第 53 章 評價模型的表現 Assessing model performance
在廣義線性迴歸的模型表現中,還有幾個重要的概念,精準度 (calibration),變異度 (variation),和分辨能力 (descrimination),本章繼續用二分類結果變量和多個共變量的廣義線性迴歸模型來理解這幾個概念。本章使用邏輯迴歸,也就是 \(\text{logit}\) 鏈接方程的 GLM 來解釋,但是實際上使用其他鏈接方程時,這些概念也是一樣通用的。
當用邏輯迴歸模型擬合了觀測數據。我們可以通過擬合的模型來計算每個觀測對象的預測“成功”概率 (the predicted probability of “success” for each subject)。當使用 \(\text{logit}\) 作鏈接方程時,每個人的預測概率 (predicted probability) 爲:
\[ \hat\pi_i = \frac{\text{exp}(\hat\alpha + \hat\beta_1x_{i1} + \cdots + \hat\beta_px_{ip})}{1+\text{exp}(\hat\alpha + \hat\beta_1x_{i1} + \cdots + \hat\beta_px_{ip})} \]
53.1 精準度 calibration
模型具有良好的精準度時,其計算獲得的每個觀測對象的預測概率,和每個觀測對象本身“成功”的概率期望值保持一致。
\[ E(Y|\hat\pi = p) = p \]
當一個 GLM 具有良好精準度時,我們可以利用它在臨牀醫學中發揮重要的作用 (如預測患者死亡,發病或療效等)。如果模型的精準度不佳,那可能導致的嚴重後果有:治療不必要治療的“健康人”,或者漏掉應該治療的“患者”。當一個模型的預測變量只包含了分類型變量,比較觀測概率和預測概率的過程較爲簡單,比較各個分類變量的排列組合後,不同共變量類型 (covariate pattern) 的患者的觀測值和預測值即可。
這裏再沿用之前 NHANES 的重度飲酒相關的數據 (Section 52.4)來繼續下面對精準度的說明,先擬合一個只有性別作爲預測變量的邏輯迴歸模型:
NHANES <- read_dta("backupfiles/nhanesglm.dta")
NHANES <- NHANES %>%
mutate(Gender = ifelse(gender == 1, "Male", "Female")) %>%
mutate(Gender = factor(Gender, levels = c("Male", "Female")))
with(NHANES, table(Gender))## Gender
## Male Female
## 1391 1157NHANES <- mutate(NHANES, Heavydrinker = ALQ130 > 5)
Model_perf <- glm(Heavydrinker ~ Gender, data = NHANES, family = binomial(link = "logit"))
logistic.display(Model_perf)##
