4.6 字符串查询
grep(pattern, x,
ignore.case = FALSE, perl = FALSE, value = FALSE,
fixed = FALSE, useBytes = FALSE, invert = FALSE
)
grepl(pattern, x,
ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE
)grep 和 grepl 是一对字符串查询函数,查看字符串向量 x 中是否包含正则表达式 pattern 描述的内容
ignore.case:TRUE表示忽略大小写,FALSE表示匹配的时候区分大小写fixed = TRUE表示启用 literal regular expression 字面正则表达式,默认情况下fixed = FALSEgrep函数返回匹配到的字符串向量x的元素的下标,如果value=TRUE则返回下标对应的值grepl函数返回一个逻辑向量,检查字符串向量x中的每个元素是否匹配到,匹配到返回TRUE,没有匹配到返回FALSE
# 返回下标位置
grep("[a-z]", letters)## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
## [26] 26# 返回查询到的值
grep("[a-z]", letters, value = TRUE)## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
## [20] "t" "u" "v" "w" "x" "y" "z"继续举例子
grep(x = c("apple", "banana"), pattern = "a")## [1] 1 2grep(x = c("apple", "banana"), pattern = "b")## [1] 2grep(x = c("apple", "banana"), pattern = "a", value = TRUE)## [1] "apple" "banana"grep(x = c("apple", "banana"), pattern = "b", value = TRUE)## [1] "banana"关于 grepl 函数的使用例子
grepl(x = c("apple", "banana"), pattern = "a")## [1] TRUE TRUEgrepl(x = c("apple", "banana"), pattern = "b")## [1] FALSE TRUE在 R 里面分别表示 a\\b 和 a\b
writeLines(c("a\\\\b", "a\\b"))## a\\b
## a\b下面在 R 里面分别匹配字符串 a\\b 和 a\b 中的 \\ 和 \
# 匹配字符串中的一个反斜杠
grep(x = c("a\\\\b", "a\\b"), pattern = "\\", value = TRUE, fixed = TRUE)## [1] "a\\\\b" "a\\b"grep(x = c("a\\\\b", "a\\b"), pattern = "\\\\", value = TRUE, fixed = FALSE)## [1] "a\\\\b" "a\\b"# 匹配字符串中的两个反斜杠
grep(x = c("a\\\\b", "a\\b"), pattern = "\\\\", value = TRUE, fixed = TRUE)## [1] "a\\\\b"grep(x = c("a\\\\b", "a\\b"), pattern = "\\\\\\\\", value = TRUE, fixed = FALSE)## [1] "a\\\\b"# 匹配字符串中的两个反斜杠 \\
grepl(x = "a\\\\b", pattern = "\\\\\\\\", fixed = FALSE)## [1] TRUEgrepl(x = "a\\\\b", pattern = "\\\\\\\\", fixed = TRUE)## [1] FALSEgrepl(x = "a\\\\b", pattern = "\\\\", fixed = TRUE)## [1] TRUEregexpr(pattern, text,
ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE
)
gregexpr(pattern, text,
ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE
)
regexec(pattern, text,
ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE
) 当启用 perl=TRUE 时, 函数 regexpr 和 gregexpr 支持 Python 环境下的命名捕获(named captures),但是不支持长向量的输入。如果一个分组被命名了,如 (?<first>[A-Z][a-z]+) 那么匹配到的位置按命名返回。函数 sub 不支持命名反向引用 (Named backreferences)
函数 regmatches 用来提取函数regexpr, gregexpr 和 regexec 匹配到的子字符串
useBytes = FALSE 匹配位置和长度默认是按照字符级别来的,如果 useBytes = TRUE 则是按照逐个字节的匹配结果
如果使用到了 命名捕获 则会返回更多的属性 “capture.start”,“capture.length” 和 “capture.names”,分别表示捕获的起始位置、捕获的长度和捕获的命名。
regexpr函数返回一个整型向量,第一次匹配的初始位置,-1 表示没有匹配到,返回的属性match.length表示匹配的字符数量,是一个整型向量,向量长度是匹配的文本的长度,-1 表示没有匹配到
text <- c("Hellow, Adam!", "Hi, Adam!", "How are you, Adam.")
