Capítulo 14 ¿Cómo ganar dinero con Finsmart?
Finsmart15 es una Fintech enfocada en ofrecer a empresas liquidez a través de la venta de facturas por cobrar (factoring), a través de inversionistas que buscan alternativas atractivas de rentabilidad. Podemos ver un video para comprender mejor el modelo de negocio aquí.
Una vez estamos inscritos en la web y cargamos dinero a nuestra billetera virtual podemos empezar a invertir. La forma en cómo notifican cuando hay facturas dónde invertir es a través de un grupo en Telegram:
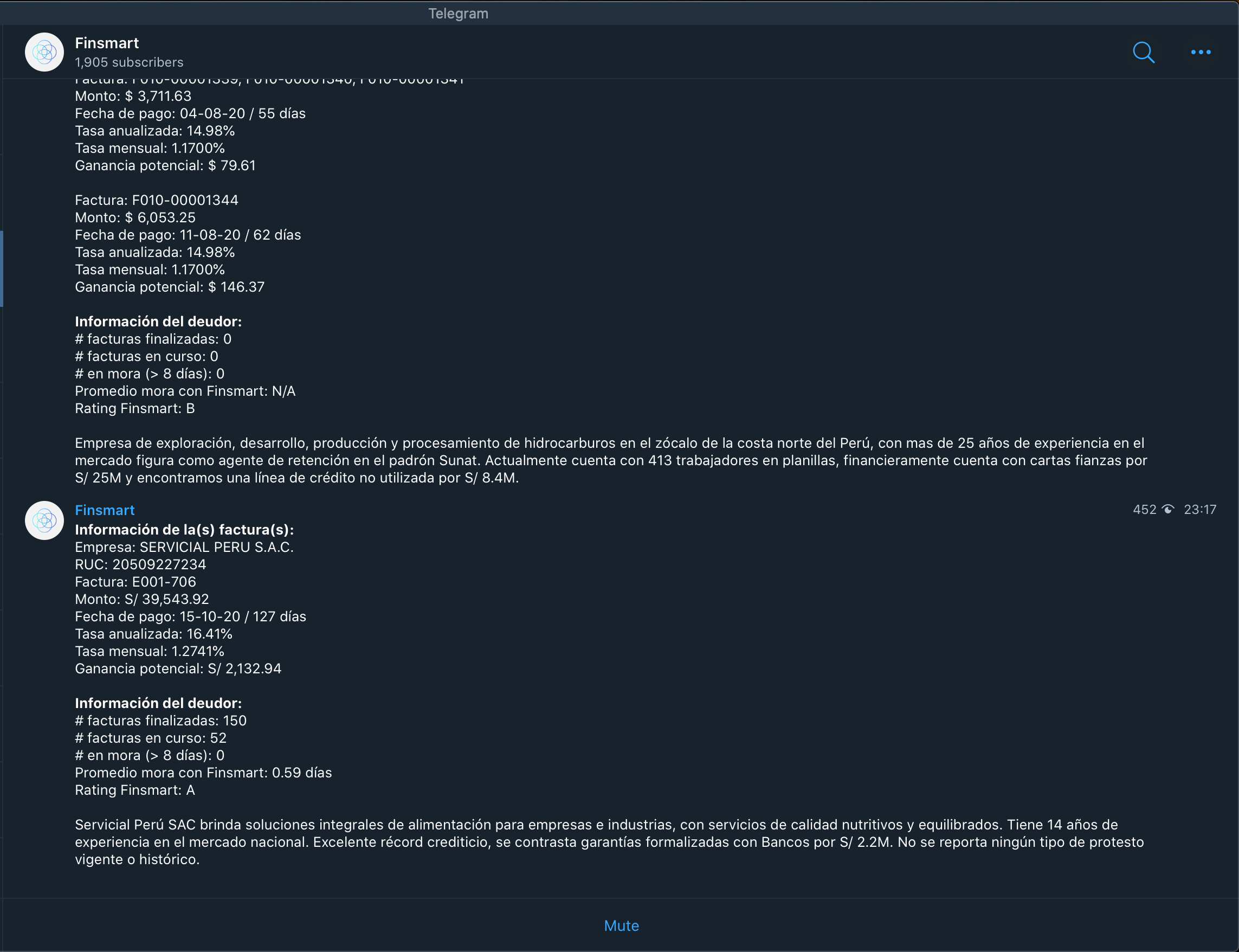
Una vez una factura llega al Telegram tenemos que abrir la plataforma web para invertir.
