Chapter 8 Mar 8–14: Multiple OLS Linear Regression
This chapter has now been updated for spring 2021 and is ready for use in HE-802.
This week, our goals are to…
- Run OLS linear regression with more than one independent variable and interpret the results.
Announcements and reminders
This week, we will have group work sessions as usual on Wednesday and Friday at 5 p.m. Boston time. You should have a calendar invitation from Nicole for these sessions. Additionally, you can always contact Nicole and Anshul to schedule an individual or group session at a different time.
I suggest that you briefly look at this week’s assignment before starting the reading in the chapter below.
This week is a good week to use your own data to do the assignment, if you wish (instead of the data provided in the assignment). This could, if you want, be the data you use for your final project in this course.
8.1 Multiple OLS linear regression
Previously, we looked at simple OLS (ordinary least squares) linear regression. In simple OLS, we had one independent variable that we were using to try to predict the values of the dependent variable. To accomplish this, we created a regression model which could be described by an equation. Plugging numbers into the equation gave us predicted values of the dependent variable. We also generated inferential statistics to determine if the relationship between the dependent and independent variable in our sample is also likely the case or not in the population of interest. Finally, we looked at the \(R^2\) statistic to determine the goodness-of-fit of our regression model.
In this section, we will replicate the simple OLS process, this time with multiple independent variables that are working together to try to predict the dependent variable. Many of the features that we saw in simple OLS will again be involved with multiple OLS. First let’s clearly distinguish between simple OLS and multiple OLS, below.
Simple compared to multiple OLS linear regression:
Simple OLS linear regression: One independent variable predicting one dependent variable. The dependent variable is the outcome of interest that we care about.
Multiple OLS linear regression: Multiple independent variables predicting one dependent variable. The dependent variable is the outcome of interest that we care about.
Remember:
All regression models have just one dependent variable (outcome of interest). The dependent variable is typically the result or outcome you are interested in, such as how much weight someone can lift, how much somebody’s blood pressure changes, or how well a student does on a test. Independent variables are measurable constructs that we hypothesize are causing or are associated with the dependent variable.
In all cases—simple linear regression, multiple linear regression, or other types of regression we will learn later—all regression analyses are using numbers to help us answer a question. We will always start with a question we want to answer, define relevant metrics (variables, for our purposes), make sure all aspects of our research design are responsible and logical, and then run a regression analysis to try to answer the question. Then we evaluate how well-fitting and trustworthy our results are before drawing a final conclusion (an answer to our question). This procedure is universal, even when the specific regression methods change.
In the rest of this section, we will learn how to run a multiple OLS linear regression, interpret its results, and evaluate its goodness-of-fit.
8.1.1 Multiple OLS linear regression in R
In this section, we will run a multiple OLS linear regression model in R and interpret the results. We will continue to use the mtcars dataset that was used earlier in this textbook to introduce simple OLS. Note that “multiple” OLS regression refers to a regression analysis in which there is more than one independent variable, which is the focus of this section. It is fine to refer to a regression model with multiple independent variables as a multiple OLS linear regression, multiple linear regression, OLS linear regression, or linear regression. All of these terms mean the same thing. The terms regression analysis and regression model can also be used interchangeably. They mean the same thing, for our purposes.
Here are the key details of the example regression analysis we will conduct:
- Question: What is the association between displacement and weight in cars, controlling for rear axle ratio and transmission?
- Dependent variable:
disp; displacement in cubic inches. - Independent variables:
wt, weight in tons;drat, rear axle ratio; andam, transmission type. - Dataset:
mtcarsdata in R, loaded asdin our example.
Run the following code to load the data and follow along with the example:
d <- mtcarsNote that you can also run the following code to learn more about this data:
?mtcarsRemember that d is a copy of the dataset mtcars. We will do all of our analysis on the dataset d.
Keep reading to see how we can try to answer our question above using multiple OLS regression!
8.1.2 Examine variables before running regression
Before we run a multiple linear regression, it can help to inspect our data first in a variety of ways. We have already learned how to calculate descriptive statistics for individual variables, make one-way and two-way tables, and make grouped descriptive statistics. Another useful way to learn about your data is to make a correlation matrix.
The code below creates a fancy correlation matrix for us:
if (!require(PerformanceAnalytics)) install.packages('PerformanceAnalytics')
library(PerformanceAnalytics)
chart.Correlation(d, histogram = TRUE)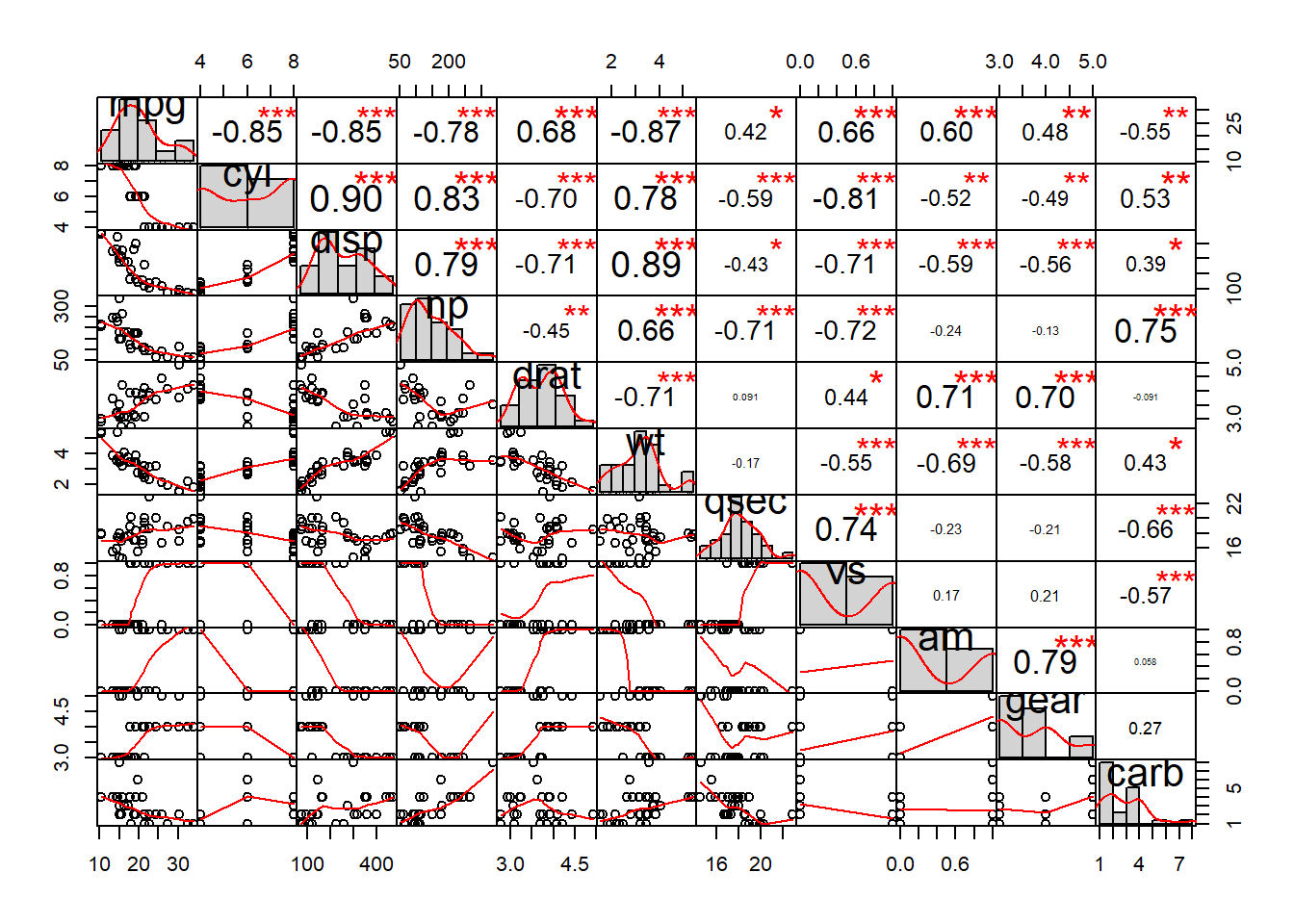
With the code above, here is what we asked the computer to do for us:
if (!require(PerformanceAnalytics)) install.packages('PerformanceAnalytics')– Check if thePerformanceAnalyticspackage is already installed and install it if not.library(PerformanceAnalytics)– Load thePerformanceAnalyticspackage.chart.Correlation(d, histogram = TRUE)– Run the functionchart.Correlation(...), which creates a correlation matrix. We put two arguments in thechart.Correlation(...)function:dtells the computer that we want a correlation matrix of the variables in the datasetd.histogram = TRUEtells the computer that we also want it to include a histogram of the distribution of each variable along the diagonal of the correlation matrix.
