第 41 章 貝葉斯定理的應用:單一參數模型
從前一章節我們可以深切體會到,貝葉斯統計是如何讓我們的先驗概率,在觀察到數據之後,更新信息,獲得事後概率 (這是一個通過數據自我學習,進化的過程)。(How a prior belief about an event can be updated, given data, to a posterior belief.)
所以說,在貝葉斯模型中,我們期待使用觀察數據來學習,以增加現有的對相關參數的知識和信息。本章我們把重點放在二項分佈,用二項分佈作爲單一參數模型來瞭解怎樣推導事後分佈。
41.1 貝葉斯理論下的事後二項分佈概率密度方程 notation for probability density functions
- \(R\) 用來表示服從一個二項分佈的隨機變量, \(R\sim Bin(n, \theta)\)。
- \(r\) 表示觀察到 \(r\) 次成功實驗,實驗次數爲 \(n\)。
- 先驗概率分佈: \(\pi_\Theta(\theta)\)
- 應用貝葉斯定理:
\[ \begin{aligned} \pi_{\Theta|R}(\theta|r) &= \frac{f_R(r|\theta)\pi_\Theta(\theta)}{\int_0^1f_R(r|\theta)\pi_\Theta(\theta)\text{ d}\theta}\\ &= \frac{f_R(r|\theta)\pi_\Theta(\theta)}{f_R(r)} \end{aligned} \]
如果我們的先驗概率分佈:
\[\begin{equation} \pi_\Theta(\theta)=\begin{cases} 1 \text{ if } \theta=0.2\\ 0 \text{ otherwise} \end{cases} \end{equation}\]
意思就是,我們 100% 相信 \(\theta\) 絕對就等於 0.2,不相信 \(\theta\) 竟然還能取任何其他值(霸道自大又狂妄的我們)。
如果先驗概率分佈:
\[\begin{equation} \pi_\Theta(\theta)=\begin{cases} 0.4 \text{ if } \theta=0.2\\ 0.6 \text{ if } \theta=0.7 \end{cases} \end{equation}\]
意思就是,我們有 60% 的把握相信 \(\theta=0.7\),有 40% 的把握相信 \(\theta=0.2\),稍微傾向於 \(\theta=0.7\)。
假設進行10次實驗,觀察到3次成功。當 \(\theta=0.2\) 時,觀察數據的似然 (likelihood) 爲:
\[f_R(3|\theta=0.2)=\binom{10}{3}0.2^3(1-0.2)^7\]
當 \(\theta=0.7\) 時,觀察數據的似然爲:
\[f_R(3|\theta=0.7)=\binom{10}{3}0.7^3(1-0.7)^7\]
應用貝葉斯定理計算事後概率分佈:
\[\begin{equation} \pi_{\Theta|R}(\theta|3)=\begin{cases} \frac{\binom{10}{3}0.2^3(1-0.2)^7\times0.4}{\binom{10}{3}0.2^3(1-0.2)^7\times0.4+\binom{10}{3}0.7^3(1-0.7)^7\times0.6}=0.937 \text{ if } \theta=0.2\\ \frac{\binom{10}{3}0.7^3(1-0.7)^7\times0.6}{\binom{10}{3}0.7^3(1-0.7)^7\times0.6+\binom{10}{3}0.2^3(1-0.2)^7\times0.4}=0.063 \text{ if }\theta=0.7 \end{cases} \end{equation}\]
所以,我們從一開始認爲只有40%的把握相信 \(\theta=0.2\),觀察數據告訴我們 10 次實驗,3次獲得了成功。所以我們現在有 93.7% 的把握相信 \(\theta=0.2\)。也就是說,觀察數據讓我們對參數 \(\theta\) 的取值可能性發生了質的變化,從原先的傾向於 \(\theta=0.7\) 到現在幾乎接近 100% 的認爲 \(\theta=0.2\)。也就是,觀察數據獲得的信息改變了我們的立場。
上面的例子很直觀,但是有下面幾個問題:
- 如果我們無法對參數 \(\theta\) 賦予先驗概率的點估計時,該怎麼辦?
- 如果事後概率不是一個離散的分佈時,該如何才能表達事後概率?
41.2 \(\theta\) 的先驗概率
一種選擇是,我們用均一分佈 (uniform distribution),即我們對數據一無所知,認爲所有的 \(\theta\) 的可能性都一樣,概率密度方程爲 \(1\)。在這一情況下,先驗概率爲 1: \(\pi_\Theta(\theta)=1\),其事後概率分佈爲:
\[ \begin{equation} \pi_{\Theta|R}(\theta|r)=\frac{\binom{n}{r}\theta^r(1-\theta)^{n-r}}{\int_0^1\binom{n}{r}\theta^r(1-\theta)^{n-r} \text{ d}\theta} \tag{41.1} \end{equation} \]
看到即使在如此簡單的先驗概率下,我們還是要使用複雜的微積分進行計算。幸運的是,像 (41.1) 的分母這樣的積分公式其實是有跡可循的。這就是 beta (\(\beta\)) 分佈。
41.2.1 beta 分佈 the beta distribution
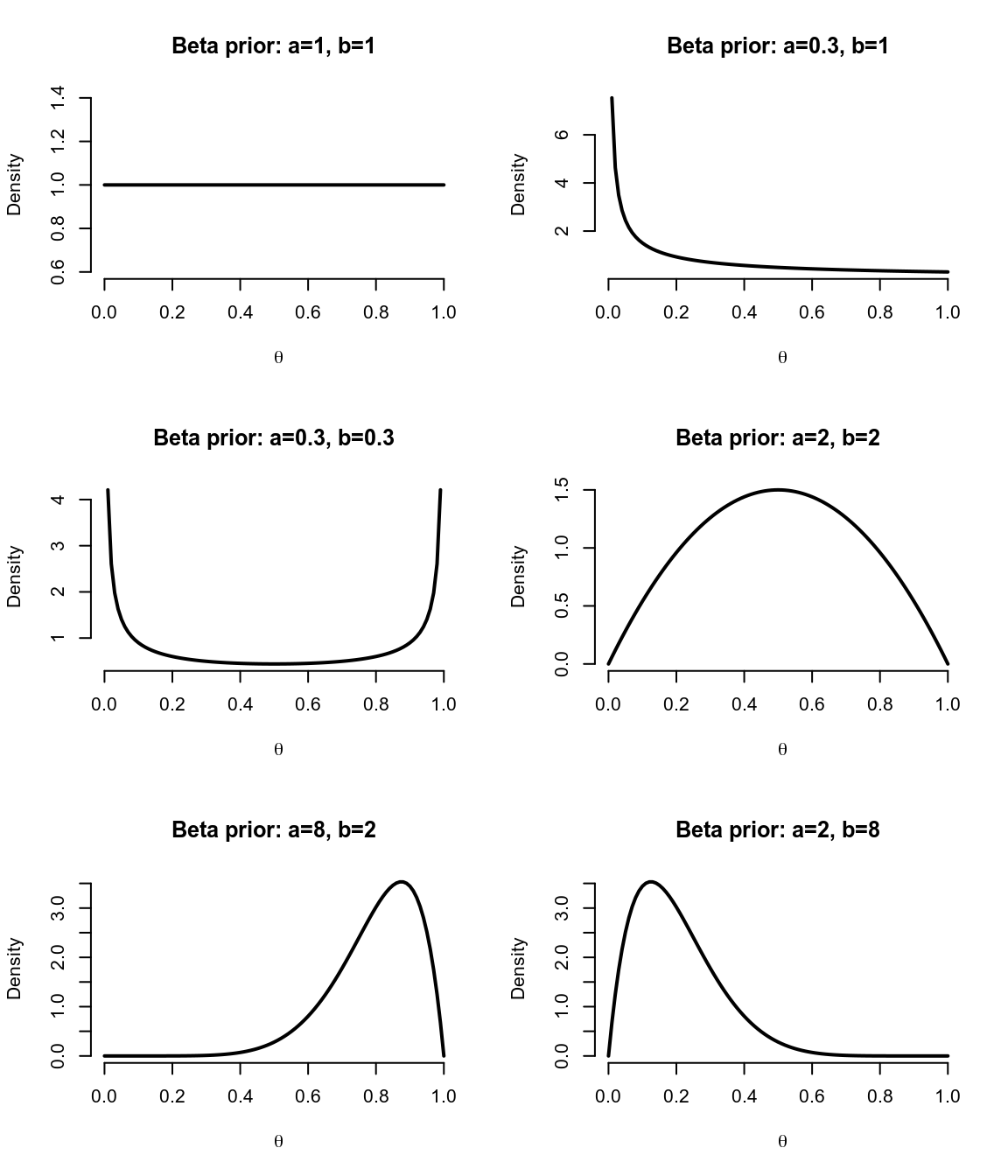
圖 41.1: Beta distribution functions for various values of a, b
我們定義 \(a>0\) 時伽馬方程爲
\[\Gamma(a)=\int_0^\infty x^{a-1}e^{-ax}\text{ d}x\]
當 \(a\) 取正整數時, \(\Gamma(a)\) 是 \((a-1)!\)。例如,當 \(a=4, \Gamma(a)=3\times2\times1=6\)。
對於 \(\theta\in[0,1]\) 時,beta 方程 \(Beta(a,b)\) 被定義爲:
\[ \begin{aligned} \pi\Theta(\theta|a,b) &= \theta^{a-1}(1-\theta)^{b-1}\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\\ &= \frac{\theta^{a-1}(1-\theta)^{b-1}}{B(a,b)} \end{aligned} \]
其中 \[B(a,b)=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)} = \int_0^1\theta^{a-1}(1-\theta)^{b-1}\text{d}\theta\]