14.1 Problemática
Existen actualmente alrededor de 2,000 inversores y menos de 5 facturas por día, lo cual ha generado que en menos de 30 segundos las inversiones desaparezcan. Además, al ser inversiones, hay facturas que tienen mayor riesgo que otras, lo cual hace difícil decidir en menos de 30 segundos si invertir en esa factura.
14.2 Acceso a la data
Actualmente el único medio de comunicación es Telegram. Esto hace muy difícil analizar históricos, especialmente en épocas donde el Covid puede haber impactado fuertemente el pago de las facturas. Viendo el video antes señalado se aprecia que la mora ha subido y tienen incluso facturas en proceso judicial que implica hasta un año de cobro.
Afortunadamente tenemos extensiones para Chrome como Save Telegram Chat History que nos permite descargarnos todo el histórico del chat a un archivo de texto plano. Para descargar el archivo tenemos que activar la extensión y luego abrir Telegram web, posicionarnos en el chat y dar click en la extensión para descargar el histórico. Para este análisis se ha colocado ya el archivo en un servidor:
14.2.1 Librerías a utilizar
Para abordar este problema se utilizará librerías ya conocidas en este libro como tidyverse, lubridate y syuzhet, pero también se usará librerías como zoo que permite autocompletar filas que eran NA con el último valor leído, readtext que permite importar archivos txt con todos los caracteres especiales como el salto de línea \n, y directlabels que permite fácilmente colocar las leyendas dentro de nuestro gráfico ggplot.
14.2.2 Importación de datos
Utilizaremos la librería readtext para importar el archivo de texto. Esta librería nos permite incluso leer varios archivos que estén ubicados en una determinada carpeta.
url <- "https://dparedesi.github.io/DS-con-R/finsmart/historico.txt"
chats <- readtext(url)
chats
#> readtext object consisting of 1 document and 0 docvars.
#> # A data frame: 1 × 2
#> doc_id text
#> <chr> <chr>
#> 1 historico.txt "\"Your Teleg\"..."Como vemos, nos genera dos columnas, la primera indicando el nombre del archivo y la segunda todo el contenido. Podemos separar el contenido en filas utilizando la función separate_rows().
data_fuente <- chats[ , 2] %>%
as_tibble() %>%
separate_rows(sep = "\n", value) %>%
slice(-(1:4)) # Removemos primeras 4 filasCon esto ya tendríamos nuestra data fuente con la cual empezar a trabajar.
14.3 Limpieza de datos
Conforme empezamos a analizar vamos a ir notando que hay algunos errores, como p.ej. que han escrito “S/ 4” y “S/4”, algunas veces han enviado “Fecha de pago” y otras “Fechas de Pago” (con la P mayúscula), entre otros errores. Es por ello que se ha recopilado en una función limpiar_datos todos los cambios necesarios que debimos de aplicar antes de separar la data en filas.
limpiar_datos <- function(c){
c %>%
str_replace_all(", Finsmart: ", "\n") %>%
str_replace_all("\nTEA:", "\nTasa anualizada:") %>%
str_replace_all("Fecha de pago", "Fecha de Pago") %>%
str_replace_all("Ganancia potencial", "Ganancia Potencial") %>%
str_replace_all("mensual: \n1.2342", "mensual: 1.2342") %>%
str_replace_all("S/([\\d])", "S/ \\1") %>%
str_replace_all("\\$([\\d])", "$ \\1") %>%
str_replace_all("20\n /", "20 /")
}Una vez tenemos esta función la aplicamos a data para obtener ahora sí nuestra data fuente limpia.