Let’s interpret the correlation matrix that we got, focusing on the following key items:
- The matrix shows us the pairwise relationships—meaning each combination of two variables separately—for all variables in our dataset
d. - On the diagonal from the top-left to bottom-right we see the name of each variable and a histogram of how that variable is distributed. For example, we see that the variable
dispmight be bimodal. We see that the variableamhas just two possible values. - In the top-right half of the matrix, we see the numeric correlation coefficients calculated for each pair of variables. For example, we see that
dispanddratare correlated at -0.71.dispandwtare correlated at 0.89. - In the bottom-left half of the matrix, we see scatterplots of each combination of variables. This tells us, for example, that
dispandhpappear to be highly correlated, whilewtandqsecare not highly correlated.
You may have noticed that the correlation matrix above is pretty large and hard to read. It also involves many variables that are unrelated to us answering our question of interest. Let’s make a smaller matrix that is more specific to our current goals.
The code below creates a copy of the dataset d called d.partial106 which only contains the four variables that we are going to use:
d.partial <- mtcars[c("disp","wt","drat", "am")]And now we can recreate the correlation matrix only for d.partial:
if (!require(PerformanceAnalytics)) install.packages('PerformanceAnalytics')
library(PerformanceAnalytics)
chart.Correlation(d.partial, histogram = TRUE)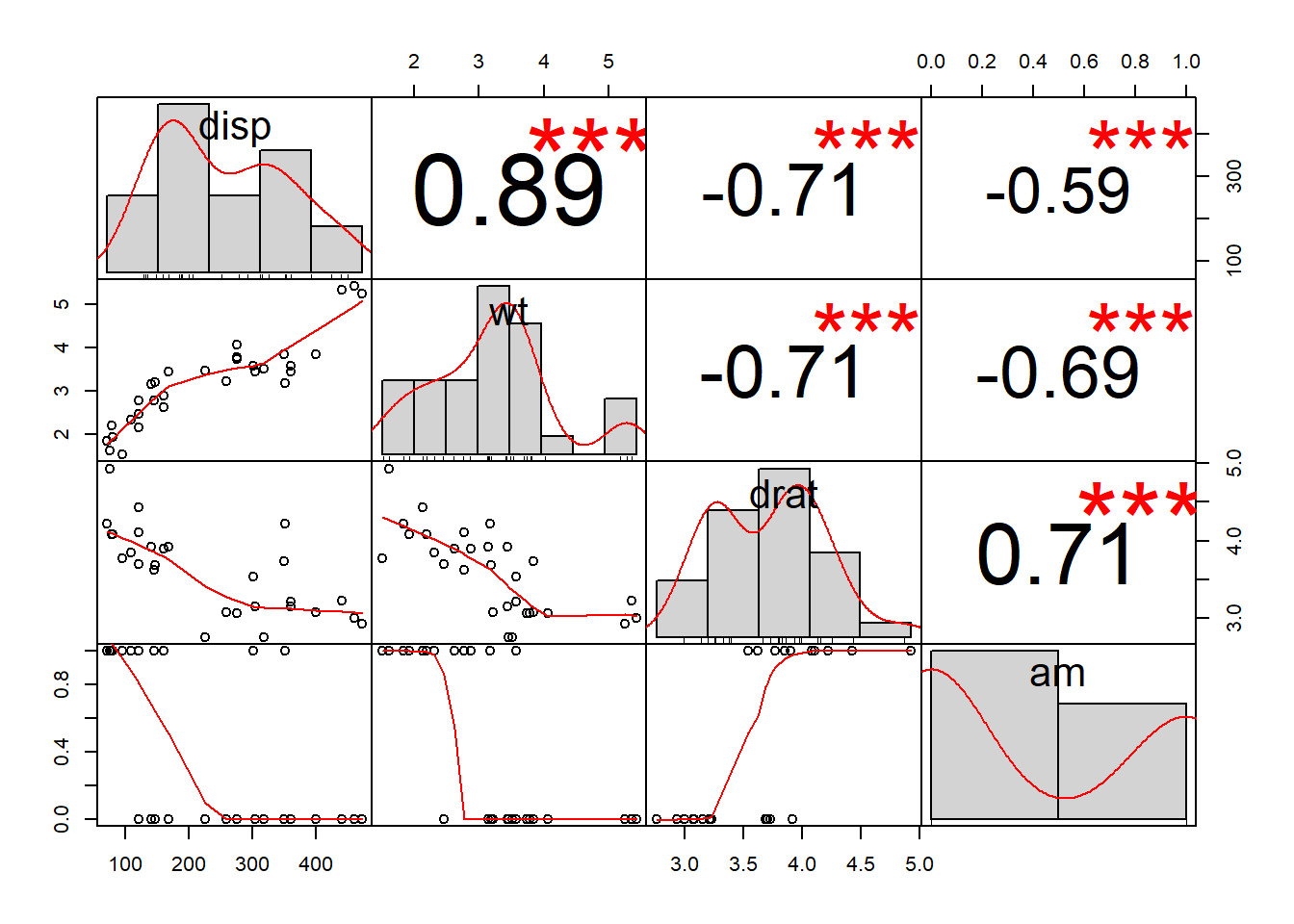
Above, we see an easier-to-read correlation matrix with only our variables of interest. Note that it was NOT necessary to make the first, larger matrix before we made the second, more readable one. We can go straight to the second one without making the first one.107
We will not necessarily always make a correlation matrix if we are doing an analysis with a large number of variables, but it is good to look at some pairwise correlations if possible before you continue with your analysis.
