6.6 数据拆分
数据拆分通常是按找某一个分类变量分组,分完组就是计算,计算完就把结果按照原来的分组方式合并
## Notice that assignment form is not used since a variable is being added
g <- airquality$Month
l <- split(airquality, g) # 分组
l <- lapply(l, transform, Oz.Z = scale(Ozone)) # 计算:按月对 Ozone 标准化
aq2 <- unsplit(l, g) # 合并
head(aq2)## Ozone Solar.R Wind Temp Month Day Oz.Z
## 1 41 190 7.4 67 5 1 0.7822293
## 2 36 118 8.0 72 5 2 0.5572518
## 3 12 149 12.6 74 5 3 -0.5226399
## 4 18 313 11.5 62 5 4 -0.2526670
## 5 NA NA 14.3 56 5 5 NA
## 6 28 NA 14.9 66 5 6 0.1972879tapply 自带分组的功能,按月份 Month 对 Ozone 中心标准化,其返回一个列表
with(airquality, tapply(Ozone, Month, scale))## $`5`
## [,1]
## [1,] 0.78222929
## [2,] 0.55725184
## [3,] -0.52263993
## [4,] -0.25266698
## [5,] NA
## [6,] 0.19728792
## [7,] -0.02768953
## [8,] -0.20767149
....上面的过程等价于
do.call("rbind", lapply(split(airquality, airquality$Month), transform, Oz.Z = scale(Ozone)))## Ozone Solar.R Wind Temp Month Day Oz.Z
