| respondent_id | life_satisfaction | country | unemployed_active |
|---|---|---|---|
| 10608 | 5 | FR | 0 |
| 10405 | 8 | FR | 1 |
| 10007 | 7 | FR | 0 |
| 11170 | 10 | FR | 0 |
| 10751 | 10 | FR | 1 |
| 10005 | 10 | FR | 0 |
| .. | .. | .. | .. |
Machine learning: Fundamental concepts
Learning outcomes/objective: Learn…
- …and repeat logic underlying predictive models.
- …that there is a (joint-)distribution underlying and model.
- …concepts such as training dataset, accuracy, bias_variance tradeoff etc.
1 Predictive modelling: Skills
2 Mean as a ‘predictive model’
2.1 Mean as a model: Data (1)
- Data: European Social Survey (ESS): Round 10 - 2020. Democracy, Digital social contacts
- Measures of life satisfaction, unemployment etc. (cf. Table 1)
- We will use this data shown in Table 1 for our predictions later on!
2.2 Mean as a model (2)
- Model(s) = Mathematical equation(s)
- Underlying a model is always a (joint) distribution
- Model summarizes (joint) distribution with fewer parameters
- e.g. mean with one parameter
- e.g., linear model with three variables (\(y\), \(x1\), \(x2\)) with three parameters (\(\text{intercept }\beta + \beta_{1} + \beta_{2}\))
- …we start with a simple example!
- “using only information from the outcome variable itself for our prediction”
2.3 Mean as a model (3)
- Simple model: Mean of the distribution of a variable
\[ \begin{aligned} \text{Lifesatisfaction}_{Claudia} = 5 = \underbrace{\color{blue}{\overline{y}}}_{\color{green}{\widehat{y}}_{Claudia}} \pm \color{red}{\varepsilon}_{Claudia} = \color{blue}{7.03} \color{red}{-2.03} \end{aligned} \]
Mean (= model) predicts Claudia’s value with a certain error
Q: How well does the model (mean = 7) predict person’s that have values of 1, of 7.03 or of 8? What is the bias?
Important: We could use this model – this mean – to predict…
- …life_satisfaction values of people that gave no answer (missings in the dataset)
- …life_satisfaction values of another group of people, e.g., Germans
- …future life_satisfaction values of other or the same people
Here the outcome variable has values from 0-10. The mean for a binary outcome variable is simply the share of 1s, e.g., in the data above the share (mean) of unemployed actively looking for a job (France) is 0.04 (73 out of 1977).
2.4 Mean as a model (table) (4)
- In Table 2 we added our predictions to the data showing only the first ten lines of the dataset (see column “error”)
- Mean provides same prediction \((\hat{y})\) for everyone
| Name | life_satisfaction | prediction (mean) | error |
|---|---|---|---|
| Patrick | 10 | 7.034 | 2.966 |
| Quinten | 7 | 7.034 | -0.034 |
| Austin | 7 | 7.034 | -0.034 |
| Quartus | 5 | 7.034 | -2.034 |
| Connor | 7 | 7.034 | -0.034 |
| Deon | 10 | 7.034 | 2.966 |
| Christopher | 8 | 7.034 | 0.966 |
| Olga | 8 | 7.034 | 0.966 |
- Qs
- What are the (dis-)advantages of taking the mean as a predictive model? Is it a good predictive model?
- How could we assess whether the mean is a good predictive model? Do we need training and test data for that?
- In how for does the data determine whether the mean is a good predictive model?
Answer
- Q1
- Advantages: Simple, fast, works with sparse information (outcome only)
- Disadvantages: Potentially very biased/large errors
- Q2
- e.g., we can calculate the mean absolut error \((MAE)\)
- \(MAE = \frac{\sum_{i}^{n} |y_{i} - x_{i}|}{n} = \frac{\sum_{i}^{n} |\epsilon_{i}|}{n}\) where \(y_{i}\) = prediction, \(x_{i}\) = true value and \(n\) = total number of datapoints, \(\epsilon_{i}\) = error
- MAE = 1.69482
- How can we interprete the MAE?
- Yes, test data if we want to test how well the mean works for new unseen data
- e.g., we can calculate the mean absolut error \((MAE)\)
- Q3
- Mean can be very good if everyone lies close to the mean (e.g., mean age is 25 whereby all students are between 24 and 26 years old)
3 Training, validation and test dataset
3.1 Training, validation and test dataset: Single split