14.4 Transformación de datos
Necesitamos ahora transformar nuestra data de filas a columnas dependiendo de las variables que necesitemos. Se ha tomado el campo fecha como primera variable a extraer y asociar todos los mensajes enviados en ese minuto y segundo.
data <- data_fuente %>%
mutate(fecha = as_datetime(substr(value, 1, 19))) %>%
mutate(atributo = str_extract(value, "[^:]*")) %>%
mutate(valor = gsub(".*:\\s*","", value)) %>%
mutate_at(c("atributo", "valor"), ~str_trim(.)) %>%
mutate(aux_fecha = fecha) %>%
mutate(fecha = na.locf(fecha)) %>%
filter(is.na(aux_fecha)) %>%
filter(valor != "") %>%
select(atributo, valor, fecha) %>%
rowid_to_column("id") %>% # Se agrega solo para validar calidad de data
mutate(empresa_aux = ifelse(atributo =="Empresa", valor, NA))
data
#> # A tibble: 6,148 × 5
#> id atributo valor fecha empresa_aux
#> <int> <chr> <chr> <dttm> <chr>
#> 1 1 Empresa ADMINISTRACION DE E… 2020-01-02 15:34:20 ADMINISTRA…
#> 2 2 Factura E001-123, E001-125,… 2020-01-02 15:34:20 <NA>
#> 3 3 Monto $ 2,472.95 2020-01-02 15:34:20 <NA>
#> 4 4 Fecha de Pago 28-01-20 / 26 días 2020-01-02 15:34:20 <NA>
#> 5 5 Tasa anualizada 15.41% 2020-01-02 15:34:20 <NA>
#> 6 6 Ganancia Potencial $ 25.75 2020-01-02 15:34:20 <NA>
#> 7 7 Rating Finsmart A++ 2020-01-02 15:34:20 <NA>
#> 8 8 Empresa ADMINISTRACION DE E… 2020-01-02 15:34:20 ADMINISTRA…
#> 9 9 Factura E001-38, E001-141, … 2020-01-02 15:34:20 <NA>
#> 10 10 Monto $ 397.93 2020-01-02 15:34:20 <NA>
#> # ℹ 6,138 more rowsLuego, se ha extraído los datos únicos de fecha + empresa_aux:
empresas_por_fecha <- data %>%
filter(!is.na(empresa_aux)) %>%
select(fecha, empresa = empresa_aux) %>%
unique()
empresas_por_fecha
#> # A tibble: 401 × 2
#> fecha empresa
#> <dttm> <chr>
#> 1 2020-01-02 15:34:20 ADMINISTRACION DE EMPRESAS S.A.C.
#> 2 2020-01-02 15:41:20 AJEPER S.A.
#> 3 2020-01-02 16:40:00 DIMATIC S.A.C
#> 4 2020-01-02 22:34:53 IPESA HYDRO S.A.
#> 5 2020-01-03 01:21:18 Import Notebook SAC
#> 6 2020-01-03 15:10:12 Import Notebook SAC
#> 7 2020-01-03 20:54:07 LEONCITO SOCIEDAD ANONIMA
#> 8 2020-01-03 21:10:35 Servicial Perú SAC
#> 9 2020-01-03 21:14:28 Import Notebook SAC
#> 10 2020-01-03 21:15:26 TVOLUTION S.A.C.
