| id | name | compas_screening_date | is_recid | is_recid_factor | age | priors_count |
|---|---|---|---|---|---|---|
| 1 | miguel hernandez | 2013-08-14 | 0 | no | 69 | 0 |
| 3 | kevon dixon | 2013-01-27 | 1 | yes | 34 | 0 |
| 4 | ed philo | 2013-04-14 | 1 | yes | 24 | 4 |
| 5 | marcu brown | 2013-01-13 | 0 | no | 23 | 1 |
| 6 | bouthy pierrelouis | 2013-03-26 | 0 | no | 43 | 2 |
| 7 | marsha miles | 2013-11-30 | 0 | no | 44 | 0 |
| 8 | edward riddle | 2014-02-19 | 1 | yes | 41 | 14 |
| 9 | steven stewart | 2013-08-30 | NA | NA | 43 | 3 |
| 10 | elizabeth thieme | 2014-03-16 | 0 | no | 39 | 0 |
| 13 | bo bradac | 2013-11-04 | 1 | yes | 21 | 1 |
Classification: Logistic model
Learning outcomes/objective: Learn…
- …and repeat logic underlying logistic model.
- …how to assess accuracy in classification (logistic regression).
- …concepts (training dataset etc.) using a “simple example”.
1 Predicting Recidvism: The data
Table 1 depicts the first rows/columns of the dataset (COMPAS) we use.
2 Predicting Recidvism: Background story
- Background story by ProPublica: Machine Bias
- Methodology: How We Analyzed the COMPAS Recidivism Algorithm
- Replication and extension by Dressel and Farid (2018): The Accuracy, Fairness, and Limits of Predicting Recidivism
- Abstract: “Algorithms for predicting recidivism are commonly used to assess a criminal defendant’s likelihood of committing a crime. […] used in pretrial, parole, and sentencing decisions. […] We show, however, that the widely used commercial risk assessment software COMPAS is no more accurate or fair than predictions made by people with little or no criminal justice expertise. In addition, despite COMPAS’s collection of 137 features, the same accuracy can be achieved with a simple linear classifier with only two features.”
- Very nice lab by Lee, Du, and Guerzhoy (2020): Auditing the COMPAS Score: Predictive Modeling and Algorithmic Fairness
- We will work with the corresponding data and use it to grasp various concepts underlying statistical/machine learning
3 Logistic model
3.1 Logistic model: Equation (1)
- Predicting recidivism (0/1): How should we model the relationship between \(Pr(Y=1|X)=p(X)\) and \(X\)?
- See Figure 1 below
- Use either linear probability model or logistic regression
- Linear probability model: \(p(X)=\beta_{0}+\beta_{1}X\)
- Linear predictions of our outcome (probabilities), can be out of [0,1] range
- Logistic regression: \(p(X)=\frac{e^{\beta_{0}+\beta_{1}X}}{1+e^{\beta_{0}+\beta_{1}X}}\)
- …force them into range using logistic function
- odds: \(\frac{p(X)}{1-p(X)}=e^{\beta_{0}+\beta_{1}X}\) (range: \([0,\infty]\), the higher, the higher probability of recidivism/default)
- log-odds/logit: \(log\left(\frac{p(X)}{1-p(X)}\right) = \beta_{0}+\beta_{1}X\) (James et al. 2013, 132)
- …take logarithm on both sides.
- Increasing X by one unit, increases the log odds by \(\beta_{1}\)
- Usually we get that in R output
- Estimation of \(\beta_{0}\) and \(\beta_{1}\) usually relies on maximum likelihood
3.2 Logistic model: Visually
- Figure 1 displays a scatterplot of predictor
Balanceand outcomeDefaultwith linear regression on the left and logistic regression on the right.
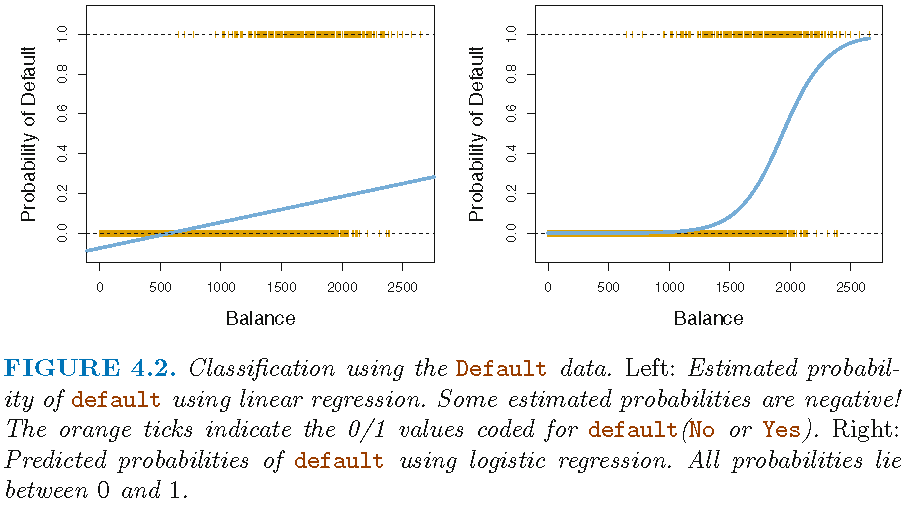
- Source: James et al. (2013, chaps. 4.3.1, 4.3.2, 4.3.4)
3.3 Logistic model: Equation (2)
- Logistic regression (LR) models the probability that \(Y\) belongs to a particular category (0 or 1)
- Rather than modeling response \(Y\) directly
- COMPAS data: Model probability to recidivate (reoffend)
- Outcome \(y\): Recidivism
is_recid(0,1,0,0,1,1,...) - Various predictors \(x's\)
- age =
age - prior offenses =
priors_count
- age =
- Outcome \(y\): Recidivism
- Use LR to obtain predicted values \(\hat{y}\)
- Predicted values will range between 0 and 1 = probabilities
- Depend on input/features (e.g., age, prior offences)
- Convert predicted values (probabilities) to a binary variable
- e.g., predict individuals will recidivate (
is_recid = Yes) if Pr(is_recid=Yes|age) > 0.5 - Here we call this variable
y_hat_01
- e.g., predict individuals will recidivate (
- Source: James et al. (2013, chap. 4.3)
3.4 Logistic model: Estimation
- Estimate model in R: glm(y ~ x1 + x2, family = binomial, data = data_train)
fit <- glm(as.factor(is_recid) ~ age + priors_count,
family = binomial,
data = data)
cat(paste(capture.output(summary(fit))[6:10], collapse="\n"))Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.029632 0.084679 12.16 <0.0000000000000002 ***
age -0.048161 0.002478 -19.44 <0.0000000000000002 ***
priors_count 0.169292 0.007331 23.09 <0.0000000000000002 ***- R output shows log odds: e.g., a one-unit increase in
ageis associated with an increase in the log odds ofis_recidby-0.05units - Difficult to interpret.. much easier to use predicted probabilities
3.5 Logistic model: Prediction
augment(): Predict values in R (orpredict())- Once coefficients have been estimated, it is a simple matter to compute the probability of outcome for values of our predictors (James et al. 2013, 134)
augment(fit, newdata = ..., type.predict = "response")1: Predict probability for each unit- Use argument
type.predict="response"to output probabilities of form \(P(Y=1|X)\) (as opposed to other information such as the logit) - Use argument
newdata = ...to obtain predictions for new data
predict(fit, newdata = data_predict, type = "response"): Predict probability setting values for particular Xs (contained indata_predict)
data_new = data.frame(age = c(20, 20, 40, 40),
priors_count = c(0, 2, 0, 2))
data_new <- augment(fit, newdata = data_new, type.predict = "response")
data_new# A tibble: 4 × 3
age priors_count .fitted
<dbl> <dbl> <dbl>
1 20 0 0.517
2 20 2 0.600
3 40 0 0.290
4 40 2 0.364- Q: How would you interpret these values?
