Capítulo 3 Data Frames
3.1 Introducción a los Data Frames
En los capítulos anteriores, exploramos diferentes tipos de objetos en R, como variables, vectores, listas y matrices. Estos objetos nos permiten almacenar información de maneras más eficientes. Ahora, en este capítulo, nos adentraremos en el mundo de los data frames, una herramienta esencial para organizar y analizar la información que te ayudará a tomar la mejor decisión sobre tu mudanza a Estados Unidos.
3.1.1 ¿Qué son los data frames?
Imagina una hoja de cálculo, con filas y columnas que organizan la información de manera tabular. En R, un data frame es precisamente eso: una estructura de datos que almacena información en un formato tabular, con filas que representan observaciones (por ejemplo, cada ciudad de Estados Unidos) y columnas que representan variables (como población, costo de vida, tasa de criminalidad).
Cada columna de un data frame puede contener un tipo de dato diferente: numérico, carácter, lógico, factor, etc. Esto hace que los data frames sean muy versátiles para almacenar información diversa.
Por ejemplo, un data frame sobre ciudades de Estados Unidos podría contener las siguientes columnas:
ciudad: Nombre de la ciudad (carácter).estado: Estado al que pertenece la ciudad (carácter).poblacion: Población de la ciudad (numérico).area: Área de la ciudad en kilómetros cuadrados (numérico).tiene_playa: Valor lógico que indica si la ciudad tiene playa (TRUEoFALSE).
3.1.2 ¿Por qué data frames?
En R, existen diversas estructuras para organizar datos, como vectores, listas y matrices. Sin embargo, los data frames se destacan como una herramienta fundamental en el análisis de datos. ¿Por qué?
Los data frames ofrecen una combinación única de características que los hacen ideales para representar y manipular información compleja:
- Estructura tabular: Organizan los datos en filas y columnas, como una hoja de cálculo, lo que facilita su visualización y comprensión.
- Flexibilidad en los tipos de datos: Cada columna puede contener un tipo de dato diferente (números, texto, fechas, etc.), lo que permite representar la diversidad de información del mundo real.
- Eficiencia en el análisis: La mayoría de las funciones y paquetes de análisis de datos en R están diseñados para trabajar con data frames.
En resumen, los data frames son una estructura de datos versátil y poderosa que se adapta a las necesidades del análisis de datos moderno.
3.1.3 Data Frames en acción: explorando información sobre Estados Unidos
En el contexto de tu mudanza a Estados Unidos, los data frames serán esenciales para organizar y analizar la información que necesitas para tomar la mejor decisión. Podemos usar data frames para almacenar información sobre:
- Criminalidad: Tasas de criminalidad en diferentes estados.
- Costo de vida: Costo de vivienda, alimentación, transporte en diferentes ciudades.
- Clima: Temperaturas promedio, precipitaciones, días de sol en diferentes regiones.
- Demografía: Población, edad promedio, nivel educativo en diferentes estados.
Con esta información organizada en data frames, podrás realizar análisis más profundos y tomar decisiones más informadas sobre tu mudanza.
3.2 Creando Data Frames: Construyendo tu base de datos para la mudanza
Ahora que ya sabes qué son los data frames y por qué son tan importantes en el análisis de datos, es hora de aprender a crearlos. En R, podemos crear data frames de diferentes maneras: importando datos desde archivos externos o creándolos manualmente.
3.2.1 Importando datos desde archivos: CSV, Excel
Una forma común de crear data frames es importando datos desde archivos externos, como archivos CSV (Comma Separated Values) o archivos de Excel. R nos ofrece funciones para leer datos de diferentes formatos.