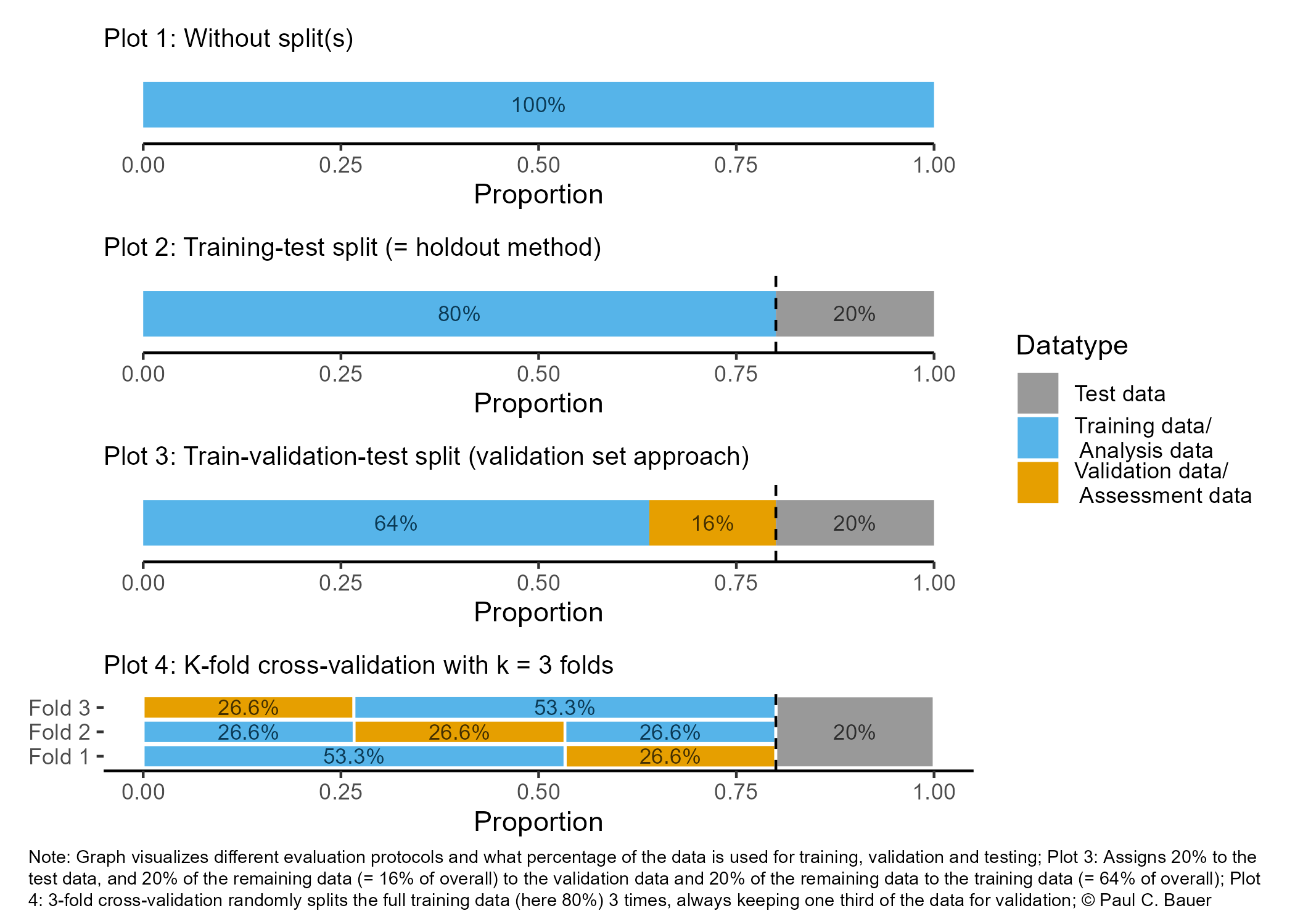
- As shown in Figure 2 when training models we sometimes…
- …only split into one training data subset, e.g., 80% of observations, and one test data subset, e.g., 20% of observations (cf. Plot 2)
- … introduce one further split (cf. Plot 3) - e.g., built models on training (analysis) dataset, validate/tune model using validation (assessment) dataset and use test dataset ONLY for final test
- …do resampling (see next slide!)
- As indicated in Figure 2, Plot 3 when doing further splitting the training data we can use the terms analysis and assessment dataset (Max Kuhn and Johnson 2019) (see also next slide)
3.2 Training, validation and test dataset: Resampling (several splits/folds)
- To avoid conceptual confusion we use the terminology by Max Kuhn and Johnson (2019) and illustrated in Figure Figure 3
- Datasets obtained from the initial split are called training and test data
- Datasets obtained from further splits to the training data are called analysis (analysis) and assessment (validation) datasets
- Often such further splits are called folds.

3.3 Training, validation and test dataset (3)
- Size of datasets: Usually 80/20 splits but depends..
- Q: What could be a problem if training and/or test dataset is too small? (thinking about uncertainty)
Answer
- Training data ↓ → Variance of parameter estimates ↑
- Test data ↓ → Variance of performance statistic ↑
4 Exercise: What’s predicted?
- Q: What do we predict using the techniques below? What is the input/what is the output? How could we use those ML models for research in our disciplines? (discuss 2!)
Answer
- Image recognition: Predict whether an image shows a sunsetSome examples
- Deepart: “Predict” what an image would look like if it was painted by…
- Speech recognition: Predict which (written) words someone just used
- Translation: Predict which English word/sentence corresponds to a German word/sentence (predict language!)
- Pose estimation (2018!): Predict body pose from image
- Deep fakes (2019): ?
- Text analysis/Natural language processing (NLP): Predict entities, sentiment, syntax, categories in text
5 Regression vs. Classification
Variables can be characterized as either quantitative or qualitative (= categorical)
Quantitative variables: Numerical values, e.g., person’s age, height, or income,
Qualitative variables: Values in one of K different classes, or categories
- e.g., a person’s gender (male or female)
Q: Are the following variables quantitative (A) or qualitative (B)?
- brand of product purchased, (2) wether a person defaults on a debt, (3) value of a house, (4) cancer diagnosis (Acute Myelogenous Leukemia, AcuteLymphoblastic Leukemia, or No Leukemia), (5) price of a stock
Problems with quantitative response = regression problems
Problems with qualitative response = classification problems
Distinction is not always crisp, e.g., logistic regression
- Typically used with a qualitative (two-class, or binary) response
- But estimates are class probabilities
Source: James et al. (2013, chap. 2.1.5)
5.1 Exercise: Classification or regression?
Classification problems occur often, perhaps even more so than regression problems, e.g., :
- A person arrives at the emergency room with a set of symptoms that could possibly be attributed to one of three medical conditions. Which of the three conditions does the individual have?
- An online banking service must be able to determine whether or nota transaction being performed on the site is fraudulent, on the basis of the user’s IP address, past transaction history, and so forth.
- On the basis of DNA sequence data for a number of patients with and without a given disease, a biologist would like to figure out which DNA mutations are deleterious (disease-causing) and which are not.
If we have a set of training observations (\(x_{1},y_{1}\)),…,(\(x_{n},y_{n}\)), we can build a classifier
Why not linear regression?
