# load and install packages if neccessary
if(!require("rvest")) {install.packages("rvest"); library("rvest")}
if(!require("xml2")) {install.packages("xml2"); library("xml2")}
if(!require("tidytext")) {install.packages("tidytext"); library("tidytext")}
if(!require("tibble")) {install.packages("tibble"); library("tibble")}
if(!require("dplyr")) {install.packages("dplyr"); library("dplyr")}Text classification
Learning outcomes/objective: Learn…
- …about basic concepts of Natural Language Processing (NLP)
- …become familiar with a typical R-tidymodels-workflow for text analysis
- …overview machine learning approaches for text data (supervised & unsupervised)
- Lab: Supervised text classification with tidymodels.
Sources: Camille Landesvatter’s topic model lecture, Original material & see references; Tuning text models
1 Text as Data
- Many sources of text data for social scientists
- open ended survey responses, social media data, interview transcripts, news articles, official documents (public records, etc.), research publications, etc.
- even if data of interest not in textual form (yet)
- speech recognition, text recognition, machine translation etc.
- “Past”: text data often ignored (by quants), selectively read, anecdotally used or manually labeled by researchers
- Today: wide variety of text analytically methods (supervised + unsupervised) and increasing adoption of these methods by social scientists (Wilkerson and Casas 2017)
2 Language in NLP
- corpus: a collection of documents
- documents: single tweets, single statements, single text files, etc.
- tokenization: “the process of splitting text into tokens” (Silge 2017), further refers to defining the unit of analysis, i.e., tokens = single words, sequences of words or entire sentences
- bag of words (method): approach where all tokens are put together in a “bag” without considering their order (alternatively: bigrams/word pairs, word embeddings)
- possible issues with a simple bag-of-word: “I’m not happy and I don’t like it!”
- stop words: very common but uninformative terms (really?) such as “the”, “and”, “they”, etc.
- document-term/feature matrix (DTM/DFM): common format to store text data (examples later)
3 (R-)Workflow for Text Analysis
- Data collection (“Obtaining Text”*)
- Data manipulation / Corpus pre-processing (“From Text to Data”*)
- Vectorization: Turning Text into a Matrix (DTM/DFM1) (“From Text to Data”*)
- Analysis (“Quantitative Analysis of Text”*)
- Validation and Model Selection (“Evaluating Performance”2)
- Visualization and Model Interpretation
3.1 Data collection
- use existing corpora
- collect new corpora
- electronic sources: application user interfaces (APIs, e.g. Facebook, Twitter), web scraping, wikipedia, transcripts of all german electoral programs
- undigitized text, e.g. scans of documents
- data from interviews, surveys and/or experiments (speech → text)
- consider relevant applications to turn your data into text format (speech-to-text recognition, pdf-to-text, OCR, Mechanical Turk and Crowdflower)
4 Data manipulation
4.1 Data manipulation: Basics (1)
- text data is different from “structured” data (e.g., a set of rows and columns)
- most often not “clean” but rather messy
- shortcuts, dialect, incorrect grammar, missing words, spelling issues, ambiguous language, humor
- web context: emojis, # (twitter), etc.
- Preprocessing much more important & crucial determinant of successful text analysis!
4.2 Data manipulation: Basics (2)
Common steps in pre-processing text data:
stemming (removal of word suffixes), e.g., computation, computational, computer \(\rightarrow\) compute
lemmatisation (reduce a term to its lemma, i.e., its base form), e.g., “better” \(\rightarrow\) “good”
transformation to lower cases
removal of punctuation (e.g., ,;.-) / numbers / white spaces / URLs / stopwords / very infrequent words
\(\rightarrow\) Always choose your preprocessing steps carefully!
- e.g., removing punctuation: “I enjoy: eating, my cat and leaving out commas” vs. “I enjoy: eating my cat and leaving out commas”
Unit of analysis?! (sentence vs. unigram vs. bigram etc.)
4.3 Data manipulation: Basics (3)
In principle, all those transformations can be achieved by using base R
Other packages however provide ready-to-apply functions, such as {tidytext}, {tm} or {quanteda}
Important
- transform data to corpus object or tidy text object (examples on the next slides) or use tidymodels step functions
4.4 Data manipulation: Tidytext Example (1) (skipped)
Pre-processing with tidytext requires your data to be stored in a tidy text object.
Q: What are main characteristics of a tidy text dataset?
- one-token-per-row
- “long format”
First, we have to retrieve some data. In keeping with today’s session, we will use data from Wikipedias entry on Natural Language Processing.
# import wikipedia entry on Natural Language Processing, parsed by paragraph
text <- read_html("https://en.wikipedia.org/wiki/Natural_language_processing#Text_and_speech_processing") %>%
html_nodes("#content p")%>%
html_text()
# we decide to keep only paragraph 1 and 2
text<-text[1:2]
text[1] "Natural language processing (NLP) is an interdisciplinary subfield of computer science and information retrieval. It is primarily concerned with giving computers the ability to support and manipulate human language. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic (i.e. statistical and, most recently, neural network-based) machine learning approaches. The goal is a computer capable of \"understanding\"[citation needed] the contents of documents, including the contextual nuances of the language within them. To this end, natural language processing often borrows ideas from theoretical linguistics. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.\n"
[2] "Challenges in natural language processing frequently involve speech recognition, natural-language understanding, and natural-language generation.\n" In order to turn this data into a tidy text dataset, we first need to put it into a data frame (or tibble).
# put character vector into a data frame
# also add information that data comes from the wiki entry on NLP and from which paragraphs
wiki_df <- tibble(topic=c("NLP"), paragraph=1:2, text=text)
str(wiki_df)tibble [2 × 3] (S3: tbl_df/tbl/data.frame)
$ topic : chr [1:2] "NLP" "NLP"
$ paragraph: int [1:2] 1 2
$ text : chr [1:2] "Natural language processing (NLP) is an interdisciplinary subfield of computer science and information retrieva"| __truncated__ "Challenges in natural language processing frequently involve speech recognition, natural-language understanding"| __truncated__Q: Describe the above dataset. How many variables and observations are there? What do the variables display?
Now, by using the unnest_tokens() function from tidytext we transform this data to a tidy text format.
Q: How does our dataset change after tokenization and removing stopwords? How many observations do we now have? And what does the paragraph variable identify/store?
Q: Also, have a closer look at the single words. Do you notice anything else that has changed, e.g., is something missing from the original text?
tibble [82 × 3] (S3: tbl_df/tbl/data.frame)
$ topic : chr [1:82] "NLP" "NLP" "NLP" "NLP" ...
$ paragraph: int [1:82] 1 1 1 1 1 1 1 1 1 1 ...
$ word : chr [1:82] "natural" "language" "processing" "nlp" ... [1] "natural" "language" "processing"
[4] "nlp" "interdisciplinary" "subfield"
[7] "computer" "science" "information"
[10] "retrieval" "primarily" "concerned"
[13] "giving" "computers" "ability" 4.5 Data manipulation: Tidytext Example (2) (skipped)
“Pros” and “Cons”:
tidytext removes punctuation and makes all terms lowercase automatically (see above)
all other transformations need some dealing with regular expressions
- example to remove white space with tidytext (s+ describes a blank space):
[1] "Naturallanguageprocessing(NLP)isaninterdisciplinarysubfieldofcomputerscienceandinformationretrieval.Itisprimarilyconcernedwithgivingcomputerstheabilitytosupportandmanipulatehumanlanguage.Itinvolvesprocessingnaturallanguagedatasets,suchastextcorporaorspeechcorpora,usingeitherrule-basedorprobabilistic(i.e.statisticaland,mostrecently,neuralnetwork-based)machinelearningapproaches.Thegoalisacomputercapableof\"understanding\"[citationneeded]thecontentsofdocuments,includingthecontextualnuancesofthelanguagewithinthem.Tothisend,naturallanguageprocessingoftenborrowsideasfromtheoreticallinguistics.Thetechnologycanthenaccuratelyextractinformationandinsightscontainedinthedocumentsaswellascategorizeandorganizethedocumentsthemselves."
[2] "Challengesinnaturallanguageprocessingfrequentlyinvolvespeechrecognition,natural-languageunderstanding,andnatural-languagegeneration." - \(\rightarrow\) consider alternative packages (e.g., tm, quanteda)
Example: tm package
- input: corpus not tidytext object
- What is a corpus in R? \(\rightarrow\) group of documents with associated metadata
# Load the tm package
library(tm)
# Clean corpus
corpus_clean <- VCorpus(VectorSource(wiki_df$text)) %>%
tm_map(removePunctuation, preserve_intra_word_dashes = TRUE) %>%
tm_map(removeNumbers) %>%
tm_map(content_transformer(tolower)) %>%
tm_map(removeWords, words = c(stopwords("en"))) %>%
tm_map(stripWhitespace) %>%
tm_map(stemDocument)
# Check exemplary document
corpus_clean[["1"]][["content"]][1] "natur languag process nlp interdisciplinari subfield comput scienc inform retriev primarili concern give comput abil support manipul human languag involv process natur languag dataset text corpora speech corpora use either rule-bas probabilist ie statist recent neural network-bas machin learn approach goal comput capabl understandingcit need content document includ contextu nuanc languag within end natur languag process often borrow idea theoret linguist technolog can accur extract inform insight contain document well categor organ document"- with the tidy text format, regular R functions can be used instead of the specialized functions which are necessary to analyze a corpus object
- dplyr workflow to count the most popular words in your text data:
- especially for starters, tidytext is a good starting point (in my opinion), since many steps has to be carried out individually (downside: maybe more code)
- other packages combine many steps into one single function (e.g. quanteda combines pre-processing and DFM casting in one step)
- R (as usual) offers many ways to achieve similar or same results
- e.g. you could also import, filter and pre-process using dplyr and tidytext, further pre-process and vectorize with tm or quanteda (tm has simpler grammar but slightly fewer features), use machine learning applications and eventually re-convert to tidy format for interpretation and visualization (ggplot2)
5 Vectorization
5.1 Vectorization: Basics
- Text analytical models (e.g., topic models) often require the input data to be stored in a certain format
- only so will algorithms be able to quickly compare one document to a lot of other documents to identify patterns
- Typically: document-term matrix (DTM), sometimes also called document-feature matrix (DFM)
- turn raw text into a vector-space representation
- matrix where each row represents a document and each column represents a word
- term-frequency (tf): the number within each cell describes the number of times the word appears in the document
- term frequency–inverse document frequency (tf-idf): weights occurrence of certain words, e.g., lowering weight of word “education” in corpus of articles on educational inequality
5.2 Vectorization: Tidytext example
Remember our tidy text formatted data (“one-token-per-row”)?
# A tibble: 5 × 3
topic paragraph word
<chr> <int> <chr>
1 NLP 1 natural
2 NLP 1 language
3 NLP 1 processing
4 NLP 1 nlp
5 NLP 1 interdisciplinaryWith the cast_dtm function from the tidytext package, we can now transform it to a DTM.
# Cast tidy text data into DTM format
dtm <- tidy_df %>%
count(paragraph,word) %>%
cast_dtm(document=paragraph,
term=word,
value=n) %>%
as.matrix()
# Check the dimensions and a subset of the DTM
dim(dtm)[1] 2 59 Terms
Docs ability accurately approaches based borrows capable
1 1 1 1 2 1 1
2 0 0 0 0 0 05.3 Vectorization: Tm example
- In case you pre-processed your data with the tm package, remember we ended with a pre-processed corpus object
- Now, simply apply the DocumentTermMatrix function to this corpus object
# Pass your "clean" corpus object to the DocumentTermMatrix function
dtm_tm <- DocumentTermMatrix(corpus_clean, control = list(wordLengths = c(2, Inf))) # control argument here is specified to include words that are at least two characters long
# Check a subset of the DTM
inspect(dtm_tm[,1:6])<<DocumentTermMatrix (documents: 2, terms: 6)>>
Non-/sparse entries: 6/6
Sparsity : 50%
Maximal term length: 8
Weighting : term frequency (tf)
Sample :
Terms
Docs abil accur approach borrow can capabl
1 1 1 1 1 1 1
2 0 0 0 0 0 0Q: How do the terms between the DTM we created with tidytext and the one created with tm differ? Why?