- Source: James et al. (2013, chaps. 4.3.3, 4.6.2)
4 Classification (logistic model): Accuracy
- See James et al. (2013, Ch. 4.4.3)
4.1 True/false negatives/positives
- Q: The tables in Figure 2 and Figure 3 illustrate how to calculate different accuracy metrics. Assuming the outcome is cancer (1 = yes, 0 = no), how could we interpret the different cells?


4.2 Accuracy
- Accuracy = Correct Classification Rate (CCR)
- \(\text{Accuracy} = \frac{\text{Number of correct predictions}}{\text{Total number of predictions}} = \frac{TP + TN}{TP + TN + FP + FN}\)
- Error rate
- 1- Accuracy
4.3 Precision and recall (binary classification)
- Precision \((TP/P^{*})\)
- Number of true positive (TP) results divided by the number of all positive results (P*), including those not identified correctly
- e.g., \(\text{Accuracy} = \frac{\text{N of patients that have cancer AND are predicted to have cancer (true positives TP)}}{\text{N of all patients predicted to have cancer (positives P*)}}\)
- Recall \((TP/P)\)
- Number of true positive results divided by the number of all samples that should have been identified as positive (P)
- e.g., \(\text{Accuracy} = \frac{\text{N of patients that have cancer AND are predicted to have cancer (true positives TP)}}{\text{N of all patients that have cancer and SHOULD have been predicted to have cancer (the "trues" P)}}\)
- F1-Score: \(F1 = 2 \times \frac{precision \times recall}{precision + recall}\)
- Highest possible value of an F-score is 1.0, indicating perfect precision and recall, and the lowest possible value is 0, if either precision or recall are zero
4.4 Exercise: recidivism
- Take our recidivism example where reoffend = recidivate = 1 = positive and not reoffend = not recidivate = 0 and discuss the table in Figure 2 using this example.
- Take our recidivism example and discuss the different definitions (Column 2) in the Table in Figure 3. Explain what precision and recall would be in that case.
Answer
Precision \((TP/P^{*})\): \(\frac{\text{N of prisoners that recidivate AND are predicted to recidivate (true positives TP)}}{\text{N of all prisoners predicted to recidivate}}\)
Recall \((TP/P)\): \(\frac{\text{N of prisoners that recidivate AND are predicted to recidivate (true positives TP)}}{\text{N of all prisoners that recidivate and SHOULD have been predicted to recidivate (the "trues" P)}}\)
4.5 Exercise: Calculate different accuracy measures
- Below you find a table cross-tabulating the true/actual values (rows) with the predicted values (columns) (important:
conf_mat()swaps rows/columns)
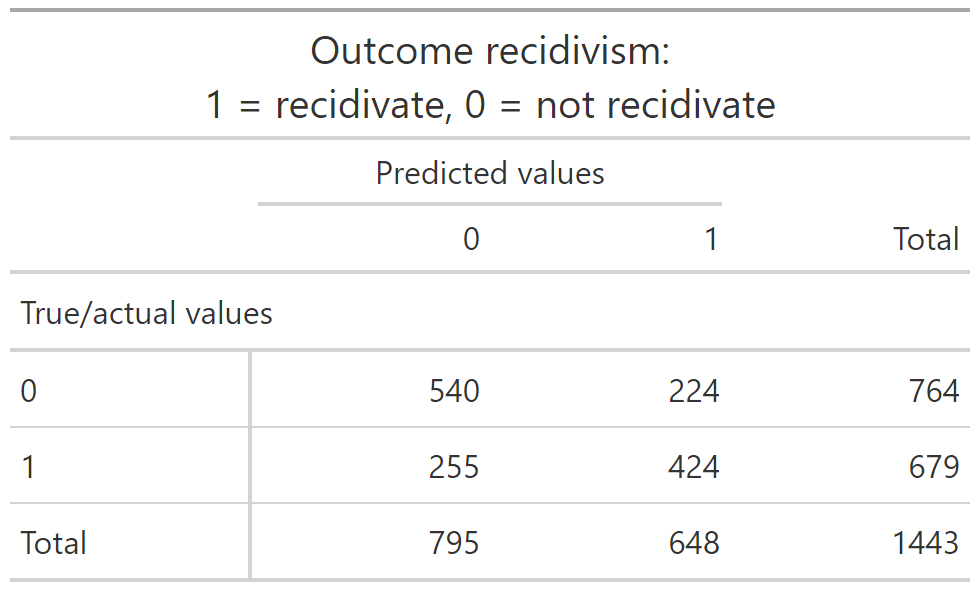
Table with labels (helper!)

Solutions
- Accuracy: \((540 + 424)/1443 = 0.67\)
- Type-I-error: \(224/764 = 0.29\)
- Precision: \(424/648 = 0.65\)
- Recall: \(424/679 = 0.62\)
- F1-score: \(2*(0.65*0.62)/(0.65+0.62) = 0.63\)
4.6 Error rates and ROC curve (binary classification)
- See James et al. (2013, Ch. 4.4.3)
- The error rates are a function of the classification threshold
- If we lower the classification threshold (e.g., use a predicted probability of 0.3 to classify someone as reoffender) we classify more items as positive (e.g. predict them to recidivate), thus increasing both False Positives and True Positives
- See James et al. (2013), Fig 4.7, p. 147
- Goal: we want to know how error rates develop as a function of the classification threshold
- The ROC curve is a popular graphic for simultaneously displaying the two types of errors (false positives, true positives rate) for all possible thresholds
- See James et al. (2013), Fig 4.8, p. 148 where \(1 - specificity = FP/N = \text{false positives rate (FPR)}\) and \(sensitivity = TP/P = \text{true positives rate (TPR)}\)
- The Area under the (ROC) curve (AUC) provides the overall performance of a classifier, summarized over all possible thresholds (James et al. 2013, 147)
- The maximum is 1, hence, values closer to it a preferable as shown in Figure 6 (maximize TRP, minimize FPR!)
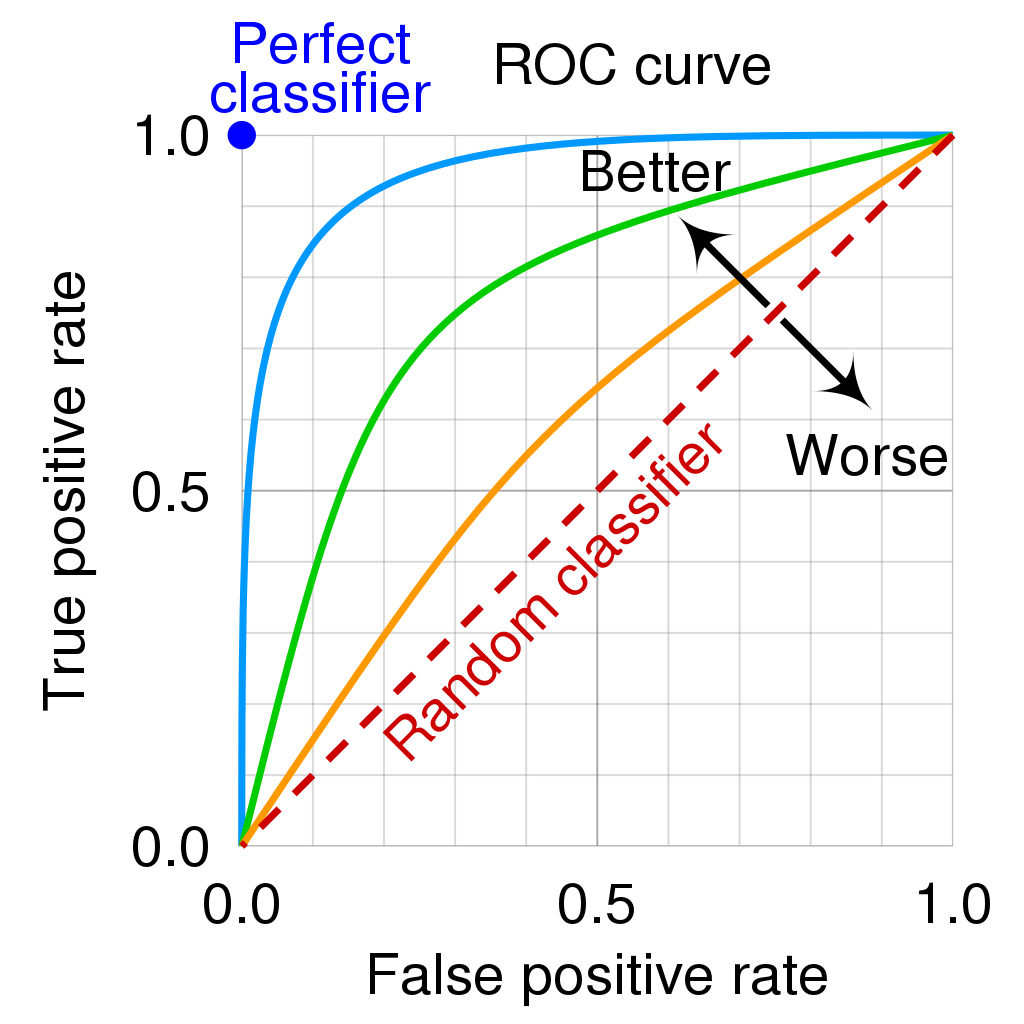
4.7 Weighting FPR and TPR differently (recidivism)
- Outcome: Recidivism where individual recidivates (1) or not (0)
- False Positive (FP): Model predicts an individual will recidivate when they actually do not. This could lead to unnecessary interventions or harsher sentences for individuals.
