2.4 Polígono de frecuencias
Los datos también de pueden visualizar con un polígono de frecuencias. En este tipo de visualización ponemos un punto en la intersección de la nota (eje horizontal) y la frecuencia (eje vertical) y trazamos una linea entre los puntos. Una de las ventajas de este tipo de visualización es que facilita la comparación entre varias distribuciones ya que los podemos desplegar en un mismo diagrama.
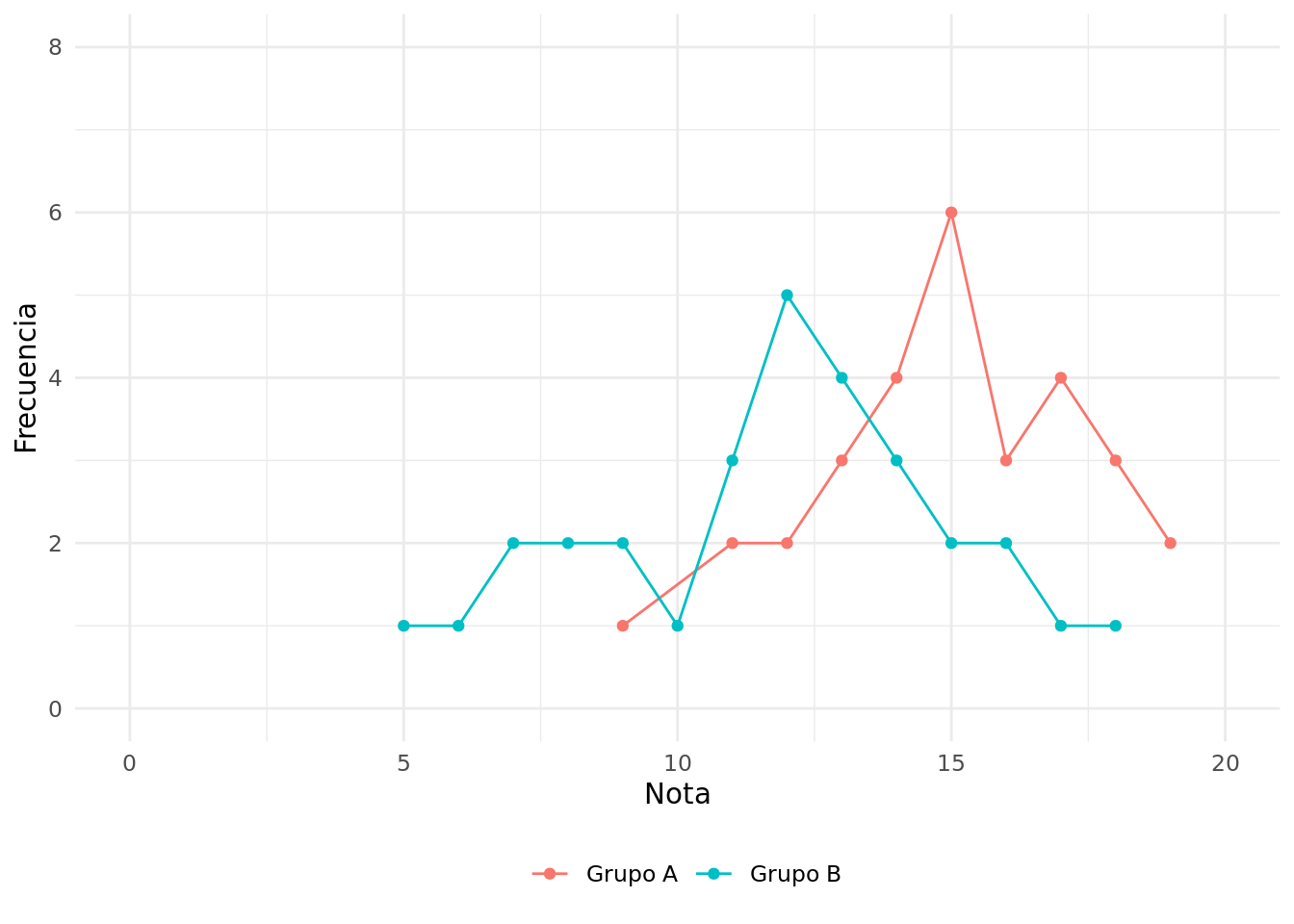
Figura 2.1: Polígono de frecuencias de notas obtenidas por dos grupos de estudiantes
Apreciamos con más precisión los valores más típicos y diferencias entre los dos grupos. También podemos ver que la parte inferior de la escala de notas está sin uso, característica que comparten ambos grupos.