莫要混淆 B 函數和 Beta 方程。B 函數的性質和詳細定義可以參照其維基百科頁面。
利用 Beta 方程作爲前概率顯得十分便捷且靈活。圖 41.1 展示的是 6 種不同的 \((a,b)\) 取值下的先驗概率分佈示意圖。其實我們可以看到,包括均一分佈在內的各種可能性都可以通過 Beta 分佈實現。其中 \((a,b)\) 被叫做超參數 (hyperparameter)。\((a,b)\) 取值越大,先驗概率分佈的方差越小。
關於 Beta 分佈的幾個性質:
- 均值:\(\text{mean}=\frac{a}{a+b}\);
- 衆數:\(\text{mode}=\frac{a-1}{a+b-2}\);
- 方差:\(\text{variance}=\frac{ab}{(a+b)^2(a+b+1)}\)。
回到均一分佈的簡單例子 (41.1) 上:
\(\pi_\Theta(\theta)=Beta(1,1)\) 是 \(\theta\in[0,1]\) 上的均一分佈。所以事後概率 posterior 和下面的式子成正比:
\[\theta^r(1-\theta)^{n-r}\]
換句話說,事後概率分佈服從 \(Beta(r+1,n-r+1)\) 分布,均值爲 \(\frac{r+1}{n+2}\),方差爲 \(\frac{(1+r)(n-r+1)}{(n+2)^2(n+3)}\)。
由此可見,在貝葉斯統計思維下,先驗概率爲均一分佈的二項分佈數據,其事後概率分佈的均值和方差,和經典概率論下的極大似然估計 \(r/n\) 不同,和它的漸進樣本方差 \(r(n-r)/n^3\) 也不同。但是,當 \(n\) 越來越大,獲得的觀察數據越多提供的信息越來越多以後,我們會發現事後概率分佈的均值和方差也會越來越趨近於經典概率論下的極大似然估計和它的方差。
於是這裏可以總結以下兩點:
- 即使先驗概率對參數毫無用處(不能提供有效信息,或者我們對所觀察的數據一無所知),也可能會對事後概率分佈結果提供一些意外的信息。
- 當樣本量增加,似然就主導了整個貝葉斯方程,在數學計算上,經典概率論和貝葉斯推理的估計結果將會十分接近。當然,其各自的意義還是截然不同的。
41.2.2 二項分佈數據事後概率分佈的一般化:共軛性
當 \(r\sim \text{Binomial}(n,\theta)\) 時,如果先驗概率 \(\pi_\Theta(\theta)=\text{Beta}(a,b)\)。那麼參數 \(\theta\) 的事後概率分佈的密度方程滿足:
\[\pi_{\Theta|r}(\theta|r)=\text{Beta}(a+r, b+n-r)\]
它的事後概率分佈均值爲:
\[E[\theta|r]=\frac{a+r}{a+b+n}\]
事後概率分佈的衆數爲:
\[\text{Mode}[\theta|r]=\frac{a+r-1}{n+a+b-2}\]
事後概率分佈方差爲:
\[\text{Var}[\theta|r]=\frac{(a+r)(b+n-r)}{(a+b+n)^2(a+b+n+1)}\]
因此,我們看到先驗概率服從 \(\text{Beta}(a,b)\) 分佈,觀察數據爲二項分佈時,事後概率分佈還是服從 \(\text{Beta}\) 分佈,僅僅只是超參數發生了轉變(更新)。這就是共軛分佈的實例。\(\text{Beta}\) 分佈是二項分佈的共軛先驗概率分佈 (the \(\text{Beta}(a,b)\) is the conjugate prior for the binomial likelihood)。
在經典概率論的框架下,參數 \(\theta\) 的估計就是極大似然估計 (MLE)。在二項分佈的例子中, \(\text{MLE}=\hat\theta=r/n\),當樣本量 \(n\rightarrow\infty\) 時,事後概率分佈均值:
\[E[\theta|r]=\frac{a+r}{a+b+n}=\frac{\frac{r}{n}+\frac{a}{n}}{1+\frac{a+b}{n}}\approx\frac{r}{n}=\text{MLE}\]
事後概率分佈的衆數爲:
\[ \begin{aligned} \text{Mode}[\theta|r] &=\frac{a+r-1}{n+a+b-2} \\ &= \frac{\frac{r}{n}+\frac{a-1}{n}}{1+\frac{a+b-2}{n}}\\ &\approx \frac{r}{n} \end{aligned} \]
事後概率分佈的方差爲:
\[\frac{(a+r)(b+n+r)}{(a+b+n)^2(a+b+n+1)}\approx0\]
當 \(n\),樣本越來越大時,我們獲得更多的來自數據的信息,所以來自數據的信息逐漸主導 (dominate) 了整個貝葉斯推斷的過程,事後均值等衆多統計結果都越來越趨近於概率論統計思想下的極大似然估計等結論。
我們也可以注意到,當 \(a\rightarrow0, b\rightarrow0\) 時,事後概率分佈的均值 \(E[\theta|r] = \frac{a+r}{a+b+n} \rightarrow \frac{r}{n}\),方差也趨向於樣本漸進方差 (asymptotic sample variance)。但是當 \(a\rightarrow 0, b\rightarrow0\) 時,先驗概率是沒有被定義的,可是此例下事後概率卻可以正常被定義。所以當先驗概率分佈無法被定義,或者被定義的不恰當時,事後概率分佈依然不受太大影響。所以特別是對於均值(或迴歸係數,regression coefficients)等參數,我們常常會使用均一分佈這樣的無信息先驗概率。
41.3 附贈–加量不加價
當樣本數據服從二項分布時使用 \(\text{Beta}(a,b)\) 作爲前概率分布,試推導事後概率分布。並且證明 Beta 分布是二項分布的共軛分布 (conjugate distribution)。
當數據服從二項分布時,其似然方程 (或概率方程) 爲:
\[f(n,r|\theta) = \binom{n}{r}\theta^r(1-\theta)^{n-r}\]用 \(\text{Beta}(a,b)\) 做前概率分布 (\(a,b\) 是 \(\theta\) 的超參數),那麼
\[\begin{aligned}\pi(\theta) &= \text{Beta}(\theta|a,b) \\ & = \theta^{a-1}(1-\theta)^{b-1}\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)} \\ & = \frac{\theta^{a-1}(1-\theta)^{b-1}}{B(a,b)} \\ \text{Where } B(a,b) &=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)} = \int_0^1\theta^{a-1}(1-\theta)^{b-1}\text{d}\theta \end{aligned}\]利用貝葉斯定理,後概率分布就可以推導爲