## 5.1 41 190 7.4 67 5 1 0.782229293
## 5.2 36 118 8.0 72 5 2 0.557251841
## 5.3 12 149 12.6 74 5 3 -0.522639926
## 5.4 18 313 11.5 62 5 4 -0.252666984
## 5.5 NA NA 14.3 56 5 5 NA
## 5.6 28 NA 14.9 66 5 6 0.197287919
## 5.7 23 299 8.6 65 5 7 -0.027689532
## 5.8 19 99 13.8 59 5 8 -0.207671494
## 5.9 8 19 20.1 61 5 9 -0.702621887
....由于上面对 Ozone 正态标准化,所以标准化后的 Oz.z 再按月分组计算方差自然每个月都是 1,而均值都是 0。
with(aq2, tapply(Oz.Z, Month, sd, na.rm = TRUE))## 5 6 7 8 9
## 1 1 1 1 1with(aq2, tapply(Oz.Z, Month, mean, na.rm = TRUE))## 5 6 7 8 9
## -4.240273e-17 1.052760e-16 5.841432e-17 5.898060e-17 2.571709e-17循着这个思路,我们可以用 tapply 实现分组计算,上面函数
sd和mean完全可以用自定义的更加复杂的函数替代
cut 函数可以将连续型变量划分为分类变量
set.seed(2019)
Z <- stats::rnorm(10)
cut(Z, breaks = -6:6)## [1] (0,1] (-1,0] (-2,-1] (0,1] (-2,-1] (0,1] (-1,0] (0,1] (-2,-1]
## [10] (-1,0]
## 12 Levels: (-6,-5] (-5,-4] (-4,-3] (-3,-2] (-2,-1] (-1,0] (0,1] (1,2] ... (5,6]# labels = FALSE 返回每个数所落的区间位置
cut(Z, breaks = -6:6, labels = FALSE)## [1] 7 6 5 7 5 7 6 7 5 6我们还可以指定参数 dig.lab 设置分组的精度,ordered 将分组变量看作是有序的,breaks 传递单个数时,表示分组数,而不是断点
cut(Z, breaks = 3, dig.lab = 4, ordered = TRUE)## [1] (0.06396,0.9186] (-0.7881,0.06396] (-1.643,-0.7881] (0.06396,0.9186]