#> # ℹ 391 more rowsEste dataset se utilizará para crear la columna empresa:
data <- data %>%
left_join(empresas_por_fecha, by = "fecha") %>%
select(id, fecha, empresa, atributo, valor) %>%
filter(atributo != "Empresa") %>%
mutate(empresa = str_to_upper(empresa))Al hacer un group by por empresa notamos que hay empresas que son la misma, pero fueron escritas de diferente forma. Por ello usamos un corrector para normalizar los datos. Así mismo, se detectó una inconsistencia que consiste en haber subido un registro errado, el cual eliminamos.
data <- data %>%
mutate(empresa = case_when(
empresa == "AMERICAN REAL ESTATE SOCIEDAD ANONIMA CERRADA"
~ "AMERICAN REAL ESTATE SAC",
empresa == "DESARROLLO SERVICIOS INVERSIONES Y TELECOMUNICACIONES PERU S.A.C"
~ "DESARROLLO SERVICIOS INVERSIONES Y TELECOMUNICACIONES PERU S.A.C.",
empresa == "SERVICIAL PERÚ SAC" ~ "SERVICIAL PERU S.A.C.",
empresa == "TERMO SISTEMAS SAC" ~ "TERMOSISTEMAS SAC",
empresa == "LOS PORTALES S.A" ~ "LOS PORTALES S.A.",
empresa == "BLUE MARKET SAC" ~ "BLUE MARKET S.A.C",
empresa == "HOMECENTERS PERUANOS ORIENTE S.A.C."
~ "HOMECENTERS PERUANOS S.A.",
empresa == "MAR ANDINO PERÚ SAC" ~ "MAR ANDINO PERU S.A.C.",
empresa == "MINACORP SAC" ~ "MINACORP S.A.C.",
TRUE ~ empresa
))
# Removemos 1 error de finsmart en la carga de data:
data <- data %>%
filter(!(empresa == "PETROLEOS DEL PERU PETROPERU SA" &
atributo == "Rating Finsmart" & valor == "A"))14.5 Creación de datasets
Podemos apreciar que la columna atributo contiene datos relacionadas a facturas y también a información de la empresa deudora. Por ello, vamos a crear datasets que nos permitan visualizar la información por separado.
14.5.1 Histórico de facturas publicadas
Para ello podemos hacer un group_by por atributo y encontraremos los atributos que corresponden a las facturas. Luego usaremos esa información para extraer las filas del dataset data:
# Atributos correspondientes a cada oportunidad de inversión:
atributos_facturas <- c("Factura", "Monto", "Fecha de Pago",
"Ganancia Potencial", "Tasa anualizada",
"Tasa mensual")
historico_facturas <- data %>%
filter(atributo %in% atributos_facturas) %>%
mutate(factura = ifelse(atributo == "Factura", valor, NA)) %>%
mutate(factura = na.locf(factura)) %>%
filter(atributo != "Factura") %>%
select(fecha, empresa, factura, atributo, valor) %>%
mutate_at("atributo", ~ str_replace_all(., "\\s", "_")) %>%
spread(atributo, valor) %>%
separate("Fecha_de_Pago", c("f_pago", "dias_inv"), sep = "/") %>%
separate("Ganancia_Potencial", c("moneda", "ganancia_potencial"),
sep = " ", extra = "merge") %>%
separate("Monto", c("moneda_", "monto"), sep = " ", extra = "merge") %>%
select(-moneda_) %>%
mutate(f_pago = dmy(f_pago)) %>%
mutate_at(c("dias_inv", "ganancia_potencial", "monto", "Tasa_anualizada",
"Tasa_mensual"), ~parse_number(.))
historico_facturas
#> # A tibble: 615 × 10
#> fecha empresa factura f_pago dias_inv moneda
#> <dttm> <chr> <chr> <date> <dbl> <chr>
#> 1 2020-01-02 15:34:20 ADMINISTRACION DE EMP… E001-1… 2020-01-28 26 $
#> 2 2020-01-02 15:34:20 ADMINISTRACION DE EMP… E001-3… 2020-01-31 29 $
#> 3 2020-01-02 15:41:20 AJEPER S.A. E001-1… 2020-02-14 43 S/.
#> 4 2020-01-02 15:41:20 AJEPER S.A. E001-1… 2020-02-14 43 S/.
#> 5 2020-01-02 16:40:00 DIMATIC S.A.C E001-29 2020-02-06 35 S/.
#> 6 2020-01-02 16:40:00 DIMATIC S.A.C E001-30 2020-02-08 37 S/.