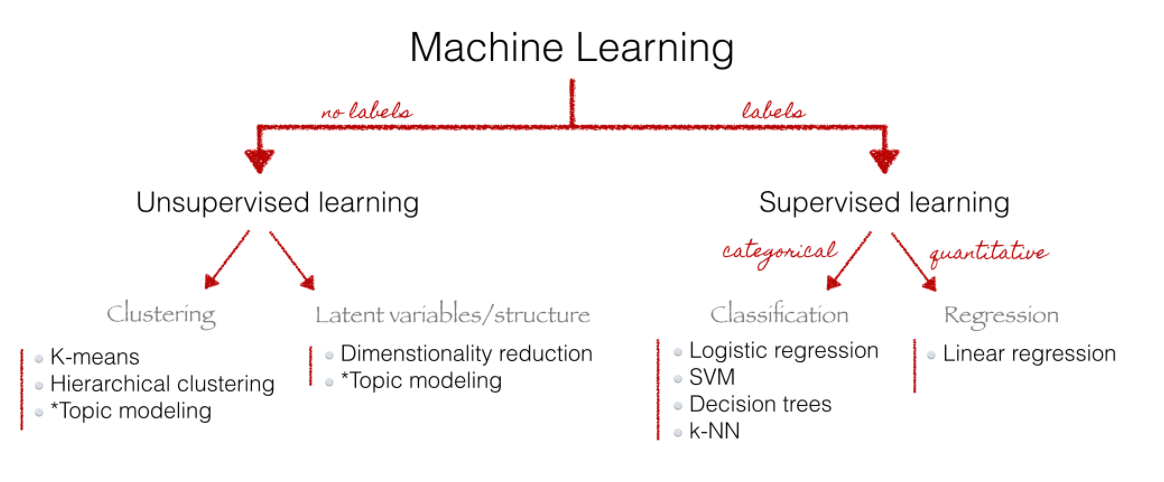
6 Analysis: Supervised vs. unsupervised
- Supervised statistical learning: involves building a statistical model for predicting, or estimating, an output based on one or more inputs
- We observe both features \(x_{i}\) and the outcome \(y_{i}\)
- Unsupervised statistical learning: There are inputs but no supervising output; we can still learn about relationships and structure from such data
- Choice depends on use case: “Whereas unsupervised methods are often used for discovery, supervised learning methods are primarily used as a labor-saving device.” (Wilkerson and Casas 2017)
Source: Christine Doig 2015, also see Grimmer and Stewart (2013) for an overview of text as data methods.
7 Unsupervised: Topic Modeling (1)
- Goal: discovering the hidden (i.e, latent) topics within the documents and assigning each of the topics to the documents
- topic models belong to a class of unsupervised classification
- i.e., no prior knowledge of a corpus’ content or its inherent topics is needed (however some knowledge might help you validate your model later on)
- Researcher only needs to specify number of topics (not as intuitive as it sounds!)

Source: Christine Doig 2015
8 Unsupervised: Topic Modeling (2)
- one of the most popular topic model algorithms
- developed by a team of computer linguists (David Blei, Andrew Ng und Michael Jordan, original paper)
- two assumptions:
- each document is a mixture over latent topics
- for example, in a two-topic model we could say “Document 1 is 90% topic A and 10% topic B, while Document 2 is 30% topic A and 70% topic B.”
- each topic is a mixture of words (with possible overlap)
- each document is a mixture over latent topics
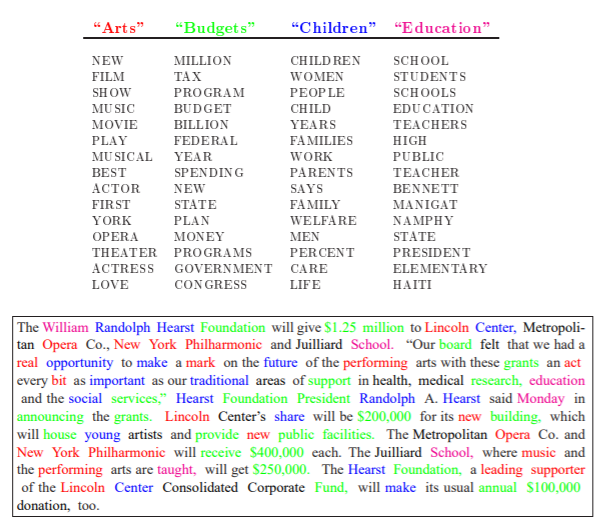
Note: Exemplary illustration of findings from an LDA on a corpus of news articles. Topics are mixtures of words. Documents are mixtures of topics. Source: Blei, Ng, Jordan (2003)
9 Preprocessing text
- Following chapter Tuning text models.
- Text must be heavily processed to be used as predictor data for modeling
- We pursue different steps:
- Create an initial set of count-based features, such as the number of words, spaces, lower- or uppercase characters, URLs, and so on; we can use the textfeatures package for this.
- Tokenize the text (i.e. break the text into smaller components such as words).
- Remove stop words such as “the”, “an”, “of”, etc.
- Stem tokens to a common root where possible.
- Remove predictors with a single distinct value.
- Center and scale all predictors.
- Important: More advanced preprocessing (transformers, BERT) is in the process of being implemented (see
textrecipes)- Right now still has to be done before (e.g., basic BERT with r)
10 Lab: Classifying text
Lab is based on an older lab by myself. The data comes from our project on measuring trust (see Landesvatter & Bauer (forthcoming) in Sociological Methods & Research). The data for the lab was pre-processed. 56 open-ended answers that revealed the respondent’s profession, age, area of living/rown or others’ specific names/categories, particular activities (e.g., town elections) or city were deleted for reasons of anonymity.
- Research questions: Do individuals interpret trust questions similar? Do they have a higher level if they think of someone personally known to them?
- Objective: Predict whether they think of personally known person (yes/no).
We start by loading our data that contains the following variables:
respondent_id: Individual’s identification number (there is only one response per individual - so it’s also the id for the response)social_trust_score: Individual’s value on the trust scale- Question: Generally speaking, would you say that most people can betrusted, or that you can’t be too careful in dealing with people? Please tell me on a score of 0 to 6, where 0 means you can’t be too careful and 6 means that most people can be trusted.
- Original scale: 0 - You can’t be too careful; 1; 2; 3; 4; 5; 6 - Most people can be trusted; Don’t know;
- Recoded scale:
Don't know = NAand values0-6standardized to0-1.
- Question: Generally speaking, would you say that most people can betrusted, or that you can’t be too careful in dealing with people? Please tell me on a score of 0 to 6, where 0 means you can’t be too careful and 6 means that most people can be trusted.
text: Individual’s response to the probing question- Question: In answering the previous question, who came to your mind when you were thinking about ‘most people?’ Please describe.
human_classified: Variable that contains the manual human classification of whether person was thinking about someone personally known to them or not (this is based on the open-ended response totext)N = 295were classified as1 = yesN = 666were classified as0 = noN = 482were not classified (we want to make predictions on those those!)
Table 1 shows the first few rows of the dataset:
| respondent_id | social_trust_score | text | human_classified |
|---|---|---|---|
| 1 | 0.5000000 | People I know or have known a while. | NA |
| 2 | 0.5000000 | Really everybody I know whether it be somebody I know as a neighbor or somebody I know as a friend somebody I know as a very close in a close relationship everybody has their limits of what they're capable of doing and they may hit a wall and get to a point where they I feel threatened and acted in the erratic way but most people if I'm treating them with gentleness and respect we will have a decent interaction. But I just never know depends on how things are shaping up what kind of day everybody's having. I suppose mostly I just have confidence in my ability to stay grounded in the flow of and Gestalt of interaction and find a current the river and float down the middle so to speak metaphorically. | 1 |
| 3 | 0.6666667 | I thought about people I've met recently. One is a woman I met at the dog park I've become friends with | 1 |
| 4 | 0.1666667 | Strangers and sometimes even work colleagues. | 1 |
| 5 | 0.3333333 | I was clearly thinking of coworkers, 2 in particular where trust depended on whether or not there was something to gain by them being trustworthy or not. What they could get away with to their benefit | 1 |
| 6 | 0.5000000 | Depends on the person. | NA |
The variable human_classified contains the values NA (was not classified), 1 (respondents were thinking about people known to them) and 0 (respondents were not thinking about people known to them).
10.1 Random Forest (with tuning) for text classification
- Steps
- Load and initial split of the data
- Create folds for cross-validation
- Define recipe (text preprocessing) & model (random forest + parameters to tune) & workflow
- 1st fitting & tuning session: Fit model to resampled training data (folds) + tuning in parallel and inspect accuracy & tuning parameters afterwards
- If happy,
select_besthyperparameters (identified in tuning),finalize_modelthe model with those parameters and create a finalworkflow_final. Train/fitworkflow_finalto the full training dataset and obtainfit_final. - Use
fit_finalto predict outcome both indata_trainanddata_testand evaluate accuracy. - To explore which predictors are important calcuculate and visualize variable importance.
We first import the data into R:
# Extract data with missing outcome
data_missing_outcome <- data %>%
filter(is.na(human_classified))
dim(data_missing_outcome)[1] 482 4# Omit individuals with missing outcome from data
data <- data %>% drop_na(human_classified) # ?drop_na
dim(data)[1] 961 4# 1.
# Split the data into training and test data
set.seed(345)
data_split <- initial_split(data, prop = 0.8)
data_split # Inspect<Training/Testing/Total>
<768/193/961># Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# 2.
# Create resampled partitions of training data
data_folds <- vfold_cv(data_train, v = 2) # V-fold/k-fold cross-validation
data_folds # data_folds now contains several resamples of our training data # 2-fold cross-validation
# A tibble: 2 × 2
splits id
<list> <chr>
1 <split [384/384]> Fold1
2 <split [384/384]> Fold2# 3.
# Define the recipe & model
recipe1 <-
recipe(human_classified ~ respondent_id + text, data = data_train) %>%
update_role(respondent_id, new_role = "id") %>% # update role
step_tokenize(text) %>% # Tokenize text (split into words)
step_stopwords(text) %>% # Remove stopwords
step_stem(text) %>% # Text stemming
step_tokenfilter(text, max_tokens = 100) %>% # Filter max tokens
step_tf(text) # convert to term-feature matrix
# Extract and preview data + recipe (direclty with $)
data_preprocessed <- prep(recipe1, data_train)$template
dim(data_preprocessed)[1] 768 102tf_text_acquaint
0 1 2
746 21 1 # Specify model with tuning
model1 <- rand_forest(
mtry = tune(), # tune mtry parameter
trees = 1000, # grow 1000 trees
min_n = tune() # tune min_n parameter
) %>%
set_mode("classification") %>%
set_engine("ranger",
importance = "permutation") # potentially computational intensive
# Specify workflow (with tuning)
workflow1 <- workflow() %>%
add_recipe(recipe1) %>%
add_model(model1)
# 4. 1st fitting & tuning & evaluation of accuracy
# Specify to use parallel processing
doParallel::registerDoParallel()
set.seed(345)
tune_result <- tune_grid(
workflow1,
resamples = data_folds,
grid = 10 # choose 10 grid points automatically
)
tune_result# Tuning results
# 2-fold cross-validation
# A tibble: 2 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [384/384]> Fold1 <tibble [20 × 6]> <tibble [0 × 3]>
2 <split [384/384]> Fold2 <tibble [20 × 6]> <tibble [0 × 3]>tune_result %>%
collect_metrics() %>% # extract metrics
filter(.metric == "accuracy") %>% # keep accuracy only
select(mean, min_n, mtry) %>% # subset variables
pivot_longer(min_n:mtry, # convert to longer
values_to = "value",
names_to = "parameter"
) %>%
ggplot(aes(value, mean, color = parameter)) + # plot!
