Chapter 32 Causal Inference
We want to (know what we can) learn about causation from observations: We know “correlation does not necessarily imply causation”, and that experiments are our best way to learn about causes. But we also understand that there is some use in observation, and we want to know how we can evaluate causal claims in observational studies.
Required reading / Viewing:
Calling bullshit Chapter 4. Causality. download here.32.1 What is a cause?
Like so much of statistics, understanding causation requires an healthy dose of our imagination.
Specifically imagine multiple worlds. For example, we can imagine a world in which there was some treatment (e.g. we drank coffee, we got a vaccine, we raised taxes etc) and one in which that treatment was absent (e.g. we didn’t have coffee, we didn’t raise taxes etc), and we then follow some response variable of interest. We say that the treatment is a cause of the outcome if changing it will change the outcome, on average. Note for quantitative treatments, we can imagine a bunch of worlds where the treatments was modified by some quantitative value.
In causal inference, considering the outcome if we had changed a treatment is called counterfactual thinking, and it is critical to our ability to think about causes.
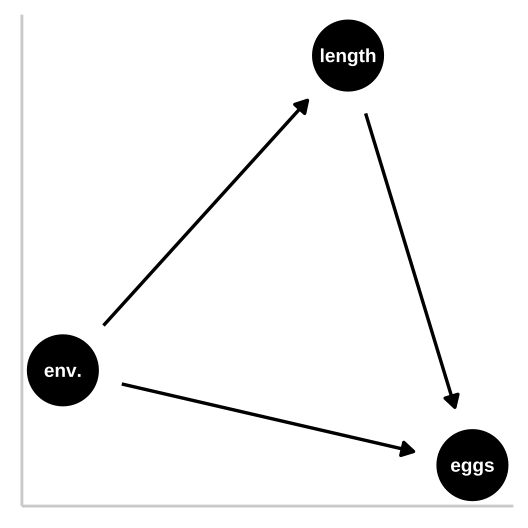
32.2 DAGs, confounds, and experiments
Say we wanted to know if smoking causes cancer.
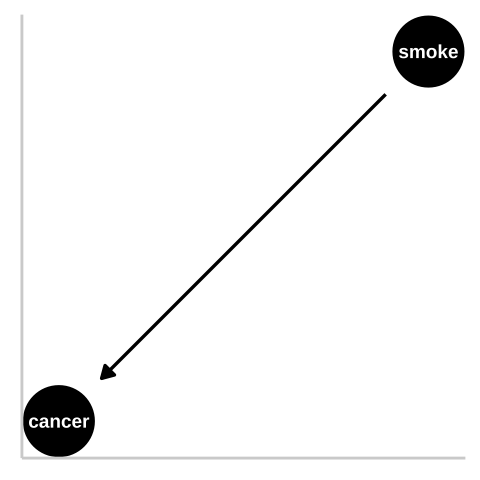
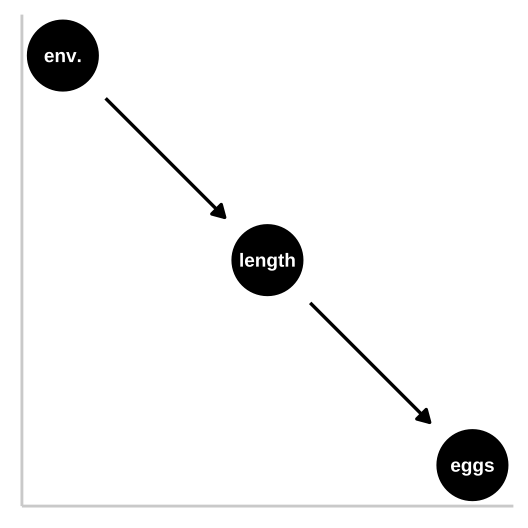
Figure 32.1: We could represent this causal claim with the simplest causal graph we can imagine. This is our first formal introduction to a Directed Acyclic Graph (herefater DAG). This is Directed because WE are pointing a causal arrow from smoking to cancer. It is acyclic because causality in these models only flows in one direction, and its a graph because we are looking at it. These DAGs are the backbone of causal thinking because they allow us to lay our causal models out there for the world to see. Here we will largely use DAGs to consider potential causal paths, but these can be used for mathematical and statistical analyses.