regexpr("Adam", text)## [1] 9 5 14
## attr(,"match.length")
## [1] 4 4 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUEtxt <- c(
"The", "licenses", "for", "most", "software", "are",
"designed", "to", "take", "away", "your", "freedom",
"to", "share", "and", "change", "it.",
"", "By", "contrast,", "the", "GNU", "General", "Public", "License",
"is", "intended", "to", "guarantee", "your", "freedom", "to",
"share", "and", "change", "free", "software", "--",
"to", "make", "sure", "the", "software", "is",
"free", "for", "all", "its", "users"
)
# gregexpr("en", txt)
regexpr("en", txt)## [1] -1 4 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 2 -1 4
## [26] -1 4 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
## attr(,"match.length")
## [1] -1 2 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 2 -1 2
## [26] -1 2 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUEgregexpr函数返回一个列表,返回列表的长度与字符串向量的长度一样,列表中每个元素的形式与regexpr的返回值一样, except that the starting positions of every (disjoint) match are given.
gregexpr("Adam", text)## [[1]]
## [1] 9
## attr(,"match.length")
## [1] 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUE
##
## [[2]]
## [1] 5
## attr(,"match.length")
## [1] 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUE
##
## [[3]]
## [1] 14
## attr(,"match.length")
## [1] 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUEregexec函数返回一个列表,类似函数gregexpr的返回结果,长度与字符串向量的长度一样,如果没有匹配到就返回 -1,匹配到了就返回一个匹配的初值位置的整型序列,所有子字符串与括号分组的正则表达式的子表达式对应,属性 “match.length” 是一个表示匹配的长度的向量,如果是 -1 表示没有匹配到。位置、长度和属性的解释与regexpr一致
regexec("Adam", text)## [[1]]
## [1] 9
## attr(,"match.length")
## [1] 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUE
##
## [[2]]
## [1] 5
## attr(,"match.length")
## [1] 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUE
##
## [[3]]
## [1] 14
## attr(,"match.length")
## [1] 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUE下面这个将链接分解的例子由 Luke Tierney 提供12
x <- "http://stat.umn.edu:80/xyz"