- False Negative (FN): Model predicts an individual will not recidivate when they actually do. This could result in individuals who are at risk, being released without proper intervention, potentially leading to repeat offenses.
- Assign costs
- Cost of False Positive (FP): unnecessary prison time (costs for individual and society)
- Cost of False Negative (FN): repeat offenses (costs for society probably higher) (probably more important) → (weight FN more strongly)
- Pick threshold focusing on minimizing FN (ideally both FPR/FNR high!)
- Important: Probability threshold of classifying someone as 0/1 not shown in Figure 6
- We need to get it from the underlying calculations in Table 2
5 Lab: Classification using a logistic model
Learning outcomes/objective: Learn…
- …how to use trainingset and validation dataset for ML in R.
- …how to predict binary outcomes in R (using a simple logistic regression).
- …how to assess accuracy in R (logistic regression).
5.1 The data
Our lab is based on Lee, Du, and Guerzhoy (2020) and on James et al. (2013, chap. 4.6.2) with various modifications. We will be using the dataset at LINK that is described by Angwin et al. (2016). - It’s data based on the COMPAS risk assessment tools (RAT). RATs are increasingly being used to assess a criminal defendant’s probability of re-offending. While COMPAS seemingly uses a larger number of features/variables for the prediction, Dressel and Farid (2018) showed that a model that includes only a defendant’s sex, age, and number of priors (prior offences) can be used to arrive at predictions of equivalent quality.
Overview of Compas dataset variables
id: ID of prisoner, numericname: Name of prisoner, factorcompas_screening_date: Date of compass screening, datedecile_score: the decile of the COMPAS score, numericis_recid: whether somone reoffended/recidivated (=1) or not (=0), numericis_recid_factor: same but factor variableage: a continuous variable containing the age (in years) of the person, numericage_cat: age categorizedpriors_count: number of prior crimes committed, numericsex: gender with levels “Female” and “Male”, factorrace: race of the person, factorjuv_fel_count: number of juvenile felonies, numericjuv_misd_count: number of juvenile misdemeanors, numericjuv_other_count: number of prior juvenile convictions that are not considered either felonies or misdemeanors, numeric
We first import the data into R:
5.2 Inspecting the dataset
The variables were named quite well, so that they are often self-explanatory:
decile_scoreis the COMPAS scoreis_recidwether someone reoffended (1 = recidividate = reoffend, 0 = NOT)racecontains the raceagecontains age.priors_countcontains the number of prior offenses- etc.
First we should make sure to really explore/unterstand our data. How many observations are there? How many different variables (features) are there? What is the scale of the outcome? What are the averages etc.? What kind of units are in your dataset?
[1] 7214[1] 14[1] 7214 14tibble [7,214 × 14] (S3: tbl_df/tbl/data.frame)
$ id : num [1:7214] 1 3 4 5 6 7 8 9 10 13 ...
$ name : Factor w/ 7158 levels "aajah herrington",..: 4922 4016 1989 4474 690 4597 2035 6345 2091 680 ...
$ compas_screening_date: Date[1:7214], format: "2013-08-14" "2013-01-27" ...
$ decile_score : num [1:7214] 1 3 4 8 1 1 6 4 1 3 ...
$ is_recid : num [1:7214] 0 1 1 0 0 0 1 NA 0 1 ...
$ is_recid_factor : Factor w/ 2 levels "no","yes": 1 2 2 1 1 1 2 NA 1 2 ...
$ age : num [1:7214] 69 34 24 23 43 44 41 43 39 21 ...
$ age_cat : Factor w/ 3 levels "25 - 45","Greater than 45",..: 2 1 3 3 1 1 1 1 1 3 ...
$ priors_count : num [1:7214] 0 0 4 1 2 0 14 3 0 1 ...
$ sex : Factor w/ 2 levels "Female","Male": 2 2 2 2 2 2 2 2 1 2 ...
$ race : Factor w/ 6 levels "African-American",..: 6 1 1 1 6 6 3 6 3 3 ...
$ juv_fel_count : num [1:7214] 0 0 0 0 0 0 0 0 0 0 ...
$ juv_misd_count : num [1:7214] 0 0 0 1 0 0 0 0 0 0 ...
$ juv_other_count : num [1:7214] 0 0 1 0 0 0 0 0 0 0 ...Also always inspect summary statistics for both numeric and categorical variables to get a better understanding of the data. Often such summary statistics will also reveal errors in the data.
Q: Does anything strike you as interesting the two tables below?
| Unique (#) | Missing (%) | Mean | SD | Min | Median | Max | ||
|---|---|---|---|---|---|---|---|---|
| id | 7214 | 0 | 5501.3 | 3175.7 | 1.0 | 5509.5 | 11001.0 |  |
| decile_score | 10 | 0 | 4.5 | 2.9 | 1.0 | 4.0 | 10.0 |  |
| is_recid | 3 | 9 | 0.5 | 0.5 | 0.0 | 0.0 | 1.0 |  |
| age | 65 | 0 | 34.8 | 11.9 | 18.0 | 31.0 | 96.0 |  |
| priors_count | 37 | 0 | 3.5 | 4.9 | 0.0 | 2.0 | 38.0 |  |
| juv_fel_count | 11 | 0 | 0.1 | 0.5 | 0.0 | 0.0 | 20.0 |  |
| juv_misd_count | 10 | 0 | 0.1 | 0.5 | 0.0 | 0.0 | 13.0 |  |
| juv_other_count | 10 | 0 | 0.1 | 0.5 | 0.0 | 0.0 | 17.0 |  |
| N | % | ||
|---|---|---|---|
| is_recid_factor | no | 3422 | 47.4 |
| yes | 3178 | 44.1 | |
| age_cat | 25 - 45 | 4109 | 57.0 |
| Greater than 45 | 1576 | 21.8 | |
| Less than 25 | 1529 | 21.2 | |
| sex | Female | 1395 | 19.3 |
| Male | 5819 | 80.7 | |
| race | African-American | 3696 | 51.2 |
| Asian | 32 | 0.4 | |
| Caucasian | 2454 | 34.0 | |
| Hispanic | 637 | 8.8 | |
| Native American | 18 | 0.2 | |
| Other | 377 | 5.2 |
The table() function is also useful to get an overview of variables. Use the argument useNA = "always" to display potential missings.