\[ \begin{aligned} \pi(\theta|n,r) & = \frac{f(n,r|\theta)\pi(\theta)}{\int f(n,r |\theta)\pi(\theta)\text{d}\theta} \\ & = \frac{\binom{n}{r}\theta^r(1-\theta)^{n-r}\pi(\theta)}{\int_0^1\binom{n}{r}\theta^r(1-\theta)^{n-r} \pi(\theta) \text{ d}\theta} \\ & = \frac{\binom{n}{r}\theta^r(1-\theta)^{n-r}\frac{\theta^{a-1}(1-\theta)^{b-1}}{B(a,b)}}{\int_0^1\binom{n}{r}\theta^r(1-\theta)^{n-r} \frac{\theta^{a-1}(1-\theta)^{b-1}}{B(a,b)} \text{ d}\theta} \\ & = \frac{\binom{n}{r}\theta^{r+a-1}(1-\theta)^{n+b-r-1}}{\int_0^1\binom{n}{r}\theta^{r+a-1}(1-\theta)^{n+b-r-1} \text{ d}\theta} \\ & = \frac{\theta^{r+a-1}(1-\theta)^{n+b-r-1}}{B(r+a, n+b-r)} \\ & \sim \text{Beta}(r+a, n+b-r) \end{aligned} \] 這個推導的結果告訴我們,先驗概率 \(\pi(\theta) = \frac{\theta^{a-1}(1-\theta)^{b-1}}{B(a,b)}\sim \text{Beta}(a,b)\),通過和二項分布的似然方程相乘,獲得後驗概率 \(\pi(\theta|n,r) = \frac{\theta^{r+a-1}(1-\theta)^{n+b-r-1}}{B(r+a, n+b-r)}\sim\text{Beta}(r+a, n+b-r)\)。這兩個概率都服從 \(\text{Beta}\) 分布,也就是證明了 \(\text{Beta}\) 分布,是二項分布的共軛分布。新產生的事後概率的性質有:
- \(\theta\) 的均值 mean \(\mu= \frac{a+r}{a+b+n}\);
- \(\theta\) 的方差 variance \(\sigma^2 = \frac{(a+r)(n+b-r)}{(a+b+n)^2(a+b+n+1)}\);
41.4 練習題
41.4.1 Q1
當先驗概率分佈服從 \(\text{Beta}(0.5,0.5)\),觀察數據記錄到 \(5\) 個患者中 \(3\) 人死亡的事件。 試求: 死亡發生概率 \(\theta\) 的 95% 可信區間 (credible intervals)。
解
根據 Section 41.2.2 的公式,當先驗概率爲 \(\pi_{\Theta|r}(\theta|r)=\text{Beta}(a=0.5,b=0.5)\) ,數據 \(n=5, r=3\)。參數 \(\theta\) 的事後概率分佈 \(\pi_{\Theta|r}(\theta|r)=\text{Beta}(a+r,b+n-r)=\text{Beta}(3.5,2.5)\)。
在 R 裏進行貝葉斯計算十分簡便:
# 95% Credible Intervals
L <- qbeta(0.025, 3.5, 2.5)
U <- qbeta(0.975, 3.5, 2.5)
print(c(L,U))## [1] 0.20941666 0.90560967事後分佈 \(\pi_{\Theta|r}(\theta|r)=\text{Beta}(3.5,2.5)\) 的分佈圖形如下:
post <- Vectorize(function(theta) dbeta(theta, 3.5, 2.5))
# Illustration
x <- seq(0,1,length=10000)
y <- post(x)
plot(x,y, type = "l", xlab=~theta, ylab="Density", lwd=2, frame.plot = FALSE)
polygon(c(L, x[x>=L & x<= U], U), c(0, y[x>=L & x<=U], 0), col="grey")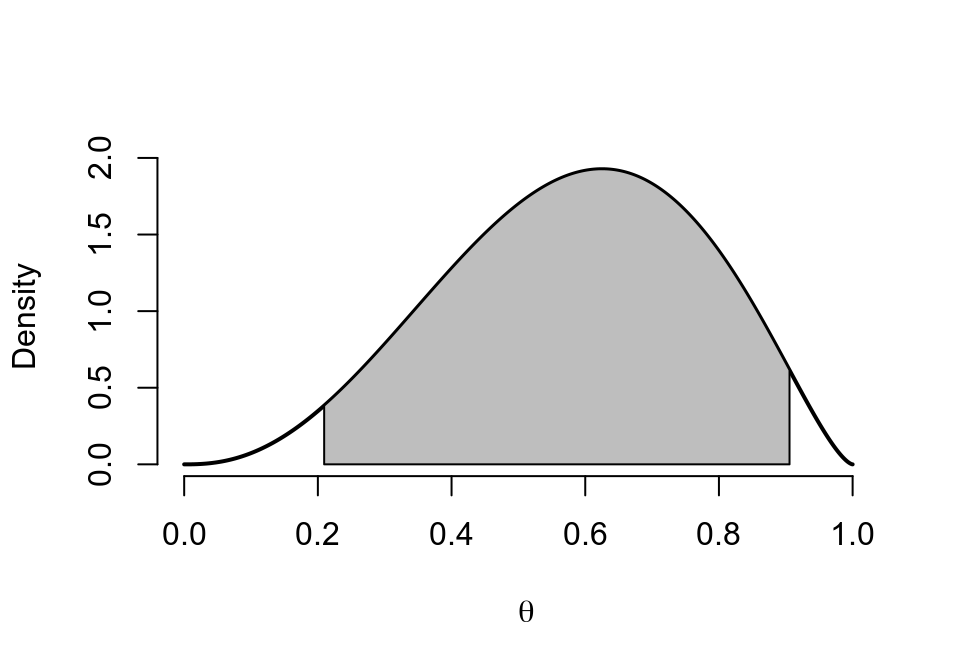
圖 41.2: Posterior distribution of Beta(3.5,2.5)
我們可以自己寫一個求可信區間的公式來計算:
# Credible Interval function:
# a, b : shape / super parameters
# level: probability level (0,1)
cred.int <- function(a,b,level){
L <- qbeta((1-level)/2, a, b) # Lower limit
U <- qbeta((1+level)/2, a, b) # Upper limit
return(c(L,U))
}
cred.int(3.5,2.5,0.95)## [1] 0.20941666 0.9056096795%可信區間 \((0.2094, 0.9056)\) 告訴我們,參數 \(\theta\in(0.2094, 0.9056)\) 的概率是 \(0.95\)。
下面我們嘗試寫 Beta 分佈的其他統計量:均值,衆數,方差等。
# a, b: shape / super parameters
MeanBeta <- function(a,b) a/(a+b)
ModeBeta <- function(a,b) {
m <- ifelse(a>1 & b>1, (a-1)/(a+b-2), NA)
return(m)
}
VarianceBeta <- function(a,b) (a*b)/((a+b)^2*(a+b+1))
# mean
MeanBeta(3.5,2.5)## [1] 0.58333333# mode
ModeBeta(3.5,2.5)## [1] 0.625# Variance
VarianceBeta(3.5, 2.5)## [1] 0.034722222# SD
sqrt(VarianceBeta(3.5, 2.5))## [1] 0.18633941.4.2 Q2
假如數據還是 Q1 的數據,然而先驗概率讓我們認爲可能在 5 名受試對象中觀察到 1 次事件。
- 試求超參數 \((a,b)\) 滿足先驗概率的 Beta 分佈。(不止一組)
解
我們認爲最有可能發生 “5 名受試對象中觀察到 1 次事件” 的情況,那麼先驗概率的均值爲 \(\frac{a}{a+b}=0.2\)。所以,在實數中有無數組超參數都可以用來模擬先驗概率分佈。例如 \(a=1, b=4; a=10, b=40; a=100, b=400; a=0.317, b=1.268, \cdots\)。
- 假如觀察數據是 \(n=5, r=1\),計算事後概率分佈及其均值,標準差。
解
先來嘗試寫一個計算貝葉斯二項分佈的方程:
# binbayes function in R
#------------------------------