- No natural way to convert qualitative response variable with more than two levels into a quantitative response for LM
- e.g., 1 = stroke, 2 = drug overdose, 3 = epileptic seizure
- and linear probability model for binary outcome provides predictions outside of [0,1] interval (James et al. 2013, 131, Figure 4.2)
- No natural way to convert qualitative response variable with more than two levels into a quantitative response for LM
Source: James et al. (2013, chaps. 4.1, 4.2)
5.2 Classification: Two-class (binary) vs. multi-class problems
- Many classification involve several classes…
- …but can usually be reframed as (multiple) two-class
- e.g., Religion: Predicting whether someone is protestant vs. all others
- Logistic regression restricted to two-class problems by default
- Other models allow for predicting several classes (e.g., multinomial logistic regression)
6 Assessing Model Accuracy
6.1 Assessing Model Accuracy: Classification
- Accuracy or Correct Classification Rate (CCR), i.e., the rate of correctly classified test observations
- …the opposite of the error rate
- Training error rate: the proportion of mistakes that are made if we apply estimate to the training observations
- \(\frac{1}{n}\sum_{i=1}^{n}I(y_{i}\neq\hat{y}_{i})\): Fraction of incorrect classifications
- \(\hat{y}_{i}\): predicted class label for observation \(i\)
- \(I(y_{i}\neq\hat{y}_{i})\): indicator variable that equals 1 if \(y_{i}\neq\hat{y}_{i}\) (= error) and zero if \(y_{i}=\hat{y}_{i}\)
- If \(I(y_{i}\neq\hat{y}_{i})=0\) then the ith observation was classified correctly (otherwise missclassified)
- \(\frac{1}{n}\sum_{i=1}^{n}I(y_{i}\neq\hat{y}_{i})\): Fraction of incorrect classifications
- Test error rate: Associated with a set of test observations of the form (\(x_{0},y_{0}\))
- \(Ave(I(y_{0}=\hat{y}_{0}))\)
- \(\hat{y}_{0}\): predicted class label that results from applying the classifier to the test observation with predictor \(x_{0}\)
- \(Ave(I(y_{0}=\hat{y}_{0}))\)
- Good classifier: One for which the test error rate is smallest
- Further measures: Precision, recall (sensitivity), F1 score, ROC AUC
- Source: James et al. (2013, chap. 2.2.3)
More background
- Accuracy:
- Accuracy measures the proportion of correctly classified instances among the total instances.
- It is calculated as the number of correctly predicted instances divided by the total number of instances.
- Accuracy is a simple and intuitive metric, but it can be misleading, especially in imbalanced datasets where the classes are not evenly represented.
- Precision:
- Precision measures the proportion of true positive predictions among all positive predictions.
- It is calculated as the number of true positive predictions divided by the sum of true positive and false positive predictions.
- Precision focuses on the accuracy of positive predictions and is useful when the cost of false positives is high.
- Recall (Sensitivity):
- Recall measures the proportion of true positive predictions among all ACTUAL positive instances.
- It is calculated as the number of true positive predictions divided by the sum of true positive and false negative predictions.
- Recall focuses on capturing all positive instances and is important when the cost of false negatives is high.
- F1 Score:
- F1 score is the harmonic mean of precision and recall.
- It provides a balance between precision and recall, especially when there is an imbalance between the classes.
- F1 score is calculated as the harmonic mean of precision and recall: \(F1 = 2 \times \frac{precision \times recall}{precision + recall}\).
- F1 score ranges from 0 to 1, where 1 indicates perfect precision and recall, and 0 indicates poor performance.
Accuracy and area under the receiver operating characteristic curve (ROC AUC) often used for balanced-classification problems and precision-recall for class-imbalanced problems. Ranking problems or multilabel classification may require other measures.
6.2 Assessing Model Accuracy: Regression
- Mean squared error (James et al. 2013, Ch. 2.2)
- \(MSE=\frac{1}{n}\sum_{i=1}^{n}(y_{i}- \hat{f}(x_{i}))^{2}\) (James et al. 2013, Ch. 2.2.1)
- \(y_{i}\) is \(i\)s true outcome value
- \(\hat{f}(x_{i}) = \hat{y}_{i}\) is the prediction that \(\hat{f}\) gives for the \(i\)th observation
- MSE is small if predicted responses are to the true responses, and large if they differ substantially
- \(MSE=\frac{1}{n}\sum_{i=1}^{n}(y_{i}- \hat{f}(x_{i}))^{2}\) (James et al. 2013, Ch. 2.2.1)
- Training MSE: MSE computed using the training data
- Test MSE: How is the accuracy of the predictions that we obtain when we apply our method to previously unseen test data?
- \(\text{Ave}(y_{0} - \hat{f}(x_{0}))^{2}\): the average squared prediction error for test observations \((y_{0},x_{0})\)
- Further measures
- Mean absolute error (MAE): …no squaring as in MSE
- R-squared: See Definitions -> Figure
- Fundamental property of ML (cf. James et al. 2013, 31, Figure 2.9)
- As model flexibility increases, training MSE will decrease, but the test MSE may not (danger of overfitting)
- Q: Why?
- As model flexibility increases, training MSE will decrease, but the test MSE may not (danger of overfitting)
More background
- Difference Between MSE, MAE, and R-squared in Prediction Accuracy: MSE is suitable for applications where larger errors need to be penalized more, MAE is preferable when the emphasis is on the overall accuracy without sensitivity to outliers, and R-squared is useful for assessing the overall goodness of fit of the model. However, it’s often recommended to use multiple metrics together to get a comprehensive understanding of model performance.
- Mean Squared Error (MSE):
- MSE calculates the average squared difference between the actual values and the predicted values.
- It emphasizes larger errors due to the squaring operation, making it sensitive to outliers.
- It is differentiable, making it useful for optimization algorithms.
- It penalizes large errors more than smaller ones, which may not always be desirable depending on the application.
- MSE can be heavily influenced by outliers, making it less robust in the presence of outliers.
- Mean Absolute Error (MAE):
- MAE calculates the average absolute difference between the actual values and the predicted values.
- It provides a more balanced view of errors compared to MSE as it is not as sensitive to outliers.
- It is more interpretable than MSE since it’s in the same units as the original data.
- It treats all errors equally regardless of their magnitude, which may not reflect the actual importance of errors in some cases.
- MAE is not differentiable at zero, which can complicate optimization tasks.
- R-squared (Coefficient of Determination):
- R-squared measures the proportion of the variance in the dependent variable that is predictable from the independent variables.
- It provides an indication of the goodness of fit of the model.