African-American Asian Caucasian Hispanic
3696 32 2454 637
Native American Other <NA>
18 377 0
no yes
0 3422 0
1 0 3178
1 2 3 4 5 6 7 8 9 10
1440 941 747 769 681 641 592 512 508 383 Finally, there are some helpful functions to explore missing data included in the naniar package. Can you decode those graphs? What do they show? (for publications the design would need to be improved)
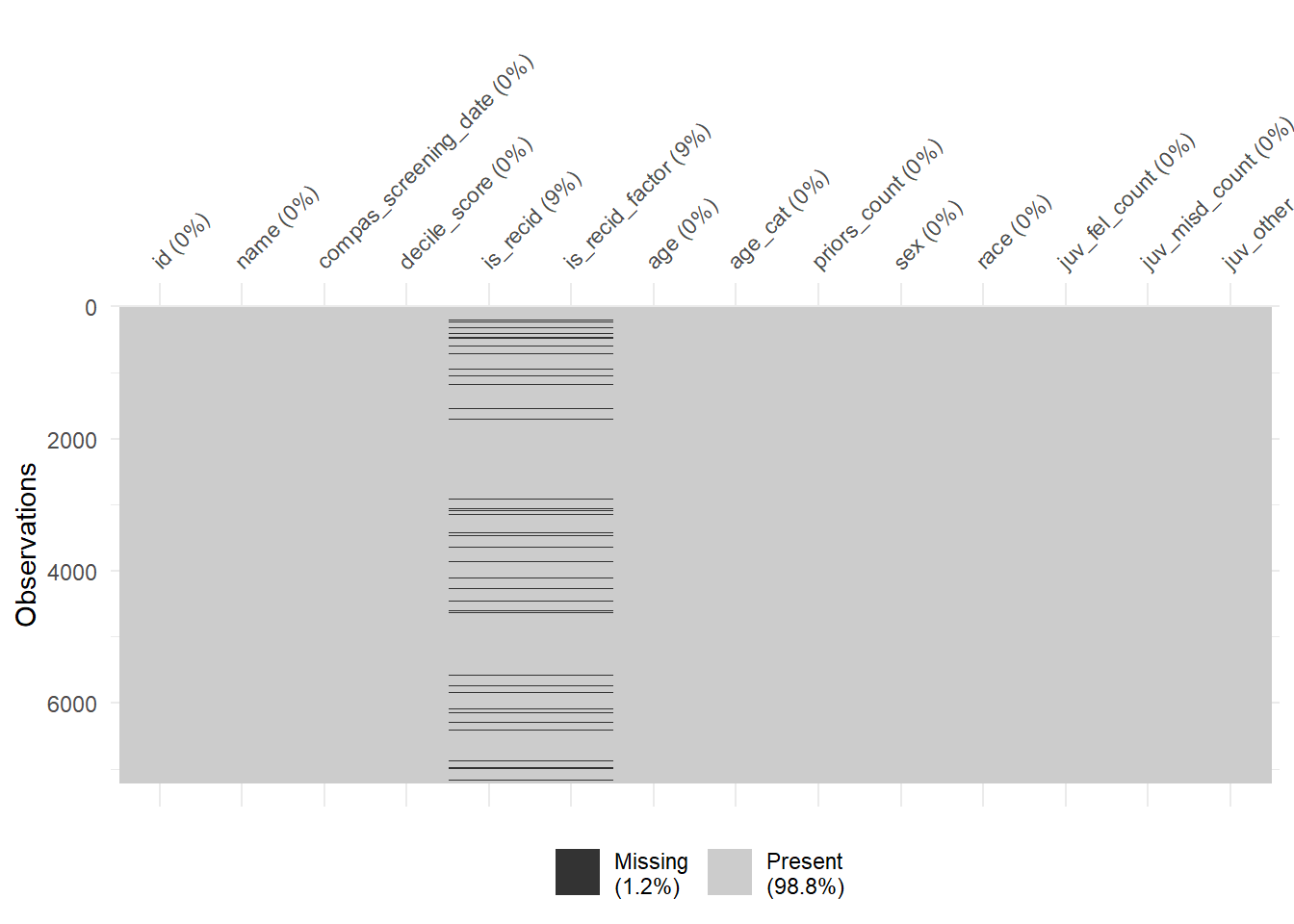

5.3 Exploring potential predictors
A correlation matrix can give us first hints regarding important predictors.
- Q: Can we identify anything interesting?
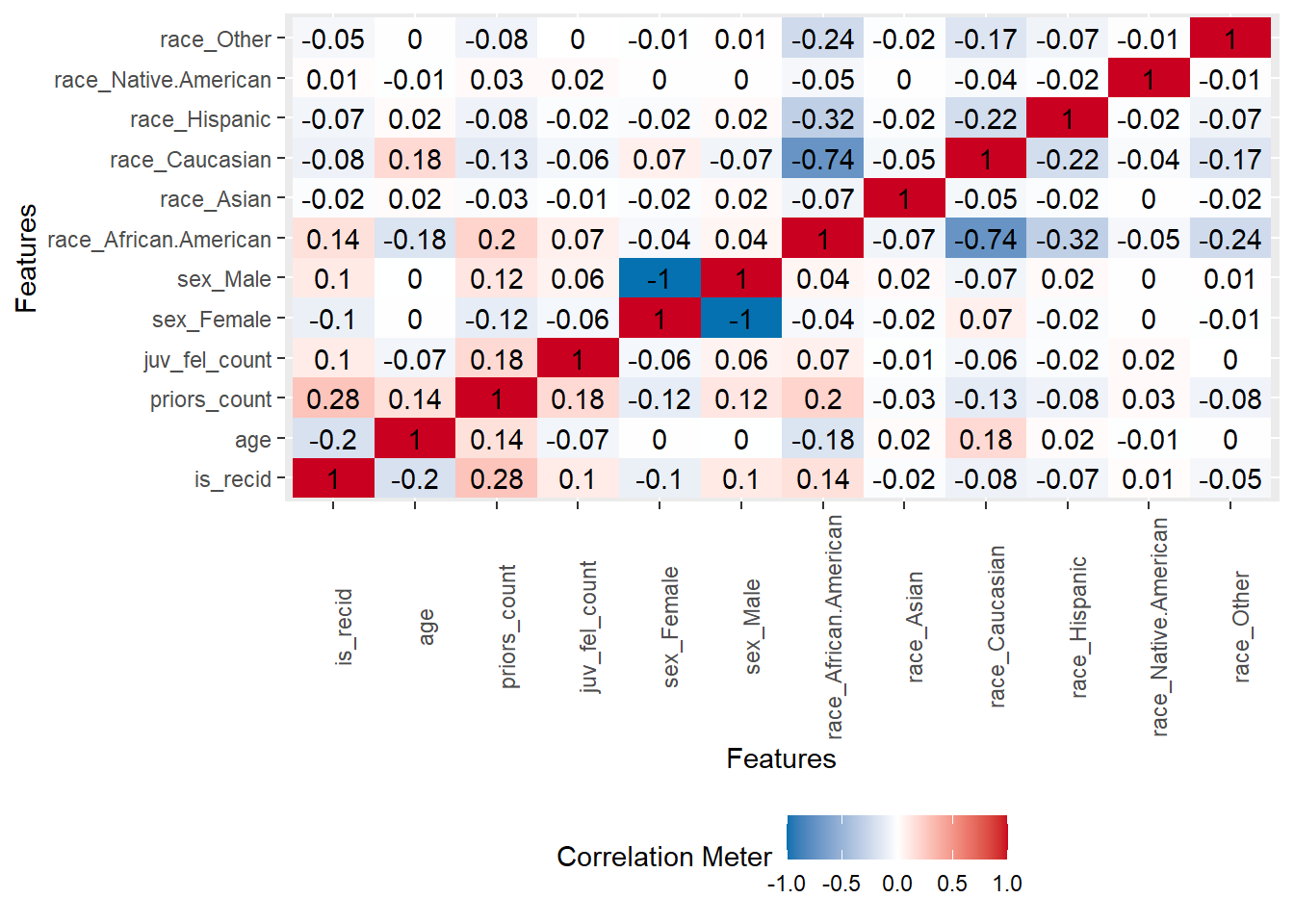
5.4 Building a first logistic ML model
Below we estimate a simple logistic regression machine learning model only using one split into training and test data. To start, we check whether there are any missings on our outcome variable is_recid_factor (we use the factor version of our outcome variable). We extract the subset of individuals for whom our outcome is_recid_factor is missing, store them data_missing_outcome and delete those individuals from the actual dataset data.