geom_point(show.legend = FALSE) +
facet_wrap(~parameter, scales = "free_x") +
labs(x = NULL, y = "accuracy")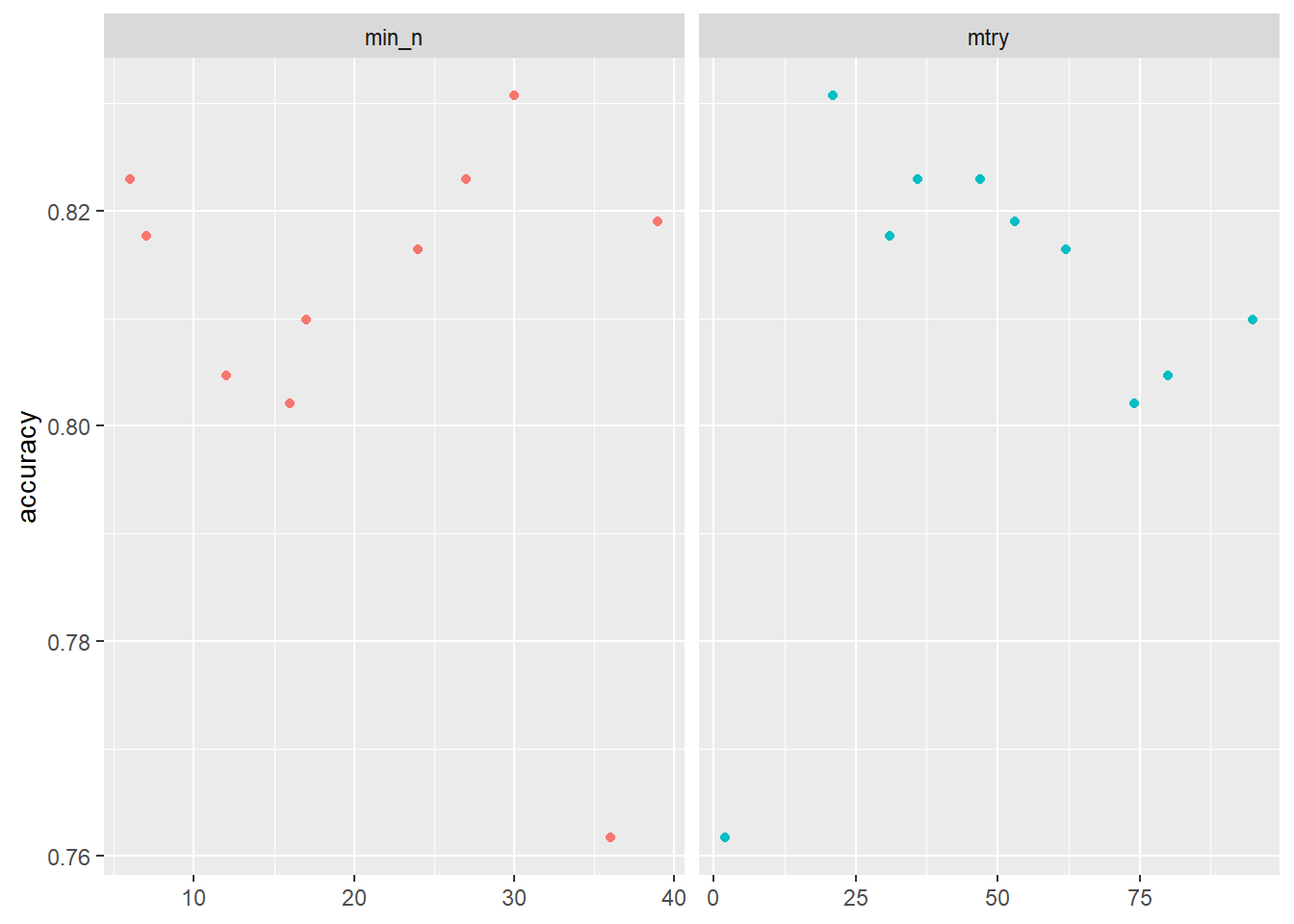
# 5. Choose best model after tuning & fit/train
# Find tuning parameter combination with best performance values
best_accuracy <- select_best(tune_result, "accuracy")
best_accuracy# A tibble: 1 × 3
mtry min_n .config
<int> <int> <chr>
1 21 30 Preprocessor1_Model01 # Take list/tibble of tuning parameter values
# and update model1 with those values.
model_final <- finalize_model(model1, best_accuracy)
model_finalRandom Forest Model Specification (classification)
Main Arguments:
mtry = 21
trees = 1000
min_n = 30
Engine-Specific Arguments:
importance = permutation
Computational engine: ranger # Define final workflow
workflow_final <- workflow() %>%
add_recipe(recipe1) %>% # use standard recipe
add_model(model_final) # use final model
# Fit final model
fit_final <- parsnip::fit(workflow_final, data = data_train)
fit_final══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: rand_forest()
── Preprocessor ────────────────────────────────────────────────────────────────
5 Recipe Steps
• step_tokenize()
• step_stopwords()
• step_stem()
• step_tokenfilter()
• step_tf()
── Model ───────────────────────────────────────────────────────────────────────
Ranger result
Call:
ranger::ranger(x = maybe_data_frame(x), y = y, mtry = min_cols(~21L, x), num.trees = ~1000, min.node.size = min_rows(~30L, x), importance = ~"permutation", num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1), probability = TRUE)
Type: Probability estimation
Number of trees: 1000
Sample size: 768
Number of independent variables: 100
Mtry: 21
Target node size: 30
Variable importance mode: permutation
Splitrule: gini
OOB prediction error (Brier s.): 0.1205772 # Q: What do the values for `mtry` and `min_n` in the final model mean?
# 6. Predict & evaluate accuracy (both in full training and test data)
metrics_combined <-
metric_set(accuracy, precision, recall, f_meas) # Set accuracy metrics
# Accuracy: Full training data
augment(fit_final, new_data = data_train) %>%
metrics_combined(truth = human_classified, estimate = .pred_class) # A tibble: 4 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.895
2 precision binary 0.904
3 recall binary 0.947
4 f_meas binary 0.925# Cross-classification table
augment(fit_final, new_data = data_train) %>%
conf_mat(data = .,
truth = human_classified, estimate = .pred_class) Truth
Prediction 0 1
0 499 53
1 28 188# Accuracy: Test data
augment(fit_final, new_data = data_test) %>%
metrics_combined(truth = human_classified, estimate = .pred_class) # A tibble: 4 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.860
2 precision binary 0.894
3 recall binary 0.914
4 f_meas binary 0.904# Cross-classification table
augment(fit_final, new_data = data_test) %>%
conf_mat(data = .,
truth = human_classified, estimate = .pred_class) Truth
Prediction 0 1
0 127 15
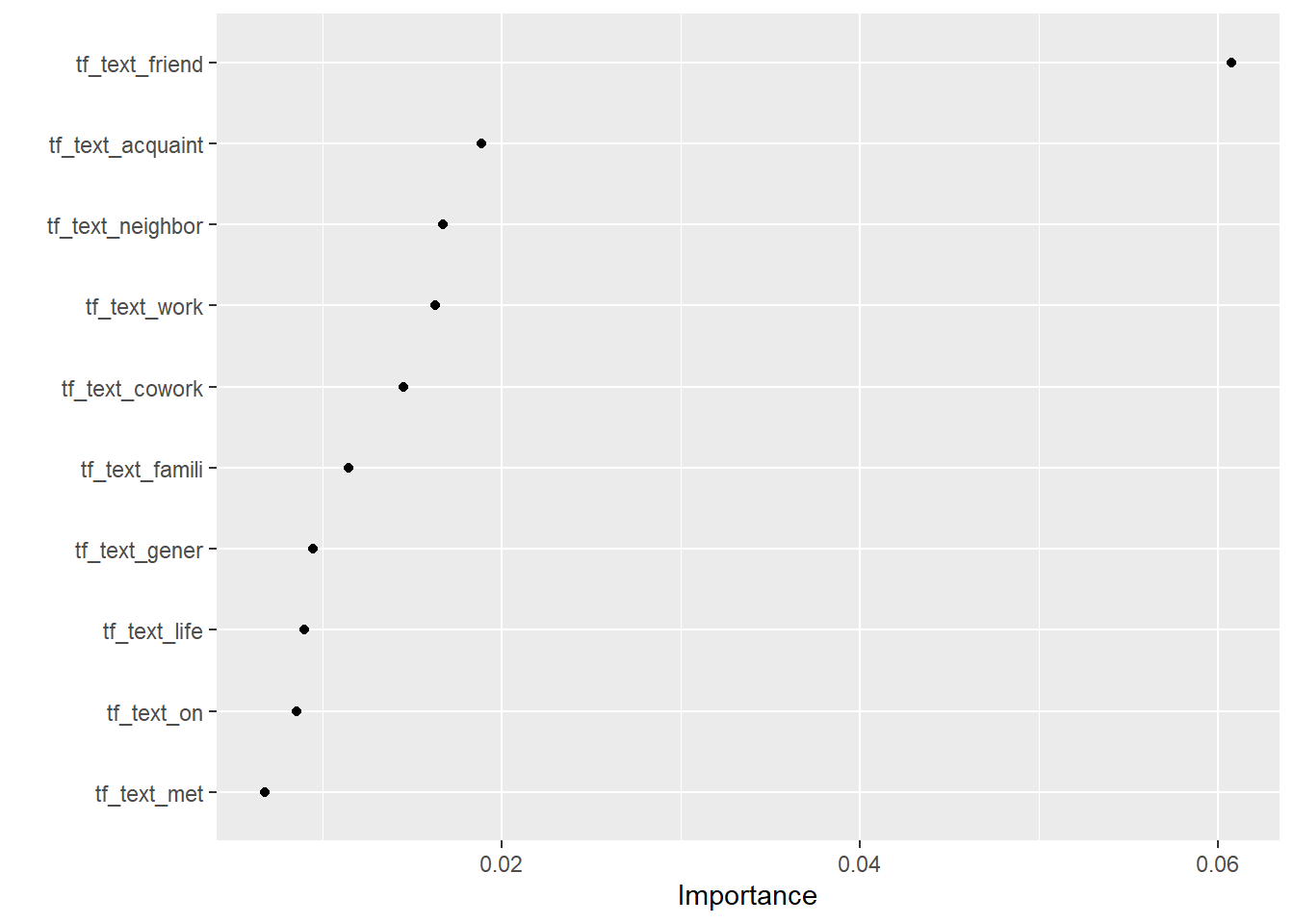
1 12 39# 7. Visualize variable importance
# install.packages("vip")
fit_final$fit$fit %>%
vip::vi() %>%
dplyr::slice(1:10) %>%
kable()| Variable | Importance |
|---|---|
| tf_text_friend | 0.0607590 |
| tf_text_acquaint | 0.0188360 |
| tf_text_neighbor | 0.0167197 |
| tf_text_work | 0.0162719 |
| tf_text_cowork | 0.0144992 |
| tf_text_famili | 0.0114177 |
| tf_text_gener | 0.0094499 |
| tf_text_life | 0.0089688 |
| tf_text_on | 0.0085111 |
| tf_text_met | 0.0067403 |
11 Exercise
- In the lab above we used a random forest to built a classifier for our labelled text. Thereby we made different choice in preprocessing the texts. Please modify those choices (e.g., don’t remove stopwords, change
max_tokens). How does this affect the accuracy of your model (and the training process)?
12 Lab: Classifying text using BERT
This lab was inspired by a lab by Dr. Hervé Teguim. The lab requires a working Python installation.
Below we install reticulate and the necessary python packages. We also import these packages/modules to make them available from within R in the virtual environment r-reticulate.
