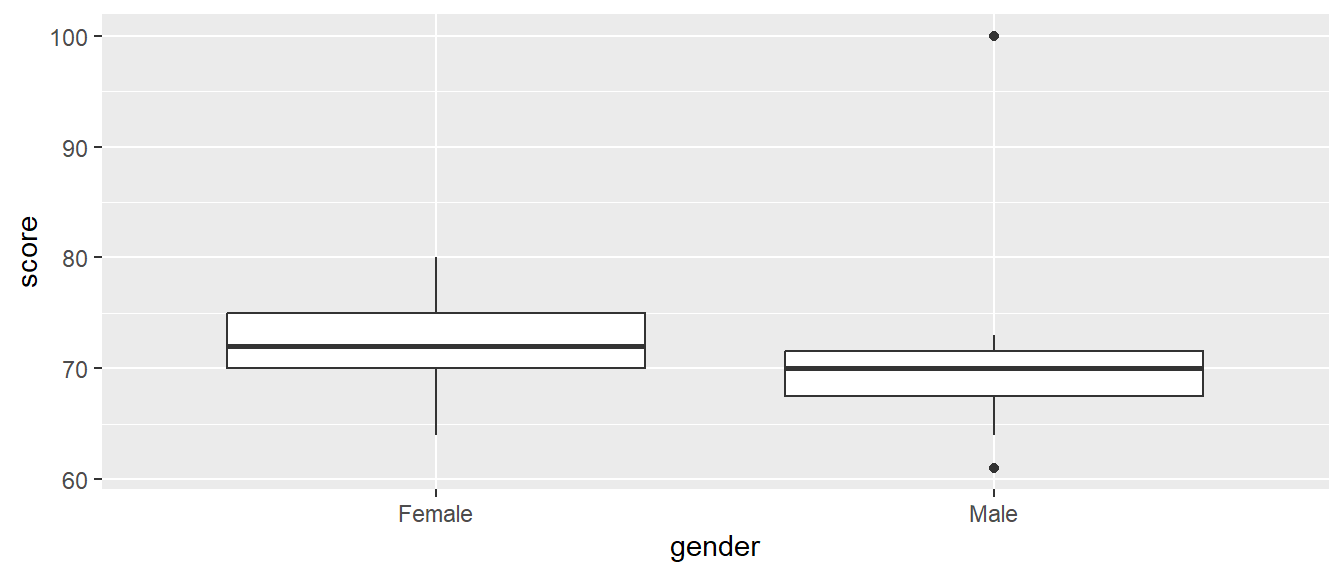
##
## Welch Two Sample t-test
##
## data: score by gender
## t = 0.33777, df = 21.616, p-value = 0.7388
## alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
## 95 percent confidence interval:
## -4.460028 6.193361
## sample estimates:
## mean in group Female mean in group Male
## 71.60000 70.73333##
## Wilcoxon rank sum test with continuity correction
##
## data: score by gender
## W = 151.5, p-value = 0.108
## alternative hypothesis: true location shift is not equal to 0Neither the independent samples \(t\)-test (as we covered in class, here using software to compute the \(df\) and the \(p\)-value) nor the Wilcoxon-Mann-Whitney test (a nonparametric alternative based on ranking data, often used when samples are small and the normality assumption is not met) are statistically significant at \(\alpha=0.05\).
Jake thought about changing to a one-sided hypothesis that females would do better than males on this memory test. This would cut all of the \(p\)-values in half, but this is really a decision that needed to be made BEFORE data collection and certainly not in the middle of data analysis.
Jake notices the male with a score of \(X=100\), and feels that this is probably impossible. He makes the decision to replace this with the median score of \(M=70\). I don’t see any justification for this; there are advanced methods of estimating (“imputing”) missing data points, but I would rather just delete this value if the score of 100 is truly impossible.
Here’s how it turns out with Jake’s decision.