32.2.1 Confounds
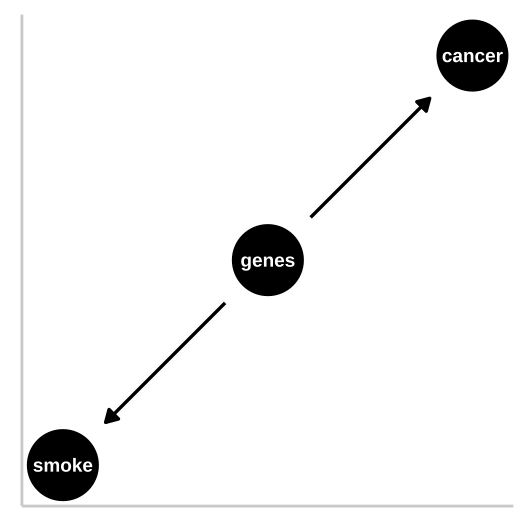
Figure 32.2: R.A. Fisher – a pipe enthusiast, notorious asshole, eugenicist, and the father of modern statistics and population genetics was unhappy with this DAG. He argued that a confound could underlie the strong statistical association between smoking and lung cancer. Specifically, Fisher proposed that the propensity to smoke and to develop lung cancer could be causally unrelated, if both were driven by similar genetic factors. Fisher’s causal model is presented in th DAG to the right – here genes point to cancer and to smoking, but no arrow connects smoking to lung cancer.
In the specifics of this case, Fisher turned out to be quite wrong – genes do influence the probability of smoking and genes do influence the probability of lung cancer, but smoking has a much stronger influence on the probability of getting lung cancer than does genetics.
32.2.2 Randomized Controlled Experiments
This is why, despite their limitations (Ch. 30), randomized control experiments are our best to learn about causation – we randomly place participant in these alternative realities that we imagine and look at the outcome of alternative treatments. That is, we bring our imaginary worlds to life.
So to distinguish between the claim that smoking causes cancer and Fisher’s claim that genetics is a confound and that smoking does not cause cancer, he could randomly assign some people to smoke and some to not. Of course, this is not feasible for both ethical and logistical reasons, so we need some way to work through this. This is our goal today!
32.2.3 DAGs
I’ve introduced two DAGs so far.
Figure 32.1 is a causal model of smoking causing lung cancer. Note this does it mean that nothing else causes lung cancer, or that everyone who smokes will get lung cancer, or that no one who doesn’t smoke will get lung cancer. Rather, it means that if we copied each person, ad had one version of them smoke and the other not, there would be more cases of lung cancer in the smoking clones than the nonsmoking clones.
Figure 32.2 presents Fisher’s argument that smoking does not cause cancer and that rather, both smoking and cancer are influenced by a common cause – genetics.
These are not the only plausible causal models for an association between smoking and cancer. I present three other possibilities in Figure 32.3.
- A pipe is presented in Figure 32.3a. That is – genes cause smoking and smoking causes cancer. Empirically and statistically, this is a hard model to evaluate because changing genes would “cause” cancer in an experiment, and “controlling for genetics” by including it in a linear model would hide the effect of smoking. The right thing to do is to ignore the genetic component – but that feels wrong and how do we justify it? One way to get at this s to “match” on genetics and then compare outcomes for cancer. A 2017 study compared the incidence of lung cancer between monozygotic twins for which one smoked and one did not, and found a higher incidence of cancer in the smoking twin (Hjelmborg et al. 2017).
- A collider is presented in Figure 32.3b, as both genes and smoking cause cancer (they “collide”). Here there are two “paths” between smoking and cancer. 1. The front door causal path – smoking causes cancer, and 2. The back door non causal path in connecting smoking to cancer via the confounding variable, genetics. Here the challenge is to appropriately partition and attribute causes.