Importando datos desde archivos CSV: Para importar datos desde un archivo CSV, usamos la función
read.csv().url <- "https://dparedesi.github.io/DS-con-R/notas-estudiantes.csv" # Importar datos desde un archivo CSV llamado "notas-estudiantes.csv" ciudades <- read.csv(url) ciudades #> inicio genero tipo P1 P2 P3 P4 P5 P6 #> 1 03/05/2020 mujer Trabajo individual 1 5 5 5 5 5 5 #> 2 03/05/2020 hombre Trabajo individual 1 5 5 5 5 4 5 #> 3 03/05/2020 mujer Trabajo individual 1 5 5 4 5 5 5 #> 4 03/05/2020 hombre Trabajo individual 1 5 5 5 5 5 5 #> 5 03/05/2020 hombre Trabajo individual 1 2 5 5 5 5 5 #> 6 03/05/2020 hombre Trabajo individual 1 5 4 5 1 5 5 #> 7 03/05/2020 hombre Trabajo individual 1 2 1 5 5 2 5 #> 8 03/05/2020 hombre Trabajo individual 1 5 5 5 5 5 5 #> 9 03/05/2020 hombre Trabajo individual 1 4 5 5 5 5 5 #> 10 03/05/2020 hombre Trabajo individual 1 3 4 5 5 5 5 #> 11 03/05/2020 hombre Trabajo individual 1 2 5 5 5 5 5 #> 12 03/05/2020 mujer Trabajo individual 1 1 1 5 5 5 1 #> 13 03/05/2020 hombre Trabajo individual 1 5 5 5 5 5 5 #> 14 03/05/2020 mujer Trabajo individual 1 3 5 5 1 1 1 #> 15 03/05/2020 hombre Trabajo individual 1 4 5 5 5 5 5 #> 16 03/05/2020 mujer Trabajo individual 1 5 5 5 5 5 5 #> 17 03/05/2020 hombre Trabajo individual 1 5 1 5 5 1 1 #> 18 03/05/2020 mujer Trabajo individual 1 4 5 5 5 5 5 #> 19 03/05/2020 hombre Trabajo individual 1 5 3 5 5 5 2 #> 20 03/05/2020 hombre Trabajo individual 1 3 5 5 5 5 5 #> 21 03/05/2020 hombre Trabajo individual 1 1 4 4 4 5 5La función
read.csv()tiene varios argumentos opcionales que nos permiten personalizar la importación de datos. Algunos de los argumentos más comunes son:header: Indica si el archivo tiene una fila de encabezado (TRUEoFALSE).sep: Especifica el carácter que se usa para separar las columnas (por defecto, la coma “,”).dec: Especifica el carácter que se usa para separar los decimales (por defecto, el punto “.”).
Importando datos desde archivos de Excel: Para importar datos desde un archivo de Excel, podemos usar la función
read_excel()del paquetereadxl.# Instalar el paquete readxl (si no lo tienes instalado) install.packages("readxl") # Cargar el paquete readxl library(readxl) # Importar datos desde un archivo de Excel llamado "estados.xlsx" estados <- read_excel("estados.xlsx")La función
read_excel()tiene varios argumentos opcionales, comosheetpara especificar la hoja de cálculo que se quiere importar.
3.2.2 Creando data frames manualmente
También podemos crear data frames manualmente, combinando vectores con la función data.frame().
# Crear vectores con información sobre ciudades
ciudades <- c("Nueva York", "Los Ángeles", "Chicago")
estados <- c("Nueva York", "California", "Illinois")
poblacion <- c(8.4e6, 3.9e6, 2.7e6)
# Crear un data frame con la información de las ciudades
df_ciudades <- data.frame(ciudad = ciudades, estado = estados, poblacion = poblacion)
df_ciudades
#> ciudad estado poblacion
#> 1 Nueva York Nueva York 8400000
#> 2 Los Ángeles California 3900000
#> 3 Chicago Illinois 2700000En este ejemplo, creamos un data frame llamado df_ciudades con tres columnas: ciudad, estado y poblacion. Cada columna se crea a partir de un vector. Observa que los vectores deben tener la misma longitud para que se puedan combinar en un data frame.
3.2.3 Ejemplos
Podemos usar data frames para organizar información diversa sobre nuestra mudanza a Estados Unidos. Por ejemplo, podríamos crear un data frame con información sobre diferentes ciudades, incluyendo su costo de vida, tasa de criminalidad, y clima. También podríamos crear un data frame con información sobre los diferentes estados, incluyendo su población, producto interno bruto (PIB), y sistema educativo.