## Logistic regression predicting Heavydrinker
##
## OR(95%CI) P(Wald's test) P(LR-test)
## Gender: Female vs Male 0.17 (0.12,0.24) < 0.001 < 0.001
##
## Log-likelihood = -834.1079
## No. of observations = 2548
## AIC value = 1672.2158完成這個模型之後,在 STATA 裏可以用簡便的 estat gof, table 命令獲取模型擬合的觀測值和期待值表格,然而 R 裏面需要用到 LogisticDx 包裏的診斷命令 dx 獲取 (我花了好幾個小時才找到這個命令,不得不說 STATA 對於流行病的傳統計算真的是比較方便):
LogisticDx::dx(Model_perf)[, 2:6]## GenderFemale y P n yhat
## 1: 0 249 0.179007908 1391 249
## 2: 1 42 0.036300778 1157 42# obtain Pearson's test statistics
chi2 <- sum((LogisticDx::dx(Model_perf)$sPr)^2)
pval <- pchisq(chi2, 1, lower.tail=FALSE)
data.frame(test="Pearson chi2(1)",chi.sq=chi2,pvalue=pval)## test chi.sq pvalue
## 1 Pearson chi2(1) 7.5334682e-25 1在這個只有性別作預測變量的邏輯迴歸模型裏,當然只有男,女,兩種共變量模式 (covariate patterns)。此時,模型的精準度100% (y 是觀測值, yhat 是期待值)。接下來,再在模型中加入一個是否體重超重的二分類變量。再獲取其觀測值和期待值表格如下:
NHANES <- mutate(NHANES, highbmi = bmi > 25)
Model_perf <- glm(Heavydrinker ~ Gender + highbmi, data = NHANES, family = binomial)
logistic.display(Model_perf)##
## Logistic regression predicting Heavydrinker
##
## crude OR(95%CI) adj. OR(95%CI) P(Wald's test) P(LR-test)
## Gender: Female vs Male 0.17 (0.12,0.24) 0.17 (0.12,0.24) < 0.001 < 0.001
##
## highbmi 1.21 (0.93,1.58) 1.11 (0.84,1.46) 0.456 0.453
##
## Log-likelihood = -833.8269
## No. of observations = 2548
## AIC value = 