3.1 Centralización
La centralización o tendencia central de un conjunto de datos es uno o un número reducido de valores que representan todo el conjunto.
Existen tres medidas de centralicación: la media, la mediana y la moda. A continuación las vamos a definir y ver cómo se calculan y luego vamos a considerar cuándo se debe usar cada una de ellas.
3.1.1 La media
La media es seguramente la medida de centralización de uso más frecuente.8 Se conoce también como el promedio y, más técnicamente, la media arithmetica. La media se obtiene por la suma de las observaciones dividido por el número de observaciones. Por ejemplo si queremos sacar el promedio de seis observaciones de una variable: 15, 12, 11, 18, 15 y 15; tenemos:
\[\begin{equation} {{15 + 12 + 11 + 18 + 15 + 15}\over{6}}={86\over6}=14,33 \tag{3.1} \end{equation}\]
En el caso de nuestra muestra de notas para de capítulos anteriores tenemos:
\[\begin{equation} {{ 15 + 12 + 11 + 18 + 15 + 15+ \\ 9 + 19 + 14 + 13 + 11 + 12 + \\ 18 + 15 + 16 + 14 + 16 + 17 + \\ 15 + 17 + 13 + 14 + 13 + 15 + \\ 17 + 19 + 17 + 18 + 16 + 14}\over{30}}={448\over30}=14.93 \tag{3.2} \end{equation}\]
Ya con el cómputo en (3.2) nos damos cuenta de que si bien es posible hacer estos cálculos a mano puede resultar bastante engorroso. Además con tantos números dando vuelta sube la probabilidad de un error de tipeo y con lo cual sacaríamos un resultado incorrecto.
Por suerte es bastante sencillo sacar la media con R. Para los dos ejemplos anteriores tenemos:
x = c(15, 12, 11, 18, 15 , 15)
mean(x)## [1] 14.33333y
notas = c(15, 12, 11, 18, 15, 15, 9, 19, 14, 13, 11, 12, 18,
15, 16, 14, 16, 17, 15, 17, 13, 14, 13, 15, 17, 19,
17, 18, 16, 14)
mean(notas)## [1] 14.93333Notación matemática
En textos de matemática y estadística se usa con frecuencia llaves para significar un conjunto, de modo que los datos del primer conjunto se expresaría así: x = {15, 12, 11, 18, 15 , 15}.
Una notación compacta para significar la suma de las observaciones en una variable es \(\Sigma\): la letra griega sigma, en mayúscula.
Para significar el número de observaciones de usa N, de número.
Así se puede definir la media de manera compacta así: \[ {\Sigma{x}}\over{N} \]
También se usa una barra vertical sobre el nombre de la variable para significar la media (o promedio aritmético): por ejemplo: \[\bar{x} = 14,33\]
Entonces en general tenemos:
que se podría leer: «la media de equis es igual a la suma de las observaciones de equis sobre el número de observaciones».
3.1.2 La mediana
Otra medida de centralización es la mediana (también: valor mediano). Para obtenerla ponemos nuestros datos en orden ascendiente y sacamos el valor que está justo en la mitad. Por ejemplo: si queremos sacar la mediana de {15, 12, 11, 18, 15, 15, 9}, primero los ordenamos: {9, 11, 12, 15, 15 ,15, 18}. Vemos que hay siete observaciones con lo cual la mediana es la observación que está en cuarta posición, es decir que la mediana de estos datos es 15. Si el conjunto de datos tiene un número par de observaciones, no va a haber una observación justo en el medio. En ese caso se toman los dos valores del medio, se los suma y se divide por dos9. Por ejemplo: {8, 8, 9, 11, 12, 15, 15 ,15}. Acá tenemos ocho observaciones (ya ordenados) tomamos los dos valores de la posición cuarta y quinta, los sumamos y dividimos por dos: \({11+12\over2}=11,5\).
Notación matemática
El valor mediano, o la mediana, se denota en notación matemática con una tilde como la que se usa en la letra ñ en español. Al igual que la barra para la media, se coloca por encima de la variable, así: \[\huge{\tilde{x}}\].
Al igual que la media podemos sacar la mediana de forma sencilla con R con la función median.
x = c(9, 11, 12, 15, 15 ,15, 18)
median(x)## [1] 15y
x = c(8, 8, 9, 11, 12, 15, 15 ,15)
median(x)## [1] 11.53.1.3 La moda
La moda es la observación más frecuente del conjunto. Por ejemplo: {9, 11, 12, 15, 15 ,15, 18}. El valor 15 es la moda de estos datos.
A diferencia de las otras medidas de centralidad la moda no necesariamente es un valor único. Si tuviéramos por ejemplo: {2, 4, 5, 7, 7, 7, 9, 11, 12, 15, 15, 15, 18} hay dos valores con la misma frecuencia máxima. Tanto 7 como 15 aparecen tres veces. En este caso hay dos modas y hablamos de una distribución bimodal.