8.1.3 Multiple OLS in our sample
Let’s start to answer our question articulated above by making a multiple OLS linear regression model. Remember, our question of interest is: What is the association between displacement and weight in cars, controlling for rear axle ratio and transmission?
The code below runs a multiple OLS regression to address our question within our sample of 32 observations:
reg1 <- lm(disp~wt+drat+am, data = d)Here is what we are telling the computer to do with the code above:
reg1– Create a new regression object calledreg1. This can be named anything, not necessarilyreg1.<-– Assignreg1to be the result of the output of the functionlm(...)lm(...)– Run a linear model using OLS linear regression.disp– This is the dependent variable in the regression model.~– This is part of a formula. This is like the equals sign within an equation.wt– This is the first independent variable in the regression model.+– This is a plus sign. We put a plus sign in between all independent variables in the regression model we are making.drat– This is the second independent variable in the regression model.am– This is the third independent variable in the regression model. We can add an unlimited number of independent variables. In this case we stopped at three.data = d– Use the datasetdfor this regression.dis where the dependent and independent variables are located. If our dataset had a different name, likemydataoraldfji, then we would replacedwithmydataoraldfjiin this part of the code.
If you look in the Environment tab in RStudio, you will see that reg1 is saved and listed there. Our regression results are stored as the object reg1 in R and we can refer back to them any time we want, as we will be doing multiple times below.
We are now ready to inspect the results of our regression model by using the summary(...) function to give us a summary of reg1, like this:
summary(reg1)##
## Call:
## lm(formula = disp ~ wt + drat + am, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -62.52 -44.03 -13.08 28.12 136.55
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 62.14 137.78 0.451 0.655
## wt 104.81 16.09 6.512 4.67e-07 ***
## drat -50.75 30.29 -1.675 0.105
## am 34.23 31.57 1.084 0.288
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 57.03 on 28 degrees of freedom
## Multiple R-squared: 0.8088, Adjusted R-squared: 0.7883
## F-statistic: 39.47 on 3 and 28 DF, p-value: 3.438e-10Above, we see summary output of our regression model. The most important section that we will look at first is the Coefficients section of the output. We will use these coefficients to write the equation of our regression model.
Here are some new details about multiple regression model equations:
- So far in this textbook, we have written a simple regression equation like this: \(\hat{y}=b_1x+b_0\)
- Now we will write a more complicated multiple regression equation like this: \(\hat{y}=b_1x_1+b_2x_2+...+b_0\).
- There will now be one \(x_{something}\) for each independent variable in our regression model.
- There will now be one \(b_{something}\) number for each predicted slope in our regression model. \(b_1, b_2, b_3\) and so on (one for each independent variable) can be called the slopes, coefficients, or betas of the regression model. It is fine to write these as \(b\), \(B\), or \(\beta\).
- There will still be a single \(b_0\) which represents the intercept of the regression model. This still tells us the predicted value of the dependent variable when the values of all independent variables are 0.
- There is still a \(\hat{y}\) on the left side of the equation, representing the predicted value(s) of the single dependent variable that is our outcome of interest.
Here is the regression equation for reg1: \(\hat{disp} = 104.81 wt - 50.75 drat + 34.23 am + 62.14\)
This equation came directly from the regression table:
- 104.81 is the coefficient of
wtin the summary table. This means that in our sample, for every one ton increase inwt,dispis predicted to increase by 104.81 cubic inches on average, controlling for the other independent variablesdratandam. - -50.75 is the coefficient of
dratin the summary table. This means that in our sample, for every one unit increase indrat,dispis predicted to decrease by 50.75 cubic inches on average, controlling for the other independent variableswtandam. - 34.23 is the coefficient of
amin the summary table.amis a dummy variable. The computer doesn’t “know” this (the computer just thinks thatamis a continuous numeric variable like the others), but we do.- If
amhad been a typical continuous numeric variable, here is how we would interpret its coefficient: In our sample, for every one unit increase inam,dispis predicted to increase by 34.23 cubic inches on average, controlling for the other independent variableswtanddrat. - However, since
amis a dummy variable, we humans can interpret it differently. Note that observations that haveamcoded as 0 are cars with an automatic transmission. And observations withamcoded as 1 are cars with a manual transmission. For us humans, a “one-unit increase inam” can only possibly represent a change from 0 to 1. A change from 0 to 1 inammeans a change from automatic (which is 0) to manual (which is 1). - This is how we humans interpret the
amcoefficient: In our sample, a car with manual transmission is predicted to have a value ofdispthat is on average 34.23 cubic inches higher than thedispof a car with automatic transmission, controlling forwtanddrat. - Here’s another way to think about it: the dummy variable
amdivides our 32 observations into two groups, those with automatic transmission (am = 0) and those with manual transmission (am = 1). When we put the dummy variableaminto the regression, the result just tells us the estimated average difference in the dependent variabledispbetween automatic and manual cars. Dummy variables just help us estimate differences between two groups.
- If
We will learn more about dummy variables in the near future in this class.
Notice the following characteristics of our results and interpretation of our regression results for our sample:
In our interpretation of the regression results, we always used the words predicted and average. This is because the relationship between the dependent variable
dispand any of the independent variables is not a true exact relationship. It is a best guess about the relationship. This best guess is just an average trend across all of the observations in our sample. It is not the exact truth that if we added one ton of weight to a car, itsdispwould increase by exactly 104.81 cubic inches. Instead, 104.81 cubic inches is just the predicted average increase indispfor each additional ton heavier a car is.All of the relationships that we calculated in our regression results are associations, not causal relationships. We did NOT find that each one unit increase in
dratcauses an average decrease of 50.75 cubic inches indisp. We merely found that each one unit increase indratis associated with an average decrease of 50.75 cubic inches indisp, when controlling forwtandam.The key part of our interpretations of the slopes in our regression results were the magic words “For every one unit increase in X…,” with “X” referring to any of the independent variables. These are the first words that should come to your mind when you try to interpret a regression result. It may be worthwhile to write these words on a sticky note next to your workstation until you have them memorized.
The question we initially wanted to answer only concerned the relationship between the dependent variable
dispand the independent variablewt.dratandamwere just supposed to be control variables that we adjusted for in the regression model. But why did we interpret the results above without giving any special attention to thewtcoefficient? Well, from the computer’s perspective, it is calculating for us the relationship between the dependent variable and each independent variable one at a time, controlling for any other independent variables. So this regression model is actually answering three questions all at once, even though we only care about the answer to the first one:- What is the relationship between
dispandwt, controlling fordratandam? - What is the relationship between
dispanddrat, controlling forwtandam? - What is the relationship between
dispandam, controlling forwtanddrat?
- What is the relationship between
It is important to note that any relationships we found between variables are just associations rather than causal relationships.
With our regression equation—\(\hat{disp} = 104.81 wt - 50.75 drat + 34.23 am + 62.14\)—we can calculate predicted values for our dependent variable disp by plugging in values of wt, drat, and am.