# Based on https://rpubs.com/Teguim/textclassificationwithBERT
# First set up the python environment to use: Global options -> Python
library(reticulate) # To communicate with python
# List all available virtualenvs
virtualenv_list() [1] "r-reticulate"virtualenv: r-reticulate# indicate that we want to use a specific virtualenv
use_virtualenv("r-reticulate")
# install python packages
virtualenv_install("r-reticulate", "pip")Using virtual environment "r-reticulate" ...Using virtual environment "r-reticulate" ...Using virtual environment "r-reticulate" ...Using virtual environment "r-reticulate" ...Using virtual environment "r-reticulate" ...Using virtual environment "r-reticulate" ...Using virtual environment "r-reticulate" ...We then import the data into R:
# Rename labelled data
data <- data %>% rename(label = human_classified) %>%
select(text, label) %>%
mutate(label = as.numeric(as.character(label)))
# Extract data with missing outcome
data_missing_outcome <- data %>%
filter(is.na(label))
dim(data_missing_outcome)[1] 482 2# Omit individuals with missing outcome from data
data <- data %>% drop_na(label) # ?drop_na
dim(data)[1] 961 2# 1.
# Split the data into training, validation and test data
set.seed(1234)
data_split <- initial_validation_split(data, prop = c(0.6, 0.2))
data_split # Inspect<Training/Validation/Testing/Total>
<576/192/193/961># Extract the datasets
data_train <- training(data_split)
data_validation <- validation(data_split)
data_test <- testing(data_split) # Do not touch until the end!
dim(data_train)[1] 576 2Then we load the respective dataset into python so that we can access it there and save it in data.
# Load the dataset
#data = r.data_train # Get data from R into python
#len(data.index)
from datasets import DatasetDict
# Assuming you have your dataset 'train_dataset' ready
# Create a DatasetDict
data = DatasetDict()
data["train"] = r.data_train
data["train"] text label
0 Really everybody I know whether it be somebody... 1.0
1 I thought about people I've met recently. One ... 1.0
2 I was clearly thinking of coworkers, 2 in part... 1.0
3 People that work in stores I go to often 0.0
4 I was thinking more about "friends of friends"... 0.0
.. ... ...
571 Some people in the world around us can have th... 0.0
572 A football fan 0.0
573 A man that lived across the road from us and f... 1.0
574 people in general? 0.0
575 People I haven’t seen before, or talk before, ... 0.0
[576 rows x 2 columns] text label
0 The public in general, not my close friends 0.0
1 Most of the people I know. Only a few are trul... 1.0
2 The citizens of my city. 0.0
3 I assume everyone can be trusted to a certain ... 0.0
4 people in sales, or everyone that breathes air. 0.0
.. ... ...
187 No one 0.0
188 Everybody can't be easily trusted. 0.0
189 I imagined white Christian Americans. 0.0
190 A stranger 0.0
191 Friends 1.0
[192 rows x 2 columns] text label
0 Strangers and sometimes even work colleagues. 1.0
1 2 different types--the political and cultural ... 0.0
2 I first thought about strangers or unfamiliar ... 0.0
3 Literally mankind as a whole. I thought about ... 0.0
4 nobody 0.0
.. ... ...
188 Again, no one person in particular came to mind. 0.0
189 Because most people think like this because th... 0.0
190 Anyone in society. 0.0
191 Friends 1.0
192 Most the population 0.0
[193 rows x 2 columns]# We define a function dataframe_to_dataset(df) that takes a pandas DataFrame df as input and returns a Dataset object created from the DataFrame using Dataset.from_pandas(df).
# We iterate over the items in data.items(). For each key-value pair, we convert the value (pandas DataFrame) to a Dataset using the dataframe_to_dataset function, and assign the result back to the data DatasetDict at the same key.
# Conver
from datasets import Dataset, DatasetDict
# Assuming you have a DatasetDict named data with values train, validate, and test
# Function to convert pandas DataFrame to Dataset
def dataframe_to_dataset(df):
return Dataset.from_pandas(df)
# Iterate over the items in the DatasetDict and convert pandas DataFrame to Dataset
for key, value in data.items():
data[key] = dataframe_to_dataset(value)
# Now the values in the DatasetDict data are of type Dataset
data.map<bound method DatasetDict.map of DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 576
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 192
})
test: Dataset({
features: ['text', 'label'],
num_rows: 193
})
})>Use exit() or Ctrl-Z plus Return to exit# Set the labels properly
# Assuming data is your DatasetDict object
# Cast the "label" column to int type
# Convert "label" column to int type
data["train"]["label"][1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0][0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0][1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0]Use exit() or Ctrl-Z plus Return to exit# CHANGE LABELS TO INTEGER
# TRAINING DATA
labels = data["train"]["label"] # Extract labels from the dataset
labels_int = [int(label) for label in labels] # Convert labels from float to int
data["train"] = data["train"].add_column("label_int", labels_int) # Update the dataset with the new integer labels
data["train"] = data["train"].remove_columns("label") # Optionally, you can remove the old float labels if you want to clean up the dataset
data["train"] = data["train"].rename_column("label_int", "label") # Rename the new 'label_int' column back to 'label'
print(data["train"]["label"][:5]) # Verify the changes[1, 1, 1, 0, 0]# VALIDATION DATA
labels = data["validation"]["label"] # Extract labels from the dataset
labels_int = [int(label) for label in labels] # Convert labels from float to int
data["validation"] = data["validation"].add_column("label_int", labels_int) # Update the dataset with the new integer labels
data["validation"] = data["validation"].remove_columns("label") # Optionally, you can remove the old float labels if you want to clean up the dataset
data["validation"] = data["validation"].rename_column("label_int", "label") # Rename the new 'label_int' column back to 'label'
print(data["validation"]["label"][:5]) # Verify the changes[0, 1, 0, 0, 0]# TEST DATA
labels = data["test"]["label"] # Extract labels from the dataset
labels_int = [int(label) for label in labels] # Convert labels from float to int
data["test"] = data["test"].add_column("label_int", labels_int) # Update the dataset with the new integer labels
data["test"] = data["test"].remove_columns("label") # Optionally, you can remove the old float labels if you want to clean up the dataset
data["test"] = data["test"].rename_column("label_int", "label") # Rename the new 'label_int' column back to 'label'
print(data["test"]["label"][:5]) # Verify the changes[1, 0, 0, 0, 0][1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0][0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1][1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0]This code segment imports the AutoTokenizer class from the transformers library and uses it to tokenize text data. It first defines the pre-trained model checkpoint name as “distilbert-base-cased” and initializes the tokenizer accordingly. Then, it defines a custom function called tokenize_function, which applies the tokenizer to each batch of text data, enabling padding and truncation. Finally, the function is applied to the data dataset, assuming it’s a dataset object with text data, using the map function with batched tokenization enabled for efficiency.
# Tokenization
# Import the AutoTokenizer class from the transformers module
from transformers import AutoTokenizer
# Define the pre-trained model checkpoint name
checkpoint = "distilbert-base-cased"
# Initialize the tokenizer using the pre-trained model checkpoint
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased")
# Define a custom function to tokenize a batch of text data
def tokenize_function(batch):
# Tokenize the text data in the batch, enabling padding and truncation
return tokenizer(batch["text"], padding=True, truncation=True)
# Apply the tokenize_function to the data dataset, performing tokenization on each batch
# `data` is assumed to be a dataset object with text data to tokenize
# `batched=True` enables tokenization in batches for efficiency
# `batch_size=None` indicates that the dataset will be tokenized with the default batch size
data_encoded = data.map(tokenize_function, batched=True, batch_size=None)
Map: 0%| | 0/576 [00:00<?, ? examples/s]
Map: 100%|##########| 576/576 [00:00<00:00, 16644.87 examples/s]
Map: 0%| | 0/192 [00:00<?, ? examples/s]
Map: 100%|##########| 192/192 [00:00<00:00, 11715.42 examples/s]
Map: 0%| | 0/193 [00:00<?, ? examples/s]
Map: 100%|##########| 193/193 [00:00<00:00, 11538.42 examples/s]# Show the sentence, the different tokens and the corresponding numerical ids
print(data_encoded['train'][0]){'text': "Really everybody I know whether it be somebody I know as a neighbor or somebody I know as a friend somebody I know as a very close in a close relationship everybody has their limits of what they're capable of doing and they may hit a wall and get to a point where they I feel threatened and acted in the erratic way but most people if I'm treating them with gentleness and respect we will have a decent interaction. But I just never know depends on how things are shaping up what kind of day everybody's having. I suppose mostly I just have confidence in my ability to stay grounded in the flow of and Gestalt of interaction and find a current the river and float down the middle so to speak metaphorically.", 'label': 1, 'input_ids': [101, 8762, 10565, 146, 1221, 2480, 1122, 1129, 9994, 146, 1221, 1112, 170, 12179, 1137, 9994, 146, 1221, 1112, 170, 1910, 9994, 146, 1221, 1112, 170, 1304, 1601, 1107, 170, 1601, 2398, 10565, 1144, 1147, 6263, 1104, 1184, 1152, 112, 1231, 4451, 1104, 1833, 1105, 1152, 1336, 1855, 170, 2095, 1105, 1243, 1106, 170, 1553, 1187, 1152, 146, 1631, 4963, 1105, 5376, 1107, 1103, 27450, 1236, 1133, 1211, 1234, 1191, 146, 112, 182, 12770, 1172, 1114, 6892, 1757, 1105, 4161, 1195, 1209, 1138, 170, 11858, 8234, 119, 1252, 146, 1198, 1309, 1221, 9113, 1113, 1293, 1614, 1132, 23918, 1146, 1184, 1912, 1104, 1285, 10565, 112, 188, 1515, 119, 146, 6699, 2426, 146, 1198, 1138, 6595, 1107, 1139, 2912, 1106, 2215, 18395, 1107, 1103, 4235, 1104, 1105, 144, 16144, 6066, 1104, 8234, 1105, 1525, 170, 1954, 1103, 2186, 1105, 15666, 1205, 1103, 2243, 1177, 1106, 2936, 21927, 9203, 119, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}Use exit() or Ctrl-Z plus Return to exitBelow a pre-trained model for sequence classification is defined using the Hugging Face Transformers library in Python. The AutoModelForSequenceClassification class is imported from the transformers module. The variable num_labels is assigned the number of output labels for the classification task, which is set to 2 here. The from_pretrained() method is then used to load a pre-trained DistilBERT model for sequence classification (‘distilbert-base-cased’). Additionally, the num_labels argument is specified to initialize the model with the correct number of output labels. This code initializes a model that is ready for training on a binary classification task.
# Definition of the model for training
from transformers import AutoModelForSequenceClassification
# Number of output labels for the classification task
num_labels = 2
# Load a pre-trained DistilBERT model for sequence classification and initialize it with the specified number of labels
# The 'distilbert-base-cased' checkpoint is used, which is a smaller version of the BERT model with cased vocabulary
model = AutoModelForSequenceClassification.from_pretrained('distilbert-base-cased',
num_labels=num_labels)
modelDistilBertForSequenceClassification(
(distilbert): DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(28996, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0-5): 6 x TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(activation): GELUActivation()
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=2, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)Use exit() or Ctrl-Z plus Return to exitWe import the accuracy_score function from sklearn.metrics module to calculate the accuracy of predictions.
A function named get_accuracy is defined, which takes preds as input, representing the predictions made by a model.
Inside the function: * predictions variable is assigned the predicted labels obtained by taking the index of the maximum value along the last axis of the predictions tensor. This is done using the argmax() method. * labels variable is assigned the true labels extracted from the preds object. * The accuracy variable is assigned the accuracy score calculated by comparing the true labels and predicted labels using the accuracy_score function. * Finally, a dictionary containing the accuracy score is returned.