- A more complex and realistic model including the effects of the environment on cancer and smoking is presented in 1.5c. Noe that in this model genes do not cause the environment and the environment does not cause genes.
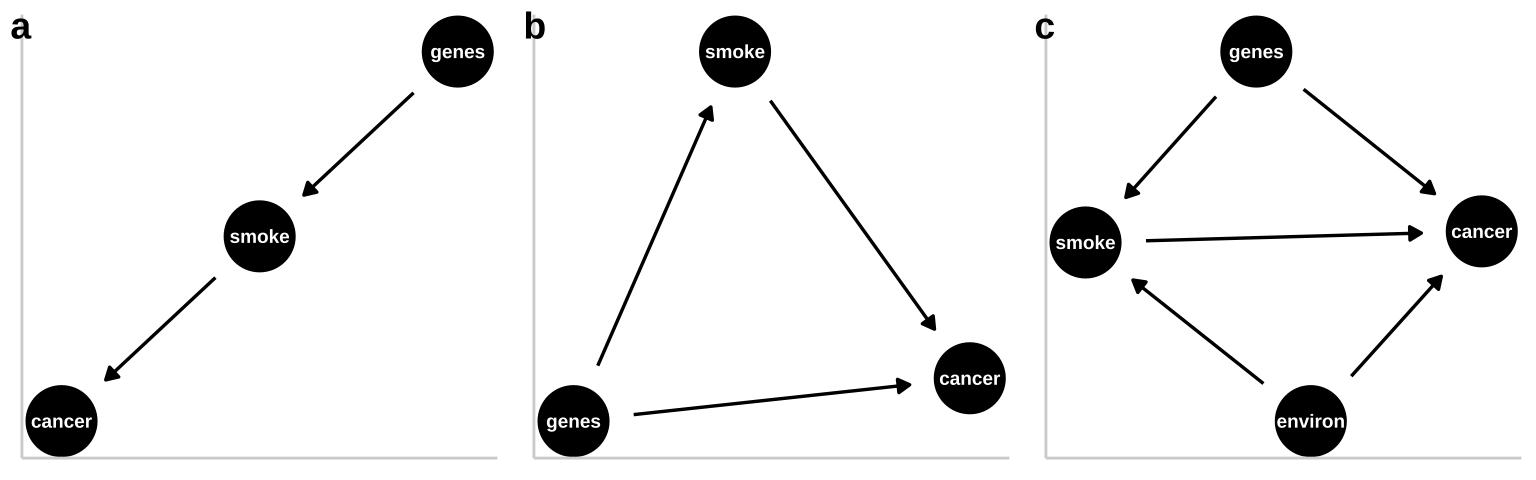
Figure 32.3: Three plausible DAGs concerning the relationship between smoking and cancer. a A pipe – Genes cause smoking, and smoking causes cancer. b A collider – genes cause cancer and smoking, and smoking causes cancer. c Complex reality – Environmental factors cause smoking and cancer, and genetics cause smoking and cancer, while smoking too causes cancer.
32.3 When correlation is (not) good enough
So we are going to think through causation – but we might wonder when we need to know causes.
- We don’t need to understand causation to make predictions under the status quo. If I just want to make good predictions, I can build a good multiple regression model, and make predictions from it, and we will be just fine. If I want to buy good corn – I can go to the farm stand that reliably sells yummy corn, I don’t care if the corn is yummy because of the soil, the light environment, or the farmers playing Taylor Swift every morning to get the corn excited. Similarly, if I was selling insurance, I would just need to reliably predict who would get lung cancer, I wouldn’t need to know why.
- We need to understand causation when we want to intervene (or make causal claims). If I want to grow my own yummy corn, I would want to know what about the farmers practice made the corn yummy. I wouldn’t need to worry about fertilizing my soil if it turned out that pumping some Taylor swift tunes was all I needed to do to make yummy corn. Similarly, if I was giving public health advice I would need to know that smoking caused cancer to credibly suggest that people quit smoking to reduce their chance of developing lung cancer. selling insurance, I would just need to reliably predict who would get lung cancer, I wouldn’t need to know why.