#> 7 2020-01-02 22:34:53 IPESA HYDRO S.A. E001-5… 2020-04-09 98 $
#> 8 2020-01-03 01:21:18 IMPORT NOTEBOOK SAC E001-7… 2020-03-13 71 S/.
#> 9 2020-01-03 01:21:18 IMPORT NOTEBOOK SAC E001-7… 2020-03-15 73 S/.
#> 10 2020-01-03 15:10:12 IMPORT NOTEBOOK SAC E001-7… 2020-03-10 67 $
#> # ℹ 605 more rows
#> # ℹ 4 more variables: ganancia_potencial <dbl>, monto <dbl>,
#> # Tasa_anualizada <dbl>, Tasa_mensual <dbl>14.5.2 Histórico del deudor:
De la misma forma, podemos obtener los atributos que corresponden solo al deudor:
atributos_deudor <- c("Rating Finsmart", "# facturas en curso",
"# facturas finalizadas", "Promedio mora con Finsmart",
"# en mora (> 8 días)")
historico_deudor <- data %>%
filter(atributo %in% atributos_deudor) %>%
select(-id) %>%
mutate(atributo = case_when(
atributo == "Rating Finsmart" ~ "rating",
atributo == "# facturas en curso" ~ "en_curso",
atributo == "# facturas finalizadas" ~ "finalizadas",
atributo == "Promedio mora con Finsmart" ~ "promedio_mora",
atributo == "# en mora (> 8 días)" ~ "mora_mas_8_dias",
TRUE ~ as.character("")
)) %>%
unique() %>%
spread(atributo, valor) %>%
mutate_at(c("en_curso", "finalizadas", "mora_mas_8_dias", "promedio_mora"),
~parse_number(.)) %>%
mutate(rating_n = case_when(rating == "A++" ~ 5, rating == "A+" ~ 4,
rating == "A" ~ 3, rating == "B+" ~ 2,
rating == "B" ~ 1, TRUE ~ 0))
historico_deudor
#> # A tibble: 401 × 8
#> fecha empresa en_curso finalizadas mora_mas_8_dias
#> <dttm> <chr> <dbl> <dbl> <dbl>
#> 1 2020-01-02 15:34:20 ADMINISTRACION DE E… NA NA NA
#> 2 2020-01-02 15:41:20 AJEPER S.A. NA NA NA
#> 3 2020-01-02 16:40:00 DIMATIC S.A.C NA NA NA
#> 4 2020-01-02 22:34:53 IPESA HYDRO S.A. NA NA NA
#> 5 2020-01-03 01:21:18 IMPORT NOTEBOOK SAC NA NA NA
#> 6 2020-01-03 15:10:12 IMPORT NOTEBOOK SAC NA NA NA
#> 7 2020-01-03 20:54:07 LEONCITO SOCIEDAD A… NA NA NA
#> 8 2020-01-03 21:10:35 SERVICIAL PERU S.A.… NA NA NA
#> 9 2020-01-03 21:14:28 IMPORT NOTEBOOK SAC NA NA NA
#> 10 2020-01-03 21:15:26 TVOLUTION S.A.C. NA NA NA
#> # ℹ 391 more rows
#> # ℹ 3 more variables: promedio_mora <dbl>, rating <chr>, rating_n <dbl>14.6 Calcular datasets de probabilidades de publicación
Ahora que ya tenemos tanto el histórico de la publicación de facturas podemos calcular la probabilidad de publicación por día y por hora para analizar posteriormente si hay una tendencia a publicar en algún determinado día u hora.
prob_x_dia_x_mes <- historico_facturas %>%
group_by(mes = month(fecha), dia = as.POSIXlt(fecha)$wday) %>%
summarise(t = n()) %>%
mutate(prob = t / sum(t)) %>%
select(-t) %>%
mutate(dia = case_when(dia == 1 ~ "lu", dia == 2 ~ "ma",
dia == 3 ~ "mie", dia == 4 ~ "jue",
dia == 5 ~ "vie", dia == 6 ~ "sab",
TRUE ~ as.character("do") ))
#> `summarise()` has grouped output by 'mes'. You can override using the `.groups`
#> argument.