## [5] (-1.643,-0.7881] (0.06396,0.9186] (-0.7881,0.06396] (0.06396,0.9186]
## [9] (-1.643,-0.7881] (-0.7881,0.06396]
## Levels: (-1.643,-0.7881] < (-0.7881,0.06396] < (0.06396,0.9186]此时,统计每组的频数,如图 6.2
# 条形图
plot(cut(Z, breaks = -6:6))
# 直方图
hist(Z, breaks = -6:6)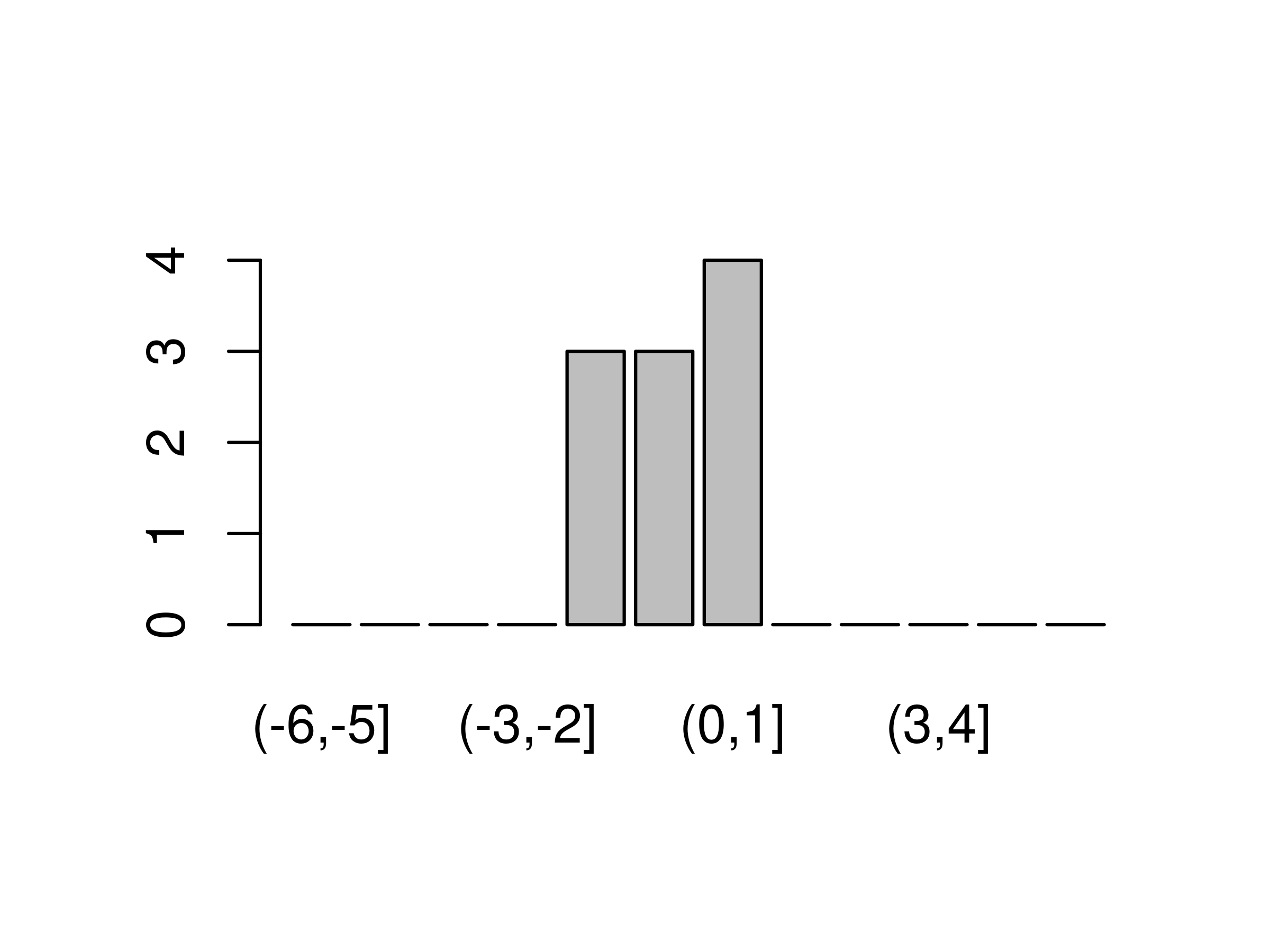
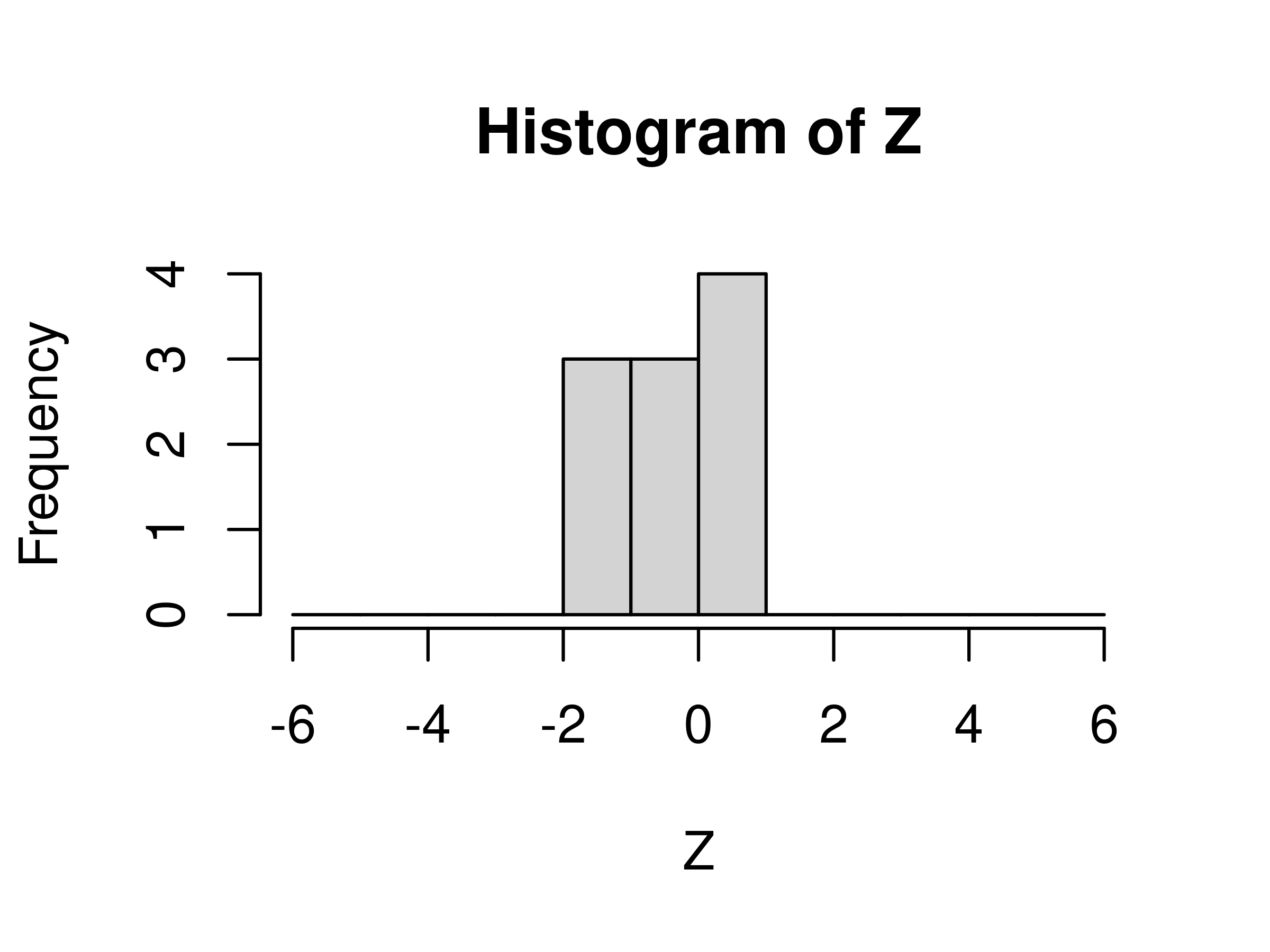
图 6.2: 连续型变量分组统计
在指定分组数的情况下,我们还想获取分组的断点
labs <- levels(cut(Z, 3))
labs## [1] "(-1.64,-0.788]" "(-0.788,0.064]" "(0.064,0.919]"用正则表达式抽取断点
cbind(
lower = as.numeric(sub("\\((.+),.*", "\\1", labs)),
upper = as.numeric(sub("[^,]*,([^]]*)\\]", "\\1", labs))
)## lower upper
## [1,] -1.640 -0.788
## [2,] -0.788 0.064
## [3,] 0.064 0.919更多相关函数可以参考 findInterval 和 embed
tabulate 和 table 有所不同,它表示排列,由 0 和 1 组成的一个长度为 5 数组,其中 1 有 3 个,则排列组合为
combn(5, 3, tabulate, nbins = 5)## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 1 1 1 1 1 1 0 0 0 0
## [2,] 1 1 1 0 0 0 1 1 1 0
## [3,] 1 0 0 1 1 0 1 1 0 1
## [4,] 0 1 0 1 0 1 1 0 1 1
## [5,] 0 0 1 0 1 1 0 1 1 1