Let’s practice calculating a predicted value of disp for an observation (a car, in this case) with the following characteristics:
- Name of car: Yalfo
wt= 2 tons- drat = 2 units
- manual transmission
We follow these steps to make the prediction:
- Start with initial regression equation: \(\hat{disp} = 104.81 wt - 50.75 drat + 34.23 am + 62.14\)
- Slightly re-write initial regression equation, for clarity: \(\hat{disp} = (104.81*wt) + (-50.75*drat) + (34.23*am) + 62.14\)
- Plug specific characteristics of Yalfo into equation: \(\hat{disp} = (104.81*2) + (-50.75*2) + (34.23*1) + 62.14 = 204.49 \text{ cubic inches}\)
Note that we plugged in 1 for am since Yalfo has a manual transmission and am is coded as 1 for observations with manual transmissions.
R can do the calculation for us with the following code:
(104.81*2) + (-50.75*2) + (34.23*1) + 62.14## [1] 204.49You can put the code above into an R code chunk in RMarkdown and run it to get the answer (which in this case is our predicted value for Yalfo).
Now let’s imagine another car called the Yalfo-2. Yalfo-2 is the same as Yalfo except Yalfo-2 has an automatic transmission. Then we would change am from 1 (for the manual Yalfo) to 0 (for the automatic Yalfo-2), like this:
\[\hat{disp} = (104.81*2) + (-50.75*2) + (34.23*0) + 62.14 = 170.26 \text{ cubic inches}\]
The Yalfo has a predicted displacement of 204.49 cubic inches and the Yalfo-2 has a predicted displacement of 170.26 cubic inches. This is a difference of \(204.49 - 170.26 = 34.23 \text{ cubic inches}\). This difference is the same value as the coefficient of am! We just demonstrated that the coefficient of the dummy variable am tells us the predicted difference between a car with manual transmission and automatic transmission.
Let’s practice one more important calculation of a predicted value of another hypothetical observation (another car):
- Name of car: FeatherMobile
wt= 0 tons- drat = 0 units
- automatic transmission
We plug the characteristics of the FeatherMobile into the regression equation:
\[\hat{disp} = (104.81*0) + (-50.75*0) + (34.23*0) + 62.14 = 62.14 \text{ cubic inches}\]
This shows that the intercept of a regression model is the predicted value of the dependent variable—disp, in this case—when all of the independent variables are 0. As we discussed when we learned about simple regression, the intercept is often meaningless. In this case, there is no such thing as a car that is weightless, so the intercept is meaningless. Nevertheless, it is important to know what the intercept theoretically represents.
Our regression model tells us the exact predicted relationship on average between displacement and weight in our sample. Everything written above has pertained to our sample only. We will now turn our attention to inference and our population of interest.
8.1.4 Multiple OLS in our population
We are now interested in answering this question: What is the true relationship between disp and wt in the population from which our sample was selected, when controlling for drat and am?
To answer this question, we have to look at some of the inferential statistics that are calculated when we do a regression analysis. We also need to conduct some diagnostic tests of assumptions before we can trust the results.
We will start by calculating the 95% confidence intervals for our estimated regression coefficients, by running the confint(...) function on our saved regression results—called reg1—like this:
confint(reg1)## 2.5 % 97.5 %
## (Intercept) -220.08792 344.36793
## wt 71.84099 137.77595
## drat -112.79506 11.29956
## am -30.44439 98.89628It is also possible to create a regression summary table that contains everything we need all in one place, using the summ(...) function from the jtools package.
Run the following code to load the package and see our regression results:
if (!require(jtools)) install.packages('jtools')
library(jtools)
summ(reg1, confint = TRUE)| Observations | 32 |
| Dependent variable | disp |
| Type | OLS linear regression |
| F(3,28) | 39.47 |
| R² | 0.81 |
| Adj. R² | 0.79 |
| Est. | 2.5% | 97.5% | t val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 62.14 | -220.09 | 344.37 | 0.45 | 0.66 |
| wt | 104.81 | 71.84 | 137.78 | 6.51 | 0.00 |
| drat | -50.75 | -112.80 | 11.30 | -1.68 | 0.10 |
| am | 34.23 | -30.44 | 98.90 | 1.08 | 0.29 |
| Standard errors: OLS |
Here is what the lines of code above accomplished:
if (!require(jtools)) install.packages('jtools')– Check if thejtoolspackage is already installed and install it if not.library(jtools)– Load thejtoolspackage.summ(reg1, confint = TRUE)– Create a summary output of the savedreg1regression result. Include the confidence intervals (becauseconfintis set toTRUE).
We can now interpret the 95% confidence intervals that were calculated:
wt: In the population from which our sample was drawn, we are 95% confident that the slope of the relationship between displacement and weight is between 71.84 and 137.78 cubic inches, controlling fordratandam. In other words: In our population of interest, we are 95% confident that for every one ton increase in a car’s weight, its displacement is predicted to increase by at least 71.84 cubic inches or at most 137.78 cubic inches, controlling fordratandam. Since this 95% confidence interval is entirely on one side of 0—above, in this case—we can conclude with high certainty that there is a positive relationship in the population betweendispandwt. This is the answer to our question of interest, if our data passes all diagnostic tests that we will conduct later.drat: In the population from which our sample was drawn, we are 95% confident that the slope of the relationship between displacement and rear axle ratio is between -112.80 and 11.30 cubic inches, controlling forwtandam. In other words: In our population of interest, we are 95% confident that for every one unit increase in a car’s rear axle ratio, its displacement is predicted to change by at least -112.80 cubic inches or at most 11.30 cubic inches, controlling fordratandam. Since this 95% confidence interval includes 0, we cannot conclude that there is a non-zero relationship of any kind betweendispanddrat. The true relationship could be negative, zero, or positive. We didn’t find any definitive evidence. Note that even though we did not find a definitive answer about the relationship betweendispanddrat, we still did successfully control for the variabledrat. The findings from this regression model about the relationships between a)dispandwtand b)dispandamare still legitimate.am: In the population from which our sample was drawn, we are 95% confident that manual transmission cars have displacements that are between 30.44 cubic inches lower108 and 98.90 cubic inches higher than automatic transmission cars, controlling for weight and rear axle ratio. Since this confidence interval crosses 0, we did not find evidence of a non-zero relationship betweendispandam. We did, however, successfully control foramin this regression, such that we might be able to draw conclusive answers about the relationship between the dependent variabledispand other independent variableswtanddrat.Intercept: In the population from which our sample was drawn, we are 95% confident that a car that weighs 0 tons, has a rear axle ratio of 0 units, and has automatic transmission has a displacement that is between -220.09 and 344.37 cubic inches. We are again not at all confident about what this predicted value might truly be in the population, and that is okay.
Like with simple regression, the computer conducted a number of hypothesis tests for us when it ran our regression analysis. For example, one of these hypothesis tests relates to the slope estimate for displacement and weight.
Here is the framework for this hypothesis test:
\(H_0\): In the population of interest, \(b_{wt} = 0\). In other words: in the population of interest, there is no relationship between displacement and weight of cars.
\(H_A\): In the population of interest, \(b_{wt} \ne 0\). In other words: in the population of interest, there is a non-zero relationship between displacement and weight of cars.