prob_x_hora <- historico_facturas %>%
group_by(mes = month(fecha), hora = hour(fecha)) %>%
summarise(t = n()) %>%
mutate(prob = t / sum(t)) %>%
select(-t)
#> `summarise()` has grouped output by 'mes'. You can override using the `.groups`
#> argument.14.7 Visualización
Ahora que ya contamos con todos los datasets necesarios para el análisis podemos realizar visualizaciones para detectar insights.
14.7.1 Probabilidad de publicar por día
Podemos visualizar la probabilidad de que se publique por día. Habiendo 5 días a la semana, uno esperaría que haya un 20% de probabilidad cada día.
prob_x_dia_x_mes %>%
ggplot() +
aes(mes, prob, col = dia) +
geom_line() +
ggtitle("Probabilidad de publicar factura por día") +
geom_dl(aes(label = dia), method = "last.points") +
theme(legend.position = "none")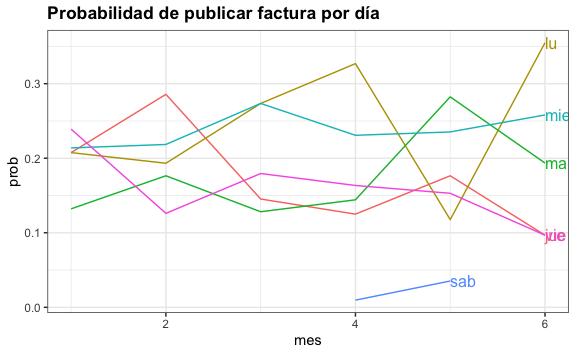
Vemos cómo los lunes, martes y miércoles la probabilidad de publicar una factura es más alta del 20%. Sin embargo, vemos cómo los jueves y viernes la probabilidad es de entre 10% a 15%. Como inversionista, sería más eficiente estar pendiente los primeros días de la semana.
14.7.2 Probabilidad de publicar por hora
De la misma forma, podemos visualizar la probabilidad de que se publique a determinada hora del día (UK time).
prob_x_hora %>%
mutate(hora = as.character(hora)) %>%
ggplot() +
aes(mes, prob, col = hora, group = hora ) +
geom_line() +
ggtitle("Probabilidad de publicar factura por hora") +
geom_dl(aes(label = hora), method = "top.points"
#method = list(dl.combine("first.points", "last.points"))
) +
theme(legend.position = "none")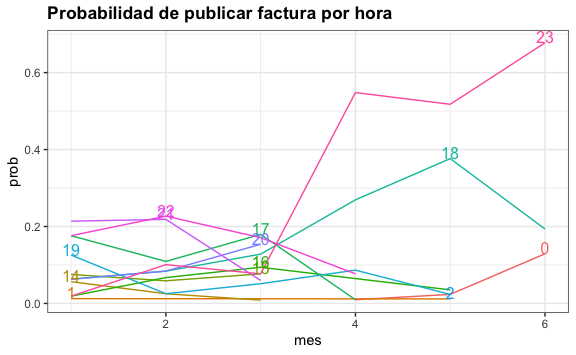
Vemos claramente una tendencia de publicaciones a las 23 hrs (5pm en Lima) y a las 18 hrs (mediodía en Lima). Sin saber nada de la empresa podemos ver sus hábitos de sus procesos operativos.
14.7.3 ¿En qué empresas invertir?