- R-squared ranges from 0 to 1, where 1 indicates perfect prediction and 0 indicates no improvement over a baseline model (usually the mean of the dependent variable).
- It is scale-independent, making it easier to compare models across different datasets.
- R-squared can be misleading when used alone, especially with complex models, as it can increase even when adding irrelevant predictors (overfitting).
- It assumes that the relationship between the dependent and independent variables is linear, which may not always be the case.
7 Universal workflow of machine learning
- Source: Adapted from Chollet and Allaire (2018, 118f)
- Define the problem at hand and the data on which you’ll be training. Collect this data, or annotate it with labels if need be.
- Choose how you’ll measure success on your problem. Which metrics will you monitor on your validation data?
- Determine your evaluation protocol: hold-out validation? K-fold validation? Which portion of the data should you use for validation?
- Preparing/preprocess your data
- Develop a first model that does better than a basic baseline: a model with statistical power.
- Develop a model that overfits.
- Regularize your model and tune its hyperparameters, based on performance on the validation data.
- Final training (on all training + validation data) and model testing on unseen test dataset
Often Step 5, 6, and 7 are subsumed under one step Training & validation.
7.1 Step 1: Defining the problem and assembling a dataset (skipped)
What will your input data be? What are you trying to predict?
- We can only learn to predict something if we have available training data
- e.g., learning to classify sentiment of movie reviews only possible when both movie reviews and sentiment annotations are available
- Data availability usually limiting factor at this stage
- We can only learn to predict something if we have available training data
What type of problem are you facing? Binary classification? Multiclass classification? Regression?1
- This will guide your choice of model architecture, loss function (accuracy measure)
Hypotheses/Expectations: hypothesizing that our outputs can be predicted given our inputs, i.e., that available data is sufficiently informative
Nonstationary problems: Using data from 2018 to predict people’s life satisfaction.. what is the problem here?
More background
- Using ML trained on past data to predict the future is making the assumption that the future will behave like the past.
- More generally, we have to think about whether training data can be used to generalize to observations we want to predict.
- Can you think of more examples of where generalization may go wrong?
7.2 Step 2: Choosing a measure of success (skipped)
- To achieve (predictive) success, we must define what success means: accuracy? precision-recall? customer retention rate?
- The success metric will guide choice of loss function
- what your model optimizes should directly align with our higher-level goals
- The success metric will guide choice of loss function
- Metric of success and loss function can be the same, e.g., the MSE. The loss function is used during the training phase to optimize the model parameters (weights and biases) by minimizing the discrepancy between predicted and actual values. The final metric of success is calculated using the test data.
7.3 Step 3: Deciding on an evaluation protocol (skipped)
- Once measure of success (e.g., accuracy) is defined think about how to measure our progress
- Three common evaluation protocols
- Maintaining a hold-out validation set (good if you have plenty of data)
- Doing K-fold cross-validation (good choice if you have too few data points for hold-out validation to be reliable)
- iterated K-fold validation (when little data is available)
- Often 1. is sufficient
7.4 Step 4: Preparing/preprocess your data (skipped)
- Next step is to format data so it can be fed into our model
- Involves recoding variables etc. (e.g., think about how to code education variable)
- Sometimes we need to prepare text data
- Feature engineering might also be necessary
7.5 Step 5: Develop model that does better than a baseline (skipped)
- Goal: achieve statistical power, develop small model capable to beat dumb baseline
- Often baseline is coinflip, i.e., 50% success rate (or the mean if continuous outcome)
- Two hypotheses:
- We’re hypothesizing that your outputs can be predicted given your inputs
- We’re hypothesizing that the available data is sufficiently informative to learn the relationship between inputs and outputs
- Hypotheses could be false
7.6 Step 6: Scaling up: developing a model that overfits (skipped)
- Monitor training loss and validation loss, as well as the training and validation values for any metrics you care about
- Start by trying to maximize accuracy in your training dataset, i.e., achieving best predictions possible
- When model’s performance on the validation data begins to degrade, you’ve achieved overfitting
7.7 Step 7: Regularizing your model and tuning your hyperparameters (skipped)
- Attention: every time you use feedback from your validation process to tune your model, you leak information about the validation process into the model
- Repeated a few times, this is no problem; but done systematically over many iterations, it will eventually cause your model to overfit to the validation process (even though no model is directly trained on any of the validation data)
- This makes the evaluation process less reliable
7.8 Step 8: Final training and testing on unseen data (skipped)
- Once model has been validated, we can train our final production model on all the available data (training and validation)
- Then we evaluate it one last time on the test dataset
- If performance on test set is significantly worse than performance measured on validation data, this may mean either that your validation procedure wasn’t reliable after all, or that you started overfitting to the validation data while tuning the parameters of the model
- e.g., choose a more reliable evaluation protocol(such as iterated K-fold validation).
8 Prediction models (general form)
8.1 Prediction: Model (general form)
- cf. James et al. (2013, 16–21)
- Output variable \(Y\), e.g., life satistfaction, trust, unemployment, recidivism
- Often called the response/dependent variable
- Input variable(s) \(X\) (usually with subscript, e.g., \(X_{1}\) is education)
- Usually called predictors/independent variables/features
- Example
- Quantitative response \(Y\) and \(p\) different predictors, \(X_{1},...,X_{p}\)
- We assume a relationship between output \(Y\) and inputs \(X = X_{1},...,X_{p}\)
- can be written generally as \(Y = f(X) + \varepsilon\)
- \(f\) represents the systematic information that \(X\) provides about \(Y\)
- \(\varepsilon\) is a random error term which is independent of \(X\) and has mean zero
- can be written generally as \(Y = f(X) + \varepsilon\)
