Capítulo 11 Procesamiento de cadenas y minería de texto
11.1 Funciones básicas
Ya hemos aprendido a importar datos y a consolidarlos. Sin embargo, aun no podemos trabajar con esta data. Tenemos que validar mediante el procesamiento de cadenas y asegurar una calidad mínima para poder realizar nuestros análisis.
Por ejemplo, en el capítulo anterior importamos datos de Wikipedia, sin embargo no nos centramos en si ya podíamos realizar operaciones o visualizaciones con nuestra data.
library(rvest)
url <- "https://es.wikipedia.org/wiki/Anexo:Pa%C3%ADses_hispanos_por_poblaci%C3%B3n"
#url <- "https://es.wikipedia.org/wiki/Distribuci%C3%B3n_geogr%C3%A1fica_del_idioma_espa%C3%B1ol" #as a back up URL
data_en_html <- read_html(url)
tablas_web <- data_en_html %>%
html_nodes("body") %>%
html_nodes("table")
tabla_en_bruto <- tablas_web[[2]] %>%
html_table
tabla_en_bruto <- tabla_en_bruto %>%
setNames(c("N", "pais", "poblacion", "prop_poblacion", "cambio_medio", "link"))
tabla_en_bruto <- tabla_en_bruto %>%
as_tibble()
tabla_en_bruto %>% head(5)
#> # A tibble: 5 × 5
#> N pais poblacion prop_poblacion cambio_medio
#> <chr> <chr> <chr> <chr> <chr>
#> 1 México México 132 820 000 27,95 1 285 000 www.datos.gob.mx/busca…
#> 2 Colombia Colombia 50 882 884 10,71 572 000 www.dane.gov.co
#> 3 España España 47 431 246 9,98 45 000 https://www.ine.es/pre…
#> 4 Argentina 45 195 777 9,51 465 000 www.indec.mecon.ar
#> 5 Perú Perú 33 105 273 6,96 342 000 www.inei.gob.peTal vez no nos hayamos dado cuenta, pero podemos observar columnas con espacios o comas donde deberían de haber números. Lo podemos validar no solo analizando la clase de la columna, sino también si intentamos calcular el promedio de esa variable.
class(tabla_en_bruto$poblacion)
#> [1] "character"
mean(tabla_en_bruto$poblacion)
#> Warning in mean.default(tabla_en_bruto$poblacion): argument is not numeric or
#> logical: returning NA
#> [1] NANo podemos hacer tampoco una conversión directa a número porque los espacios en blanco y las comas son caracteres.
as.numeric(tabla_en_bruto$poblacion)
#> Warning: NAs introduced by coercion
#> [1] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NASon tan frecuentes y tantas las casuísticas posibles que ya existen múltiples funciones para procesar cadenas incluidas en la librería tidyverse. Así mismo, hay más de una forma de cómo procesar cadenas. Siempre dependerá de cómo se encuentra la data en bruto.
11.1.1 Reemplazando caracteres
Una de las función básicas que más usaremos será el reemplazar caracteres. Aplicamos esta función cuando estamos seguros que ese cambio no va a comprometer al resto de datos. Tenemos espacios y tenemos comas. Entonces podríamos empezar por reemplazar alguno de los dos para normalizarlos utilizando la función str_replace_all(cadena, patron, reemplazo). En el atributo patrón usaremos \\s, que viene de space (espacio en inglés). Vamos a aprender primero a modificar los datos almacenados en un vector y luego replicaremos a toda nuestra tabla.
library(tidyverse)
library(stringr)
vector_poblacion <- tabla_en_bruto$poblacion
vector_poblacion <- str_replace_all(vector_poblacion, "\\s", ",")
vector_poblacion
#> [1] "27,95" "10,71" "9,98" "9,51" "6,96" "5,98" "4,02" "3,77"
#> [9] "3,71" "2,45" "2,4" "2,3" "2,1" "1,4" "1,4" "1,4"
#> [17] "1,1" "0,9" "0,7" "0,7" "100,00"Hemos llevado a propósito todos los valores a estar separados por comas porque ahora podremos usar fácilmente la función parse_number(vector) que no solo reemplaza las comas por vacío, sino que remueve todo valor no numérico antes del primer número, lo cual nos facilita si tuviésemos valores monetarios, y además nos convierte el valor de tipo caracter a tipo numérico.
vector_poblacion <- parse_number(vector_poblacion)
# Ejemplo adicional por si tuviésemos un valor monetario:
parse_number("$345,153")
#> [1] 345153Este vector ahora sí nos permite hacer operaciones matemáticas o visualización de la distribución.
# Convertir a millones
vector_poblacion <- vector_poblacion/10^6
# Removemos el último valor que es la población del mundo:
largo <- length(vector_poblacion)
vector_poblacion <- vector_poblacion[-largo]
# Visualización
boxplot(vector_poblacion)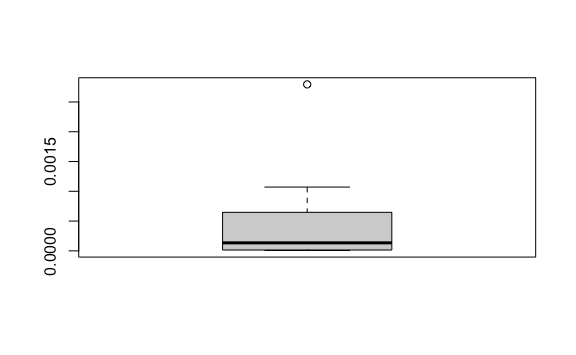
Ya sabemos qué funciones utilizar para transformar los campos de nuestro caso. Sin embargo, los hemos aplicado a vectores. Para mutar las columnas de nuestra tabla en bruto usaremos la función mutate_at(columnas, ~funcion) usando el operador pipeline %>%. Apliquemos el primer cambio de los espacios por comas y no solo a la columna 3, población, sino también a la columna 5, cambio medio.
tabla_en_bruto %>%
mutate_at(c(3,5), ~str_replace_all(., "\\s", ","))
#> # A tibble: 21 × 5
#> N pais poblacion prop_poblacion cambio_medio
#> <chr> <chr> <chr> <chr> <chr>
#> 1 México México 132 820 000 27,95 1 285 000 www.datos.gob.mx/bu…
#> 2 Colombia Colombia 50 882 884 10,71 572 000 www.dane.gov.co
#> 3 España España 47 431 246 9,98 45 000 https://www.ine.es/…
#> 4 Argentina 45 195 777 9,51 465 000 www.indec.mecon.ar
#> 5 Perú Perú 33 105 273 6,96 342 000 www.inei.gob.pe
#> 6 Venezuela Venezuela 28 435 943 5,98 416 000 www.ine.gov.ve
#> 7 Chile Chile 19 116 209 4,02 188 000 www.ine.cl
#> 8 Guatemala Guatemala 17 915 567 3,77 496 000 www.ine.gob.gt
#> 9 Ecuador Ecuador 17 643 060 3,71 255 000 www.ecuadorencifras…
#> 10 Bolivia Bolivia 11 673 029 2,45 163 000 www.ine.gob.bo
#> # ℹ 11 more rowsHemos quitado de la función str_replace_all el atributo cadena y lo hemos reeplazado por un punto .. Y es que ese punto . nos indica que evaluará para cada columna c(3,5) de nuestra tabla.
Ahora, apliquemos la función parse_number que aplicamos anteriormente.
tabla_en_bruto %>%
mutate_at(c(3,5), ~str_replace_all(., "\\s", ",")) %>%
mutate_at(c(3,5), ~parse_number(.))
#> Warning: There was 1 warning in `mutate()`.
#> ℹ In argument: `cambio_medio = (structure(function (..., .x = ..1, .y = ..2, .
#> = ..1) ...`.
#> Caused by warning:
#> ! 19 parsing failures.
#> row col expected actual
#> 1 -- a number www.datos.gob.mx/busca/organization/conapo
#> 2 -- a number www.dane.gov.co
#> 3 -- a number https://www.ine.es/prensa/pad_2020_p.pdf
#> 4 -- a number www.indec.mecon.ar
#> 5 -- a number www.inei.gob.pe
#> ... ... ........ ..........................................
#> See problems(...) for more details.