# Import the accuracy_score function from the sklearn.metrics module
from sklearn.metrics import accuracy_score
# Define a function to calculate the accuracy of predictions
def get_accuracy(preds):
# Extract the predicted labels by taking the index of the maximum value along the last axis of the predictions tensor
predictions = preds.predictions.argmax(axis=-1)
# Extract the true labels from the preds object
labels = preds.label_ids
# Calculate the accuracy score by comparing the true labels and predicted labels
accuracy = accuracy_score(preds.label_ids, preds.predictions.argmax(axis=-1))
# Return a dictionary containing the accuracy score
return {'accuracy': accuracy}Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 576
})576Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 576
})[1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0]["Really everybody I know whether it be somebody I know as a neighbor or somebody I know as a friend somebody I know as a very close in a close relationship everybody has their limits of what they're capable of doing and they may hit a wall and get to a point where they I feel threatened and acted in the erratic way but most people if I'm treating them with gentleness and respect we will have a decent interaction. But I just never know depends on how things are shaping up what kind of day everybody's having. I suppose mostly I just have confidence in my ability to stay grounded in the flow of and Gestalt of interaction and find a current the river and float down the middle so to speak metaphorically.", "I thought about people I've met recently. One is a woman I met at the dog park I've become friends with", 'I was clearly thinking of coworkers, 2 in particular where trust depended on whether or not there was something to gain by them being trustworthy or not. What they could get away with to their benefit', 'People that work in stores I go to often', 'I was thinking more about "friends of friends". People you meet through your friends who they engage with but you never have.', 'Complete strangers in a social setting. Like a party or event.', 'My family, friends, and acquaintances.', 'People I know and also you just have to go with your gut instinct. Or I do.', 'People I meet more than once and not only if they are retail employees but strangers.', "Someone doing something behind my back that will jeopardize my wellbeing, my place of residence, or blame me or start stories about me that aren't true. This has happened a few times to me before.", 'Most Americans', 'Several people that I recently met at a meeting.', 'The general society', 'coworkers', 'General people I interact with', 'People who I have previously encountered and know.', "Well I want to say that before this past 18-24 month period; I almost always chose to believe that people were rarely malevolent intentionally and that by demonstrating trust you earned it. I still want to believe that outside of the US this may be true in limited instances at least. I don't think most people are committed to truth if it isn't both the easiest path and the one that they personally benefit from and champion.", "Just the average person you see around. Past coworkers came to mind, people I've seen on the bus, friends and family.", 'I thought of all people I come across - friends, neighbors, relatives, spouses/significant others, acquaintances, strangers.', 'I was thinking of everybody, from professionals to random strangers on the street.', "Again i'm not picturing anyone. Just a general premise.", 'No one in particular', "Most people would be everyone that I don't know.", 'No one in particular.', 'I thought not only about my closest people (relatives and friends) but thought about people in general', 'Almost all relationships', 'General average people with normal jobs and a mundane existence.', 'Strangers I would say are most people to me', 'Friends and work associates', "Just people in general, but I imagined a wide variety or strangers like someone might run across in a large city. It's a relatively random draw of people, so some of them are likely to be perfectly good people, but some of them are likely to be a bit more dangerous.", 'the same homeless person', 'Again, it’s hard to say. Can I see what this person looks like? That has an impact I’m sure.', 'People in my community.', 'Fellow Americans', 'Former friends', 'People I may casually meet not necessarily know. A new neighbor. A new coworker.', 'The average person that you see on the side of the street just smiling.', 'I tried to think about humanity at large; a stranger you might meet on the street and ask for directions, trusting someone at the airport to watch your bag', 'I was thinking about ordinary people in my community. I do not know them so they would be considered strangers who I would pass by at stores. I would trust these people, and feel safe to be around them.', 'Neighbors, politically active people and their associates/ candidates.', 'Folks living in America', 'My friends', 'regular people that you see on the street everyday, co-workers, costumers', 'Who knows', "Random people I don't know", 'everyday people that one would meet, and even people you may have known for a while and know fairly well.', 'strangers', 'I thought of my coworkers and general people I would see in my community. People I would see shopping in the store or other places of business.', 'No onr', "Any person that I don't really know.", "People that you don't know well.", 'Nobody.', 'Acquaintances', 'friends and family, people I interact with in the community.', 'anyone that makes a point to introduce themselves to you', 'I was thinking about people in general with no restrictions on race or income level.', 'Anyone can turn out to be a serial killer.', 'Friends and people I may meet outside of my family. It could be worker in a store, people from my church, people that I strike up a conversation with.', 'someone random on the side of the road', 'I just think of mostly everyone', 'random strangers on the street', 'nobody came to mind. "most people" is not a singular specification.', 'People I would meet through friends and family or other people in my field of work.', 'a doctor', 'A friend of my son who visited the house to play video games with him. Then one day I came home to find the back door busted down and video game console and games gone.', 'As most of the activities I currently participate in are child related I thought of fellow parents', "A combination of neighbors and people you do business with. That's why I read it halfway", 'One of my common friend. At first I did not trust him a lot.', 'People at work, people met at random, relatives and friends', 'I generally thought of people I do not know such as strangers.', "the general population. when you go to the store or any public place. the crowd is 'most people.'", 'People that I know but not very well.', "I based that off of all the people I've met and gotten to know.", 'No one in particular. Generally speaking my guard is up the first few times I interact with people. That said, I think everyone deserves a chance to show themselves to be trustworthy.', 'Any person that I might have an interaction with.', 'Neighbors', 'every one, trust has to be earned', 'My answer is the same as in the previous question: no one in particular, just people in general.', 'people on the street', 'People that have crossed me', 'men women and children', "I largely thought about the people I've come in contact with since moving from a small town to a city, where thievery and murder are common. My experience living in a city has taught me to keep more to myself.", "People I don't know or who are introduced to me.", "I tried to quickly imagine a crowd of various people of diverse backgrounds, people I know and people I don't know.", 'The general public', 'General public you’d encounter in the grocery store and things like that', 'I tried to imagine average stranger one might meet on a daily basis.', 'persons I see as I walk around the neighborhood', 'a neighbor who revealed a secret that I thought she would never tell', 'I was thinking about "most people." I was thinking very broadly, and about no one in particular. My outlook is that I think most people realize trust is necessary for social cohesion, and also desirable to participate satisfactorily in society.', 'just generic people I might run into locally', 'LMAO. Again, new students at the start of a semester. Occasionally, there is a suck up\r\n', 'Generally the people I have encountered in my life.', 'People you meet in public settings like stores.', 'It’s clear, from some people’s politics, that they are selfish and not necessarily trustworthy. Our state, however, has a higher population of educated and trustworthy people.', 'I thought again of the general public but then my mind went to my new neighborhood which is primarily a different race than myself and family yet most have been friendly and accepting of us except for a few neighbors. I want to answer "most people can be trusted" but then I feel I am naïve to chose that. So I chose "5" instead which is close to "6" but shows I am hesitating a bit.', 'Most people are mostly you meet at random times. Could be at the store or while out running errands.', 'In todays world I believe trust is earned. There are too many who are out to do harm to others to give blind trust any merit. I am thinking about anyone outside of my close circle of family and friends.', 'Really, anyone', "I think there's more divisiveness in today's society and people are generally trustworthy until they prove you wrong.", 'Family, friends, acquaintances.', 'Most people has the same connotation as everybody does it to me. Statistical proof?', 'No one came to mind.', 'Anyone', "Anyone that I've not had any dealings with.", 'strangers or acquaintances', 'citizens of the town I live in', 'The general public -- people I interact with as I go about my day.', 'Again, nobody came to mind.', 'My neighbors', 'Past employees/coworkers', 'I was thinking of neighbors, co-workers and acquaintances.', 'Someone who is honest', 'The typical person', 'A crowd of people in general.', 'New acquaintances\r\n', "People I'm close to you", 'Based on prior experiences, I would say its the friends that I have.', 'Trumpians', 'My friends', 'A friend of mine who is no longer a friend.', "Pretty much everyone who doesn't harm me. I generally trust people until I have reason not to trust them, but theft unfortunately has become somewhat endemic where I live. And people post about getting robbed, houses being broken into, etc. on Next Door, so I am very aware of this issue. It makes you more cautious.", 'most people i see daily', "People I meet in my daily activities like salespeople, other parents at my son's school, the teachers, workmen who work on my house, people in my dog training classes, etc", 'A crowded street in a metropolitan area during the middle of the day', 'It was so open it could be anyone. I mean a lot of people think Ted Bundy was a great guy.', 'humans', 'just people i know from past experiences', 'strangers', 'No one in particular', 'Tourists that come to our little village. I tend to be very wary of them.', 'The general public, co-workers, salespeople, certain family members, and acquaintances.', "someone I don't know when I am in a new situation", 'Telemarketers, many different sales people, religious fanatics, some politicians, \r\nScience non-believers', 'people I know', "Vague people, maybe at a store. Then I thought about my landlady watching my cats when I'm away. Then whether I'd trust a random person watching my cats. Then I thought about various people who code software and was reminded of the suspicious feeling I get if an app was made by Russians, so I figured one should maybe be a little more careful.", "Average person getting through life like most of us. I believe that the majority of people don't hold ill will to others. Media over emphasizes the negative", 'People in general', 'people around me on vacation', 'Most people mean people you meet on the street and can include friends and family.', 'The average person you meet on the street or at your job or while out shopping. Just any regular person you come into contact with.', 'Friends who appear to be your friends until you really need them and they aren’t there for you.', 'General strangers that I would have no prior relationship with', "again, just random people that I don't know", 'Most of the general public.', 'strangers', 'Most people.', 'Fellow students/classmates\r\n', 'People who come to my house door. People I meet through work. To a lesser degree people that come up to me in a public place and the contact doesn\'t have to do with any business we might have together and not in an obvious "Nice weather wer\'e having" demeanor.', 'coworkers', 'An average stranger', 'a friend of mine', 'strangers', 'The general public.