32.4 Multiple regression, and causal inference
So far we have considered how we draw and think about causal models. This is incredibly useful – drawing a causal model makes our assumptions and reasoning clear.
But what can we do with these plots, and how can they help us do statistics? It turns out they can be pretty useful! To work through this I will simulate fake data under different causal models and run different linear regressions on the simulated data to see what happens.
32.4.1 Imaginary scenario
In evolution, fitness is the metric we care about most. While it is nearly impossble to measure and define, we often can measure things related to it, like the number of children that an organism has. For the purposes of this example let’s say that is good enough.
So, say we are studying a fish and want to see if being big (in length) increases fitness (measured as the number of eggs produced). To make things more interesting, let’s say that fish live environements whose quality we can measure. For the purpoes of this example, let’s say that we can reliably and correctly estimate all these values without bias, and that all have normally distributed residuals etc..
32.4.1.1 Causal model 1: The confound
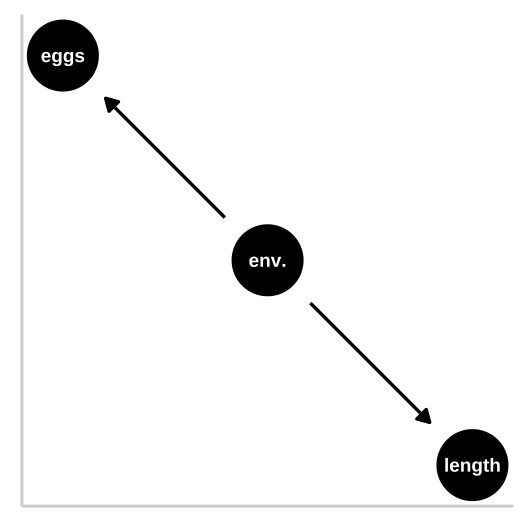
Let’s start with a simple confound – say a good environment makes fish bigger and increases their fitness, but being bigger itself has no impact on fitness. First let’s simulate
n_fish <- 100
confounded_fish <- tibble(env_quality = rnorm(n = n_fish, mean = 50, sd = 5), #simulating the environment
fish_length = rnorm(n = n_fish, mean = env_quality, sd = 2),
fish_eggs = rnorm(n = n_fish, mean = env_quality/2, sd = 6) %>% round()) #Now we know that fish length does not cause fish to lay more eggs – as we did not models this. Nonetheless, a plot and a statistical test show a strong association between length and eggs if we do not include if we do not include environmental quality in our model.
confound_plot <- ggplot(confounded_fish, aes(x = fish_length, y = fish_eggs)) +
geom_point()+
geom_smooth(method = "lm")+
labs("Confound", subtitle = "# eggs increases with length\nwithout a causal relationship.")
confound_plot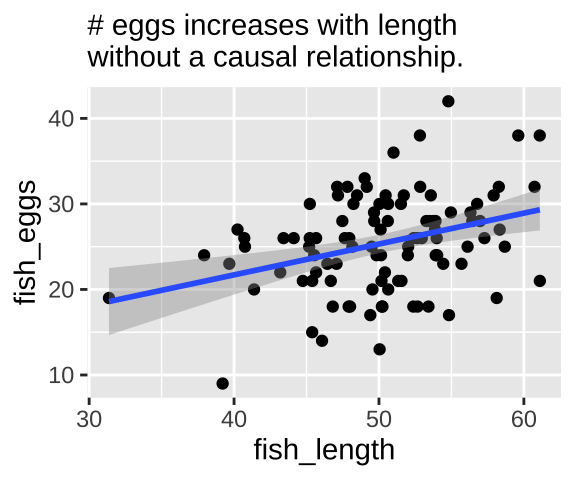
Our statistical analysis will not show cause
We can build a simple linear model predicting the number of fish eggs as a function of fish length. We can see that the prediction is good, and makes sense – egg number reliably increases with fish length. But we know this is not a causal relationship (because we didn’t have this cause in our simulation).