#> # A tibble: 21 × 5
#> N pais poblacion prop_poblacion cambio_medio
#> <chr> <chr> <dbl> <chr> <dbl>
#> 1 México México 132 820 000 2795 1 285 000 NA
#> 2 Colombia Colombia 50 882 884 1071 572 000 NA
#> 3 España España 47 431 246 998 45 000 NA
#> 4 Argentina 45 195 777 951 465 000 NA
#> 5 Perú Perú 33 105 273 696 342 000 NA
#> 6 Venezuela Venezuela 28 435 943 598 416 000 NA
#> 7 Chile Chile 19 116 209 402 188 000 NA
#> 8 Guatemala Guatemala 17 915 567 377 496 000 NA
#> 9 Ecuador Ecuador 17 643 060 371 255 000 NA
#> 10 Bolivia Bolivia 11 673 029 245 163 000 NA
#> # ℹ 11 more rows11.2 Expresiones regulares
Una expresión regular10 (o regex como se le conoce en inglés) es un patrón que describe un conjunto de cadenas. Ya hemos utilizado regex en la sección anterior utilizando solo el patrón \\s. Sin embargo, normalmente tendremos muchas más casuísticas que requerirán un patrón que pueda convertir un rango más amplio de casos.
Si bien podríamos analizar todas las casuísticas posibles disponibles en la documentación, aprendemos más rápido por casuísticas. Analicemos un caso que nos permitirá aprender poco a poco algunos patrones.
En la librería dslabs encontramos y utilizamos anteriormente los datos del data frame estaturas, heigths, de alumnos de una universidad expresados en pulgadas.
library(dslabs)
data(heights)
heights %>%
head(10)
#> sex height
#> 1 Male 75
#> 2 Male 70
#> 3 Male 68
#> 4 Male 74
#> 5 Male 61
#> 6 Female 65
#> 7 Female 66
#> 8 Female 62
#> 9 Female 66
#> 10 Male 67Estos datos estaban listos para ser analizados. Sin embargo, no fue así como provino de la fuente. Los estudiantes tuvieron que llenar una encuesta y aún cuando se les pidió su estatura en pulgadas, ellos completaron su estatura en pulgadas, pies, centímetros, escribiendo números, letras, etc. Podemos ver la data inicial del formulario en el data frame reported_heights.
reported_heights %>%
head(10)
#> time_stamp sex height
#> 1 2014-09-02 13:40:36 Male 75
#> 2 2014-09-02 13:46:59 Male 70
#> 3 2014-09-02 13:59:20 Male 68
#> 4 2014-09-02 14:51:53 Male 74
#> 5 2014-09-02 15:16:15 Male 61
#> 6 2014-09-02 15:16:16 Female 65
#> 7 2014-09-02 15:16:19 Female 66
#> 8 2014-09-02 15:16:21 Female 62
#> 9 2014-09-02 15:16:21 Female 66
#> 10 2014-09-02 15:16:22 Male 67Si bien podríamos pensar que ingresaron bien los datos, no tenemos que confiarnos y siempre es mejor validar la calidad de nuestra data. Hay múltiples maneras de validar, como podemos ver a continuación:
estaturas <- reported_heights$height
# Validación opción 1: Muestra aleatoria
sample(estaturas, 100)
#> [1] "68" "74" "68.8976378" "71.5"
#> [5] "5'10''" "73" "5.4" "65"
#> [9] "6" "172" "65" "70"
#> [13] "5.11" "70" "67" "71"
#> [17] "70.866" "68.5" "1" "68"
#> [21] "72.5" "5'12" "5.5" "63"
#> [25] "73" "70" "68" "69"
#> [29] "67" "64.5" "69.29" "76"
#> [33] "75" "75" "70" "52"
#> [37] "67.5" "71" "80" "72"
#> [41] "67" "69.3" "1.7" "70"
#> [45] "68" "60" "68" "6"
#> [49] "70" "72" "5 feet 6 inches" "62"
#> [53] "66" "6 04" "72" "59"
#> [57] "183" "66" "71" "63"
#> [61] "5" "5.7" "67" "67"
#> [65] "62" "64.57" "5'5" "78"
#> [69] "63" "67.72" "63" "5'3\""
#> [73] "170" "68" "73" "5.57"
#> [77] "66" "66" "70" "70"
#> [81] "67" "162" "67" "5'6"
#> [85] "6" "11111" "70" "74"
#> [89] "157" "76" "65" "69"
#> [93] "70" "5.5" "70.1" "63"
#> [97] "81" "5'6" "72" "169"
# Validación opción 2: convertir a números y contar si hay NAs
x <- as.numeric(estaturas)
#> Warning: NAs introduced by coercion
sum(is.na(x))
#> [1] 81
# Validación opción 3: agregar columna de los que no pueden convertirse en número:
reported_heights %>%
mutate(estatuta_numero = as.numeric(height)) %>%
filter(is.na(estatuta_numero)) %>%
head(10)
#> Warning: There was 1 warning in `mutate()`.
#> ℹ In argument: `estatuta_numero = as.numeric(height)`.
#> Caused by warning:
#> ! NAs introduced by coercion
#> time_stamp sex height estatuta_numero
#> 1 2014-09-02 15:16:28 Male 5' 4" NA
#> 2 2014-09-02 15:16:37 Female 165cm NA
#> 3 2014-09-02 15:16:52 Male 5'7 NA
#> 4 2014-09-02 15:16:56 Male >9000 NA
#> 5 2014-09-02 15:16:56 Male 5'7" NA
#> 6 2014-09-02 15:17:09 Female 5'3" NA
#> 7 2014-09-02 15:18:00 Male 5 feet and 8.11 inches NA
#> 8 2014-09-02 15:19:48 Male 5'11 NA
#> 9 2014-09-04 00:46:45 Male 5'9'' NA
#> 10 2014-09-04 10:29:44 Male 5'10'' NAPodríamos querer optar por eliminar estos datos NAs al no ser significativos respecto al total de 1,095 datos. Sin embargo, hay varios de estos datos que siguen un patrón determinado y en vez de ser descartados podrían ser convertidos a la escala que tenemos en el resto de la data. Por ejemplo, hay personas que ingresaron su estatura como 5’7”, que, para quienes recuerdan la conversión, se puede convertir porque 1 pie son 12 pulgadas. Entonces \(5*12+7=67\). Y así, como ese caso, podemos detectar patrones, pero tenemos, nuevamente, que ser cuidadosos en detectar el patrón exacto y no uno muy genérico que pueda cambiar otras casuísticas. Si todos siguiesen el mismo patrón \(x'y''\) o \(x'y\) sería mucho más fácil convertirlo a pulgadas al calcular \(x*12+y\).
Empecemos extrayendo nuestra columna a un solo vector de caracteres con todos los valores que no convierten en automático a número o fueron ingresados en pulgadas. Esto lo detectamos si miden más de 5 y hasta 7 pies (de 1.5m a 2.1 metros). Luego de ello iremos creando poco a poco las transformaciones.
estaturas_error <- reported_heights %>%
filter(is.na(as.numeric(height)) | # No convierte a número
(!is.na(as.numeric(height)) & as.numeric(height) >= 5 &
as.numeric(height) <= 7 ) # o ingresó en pies y no pulgadas
) %>%
.$height
length(estaturas_error)
#> [1] 168Agregando la condición de haber ingresado en pies tenemos 168 errores. No podemos ignorar 15.3% de errores.