\r\n', 'A friend came to my mind', 'most people in my professional or social circle', 'I was thinking about people who may approach me while I am outside or in a store who I do not already personally know.', 'Any stranger who you might meet on any day.', 'People that I know', 'Strangers\r\n', 'A quick survey of the thousands of people I have interacted with in my life.', 'people that I do not know currently', 'People in general\r\nMost people will stay you in a second\r\nThey take kindness as weakness', 'New employee worker.', 'My thought is there a enough bad people and those in a position that they have to lie to warrant my rating.', 'kinfolk', 'General population', 'My coworkers at work.', 'I thought of myself. Because i’m protecting myself', 'Pretty much every human being I have ever met in my life', 'No one in particular. Nothing came to my mind', 'I guess everyone in the world', "people you don't really know", 'family and friends that I have met throughout my lifetime.', "When I read 'most people' I thought of the 'general public', in terms of a whole.", 'I thought about the people in my community where I live.', 'Salespeople', 'a random man on the street', 'Just anybody I might meet.', 'My group members in school group projects and/or research.', 'Strangers you pass on a street on a regular basis.', 'No one specific', 'PEOPLE I MEET IN SOCIAL SETTINGS AND WORK PLACE SETTINGS', 'The general public. People you might meet while shopping.', 'I was talking about people that I meet when working with and how they are very trusting and understanding', "Thinking mostly of people that you are going to interact with at least a couple time - like texting people from Craigslist before they show up at your house, or an arborist who comes to work at your house and you'd be wanting to have them work regularly for you if they are trustworthy. In a more minor sense, thinking of my best friend who is alone in the world (far from me) right now and having to try to make a new set of friends and we've been talking about how to ever know if someone is trustworthy.", 'People I see at the store', 'people I worked with', 'Family, friends and average people', 'Politicians who say they are fighting for you but really aren’t.', "When answering the question, I thought about politicians. When people vote for a politician, they expect that politician to provide change. However, for some of those politicians, they don't deliver on their promises. So, in this case, some politicians can't be trusted to bring change. Therefore, not all people can be trusted too much.", 'People that I’d likely encounter, in my community but who I don’t necessarily know.', 'Most people that I have come by in my day to day life between school, shopping, and going out.', 'Car salesmen. Lawyers.', 'People that I have friendship with, and I have been friends with for years.', 'coworkers and classmates', 'Most People', "One of my old neighbors whom I'd known for 16 years turned out to be a very selfish, self-centered person. We weren't friends, but I was nevertheless shocked because this person had, until that point, led people to believe they were trustworthy.", 'People that I interact with in the normal course of events.', 'Average people like me.', 'Other Americans in my neighborhood, city, and region.', 'I was thinking about my father. \r\n', 'No one in particular.', 'People in a public space such as a mall', 'Other people I see living life around me. Like neighbors, people working at stores around me.', 'Human society in general.', 'Parents at the playground', 'No one, in particular, just thinking of a crowd of random people.', 'General public', 'The general population - no particular distinct group', 'No one in particular came to mind.', 'People that live near me', 'Friend. She does things for you but there is always a payback, big time payback.', "Generally everyone across the board all my coworkers friends family but I mainly was going on all the people I don't know and I don't trust anyone till I have met them and I can't totally distrust everyone with out getting to know them I leave my guard up until I get to know them before I trust them or not but at first meet I don't totally trust anyone until I get to know them.", 'I did not think of anyone in particular so much as the general attitude I take towards the general public.', 'people I have encountered in my life', 'My friends', 'Bad guys.', "When thinking of most people I think of people I might have to come into contact with for house repairs or to rent an apartment. I also feel this way with new coworkers or fellow passengers on public transport. It is a good rule of thumb to not trust salespeople or people who provide services such as taxi drivers or delivery people. It's good to not really trust strangers at all.", 'People around me all is trustable.', 'People that you casually know.', 'my coworkers', "I thought of all the people in my community and in my country as a whole, including people whom I'm close to, people I don't know, and people I don't like very much.", 'co-workers', 'A friend', 'Old friends and family members who have betrayed me.', 'Unknown people', 'The people I interact with', 'I was thinking about people you interact with at situations like the post office or at a store.', 'Strangers that I have an interaction with.', 'Robbers', 'General population will do the right thing most of the time. I do feel more of the younger folks have a sliding scale on who gets taken advantage of and when.', "People in general. I thought about strangers I've met and figures I know in the public sphere.", "Anyone. I don't care if it's a mother with children. I don't care if it's just children. You never know who anyone really is. You don't know about plans they may have, or their pasts. You don't know what's going on in their heads. You can't be too careful, especially now days.", 'pretty much the same - just a small group of adults at a business networking function', 'EMPLOYER', "everyone that I don't know personally", 'People from my same hometown.', 'Sales people, store clerks, receptionists, people I meet online.', 'Friends or peers', 'What came to mind was no one, I generalized my experience with most people I have had. I thought of all the times people proved to be way different than they initially came off.', 'Strangers and acquaintances', 'People in my neighborhood.', 'The average person I would encounter, generally in the middle class range, full time employed, ages 25-60.', 'People from previous friendships.', 'My ex girlfriend came to my mind', 'My spouse', 'friends', 'friends', "People in general. I don't trust people I don't know well.", 'Stranger', 'The same person as before', 'The encounter I had with people in recent times has made me know that there are only few people around you who you can count on.', 'Random strangers.. outside, shopping, etc', 'Again, no one specifically.', 'might be impersonator', 'I think there is a good balance between trustworthy people and people who will take advantage of you. However, I do think if you are more of a trusting, giving person the opposite kind of people can be attracted to you. So it can make it seem as though there are more of those kind of people.', "Most people can't be trusted because people have different thoughts to one another. Some people wants the other people to succeed while some people want the other people to fail or harm them", 'The man that assualted my son when my son stopped his car to help a disabled older man who had already been assaulted.', 'People in general. People outside your immediate social circle', 'Americans', 'My neighbour', 'I would only consider myself "close" to a small subset of people I know and am acquainted with. In my head, that pretty much means I am "not close" to "most people" if that makes any sense. So I would consider your casual acquaintances, co-workers you only vaguely know outside of work, people I only know on the internet as "most people."', 'men and women of all races\r\n', 'The general population.', "People in general. Didn't matter who, just walking down the street. Just... people.", 'A co worker. On average time he has remained trusted, both at work and out of work.', 'good', 'anyone out and about on a normal day', 'A person I met a week ago', 'Cunny people', 'Random strangers', 'Anyone I meet for the first time.', 'White people, mostly white men.', 'The average person I see every day on the bus or train', 'challenge and success', 'People with good intentions', 'someone in an emergency situation', 'Strangers that you have never met before.', "Most people just ignore you or don't want anything to do with you anyway,, when I think of most people I think of people gathered around just kind of doing there own thing", 'Merciful', 'Kids I grew up with, some of which I still interact with on Facebook.', 'Very honestly and helpful', 'neighbors, friends, coworkers', 'The average person that I have met in my life. Mostly poor folks with addictions and low education.', "People that you do not know, by definition is everybody in the world that you don't know. Some people in this category would be perfectly trust worthy while others are vile deceitful people. The mass majority are neither crooked nor trustable.", 'I thought of people in my neighborhood.', 'Nobody in particular.', 'Anybody you meet', 'people in my town', "NOBODY IN PARTICULAR came to mind. I don't understand your continual harping on WHO? WHO? WHO? I want to know a person before trusting my life or my loved ones to that person.", 'Anyone, no one or no group in particular', 'Gnereal public', 'Others may have more trust than I do. It takes a lot for me to trust others because they blow with the winds of opportunity, in most cases.', 'Just general people that you see or run into during your day.', 'No one in particular,', "People I've met and had some interaction with.", 'A crowd of people came to mind. No one in particular. A mix of female and males. All ages. In a stadium setting!', 'People of my current society in which I live.', 'I thought about criminals', 'Businessmen, politicans', 'Politicians and business people.', 'I did not get a clear picture of any one face; just generally other Americans.', 'No one.', 'I was thinking of caucasian people.', 'Nobody, I quite honestly don\'t understand why this is even asked. Why would I think of "somebody" or particular person, in a question that asks me if I would trust somebody I meet for the first time??', "The average person you might meet on the street. I'd say the odds are 50/50 that they're honest or dishonest.", 'The types of people that I interact with daily which would be people I meet in stores or while engaging with my hobbies (gaming). These are people typically around the age of 18-35, mostly men.', 'the general population', 'my friends and acquaintances', "People that I know causally that I don't know very well", 'Most people', 'a generalized version of a person, no one in particular.', 'Any stranger', 'Someone I have never met before', 'I was thinking about when I was hiking and passed the person on a trail.', 'A group of generic people, no one in particular. I thought of them as neighbors.', 'Most people that I have met in my lifetime', 'The majority of people in my life who have proven themselves untrustworthy at some point or another.', 'Random people who I do not know at all. Not related to any community that I am a part of like a church or school or anything.', 'no one', 'general public', 'In particular, the people who came to mind were those who appeared to be friendly and reliable in the beginning, but whose actions subsequently proved them to be untrustworthy.', 'I was thinking about people you would encounter is casual settings such as in your neighborhood or in local businesses.', "Everyone who I've ever met for the first time I keep at arm's length.", 'HOmeless person', "I think the average person doesn't have any ill intent.", 'Majority of people in a small town.', 'I was thinking about people who might have mental issues.', "Most people I have dealt with in my life can be trusted. So I just kind of thought of everybody I've ever known. I didn't have many 'untrustworthy' people come to mind. So that means to me that most people can be trusted.", 'friends and family', 'I didn’t have a specific individual in mind. \r\nI’m going off the belief that everyone is out only for themselves.', 'A crowd of anonymous people.', 'The general population', 'anyone NOT in a professional setting or qualified position unless you really know the person and are invested in them', 'on-line people', '\nDonald Trump and clan', '"Most people" are people who are telling me a story about why I should give them $2 in a parking lot. I don\'t trust them at all to be telling the truth.', "People who don't agree with my politics/philosophy of life.", 'People in general.', 'An ill-defined group of people. Probably Americans (my own country). No one specific. I just imagined a large group and wondered how many I could trust.', "When it comes to people that I don't know or had very few interactions with, I feel like I can hardly trust them.", 'general public', "This is such a general question that it's not easy to give a proper answer.", 'No one in particular', 'people in my neighborhood', 'Random person on the street', 'People who can impact my life', 'I think about any male or female that I met would not be interested in harming me. I would try to strike up a conversation just to be courteous. Most people would be adults.', 'Someone who betrayed my trust very badly.', 'neighbors I just meet', "People in general, strangers I don't know", 'Just the general public you encounter day to day in your daily routine.', 'Nobody', 'People who are friends of friends.', 'People in general, that I may have as aquaintences.', "I am getting so annoyed that I forgot the last question. And since you didn't design this survey so that I could go back, I can't give you an answer.", 'An average male', 'Random strangers on the street', 'i think, no I believe that most people are good and trustworthy', 'the average person ? stranger', 'Most everyone you meet on the street.', 'People I dont have a close personal relationship with', 'Anyone that I could meet in the United States', 'most unfamiliar people outside', 'In general, I was thinking of my circle of friends and how I felt when I first met them.', 'No one in particular.', 'Nobody, really -- just that people in general are trustworthy with notable == 15% == exceptions.', "Please see my previous responses. I don't think anyone can come to mind when we have yet to meet them.", 'My landscaper', "Just people that you meet each day. If you don't have some trust in people, you would end up being paranoid.