8.2 Prediction: Why estimate \(f\) (model)?
Pertains to class distinction discussed in (Breiman 2001; James et al. 2013, 17–19)
Prediction: In many situations, a set of inputs \(X\) readily available, but output \(Y\) cannot be easily obtained
- In this setting, since the error term averages to zero, we can predict \(Y\) using \(\hat{Y} = \hat{f}(X)\)
- where \(\hat{f}\) represents our estimate for \(f\), and \(\hat{Y}\) represents the resulting prediction for \(Y\)
- \(f\) is “true” function that produced \(Y\), e.g., “true” function/model that produces life satisfaction
- \(f\) is often treated as a black box, i.e., typically we are less concerned with exact form of \(\hat{f}\) provided that the predictions are accurate
- In this setting, since the error term averages to zero, we can predict \(Y\) using \(\hat{Y} = \hat{f}(X)\)
Inference: Understand the relationship between \(Y\) and \(X\) (see corresponding questions in James et al. (2013, 19–20))
8.3 Prediction: Accuracy
- Accuracy of \(\hat{Y}\) as prediction for \(Y\) depends on two quantities
- reducible error (introduced by innaccuracy of \(\hat{f}\)) and the irreducible error (associated with \(\varepsilon\))
- \(\hat{f}\) will not be a perfect estimate of \(f\) but introduce error
- This error is reducible because we can potentially improve the accuracy of \(\hat{f}\) by using the most appropriate statistical learning technique to estimate \(f\)
- But even with perfect estimate of \(f\) (estimate response with form \(\hat{Y} = f (X)\)) error remains because \(Y\) is also function of \(\varepsilon\) that cannot be predicted using \(X\)
- Variability associated with \(\varepsilon\) also affects predictions and is called irreducible error
- Q: Why is the irreducible error (always) larger than 0?
Answer
The quantity \(\varepsilon\) may contain unmeasured variables that are useful in predicting \(Y\): since we don’t measure them, \(f\) cannot use them for its prediction. The quantity may also contain unmeasurable variation (James et al. 2013, 18–19).
Irreducible error will always provide an upper bound on the accuracy of our prediction for Y. This bound is almost always unknown in practice since we may not have measured/know the necessary features/predictors. (James et al. 2013, 19)
8.4 Prediction: How Do We Estimate f?
We estimate \(f\) using the training data (James et al. 2013, 21–24)
Parametric methods with two-step approach (James et al. 2013, 21–24)
- Make assumption about the functional form of \(f\), or shape, e.g., linear model
- Train or fit the model, e.g., most common method for linear model is (ordinary) least squares
- “parametric” because assumpions about data distribution (e.g., linear) and reduces problem of estimating \(f\) down to estimating a set of parameters, e.g., coefficients of linear model
- Potential disadvantage
- the model we choose will usually not match the true unknown form of \(f\)
- if too far from true \(f\) then estimate will be poor
- Flexible models can fit many different function forms for \(f\) but require estimating more parameters but increase danger of overfitting (Q: Overfitting?)
Non-parametric methods (e.g. random forests)
- Do not make explicit assumptions about the functional form of \(f\)
- Seek estimate of \(f\) that gets as close to the data points as possible without being too rough or wiggly
8.5 Trade-Off(s): Prediction Accuracy vs. Model Interpretability
- Some ML methods are more some are less flexible (shape of f), e.g., linear model
- James et al. (2013, 25), Fig. 2.7. provides an overview
- Q: Why would we ever choose to use a more restrictive method (less flexible) model instead of a very flexible approach?
Answer
- Inference: If main goal is inference, restrictive models are much more interpretable. Linear model may be a good choice since it will be quite easy to understand the relationship between \(Y\) and \(X_{1}, ..., X_{p}\)
- Prediction