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(is_recid_factor))
dim(data_missing_outcome)[1] 614 14# Omit individuals with missing outcome from data
data <- data %>% drop_na(is_recid_factor) # ?drop_na
dim(data)[1] 6600 14
Then we split the data into training and test data.
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect<Training/Testing/Total>
<5280/1320/6600># Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
dim(data_train)[1] 5280 14[1] 1320 14
Subsequently, we estimate our linear model based on the training data. Below we just use 1 predictor:
# Fit the model
fit1 <- logistic_reg() %>% # logistic model
set_engine("glm") %>% # define lm package/function
set_mode("classification") %>%# define mode
fit(is_recid_factor ~ age, # fit the model
data = data_train) # based on training data
fit1 # Class model output with summary(fit1$fit)parsnip model object
Call: stats::glm(formula = is_recid_factor ~ age, family = stats::binomial,
data = data)
Coefficients:
(Intercept) age
1.17594 -0.03601
Degrees of Freedom: 5279 Total (i.e. Null); 5278 Residual
Null Deviance: 7313
Residual Deviance: 7090 AIC: 7094
Then, we predict our outcome in the training data and evaluate the accuracy in the training data.
- Q: How can we interpret the accuracy metrics? Are we happy?
# Training data: Add predictions
data_train %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()# A tibble: 6 × 5
is_recid_factor age .pred_class .pred_no .pred_yes
<fct> <dbl> <fct> <dbl> <dbl>
1 no 26 yes 0.440 0.560
2 no 27 yes 0.449 0.551
3 yes 41 no 0.575 0.425
4 no 50 no 0.651 0.349
5 yes 28 yes 0.458 0.542
6 no 33 no 0.503 0.497# Cross-classification table (Columns = Truth, Rows = Predicted)
data_train %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class) Truth
Prediction no yes
no 1505 948
yes 1225 1602# Training data: Metrics
data_train %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.588
2 kap binary 0.179
Finally, we can also predict data for the test data and evaluate the accuracy in the test data.
# Test data: Add predictions
data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()# A tibble: 6 × 5
is_recid_factor age .pred_class .pred_no .pred_yes
<fct> <dbl> <fct> <dbl> <dbl>
1 no 43 no 0.592 0.408
2 no 39 no 0.557 0.443
3 no 27 yes 0.449 0.551
4 no 37 no 0.539 0.461
5 no 21 yes 0.397 0.603
6 no 43 no 0.592 0.408# Cross-classification table (Columns = Truth, Rows = Predicted)
data_test %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class) Truth
Prediction no yes
no 379 255
yes 313 373# Test data: Metrics
data_test %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.570
2 kap binary 0.141Possible reasons if accuracy is higher on test data than training data:
Observing higher test accuracy may be due to:
- Bad training accuracy: Already bad accuracy in training data is easy to beat.
- Small Dataset: Test set may contain easier examples due to small dataset size.
- Overfitting to Test Data: Repeated tweaking against the same test set can lead to overfitting.
- Data Leakage: Information from the test set influencing the model during training.
- Strong Regularization: Techniques like dropout can make the model generalize better but underperform on training data.
- Evaluation Methodology: The splitting method can affect results, e.g., stratified splits.
- Random Variation: Small test sets can lead to non-representative results.
- Improper Training: Inadequate training epochs or improper learning rates.
Below code to visualize the ROC-curve. The function roc_curve() calculates the data for the ROC curve.
# Calculate data for ROC curve - threshold, specificity, sensitivity
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_curve(truth = is_recid_factor, .pred_no) %>%
head() %>% kable()| .threshold | specificity | sensitivity |
|---|---|---|
| -Inf | 0.0000000 | 1.0000000 |
| 0.3794654 | 0.0000000 | 1.0000000 |
| 0.3879800 | 0.0079618 | 1.0000000 |
| 0.3965635 | 0.0429936 | 0.9855491 |
| 0.4052112 | 0.1114650 | 0.9566474 |
| 0.4139181 | 0.1528662 | 0.9219653 |
We can then visualize is using autoplot(). Since it’s a ggplot we can make change labels etc. with +. Subsequently, we can use roc_auc() to calculate the area under the curve.
# Calculate data for ROC curve - threshold, specificity, sensitivity
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_curve(truth = is_recid_factor, .pred_no) %>%
head()# A tibble: 6 × 3
.threshold specificity sensitivity
<dbl> <dbl> <dbl>
1 -Inf 0 1
2 0.379 0 1
3 0.388 0.00796 1
4 0.397 0.0430 0.986
5 0.405 0.111 0.957
6 0.414 0.153 0.922# Calculate data for ROC curve and visualize
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_curve(truth = is_recid_factor, .pred_no) %>% # Default: Uses first class (=0=no)
autoplot() +
xlab("False Positive Rate (FPR, 1 - specificity)") +
ylab("True Positive Rate (TPR, sensitivity, recall)")
# Calculate are under the curve
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_auc(truth = is_recid_factor, .pred_no)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.597
If we are happy with the accuracy in the training data we could then use our model to predict the outcomes for those individuals for which we did not observe the outcome which we stored in data_missing.
# Missing outcome data predictions
data_missing_outcome <- data_missing_outcome %>%
augment(x = fit1, type.predict = "response")
data_missing_outcome %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()# A tibble: 6 × 5
is_recid_factor age .pred_class .pred_no .pred_yes
<fct> <dbl> <fct> <dbl> <dbl>
1 <NA> 43 no 0.592 0.408
2 <NA> 31 yes 0.485 0.515
3 <NA> 21 yes 0.397 0.603
4 <NA> 32 yes 0.494 0.506
5 <NA> 30 yes 0.476 0.524
6 <NA> 21 yes 0.397 0.6035.4.1 Visualizing predictions
It is often insightful to visualize a MLM’s predictions, e..g, exploring whether our predictions are better or worse for certain population subsets (e.g., the young). In other words, whether the model works better/worse across groups. Below we take data_test from above (which includes the predictions) and calculate the errors and the absolute errors.
data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, .pred_class, .pred_no, .pred_yes, age, sex, race, priors_count)# A tibble: 1,320 × 8