Usaremos la función str_detect(cadena, patron) que nos permitirá detectar si una cadena cumple un determinado patrón. El resultado será un valor lógico: TRUE or FALSE que podemos usar como índice para obtener los valores que cumplen en nuestro vector.
indice <- str_detect(estaturas_error, "feet")
estaturas_error[indice] # Cumplen el patrón
#> [1] "5 feet and 8.11 inches" "5 feet 7inches" "5 feet 6 inches"
estaturas_error[!indice] %>% # No cumplen el platrón
head(40)
#> [1] "6" "5' 4\"" "5.3"
#> [4] "165cm" "6" "5'7"
#> [7] ">9000" "5'7\"" "5'3\""
#> [10] "5.25" "5'11" "5.5"
#> [13] "5'9''" "6" "6.5"
#> [16] "5'10''" "5.8" "5"
#> [19] "5.6" "5,3" "6'"
#> [22] "6" "5.9" "6,8"
#> [25] "5' 10" "5.5" "6.2"
#> [28] "Five foot eight inches" "6.2" "5.8"
#> [31] "5.1" "5.11" "5'5\""
#> [34] "5'2\"" "5.75" "5,4"
#> [37] "7" "5.4" "6.1"
#> [40] "5'3"11.2.1 Alternación
| es el operador de alternación que elegirá entre uno o más valores posibles. En nuestro caso, hemos indicado que detecte si existe la palabra “feet” (pie en inglés), pero también tenemos “ft” y “foot” para referirse a lo mismo en nuestros datos. Así, podemos crear el patrón “feet” o “ft” o “foot”.
indice <- str_detect(estaturas_error, "feet|ft|foot")
estaturas_error[indice] # Cumplen
#> [1] "5 feet and 8.11 inches" "Five foot eight inches" "5 feet 7inches"
#> [4] "5ft 9 inches" "5 ft 9 inches" "5 feet 6 inches"De la misma forma podemos encontrar las variaciones para pulgadas y otros símbolos que podemos remover:
indice <- str_detect(estaturas_error, "inches|in|''|\"|cm|and")
estaturas_error[indice] # Cumplen
#> [1] "5' 4\"" "165cm" "5'7\""
#> [4] "5'3\"" "5 feet and 8.11 inches" "5'9''"
#> [7] "5'10''" "Five foot eight inches" "5'5\""
#> [10] "5'2\"" "5'10''" "5'3''"
#> [13] "5'7''" "5'3\"" "5'6''"
#> [16] "5'7.5''" "5'7.5''" "5'2\""
#> [19] "5' 7.78\"" "5 feet 7inches" "5'8\""
#> [22] "5'11\"" "5'7\"" "5' 11\""
#> [25] "6'1\"" "69\"" "5' 7\""
#> [28] "5'10''" "5ft 9 inches" "5 ft 9 inches"
#> [31] "5'11''" "5'8\"" "5 feet 6 inches"
#> [34] "5'10''" "6'3\"" "5'5''"
#> [37] "5'7\"" "6'4\"" "170 cm"En este caso hemos ingresado '' para detectar a los que ingresaron ese símbolo para denotar pulgadas y \" por si usaron doble comillas. En este último caso hemos utilizado \ para que no nos genere un error al interpretar como cierre de la cadena.
Ya podríamos comenzar reemplazando a partir de los patrones detectados:
estaturas_error <- str_replace_all(estaturas_error, "feet|ft|foot", "'")
estaturas_error <- str_replace_all(estaturas_error, "inches|in|''|\"|cm|and", "")
estaturas_error %>%
head(30)
#> [1] "6" "5' 4" "5.3" "165"
#> [5] "6" "5'7" ">9000" "5'7"
#> [9] "5'3" "5 ' 8.11 " "5.25" "5'11"
#> [13] "5.5" "5'9" "6" "6.5"
#> [17] "5'10" "5.8" "5" "5.6"
#> [21] "5,3" "6'" "6" "5.9"
#> [25] "6,8" "5' 10" "5.5" "6.2"
#> [29] "Five ' eight " "6.2"Como esfuerzo adicional, podríamos también buscar solucionar que algunas personas han escrito palabras en vez de números. Para ello creamos una función que reemplace cada palabra por un número y aplicamos al vector:
palabras_a_numero <- function(s){
str_to_lower(s) %>%
str_replace_all("zero", "0") %>%
str_replace_all("one", "1") %>%
str_replace_all("two", "2") %>%
str_replace_all("three", "3") %>%
str_replace_all("four", "4") %>%
str_replace_all("five", "5") %>%
str_replace_all("six", "6") %>%
str_replace_all("seven", "7") %>%
str_replace_all("eight", "8") %>%
str_replace_all("nine", "9") %>%
str_replace_all("ten", "10") %>%
str_replace_all("eleven", "11")
}
estaturas_error <- palabras_a_numero(estaturas_error)
estaturas_error %>%
head(30)
#> [1] "6" "5' 4" "5.3" "165" "6"
#> [6] "5'7" ">9000" "5'7" "5'3" "5 ' 8.11 "
#> [11] "5.25" "5'11" "5.5" "5'9" "6"
#> [16] "6.5" "5'10" "5.8" "5" "5.6"
#> [21] "5,3" "6'" "6" "5.9" "6,8"
#> [26] "5' 10" "5.5" "6.2" "5 ' 8 " "6.2"11.2.2 Anclaje
Ahora que está más estandarizado podemos comenzar con regex con características más genéricas. Por ejemplo, hay una persona que ha ingresado 6'. Sería conveniente tener todo de la forma pies más pulgadas. Con lo que deberíamos de tener 6'0. Para lograr ello tenemos que crear un regex acorde a esta situación genérica. Usaremos el símbolo ^ para anclar nuestra validación a que “comience con” y el símbolo $ para hacer coincidir con el fin de la cadena. Antes de reemplazar, primero veamos quiénes cumplen.
Este regex nos indica que comience con 6' y que ahí termine la expresión. Aun podríamos hacerla más genérica para abordar a quienes, en un futuro, escriban 5 pulgadas (1.52m) o 6 pulgadas (1.82m). Para ello usaremos corchete y dentro de ellos pondremos todos los valores que aceptaremos.
Sigue habiendo un solo resultado, pero nuestro regex es más genérico ahora y ya lo podemos usar para reemplazar. Antes de reemplazar en nuestro vector vamos a hacer una prueba para aprender cómo crear lo que necesitamos a partir de un patrón.
Hemos colocado entre paréntesis para indicar que lo que está dentro es nuestro primer valor y usamos \\1 para hacer referencia a ese primer valor. Entones estamos indicando que escriba el primer valor, luego una comilla ', y luego un cero 0.
Ahora ya estamos listos para aplicar a todo nuestro vector. Vamos a hacer el cambio para considerar no solo 5 y 6, sino hasta el valor de 7 pulgadas (2.1m). Así mismo, vamos a tomar los casos en que solo haya un número sin el símbolo de pies '.
estaturas_error <- str_replace_all(estaturas_error, "^([5-7])'$", "\\1'0")
estaturas_error <- str_replace_all(estaturas_error, "^([5-7])$", "\\1'0")
estaturas_error %>%
head(30)
#> [1] "6'0" "5' 4" "5.3" "165" "6'0"
#> [6] "5'7" ">9000" "5'7" "5'3" "5 ' 8.11 "
#> [11] "5.25" "5'11" "5.5" "5'9" "6'0"
#> [16] "6.5" "5'10" "5.8" "5'0" "5.6"
#> [21] "5,3" "6'0" "6'0" "5.9" "6,8"
#> [26] "5' 10" "5.5" "6.2" "5 ' 8 " "6.2"11.2.3 Repeticiones
Podemos controlar cuántas veces un patrón coincide utilizando los operadores de repetición:
| Operador | Número de veces |
|---|---|
? |
0 o 1 vez |
+ |
1 o más veces |
* |
0 o más veces |
Por ejemplo, para encontrar todos los casos donde en vez de usar el símbolo de pies ' ingresaron una coma, un punto, o un espacio usaremos el siguiente patrón:
Leamos el patrón:
- La cadena empieza con un dígito que va del 4 al 7.
\\squiere decir que va seguido de un espacio en blanco, pero usamos*para indicar que ese caracter aparezca 0 o más veces.- Luego de ese espacio buscaremos por cualquiera de los siguientes caracteres:
,, un punto\\.(al cual ponemos doble barra invertida porque el punto solo en un patrón significa “cualquier valor”). - Volvemos a usar
\\s*para buscar cero o más espacios en blanco. - Finalmente indicamos que la cadena culmina ahí con un dígito, para denotar que busque cualquier dígito usamos
\\d, d de dígito. Y agregamos asterísco para que nos mantenga uno o más dígitos que encuentre.