# a, b: shape / super parameters
# r : number of successes
# n : number of trials
binbayes <- function(a, b, r, n) {
prior <- c(a, b, NA, MeanBeta(a,b), sqrt(VarianceBeta(a, b)), qbeta(0.025, a, b), qbeta(0.5, a, b), qbeta(0.975, a, b))
posterior <- c(a+r, b+n-r, r/n, MeanBeta(a+r, b+n-r), sqrt(VarianceBeta(a+r, b+n-r)), qbeta(0.025, a+r, b+n-r), qbeta(0.5, a+r, b+n-r), qbeta(0.975, a+r, b+n-r))
out <- rbind(prior, posterior)
out <- round(out, 4)
colnames(out) <- c("a","b","r/n","Mean", "SD", "2.5%", "50%", "97.5%")
return(out)
}
# a=1, b=4, r=1, n=5
binbayes(1,4,1,5)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 1 4 NA 0.2 0.1633 0.0063 0.1591 0.6024
## posterior 2 8 0.2 0.2 0.1206 0.0281 0.1796 0.4825# a=10, b=40, r=1, n=5
binbayes(10,40,1,5)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 10 40 NA 0.2 0.0560 0.1024 0.1960 0.3202
## posterior 11 44 0.2 0.2 0.0535 0.1063 0.1963 0.3143通過繪製先驗概率分佈圖和事後概率分佈圖來比較二者的變化:
# Prior vs posterior graphs
# a,b : shape / super parameters
# r : number of successes
# n : number of trials
graph.binbayes <- function(a,b,r,n) {
prior <- Vectorize(function(theta) dbeta(theta, a,b))
posterior <- Vectorize(function(theta) dbeta(theta, a+r, b+n-r))
YL <- max(prior(seq(0.001,0.999,by=0.001)),posterior(seq(0.001,0.999,by=0.001)))
curve(prior, xlab=~theta, ylab="Density", lwd=1, lty=2,n=10000,ylim=c(0,YL), frame.plot = FALSE)
curve(posterior, xlab=~theta,lwd=2,lty = 1, add=T,n=10000)
}
graph.binbayes(1,4,1,5)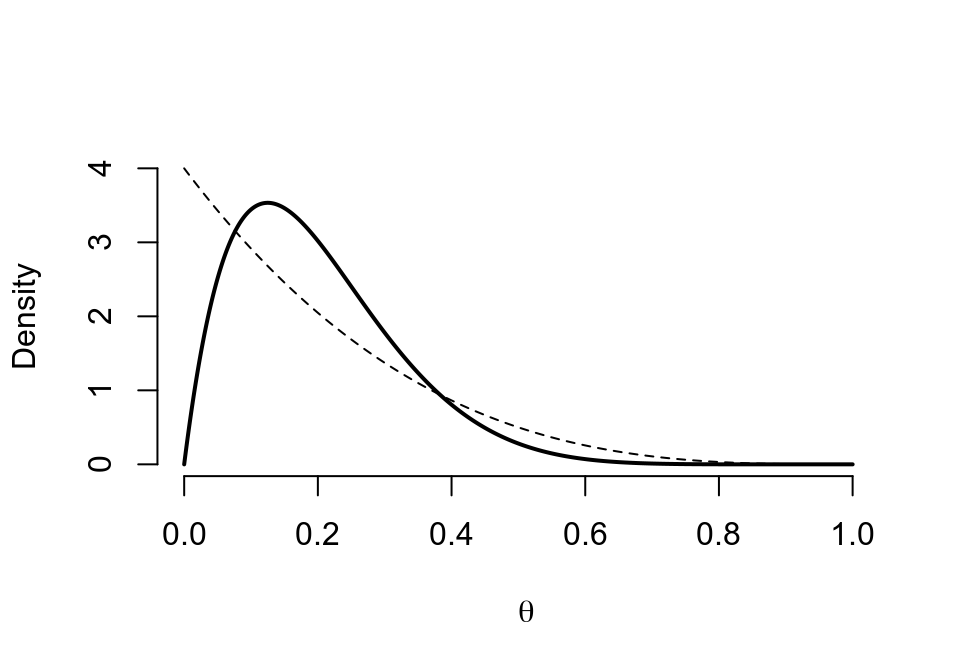
圖 41.3: Prior (dashed) Beta(1,4) vs. Posterior (cont.) Beta(2,8)
graph.binbayes(10,40,1,5)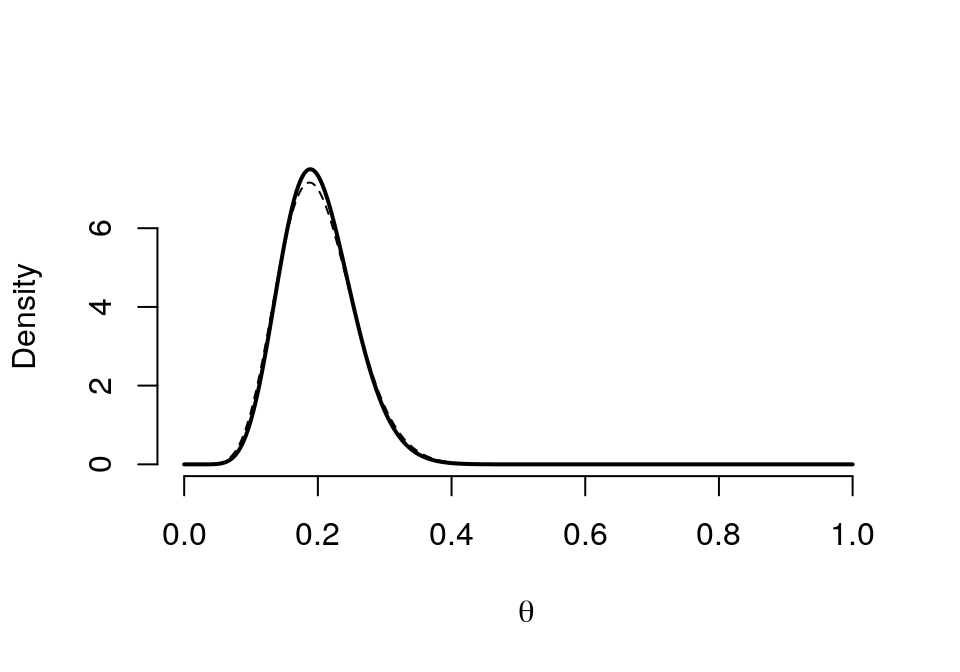
圖 41.4: Prior (dashed) Beta(10,40) vs. Posterior (cont.) Beta(11, 44)
我們可以很清楚的看見,先驗概率相同時,\(\text{Beta} (a,b)\) 的超參數如果越大,先驗概率的分佈就越趨近與對稱圖形,且極大值也就越出現在均值的地方 (本例中是 \(0.2\))。而且也會使事後概率的 HPD (highest posterior density) 的區間更狹窄 (意爲對事後概率的預測越準確),同時事後概率分佈也更加接近左右對稱。
41.4.3 Q3
我們事先估計某個事件在 \(n=20\) 名患者中發生的概率爲 \(15\%\)。當實際觀察數據爲 \(n=15,r=3\) 時,計算相應的事後概率。
解
# because 15% events happened in 20 subjects, assuming prior Beta(a=3, b=17)
# observed n=15, r=3
binbayes(3,17,3,15)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 3 17 NA 0.1500 0.0779 0.0338 0.1383 0.3314
## posterior 6 29 0.2 0.1714 0.0628 0.0676 0.1651 0.3106graph.binbayes(3,17,3,15)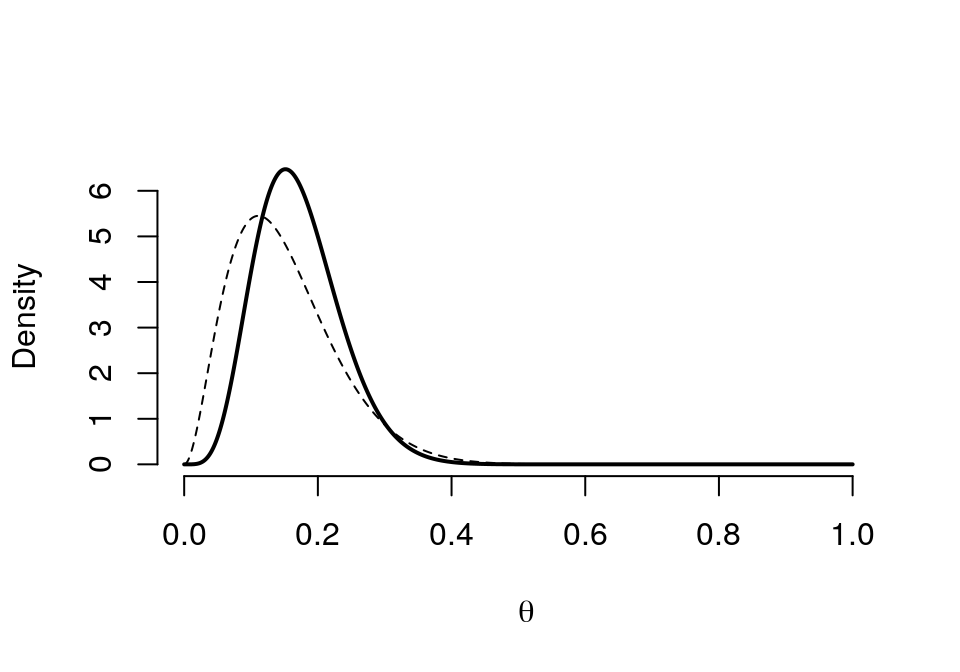
圖 41.5: Prior (dashed) Beta(3,17) vs. Posterior (cont.) Beta(6,29)
試着繪製先驗概率服從 \(\text{Beta} (1,1)\),回憶之前本章開頭的圖 41.1,這個先驗概率的含義就是我們沒有任何背景知識,對數據完全陌生的情況:
graph.binbayes(1,1,3,15)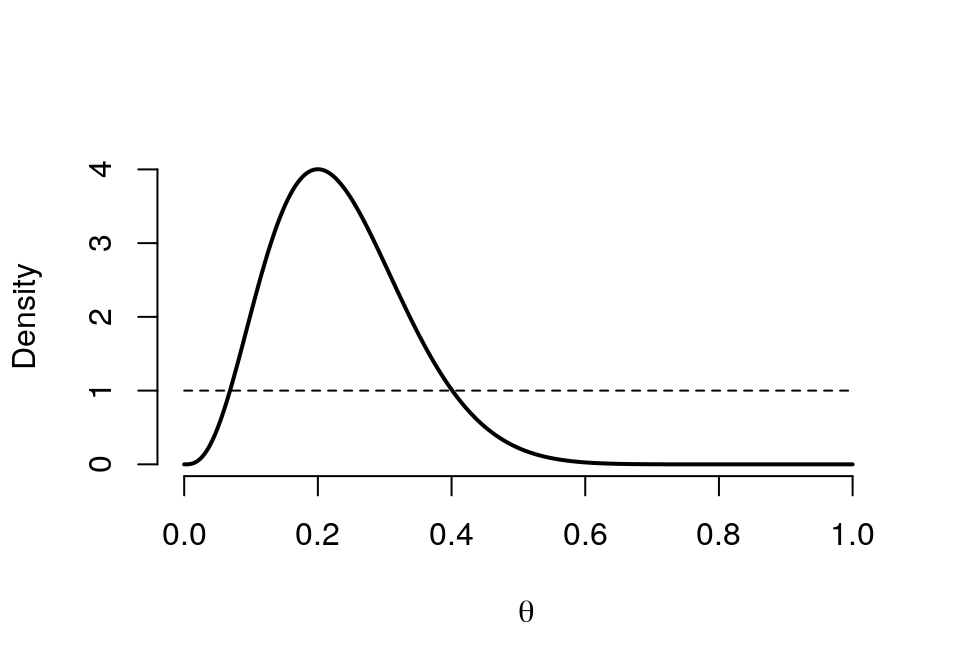
圖 41.6: Prior (dashed) Beta(1,1) vs. Posterior (cont.) Beta(4,13)
41.4.4 Q4
試給出上面各題中參數 \(\theta\) 落在 \((0.1,0.25)\) 之間的概率。
# function to calculate probabilities in a interval
# a, b: super parameters
# r : number of successes
# n : number of trials
# L : Lower limit of the probability interval
# U : Upper limit of the probability interval
prob.int <- function(a,b,r,n,L,U){
prior0 <- pbeta(U,a,b) - pbeta(L,a,b)
posterior0 <- pbeta(U,a+r,n-r+b) - pbeta(L,a+r,n-r+b)
prob <- as.matrix(c(prior0, posterior0))
prob <- round(prob,4)
colnames(prob) <- paste("Probability of theta lies between the Interval", L, U)