- High flexibility can also yield worse predictions because of overfitting (counterintuitive!)
- Debate around interpretable machine learning: Sometime we would like to know why a model predicts well (which features matter how much!)
9 Bias/variance trade-off and accuracy
Learning outcomes/objective: Learn/understand…
- …bias-variance trade-off.
9.1 Bias-variance trade-off
- See James et al. (2013, Ch. 2.2.2)
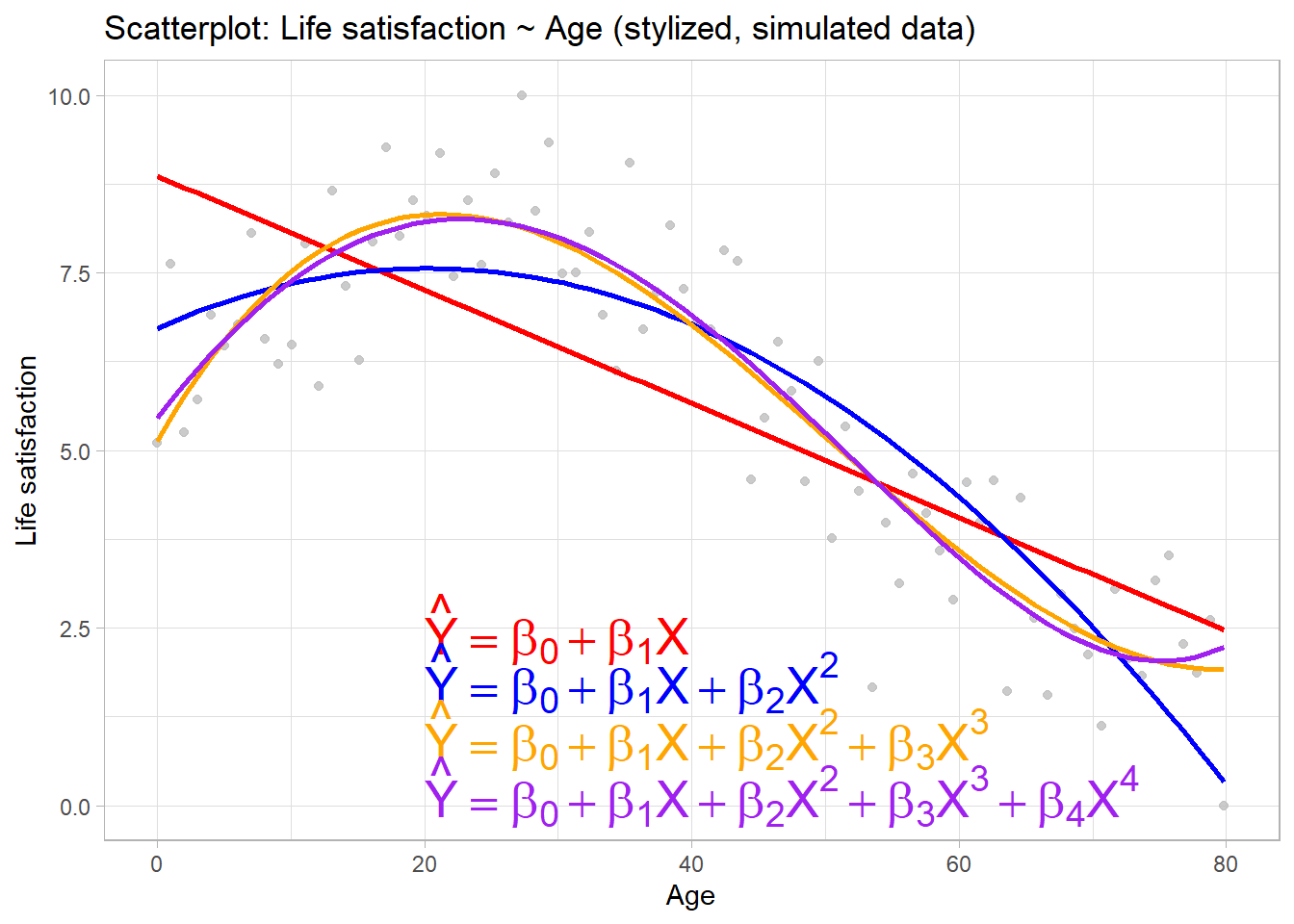
- Figure 4 shows an increasingly flexible model (linear model + polynomials)
9.1.1 Bias-variance trade-off (1)
- James et al. (2013) introduce bias-variance trade-off before turning to classification
- What do we mean by the variance and bias of a statistical learning method? (James et al. 2013, Ch. 2.2.2)
- Variance refers to amount by which \(\hat{f}\) would change if estimated using a different training data set
- Ideally estimate for \(f\) should not vary too much between training sets
- If method has high variance then small changes in training data can result in large changes in \(\hat{f}\)
- More flexible methods/models usually have higher variance
- Bias refers to the error that is introduced by approximating a (potentially complicated) real-life problem (=\(f\)) through a much simpler model
- e.g., linear regression assumes linear relationship between \(Y\) and \(X_{1},X_{2},...,X_{p}\) but unlikely that real-life problems truly have linear relationship producing bias/error
- e.g., predict life satisfaction \(Y\) with age \(X\)
- If true \(f\) is substantially non-linear, linear regression will not produce accurate estimate \(\hat{f}\) of \(f\), no matter how many training observations,
- Variance refers to amount by which \(\hat{f}\) would change if estimated using a different training data set
9.1.2 Bias-variance trade-off (2)
- Variance: error from sensitivity to small fluctuations in the training set
- High variance may result from an algorithm modeling the random noise in the training data (overfitting)
- Bias error: error from erroneous assumptions in the learning algorithm (\(\hat{f}\)) about \(f\)
- High bias can cause an algorithm to miss relevant relations between features and target outputs (underfitting)
- Bias-variance trade-off: Property of model that variance of parameter(s) estimated across samples can be reduced by increasing the bias in the estimated parameters
- e.g., we may choose linear model with higher bias to decreas variance
- Bias-variance dilemma/problem: Trying to simultaneously minimize these two sources of error that prevent supervised learning algorithms from generalizing beyond their training set
9.1.3 Bias-variance trade-off (3)
- “General rule”: with more flexible methods, variance will increase and bias will decrease
- Relative rate of change of these two quantities determines whether test MSE (regression problem) increases or decreases
- As we increase flexibility of a class of methods, bias tends to initially decrease faster than the variance increases
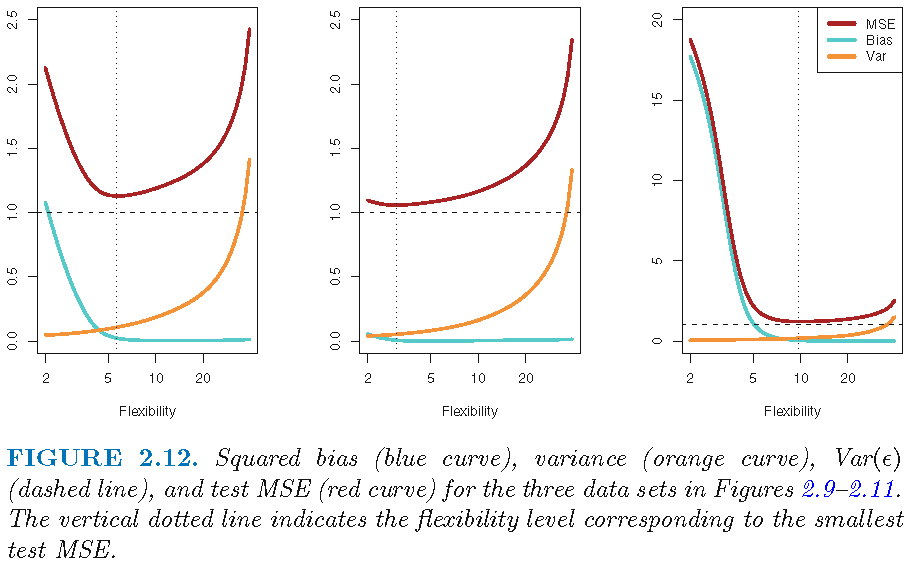
- Consequently, the expected test MSE declines as shown in Figure 5.
- Q: What does Figure 5 illustrate and which level of flexibility would be desirable?
Answer
- Figure 5 visualizes squared bias, variance and MSE as a function of flexibility. We would normally pick a flexibility leel that minimizes all three of them (indicated by the vertical dashed line).
9.1.4 Bias-variance trade-off (4)
- Good test set performance requires low variance as well as low squared bias
- Trade-off because easy to obtain method with…
- …extremely low bias but high variance
- e.g., just draw a curve that passes through every single training observation
- …very low variance but high bias
- e.g., by fitting a horizontal line to the data
- …extremely low bias but high variance
- Trade-off because easy to obtain method with…
- Challenge lies in finding a method for which both the variance and the squared bias are low
- This idea will return throughout the semester!