1673.6539LogisticDx::dx(Model_perf)[,2:7]## GenderFemale highbmiTRUE y P n yhat
## 1: 0 1 175 0.183662501 961 176.499664
## 2: 0 0 74 0.168605433 430 72.500336
## 3: 1 1 29 0.037620159 731 27.500336
## 4: 1 0 13 0.034036770 426 14.499664# obtain Pearson's test statistics
chi2 <- sum((LogisticDx::dx(Model_perf)$sPr)^2)
pval <- pchisq(chi2, 1, lower.tail=FALSE)
data.frame(test="Pearson chi2(1)",chi.sq=chi2,pvalue=pval)## test chi.sq pvalue
## 1 Pearson chi2(1) 0.29881856 0.58462403此時的模型有 4 種共變量模式 (covariate patterns),其實就是性別和超重與否的四種排列組合。這裏報告的 Pearson's test statisitics 我們在前一章講邏輯迴歸殘差的部分有講過,它就是 Pearson 標準化殘差的平方和。此處它的卡方檢驗,檢驗零假設是“模型制定正確”。所以,我們無足夠的證據 \((p=0.58)\) 來反對零假設,數據觀測值和模型的期待值似乎也較爲吻合。
但是一旦模型裏加入了新的連續型變量,整個模型的共變量模式 (covariate patterns),將會變得很難進行上面的觀測值和期待值的比較,由於加入的連續型變量會導致模型的共變量模式變得越來越多,甚至接近與樣本量個數 \(n\),也就是每個共變量模式的樣本越來越小,直至等於 \(1\)。連續型變量的模型中我們 Hosmer-Lemeshow 檢驗 (Section 46.4) 而不是 Pearson 統計檢驗量。
53.2 可解釋因變量的變異度及 \(R^2\) 決定係數
精準度的確重要,但是模型精準度好,只代表它和過去擬合它的觀測數據之間關係接近,不代表它能準確地預測其他的個體的概率。前文中只有性別作爲預測變量的邏輯迴歸模型就是實例,它和擬合的觀測數據做到了 100% 完美擬合,但是不用大腦思考也知道,除了性別還有其他更多的能預測一個人是否是重度飲酒者的變量,且擁有能提升模型的擬合程度的潛質。只有性別作預測變量的邏輯迴歸模型,最大的問題在於,它只能解釋個體之間重度飲酒者概率的變異度(variation)中極少的部分。事實上,它只能解釋能夠用性別解釋的個體之間重度飲酒者概率的變異度。所以,此處打算引伸出的概念就是類似簡單線性迴歸中的 \(R^2\) 決定係數 (Section 28.2.3) 的定義。
你應該還能記得,在簡單線性迴歸中決定係數 \(R^2\) 的含義是因變量的平方和 (平方和) 中能被模型解釋的部分:
\[ R^2 = \frac{SS_{REG}}{SS_{yy}} = \frac{\sum_{i=1}^n(\hat{y}_i-\bar{y})^2}{\sum_{i=1}^n(y_i-\bar{y})^2} = 1-\frac{\sum_{i=1}^n(y_i-\hat{y}_i)^2}{\sum_{i=1}^n(y_i-\bar{y})^2} \]
許多前人嘗試過試圖將線性迴歸的決定係數概念擴展到廣義線性迴歸模型中來,但是目前爲止的嘗試都不太成功。所以,只有一些借鑑了簡單線性迴歸的的決定係數思想的概念,得到了擴展,但是要注意,他們本身和決定係數是有區別的。
“假決定係數 (pseudo-R2)”,別名 McFadden 的似然比係數 (McFadden’s likelihood ratio index)
\[R^r_{\text{McFadden}} = 1 - \frac{\ell_c}{\ell_\text{null}}\]
其中 \(\ell_c, \ell_{\text{null}}\) 分別是模型的極大似然值 和零模型時的極大似然值。
假決定係數,之所以被冠名“假”,因爲這個係數你也可以在簡單線性迴歸下計算,但是其大小常常和一般我們熟知的決定係數結果有些差距。所以,常有人質疑其到底是否可用 (因爲它在現實生活中根本不可能取到 \(0\) 或 \(1\))。
在 R 裏,擬合了邏輯迴歸以後通常也不會報告假決定係數值的大小。所以想要獲得它,需要 DescTools::PseudoR2() 命令來獲取:
PseudoR2(Model_perf)## McFadden
## 0.078752188上文中包含了性別和是否超重的模型的假決定係數只有區區 \(0.0785\),可見,只有性別和是否超重兩個變量只能解釋結果變量變異度中極少的部分。
53.3 分辨能力 descrimination
53.3.1 敏感度和特異度
評價一個邏輯迴歸的表現,最後的一個手段是,看這個模型對觀測對象的分辨能力。也就是,當我們人爲地指定一個概率值 \(p\) 作爲是否患病的閾值,那麼,觀測對象通過模型計算獲得的概率,已經觀測對象本身的觀測概率之間,其實可以用診斷學的敏感度和特異度的概念來評價模型對於觀測對象的分別能力到底如何。所以邏輯迴歸模型的敏感度就是,病例中通過模型計算被判斷爲陽性的概率;特異度是,非病例中,通過模型計算本判斷爲陰性的概率。這個敏感度特異度當然會隨着我們選擇的閾值而變化。
圖 53.1 所示的是,將性別, BMI,和年齡三個變量放入邏輯迴歸模型之後,模型對於觀察對象的分辨能力的 ROC 示意圖。計算所得的 ROC 曲線下面積爲 0.7484。如果一個模型是失敗的,那麼其曲線下面積爲 (接近) 0.5。也就是會十分貼近 \(y=x\) 的直線。
Model_perf <- glm(Heavydrinker ~ Gender + bmi + ageyrs, data = NHANES, family = binomial)
ROC_graph <- lroc(Model_perf, grid.col = "grey", lwd = 3, frame = FALSE)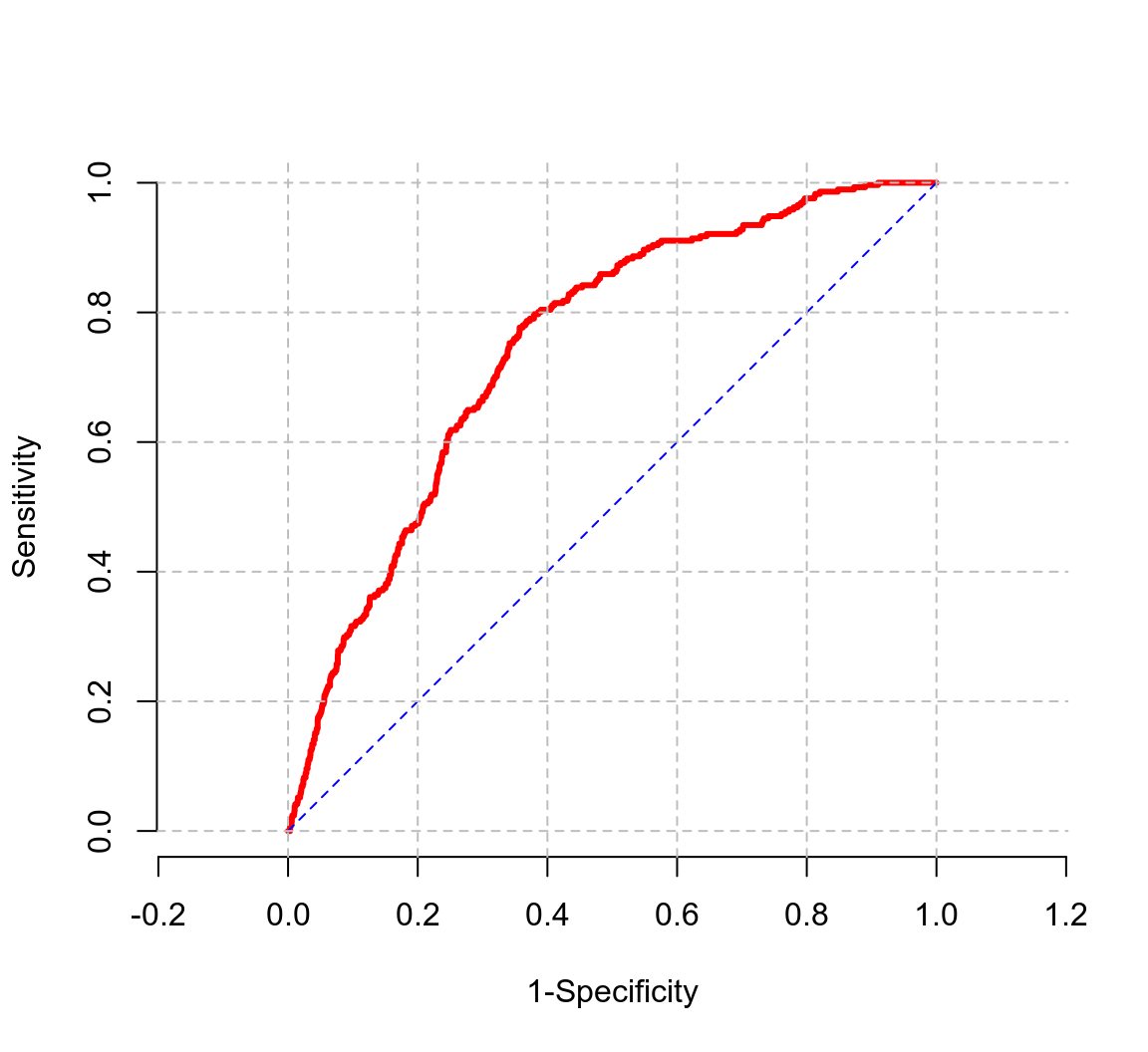
圖 53.1: Receiver operating curve for model for heavy drinking with gender, age, and BMI