En resumen: empieza con un número, luego símbolos y luego un dígito. Entre los símbolos podrían haber espacios en blanco. Ese es nuestro patrón.
indice <- str_detect(estaturas_error, "^([4-7])\\s*[,\\.]\\s*(\\d*)$")
estaturas_error[indice] # Cumplen
#> [1] "5.3" "5.25" "5.5" "6.5" "5.8" "5.6" "5,3" "5.9" "6,8"
#> [10] "5.5" "6.2" "6.2" "5.8" "5.1" "5.11" "5.75" "5,4" "5.4"
#> [19] "6.1" "5.6" "5.6" "5.4" "5.9" "5.6" "5.6" "5.5" "5.2"
#> [28] "5.5" "5.5" "6.5" "5,8" "5.11" "5.5" "6.7" "5.1" "5.6"
#> [37] "5.5" "5.2" "5.6" "5.7" "5.9" "6.5" "5.11" "5 .11" "5.7"
#> [46] "5.5" "5.8" "5.8" "5.1" "5.11" "5.7" "5.9" "5.2" "5.5"
#> [55] "5.51" "5.8" "5.7" "6.1" "5.69" "5.7" "5.25" "5.5" "5.1"
#> [64] "6.3" "5.5" "5.7" "5.57" "5.7"Ya encontramos los valores que cumplen con el patrón, así que ya estamos listos para reemplazar.
estaturas_error <- str_replace_all(
estaturas_error,
"^([4-7])\\s*[,\\.]\\s*(\\d*)$", "\\1.\\2'0"
)
estaturas_error %>%
head(30)
#> [1] "6'0" "5' 4" "5.3'0" "165" "6'0"
#> [6] "5'7" ">9000" "5'7" "5'3" "5 ' 8.11 "
#> [11] "5.25'0" "5'11" "5.5'0" "5'9" "6'0"
#> [16] "6.5'0" "5'10" "5.8'0" "5'0" "5.6'0"
#> [21] "5.3'0" "6'0" "6'0" "5.9'0" "6.8'0"
#> [26] "5' 10" "5.5'0" "6.2'0" "5 ' 8 " "6.2'0"Otro patrón que vemos ahora es cuando antes o después del símbolo de pies ' hay un espacio en blanco. Hagamos el cambio con lo aprendido e incluyamos los casos donde hay decimales:
indice <- str_detect(estaturas_error,
"^([4-7]\\.?\\d*)\\s*'\\s*(\\d+\\.?\\d*)\\s*$")
estaturas_error[indice] %>% # Cumplen
head(30)
#> [1] "6'0" "5' 4" "5.3'0" "6'0" "5'7"
#> [6] "5'7" "5'3" "5 ' 8.11 " "5.25'0" "5'11"
#> [11] "5.5'0" "5'9" "6'0" "6.5'0" "5'10"
#> [16] "5.8'0" "5'0" "5.6'0" "5.3'0" "6'0"
#> [21] "6'0" "5.9'0" "6.8'0" "5' 10" "5.5'0"
#> [26] "6.2'0" "5 ' 8 " "6.2'0" "5.8'0" "5.1'0"
estaturas_error <- str_replace_all(
estaturas_error,
"^([4-7]\\.?\\d*)\\s*'\\s*(\\d+\\.?\\d*)\\s*$",
"\\1'\\2"
)
estaturas_error %>%
head(30)
#> [1] "6'0" "5'4" "5.3'0" "165" "6'0" "5'7" ">9000" "5'7"
#> [9] "5'3" "5'8.11" "5.25'0" "5'11" "5.5'0" "5'9" "6'0" "6.5'0"
#> [17] "5'10" "5.8'0" "5'0" "5.6'0" "5.3'0" "6'0" "6'0" "5.9'0"
#> [25] "6.8'0" "5'10" "5.5'0" "6.2'0" "5'8" "6.2'0"Así mismo, tenemos el patrón en que ingresaron: pies + espacio + pulgadas sin ningún símbolo. Hagamos el cambio con lo aprendido.
indice <- str_detect(estaturas_error, "^([4-7])\\s+(\\d*)\\s*$")
estaturas_error[indice] # Cumplen
#> [1] "5 11" "6 04"
estaturas_error <- str_replace_all(
estaturas_error,
"^([4-7])\\s+(\\d*)\\s*$", "\\1'\\2"
)
estaturas_error %>%
head(30)
#> [1] "6'0" "5'4" "5.3'0" "165" "6'0" "5'7" ">9000" "5'7"
#> [9] "5'3" "5'8.11" "5.25'0" "5'11" "5.5'0" "5'9" "6'0" "6.5'0"
#> [17] "5'10" "5.8'0" "5'0" "5.6'0" "5.3'0" "6'0" "6'0" "5.9'0"
#> [25] "6.8'0" "5'10" "5.5'0" "6.2'0" "5'8" "6.2'0"Estamos listos para poner todos los patrones juntos y lo pontente de los patrones es que nos pueden servir para futuros ejercicios. Así, crearemos una función donde colocaremos cada cambio que podemos hacer a un string.
formatear_errores <- function(cadena){
cadena %>%
str_replace_all("feet|ft|foot", "'") %>% # Cambia pies por '
str_replace_all("inches|in|''|\"|cm|and", "") %>% # Remueve símbolos
str_replace_all("^([5-7])'$", "\\1'0") %>% # Agrega 0 a 5', 6' o 7'
str_replace_all("^([5-7])$", "\\1'0") %>% # Agrega 0 a 5, 6 o 7
str_replace_all("^([4-7])\\s*[,\\.]\\s*(\\d*)$", "\\1.\\2'0") %>% # Cambiar 5.3' a 5.3'0
str_replace_all("^([4-7]\\.?\\d*)\\s*'\\s*(\\d+\\.?\\d*)\\s*$", "\\1'\\2") %>% #Quita espacios al medio
str_replace_all("^([4-7])\\s+(\\d*)\\s*$", "\\1'\\2") %>% # Agrega '
str_replace("^([12])\\s*,\\s*(\\d*)$", "\\1.\\2") %>% # Cambia decimales de comas a puntos
str_trim() #Quita espacios al inicio y fin
}Así, hemos creado dos funciones que nos podrían ser útiles si fuésemos a volver a trabajar con encuestas del mismo tipo.
Antes de aplicarlo a toda nuestra tabla volvamos a extraer los valores a un vector para aplicar las funciones creadas.
estaturas_error <- reported_heights %>%
filter(is.na(as.numeric(height)) | # No convierte a número
(!is.na(as.numeric(height)) & as.numeric(height) >= 5 &
as.numeric(height) <= 7 ) # o ingresó en pies y no pulgadas
) %>%
.$heightAhora apliquemos las funciones creadas:
estaturas_formateadas <- estaturas_error %>%
palabras_a_numero() %>%
formatear_errores()
patron <- "^([4-7]\\.?\\d*)\\s*'\\s*(\\d+\\.?\\d*)\\s*$"
indice <- str_detect(estaturas_formateadas, patron)
estaturas_formateadas[!indice] # No cumplen con el patrón
#> [1] "165" ">9000" "2'33" "1.70" "yyy" "6*12"
#> [7] "69" "708,661" "649,606" "728,346" "170" "7,283,465"Hemos logrado reducir de 168 errores de 1095 registros, 15.3% de errores, a 12 errores de 1095, 1% de errores. Ya podemos aplicar a nuestra tabla inicial.