m <- regexec("^(([^:]+)://)?([^:/]+)(:([0-9]+))?(/.*)", x)
m## [[1]]
## [1] 1 1 1 8 20 21 23
## attr(,"match.length")
## [1] 26 7 4 12 3 2 4
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUE这里 x 是一个字符串,所以函数 regexec 返回的列表长度为1,正则表达式 ^(([^:]+)://)?([^:/]+)(:([0-9]+))?(/.*) 括号分组匹配到了7次,第一次匹配整个字符串,所以起始位置是1,而匹配长度是26,即整个字符串的长度,读者可以调用函数 nchar(x) 算一下,如果你愿意手动数一下也可以哈!余下不一一介绍,可以根据返回结果和图4.1一起看,最后还可以调用regmatches函数抽取匹配到的结果
regmatches(x, m)## [[1]]
## [1] "http://stat.umn.edu:80/xyz" "http://"
## [3] "http" "stat.umn.edu"
## [5] ":80" "80"
## [7] "/xyz"我们可以在 https://regex101.com/ 上测试表达式,如图4.1所示,表达式 ^(([^:]+)://)?([^:/]+)(:([0-9]+))?(/.*) 包含7个组,每个组的匹配结果见图的右下角,这样我们不难理解,函数 regmatches 返回的第列表中,第3个位置是传输协议 protocol http ,第4个位置是主机 host stat.umn.edu, 第6个位置是端口 port 80 ,第7个位置是路径 path /xyz,所以函数 regmatches 的作用就是根据函数 regexec 匹配的结果抽取子字符串。
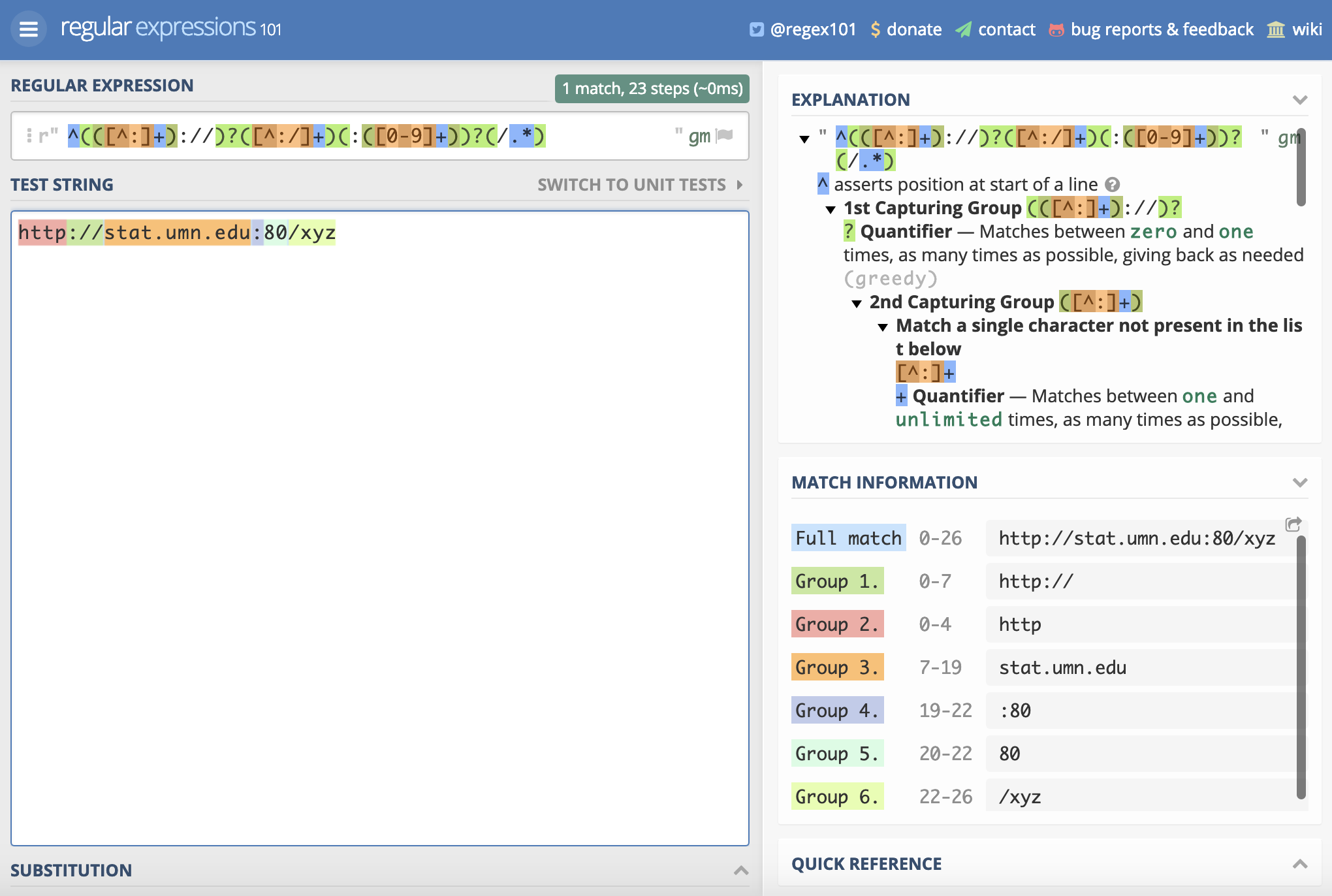
图 4.1: 正则表达式匹配结果
进一步,我们可以用 regmatches 函数抽取 URL 的部分内容,如前面提到的传输协议,主机等
URL_parts <- function(x) {
m <- regexec("^(([^:]+)://)?([^:/]+)(:([0-9]+))?(/.*)", x)
parts <- do.call(
rbind,
lapply(regmatches(x, m), `[`, c(3L, 4L, 6L, 7L))
# 3,4,6,7是索引位置
)
colnames(parts) <- c("protocol", "host", "port", "path")
parts
}
URL_parts(x)## protocol host port path
## [1,] "http" "stat.umn.edu" "80" "/xyz"目前还没有 gregexec 函数,但是可以模拟一个,首先用 gregexpr 函数返回匹配的位置,regmatches 抽取相应的值,然后用 regexec 作用到每一个提取的值,做再一次匹配和值的抽取,实现了全部的匹配。另一个例子
## There is no gregexec() yet, but one can emulate it by running
## regexec() on the regmatches obtained via gregexpr(). E.g.:
pattern <- "([[:alpha:]]+)([[:digit:]]+)"
s <- "Test: A1 BC23 DEF456"
gregexpr(pattern, s)## [[1]]
## [1] 7 10 15
## attr(,"match.length")
## [1] 2 4 6
## attr(,"index.type")
## [1] "chars"
## attr(,"useBytes")
## [1] TRUEregmatches(s, gregexpr(pattern, s))## [[1]]
## [1] "A1" "BC23" "DEF456"lapply(
regmatches(s, gregexpr(pattern, s)),
function(e) regmatches(e, regexec(pattern, e))
)## [[1]]
## [[1]][[1]]
## [1] "A1" "A" "1"
##
## [[1]][[2]]
## [1] "BC23" "BC" "23"
##
## [[1]][[3]]
## [1] "DEF456" "DEF" "456"