The result of this hypothesis test is within the regression output. The p-value for weight is extremely small. This means that we have very high confidence in the alternate hypothesis \(H_A\), meaning that there likely is an association between displacement and weight in our population of interest. More specifically, we are 95% confident that the slope of the association between displacement and weight in the population is between 71.84 and 137.78 cubic inches. Taking the p-value and confidence intervals into consideration, we reject the null hypothesis (if our diagnostic tests of OLS assumptions go well, later).
Here are some important reminders about our multiple OLS linear regression results:
- All of the estimated coefficients are measured in units of the dependent variable.
- The slope of 104.81 cubic inches is the true average relationship between displacement and weight in our sample alone.
- The 95% confidence intervals and p-values pertain to the population.
- The slope of 104.81 cubic inches is the midpoint of the 95% confidence interval.
- None of these results for the population of interest can be trusted until certain diagnostic tests of assumptions have been conducted.
- It is important to note that any relationships we found between variables are just associations rather than causal relationships.
8.1.5 Graphing multiple OLS results
With simple linear regression, it was easy to graph our regression results because we just had two variables—our dependent variable and one independent variable—to graph and a scatterplot has two dimensions. But now with multiple regression, we have four variables—our dependent variables and three independent variables. So how can we visualize our results?
There are many possibilities. We will learn just one in this section. Since our primary relationship of interest is between disp and wt, let’s make our scatterplot have disp on the vertical axis (because that’s always where we put the dependent variable) and wt on the horizontal axis. Then, since am is a dummy variable, we can draw two separate lines showing predicted values for observations that fall into each group of am.
This code plots disp against wt along with the two prediction lines:
if (!require(interactions)) install.packages('interactions')
library(interactions)
interact_plot(reg1, pred = wt, modx = am, plot.points = TRUE)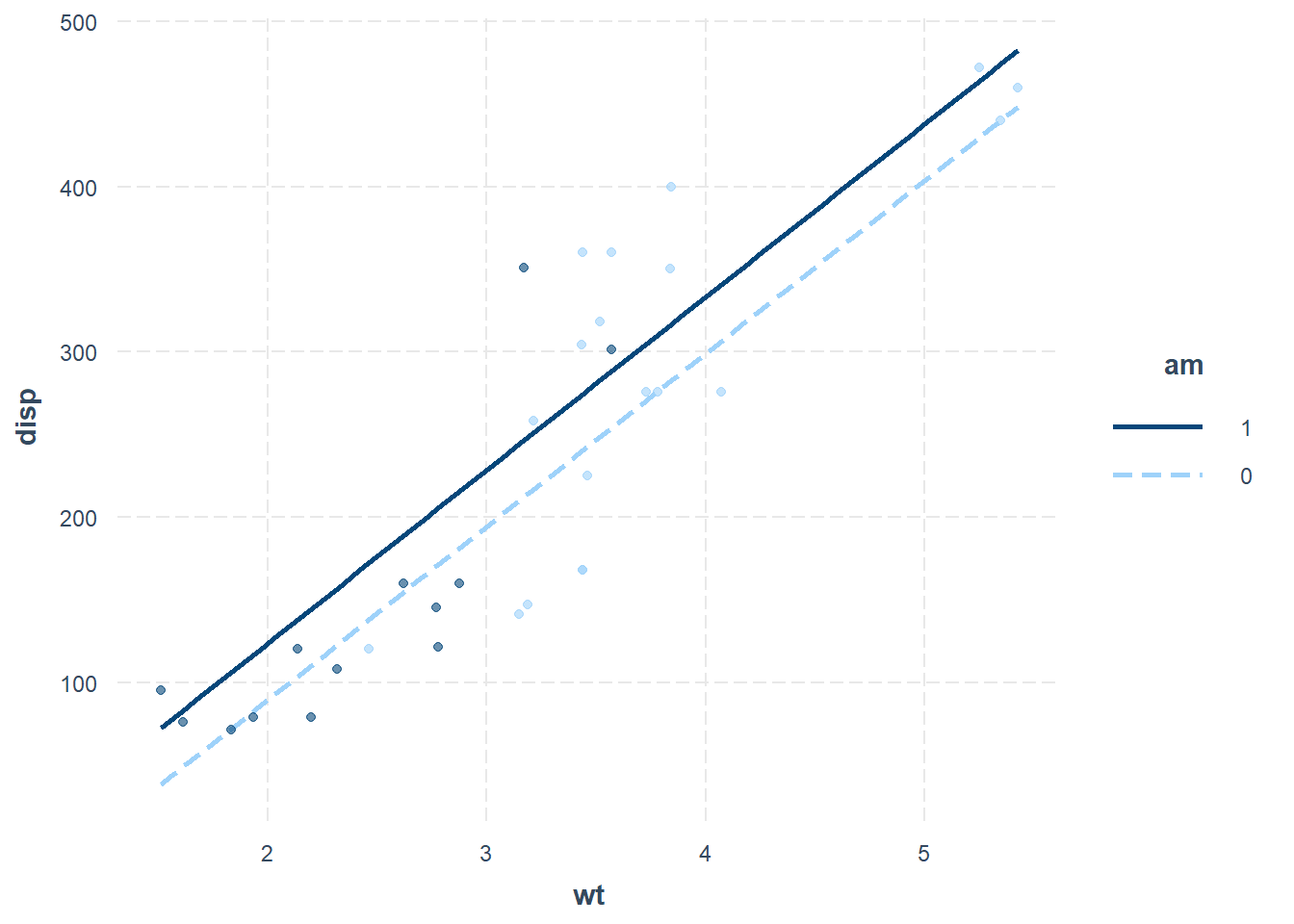
In the code we used to generate this scatterplot, here is what we asked the computer to do:
- First we installed (if necessary) and loaded the
interactionspackage. interact_plot(reg1, pred = wt, modx = am, plot.points = TRUE)– Create a scatterplot using theinteract_plot(...)function. Theinteract_plot(...)function has four arguments:reg1– We will be making a scatterplot based on the regression modelreg1.pred = wt– We want the predictor (meaning independent variable) on the horizontal axis to bewt. Note that the vertical axis will be our dependent variabledispby default; we don’t need to tell the computer that.modx = am– Here we specify thatamis the moderator variable out of all the independent variables. This tells the computer to draw separate regression lines for predictions in each category ofam.plot.points = TRUE– Plot individual data points on the scatterplot, in addition to showing regression lines.