\r\n\r\n", 'Most people are just people in general....complete strangers.', 'I was thinking about people who voted for Donald Truro twice, and that’s a significant number of adult Americans.', 'No one in particular', 'in my time the trust of strangers has decreased over time this is in general', 'The people that are in my neighborhood, and the surrounding area.', 'I guess because I live in a city were the population is more dense, the chance of dealing with a wider spectrum of people increases. I can see most encounters would be of a kind person with good intentions, so just about anyone would and could be kind.', 'No one', 'I was just thinking about people in general, not necessarily anyone specific.', 'Strangers or someone who I barely know', 'Brother', 'people with bad intentions', 'All different kinds of people - young to old, male and female.', 'Random person', 'My friends and neighbors.', 'General population of america', 'all sorts of people in general', 'I pictured the population in my metropolitan area, country and world', 'the people I work with on temporary work assignments.', 'those I meet in my everyday ativities', "I'm thinking about people in general in terms of doing what they'll say", 'General population.', 'Straight, Religious, Masculine, White American Males', 'No one in particular.', 'city folk', 'The general American population.', 'Generic people, men and women of varying ages.', 'I thought of customers at my previous workplace, and my coworkers, and my friends and their family. Nobody in particular.', 'Anyone I run into on a street, in a store, etc.', 'Everyone to ever exist.', 'A person with a smile on their face and is willing to shake your hand and carry on a conversation', 'A stranger on the street', 'I thought about the average person I deal with when I go to grocery stores or run errands.', 'My friends and coworkers', 'Ordinary, well-meaning civilians.', 'the general population', 'My neighbors, and others in my neighborhood who shop at the same grocery store.', 'People who I encounter daily but never interact with', 'the community i am living in and the secondary education community', 'Humans.', 'No one in particular', 'A friend of a friend, I don’t generally trust strangers', 'My sister', 'Friends, family, acquaintances, strangers', 'Well, most people. Not just my friends, neighbors, and family, but people in general.', 'no one in particular', "Dude. You said think about strangers. I'm STILL thinking about strangers.", "Most people to me means most strangers or people you've never met before", 'Just people in general', 'in general in society/community', 'Most of the people in the world.', 'everyone', 'Friendly women in the grocery stores', 'People you meet when you visit stores', 'strangers', 'Just a stranger from the street', 'Anyone with whom I have no history and they have not proved to me they are trustworthy.', 'Nobody in particular came to my mind. I pictured a group of faceless people in a room and I was becoming acquainted with them.', 'just a stranger in general', 'Just the everyday kind of person you always meet.', "People you don't know.", 'People you meet at stores and places you would go on a day to day basis.', 'Most people that I am acquainted with in public areas.', 'general public', 'random strangers', 'people i meet at the bar', "In general people I don't think they are all evil", 'People I know, everyone is a stranger when you first meet.', 'a random bunch of people', "Acquaintances that I don't know that well, as well as complete strangers that I do not know at all.", "Any of the people I'm introduced to on a daily basis, usually friends of people I already know. On average, they're most often women in their 30's or 40's.", 'OMG', 'The general population and more so religious individuals', '\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nthe population that lives in the US', "I was thinking about people I go to church with, members of my children's school", 'Everybody I know', 'no one in particular', "the people i've met", 'General strangers - typically men, however.', 'Just average people you know', 'most people', 'People I see in the store while shopping.', 'I think most people are the people who the people who I interact with interact with. They are people that I they are people that I work with or people that I people that I worship with or people that I May exercise with from time to time period They could also be one of my family members one of my family members or close friends.', 'Strangers in general.', "I guess the average American - white, middle class, neurotypical, straight. I have had a lot of traumatic experiences at the hands of other people so it's pretty rare for me to trust anyone.", "People that aren't really close friends/family", 'Old friends, people I used to talk to', 'Everyone else on Earth', "People in general - those in my city, people I'd see on the subway or in a restaurant.", "The people I encounter daily. Although I do trust most people, I would be careful having someone I don't know watching my loved ones or house.", 'Everybody, but was imagining the subway station and people with children.', 'People at work.', 'No one.', 'ex girlfriend', 'People like who are out in the streets living their lives', 'A group of people waiting in line to pay at the supermarket', 'Friends, family', 'Someone that I have never seen or met before.', 'anyone that has not been introduced to me by someone else i KNOW', 'I pictured people in the general population.', 'no one', 'I mainly thought of people my friends introduced me to', 'I was thinking about myself. I would like to think that I am trustworthy.', 'no one in particular\r\n', 'Everyone', 'My friends and acquittance', 'A group of people of varying ages, races and genders.', 'People in my neighborhood', 'I was thinking about all the people you would see at a crowded airport or sports stadium.', 'random people', 'Just people that mutual friends know', 'People I have met through work and high school', 'Most people can be trusted until proven untrustworthy.', 'A group of both men and women of all ages and ethnicities.', 'Again meeting new employees at my job', 'Strangers and criminals.', 'people i might interact with outside the house in public', 'i dont trust anyone too much stuff has happened to me', 'Most people would be people in general.', 'Most people that I know or have met before.', 'Coworkers, people you see while out, anyone i dont know closely.', 'People that I have known throughout my life.', 'NO ONE', 'I thought about neighbors or people at work that I know a little bit, but not deeply.', 'Some good and bad peoples.', 'random people in a place of business you visit', 'sex trafficers', 'No one in particular, just people as a whole', 'No specific person came to mind. Just a crowd of people in different colored shirts.', 'No one', 'people in class', "acquaintances I see on occasion but don't hang out with much", 'A man in casual clothing.', 'Noone in particular', 'No one particular, perhaps a co-worker', 'no one specific, just most people', "The journalist can be seen in this scenario. You hardly trust them with information so they don't publish fake news about you.", 'people in my village', 'people I have met throughout my life', 'The general public. People you see in the grocery store or while running errands.', "neighbors I haven't met", 'The general public', 'A mixture of people I had imagined for the past few questions came to mind, but in particular I was thinking of a mixture of people in grocery stores and people on university campuses.', 'we should trust most people but not absolute.', 'I was solely thinking about random people you meet in the course of your day.', 'just general every day people, like the various folks I see when out and about on a usual day', 'No one in particular, but mostly people much older.', 'Strangers I meet while outside walking', 'americans', 'I thought of people that I see at my gym. Although I see them every day, I do not necessarily trust them \r\n', 'The general population that I meet on a day to day basis.', 'The average girl or guy I see on the street and smile when I take my dog out for walks', 'Random people consuming alcohol at my job', 'No one', 'People at my college campus', 'Everyone is a stranger at first, the ones that become friends are the ones that have shown they are trustworthy.', 'Those people that you would come into contact while commuting, shopping, working, etc., that are not known to you previous to you meeting them for the first time.', 'My mother', 'I was thinking about everyone I know.', 'Noone', 'I remembered my fast college friend', 'Friends', 'A lady', 'At times I hardly trust strangers', 'Everyone i know', 'Someone I met a gym for the first time.', 'People in general, family, friends, and strangers.', 'No one.', 'General people around', 'My frinds', 'A mutual friend', 'answering the question', 'Stranger', 'a stranger', 'Again, the people that I meet through social settings. I believe in like vibration. I attract to me those who are like me for the most part.', 'Some of my in-laws, specifically my mother in law and sister in law.', 'I was thinking more generally about the population at large, not any demographic in particular', 'Salesman', 'my romantic partner', 'General people that you do not know that you may meet out and about when going to the store.', 'Everyone', 'In this scenario, I was thinking about average Americans as a whole. I understand that there is a large world outside our country, but Americans are the people that I--by and large--deal with. So, I thought of "most people" as "most of the American population."', 'A stranger', 'People in the neigbourhood', 'Most peoe can be trusted especially to carry out a particular work or job', 'Everyone', 'No one', 'Over negligence sometimes kills so you have to be wise in your dealings', 'the person who ripped off my father at the airport', 'office colleague, neighbors', 'Generally', 'rightly done', 'The general human population\r\n', 'My coursemate', 'i met a man yesterday', 'Dora in actually the person that came to my mind', 'A colleague at work', 'An ex school mate.', 'Those people at my gym, or in the neighborhood.\r\n', "I Don't automatically trust anyone until they've had a chance to prove themselves", 'General population. A woman, a man. Sort of generic, but put together (dressed in clean clothes, etc.).', 'Some people in the world around us can have the opportunity to be trusted early, but some have to acquire the benefit of the doubt.\r\n\r\nStart a friendship with a other person, trust can be built not handed over', 'A football fan', 'A man that lived across the road from us and from the way he treated his mother and he did not work regularly. I decided he could not be trusted', 'people in general?', 'People I haven’t seen before, or talk before, not friends or family members']Below, we define various parameters for training our model using the Hugging Face Transformers library. We set parameters such as the batch size, number of training epochs, learning rate, weight decay, evaluation strategy, and logging settings. These parameters control how the model is trained, including how data is batched, how often training metrics are logged, and how evaluation is performed. These parameters play a crucial role in determining the performance and efficiency of the training process.
# Parameters for the model
# Importing the TrainingArguments class from the transformers module
from transformers import TrainingArguments
# Setting parameters for training
batch_size = 16 # Batch size for training
logging_steps = len(data_encoded["train"]) // batch_size # Calculate the number of logging steps
model_name = "distilbert-base-cased-finetuned-data" # Name for the fine-tuned model
# Creating an instance of TrainingArguments with specified parameters
training_args = TrainingArguments(
output_dir=model_name, # Output directory for model checkpoints and logs
num_train_epochs=2, # Number of training epochs
learning_rate=2e-5, # Learning rate for training
per_device_train_batch_size=batch_size, # Batch size per device for training
per_device_eval_batch_size=batch_size, # Batch size per device for evaluation
weight_decay=0.01, # Weight decay parameter for regularization
evaluation_strategy="epoch", # Evaluation strategy ("epoch" evaluates at the end of each epoch)
disable_tqdm=False, # Whether to disable tqdm progress bars during training
logging_steps=logging_steps, # Number of steps before logging training metrics
log_level="error", # Logging level for training
optim='adamw_torch' # Optimizer used for training (AdamW with PyTorch backend),
)
exitUse exit() or Ctrl-Z plus Return to exitThis code segment trains a model using the Hugging Face Transformers library. It initializes a trainer object with the specified model, training arguments, dataset splits (training and validation), and tokenizer. The model is then trained using the train() method. After training, the trained model is saved using the save_model() method. Evaluation of the trained model on the validation dataset is performed using the evaluate() method to assess training and validation accuracy. Finally, predictions are generated on the test dataset data_encoded['test'] using the predict() method, and both predicted classes and true labels are extracted for further analysis.
# Model training
# Import the Trainer class from the transformers library
from transformers import Trainer
# Initialize the Trainer with the specified parameters
trainer = Trainer(model=model, # Specify the model to be trained