is_recid_factor .pred_class .pred_no .pred_yes age sex race priors_count
<fct> <fct> <dbl> <dbl> <dbl> <fct> <fct> <dbl>
1 no no 0.592 0.408 43 Male Other 2
2 no no 0.557 0.443 39 Fema… Cauc… 0
3 no yes 0.449 0.551 27 Male Cauc… 0
4 no no 0.539 0.461 37 Fema… Cauc… 0
5 no yes 0.397 0.603 21 Fema… Cauc… 0
6 no no 0.592 0.408 43 Male Cauc… 1
7 no yes 0.494 0.506 32 Male Other 0
8 no no 0.691 0.309 55 Male Cauc… 0
9 yes yes 0.467 0.533 29 Male Afri… 0
10 no yes 0.458 0.542 28 Fema… Other 0
# ℹ 1,310 more rowsFigure 7 visualizes the variation of the predicted probabilites. What can we see?
# Visualize errors and predictors
data_test %>%
augment(x = fit1, type.predict = "response") %>%
ggplot(aes(x = .pred_yes)) +
geom_histogram() +
xlim(0,1)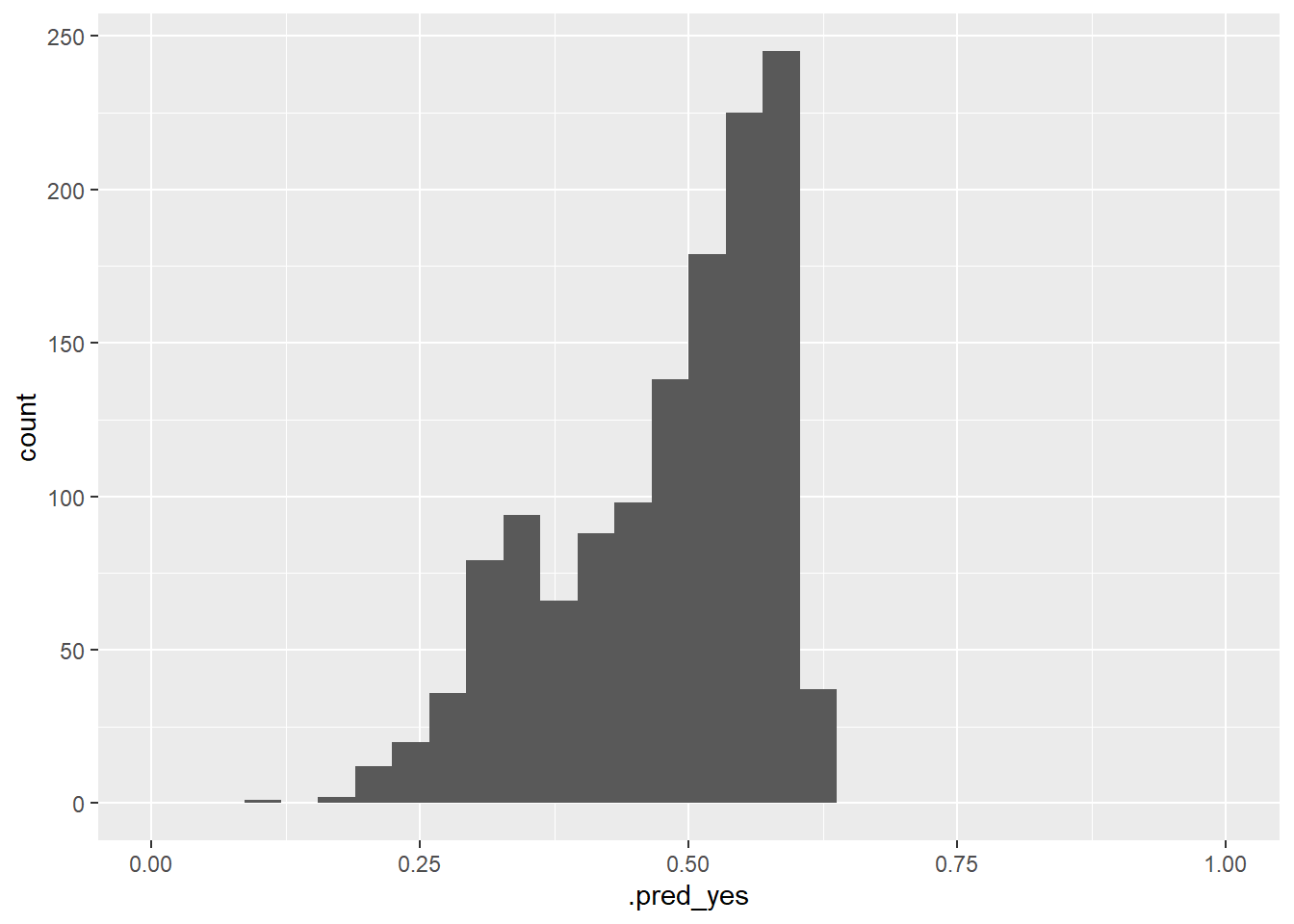
In Figure 8 we visualize the predicted probability of recidivating as a function of covariates/predictors after discretizing and factorizing some variables. Imporantly, the ML model is only based on one of those variables namely age, hence, why the predictions do not vary that strongly with the other variables.
Q: What can we observe? What problem does that point to?
# Visualize errors and predictors
library(patchwork)
library(ggplot2)
data_plot <- data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(.pred_yes, age, sex, race, priors_count) %>%
mutate(age = cut_interval(age, 8),
priors_count = as.factor(priors_count))
p1 <- ggplot(data = data_plot, aes(y = .pred_yes, x = sex)) +
geom_boxplot()
p2 <- ggplot(data = data_plot, aes(y = .pred_yes, x = age)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 30, hjust = 1))
p3 <- ggplot(data = data_plot, aes(y = .pred_yes, x = race)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 30, hjust = 1))
p4 <- ggplot(data = data_plot, aes(y = .pred_yes, x = priors_count)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 30, hjust = 1))
p1 + p2 + p3 + p4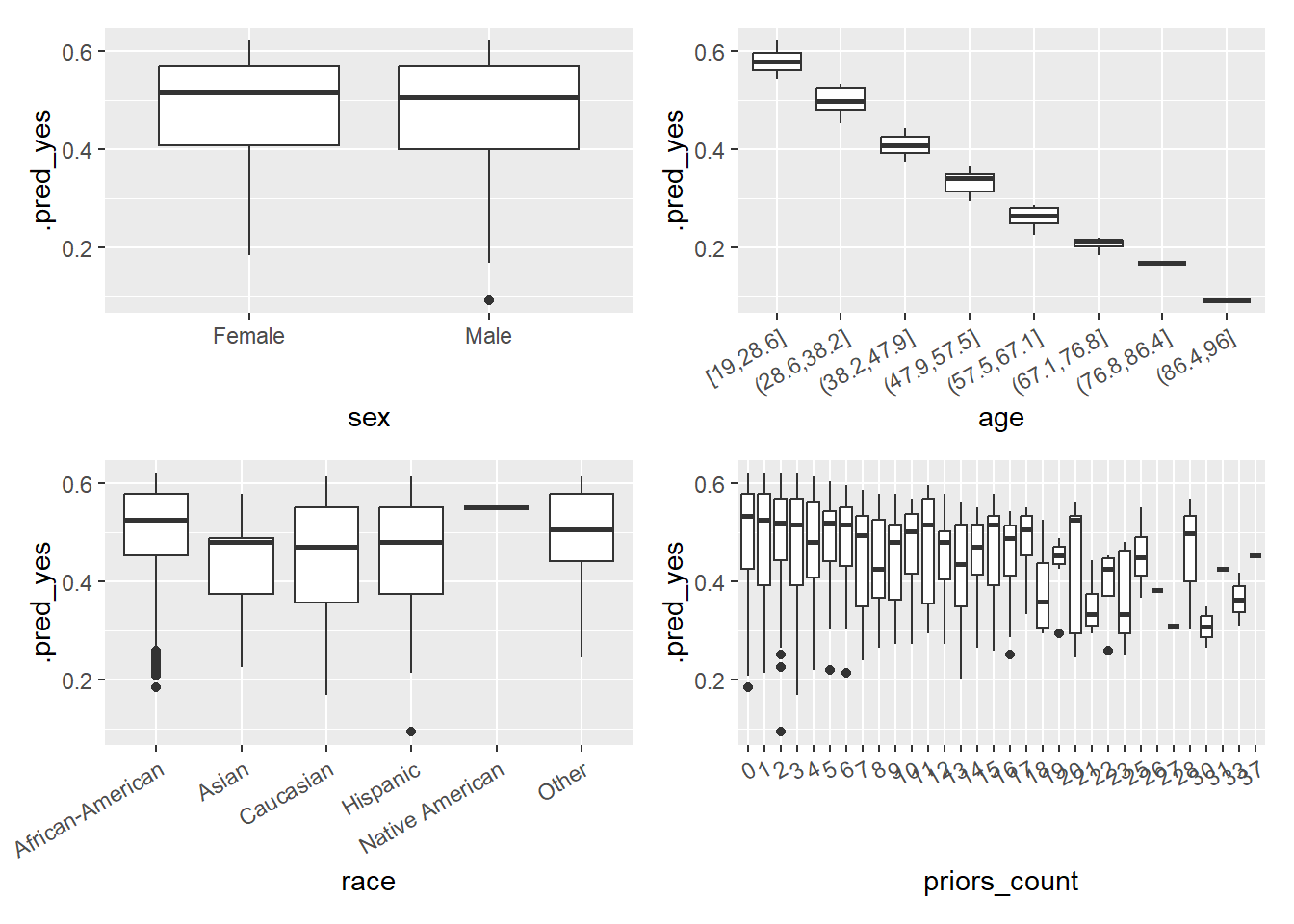
5.5 Exercise: Enhance simple logistic model
- Use the code below to load the data.