Vemos un ejemplo en el gráfico que sigue.
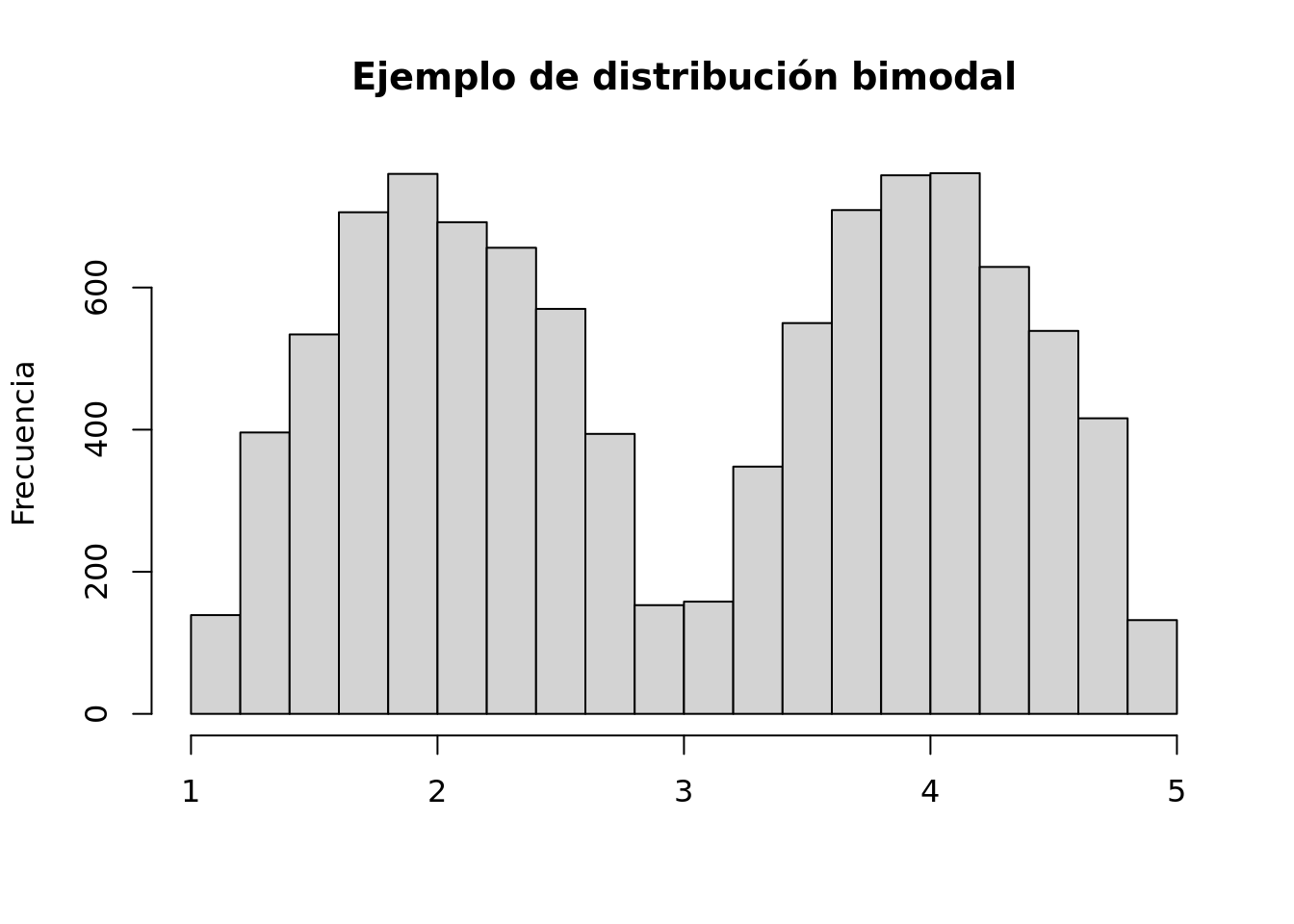
3.1.4 ¿Cuál usar?
La selección de una medida de centralización depende de varios factores:
- La escala de medición de la variable (nominal, ordinal, de intervalo o de razón)
- La forma de la distribución - si hay sesgo o no
- Para qué vamos a usar la medida.
La media debería usarse solo para variables de escala de intervalo o de razón. Si los datos son ordenables, pero sin que se pueda hablar de distancias reales entre los datos la mediana es más apropiada. Y en los casos donde ni esto es posible la moda puede ser la única medida disponible. Por ejemplo: si decimos que Italia es un país católico estamos expresando la moda de la variable nominal «religión», y si decimos que Alemania es un país católico y protestante estamos expresando una distribución bimodal de la misma variable. Podemos observar en el gráfico que en realidad se podría hablar incluso de una distribución trimodal.