# Aplicamos las fórmulas creadas
estaturas <- reported_heights %>%
mutate(height) %>%
mutate(estatura = palabras_a_numero(height) %>% formatear_errores())
# Obtenemos muestras aleatorias para validar calidad
indices_aleatorios <- sample(1:nrow(estaturas))
estaturas[indices_aleatorios, ] %>%
head(15)
#> time_stamp sex height estatura
#> 204 2014-09-02 15:33:16 Female 63 63
#> 1076 2017-07-06 06:04:32 Male 170 170
#> 322 2014-10-12 18:00:26 Female 65 65
#> 378 2014-12-02 15:15:48 Male 67.72 67.72
#> 227 2014-09-03 19:59:55 Male 67 67
#> 666 2015-08-18 18:09:46 Male 58 58
#> 418 2015-01-03 01:37:39 Male 72 72
#> 926 2016-01-27 20:42:03 Female 67 67
#> 320 2014-10-11 05:50:54 Male 5.1 5.1'0
#> 489 2015-02-27 18:05:06 Male 612 612
#> 1038 2016-10-28 13:15:55 Male 76 76
#> 942 2016-02-16 05:36:25 Female 185 185
#> 766 2016-01-11 11:57:58 Male 66 66
#> 592 2015-05-27 08:57:35 Male 89 89
#> 556 2015-05-08 13:39:13 Female 5.6 5.6'0Aun tenemos que hacer unas conversiones. Sin embargo, como ya siguen un patrón determinado podemos utilizar la función extract(columna_origen, nuevas_columnas, patron, remover_origen) para poder crear nuevas columnas por cada valor de nuestro patrón.
patron <- "^([4-7]\\.?\\d*)\\s*'\\s*(\\d+\\.?\\d*)\\s*$"
estaturas %>%
extract(estatura, c("pies", "pulgadas"), regex = patron, remove = FALSE) %>%
head(15)
#> time_stamp sex height estatura pies pulgadas
#> 1 2014-09-02 13:40:36 Male 75 75 <NA> <NA>
#> 2 2014-09-02 13:46:59 Male 70 70 <NA> <NA>
#> 3 2014-09-02 13:59:20 Male 68 68 <NA> <NA>
#> 4 2014-09-02 14:51:53 Male 74 74 <NA> <NA>
#> 5 2014-09-02 15:16:15 Male 61 61 <NA> <NA>
#> 6 2014-09-02 15:16:16 Female 65 65 <NA> <NA>
#> 7 2014-09-02 15:16:19 Female 66 66 <NA> <NA>
#> 8 2014-09-02 15:16:21 Female 62 62 <NA> <NA>
#> 9 2014-09-02 15:16:21 Female 66 66 <NA> <NA>
#> 10 2014-09-02 15:16:22 Male 67 67 <NA> <NA>
#> 11 2014-09-02 15:16:22 Male 72 72 <NA> <NA>
#> 12 2014-09-02 15:16:23 Male 6 6'0 6 0
#> 13 2014-09-02 15:16:23 Male 69 69 <NA> <NA>
#> 14 2014-09-02 15:16:26 Male 68 68 <NA> <NA>
#> 15 2014-09-02 15:16:26 Male 69 69 <NA> <NA>Ahora que ya tenemos los datos que cumplen con el patrón en otras dos columnas, y sabemos que son números, podemos convertir todo a número.
estaturas %>%
extract(estatura, c("pies", "pulgadas"), regex = patron, remove = FALSE) %>%
mutate_at(c("estatura", "pies", "pulgadas"), ~as.numeric(.)) %>%
head(15)
#> Warning: There was 1 warning in `mutate()`.
#> ℹ In argument: `estatura = (structure(function (..., .x = ..1, .y = ..2, . =
#> ..1) ...`.
#> Caused by warning in `as.numeric()`:
#> ! NAs introduced by coercion
#> time_stamp sex height estatura pies pulgadas
#> 1 2014-09-02 13:40:36 Male 75 75 NA NA
#> 2 2014-09-02 13:46:59 Male 70 70 NA NA
#> 3 2014-09-02 13:59:20 Male 68 68 NA NA
#> 4 2014-09-02 14:51:53 Male 74 74 NA NA
#> 5 2014-09-02 15:16:15 Male 61 61 NA NA
#> 6 2014-09-02 15:16:16 Female 65 65 NA NA
#> 7 2014-09-02 15:16:19 Female 66 66 NA NA
#> 8 2014-09-02 15:16:21 Female 62 62 NA NA
#> 9 2014-09-02 15:16:21 Female 66 66 NA NA
#> 10 2014-09-02 15:16:22 Male 67 67 NA NA
#> 11 2014-09-02 15:16:22 Male 72 72 NA NA
#> 12 2014-09-02 15:16:23 Male 6 NA 6 0
#> 13 2014-09-02 15:16:23 Male 69 69 NA NA
#> 14 2014-09-02 15:16:26 Male 68 68 NA NA
#> 15 2014-09-02 15:16:26 Male 69 69 NA NAAhora que nuestras columnas ya son numéricas podemos hacer operaciones para calcular la estatura.
estaturas %>%
extract(estatura, c("pies", "pulgadas"), regex = patron, remove = FALSE) %>%
mutate_at(c("estatura", "pies", "pulgadas"), ~as.numeric(.)) %>%
mutate(est_arregladas = pies*12 + pulgadas) %>%
head(15)
#> Warning: There was 1 warning in `mutate()`.
#> ℹ In argument: `estatura = (structure(function (..., .x = ..1, .y = ..2, . =
#> ..1) ...`.
#> Caused by warning in `as.numeric()`:
#> ! NAs introduced by coercion
#> time_stamp sex height estatura pies pulgadas est_arregladas
#> 1 2014-09-02 13:40:36 Male 75 75 NA NA NA
#> 2 2014-09-02 13:46:59 Male 70 70 NA NA NA
#> 3 2014-09-02 13:59:20 Male 68 68 NA NA NA
#> 4 2014-09-02 14:51:53 Male 74 74 NA NA NA
#> 5 2014-09-02 15:16:15 Male 61 61 NA NA NA
#> 6 2014-09-02 15:16:16 Female 65 65 NA NA NA
#> 7 2014-09-02 15:16:19 Female 66 66 NA NA NA
#> 8 2014-09-02 15:16:21 Female 62 62 NA NA NA
#> 9 2014-09-02 15:16:21 Female 66 66 NA NA NA
#> 10 2014-09-02 15:16:22 Male 67 67 NA NA NA
#> 11 2014-09-02 15:16:22 Male 72 72 NA NA NA
#> 12 2014-09-02 15:16:23 Male 6 NA 6 0 72
#> 13 2014-09-02 15:16:23 Male 69 69 NA NA NA
#> 14 2014-09-02 15:16:26 Male 68 68 NA NA NA
#> 15 2014-09-02 15:16:26 Male 69 69 NA NA NAFinalmente, haremos una validación de si la estatura está en un intervalo y/o si estuvo expresado en centímetros o metros.
# Asumimos para una persona un mínimo 50" (1.2m) y máx 84" (2.1m)
min <- 50
max <- 84
estaturas <- estaturas %>%
extract(estatura, c("pies", "pulgadas"), regex = patron, remove = FALSE) %>%
mutate_at(c("estatura", "pies", "pulgadas"), ~as.numeric(.)) %>%
mutate(est_arregladas = pies*12 + pulgadas) %>%
mutate(estatura_final = case_when(
!is.na(estatura) & between(estatura, min, max) ~ estatura, #pulgadas
!is.na(estatura) & between(estatura/2.54, min, max) ~ estatura/2.54, #cm
!is.na(estatura) & between(estatura*100/2.54, min, max) ~ estatura*100/2.54, #metros
!is.na(est_arregladas) & pulgadas < 12 &
between(est_arregladas, min, max) ~ est_arregladas, #pies'pulgadas
TRUE ~ as.numeric(NA)))
#> Warning: There was 1 warning in `mutate()`.
#> ℹ In argument: `estatura = (structure(function (..., .x = ..1, .y = ..2, . =
#> ..1) ...`.
#> Caused by warning in `as.numeric()`:
#> ! NAs introduced by coercion
# Muestra aleatoria:
indices_aleatorios <- sample(1:nrow(estaturas))
estaturas[indices_aleatorios, ] %>%
select(-time_stamp) %>% # Muestra todas las columnas menos time_stamp
head(10)
#> sex height estatura pies pulgadas est_arregladas estatura_final
#> 114 Female 66.5 66.5 NA NA NA 66.50000
#> 208 Male 70 70.0 NA NA NA 70.00000
#> 30 Male 72 72.0 NA NA NA 72.00000
#> 1015 Male 66 66.0 NA NA NA 66.00000
#> 935 Female 164 164.0 NA NA NA 64.56693
#> 518 Male 66 66.0 NA NA NA 66.00000
#> 850 Male 180 180.0 NA NA NA 70.86614
#> 671 Male 65 65.0 NA NA NA 65.00000
#> 494 Male 168 168.0 NA NA NA 66.14173
#> 268 Male 175 175.0 NA NA NA 68.89764Ya tenemos nuestra muestra validada, solo tendríamos que tomar las columnas que necesitamos y comenzar a utilizar el objeto para los análisis que necesitemos.