- In the next chunk you find the code we used above to built our first predictive model for our outcome
is_recid_factor. Please use the code and add further predictors to the model. Can you find a model with better accuracy picking further predictors?
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(is_recid_factor))
dim(data_missing_outcome)
# Omit individuals with missing outcome from data
data <- data %>% drop_na(is_recid_factor) # ?drop_na
dim(data)
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Fit the model
fit1 <- logistic_reg() %>% # logistic model
set_engine("glm") %>% # define lm package/function
set_mode("classification") %>%# define mode
fit(is_recid_factor ~ age, # fit the model
data = data_train) # based on training data
fit1
# Training data: Add predictions
data_train %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
# Cross-classification table (Columns = Truth, Rows = Predicted)
data_train %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class)
# Training data: Metrics
data_train %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)
# Test data: Add predictions
data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
# Cross-classification table (Columns = Truth, Rows = Predicted)
data_test %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class)
# Test data: Metrics
data_test %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)6 Homework/Exercise:
Above we used a logistic regression model to predict recidivism. In principle, we could also use a linear probability model, i.e., estimate a linear regression and convert the predicted probabilities to a predicted binary outcome variable later on.
- What might be a problem when we use a linear probability model to obtain predictions (see James et al. (2013), Figure, 4.2, p. 131)?
- Please use the code above (see next section below) but now change the model to a linear probability model using the same variables. How is the accuracy of the lp-model as compared to the logistic model? Did you expect that?
- Tipps
- The linear probability model is defined through
linear_reg() %>% set_engine('lm') %>% set_mode('regression') - The linear probability model provides a predicted probability that needs to be converted to a binary class variable at the end.
- The linear probability model requires a numeric outcome, i.e., use
is_recidas outcome and only convertis_recidto a factor at the end (as well as the predicted class).
- The linear probability model is defined through
Solution
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(is_recid))
dim(data_missing_outcome)
# Omit individuals with missing outcome from data
data <- data %>% drop_na(is_recid) # ?drop_na
dim(data)
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Fit the model
fit1 <- linear_reg() %>% # logistic model
set_engine("lm") %>% # define lm package/function
set_mode("regression") %>%# define mode
fit(is_recid ~ age, # fit the model
data = data_train) # based on training data
fit1
# Training data: Add predictions
data_train <- augment(x = fit1, data_train) %>%
mutate(.pred_class = as.factor(ifelse(.pred>=0.5, 1, 0)),
is_recid = factor(is_recid))
head(data_train %>%
select(is_recid, is_recid_factor, age, .pred, .resid, .pred_class))
# Training data: Metrics
data_train %>%
metrics(truth = is_recid, estimate = .pred_class)
# Test data: Add predictions
data_test <- augment(x = fit1, data_test) %>%
mutate(.pred_class = as.factor(ifelse(.pred>=0.5, 1, 0)),
is_recid = factor(is_recid))
head(data_test %>%
select(is_recid, is_recid_factor, age, .pred, .resid, .pred_class))
# Test data: Metrics
data_test %>%
metrics(truth = is_recid, estimate = .pred_class) 6.1 All the code
# namer::unname_chunks("03_01_predictive_models.qmd")
# namer::name_chunks("03_01_predictive_models.qmd")
options(scipen=99999)
#| echo: false
library(tidyverse)
library(lemon)
library(knitr)
library(kableExtra)
library(dplyr)
library(plotly)
library(randomNames)
library(stargazer)
library(gt)
library(tidymodels)
library(tidyverse)
set.seed(0)
load("www/data/data_compas.RData")
data_table <- data %>% select(id, name, compas_screening_date, is_recid,
is_recid_factor, age, priors_count) %>%
slice(1:10)
data_table %>%
kable(format = "html",
escape=FALSE,
align=c(rep("l", 1), "c", "c")) %>%
kable_styling(font_size = 16)
library(tidyverse)
set.seed(0)
load(file = "www/data/data_compas.Rdata")
# First 5000 observations as training data
data_train <- data[1:5000,]
fit <- glm(as.factor(is_recid) ~ age + priors_count,
family = binomial,
data = data)
cat(paste(capture.output(summary(fit))[6:10], collapse="\n"))
ggplot(data_train) + geom_smooth(aes(x = priors_count, y = y_hat)) + geom_point(aes(x = priors_count, y = is_recid)) + ylim(0,1)
data_new = data.frame(age = c(20, 20, 40, 40),
priors_count = c(0, 2, 0, 2))
data_new <- augment(fit, newdata = data_new, type.predict = "response")
data_new
# Visualize predicted values in plot
fit_linear <- lm(is_recid ~ age,
data = data_train)
data_train$y_hat_lm <- predict(fit_linear, type = "response")
ggplot(data = data_train, aes(x = age, y = is_recid)) +
geom_jitter(width = 0.1, height = 0.1, alpha = 0.1) +
geom_point(aes(x = age, y = y_hat), color = "red") +
geom_point(aes(x = age, y = y_hat_lm), color = "blue")
fit <- glm(as.factor(is_recid) ~ age,
family = binomial,
data = data_train)
fit2 <- lm(is_recid ~ age,
data = data_train)
data_train$y_hat <- predict(fit, type = "response")
data_train$y_hat2 <- predict(fit2, type = "response")
ggplot(data_train) +
geom_smooth(aes(x = priors_count, y = y_hat)) +
#geom_smooth(aes(x = priors_count, y = y_hat2)) +
geom_point(aes(x = priors_count, y = is_recid)) +
ylim(0,1)
x <- structure(c(540L, 255L, 224L, 424L),
dim = c(2L, 2L),
dimnames = structure(list(
c("0", "1"),
c("0", "1")),
names = c("", "")),
class = "table")
x <- cbind(x, rowSums(x))
x <- rbind(x, colSums(x))
x <- as.data.frame.matrix(x)
rownames(x)[3] <- "Total"
names(x)[3] <- "Total"
x <- x %>%
mutate(row_spanner = "True/actual values") %>%
mutate(category = rownames(.)) %>%
remove_rownames() %>%
select(category, row_spanner, everything())
confusion_matrix_reduced <- gt::gt(x,
#rownames_to_stub = TRUE,
rowname_col = "category",
groupname_col = "row_spanner") %>%
tab_spanner(
label = "Predicted values",
columns = c("0","1")
) |>
cols_width(everything() ~ px(120)) |>
tab_header(
title = md("Outcome recidivism:<br> 1 = recidivate, 0 = not recidivate"))
gtsave(data = confusion_matrix_reduced, filename = "confusion_matrix_reduced.png")
# Add names
x[1,3] <- paste0(x[1,3], " (TN)")
x[2,3] <- paste0(x[2,3], " (FN)")
x[1,4] <- paste0(x[1,4], " (FP)")
x[2,4] <- paste0(x[2,4], " (TP)")
x[3,3] <- paste0(x[3,3], " (N*)")
x[3,4] <- paste0(x[3,4], " (P*)")
x[1,5] <- paste0(x[1,5], " (N)")
x[2,5] <- paste0(x[2,5], " (P)")
confusion_matrix <- gt::gt(x,
#rownames_to_stub = TRUE,
rowname_col = "category",
groupname_col = "row_spanner") %>%
tab_spanner(
label = "Predicted values",
columns = c("0","1")
) |>
cols_width(everything() ~ px(120) ) |>
tab_header(
title = md("Outcome recidivism:<br> 1 = recidivate, 0 = not recidivate"))
confusion_matrix
gtsave(data = confusion_matrix, filename = "confusion_matrix.png")
# install.packages(pacman)
pacman::p_load(tidyverse,
tidymodels,
knitr,
kableExtra,
DataExplorer,
visdat,
naniar)
load(file = "www/data/data_compas.Rdata")
# install.packages(pacman)
pacman::p_load(tidyverse,
tidymodels,
knitr,
kableExtra,
DataExplorer,
visdat,
naniar)
rm(list=ls())
load(url(sprintf("https://docs.google.com/uc?id=%s&export=download",
"1gryEUVDd2qp9Gbgq8G0PDutK_YKKWWIk")))
nrow(data)
ncol(data)
dim(data)
str(data) # Better use glimpse()
# glimpse(data)
# skimr::skim(data)
library(modelsummary)
datasummary_skim(data, type = "numeric", output = "html")
datasummary_skim(data, type = "categorical", output = "html")