args=training_args, # Specify training arguments
compute_metrics=get_accuracy, # Specify function to compute metrics
train_dataset=data_encoded["train"], # Specify training dataset
eval_dataset=data_encoded["validation"], # Specify validation dataset
tokenizer=tokenizer) # Specify tokenizer
# Train the model
trainer.train(){'loss': 0.5934, 'grad_norm': 2.404886245727539, 'learning_rate': 1e-05, 'epoch': 1.0}
{'eval_loss': 0.5056819319725037, 'eval_accuracy': 0.7447916666666666, 'eval_runtime': 9.8507, 'eval_samples_per_second': 19.491, 'eval_steps_per_second': 1.218, 'epoch': 1.0}
{'loss': 0.4141, 'grad_norm': 3.851449489593506, 'learning_rate': 0.0, 'epoch': 2.0}
{'eval_loss': 0.3936673104763031, 'eval_accuracy': 0.828125, 'eval_runtime': 9.96, 'eval_samples_per_second': 19.277, 'eval_steps_per_second': 1.205, 'epoch': 2.0}
{'train_runtime': 276.5441, 'train_samples_per_second': 4.166, 'train_steps_per_second': 0.26, 'train_loss': 0.5037513176600138, 'epoch': 2.0}
TrainOutput(global_step=72, training_loss=0.5037513176600138, metrics={'train_runtime': 276.5441, 'train_samples_per_second': 4.166, 'train_steps_per_second': 0.26, 'train_loss': 0.5037513176600138, 'epoch': 2.0})
0%| | 0/72 [00:00<?, ?it/s]
1%|1 | 1/72 [00:03<04:34, 3.87s/it]
3%|2 | 2/72 [00:07<04:37, 3.97s/it]
4%|4 | 3/72 [00:11<04:34, 3.98s/it]
6%|5 | 4/72 [00:15<04:29, 3.97s/it]
7%|6 | 5/72 [00:19<04:27, 3.99s/it]
8%|8 | 6/72 [00:24<04:26, 4.04s/it]
10%|9 | 7/72 [00:27<04:19, 3.99s/it]
11%|#1 | 8/72 [00:31<04:15, 3.99s/it]
12%|#2 | 9/72 [00:35<04:12, 4.01s/it]
14%|#3 | 10/72 [00:39<04:03, 3.92s/it]
15%|#5 | 11/72 [00:43<03:55, 3.86s/it]
17%|#6 | 12/72 [00:47<03:49, 3.82s/it]
18%|#8 | 13/72 [00:50<03:43, 3.79s/it]
19%|#9 | 14/72 [00:54<03:39, 3.78s/it]
21%|## | 15/72 [00:58<03:34, 3.76s/it]
22%|##2 | 16/72 [01:02<03:33, 3.82s/it]
24%|##3 | 17/72 [01:06<03:31, 3.84s/it]
25%|##5 | 18/72 [01:09<03:27, 3.84s/it]
26%|##6 | 19/72 [01:13<03:23, 3.85s/it]
28%|##7 | 20/72 [01:17<03:18, 3.82s/it]
29%|##9 | 21/72 [01:21<03:14, 3.82s/it]
31%|### | 22/72 [01:25<03:12, 3.85s/it]
32%|###1 | 23/72 [01:29<03:10, 3.88s/it]
33%|###3 | 24/72 [01:33<03:04, 3.84s/it]
35%|###4 | 25/72 [01:37<03:04, 3.92s/it]
36%|###6 | 26/72 [01:41<03:12, 4.19s/it]
38%|###7 | 27/72 [01:46<03:08, 4.20s/it]
39%|###8 | 28/72 [01:49<02:55, 3.99s/it]
40%|#### | 29/72 [01:53<02:43, 3.81s/it]
42%|####1 | 30/72 [01:56<02:35, 3.70s/it]
43%|####3 | 31/72 [02:00<02:29, 3.64s/it]
44%|####4 | 32/72 [02:03<02:22, 3.55s/it]
46%|####5 | 33/72 [02:06<02:14, 3.45s/it]
47%|####7 | 34/72 [02:10<02:12, 3.48s/it]
49%|####8 | 35/72 [02:13<02:08, 3.47s/it]
50%|##### | 36/72 [02:16<02:02, 3.42s/it]
50%|##### | 36/72 [02:16<02:02, 3.42s/it]
0%| | 0/12 [00:00<?, ?it/s][A
17%|#6 | 2/12 [00:00<00:04, 2.49it/s][A
25%|##5 | 3/12 [00:01<00:05, 1.77it/s][A
33%|###3 | 4/12 [00:02<00:05, 1.48it/s][A
42%|####1 | 5/12 [00:03<00:05, 1.39it/s][A
50%|##### | 6/12 [00:04<00:04, 1.32it/s][A
58%|#####8 | 7/12 [00:04<00:03, 1.28it/s][A
67%|######6 | 8/12 [00:05<00:03, 1.25it/s][A
75%|#######5 | 9/12 [00:06<00:02, 1.25it/s][A
83%|########3 | 10/12 [00:07<00:01, 1.23it/s][A
92%|#########1| 11/12 [00:08<00:00, 1.22it/s][A
100%|##########| 12/12 [00:09<00:00, 1.24it/s][A
[A
50%|##### | 36/72 [02:26<02:02, 3.42s/it]
100%|##########| 12/12 [00:09<00:00, 1.24it/s][A
[A
51%|#####1 | 37/72 [02:30<03:42, 6.37s/it]
53%|#####2 | 38/72 [02:33<03:06, 5.50s/it]
54%|#####4 | 39/72 [02:37<02:41, 4.89s/it]
56%|#####5 | 40/72 [02:40<02:21, 4.43s/it]
57%|#####6 | 41/72 [02:43<02:06, 4.08s/it]
58%|#####8 | 42/72 [02:46<01:55, 3.84s/it]
60%|#####9 | 43/72 [02:50<01:47, 3.70s/it]
61%|######1 | 44/72 [02:53<01:40, 3.59s/it]
62%|######2 | 45/72 [02:57<01:34, 3.52s/it]
64%|######3 | 46/72 [03:00<01:29, 3.43s/it]
65%|######5 | 47/72 [03:03<01:26, 3.47s/it]
67%|######6 | 48/72 [03:07<01:22, 3.42s/it]
68%|######8 | 49/72 [03:10<01:18, 3.39s/it]
69%|######9 | 50/72 [03:13<01:14, 3.38s/it]
71%|####### | 51/72 [03:17<01:10, 3.37s/it]
72%|#######2 | 52/72 [03:20<01:07, 3.36s/it]
74%|#######3 | 53/72 [03:23<01:03, 3.36s/it]
75%|#######5 | 54/72 [03:27<01:00, 3.34s/it]
76%|#######6 | 55/72 [03:30<00:56, 3.35s/it]
78%|#######7 | 56/72 [03:33<00:54, 3.40s/it]
79%|#######9 | 57/72 [03:37<00:50, 3.36s/it]
81%|######## | 58/72 [03:40<00:46, 3.34s/it]
82%|########1 | 59/72 [03:43<00:43, 3.33s/it]
83%|########3 | 60/72 [03:47<00:39, 3.32s/it]
85%|########4 | 61/72 [03:50<00:36, 3.30s/it]
86%|########6 | 62/72 [03:53<00:32, 3.30s/it]
88%|########7 | 63/72 [03:56<00:29, 3.27s/it]
89%|########8 | 64/72 [04:00<00:26, 3.26s/it]
90%|######### | 65/72 [04:03<00:22, 3.28s/it]
92%|#########1| 66/72 [04:06<00:19, 3.30s/it]
93%|#########3| 67/72 [04:10<00:16, 3.29s/it]
94%|#########4| 68/72 [04:13<00:13, 3.27s/it]
96%|#########5| 69/72 [04:16<00:09, 3.28s/it]
97%|#########7| 70/72 [04:20<00:06, 3.32s/it]
99%|#########8| 71/72 [04:23<00:03, 3.28s/it]
100%|##########| 72/72 [04:26<00:00, 3.30s/it]
100%|##########| 72/72 [04:26<00:00, 3.30s/it]
0%| | 0/12 [00:00<?, ?it/s][A
17%|#6 | 2/12 [00:00<00:04, 2.41it/s][A
25%|##5 | 3/12 [00:01<00:05, 1.69it/s][A
33%|###3 | 4/12 [00:02<00:05, 1.48it/s][A
42%|####1 | 5/12 [00:03<00:05, 1.36it/s][A
50%|##### | 6/12 [00:04<00:04, 1.32it/s][A
58%|#####8 | 7/12 [00:04<00:03, 1.28it/s][A
67%|######6 | 8/12 [00:05<00:03, 1.27it/s][A
75%|#######5 | 9/12 [00:06<00:02, 1.23it/s][A
83%|########3 | 10/12 [00:07<00:01, 1.23it/s][A
92%|#########1| 11/12 [00:08<00:00, 1.22it/s][A
100%|##########| 12/12 [00:09<00:00, 1.24it/s][A
[A
100%|##########| 72/72 [04:36<00:00, 3.30s/it]
100%|##########| 12/12 [00:09<00:00, 1.24it/s][A
[A
100%|##########| 72/72 [04:36<00:00, 3.30s/it]
100%|##########| 72/72 [04:36<00:00, 3.84s/it]## Save the model
# Save the trained model
trainer.save_model()
## Training and validation accuracy
# Evaluate the model on the validation dataset and print training and validation accuracy
trainer.evaluate(){'eval_loss': 0.3936673104763031, 'eval_accuracy': 0.828125, 'eval_runtime': 9.9281, 'eval_samples_per_second': 19.339, 'eval_steps_per_second': 1.209, 'epoch': 2.0}
0%| | 0/12 [00:00<?, ?it/s]
17%|#6 | 2/12 [00:00<00:04, 2.07it/s]
25%|##5 | 3/12 [00:01<00:05, 1.55it/s]
33%|###3 | 4/12 [00:02<00:05, 1.41it/s]
42%|####1 | 5/12 [00:03<00:05, 1.35it/s]
50%|##### | 6/12 [00:04<00:04, 1.31it/s]
58%|#####8 | 7/12 [00:05<00:03, 1.26it/s]
67%|######6 | 8/12 [00:05<00:03, 1.27it/s]
75%|#######5 | 9/12 [00:06<00:02, 1.28it/s]
83%|########3 | 10/12 [00:07<00:01, 1.26it/s]
92%|#########1| 11/12 [00:08<00:00, 1.24it/s]
100%|##########| 12/12 [00:09<00:00, 1.24it/s]
100%|##########| 12/12 [00:09<00:00, 1.32it/s]## Get the predictions
# Get predictions on the test dataset
preds = trainer.predict(data_encoded['test'])
0%| | 0/13 [00:00<?, ?it/s]
15%|#5 | 2/13 [00:01<00:07, 1.38it/s]
23%|##3 | 3/13 [00:02<00:10, 1.04s/it]
31%|### | 4/13 [00:04<00:10, 1.20s/it]
38%|###8 | 5/13 [00:05<00:10, 1.29s/it]
46%|####6 | 6/13 [00:07<00:09, 1.35s/it]
54%|#####3 | 7/13 [00:08<00:08, 1.44s/it]
62%|######1 | 8/13 [00:10<00:07, 1.48s/it]
69%|######9 | 9/13 [00:12<00:05, 1.50s/it]
77%|#######6 | 10/13 [00:13<00:04, 1.56s/it]
85%|########4 | 11/13 [00:15<00:03, 1.62s/it]
92%|#########2| 12/13 [00:17<00:01, 1.60s/it]
100%|##########| 13/13 [00:17<00:00, 1.16s/it]
100%|##########| 13/13 [00:17<00:00, 1.32s/it]# Extract predicted classes
pred_class = preds.predictions.argmax(axis=-1)
# Extract true labels
label = preds.label_ids
exitUse exit() or Ctrl-Z plus Return to exitIn this code snippet, a tibble dataframe named prediction is created, which contains two columns: pred_class representing the predicted classes (converted to factors), and label representing the true labels (also converted to factors). Subsequently, the metrics function is called, which computes various model evaluation metrics. In this instance, it computes the accuracy metric by comparing the predicted classes with the true labels from the prediction dataframe.
# Computing different model metrics
# Create a tibble dataframe containing predicted classes and labels, converting them to factors
prediction <- tibble(
pred_class = as_factor(py$pred_class),
label = as_factor(py$label)
)
# Compute accuracy metric using the `metrics` function, passing in the prediction dataframe along with the label and predicted class columns
# The `metrics` function calculates various metrics such as accuracy, precision, recall, etc.
# In this case, it computes accuracy by comparing the predicted classes with the true labels
metrics(prediction, label, pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.855
2 kap binary 0.635In summary, this code calculates the confusion matrix using the true labels and predicted class labels from the prediction data frame, and then generates a heatmap visualization of the confusion matrix using ggplot2. This visualization helps to understand the performance of a classification model by showing how often each class is misclassified as another.
# Confusion matrix
# Calculate the confusion matrix using the conf_mat() function from the 'yardstick' package.
# This function takes two arguments: 'label' which represents the true labels and 'pred_class' which represents the predicted class labels.
# The '%>%' operator pipes the 'prediction' data frame into the conf_mat() function.
# Then, the resulting confusion matrix is piped into the autoplot() function from the 'ggplot2' package to visualize it as a heatmap.
prediction %>%
conf_mat(label, pred_class) %>%
autoplot(type = "heatmap")
In summary, this code snippet initializes a text classification pipeline using a pre-trained model specified by model_name. It then utilizes this pipeline to classify a sample text, 'This is not my idea of fun', and stores the result. The result would typically include the predicted label and the associated confidence score or probability, depending on the specific classifier used.
# Importing the required library
from transformers import pipeline
# Initializing a text classification pipeline with the specified model
# 'model_name' should be replaced with the name of the pre-trained model to be used
# This could be a model trained for text classification tasks like sentiment analysis,
# or any other similar task supported by the Hugging Face Transformers library
classifier = pipeline('text-classification', model=model_name)
# Using the initialized pipeline to classify a sample text
# The text provided as an argument ('This is not my idea of fun') will be passed to the classifier,
# which will assign it a label based on the model's predictions
result = classifier('This is not my idea of fun')The code below classifier('This was beyond incredible') performs text classification using the classifier pipeline initialized earlier.
13 Labelling data: How to create a training dataset
First, we would load the full dataset that contains the texts. Below we have a dataset with tweets that we classify.
# Import data
data <- read_csv("www/data/data_tweets_de.csv",
col_types = cols(.default = "c")) %>% # Make sure to read in columns as character (otherwise you will get problem with long numbers) %>%
select(text) %>% # drop irrelevant variables
mutate(text_id = row_number()) # Add unique identifier
# Store data with ID
# Don't change data so that ID does not get lost
write_excel_csv(data, "www/data/data_tweets_de_id.csv") # Store data with ID
# Load data
set.seed(100) # set seed for random select
data_for_coding <- read_csv("www/data/data_tweets_de_id.csv",
col_types = cols(.default = "c")) %>%
sample_n(size = nrow(.)) %>% # Randomly reorder rows
slice(1:1000) # Take the first 1000 observations as an example
# Why would we randomly reorder rows?Then we store the data locally in an excel file. Make sure that any data you export or import always contains a unique classifier (we created one above called text_id). Use delim = ';#;' or something special as delimiter that is unique and does not appear in the text (excel seems to recognize a unique delimiter).
We open the excel file and save it under another name (to make sure it’s not overwritten again), e.g., data_for_coding_paul.csv if the person who codes the sample is called Paul.
In this new excel file we create a variable called human_classified (or any other name) and label as many observations as possible following our coding scheme.
Then we import the data file the contains the labeled outcome stored in human_classified.
And we can check how many we have classified (here I classified only few observations). And we would also merge the data with the original data.
0 1 <NA>
17 11 972 After that we would basically proceed as described in the lab above. If you don’t want to export the full dataset for manual labeling chose a subset and join the datasets again later (just make sure you have a unique identifier for joining). Make sure to check whether the process is sound and does not overwrite anything.
Besides, it may make sense to label with several persons (intercoder reliability) and discuss tricky cases and code them together.
References
Grimmer, Justin, and Brandon M Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Polit. Anal. 21 (3): 267–97.
Silge, Julia. 2017. Text Mining with r : A Tidy Approach. First edition. Beijing, China.
Wilkerson, John, and Andreu Casas. 2017. “Large-Scale Computerized Text Analysis in Political Science: Opportunities and Challenges.” Annu. Rev. Polit. Sci. 20 (1): 529–44.
Footnotes
Document-term matrix (DTM) is a mathematical representation of text data where rows correspond to documents in the corpus, and columns correspond to terms (words or phrases). DFM, also known as a document-feature matrix, is similar to a DTM but instead of representing the count of terms in each document, it represents the presence or absence of terms.↩︎