# Crear un data frame con información sobre ciudades
df_ciudades <- data.frame(
ciudad = c("Nueva York", "Los Ángeles", "Chicago", "Houston"),
estado = c("Nueva York", "California", "Illinois", "Texas"),
costo_vida = c(3.5, 2.8, 2.5, 2.0), # En miles de dólares
tasa_criminalidad = c(400, 350, 500, 450), # Por cada 100,000 habitantes
clima = c("Templado", "Mediterráneo", "Continental", "Subtropical")
)
df_ciudades
#> ciudad estado costo_vida tasa_criminalidad clima
#> 1 Nueva York Nueva York 3.5 400 Templado
#> 2 Los Ángeles California 2.8 350 Mediterráneo
#> 3 Chicago Illinois 2.5 500 Continental
#> 4 Houston Texas 2.0 450 Subtropical
# Crear un data frame con información sobre estados
df_estados <- data.frame(
estado = c("California", "Texas", "Florida", "Nueva York"),
poblacion = c(39.2e6, 29.0e6, 21.4e6, 19.4e6),
pib = c(3.2e12, 1.8e12, 1.1e12, 1.7e12), # En dólares
sistema_educativo = c("Bueno", "Regular", "Bueno", "Excelente")
)
df_estados
#> estado poblacion pib sistema_educativo
#> 1 California 39200000 3.2e+12 Bueno
#> 2 Texas 29000000 1.8e+12 Regular
#> 3 Florida 21400000 1.1e+12 Bueno
#> 4 Nueva York 19400000 1.7e+12 ExcelenteEstos data frames nos permitirán analizar la información de forma más eficiente y tomar decisiones más informadas sobre nuestra mudanza.
3.3 Explorando Data Frames: Descubriendo los secretos de tus datos
Ya hemos aprendido a crear data frames, ahora es momento de explorar su contenido y descubrir la información que esconden. R nos ofrece diversas herramientas para examinar y comprender nuestros datos.
3.3.1 Accediendo a filas, columnas y celdas
Un data frame es como un mapa organizado en filas y columnas. Para acceder a la información que necesitamos, debemos saber cómo navegar por este mapa. R nos proporciona diferentes maneras de acceder a las filas, columnas y celdas de un data frame.
Accediendo a columnas: Podemos acceder a una columna de un data frame usando el operador
$seguido del nombre de la columna.# Acceder a la columna "estado" del data frame "df_ciudades" df_ciudades$estado #> [1] "Nueva York" "California" "Illinois" "Texas"También podemos acceder a una columna usando el nombre del data frame seguido de corchetes y el nombre de la columna entre comillas.
Accediendo a filas: Podemos acceder a una fila de un data frame usando corchetes y el número de la fila.
Accediendo a celdas: Podemos acceder a una celda específica de un data frame usando corchetes y especificando la fila y la columna.
Filtrando filas con condiciones: Podemos usar condiciones lógicas para filtrar las filas de un data frame. Por ejemplo, si queremos obtener las ciudades con un costo de vida menor a 3:
3.3.2 Funciones para explorar data frames
R nos ofrece varias funciones útiles para explorar data frames:
head(): Muestra las primeras 6 filas del data frame.tail(): Muestra las últimas 6 filas del data frame.str(): Muestra la estructura del data frame, incluyendo el nombre de las columnas, el tipo de dato de cada columna y los primeros valores de cada columna.str(df_ciudades) #> 'data.frame': 4 obs. of 5 variables: #> $ ciudad : chr "Nueva York" "Los Ángeles" "Chicago" "Houston" #> $ estado : chr "Nueva York" "California" "Illinois" "Texas" #> $ costo_vida : num 3.5 2.8 2.5 2 #> $ tasa_criminalidad: num 400 350 500 450 #> $ clima : chr "Templado" "Mediterráneo" "Continental" "Subtropical"summary(): Proporciona estadísticas descriptivas de cada columna del data frame, como la media, la mediana, los valores mínimo y máximo, etc.summary(df_estados) #> estado poblacion pib sistema_educativo #> Length:4 Min. :19400000 Min. :1.10e+12 Length:4 #> Class :character 1st Qu.:20900000 1st Qu.:1.55e+12 Class :character #> Mode :character Median :25200000 Median :1.75e+12 Mode :character #> Mean :27250000 Mean :1.95e+12 #> 3rd Qu.:31550000 3rd Qu.:2.15e+12 #> Max. :39200000 Max. :3.20e+12View(): Abre una ventana con una vista interactiva del data frame, similar a una hoja de cálculo.