ROC_graph$auc## [1] 0.74835297曲線下面積,AUC 的另一個有用的意義是,從觀測對象中任意選取兩個人,一個是病例 \((y_i = 1)\),一個是非病例 \((y_j = 0)\),那麼曲線下面積就是模型能夠正確將這兩個對象按照是否患病的可能性進行排序的概率。 \(\text{AUC} = \text{Pr}(\pi_i > \pi_j | y_i = 1 \& y_j = 0)\)
ROC 曲線本身有自己的優點,也有許多侷限性。最近有另外一個用於診斷的新型曲線–預測曲線(Pepe et al. 2007)。預測曲線繪製的是,觀測對象的擬合後概率 \(\hat\pi_i\) 和這個概率在所有觀察對象的擬合後概率的百分位數 (percentile) 之間的曲線。一個模型,如果給許多對象相似的概率,那麼不能說這個模型的分辨能力足夠好。同時,此圖也能一目瞭然讓人看到大概多少對象的患病概率是大於一定水平的。
Predictive <- data.frame(fitted(Model_perf), rank(fitted(Model_perf))/2548)
names(Predictive) <- c("hatpi", "percentile")
ggplot(Predictive, aes(x = percentile, y = hatpi)) + geom_line() +
ylim(0, 0.4) +
labs(x = "Risk percentile", y = "Heavy drinker risk") + theme_bw() +
theme(axis.title = element_text(size = 17),
axis.text.x = element_text(size = 15),
axis.text.y = element_text(size = 15))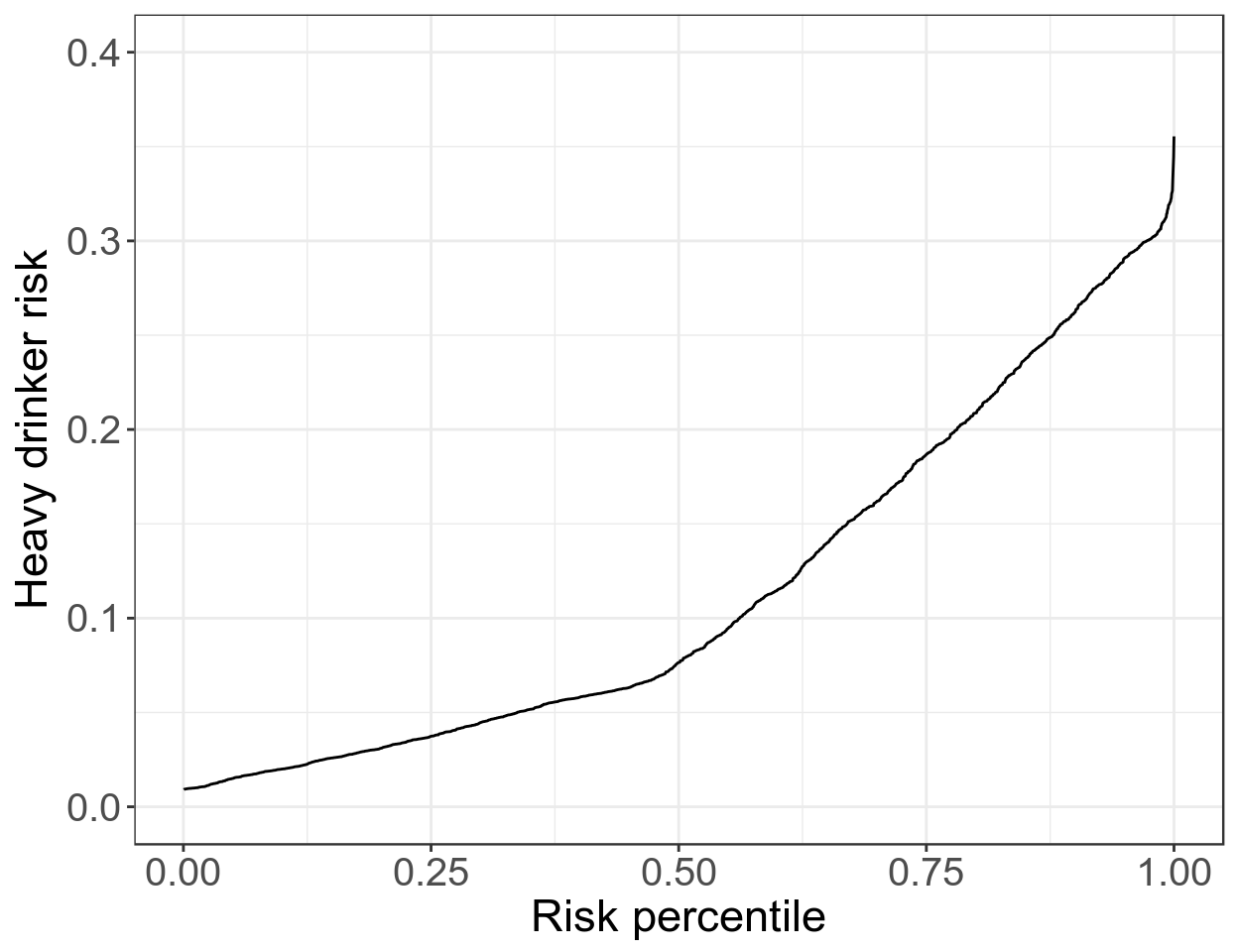
圖 53.2: Predictiveness curve for model for heavy drinking with gender, age, and BMI as covariate
圖 53.2 所示的是,性別,年齡,BMI作爲共變量的邏輯迴歸模型的預測變量,預測重度飲酒概率的模型給出的預測曲線。從圖中可見,大多數人的概率值各不相同。而且,圖中也能告訴我們大約 20% 的觀測對象其重度飲酒的概率大於 0.2。
References
Pepe, Margaret S, Ziding Feng, Ying Huang, Gary Longton, Ross Prentice, Ian M Thompson, and Yingye Zheng. 2007. “Integrating the Predictiveness of a Marker with Its Performance as a Classifier.” American Journal of Epidemiology 167 (3). Oxford University Press: 362–68.