rownames(prob) <- c("Prior","Posterior")
return(prob)
}
# Prior Beta(0.317,1.286) n = 5, r=1
binbayes(0.317, 1.286, 1, 5)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 0.317 1.286 NA 0.1978 0.2469 0.000 0.0823 0.8516
## posterior 1.317 5.286 0.2 0.1995 0.1449 0.013 0.1684 0.5493prob.int(0.317, 1.286, 1, 5,0.1,0.25)## Probability of theta lies between the Interval 0.1 0.25
## Prior 0.1711
## Posterior 0.3911graph.binbayes(0.317, 1.286, 1, 5)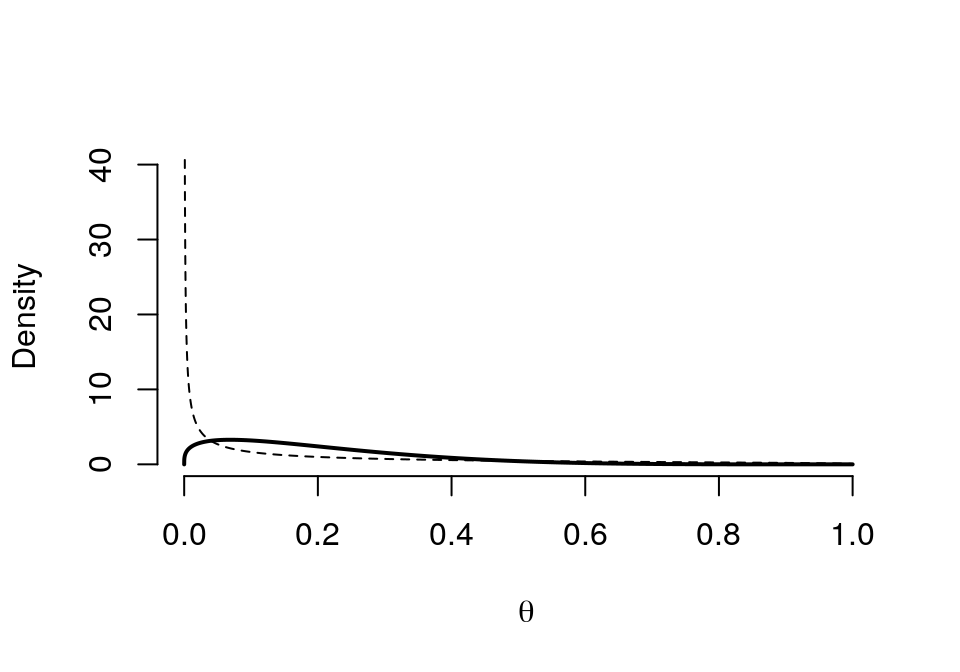
圖 41.7: Prior (dashed) Beta(0.317,1.286) vs. Posterior (cont.) Beta(1.317, 5.286)
# Prior Beta(10,40) n = 5, r=1
binbayes(10, 40, 1, 5)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 10 40 NA 0.2 0.0560 0.1024 0.1960 0.3202
## posterior 11 44 0.2 0.2 0.0535 0.1063 0.1963 0.3143prob.int(10, 40, 1, 5,0.1,0.25)## Probability of theta lies between the Interval 0.1 0.25
## Prior 0.7951
## Posterior 0.8099所以在範圍固定的時候,事後概率分佈總是能夠比先驗概率分佈給出更高的累計概率。
41.4.5 Q5
一個臨牀試驗要進行兩個階段 (two phases),第一階段我們觀察到 \(10\) 個患者中 \(1\) 個事件。第二階段,觀察到 \(n=50, r=5\)。
- 兩個階段都使用 \(\text{Beta}(1,1)\) 作先驗概率。求兩個實驗階段參數 \(\theta<0.1\) 的概率。
# Phase I
binbayes(1, 1, 1, 10)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 1 1 NA 0.5000 0.2887 0.0250 0.500 0.9750
## posterior 2 10 0.1 0.1667 0.1034 0.0228 0.148 0.4128prob.int(1,1,1,10,0,0.1)## Probability of theta lies between the Interval 0 0.1
## Prior 0.1000
## Posterior 0.3026graph.binbayes(1, 1, 1, 10)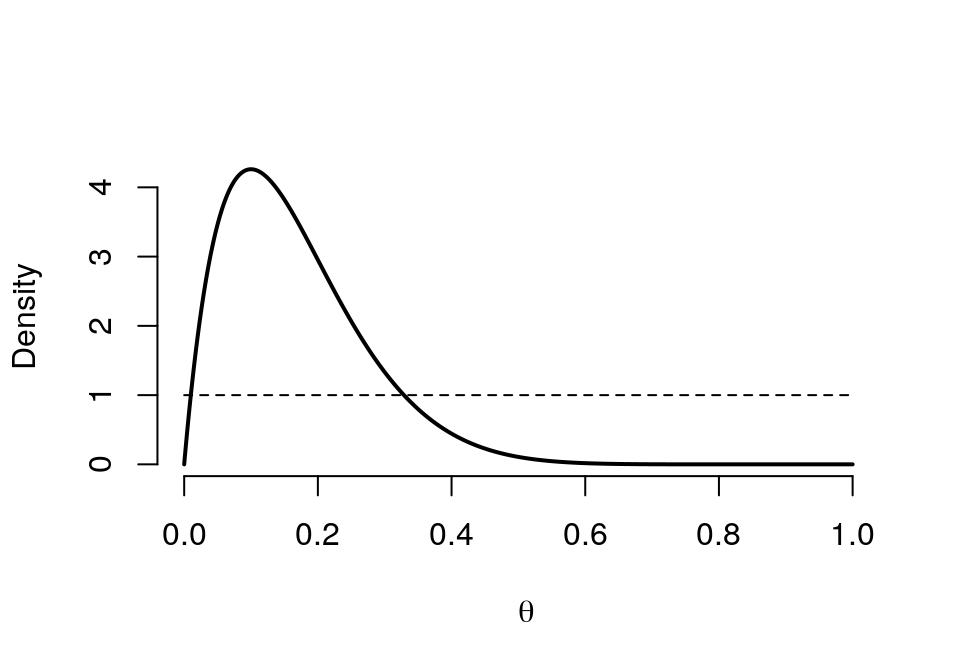
圖 41.8: Prior (dashed) Beta(1,1) vs. Posterior (cont.) Beta(2, 10)
# Phase II
binbayes(1, 1, 5, 50)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 1 1 NA 0.5000 0.2887 0.0250 0.5000 0.9750
## posterior 6 46 0.1 0.1154 0.0439 0.0444 0.1105 0.2141prob.int(1,1,5,50,0,0.1)## Probability of theta lies between the Interval 0 0.1
## Prior 0.1000
## Posterior 0.4024graph.binbayes(1, 1, 5, 50)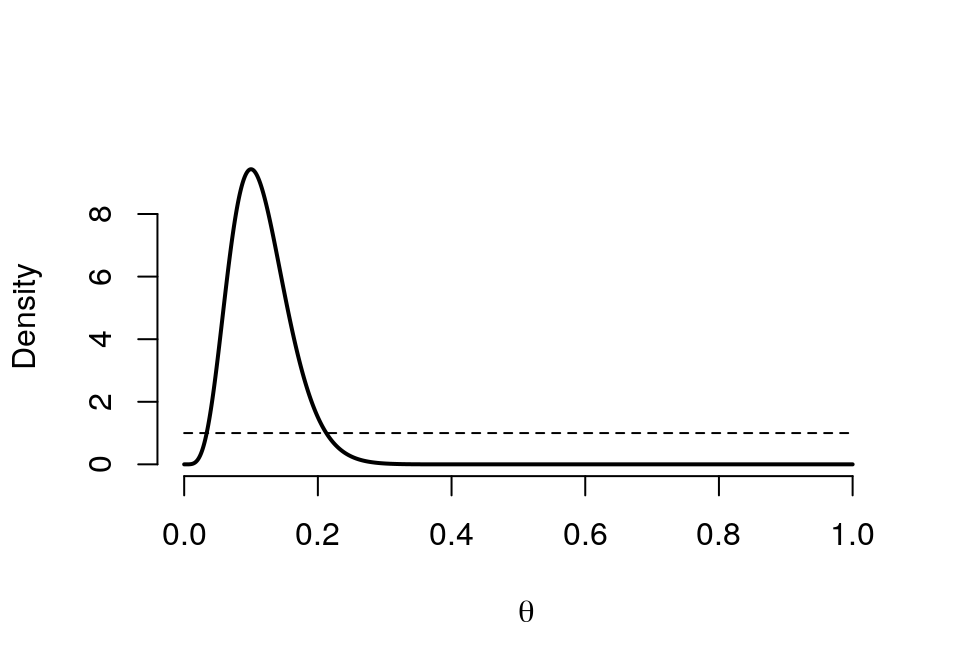
圖 41.9: Prior (dashed) Beta(1,1) vs. Posterior (cont.) Beta(6, 46)
- 繼續使用先驗概率分佈 \(\text{Beta}(1,1)\),合併兩個實驗階段,求此時的事後概率分佈,以及參數 \(\theta<0.1\) 的概率。
# Combining both phases
binbayes(1, 1, 6, 60)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 1 1 NA 0.5000 0.2887 0.0250 0.5000 0.9750
## posterior 7 55 0.1 0.1129 0.0399 0.0474 0.1087 0.2019prob.int(1,1,6,60,0,0.1)## Probability of theta lies between the Interval 0 0.1
## Prior 0.1000
## Posterior 0.4105graph.binbayes(1, 1, 6, 60)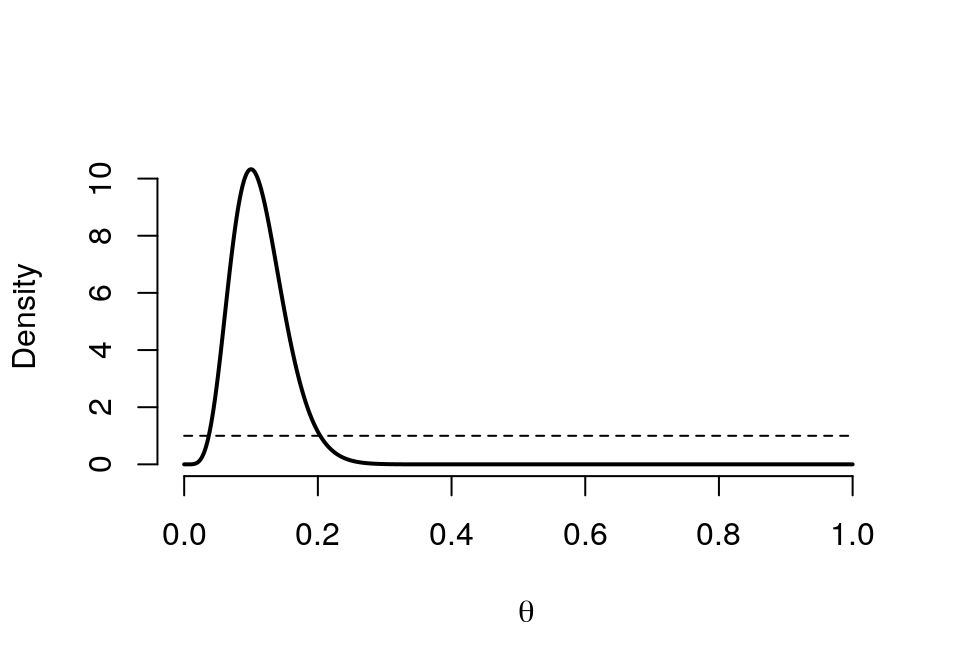
圖 41.10: Prior (dashed) Beta(1,1) vs. Posterior (cont.) Beta(7, 55)
- 用第一階段的實驗結果做第二階段實驗的先驗概率分佈,再計算事後概率分佈,以及 \(\theta<0.1\) 的概率。
# Using Phase I results as a prior for Phase II
binbayes(2, 10, 5, 50)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 2 10 NA 0.1667 0.1034 0.0228 0.1480 0.4128
## posterior 7 55 0.1 0.1129 0.0399 0.0474 0.1087 0.2019prob.int(2,10,5,50,0,0.1)## Probability of theta lies between the Interval 0 0.1
## Prior 0.3026
## Posterior 0.4105graph.binbayes(2, 10, 5, 50)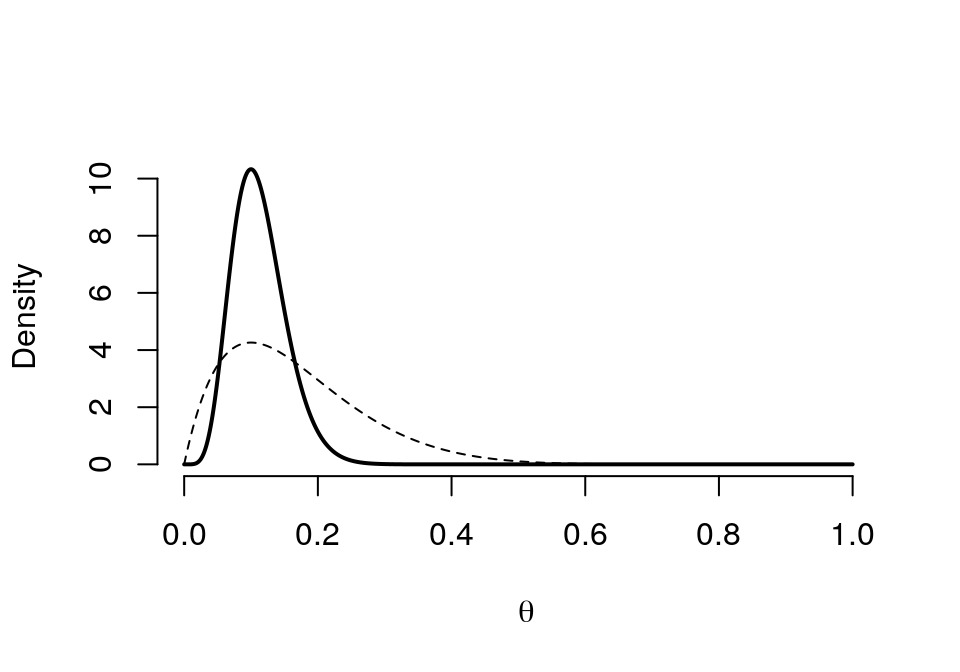
圖 41.11: Prior (dashed) Beta(2,10) vs. Posterior (cont.) Beta(7, 55)
第2,3兩個小問題提示我們,無論是將第一階段實驗結果作爲第二階段實驗的先驗假設還是將兩次實驗合併,最終的結果是不會改變的。Both approaches are equivalent.