Otro ejemplo
En este ejemplo vamos a considerar un libro de la literatura romántica: «Persuasion» escrito por Jane Austen (Austen 1817)7. Vamos a visualizar el número de caracteres por palabra en el texto. Obtenemos:
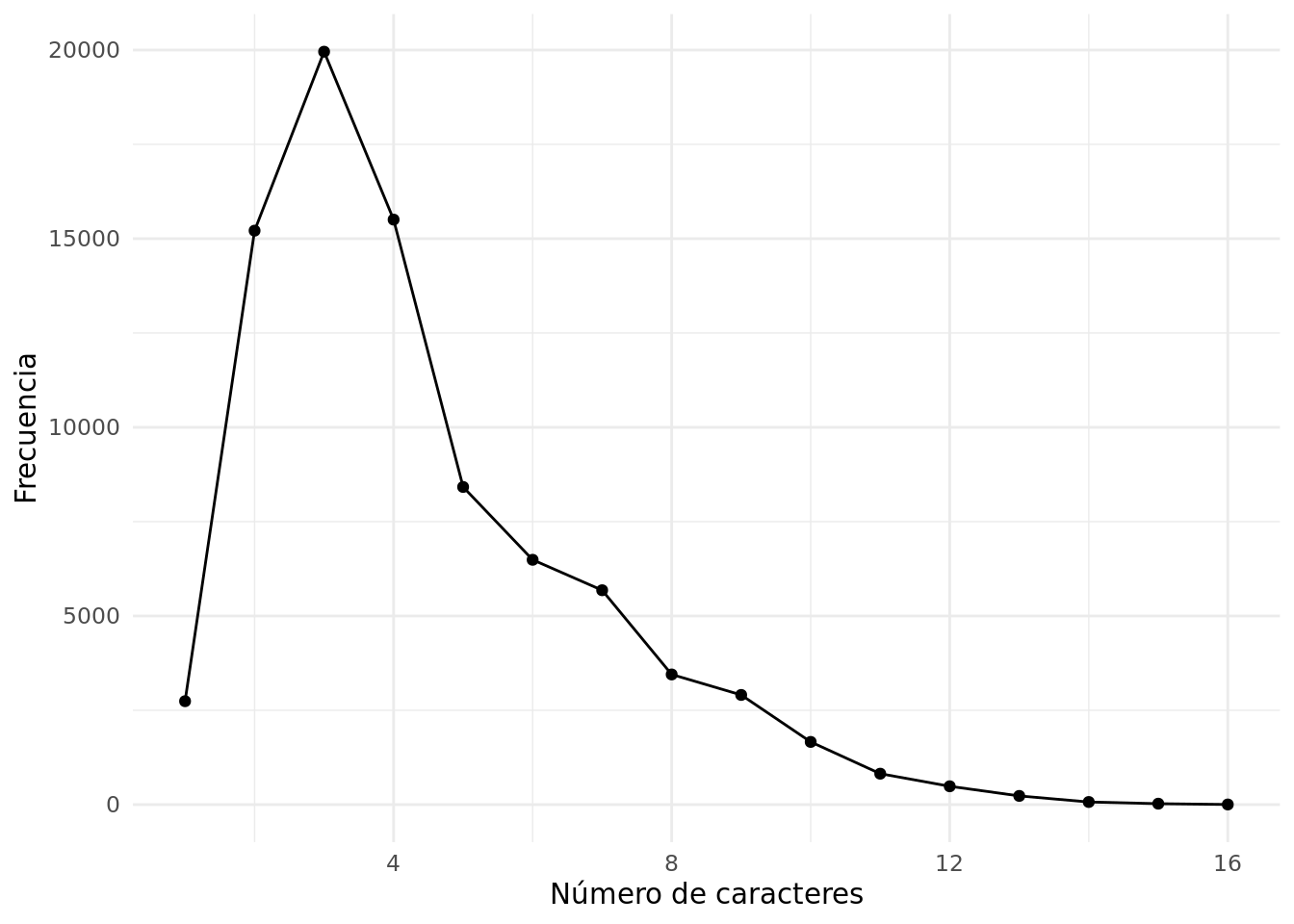
Figura 2.2: Polígono de frecuencias del largo de palabras en un texto de Austin
A differencia de la distribución de notas, vemos acá que encontramos observaciones a lo largo del rango de uno a deciseis, con la concentración de valores alrededor de tres. Esto tiene su interpretación bastante intuitiva ya que el uso de palabras cortas, como son artículos, preposiciones y conjunciones abundan en cuanquier texto y las palabras muy largas son de uso menos frecuente. Resulta lógico suponer que encontraríamos un perfil similar en cualquier texto de cierta longitud.
Referencias
El texto está disponible online y en el paquete de R «tidytext» (Silge and Robinson 2016)↩︎