- In real-life situation \(f\) is unobserved hence not possible to compute test MSE, bias, or variance for a statistical learning method (because we fit our model to the training data not the test data!)
- But good to keep in mind and later on we discuss methods to estimate test MSE using training (cross-validation!)
9.2 Exercise 1
Adapted from James et al. (2013, Exercise 2.4.1): Thinking of our classification problem (predicting recidivism, i.e., whether a prisoner reoffends), indicate whether we would generally expect the performance of a flexible statistical learning method to be better or worse than an inflexible method. Justify your answer.
- The sample size \(n\) is extremely large, and the number of predictors \(p\) is small.
- The number of predictors \(p\) is extremely large, and the number of observations \(n\) is small.
- The relationship between the predictors and response is highly non-linear.
- The variance of the error terms, i.e. \(\sigma^{2}=Var(\epsilon)\), is extremely high.
Answer
- Flexible is better since there is less room for adaption to outliers!
- Flexible is worse since function will adapt non-typical outliers!
- Flexible is better because the function should adapt the non-linear true function f.
- Flexible is probably better because it would better adapt to the high variance, i.e., high variance seems to indicate that non-flexible model is not a good approximation of f.
9.3 Exercise 2 (skipped)
James et al. (2013, Exercise 2.4.2): Explain whether each scenario is a classification or regression problem, and indicate whether we are most interested in inference or prediction. Finally, provide \(n\) and \(p\).
- We collect a set of data on the top 500 firms in the US. For each firm we record profit, number of employees, industry and the CEO salary. We are interested in understanding which factors affect CEO salary.
- We are considering launching a new product and wish to know whether it will be a success or a failure. We collect data on 20 similar products that were previously launched. For each product we have recorded whether it was a success or failure, price charged for the product, marketing budget, competition price, and ten other variables.
- We are interesting in predicting the % change in the US dollar in relation to the weekly changes in the world stock markets. Hence we collect weekly data for all of 2012. For each week we record the % change in the dollar, the % change in the US market, the % change in the British market, and the % change in the German market.
Answer
- Regression problem; Inference; n = 500; p = 3 (profit, number of employees, industry)
- Classification problem; Prediction; n = 20; p = 14 (success or failure, price charged for the product, marketing budget, competition price, and ten other variables)
- Regression problem; Prediction; n = 52; p = 4; (% change in the dollar, the % change in the US market, the % change in the British market, and the % change in the German market)
10 Tidymodels & packages

- See github website.
10.1 Overview of packages
- A collection of packages for modeling and machine learning using tidyverse principles (see Barter (2020), M. Kuhn and Wickham (2020) and M. Kuhn and Silge (2022) for summaries)
- Much like
tidyverse,tidymodelsconsists of various core packages:rsample: for sample splitting (e.g. train/test or cross-validation)- provides functions to create different types of resamples and corresponding classes for their analysis
initial_split: Use this to split the data into training and test data (with argumentsprop,strata)prop-argument: Specify share of training data observationsstrata-argument: Conduct stratified sampling on the dependent variable (better if classes are imbalanced!)training(),testing(),analysis()andassessment()can be used to extract the corresponding datasets from anrsplitobjectvalidation_split: Split the training data into analysis data (= training data) and assessment data (= validation data)- Later we’ll explore more functions such as
vfold_cv
- Later we’ll explore more functions such as
recipes: for pre-processing- Use dplyr-like pipeable sequences of feature engineering steps to get your data ready for modeling.
parsnip: specifying the model namely model type, engine and mode- Goal: provide a tidy, unified interface to access models from different packages
model type-argument: e.g, linear or logistic regressionengine-argument: R packages that contain these modelsmode-argument: either regression or classification
tune: for model tuning- Goal: facilitate hyperparameter tuning. It relies heavily on
recipes,parsnip, anddialsdials: contains infrastructure to create and manage values of tuning parameters
- Goal: facilitate hyperparameter tuning. It relies heavily on
yardstick: evaluate model accuracy- Goal: estimate how well models are working using tidy data principles
conf_mat(): calculates cross-tabulation of observed and predicted classesmetrics(): estimates 1+ performance metrics
workflowsets:- Goal: allow users to create and easily fit a large number of different models.
- Use
workflowsetsto create aworkflow setthat holds multipleworkflow objects- These objects can be created by crossing all combinations of preprocessors (e.g., formula, recipe, etc) and model specifications. This set can be tuned or resampled using a set of specific functions.
10.2 ML workflow using tidymodels
| Data resampling, feature engeneering | Model fitting, tuning | Model evaluation |
|---|---|---|
| rsample | tune | yardstick |
| recipes | parsnip | |
| dials |
11 Appendix
11.1 Appendix: Mean as ML model?
- If we were to follow a machine learning logic we would proceed as follows:
- Step 1: Split data shown in Figure 1 into two subsets: training and test data
- Step 2: Train model, i.e., calculate the mean of life_satisfaction for training dataset
- Step 3: Check accuracy of model in training dataset (calculate the average error)
- Step 4: Check accuracy in test dataset (calculate the average error)
- Step 5: If happy we could use our model (life_satisfaction mean from training dataset) to predict, e.g., missings in the data on the variable life_satisfaction
# install.packages("rsample")
library(rsample)
library(tidyverse)
# Load dataset
load(url(sprintf("https://docs.google.com/uc?id=%s&export=download",
"173VVsu9TZAxsCF_xzBxsxiDQMVc_DdqS")))
# Set seed
set.seed(42) # Why?
# Step 1
# Create a split object (?initial_split)
data_split <- initial_split(data, prop = 0.80)
data_split<Training/Testing/Total>
<1581/396/1977># Extract training dataframe
data_training <- training(data_split)
# Extract test dataframe
data_test <- testing(data_split)
# Check dimensions of the two datasets
dim(data_training)[1] 1581 346[1] 396 346# Step 2
# Estimate our model (the mean in the test data)
test_data_mean <- mean(data_training$life_satisfaction, na.rm=TRUE)
# Step 3
data_training <- data_training %>%
mutate(prediction = test_data_mean) %>% # Append predictions
mutate(error = prediction - life_satisfaction)
# Attention
mean(abs(data_training$error), na.rm=TRUE) # MAE: Check accuracy in training data[1] 1.67641# Step 4
data_test <- data_test %>%
mutate(prediction = test_data_mean) %>% # Append predictions
mutate(error = test_data_mean - life_satisfaction)
mean(abs(data_test$error), na.rm=TRUE) # MAE: Check accuracy in training data[1] 1.7711311.2 Appendix: Class imbalance & oversampling
- Class imbalance may create several problems..