41.4.6 Q6
藥物 A 和藥物 B 都被批准用於治療某種疾病。在 5000 例病例中使用藥物 A,發現有 3 人發生了不良副作用。在另外 7000 例病例中使用藥物 B,發現只有 1 例發生了副作用。
- 先使用單一分佈作爲先驗概率 (uniform prior: \(\text{Beta}(1,1)\))。求藥物 A 和藥物 B 各自發生不良反應的事後概率。
藥物 A
# Drug A
binbayes(1,1, 3, 5000)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 1 1 NA 0.5000 0.2887 0.0250 0.5000 0.9750
## posterior 4 4998 0.0006 0.0008 0.0004 0.0002 0.0007 0.0018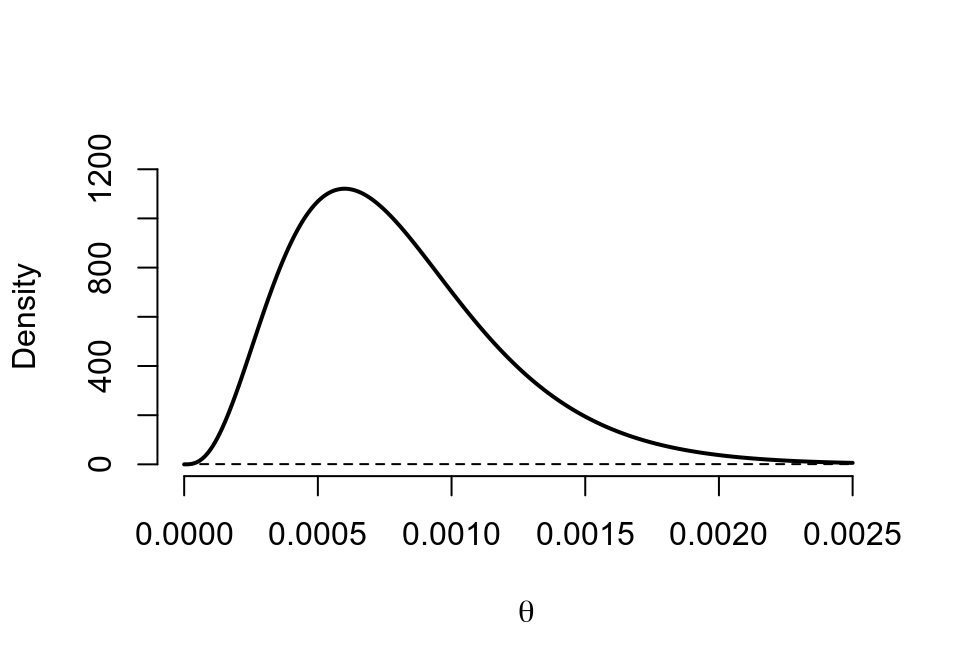
圖 41.12: Prior (dashed) Beta(1,1) vs. Posterior (cont.) Beta(4, 4998)
藥物 B
# Drug B
binbayes(1,1, 1, 7000)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 1 1 NA 0.5000 0.2887 0.025 0.5000 0.9750
## posterior 2 7000 0.0001 0.0003 0.0002 0.000 0.0002 0.0008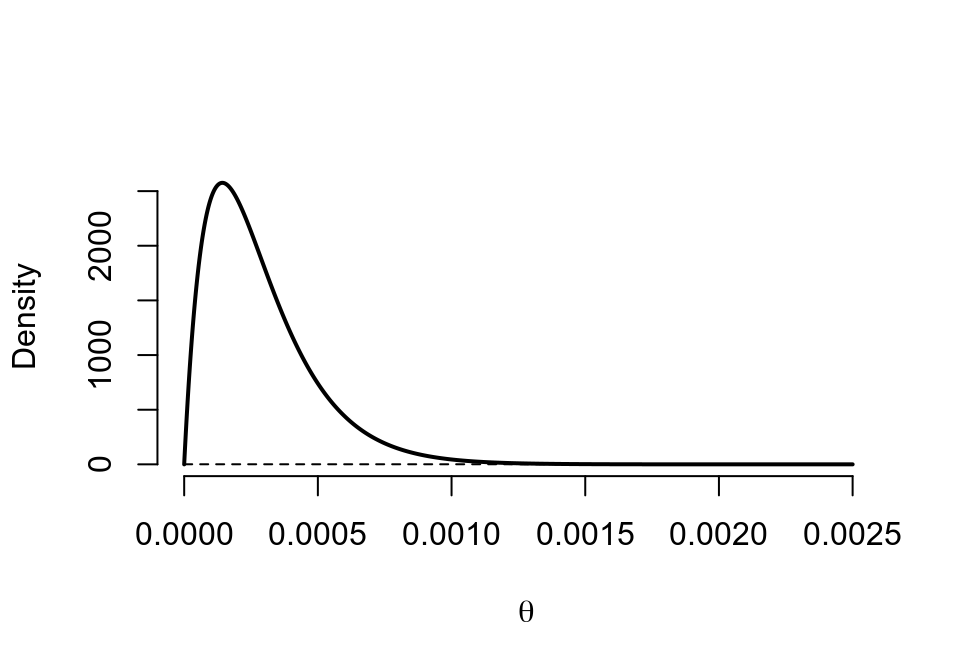
圖 41.13: Prior (dashed) Beta(1,1) vs. Posterior (cont.) Beta(2, 7000)
- 使用 \(\text{Beta}(0.00001,0.00001)\) 作爲先驗概率,重複上面的計算
藥物 A
# Drug A
binbayes(0.00001, 0.00001, 3, 5000)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 0 0 NA 0.5000 0.5000 0.0000 0.5000 1.0000
## posterior 3 4997 0.0006 0.0006 0.0003 0.0001 0.0005 0.0014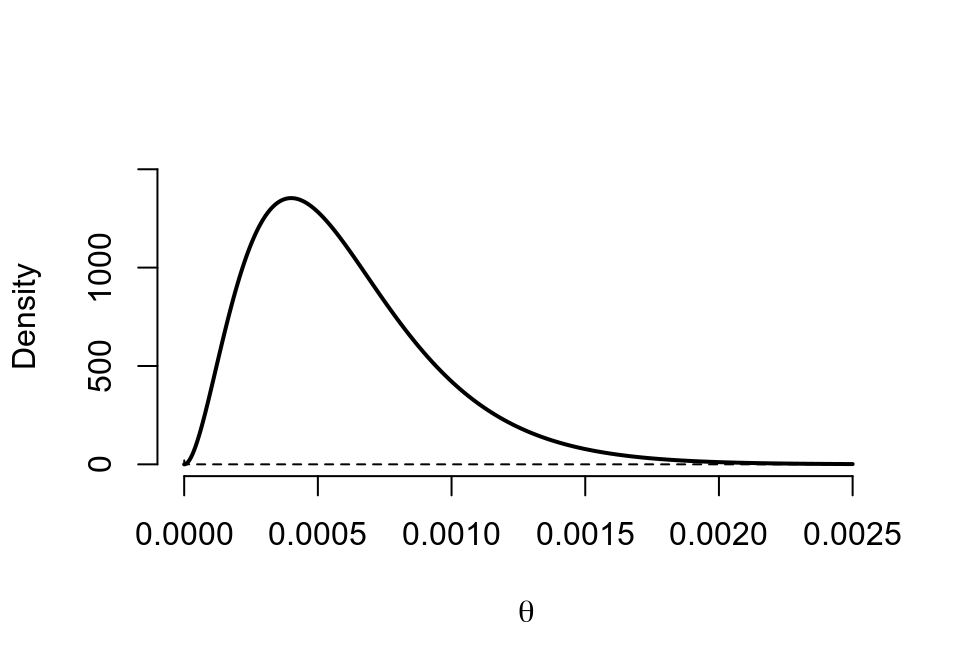
圖 41.14: Prior (dashed) Beta(0.00001,0.00001) vs. Posterior (cont.) Beta(3, 4997)
藥物 B
# Drug B
binbayes(0.00001, 0.00001, 1, 7000)## a b r/n Mean SD 2.5% 50% 97.5%
## prior 0 0 NA 0.5000 0.5000 0 0.5000 1.0000
## posterior 1 6999 0.0001 0.0001 0.0001 0 0.0001 0.0005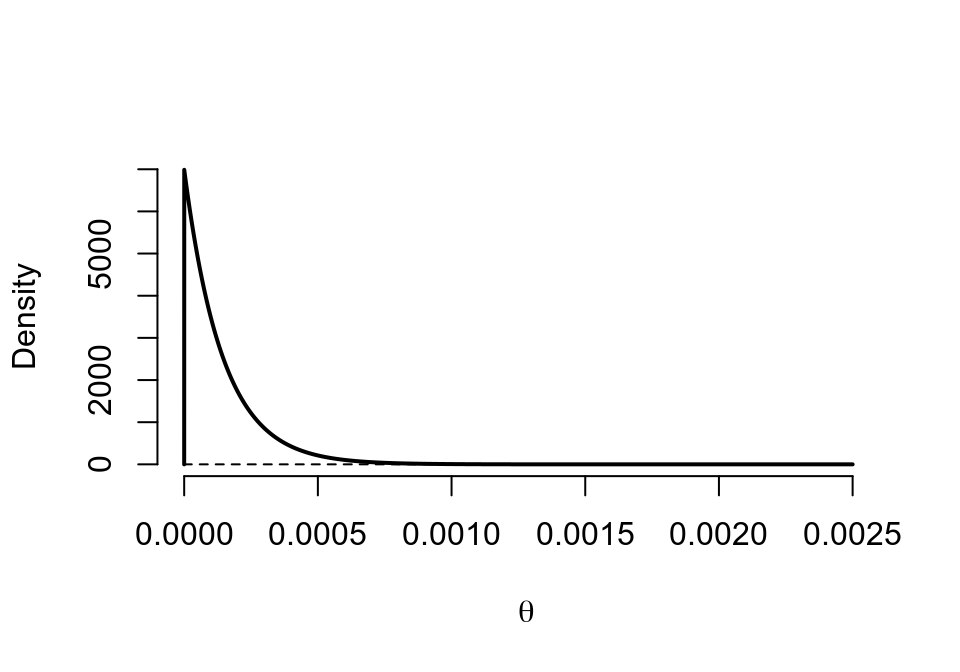
圖 41.15: Prior (dashed) Beta(0.00001,0.00001) vs. Posterior (cont.) Beta(1, 6999)
- 現在使用概率論的計算信賴區間 (confidence intervals) 的方法,求上面數據的精確二項分佈 95% 信賴區間。之前兩問中使用的哪個先驗概率更加接近概率論算法?
#------------------------------------------------
# Binomial confidence intervals
#------------------------------------------------
# r : number of successes
# n : number of trials
# level: confidence level
binom.confint <- function(r,n,level){