table(data$race, useNA = "always")
table(data$is_recid, data$is_recid_factor)
table(data$decile_score)
vis_miss(data)
gg_miss_upset(data, nsets = 2, nintersects = 10)
# Ideally, use higher number of nsets/nintersects
# with more screen space
plot_correlation(data %>% dplyr::select(is_recid, age,
priors_count,sex,
race,
juv_fel_count),
cor_args = list("use" = "pairwise.complete.obs"))
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(is_recid_factor))
dim(data_missing_outcome)
# Omit individuals with missing outcome from data
data <- data %>% drop_na(is_recid_factor) # ?drop_na
dim(data)
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
dim(data_train)
dim(data_test)
# Fit the model
fit1 <- logistic_reg() %>% # logistic model
set_engine("glm") %>% # define lm package/function
set_mode("classification") %>%# define mode
fit(is_recid_factor ~ age, # fit the model
data = data_train) # based on training data
fit1 # Class model output with summary(fit1$fit)
# Training data: Add predictions
data_train %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
# Cross-classification table (Columns = Truth, Rows = Predicted)
data_train %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class)
# Training data: Metrics
data_train %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)
# Test data: Add predictions
data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
# Cross-classification table (Columns = Truth, Rows = Predicted)
data_test %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class)
# Test data: Metrics
data_test %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)
# Calculate data for ROC curve - threshold, specificity, sensitivity
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_curve(truth = is_recid_factor, .pred_no) %>%
head() %>% kable()
# Calculate data for ROC curve - threshold, specificity, sensitivity
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_curve(truth = is_recid_factor, .pred_no) %>%
head()
# Calculate data for ROC curve and visualize
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_curve(truth = is_recid_factor, .pred_no) %>% # Default: Uses first class (=0=no)
autoplot() +
xlab("False Positive Rate (FPR, 1 - specificity)") +
ylab("True Positive Rate (TPR, sensitivity, recall)")
# Calculate are under the curve
data_test %>%
augment(x = fit1, type.predict = "response") %>%
roc_auc(truth = is_recid_factor, .pred_no)
# Missing outcome data predictions
data_missing_outcome <- data_missing_outcome %>%
augment(x = fit1, type.predict = "response")
data_missing_outcome %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, .pred_class, .pred_no, .pred_yes, age, sex, race, priors_count)
# Visualize errors and predictors
data_test %>%
augment(x = fit1, type.predict = "response") %>%
ggplot(aes(x = .pred_yes)) +
geom_histogram() +
xlim(0,1)
# Visualize errors and predictors
library(patchwork)
library(ggplot2)
data_plot <- data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(.pred_yes, age, sex, race, priors_count) %>%
mutate(age = cut_interval(age, 8),
priors_count = as.factor(priors_count))
p1 <- ggplot(data = data_plot, aes(y = .pred_yes, x = sex)) +
geom_boxplot()
p2 <- ggplot(data = data_plot, aes(y = .pred_yes, x = age)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 30, hjust = 1))
p3 <- ggplot(data = data_plot, aes(y = .pred_yes, x = race)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 30, hjust = 1))
p4 <- ggplot(data = data_plot, aes(y = .pred_yes, x = priors_count)) +
geom_boxplot() +
theme(axis.text.x = element_text(angle = 30, hjust = 1))
p1 + p2 + p3 + p4
# install.packages(pacman)
pacman::p_load(tidyverse,
tidymodels,
knitr,
kableExtra,
DataExplorer,
visdat,
naniar)
load(file = "www/data/data_compas.Rdata")
# install.packages(pacman)
pacman::p_load(tidyverse,
tidymodels,
knitr,
kableExtra,
DataExplorer,
visdat,
naniar)
rm(list=ls())
load(url(sprintf("https://docs.google.com/uc?id=%s&export=download",
"1gryEUVDd2qp9Gbgq8G0PDutK_YKKWWIk")))
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(is_recid_factor))
dim(data_missing_outcome)
# Omit individuals with missing outcome from data
data <- data %>% drop_na(is_recid_factor) # ?drop_na
dim(data)
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Fit the model
fit1 <- logistic_reg() %>% # logistic model
set_engine("glm") %>% # define lm package/function
set_mode("classification") %>%# define mode
fit(is_recid_factor ~ age, # fit the model
data = data_train) # based on training data
fit1
# Training data: Add predictions
data_train %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
# Cross-classification table (Columns = Truth, Rows = Predicted)
data_train %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class)
# Training data: Metrics
data_train %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)
# Test data: Add predictions
data_test %>%
augment(x = fit1, type.predict = "response") %>%
select(is_recid_factor, age, .pred_class, .pred_no, .pred_yes) %>%
head()
# Cross-classification table (Columns = Truth, Rows = Predicted)
data_test %>%
augment(x = fit1, type.predict = "response") %>%
conf_mat(truth = is_recid_factor, estimate = .pred_class)
# Test data: Metrics
data_test %>%
augment(x = fit1, type.predict = "response") %>%
metrics(truth = is_recid_factor, estimate = .pred_class)
# install.packages(pacman)
pacman::p_load(tidyverse,
tidymodels,
knitr,
kableExtra,
DataExplorer,
visdat,
naniar)
load(file = "www/data/data_compas.Rdata")
# install.packages(pacman)
pacman::p_load(tidyverse,
tidymodels,
knitr,
kableExtra,
DataExplorer,
visdat,
naniar)
rm(list=ls())
load(url(sprintf("https://docs.google.com/uc?id=%s&export=download",
"1gryEUVDd2qp9Gbgq8G0PDutK_YKKWWIk")))
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(is_recid))
dim(data_missing_outcome)
# Omit individuals with missing outcome from data
data <- data %>% drop_na(is_recid) # ?drop_na
dim(data)
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Fit the model
fit1 <- linear_reg() %>% # logistic model
set_engine("lm") %>% # define lm package/function
set_mode("regression") %>%# define mode
fit(is_recid ~ age, # fit the model
data = data_train) # based on training data
fit1
# Training data: Add predictions
data_train <- augment(x = fit1, data_train) %>%
mutate(.pred_class = as.factor(ifelse(.pred>=0.5, 1, 0)),
is_recid = factor(is_recid))
head(data_train %>%
select(is_recid, is_recid_factor, age, .pred, .resid, .pred_class))
# Training data: Metrics
data_train %>%
metrics(truth = is_recid, estimate = .pred_class)
# Test data: Add predictions
data_test <- augment(x = fit1, data_test) %>%
mutate(.pred_class = as.factor(ifelse(.pred>=0.5, 1, 0)),
is_recid = factor(is_recid))
head(data_test %>%
select(is_recid, is_recid_factor, age, .pred, .resid, .pred_class))
# Test data: Metrics
data_test %>%
metrics(truth = is_recid, estimate = .pred_class)
labs = knitr::all_labels()
labs = setdiff(labs, c("setup", "setup2", "homework-solution-hide", "get-labels", "load-data-1"))References
Angwin, Julia, Jeff Larson, Lauren Kirchner, and Surya Mattu. 2016. “Machine Bias.” https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing.
Dressel, Julia, and Hany Farid. 2018. “The Accuracy, Fairness, and Limits of Predicting Recidivism.” Sci Adv 4 (1): eaao5580.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning: With Applications in R. Springer Texts in Statistics. Springer.
Lee, Claire S, Jeremy Du, and Michael Guerzhoy. 2020. “Auditing the COMPAS Recidivism Risk Assessment Tool: Predictive Modelling and Algorithmic Fairness in CS1.” In Proceedings of the 2020 ACM Conference on Innovation and Technology in Computer Science Education, 535–36. ITiCSE ’20. New York, NY, USA: Association for Computing Machinery.
Footnotes
Alternatively use
predict(fit, newdata = NULL, type = "response").↩︎