3.3.3 Ejemplos: explorando data frames con información sobre la mudanza
Al explorar los data frames que creamos en la sección anterior, podemos obtener información valiosa sobre las ciudades y estados de Estados Unidos. Por ejemplo, podríamos usar summary() para obtener estadísticas descriptivas del costo de vida en diferentes ciudades, o View() para examinar en detalle la información sobre cada estado.
# Obtener estadísticas descriptivas del costo de vida en diferentes ciudades
summary(df_ciudades$costo_vida)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 2.000 2.375 2.650 2.700 2.975 3.500Además de las funciones mencionadas, podemos usar otras herramientas para explorar nuestros data frames. Por ejemplo, podemos usar la función table() para obtener la frecuencia de cada valor en una columna categórica, como la columna clima en el data frame df_ciudades.
También podemos usar la función hist() para crear un histograma de una columna numérica, como la columna poblacion en el data frame df_estados.

Estas son solo algunas ideas de cómo podemos explorar nuestros data frames. A medida que te familiarices con R, descubrirás nuevas funciones y técnicas para analizar y visualizar tus datos.
3.4 Manipulando Data Frames: Transformando tus datos
En la sección anterior, aprendimos a explorar data frames y acceder a la información que contienen. Ahora, daremos un paso más allá y aprenderemos a manipular data frames, transformando los datos para responder preguntas específicas y obtener información relevante para nuestra mudanza.
3.4.1 Introducción al operador pipeline (%>%)
Antes de manipular data frames, introduciremos una herramienta para escribir código más legible y eficiente: el operador pipeline (%>%). Este operador se encuentra en el paquete tidyverse, una colección de paquetes de R diseñados para la ciencia de datos. Uno de los paquetes incluidos en tidyverse es dplyr, que contiene muchas funciones útiles para trabajar con data frames.
Un paquete en R es como una caja de herramientas con funciones y datos adicionales para realizar tareas específicas. Para usar las funciones de un paquete, primero debemos instalarlo y luego cargarlo en nuestro entorno de trabajo.
Para instalar el paquete tidyverse, podemos usar la siguiente instrucción en la consola de R:
Esto instalará tidyverse y todos los paquetes que contiene, incluyendo dplyr. Una vez instalado el paquete, podemos cargarlo con la función library():
Ahora ya podemos usar el operador pipeline (%>%) y las demás funciones de dplyr.
El operador pipeline nos permite encadenar varias operaciones de forma secuencial. En lugar de escribir código anidado, podemos usar el operador pipeline para “pasar” el resultado de una operación a la siguiente.
Por ejemplo, si queremos visualizar solo los datos estado, población y total del data frame murders (del paquete dslabs), podemos usar un pipeline:
# Cargar la librería y el dataset
library(dslabs)
data(murders)
# Pipeline
murders %>% select(state, population, total)
#> state population total
#> 1 Alabama 4779736 135
#> 2 Alaska 710231 19
#> 3 Arizona 6392017 232
#> 4 Arkansas 2915918 93
#> 5 California 37253956 1257
#> 6 Colorado 5029196 65
#> 7 Connecticut 3574097 97
#> 8 Delaware 897934 38
#> 9 District of Columbia 601723 99
#> 10 Florida 19687653 669
#> 11 Georgia 9920000 376
#> 12 Hawaii 1360301 7
#> 13 Idaho 1567582 12
#> 14 Illinois 12830632 364
#> 15 Indiana 6483802 142
#> 16 Iowa 3046355 21
#> 17 Kansas 2853118 63
#> 18 Kentucky 4339367 116
#> 19 Louisiana 4533372 351
#> 20 Maine 1328361 11
#> 21 Maryland 5773552 293
#> 22 Massachusetts 6547629 118
#> 23 Michigan 9883640 413
#> 24 Minnesota 5303925 53
#> 25 Mississippi 2967297 120
#> 26 Missouri 5988927 321
#> 27 Montana 989415 12
#> 28 Nebraska 1826341 32
#> 29 Nevada 2700551 84
#> 30 New Hampshire 1316470 5
#> 31 New Jersey 8791894 246
#> 32 New Mexico 2059179 67
#> 33 New York 19378102 517
#> 34 North Carolina 9535483 286
#> 35 North Dakota 672591 4
#> 36 Ohio 11536504 310
#> 37 Oklahoma 3751351 111
#> 38 Oregon 3831074 36
#> 39 Pennsylvania 12702379 457
#> 40 Rhode Island 1052567 16
#> 41 South Carolina 4625364 207
#> 42 South Dakota 814180 8
#> 43 Tennessee 6346105 219
#> 44 Texas 25145561 805
#> 45 Utah 2763885 22
#> 46 Vermont 625741 2
#> 47 Virginia 8001024 250
#> 48 Washington 6724540 93
#> 49 West Virginia 1852994 27
#> 50 Wisconsin 5686986 97
#> 51 Wyoming 563626 5El código con pipeline es más fácil de leer y entender, ya que sigue el flujo natural de las operaciones. Pipeline crea una vista; no estamos editando el data frame murders.