p <- r/n
conf <- as.vector(binom.test(r,n,conf.level = 0.95)$conf.int)
out <- c(p,conf)
out <- as.matrix(t(round(out,8)))
colnames(out) <- c("MLE", "L", "U")
return(out)
}
# Drug A
binom.confint(3,5000,0.95)## MLE L U
## [1,] 0.0006 0.00012375 0.00175244# Drug B
binom.confint(1,7000,0.95)## MLE L U
## [1,] 0.00014286 3.62e-06 0.00079569明顯可以看到,先驗概率使用 \(\text{Beta}(0.00001,0.00001)\) 時,事後概率的均值和可信區間的下限值更接近概率論算法。使用先驗概率 \(\text{Beta}(1,1)\) 時,事後概率的可信區間的上限值更接近概率論算法。
- 如果需要你來下結論說,藥物 B 和藥物 A 哪個更加安全? 求 \(\text{Pr}(\theta_B < \theta_A|data)\)。
解
貝葉斯
在計算機的輔助下,這是一個十分簡單的計算。我們從各自的事後分佈中採集大量隨機樣本,然後求 \(\theta_B-\theta_A\) 然後看有多少比例這個數值是小於零的就可以得出結論:
# Simulating from each posterior
set.seed(1001)
post.thetaA <- rbeta(1000000, 3, 4997)
post.thetaB <- rbeta(1000000, 1, 6999)
# Taking the differences
theta.diff0 <- post.thetaB - post.thetaA# Histogram of the differences
hist(theta.diff0,probability = TRUE, breaks = 50, xlab=expression(theta[B] - theta[A]),main = "")
abline(v=0, col="red", lwd=2)
box()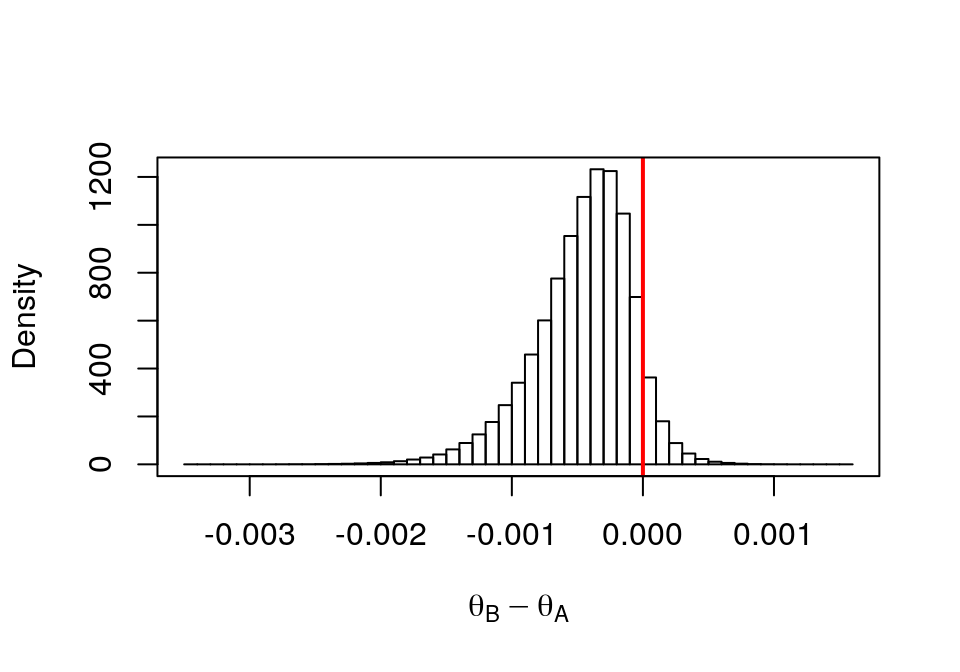
圖 41.16: Histogram of Drug B - Drug A
也可以不採用直方圖而是使用連續曲線:
# Continuous version
plot(density(theta.diff0), xlab=expression(theta[B] - theta[A]), lwd=2, main = "", frame=FALSE)
abline(v=0, col="red", lwd=2)
box()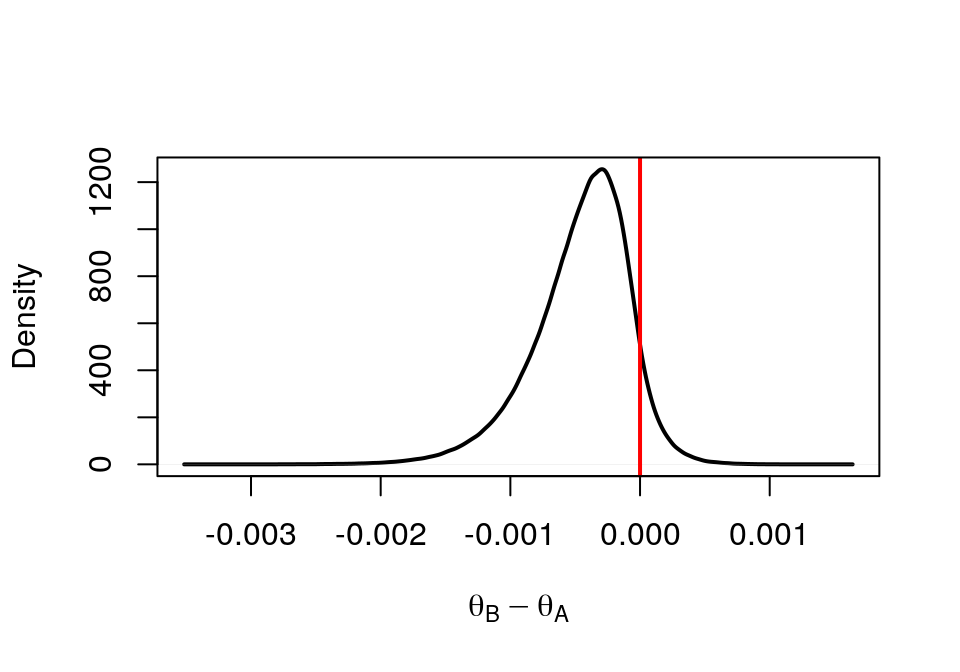
圖 41.17: Density of Drug B - Drug A
計算 \(\text{Pr}(\theta_B < \theta_A|data)\) 和可信區間:
# P(theta[B] < theta[A] | Data)
mean(theta.diff0 <0)## [1] 0.927829# Credible interval for theta[B] - theta[A]
quantile(theta.diff0, c(0.05,0.95))## 5% 95%
## -0.001142862872 0.000052484912quantile(theta.diff0, c(0.10,0.90))## 10% 90%
## -0.00094605885 -0.00004674857# Simulating from each posterior
set.seed(1001)
post.thetaA <- rbeta(1000000, 4, 4998)