Now we can turn to interpreting the scatterplot:
Dark blue points show the true (actual)
dispandwtof cars with manual transmissions in our data.The dark blue line shows the predicted relationship between
dispandwtcalculated by our regression model for cars with manual transmissions.Light blue points show the true (actual)
dispandwtof cars with automatic transmissions in our data.The light blue line shows the predicted relationship between
dispandwtcalculated by our regression model for cars with automatic transmissions.Remember that our regression model predicts that in our sample, cars with manual transmissions will have a
dispthat is 34.23 cubic inches higher than cars with automatic transmissions, controlling for the other two independent variables. This predicted difference of 34.23 cubic inches between these two types of cars is shown visually in the scatterplot. Choose any weight and check this for yourself. Let’s consider a car that weighs 3 tons. If this 3-ton car has automatic transmission, its predicteddispis around 190 cubic inches on the scatterplot. If this 3-ton car has manual transmission, its predicteddispis around 225 cubic inches on the scatterplot. This is a difference of about 35 cubic inches, which is almost the same value as our coefficient ofamwhich is 34.23 cubic inches!We see that when we controlled for
wt, meaning we looked at just a single value ofwt, the difference betweenam = 1observations andam = 0observations is around 34.23 cubic inches. If we looked at a different value ofwt, such as 4.5 tons, the difference between automatic and manual cars would still be 34.23 cubic inches. This is what it means to control for one independent variable—wt, in this case—while looking at the relationship between the dependent variable (disp) and another independent variableam.The scatterplot also shows that our regression model successfully controlled for
amwhen considering the relationship betweendispandwt. We know this because the two lines in the plot are parallel. The slope defining the relationship betweendispandwtis the same regardless of which line you choose to look at. This is what it means to control foram. We uncovered the relationship between the dependent variabledispand another independent variablewtregardless of the value ofam.Another useful way to think about a dummy variable is that it shifts the intercept of a regression model for a particular group. Let’s see how this is the case:109
- Start with the regression equation from our regression model
reg1: \(\hat{disp} = 104.81 wt - 50.75 drat + 34.23 am + 62.14\). - Plug in
am = 0for observations (cars) with automatic transmission: \(\hat{disp} = 104.81 wt - 50.75 drat + 34.23*0 + 62.14\). We then simplify this into a final regression equation only for cars with automatic transmission: \(\hat{disp}_\text{automatic transmission} = 104.81 wt - 50.75 drat + 62.14\). - Plug in
am = 1for observations (cars) with manual transmission: \(\hat{disp} = 104.81 wt - 50.75 drat + 34.23*1 + 62.14\). We then simplify this into a final regression equation only for cars with manual transmission: \(\hat{disp}_\text{manual transmission} = 104.81 wt - 50.75 drat + 96.37\). - Notice above that we created two equations—one for \(\hat{disp}_\text{automatic transmission}\) and another for \(\hat{disp}_\text{manual transmission}\). Once we simplified these equations, they are exactly the same except they have different intercepts.
- Start with the regression equation from our regression model
The scatterplot also give us a visual sense for how well our regression model fits our data. The closer the plotted points are to the line(s), the better fitting our regression line is.
8.1.6 Generic code for multiple OLS linear regression in R
This section contains a generic version of the code and interpretation that you can use to run a multiple OLS linear regression in R. You can copy the code below and follow the guidelines to replace elements of this code such that it is useful for analyzing your own data.
To run an OLS linear regression in R, you will use the lm(...) command:
reg1 <- lm(DepVar ~ IndVar1 + IndVar2 + IndVar3 + IndVar4 + ..., data = mydata)
Here is what we are telling the computer to do with the code above:
reg1– Create a new regression object calledreg1. You can call this whatever you want. It doesn’t need to be calledreg1.<-– Assignreg1to be the result of the output of the functionlm(...)lm(...)– Run a linear model using OLS linear regression.DepVar– This is the dependent variable in the regression model. You will write the name of your own dependent variable instead ofDepVar.~– This is part of a formula. This is like the equals sign within an equation. The~goes after the dependent variable and before the independent variables.IndVar1– This is the first independent variable in the regression model. You will write the name of one of your own independent variables here instead ofIndVar.+– This is a plus sign. All of your independent variables should be listed, separated by plus signs.IndVar2–IndVar4– These are additional independent variables. You will write the names of the variables from your own dataset in place of these. You can have as many or as few independent variables as you would like. The order in which you input the independent variables doesn’t matter, as long as they are all after the~, separated by plus signs, and before the comma.data = mydata– Use the datasetmydatafor this regression.mydatais where the dependent and independent variables are located. You will replacemydatawith the name of your own dataset.
Then we would run the following command to see the results of our saved regression, reg1:
summary(reg1)
The summary(...) function shows you the results of the regression that you created and saved as reg1.
If you look in your Environment tab in RStudio, you will see that reg1 (or whatever you called your regression) is saved and listed there.
A summary table with confidence intervals can be created with the following code:
if (!require(jtools)) install.packages('jtools')
library(jtools)
summ(reg1, confint = TRUE)8.2 Residuals in multiple OLS
We will continue using the reg1 regression model that we created earlier in this chapter, which examined the relationship between displacement and weight of cars. Earlier in the chapter, our focus was on interpreting the slopes and intercept in the regression model. Now we will turn our attention to an analysis of the individual observations in our dataset. Below, we will examine errors between our actual and predicted values of displacement in our regression model.
Remember: Displacement (disp) is our dependent variable; and weight (wt), rear axle ratio (drat), and transmission type (am) are our independent variables in this regression model. The dependent variable is our outcome of interest that we care about. Just like in simple OLS, our main concern when we analyze residuals and error is our predictions of the dependent variable made by the regression model. Most of the procedure below is based on the dependent variable alone, which is displacement (disp).
Now we are going to calculate the predicted values (also called fitted values) for our regression model reg1. This follows the same process and code that we used for simple OLS previously.
Here we calculate predicted values in R:
d$disp.predicted <- predict(reg1)Inspect new variable in d called disp.predicted:
View(d)We run the following code to calculate the regression residuals:
d$disp.resid <- resid(reg1)Now a new variable called disp.resid has been added to our dataset d. You can inspect this new variable by opening d in R on your own computer, using the View(...) command:
View(d)In the table below, you can see our independent variable (wt), dependent variable (disp), predicted values of the dependent variable (disp.predicted), and the residuals (disp.resid):
d[c("wt","disp","disp.predicted","disp.resid")] wt disp disp.predicted disp.residMazda RX4 2.620 160.0 173.04790 -13.047902 Mazda RX4 Wag 2.875 160.0 199.77406 -39.774061 Datsun 710 2.320 108.0 144.14275 -36.142749 Hornet 4 Drive 3.215 258.0 242.79615 15.203849 Hornet Sportabout 3.440 360.0 262.82571 97.174286 Valiant 3.460 225.0 284.71351 -59.713506 Duster 360 3.570 360.0 273.40595 86.594051 Merc 240D 3.190 146.7 209.21981 -62.519811 Merc 230 3.150 140.8 193.35549 -52.555489 Merc 280 3.440 167.6 223.74994 -56.149945 Merc 280C 3.440 167.6 223.74994 -56.149945 Merc 450SE 4.070 275.8 332.91487 -57.114869 Merc 450SL 3.730 275.8 297.27999 -21.479990 Merc 450SLC 3.780 275.8 302.52041 -26.720413 Cadillac Fleetwood 5.250 472.0 463.69355 8.306454 Lincoln Continental 5.424 460.0 478.37788 -18.377877 Chrysler Imperial 5.345 440.0 458.42603 -18.426025 Fiat 128 2.200 78.7 119.89375 -41.193750 Honda Civic 1.615 75.7 15.44521 60.254793 Toyota Corolla 1.835 71.1 74.53397 -3.433974 Toyota Corona 2.465 120.1 132.72619 -12.626194 Dodge Challenger 3.520 318.0 291.00201 26.997986 AMC Javelin 3.435 304.0 262.30167 41.698329 Camaro Z28 3.840 350.0 275.31540 74.684595 Pontiac Firebird 3.845 400.0 308.82549 91.174514 Fiat X1-9 1.935 79.0 92.11951 -13.119506 Porsche 914-2 2.140 120.3 95.84353 24.456471 Lotus Europa 1.513 95.1 63.62214 31.477865 Ford Pantera L 3.170 351.0 214.45328 136.546721 Ferrari Dino 2.770 145.0 202.97854 -57.978543 Maserati Bora 3.570 301.0 290.88514 10.114863 Volvo 142E 2.780 121.0 179.16023 -58.160229
Let’s review everything we just did (this process is exactly the same now with multiple OLS as it was for simple OLS):
Calculate the predicted values of
dispfor each observation—meaning each car, in this case—in our dataset, by plugging each car’swt,drat, andamvalue into the regression equation \(\hat{disp} = 104.81 wt - 50.75 drat + 34.23 am + 62.14\). These predicted values appear in the table above in thedisp.predictedcolumn.Calculate the residual error for each observation—still meaning each car—in our dataset by calculating the difference between each car’s actual displacement (
dispcolumn) and predicted displacement (disp.predictedcolumn). These residual errors appear in thedisp.residcolumn.We are now ready to use the residuals to quantify and describe error in our regression model. Remember that we want the residuals (residual errors) to be as small as possible.