Podemos mostrar las primeras filas usando la función head():
head(murders %>% select(state, population, total))
#> state population total
#> 1 Alabama 4779736 135
#> 2 Alaska 710231 19
#> 3 Arizona 6392017 232
#> 4 Arkansas 2915918 93
#> 5 California 37253956 1257
#> 6 Colorado 5029196 65También podemos usar el operador pipeline para mostrar las primeras filas:
murders %>% select(state, population, total) %>% head()
#> state population total
#> 1 Alabama 4779736 135
#> 2 Alaska 710231 19
#> 3 Arizona 6392017 232
#> 4 Arkansas 2915918 93
#> 5 California 37253956 1257
#> 6 Colorado 5029196 65Para una mejor legibilidad, usaremos una función por línea, obteniendo el mismo resultado:
3.4.2 Transformando una tabla con mutate()
Podemos crear nuevas columnas o modificar existentes usando la función mutate(). Por ejemplo, para agregar una columna con el ratio de homicidios por cada 100 mil habitantes al data frame murders:
murders %>%
mutate(ratio = total / population * 100000) %>%
head()
#> state abb region population total ratio
#> 1 Alabama AL South 4779736 135 2.824424
#> 2 Alaska AK West 710231 19 2.675186
#> 3 Arizona AZ West 6392017 232 3.629527
#> 4 Arkansas AR South 2915918 93 3.189390
#> 5 California CA West 37253956 1257 3.374138
#> 6 Colorado CO West 5029196 65 1.292453Esto crea una vista con la columna adicional ratio.
Si queremos modificar el data frame murders directamente, usamos el operador de asignación <-:
3.4.3 Filtrando datos: seleccionando las ciudades que te interesan
Podemos filtrar filas que cumplen una condición usando la función filter(). Por ejemplo, para obtener los estados con menos de 1 homicidio por cada 100 mil habitantes:
# Cargar el dataset
data(murders)
murders %>%
mutate(ratio = total / population * 100000) %>%
filter(ratio < 1)
#> state abb region population total ratio
#> 1 Hawaii HI West 1360301 7 0.5145920
#> 2 Idaho ID West 1567582 12 0.7655102
#> 3 Iowa IA North Central 3046355 21 0.6893484
#> 4 Maine ME Northeast 1328361 11 0.8280881
#> 5 Minnesota MN North Central 5303925 53 0.9992600
#> 6 New Hampshire NH Northeast 1316470 5 0.3798036
#> 7 North Dakota ND North Central 672591 4 0.5947151
#> 8 Oregon OR West 3831074 36 0.9396843
#> 9 South Dakota SD North Central 814180 8 0.9825837
#> 10 Utah UT West 2763885 22 0.7959810
#> 11 Vermont VT Northeast 625741 2 0.3196211
#> 12 Wyoming WY West 563626 5 0.8871131Podemos usar diferentes operadores para crear nuestras condiciones:
>: mayor que<: menor que>=: mayor o igual que<=: menor o igual que==: igual a!=: diferente a
También podemos combinar condiciones usando operadores lógicos:
&: AND (y)|: OR (o)!: NOT (no)
Por ejemplo, para filtrar por ratio menor a 1 y región Oeste:
murders %>%
mutate(ratio = total / population * 100000) %>%
filter(ratio < 1 & region == "West")
#> state abb region population total ratio
#> 1 Hawaii HI West 1360301 7 0.5145920
#> 2 Idaho ID West 1567582 12 0.7655102
#> 3 Oregon OR West 3831074 36 0.9396843
#> 4 Utah UT West 2763885 22 0.7959810
#> 5 Wyoming WY West 563626 5 0.88711313.4.4 Ordenando datos: encontrando las ciudades más seguras
La función arrange() del paquete dplyr nos permite ordenar las filas de un data frame según una o varias columnas. Imagina que tienes un data frame con información sobre diferentes ciudades, y quieres ordenarlas de la más segura a la menos segura, basándote en su tasa de criminalidad. O tal vez quieres ordenarlas por costo de vida, de la más barata a la más cara. arrange() te permite hacer esto de forma sencilla.