post.thetaB <- rbeta(1000000, 2, 7000)
# Taking the differences
theta.diff1 <- post.thetaB - post.thetaAhist(theta.diff1,probability = TRUE, breaks = 50, xlab=expression(theta[B] - theta[A]),main = "")
abline(v=0, col="red", lwd=2)
box()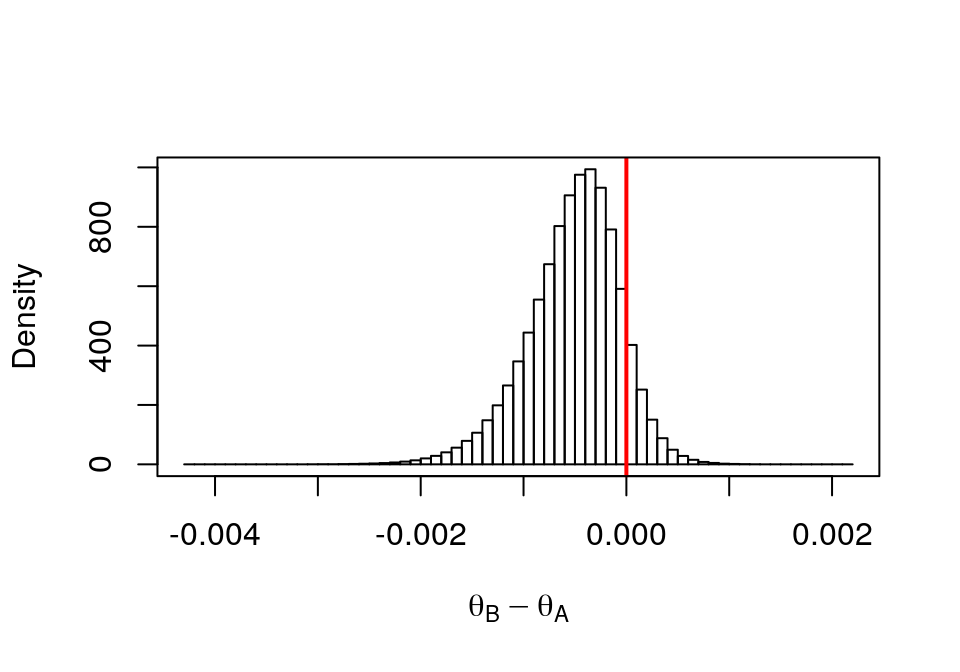
圖 41.18: Histogram of Drug B - Drug A
# Continuous version
plot(density(theta.diff1), xlab=expression(theta[B] - theta[A]), lwd=2,main = "")
abline(v=0, col="red", lwd=2)
box()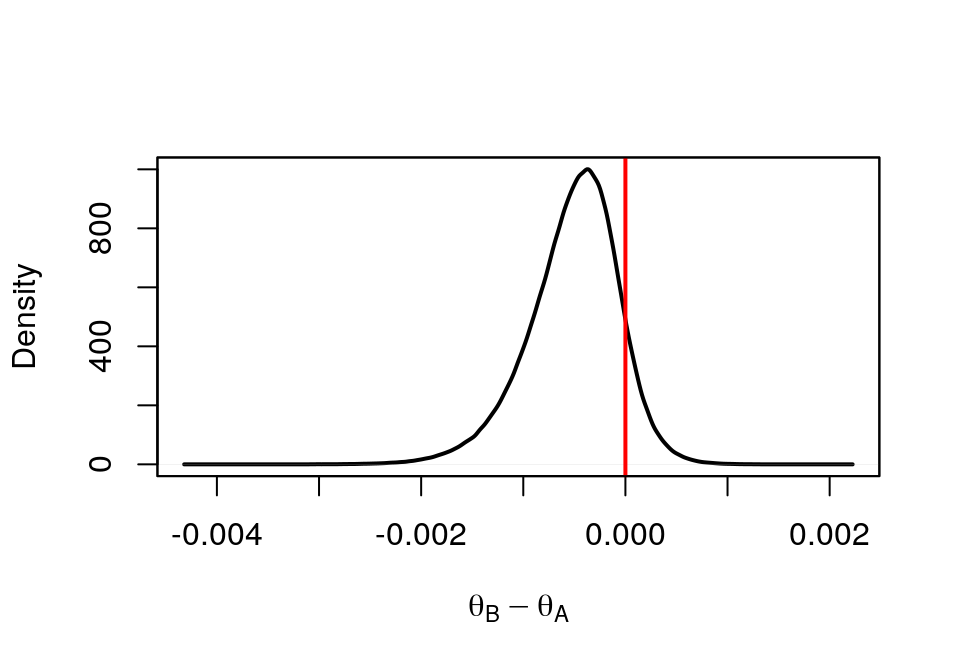
圖 41.19: Density of Drug B - Drug A
計算 \(\text{Pr}(\theta_B < \theta_A|data)\) 和可信區間:
# P(theta[B] < theta[A] | Data)
mean(theta.diff1 <0)## [1] 0.899677# Credible interval for theta[B] - theta[A]
quantile(theta.diff1, c(0.05,0.95))## 5% 95%
## -0.00131289334 0.00013423126quantile(theta.diff1, c(0.10,0.90))## 10% 90%
## -1.0955252e-03 6.5146438e-07概率論算法
# Normal Approximation
diff_mle <- (1/7000)-(3/5000)
diff_se <- sqrt( 1*6999/7000^3 + 3*4997/5000^3 )
U <- diff_mle + 1.28*diff_se
L <- diff_mle - 1.28*diff_se
print(c(U,L))## [1] 0.000022358961 -0.000936644675norm.app <- Vectorize(function(x) dnorm(x,diff_mle,diff_se))# Comparison
plot(density(theta.diff0), xlab=expression(theta[B] - theta[A]), xlim= c(-0.002,0.001), lwd=2, col="red",main = "")
points(density(theta.diff1), xlab=expression(theta[B] - theta[A]), type = "l", col = "blue", lwd=2)
curve(norm.app,-0.0045,0.002,add=T,lwd=2,n=10000)
legend(-0.0021, 1300, c("Posterior with B(0,0)","Posterior with B(1,1)","Frequentist Normal App"), col=c("red","blue","black"),
text.col = "black", lty = c(1, 1, 1), lwd = c(2,2,2),
merge = TRUE, bg = "gray90",cex=0.8)
box()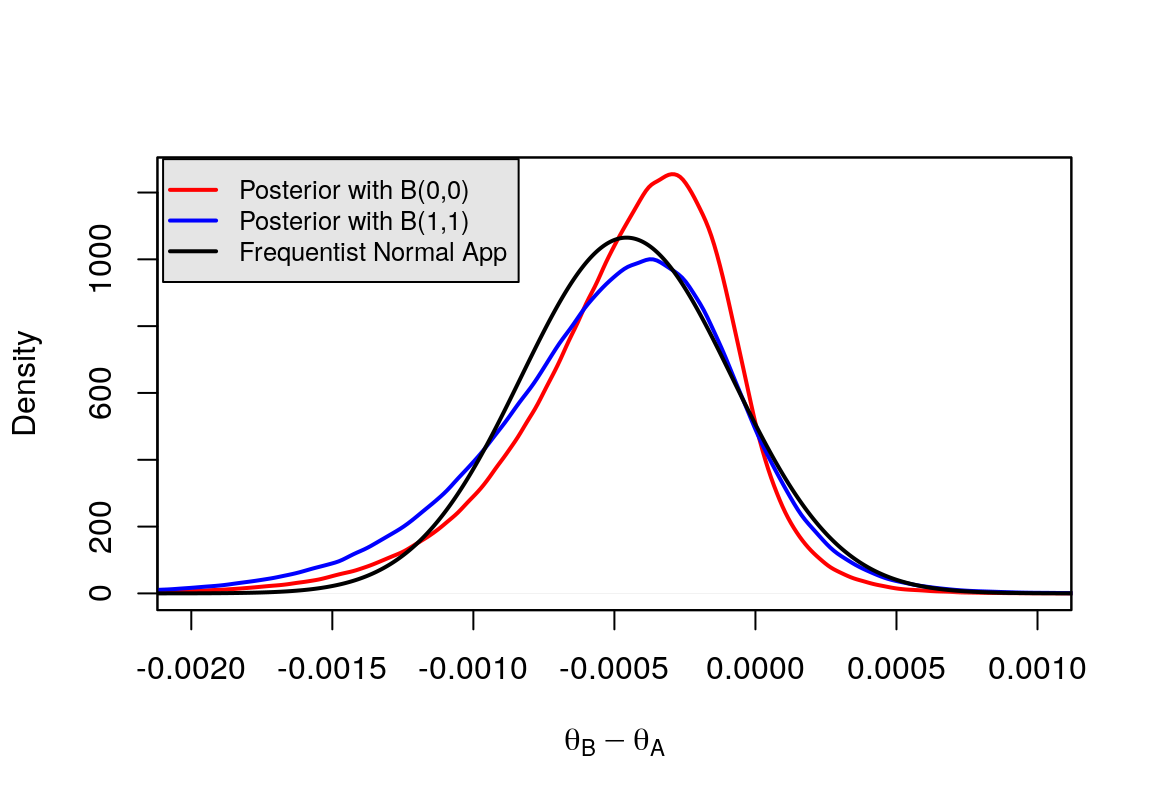
圖 41.20: Comparison of different prior distribution and frequentist approximation