11.3 De cadenas a fechas
Regularmente cuando importamos datos, no solo vamos a querer transformar los datos numéricos. También vamos a tener múltiples casos donde necesitamos transformar nuestra cadena a una fecha en algún formato en particular. Para ello, utilizaremos la librería lubridate, incluida en tidyverse, la cual nos provee con diversas funciones para hacer el tratamiento de fechas más accesible.
Cuando la cadena de texto se encuentra en el formato de fecha ISO 8601 (AAAA-MM-DD), podemos utilizar directamente la función month(), day(), year().
fechas_char <- c("2010-05-19", "2020-05-06", "2010-02-03")
str(fechas_char)
#> chr [1:3] "2010-05-19" "2020-05-06" "2010-02-03"
month(fechas_char)
#> [1] 5 5 2Sin embargo, no siempre tenemos la fecha en ese formato y lubridate() de otras funciones que son más flexibles al momento de coercionar datos. Miremos este ejemplo:
fechas <- c(20090101, "2009-01-02", "2009 01 03", "2009-1-4",
"2009-1, 5", "Created on 2009 1 6", "200901 !!! 07")
str(fechas)
#> chr [1:7] "20090101" "2009-01-02" "2009 01 03" "2009-1-4" "2009-1, 5" ...
ymd(fechas)
#> [1] "2009-01-01" "2009-01-02" "2009-01-03" "2009-01-04" "2009-01-05"
#> [6] "2009-01-06" "2009-01-07"El primer dato ingresado fue un número, pero ya sabemos que lo coerciona a texto. Luego, tenemos diferentes valores ingresados, pero todos siguen un mismo patrón. Primero está el año, luego el mes y luego el día. Cuando sabemos que primero está el año, luego mes y luego día usaremos la función ymd() para convertir todas las fechas a formato ISO 8601.
De la misma forma, tendremos las siguientes funciones que podemos utilizar dependiendo de la forma en que tengamos la fecha de nuestra fuente. En todos los casos nos va a convenir convertir a formato ISO 8601. Por ejemplo aquí podemos ver cuándo reconoce correctamente el formato y cuánto el formateo falla.
x <- "28/03/89"
ymd(x)
#> [1] NA
mdy(x)
#> [1] NA
ydm(x)
#> [1] NA
myd(x)
#> [1] NA
dmy(x)
#> [1] "1989-03-28"
dym(x)
#> [1] NAFinalmente, de la misma forma en que podemos utilizar estas funciones de días, meses y años, también podemos usar par referirnos a horas, minutos y segundos.
11.4 Ejercicios
Antes de resolver el siguiente ejercicio ejecuta este Script:
ventas <- tibble(
mes = c("Abril", "Mayo", "Junio"),
ventas = c("s/32,124", "s/35,465", "S/38,332"),
ganancias = c("s/8,120", "s/9,432", "s/10,543")
)- Del objeto
ventasconvierte las columnas de ventas y ganancias a valores numéricos.
Solución
- Dado el vector universidades:
universidades <- c("U. Católica de Chile", "Univ Nacional Autónoma de México",
"Univ. Nacional de Ingeniería", "Universidad de los Andes",
"U de Barcelona", "California State University")Limpia la data para obtener el nombre completo como figura a continuación:
#> [1] "Universidad Católica de Chile"
#> [2] "Universidad Nacional Autónoma de México"
#> [3] "Universidad Nacional de Ingeniería"
#> [4] "Universidad de los Andes"
#> [5] "Universidad de Barcelona"
#> [6] "California State University"Para los siguientes ejercicios, vamos a trabajar sobre los datos de las encuestas realizadas previas al Brexit en Reino Unio. Ejecuta primero el Script:
library(rvest)
library(tidyverse)
url <- "https://en.wikipedia.org/w/index.php?title=Opinion_polling_for_the_United_Kingdom_European_Union_membership_referendum&oldid=896735054"
tabla <- read_html(url) %>% html_nodes("table")
encuestas <- tabla[[5]] %>% html_table(fill = TRUE)- Actualiza el objeto
encuestascon los siguientes nombresc("fecha", "permanecer", "salir", "no_decide", "spread", "muestra", "encuestadora", "tipo", "notas"). No todas las encuestas tienen en la columnapermanecerun valor porcentual. Filtra las columnas para que se muestren solo los valores que contengan el símbolo de%.
Solución
- Almacena los valores de la columna
permaneceral vectorpermanecery convierte los valores al valor numérico del porcentaje. Es decir, valores de 0 a 1 (0.5 en vez de 50%).
Solución
- Encontramos en la columna
no_decideel valor de “N/A” cuando por porcentajes depermanecermássalirsuman 100%. Por ende,no_decidedebería de ser cero en esos casos y no “N/A”. Almacena los valores deno_decideen el vectorno_decidey transforma los valores “N/A” a 0%
- Crea la función
formato_porcentaje(cadena)donde consolides las transformaciones realizadas en los ejercicios anteriores. Luego prueba la función con el vector:c("13.5%", "N/A", "10%")
Solución
- Modifica las columnas de la tabla
encuestaspara cambiar los valores necesarios de texto a números.
Solución
- Importa el siguiente archivo que contiene los casos de covid reportados por el Ministerio de Salud de Perú de la siguiente ruta: “https://www.datosabiertos.gob.pe/sites/default/files/DATOSABIERTOS_SISCOVID.csv” en el objeto
covidPeru. Convierte a tipo fecha la columna fecha de nacimiento y crea un histograma con las edades de los infectados.
Solución
url <- "https://www.datosabiertos.gob.pe/sites/default/files/DATOSABIERTOS_SISCOVID.csv"
covidPeru <- read_csv(url)
# Buscamos a los que no siguen el estándar ISO 8601:
index <- str_detect(covidPeru$FECHA_NACIMIENTO, "\\d{4}-\\d{2}-\\d{2}")
covidPeru$FECHA_NACIMIENTO[!index]
# Vemos fechas en formato DD/MM/AAAA
# Reemplazamos a formato ISO 8601:
covidPeru <- covidPeru %>%
mutate_at("FECHA_NACIMIENTO",
~str_replace(., "(\\d{2})/(\\d{2})/(\\d{4})", "\\3-\\2-\\1")
)
# Volvemos a buscar a los que no siguen el estándar ISO 8601:
index <- str_detect(covidPeru$FECHA_NACIMIENTO, "\\d{4}-\\d{2}-\\d{2}")
covidPeru$FECHA_NACIMIENTO[!index]
# Convertimos la columna a fecha:
covidPeru <- covidPeru %>%
mutate_at("FECHA_NACIMIENTO", ~ymd(.))
# Ahora que ya es formato fecha creamos histograma:
covidPeru %>%
mutate(edad = year(now()) - year(FECHA_NACIMIENTO)) %>%
.$edad %>%
hist()11.5 Minería de texto: Mapa de palabras
La minería de texto es el descubrimiento por computadora de información nueva, previamente desconocida, mediante la extracción automática de información de diferentes recursos escritos. Los recursos escritos pueden ser sitios web, libros, chats, comentarios, correos electrónicos, reseñas, artículos, etc. Así, la minería de texto, también conocida como minería de datos de texto, aproximadamente equivalente al análisis de texto, es el proceso de derivar información de alta calidad del texto.
La primera técnica de minería de texto que aprenderemos será la construcción de mapas de palabras. Para ello, necesitaremos instalar paquetes desarrollados exclusivamente para la minería de texto (text mining en inglés) y algunas librerías para el tratamiento de texto que ya habíamos utilizado como readr o stringr:
install.packages("syuzhet")
install.packages("tm")
install.packages("wordcloud")
library(syuzhet) # Funciones get_
library(stringr) # Funciones str_
library(tm) # Funciones de text mining
library(wordcloud) # Crear mapa de nubes11.5.1 Importando los datos
Los mapas de palabras o nubes de palabras, nos permiten identificar rápidamente cuáles son las palabras que más se repiten en un texto. Son muy útiles cuando tenemos campos que llegan de un formulario, por ejemplo, llenado por los clientes y queremos saber de qué se está hablando más. También nos ayuda para analizar contenido en algún libro, revista, etc.