- Bias in model performance towards the majority class due to insufficient learning from the minority class due to limited representation
- Misleading evaluation metrics that prioritize accuracy and overlook minority class performance
- Sensitivity to sampling and data distribution, leading to unreliable performance evaluation
- Increased false positives or false negatives, impacting decision-making in critical domains
tidymodelsprovides different step functions to tackle class imbalance such asstep_upsample()- creates a specification of a recipe step that will replicate rows of a data set to make the occurrence of levels in a specific factor level equal (see
?step_upsample)
- creates a specification of a recipe step that will replicate rows of a data set to make the occurrence of levels in a specific factor level equal (see
- Further reading: Google intro to imbalanced data
11.3 Appendix: Stratified splitting
- Stratified splitting: involves preserving the class distribution in each split of the dataset.
- We may use it to preserve class representation, i.e., assure the sample representativity of each class after splitting which has several advantages
- Preserves class representation in each split of the dataset, ensuring that each split contains a proportionate representation of different classes, which helps prevent bias and allows the model to learn from and generalize to all classes effectively.
- Improves generalization performance by training and evaluating on representative data, as the stratified splitting ensures that the model is exposed to a diverse range of instances from each class, allowing it to learn patterns and relationships that are representative of the real-world distribution and make more accurate predictions on unseen data.
- Provides a reliable evaluation, especially with imbalanced datasets, by ensuring that the performance assessment is based on a representative sample from each class. This prevents unreliable performance metrics that may result from a random split where the testing set lacks sufficient representation of minority classes.
- Enhances model fairness by maintaining proportional class representation, preventing the model from favoring or neglecting certain classes during training and evaluation. By ensuring that all classes are equally represented in the splits, the model can be developed to treat all classes fairly and make unbiased predictions.
- Facilitates consistent experimentation and fair model comparisons by using the same stratification scheme across multiple experiments. This ensures that different models or algorithms are evaluated on comparable splits, enabling reliable and meaningful comparisons of their performance in handling class imbalance and capturing patterns across all classes.
- We may use it to preserve class representation, i.e., assure the sample representativity of each class after splitting which has several advantages
set.seed(123) # Why?
# Split the data into training and test data statifying for life_satisfaction
data_split <- initial_split(data, prop = 0.8, strata = life_satisfaction)
data_split # Inspect<Training/Testing/Total>
<1580/397/1977>
0 1 2 3 4 5 6 7 8 9 10
27 14 39 42 62 129 131 254 375 170 172
0 2 3 4 5 6 7 8 9 10
7 4 8 14 41 39 70 90 43 41
0 1 2 3 4 5 6 7 8 9 10
0.019 0.010 0.028 0.030 0.044 0.091 0.093 0.180 0.265 0.120 0.122
0 2 3 4 5 6 7 8 9 10
0.020 0.011 0.022 0.039 0.115 0.109 0.196 0.252 0.120 0.115 # Split the data into training and test data statifying for female
data_split <- initial_split(data, prop = 0.8, strata = female)
data_split # Inspect<Training/Testing/Total>
<1581/396/1977>
0 1
0.493 0.507
0 1
0.492 0.508 # Split the data into training and test data statifying for unemployed
data_split <- initial_split(data, prop = 0.8, strata = unemployed)
data_split # Inspect<Training/Testing/Total>
<1581/396/1977>
0 1
0.981 0.019
0 1
0.99 0.01 strata = ...: A variable used to conduct stratified sampling. When not NULL, each resample is created within the stratification variable. Numeric strata are binned into quartiles.- This can help ensure that the resample(s) has/have equivalent proportions as the original data set.
- For a categorical variable, sampling is conducted separately within each class.
- For a numeric stratification variable, strata is binned into quartiles, which are then used to stratify. Strata below 10% of the total are pooled together
- This can help ensure that the resample(s) has/have equivalent proportions as the original data set.
11.4 Fundstücke/Finding(s)
- There is a new pipe..
|>instead of%>%(e.g., blog post)|>does not rely onmagrittrpackage
- Is the glass half empty or half full?
- How AI experts are using GPT-4: Can anyone do a presentation on GPT-4 and the paper below? (functioning, use-cases)
- GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
- See Table 11, page 30
- See Table 11, page 30
- Are Translators Afraid of Artificial Intelligence? (Kirov and Malamin 2022)
References
Barter, Rebecca. 2020. “Tidymodels: Tidy Machine Learning in R.” https://www.rebeccabarter.com/blog/2020-03-25_machine_learning/#what-is-tidymodels.
Breiman, Leo. 2001. “Statistical Modeling: The Two Cultures (with Comments and a Rejoinder by the Author).” SSO Schweiz. Monatsschr. Zahnheilkd. 16 (3): 199–231.
Chollet, Francois, and J J Allaire. 2018. Deep Learning with R. 1st ed. Manning Publications.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning: With Applications in R. Springer Texts in Statistics. Springer.
Kirov, V, and B Malamin. 2022. “Are Translators Afraid of Artificial Intelligence?” Societies.
Kuhn, Max, and Kjell Johnson. 2019. Feature Engineering and Selection: A Practical Approach for Predictive Models. CRC press (Taylor & Francis).
Kuhn, M, and J Silge. 2022. “Tidy Modeling with R.”
Kuhn, M, and H Wickham. 2020. “Tidymodels: A Collection of Packages for Modeling and Machine Learning Using Tidyverse Principles.” Boston, MA, USA.
Footnotes
Scalar regression? Vector regression? Multilabel classification? Something else, like clustering, generation, or reinforcement learning?↩︎