lm(fish_eggs ~ fish_length, confounded_fish) %>% summary()##
## Call:
## lm(formula = fish_eggs ~ fish_length, data = confounded_fish)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12.420 -3.197 0.325 3.197 14.959
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.2711 5.0853 1.430 0.155942
## fish_length 0.3608 0.1006 3.585 0.000527 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.403 on 98 degrees of freedom
## Multiple R-squared: 0.116, Adjusted R-squared: 0.1069
## F-statistic: 12.85 on 1 and 98 DF, p-value: 0.000527lm(fish_eggs ~ fish_length, confounded_fish) %>% anova() ## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## fish_length 1 375.23 375.23 12.854 0.000527 ***
## Residuals 98 2860.77 29.19
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Adding the confound into our model
So, let’s build a model including the confound environmental quality.
fish_lm_w_confound <- lm(fish_eggs~ env_quality + fish_length, confounded_fish) Looking at the estimates from the model we see that the answers don’t make a ton of sense
fish_lm_w_confound %>% coef() %>% round(digits = 2)## (Intercept) env_quality fish_length
## 4.40 0.52 -0.10In this case, an ANOVA with type one sums of squares give reasonable p-values, while an ANOVA with type II sums of squares shows that neither environment nor length is a significant predictor of egg number. This is weird.
fish_lm_w_confound %>% anova() ## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## env_quality 1 455.32 455.32 15.9027 0.0001293 ***
## fish_length 1 3.42 3.42 0.1195 0.7303689
## Residuals 97 2777.26 28.63
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1fish_lm_w_confound %>% Anova(type = "II")## Anova Table (Type II tests)
##
## Response: fish_eggs
## Sum Sq Df F value Pr(>F)
## env_quality 83.51 1 2.9166 0.09087 .
## fish_length 3.42 1 0.1195 0.73037
## Residuals 2777.26 97
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1What to do?
First let’s look at all the relationships in our data
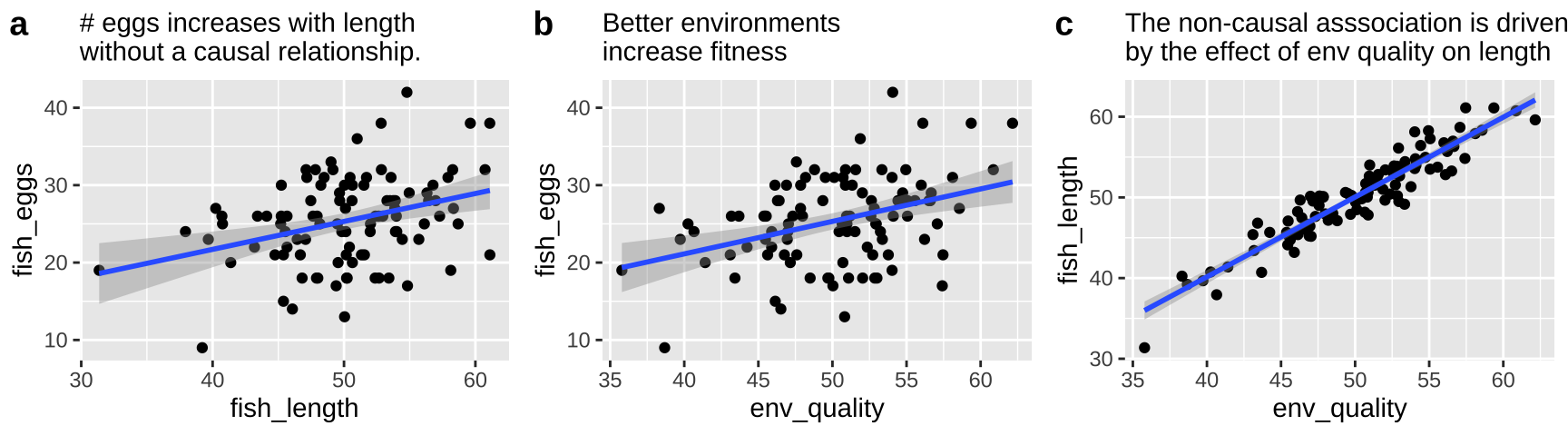
The right thing to do in this case is to just build a model with the environmental quality.