Vamos a analizar la obra “Niebla” escrita por el autor Miguel de Unamuno. El texto lo obtendremos de la web del Proyecto Gutenberg11, el cual nos da acceso a una librería de alrededor de 60 mil libros gratuitos. Importaremos el texto usando la función get_text_as_string() de la librería syuzhet para importar todo el texto como una cadena. Esta función es muy útil si deseamos importar archivos grandes. Luego, usaremos la función get_sentences(), para crearnos un vector de oraciones a partir del texto inicial.
11.5.2 Limpieza del texto
Como ya hemos aprendido anteriormente, no tenemos que ir directo a analizar. Sino, tenemos que limpiar nuestra data. Lo primero que haremos es eliminar las primeras filas que no corresponden a la obra.
# Eliminamos primeras filas de notas, prólogo, post-prólogo
total_lineas <- length(oraciones)
linea_empieza <- 115
linea_final <- total_lineas - linea_empieza
texto_limpio <- oraciones[linea_empieza:linea_final]A continuación utilizaremos un regex para detectar caracteres especiales de la codificación, como saltos de línea y tabulaciones. Para ello usaremos el regex [[:cntrl:]]. Así mismo, convertiremos todas las palabras a minúsculas para facilitar las comparaciones entre palabras. Finalmente, como queremos analizar las palabras, eliminamos todos los signos de puntuación.
texto_limpio <- texto_limpio %>%
str_replace_all(., "[[:cntrl:]]", " ") %>%
str_to_lower() %>%
removePunctuation() %>%
str_replace_all(., "—", " ")Por otro lado, la librería “tm”, de text mining en inglés, nos provee funciones y vectores para poder limpiar nuestros datos. Ya usamos la función removePunctuation(). Sin embargo, también tenemos la función stopwords("spanish") nos llama a un vector con palabras vacías, es decir, aquellas con poco valor para el análisis, tales como algunas preposiciones y muletillas. Además, usaremos la función removeWors() para remover todas las palabras que se encuentre en nuestro vector de palabras vacías
Finalmente, eliminamos los vacíos excesivos, algunos de ellos creados por las transformaciones anteriores.
11.5.3 Creación del Corpus
Para poder crear un mapa de palabras necesitamos aplicar la función VectorSource() para convertir cada fila a una documento y la función Corpus() que nos permitirá crear estos documentos como una colección de datos.
Ya estamos listos para crear nuestro mapa de palabras. Para ello usaremos la librería wordcloud() y la función del mismo nombre.
wordcloud(coleccion,
min.freq = 5,
max.words = 80,
random.order = FALSE,
colors = brewer.pal(name = "Dark2", n = 8)
)
11.5.4 2da Limpieza de datos
En minería de texto frecuentemente vamos a obtener un resultado que aun requiere de limpiar más datos. Por ejemplo, vemos aun palabras como pronombres de poco interés para el análisis. Volveremos a usar la función removeWords(), pero esta vez con un vector personalizado de las palabras que deseamos retirar.
a_retirar <- c("usted", "pues", "tal", "tan", "así", "dijo",
"cómo", "sino", "entonces", "aunque", "don", "doña")
texto_limpio <- removeWords(texto_limpio, words = a_retirar)
coleccion <- texto_limpio %>%
VectorSource() %>%
Corpus()
wordcloud(coleccion,
min.freq = 5,
max.words = 80,
random.order = FALSE,
colors = brewer.pal(name = "Dark2", n = 8)
)
Augusto y Eugenia, como podemos asumir, son los protagonistas de Niebla y gran parte de la acción en este libro ocurre en la “casa” de uno u otro protagonista, discutiendo las relaciones entre “hombre” y “mujer”.
11.5.5 Frecuencia de palabras
Ya tenemos una idea visual de las palabras más utilizadas. Sin embargo, también podríamos saber exactamente cuántas veces apareció una determinada palabra. Para ello tenemos que convertir nuestra colección a una matrix. Para ello usamos las funciones juntas TermDocumentMatrix(), as.matrix() y rowSums() que nos dejarán con un vector con la frecuencia de palabras.
palabras <- coleccion %>%
TermDocumentMatrix() %>%
as.matrix() %>%
rowSums() %>%
sort(decreasing = TRUE)
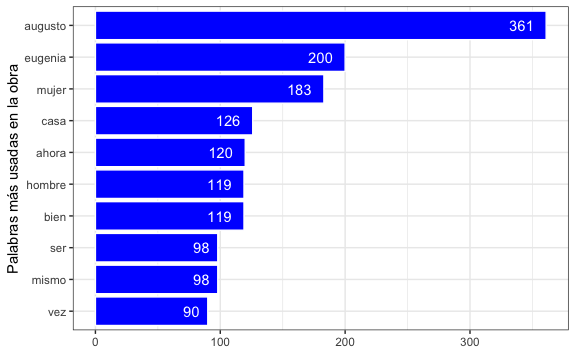
palabras %>%
head(20)
#> augusto eugenia mujer casa ahora bien hombre ser mismo vez
#> 361 200 183 126 120 119 119 98 98 90
#> ojos vida sé cosas fué madre después pobre luego dos
#> 86 84 82 71 71 71 71 69 69 69Con este vector ya es fácil convertirlo a data frame, dado que tenemos los nombres y los valores, y visualizarlo.
frecuencias <- data.frame(
palabra = names(palabras),
frecuencia = palabras
)
# Visualización de top 10 palabras:
frecuencias[1:10,] %>%
ggplot() +
aes(frecuencia, y = reorder(palabra, frecuencia)) +
geom_bar(stat = "identity", color = "white", fill = "blue") +
geom_text(aes(label = frecuencia, hjust = 1.5), color = "white") +
labs(
x = NULL,
y = "Palabras más usadas en la obra"
)
11.6 Minería de texto: Análisis de sentimientos
Cuando analizamos textos no solo vamos a querer saber cuáles son las palabras que más se utilizan en textos, sean estos comentarios dejados por nuestros clientes, solicitudes de reclamo, etc. También es muy útil el saber el tono de los mensajes. Esta técnica es conocida como análisis de sentimientos, la cual se puede hacer muy fácilmente con la librería que ya hemos usado syuzhet.
Y qué mejor lugar para analizar tonos de mensajes que en Twitter. Para ello, vamos a descargar un historial de Tweets de algún personaje Hispanohablante de la página vicinitas.io. Esta página nos permite descargar un excel dada una cuenta pública:
https://www.vicinitas.io/free-tools/download-user-tweets.
Para nuestro ejemplo, utilizaremos tweets de la cuenta de la abogada Rosa María Palacios12. Para este ejemplo ya se ha cargado el excel a Github. Descargaremos ese excel directamente desde ahí a nuestra computadora a un archivo temporal y luego lo leeremos usando read_excel().
url <- "https://dparedesi.github.io/DS-con-R/rmapalacios_user_tweets.xlsx"
# Creamos un nombre & ruta temporal para nuestro archivo.
archivo_temporal <- tempfile()
# Descargamos el archivo en nuestro temporal
download.file(url, archivo_temporal)
# Importamos el excel
publicaciones <- read_excel(archivo_temporal)
# Eliminamos el archivo temporal
file.remove(archivo_temporal)
#> [1] TRUEHemos creado nuestro objeto publicaciones, el cual tiene en la columna Text los diferentes tweets, retweets y replies, realizados. Si bien podríamos hacer un análisis de datos utilizando las otras columnas, nos vamos a centrar en el contenido y tono de los Tweets. Para ello, vamos a eliminar los Retweets y las repuestas, quedándonos solo con los Tweets.
Con lo aprendido haciendo mapas de palabras, creemos un mapa con el contenido de las publicaciones.
tuits_limpio <- tuits %>%
removePunctuation() %>%
str_to_lower() %>%
str_replace_all(., "[[:cntrl:]]", " ") %>%
removeWords(., words = stopwords("spanish")) %>%
removeWords(., words = c("usted", "pues", "tal", "tan",
"así", "dijo", "cómo", "sino",
"entonces", "aunque", "que"))
coleccion <- tuits_limpio %>%
VectorSource() %>%
Corpus()
wordcloud(coleccion,
min.freq = 5,
max.words = 80,
random.order = FALSE,
colors = brewer.pal(name = "Dark2", n = 8)
)
Ella es una abogada, con lo que hace mucho sentido que postee contenido de lo que se puede o no se puede. Podríamos ser más rigurosos y buscar conseguir esta combinación agregando guiónes bajo si se detecta el patrón, pero por el momento nos vamos a enfocar en el tono.