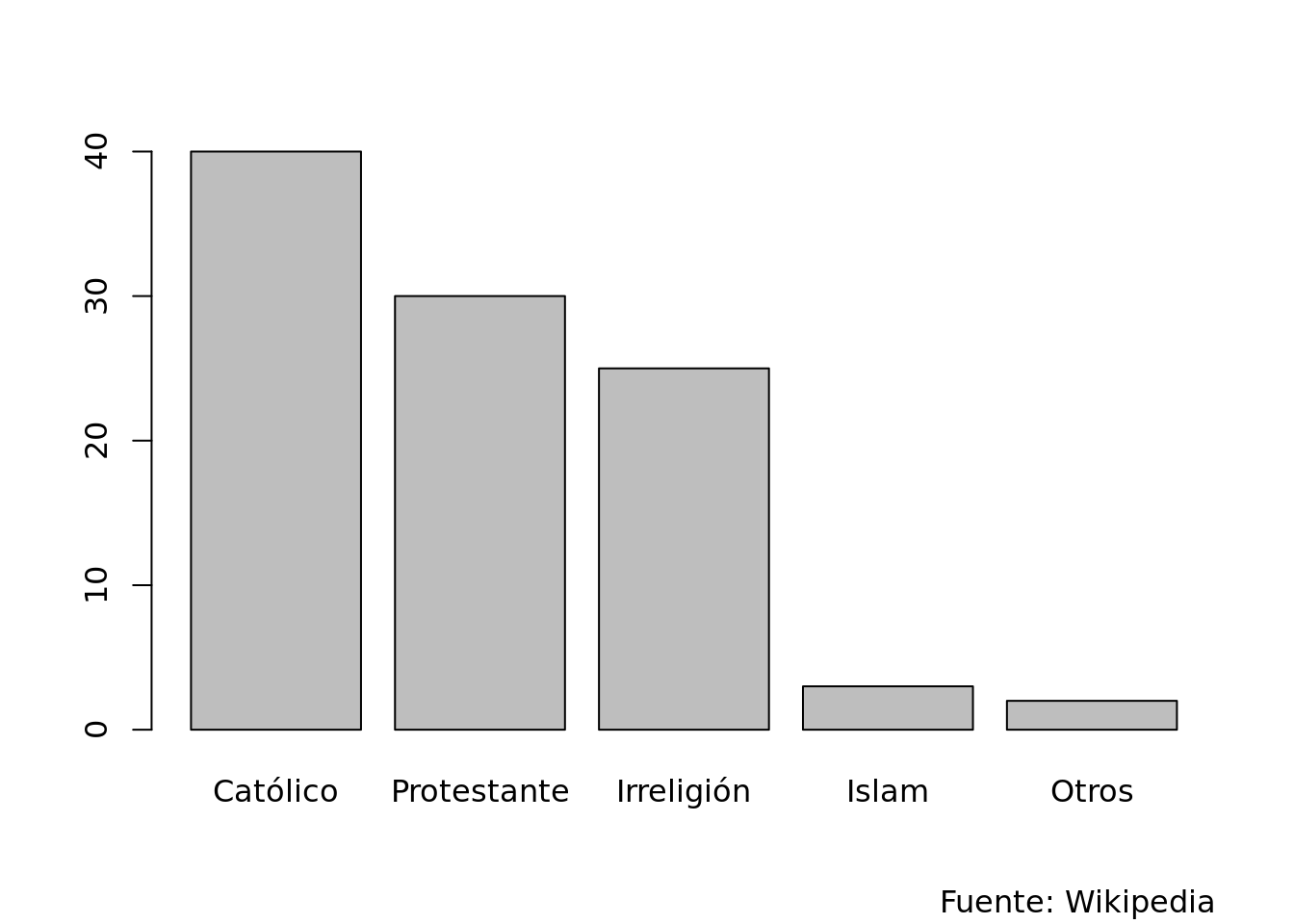
Figura 3.1: Religión en Alemania
En cuanto a la forma de la distribución se favorece la mediana por sobre la media si la distribución es muy sesgada. Esto ocurre sobre todo si hay valores extremos o atípicos. Por ejemplo si tenemos los datos: {15, 12, 11, 18, 15, 15, 200} está claro que si calculamos la media el valor extremo (200) va influir mucho más que cualquier otra observación. En este caso la media es 40,85 y el mediano 15. El primer valor (40,85) no es muy representativo de la muestra ya que no corresponde a ninguna observación y está lejos de cualquiera de ellas. El mediano, en cambio, puede resultar una mejor medida en este caso.