lm(fish_eggs ~ env_quality , confounded_fish) %>% summary()##
## Call:
## lm(formula = fish_eggs ~ env_quality, data = confounded_fish)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12.6635 -3.0403 0.2347 3.5989 14.9756
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.3464 5.2826 0.823 0.41263
## env_quality 0.4194 0.1047 4.006 0.00012 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.327 on 98 degrees of freedom
## Multiple R-squared: 0.1407, Adjusted R-squared: 0.1319
## F-statistic: 16.05 on 1 and 98 DF, p-value: 0.0001204lm(fish_eggs ~ env_quality , confounded_fish) %>% anova()## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## env_quality 1 455.32 455.32 16.047 0.0001204 ***
## Residuals 98 2780.68 28.37
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 132.4.1.2 Causal model 2: The pipe
So now let’s look at a pipe in which the environment causes fish length and fish length causes fitness, but environment itself has has no impact on fitness. First let’s simulate
pipe_fish <- tibble(env_quality = rnorm(n = n_fish, mean = 50, sd = 5), #simulating the environment
fish_length = rnorm(n = n_fish, mean = env_quality, sd = 2),
fish_eggs = rnorm(n = n_fish, mean = fish_length/2, sd = 5) %>% round()) #Now we know that environmental quality does not directly cause fish to lay more eggs – as we did not models this. Nonetheless, a plot and a statistical test show a strong association between quality and eggs if we do not include if we do not include fish length in our model.
pipe_plot <- ggplot(pipe_fish, aes(x = env_quality, y = fish_eggs)) +
geom_point()+
geom_smooth(method = "lm")+
labs( subtitle = "# eggs increases with env quality\nalthough the causal relationship is indirect.")
pipe_plot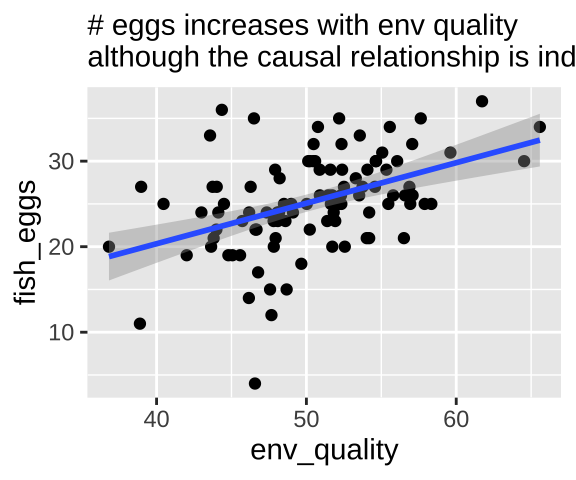
Our statistical analysis will not show cause
We can build a simple linear model predicting the number of fish eggs as a function of environmental quality. We can see that the prediction is good, and makes sense – egg number reliably increases with environmental quality. But we know this is not a causal relationship (because we didn’t have this cause in our simulation).
lm(fish_eggs ~ env_quality, pipe_fish) %>% summary()##
## Call:
## lm(formula = fish_eggs ~ env_quality, data = pipe_fish)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.4554 -2.6874 -0.1292 3.2451 13.5918
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.4024 4.8952 0.286 0.775
## env_quality 0.4736 0.0966 4.902 3.76e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.088 on 98 degrees of freedom
## Multiple R-squared: 0.1969, Adjusted R-squared: 0.1887
## F-statistic: 24.03 on 1 and 98 DF, p-value: 3.756e-06lm(fish_eggs ~ env_quality, pipe_fish) %>% anova() ## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## env_quality 1 622.24 622.24 24.032 3.756e-06 ***
## Residuals 98 2537.47 25.89
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Adding the immediate cause into our model
So, let’s build a model including the immediate cause, fish length.