Con nuestro objeto tuits_limpio podemos obtener cuál es el tono utilizando la función get_nrc_sentiment(), la cual nos da un score por cada fila del vector de acuerdo al Léxico de Emociones NRC13. El Léxico de Emociones NRC es una lista de palabras y sus asociaciones con ocho emociones básicas (ira, miedo, anticipación, confianza, asombro, tristeza, alegría y aversión) y dos sentimientos (negativo y positivo).
resultado <- get_nrc_sentiment(tuits_limpio, language = "spanish")
resultado %>%
head(10)
#> anger anticipation disgust fear joy sadness surprise trust negative positive
#> 1 0 1 0 2 1 3 0 3 5 3
#> 2 4 0 3 5 0 3 0 0 7 0
#> 3 0 0 0 0 0 0 0 0 0 0
#> 4 0 1 1 1 1 1 1 1 1 2
#> 5 0 2 0 1 3 1 0 4 0 4
#> 6 0 0 0 0 0 0 0 0 0 0
#> 7 1 1 0 3 0 1 0 1 3 0
#> 8 0 0 0 0 0 1 0 0 2 3
#> 9 1 0 1 1 0 1 0 0 1 0
#> 10 0 0 0 0 0 0 0 0 0 0Podemos realizar algunas transformaciones a este data frame, pero antes vamos a crear una función de traducción. Dado que, aun tenemos que traducir las cabeceras.
trad_emociones <- function(cadena){
case_when(
cadena == "anger" ~ "Ira",
cadena == "anticipation" ~ "Anticipación",
cadena == "disgust" ~ "Aversión",
cadena == "fear" ~ "Miedo",
cadena == "joy" ~ "Alegría",
cadena == "sadness" ~ "Tristeza",
cadena == "surprise" ~ "Asombro",
cadena == "trust" ~ "Confianza",
cadena == "negative" ~ "Negativo",
cadena == "positive" ~ "Positivo",
TRUE ~ cadena
)
}Ahora sí, con nuestra función lista, podemos transformar nuestro objeto resultado para obtener las frecuencias de cada emocion y sentimiento.
# Resumen de las emociones/sentimientos
sentimientos <- resultado %>%
gather(sentimiento, cantidad) %>%
mutate(sentimiento = trad_emociones(sentimiento)) %>%
group_by(sentimiento) %>%
summarise(total = sum(cantidad))
sentimientos
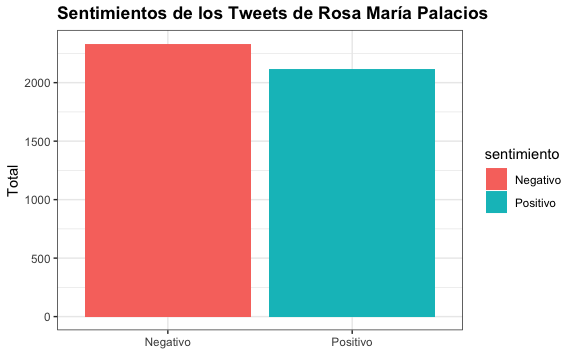
#> # A tibble: 10 × 2
#> sentimiento total
#> <chr> <dbl>
#> 1 Alegría 547
#> 2 Anticipación 903
#> 3 Asombro 421
#> 4 Aversión 810
#> 5 Confianza 1369
#> 6 Ira 803
#> 7 Miedo 1342
#> 8 Negativo 2334
#> 9 Positivo 2117
#> 10 Tristeza 1177Vemos que tenemos las 8 emociones más los 2 sentimientos. Obtengamos los índices de los sentimientos positivos y negativos:
Este vector nos servirá para poder visualizar de forma separada las emociones y los sentimientos.
# Visualización de emociones
sentimientos[!index,] %>%
ggplot() +
aes(sentimiento, total) +
geom_bar(aes(fill = sentimiento), stat = "identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
xlab(NULL) +
ylab("Total") +
ggtitle("Emociones en los Tweets de Rosa María Palacios")
# Visualización de si son sentimientos positivos o negativos:
sentimientos[index,] %>%
ggplot() +
aes(sentimiento, total) +
geom_bar(aes(fill = sentimiento), stat = "identity") +
xlab(NULL) +
ylab("Total") +
ggtitle("Sentimientos de los Tweets de Rosa María Palacios")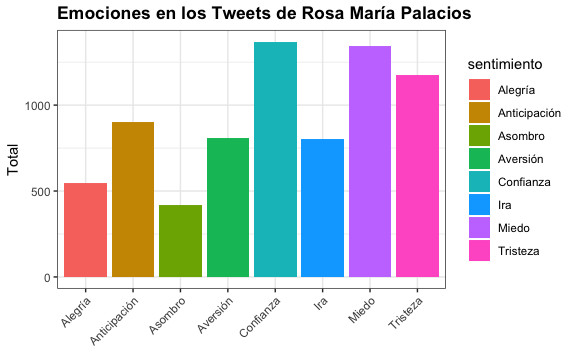
Esta técnica nos es muy útil como punto de partida de futuros análisis sobre la tonalidad de algún determinado texto.
11.7 Ejercicios
Para estos ejercicios utilizaremos más libros del proyecto Project Gutenberg. Sin embargo, extraeremos el texto con una librería en R, la librería gutenbergr.
install.packages("gutenbergr")
library(gutenbergr)
# Tibble: listado de libros en Gutenberg.org
gutenberg_metadata
# Listado de libros en español
gutenberg_works(languages = "es")- La función
gutenberg_download(id)nos descarga el texto en un objeto de tipo tibble con una fila por cada línea. Descarga el libro “El ingenioso hidalgo don Quijote de la Mancha” al objetodescarga. Almacena la columnatexten el objetoobray reporta las primeras 50 líneas del objeto.
- Por la cantidad de líneas de esta obra, tomemos una muestra aleatoria de 1,000 líneas y almacénalo en el objeto
muestra. Remueve las palabras, los signos de puntuación, los saltos de línea y demás elementos aprendidos durante este capítulo. Almacena esta transformación en el objetomuestra_limpia.
Solución
muestra <- sample(obra, 1000)
muestra_limpia <- muestra %>%
str_replace("\xe1", "a") %>% # Removemos las tildes
str_replace("\xe9", "e") %>% # Removemos las tildes
str_replace("\xed", "i") %>% # Removemos las tildes
str_replace("\xf3", "o") %>% # Removemos las tildes
removePunctuation() %>%
str_to_lower() %>%
str_replace_all(., "[[:cntrl:]]", " ") %>%
removeWords(., words = stopwords("spanish")) %>%
removeWords(., words = c("usted", "pues", "tal", "tan",
"así", "dijo", "cómo", "sino",
"entonces", "aunque", "que"))- Crea un mapa de palabras a partir del objeto
muestra_limpia.
Solución
- Realiza un análisis de emociones de la muestra obtenida.
Solución
resultado <- get_nrc_sentiment(muestra_limpia, language = "spanish")
sentimientos <- resultado %>%
gather(sentimiento, cantidad) %>%
mutate(sentimiento = trad_emociones(sentimiento)) %>%
group_by(sentimiento) %>%
summarise(total = sum(cantidad))
index <- sentimientos$sentimiento %in% c("Positivo", "Negativo")
# Visualización de emociones
sentimientos[!index,] %>%
ggplot() +
aes(sentimiento, total) +
geom_bar(aes(fill = sentimiento), stat = "identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
xlab(NULL) +
ylab("Total") +
ggtitle("Emociones en El Quijote")
# Visualización de si son sentimientos positivos o negativos:
sentimientos[index,] %>%
ggplot() +
aes(sentimiento, total) +
geom_bar(aes(fill = sentimiento), stat = "identity") +
xlab(NULL) +
ylab("Total") +
ggtitle("Sentimientos en El Quijote")