8.3 R-squared metric of goodness of fit in multiple OLS
All regression models have a variety of goodness-of-fit measures that help us understand how well a regression model fits our data and/or how appropriate it is for our data. In this section, we will learn about the measure called \(R^2\). This measure is referred to as “R-squared,” “R-square,” “Multiple R-squared,” or something similar. They all mean the same thing.
You already know how to calculate \(R^2\) in simple OLS. The process for calculating \(R^2\) in multiple OLS is the same. It is all based on the dependent variable, predicted values of the dependent variable, and the residuals. We will continue to use our reg1 example about cars in this section.
If you look at the summary table that we made for reg1, you will see that \(R^2 = 0.81\). This number can also be interpreted as 81%%. This means that 81%% of the variation in the Y variable disp is accounted for by variation in the X variables wt, drat, and am. This is a very high \(R^2\) in the context of social science, behavioral, health, and education data. Every time you run an OLS regression (and many other types of regressions as well), you should examine the \(R^2\) statistic to see how well your regression model fits your data.
The \(R^2\) statistic tells us how well our independent variable helps us predict the value of our dependent variable. Our ultimate goal is to make good predictions of the dependent variable by fitting the best regression line possible to the data. Once you know the \(R^2\) of a regression model, you can also use that to compare it to other regression models to see which model has the better fitting line. We will practice doing this later in this textbook.
As you saw when studying simple OLS, \(R^2\) has an interesting connection to correlation. \(R^2\) is the square of the correlation of the actual and predicted values in any OLS linear regression. We will demonstrate this by calculating in R, below.
8.3.1 Correlation and R-squared
This procedure is the same as the one we used for simple OLS and is presented below in abbreviated form.
We have already calculated the predicted values from our regression model and added them to our dataset d in a variable called disp.predicted. And of course our actual values are simply the ones held in the disp variable in d. So we are all set to calculate the correlation of these variables.
The code below calculates the correlation between our actual and predicted values in reg1:
cor(d$disp,d$disp.predicted)## [1] 0.8993098Now we save this correlation:
r.reg <- cor(d$disp,d$disp.predicted)And like before, we square this correlation value:
r.reg^2## [1] 0.8087581Once again, we see that the square of the correlation of the actual and predicted values is equal to \(R^2\) in our regression model. This is always the case and it is a great way to remember what \(R^2\) helps us measure.
Let’s break it down step by step:
- The actual values are the true/real outcomes of interest (values of the dependent variable) in our observations (rows of data).
- The predicted values are the best guess that we can make about the values of the dependent variable using only the independent variables. That last part is the key. We used only the independent variables to generate the predicted values, by plugging them into the regression equation.
- We want to know: How well can the independent variables make predictions of the dependent variable? It turns out that we have everything we need now to answer this question.
- We look at the correlation of the predicted values (which represents the best guess made only by the independent variables) with the actual values (which are the true numbers we are trying to predict). This tells us how well the independent variables are able to predict or explain the dependent variable.
- We square the correlation that we just calculated so that it is the same as the other way to calculate goodness-of-fit, which is \(R^2 = 1 - \frac{SSR}{SST}\), as you know from before.
8.3.2 Calculating R-squared
Now we will calculate \(R^2\) the other way. This is again the same as the process for calculating \(R^2\) in simple OLS, so we will go quickly.
First we will calculate SSR.
Here is the code to square the residuals:
d$disp.resid2 <- d$disp.resid^2Then we calculate the sum of these squared residuals:
sum(d$disp.resid2)## [1] 91066.47The sum above is the SSR. \(SSR = 91066.47\).
Next, we will calculate SST.