fish_lm_w_cause <- lm(fish_eggs~ fish_length + env_quality, pipe_fish) Looking at the estimates from the model we see that the answers don’t make a ton of sense
fish_lm_w_cause %>% coef() %>% round(digits = 2)## (Intercept) fish_length env_quality
## 1.90 0.23 0.24The stats here again come out a bit funny. A type
lm(fish_eggs~ fish_length + env_quality, pipe_fish) %>% anova()## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## fish_length 1 625.04 625.04 24.1207 3.665e-06 ***
## env_quality 1 21.13 21.13 0.8155 0.3687
## Residuals 97 2513.54 25.91
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1lm(fish_eggs~ env_quality + fish_length, pipe_fish) %>% anova()## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## env_quality 1 622.24 622.24 24.0130 3.832e-06 ***
## fish_length 1 23.92 23.92 0.9232 0.339
## Residuals 97 2513.54 25.91
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1lm(fish_eggs~ fish_length + env_quality, pipe_fish) %>% Anova(type = "II")## Anova Table (Type II tests)
##
## Response: fish_eggs
## Sum Sq Df F value Pr(>F)
## fish_length 23.92 1 0.9232 0.3390
## env_quality 21.13 1 0.8155 0.3687
## Residuals 2513.54 97What to do?
First let’s look at all the relationships in our data
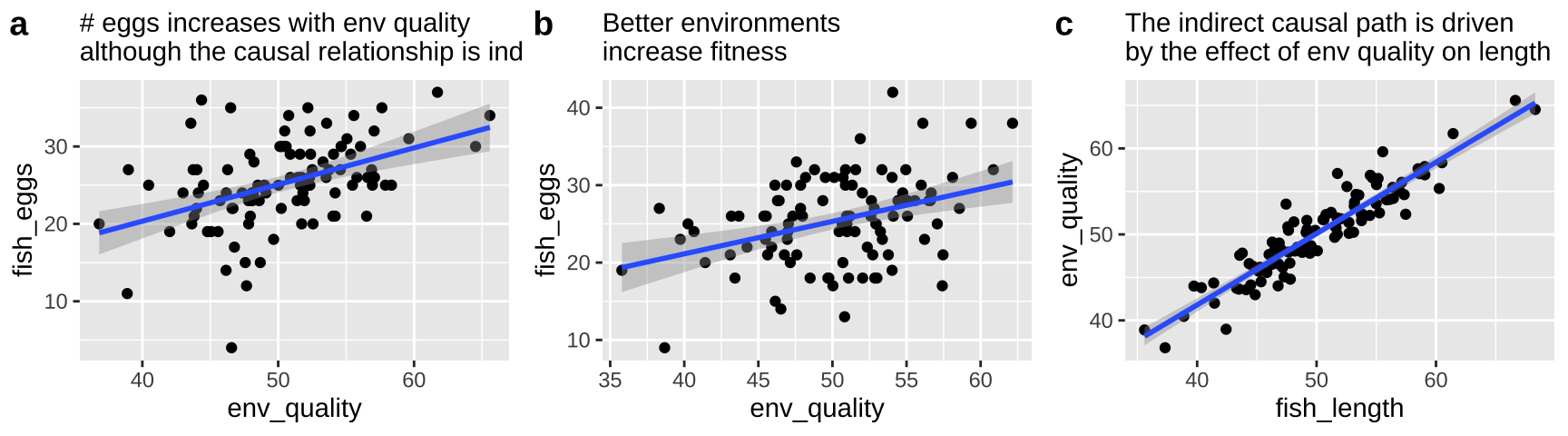
The right thing to do in this case is to just build a model with the fish length.