Ahora que ya sabemos que hay días y horas en los que se publican más facturas faltaría analizar en qué empresas invertir. Para ello se ha creado el dataset empresas_target donde se encuentran las top 10 empresas que más facturas han sido cargadas a la plataforma en los dos últimos meses.
fecha_2_meses_atras <- seq(now(), length = 2, by = "-2 months")[2]
fecha_2_meses_atras <- as.Date(fecha_2_meses_atras)
empresas_target <- historico_deudor %>%
filter(!is.na(finalizadas)) %>%
filter(fecha >= fecha_2_meses_atras) %>%
group_by(empresa) %>%
summarise(total = max(finalizadas), ult = max(fecha)) %>%
top_n(10, total)
empresas_target
#> # A tibble: 0 × 3
#> # ℹ 3 variables: empresa <chr>, total <dbl>, ult <dttm>
empresas_target <- empresas_target%>%
.$empresa14.7.3.1 Evolución del rating por empresa
El primer criterio sería ver cómo ha evolucionado el rating de cada empresa. Una empresa A++ tiene un valor de 5 puntos, A tiene 4 puntos, etc.
historico_deudor %>%
filter(empresa %in% empresas_target) %>%
ggplot() +
aes(fecha, rating_n, col = empresa) +
geom_point() +
geom_line() +
geom_dl(aes(label = empresa), method = list(cex = 0.5, "smart.grid") ) +
theme(legend.position = "none") +
labs(x = "", y = "Rating Finsmart",
title = "Evolución del rating por empresa")
Vemos como es que a pesar del Covid ninguna empresa ha disminuido el rating que le asigna Finsmart. Incluso vemos cómo en febrero la empresa TVOLUTION S.A.C. incrementó su rating. TVOLUTION no solo ha subido su rating sino que tiene es una de las que más facturas publicadas tiene.
14.7.3.2 Evolución de la mora promedio
Un dato importante para evaluar una inversión es si el deudor ha incrementado su mora (días que demora en pagar), en especial en épocas de Covid.
historico_deudor %>%
filter(empresa %in% empresas_target) %>%
ggplot() +
aes(fecha, promedio_mora, col = empresa) +
geom_point() +
geom_line() +
scale_y_continuous(trans = "log2") +
geom_dl(aes(label = empresa), method = list(cex = 0.5, "top.points") ) +
theme(legend.position = "none") +
labs(x = "", y = "Días de mora", title = "Evolución de la mora promedio")
Detectamos una empresa Gestión de servicios compartidos como la única que ha incrementado su promedio de mora. Ésta sería la única empresa donde no deberíamos de invertir. Todas las demás empresas target han mantenido su mora o la han reducido. Así mismo vemos cómo TVOLUTION e IPESA HYDRO S.A. son las que más han reducido su mora. Esto nos da seguridad para invertir en estas dos empresas.
14.7.3.3 Evolución de la tasa ofrecida por empresa
Finalmente, analizaremos si han habido cambios en la tasa de retorno ofrecida por cada empresa.
historico_facturas %>%
filter(empresa %in% empresas_target) %>%
ggplot() +
aes(fecha, Tasa_anualizada, col = empresa) +
geom_point() +
geom_line() +
geom_dl(aes(label = empresa), method = list(cex = 0.5, "smart.grid") ) +
theme(legend.position = "none") +
labs(x = "", y = "Tasa anual (%)",
title = "Evolución de la tasa ofrecida por empresa")

Vemos que todos se mantienen igual. Solo IPESA ha disminuido, probablemente porque es una empresa que factura en dólares y pagar una tasa de 14.5% anual ya era bastante alto.
14.8 Conclusión
Hemos extraído insights a partir de un chat de Telegram y hemos podido determinar:
- Que los días de mayor publicación son los lunes, martes y miércoles.
- Que las horas de publicación son normalmente al mediodía y a las 5pm (hora de Lima). Siendo las 5:14pm la hora más probable de encontrar factura.
- La empresa más segura para invertir es TVOLUTION, con un rating que ha subido en los últimos meses, un promedio de mora cada vez menor y una tasa anualizada de casi 16.5% de retorno anual.
- Las siguientes empresas con desempeño sostenibles son: SERVICIAL PERÚ, IPESA, e IMPORT NOTEBOOK.
- Por el incremento en la mora no invertiría en la empresa de Gestión de servicios compartidos