Calculate the mean of the dependent variable:
mean(d$disp)## [1] 230.7219Then subtract the mean of disp from each observation’s disp:
d$disp.meandiff <- d$disp-230.7219Square the differences from the mean:
d$disp.meandiff2 <- d$disp.meandiff^2Calculate sum of squared differences from the mean:
sum(d$disp.meandiff2)## [1] 476184.8The result above tells us that \(SST = 476184.8\)
In this table we can preview all of the new variables we just created:
d[c("wt","disp","disp.resid","disp.resid2","disp.meandiff","disp.meandiff2")]## wt disp disp.resid disp.resid2 disp.meandiff
## Mazda RX4 2.620 160.0 -13.047902 170.24774 -70.7219
## Mazda RX4 Wag 2.875 160.0 -39.774061 1581.97595 -70.7219
## Datsun 710 2.320 108.0 -36.142749 1306.29831 -122.7219
## Hornet 4 Drive 3.215 258.0 15.203849 231.15703 27.2781
## Hornet Sportabout 3.440 360.0 97.174286 9442.84192 129.2781
## Valiant 3.460 225.0 -59.713506 3565.70283 -5.7219
## Duster 360 3.570 360.0 86.594051 7498.52960 129.2781
## Merc 240D 3.190 146.7 -62.519811 3908.72672 -84.0219
## Merc 230 3.150 140.8 -52.555489 2762.07942 -89.9219
## Merc 280 3.440 167.6 -56.149945 3152.81629 -63.1219
## Merc 280C 3.440 167.6 -56.149945 3152.81629 -63.1219
## Merc 450SE 4.070 275.8 -57.114869 3262.10823 45.0781
## Merc 450SL 3.730 275.8 -21.479990 461.38995 45.0781
## Merc 450SLC 3.780 275.8 -26.720413 713.98047 45.0781
## Cadillac Fleetwood 5.250 472.0 8.306454 68.99717 241.2781
## Lincoln Continental 5.424 460.0 -18.377877 337.74637 229.2781
## Chrysler Imperial 5.345 440.0 -18.426025 339.51841 209.2781
## Fiat 128 2.200 78.7 -41.193750 1696.92503 -152.0219
## Honda Civic 1.615 75.7 60.254793 3630.64009 -155.0219
## Toyota Corolla 1.835 71.1 -3.433974 11.79218 -159.6219
## Toyota Corona 2.465 120.1 -12.626194 159.42077 -110.6219
## Dodge Challenger 3.520 318.0 26.997986 728.89123 87.2781
## AMC Javelin 3.435 304.0 41.698329 1738.75061 73.2781
## Camaro Z28 3.840 350.0 74.684595 5577.78875 119.2781
## Pontiac Firebird 3.845 400.0 91.174514 8312.79202 169.2781
## Fiat X1-9 1.935 79.0 -13.119506 172.12143 -151.7219
## Porsche 914-2 2.140 120.3 24.456471 598.11899 -110.4219
## Lotus Europa 1.513 95.1 31.477865 990.85596 -135.6219
## Ford Pantera L 3.170 351.0 136.546721 18645.00708 120.2781
## Ferrari Dino 2.770 145.0 -57.978543 3361.51140 -85.7219
## Maserati Bora 3.570 301.0 10.114863 102.31045 70.2781
## Volvo 142E 2.780 121.0 -58.160229 3382.61222 -109.7219
## disp.meandiff2
## Mazda RX4 5001.58714
## Mazda RX4 Wag 5001.58714
## Datsun 710 15060.66474
## Hornet 4 Drive 744.09474
## Hornet Sportabout 16712.82714
## Valiant 32.74014
## Duster 360 16712.82714
## Merc 240D 7059.67968
## Merc 230 8085.94810
## Merc 280 3984.37426
## Merc 280C 3984.37426
## Merc 450SE 2032.03510
## Merc 450SL 2032.03510
## Merc 450SLC 2032.03510
## Cadillac Fleetwood 58215.12154
## Lincoln Continental 52568.44714
## Chrysler Imperial 43797.32314
## Fiat 128 23110.65808
## Honda Civic 24031.78948
## Toyota Corolla 25479.15096
## Toyota Corona 12237.20476
## Dodge Challenger 7617.46674
## AMC Javelin 5369.67994
## Camaro Z28 14227.26514
## Pontiac Firebird 28655.07514
## Fiat X1-9 23019.53494
## Porsche 914-2 12192.99600
## Lotus Europa 18393.29976
## Ford Pantera L 14466.82134
## Ferrari Dino 7348.24414
## Maserati Bora 4939.01134
## Volvo 142E 12038.89534Finally, we calculate \(R^2\):
\(R^2 = 1-\frac{SSR}{SST} = 1-\frac{91066.47}{476184.8} = 0.81\)
Remember once again: We want SSR to be as low as possible, which will make \(R^2\) as high as possible. We want \(R^2\) to be high. SSR is calculated from the residuals, and residuals are errors in the regression model’s prediction. SSR is all of the error totaled up together. So if SSR is low then error is low. \(R^2\) is one of the most commonly used metrics to determine how well a regression model fit your data.
8.4 Assignment
In this chapter’s assignment, you will use a single dataset to run a multiple OLS linear regression model. The analysis you conduct should be extremely thorough and go step-by-step through the entire research process as you would do when using OLS to answer a research question. You can definitely use your own data instead of the provided data for this assignment, if you prefer.
To get started, first load the hsb2 data using the following code:
if (!require(openintro)) install.packages('openintro')
library(openintro)
data(hsb2)
h <- na.omit(hsb2)You should also run the command ?hsb2 in the console to read more about the dataset, which is called the High School and Beyond survey.110
You will use h as your dataset for this portion of the assignment, NOT hsb2. h is a copy of the dataset hsb2 in which any missing data was removed using the na.omit(...) function.
You will conduct a quantitative analysis with the following characteristics:
- Question: What is the relationship between the outcome science and: read, write, and socst?
- Data:
hsb2(copied ash) - Dependent variable: science
- Independent variables: read, write, and socst
- Analysis method: OLS
If you choose to use your own separate data, make sure to include and explain all of the characteristics above as part of the assignment you submit.
8.4.1 Prepare and explore the data
We’ll start with a few tasks to modify the data a little bit so that it is ready for you to analyze. You will also explore the data using techniques you have learned before, before you move on to running a regression model.
Task 1: Run the command summary(h) to start to learn about this dataset.
Task 2: Make a correlation matrix with all numeric variables involved in our study. Interpret any trends or noteworthy observations you see.
8.4.2 Multiple OLS linear regression
In this section, you will run an OLS regression to answer the question of interest. You will then interpret the results in both the sample and population.
Task 3: Run the appropriate OLS regression model and show the results.
Task 4: Write the regression equation.
Task 5: Calculate the predicted value of the dependent variable for somebody with the following characteristics: 44 reading score111, 50 writing score, 38 social studies score,
Task 6: Interpret regression results for each independent variable for your sample.
Task 7: Interpret regression results for each independent variable for the population.
Task 8: Interpret the \(R^2\) value for this regression model.
8.4.3 Follow up and submission
You have now reached the end of this week’s assignment. The tasks below will guide you through submission of the assignment and allow us to gather questions and/or feedback from you.
Task 9: Please write any questions you have for the course instructors (optional).
Task 10: Please write any feedback you have about the instructional materials (optional).
Task 11: Knit (export) your RMarkdown file into a format of your choosing.
Task 12: Please submit your assignment to the D2L assignment drop-box corresponding to this chapter and week of the course. And remember that if you have trouble getting your RMarkdown file to knit, you can submit your RMarkdown file itself. You can also submit an additional file(s) if needed.
We could call this anything we like, not necessarily
d.partial.↩︎This sentence was added on February 3 2021.↩︎
This note was added after this chapter was initially published for the spring 2021 course. The 34.23 coefficient estimate for
ammeans that in our sample, on average, cars coded asam=1(manual) are +34.23 cubic inches different on average in our sample than cars coded asam=0(automatic). Remember that this is a story all about manual cars, since they’re coded as 1. So we’ll consider our interpretation from the perspective of the manual cars only. Manual cars are +34.23 compared to automatics. Now, how do manuals compare to automatics in the population? We are 95% certain that this difference between manuals and automatics, from the perspective of the manuals, is between -30.44 and +98.90. Let’s consider each of these scenarios. Scenario 1 –-30.44: manuals are 30.44 cubic inches lower than automatics in their displacement, since this is a negative estimate and we’re doing all of this from the perspective of the manuals. Scenario 2 –+98.90: manuals are 98.90 cubic inches higher than automatics in their displacement, since this is a positive estimate and we’re doing all of this from the perspective of the manuals.↩︎This item was added to this list a little while after this chapter was initially made available online for Spring 2021.↩︎
The
hsb2data is part of theopenintropackage, which is why we loaded that package before using thedata()command to load the data into R.↩︎This was accidentally labeled as writing score when this chapter was first published in March 2021. This mistake was corrected on March 10 2021.↩︎