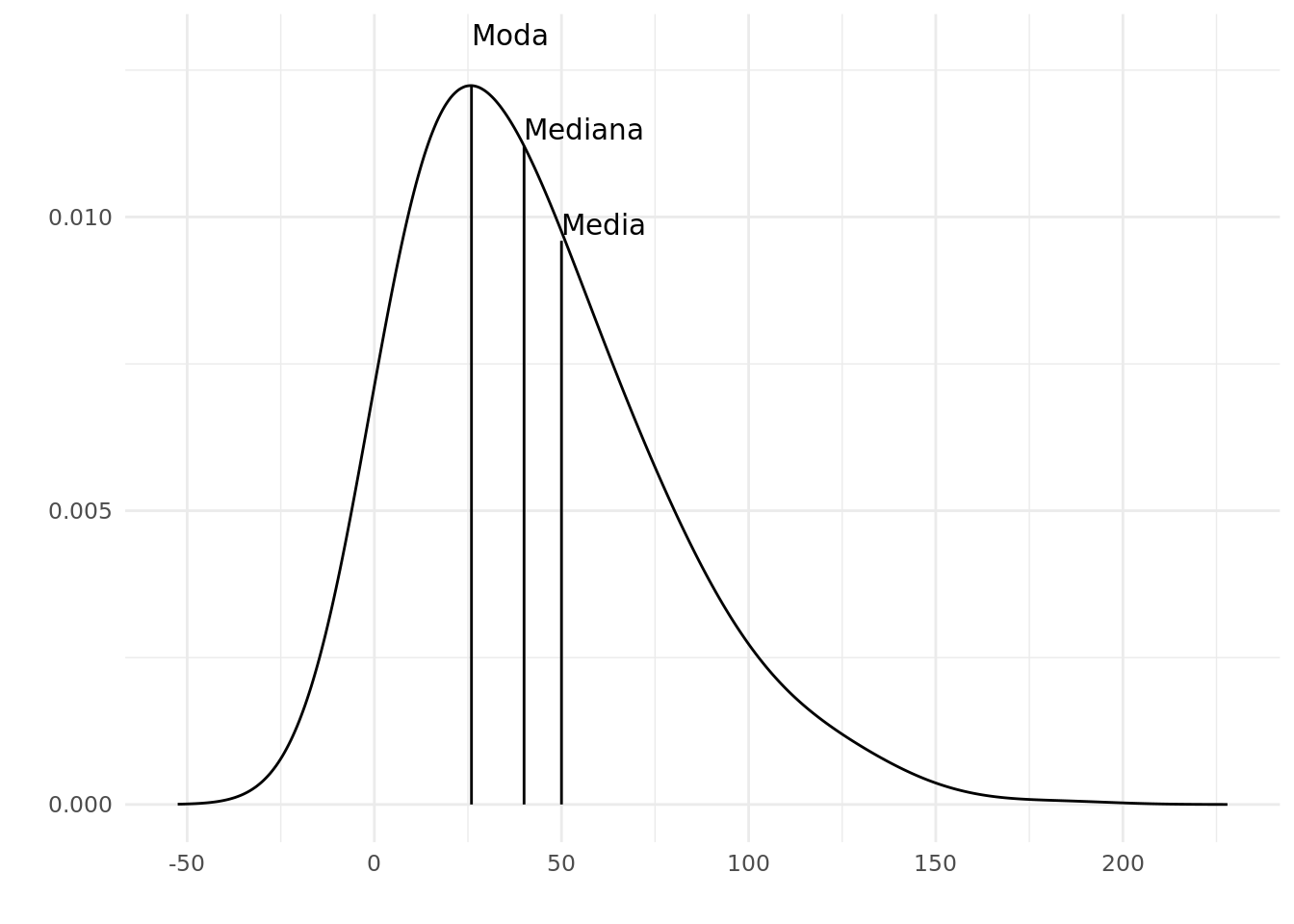
Figura 3.2: Medidas de centralización en una distribución con sesgo positivo
Para darnos cuenta de cuál de las medidas puede ser la más adecuada si tenemos datos por lo menos numéricos podemos sacar las tres medidas y ver qué tanto de asemejan unas a otras. Hay que tener en mente que cualiér distribución de datos reales va a tener un sesgo, la distribución perfectamente normal solo existe en teoría. Entonces debemos fijarnos si el sesgo que tenemos justifica el uso de una medida en espeficia. Por ejemplo, para nuestros datos de notas de dos grupos tenemos:
- Grupo A
- Media: 14,93
- Mediana: 15
- Moda: 15
- Grupo B:
- Media: 11,76
- Mediana: 12
- Moda: 12
- Media: 11,76
Vemos que hay muy poca diferencia entre las tres medidas por lo cual vamos a concluir que el sesgo observado no es lo suficientemente fuerte como para justificar el uso de otra medida que la media.
y por ende de más uso incorrecto↩︎