## gender min Q1 median Q3 max mean sd n missing
## 1 Female 64 70.0 72 75.0 80 71.60000 4.747932 15 0
## 2 Male 61 67.5 70 70.5 73 68.73333 3.283436 15 0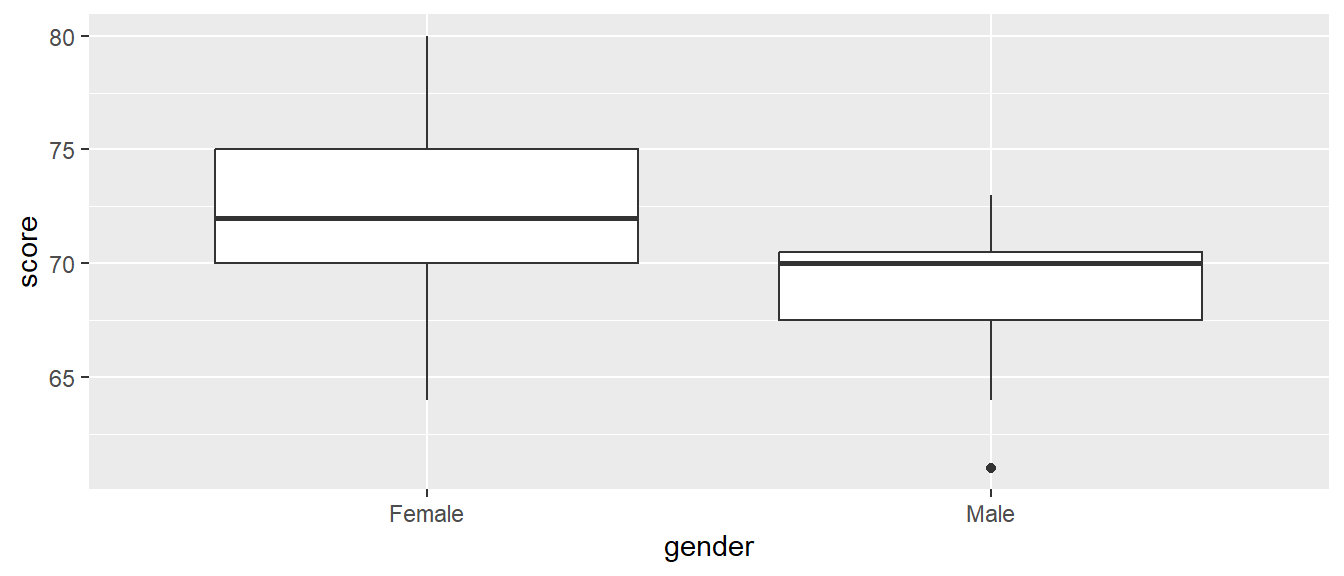
##
## Welch Two Sample t-test
##
## data: score by gender
## t = 1.9233, df = 24.898, p-value = 0.06595
## alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
## 95 percent confidence interval:
## -0.2037101 5.9370434
## sample estimates:
## mean in group Female mean in group Male
## 71.60000 68.73333##
## Wilcoxon rank sum test with continuity correction
##
## data: score by gender
## W = 162.5, p-value = 0.03847
## alternative hypothesis: true location shift is not equal to 0Notice that the \(t\)-test still has a \(p\)-value greather than \(\alpha=0.05\), but that the Wilcoxon-Mann-Whitney test is significant and Jake decided that this was the best analysis! Hmmmmmm, this is pretty sleazy.
If a score of 100 is truly impossible and I don’t know what that person’s actual score was, I could justify removing the data point and doing the analysis with 14 males rather than 15. This wasn’t presented in the textbook. Again, the \(p\)-value is slightly greater than 0.05 with the \(t\)-test and slightly below 0.05 with the Wilcoxon-Mann-Whitney test. I don’t feel there would be an ethical issue with using either the \(t\)-test or the Mann-Whitney test in this situation.
26.4 Deception at Duke
Dr. Anil Potti was a medical researcher at Duke University whose career came to a rather disgraceful end, as reported on CBS’s 60 Minutes.
Video (about a 15 minute clip, shown on the CBS show 60 Minutes in 2012)
WebExtra (3 extra minutes not shown on TV)
The keynote address at the International R Users Conference in Nashville in 2012 was delivered by Dr. Kevin R. Coombes, from The University of Texas M. D. Anderson Cancer Center in Houston (the man with beard & ponytail in the 60 Minutes clips). I was at this conference and this is when I first learned about this case, as I hadn’t seen the 60 Minutes episode shown earlier that year.
He and Dr. Keith Baggerly used what they termed forensic bioinformatics to uncover not just mistakes, but fraud, in the work done at Duke by Dr. Anil Potti
It should be noted that Coombes and Baggerly were initially interested and excited by Potti’s research and were not trying to find evidence of malpractice. However, their failed attempts to reproduce Potti’s analyses led them to discover that something “didn’t smell right” with Potti’s work.
This might not be as sexy as the forensic work you see on popular TV shows, but this is the real power of biostatistics at work.
Keith Baggerly The most common mistakes are simple. This simplicity is often hidden. The most simple mistakes are common.
Kevin Coombes As a result of our efforts, four clinical trials have been terminated and at least eight papers have been retracted. (Baggerly & Coombes spent approx. 2000 hours on this matter.)
Baggerly-Coombes Paper One theme that emerges is that the most common errors are simple; conversely, it is our experience that the most simple errors are common.
Brad Carlin Reproducibility in research is extremely important!! Given the data and the analysis details/code, others should be able to generate the same findings.
Andrew Gelman This is horrible! But, in a way, it’s not surprising. I make big mistakes in my applied work all the time. I mean, all the time…(Mecklin: Me too!)…Genetics, though, seems like more of a black box…operating some of these methods seems like knitting a sweater inside a black box: it’s a lot harder to notice your mistakes if you can’t see what you’re doing, and it can be difficult to tell by feel if you even have a functioning sweater when you’re done with it all.
It does seem kinda funny that the American Cancer Society took away their [Duke’s] grant because of a false statement on a resume [claiming to be a Rhodes Scholar]. It’s a bit like jailing Al Capone on tax evasion, I guess.
Wikipedia After leaving Duke, Potti hired Online Reputation Manager, a reputation management company, to improve search results for his name.
Nature/Keith Baggerly Journals should demand that authors submit sufficient detail for the independent assessment of their paper’s conclusions…we owe it to patients and to the public to do what we can to ensure the validity of the research we publish.
New York Times “Our intuition is pretty darn poor,” Dr. Baggerly said.
The Economist The whole thing, then, is a mess. Who will carry the can remains to be seen. But the episode does serve as a timely reminder of one thing that is sometimes forgotten. Scientists are human, too.