lm(fish_eggs ~ fish_length, pipe_fish) %>% summary()##
## Call:
## lm(formula = fish_eggs ~ fish_length, data = pipe_fish)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.7687 -2.7645 0.3112 3.2389 14.5293
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.95207 4.36623 0.905 0.368
## fish_length 0.42331 0.08611 4.916 3.55e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.086 on 98 degrees of freedom
## Multiple R-squared: 0.1978, Adjusted R-squared: 0.1896
## F-statistic: 24.17 on 1 and 98 DF, p-value: 3.552e-06lm(fish_eggs ~ fish_length, pipe_fish) %>% anova()## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## fish_length 1 625.04 625.04 24.166 3.552e-06 ***
## Residuals 98 2534.67 25.86
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 132.4.1.3 Causal model 3: The collider
So now let’s look at a collider in which the environment causes fitness and fish length, and fish length causes fitness, but environment itself has has no impact on fitness. First let’s simulate
collide_fish <- tibble(env_quality = rnorm(n = n_fish, mean = 50, sd = 5), #simulating the environment
fish_length = rnorm(n = n_fish, mean = env_quality, sd = 2),
fish_eggs = rnorm(n = n_fish, mean = (env_quality/4+ fish_length*3/4)/2, sd = 7) %>% round()) #Now we know that environmental quality increases fish length and both environmental quality and fish length directly cause fish to lay more eggs.
But our models have a bunch of trouble figuring this out. Again, a type one sums of squares puts most of the “blame” on the first thing in the model.
lm(fish_eggs ~ env_quality + fish_length, collide_fish ) %>% summary()##
## Call:
## lm(formula = fish_eggs ~ env_quality + fish_length, data = collide_fish)
##
## Residuals:
## Min 1Q Median 3Q Max
## -17.2528 -4.8432 0.2107 5.0457 17.1641
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.7752 7.8997 -0.478 0.634
## env_quality 0.2527 0.3687 0.685 0.495
## fish_length 0.3077 0.3391 0.907 0.367
##
## Residual standard error: 7.169 on 97 degrees of freedom
## Multiple R-squared: 0.1183, Adjusted R-squared: 0.1002
## F-statistic: 6.51 on 2 and 97 DF, p-value: 0.002224lm(fish_eggs ~ env_quality + fish_length, collide_fish ) %>% anova() ## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## env_quality 1 626.9 626.89 12.1965 0.0007227 ***
## fish_length 1 42.3 42.30 0.8231 0.3665374
## Residuals 97 4985.7 51.40
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1lm(fish_eggs ~ fish_length + env_quality, collide_fish ) %>% anova() ## Analysis of Variance Table
##
## Response: fish_eggs
## Df Sum Sq Mean Sq F value Pr(>F)
## fish_length 1 645.0 645.04 12.5497 0.0006112 ***
## env_quality 1 24.2 24.15 0.4699 0.4946892
## Residuals 97 4985.7 51.40
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1lm(fish_eggs ~ env_quality + fish_length, collide_fish ) %>% Anova(type = "II") ## Anova Table (Type II tests)
##
## Response: fish_eggs
## Sum Sq Df F value Pr(>F)
## env_quality 24.2 1 0.4699 0.4947
## fish_length 42.3 1 0.8231 0.3665
## Residuals 4985.7 9732.5 Additional reading
.](images/calling_bs4.jpeg)
Figure 32.4: BE SURE TO READ CHAPTER 4 of CALLING BULLSHIT. link.
32.6 Wrap up
The examples above show the complexity in deciphering causes without experiments. But they also show us the light about how we can infer causation, because causal diagrams can point to testable hypotheses.
If we can’t do experiments, causal diagrams offer us a glimpse into how we can infer causation.
Perhaps the best way to do this is by matching – if we can match subjects that are identical for all causal paths except the one we are testing, we can then test for a statistical association, ad make a causal claim we can believe in.
The field of causal inference is developing rapidly. If you want to hear more, the popular book, The Book of Why (Pearl and Mackenzie 2018) is a good place to start.