Por ejemplo, para ordenar los estados por tasa de homicidios (de menor a mayor):
murders %>%
mutate(ratio = total / population * 100000) %>%
arrange(ratio) %>%
head()
#> state abb region population total ratio
#> 1 Vermont VT Northeast 625741 2 0.3196211
#> 2 New Hampshire NH Northeast 1316470 5 0.3798036
#> 3 Hawaii HI West 1360301 7 0.5145920
#> 4 North Dakota ND North Central 672591 4 0.5947151
#> 5 Iowa IA North Central 3046355 21 0.6893484
#> 6 Idaho ID West 1567582 12 0.7655102Si queremos ordenar de forma descendente, usamos la función desc():
murders %>%
mutate(ratio = total / population * 100000) %>%
arrange(desc(ratio)) %>%
head()
#> state abb region population total ratio
#> 1 District of Columbia DC South 601723 99 16.452753
#> 2 Louisiana LA South 4533372 351 7.742581
#> 3 Missouri MO North Central 5988927 321 5.359892
#> 4 Maryland MD South 5773552 293 5.074866
#> 5 South Carolina SC South 4625364 207 4.475323
#> 6 Delaware DE South 897934 38 4.231937También podemos ordenar por varias columnas. Por ejemplo, si queremos ordenar primero por region y luego por estado (en orden alfabético):
murders %>%
arrange(region, state) %>%
head()
#> state abb region population total
#> 1 Connecticut CT Northeast 3574097 97
#> 2 Maine ME Northeast 1328361 11
#> 3 Massachusetts MA Northeast 6547629 118
#> 4 New Hampshire NH Northeast 1316470 5
#> 5 New Jersey NJ Northeast 8791894 246
#> 6 New York NY Northeast 19378102 5173.4.5 Agregando y resumiendo datos: obteniendo información general
La función summarize() del paquete dplyr nos permite calcular estadísticas descriptivas de una o varias columnas de un data frame. Es como si pudiéramos resumir la información de nuestro data frame en un solo número o en un conjunto de números.
Por ejemplo, para calcular la media de la población de los estados:
Podemos combinar summarize() con group_by() para calcular estadísticas por grupos. Por ejemplo, para calcular la población promedio por región:
3.4.6 Uniendo data frames: combinando información
Imagina que tienes dos data frames: uno con información sobre ciudades (nombre, población, etc.) y otro con información sobre los estados a los que pertenecen esas ciudades (nombre del estado, gobernador, etc.). Si quieres combinar la información de ambos data frames para tener un único data frame con toda la información de las ciudades y sus estados, puedes usar las funciones de unión de dplyr.
dplyr ofrece varias funciones para unir data frames, como left_join(), right_join(), inner_join() y full_join(). Cada función realiza un tipo de unión diferente, dependiendo de cómo se combinen las filas de los data frames.
La función left_join() une dos data frames manteniendo todas las filas del primer data frame (el de la izquierda) y añadiendo las columnas del segundo data frame que coinciden con las filas del primer data frame. Si una fila del primer data frame no tiene una coincidencia en el segundo data frame, las nuevas columnas tendrán valores NA.
Por ejemplo, si tenemos un data frame con información sobre ciudades y otro data frame con información sobre estados, podemos unirlos por la columna estado:
El data frame resultante df_ciudades_estados contendrá la información de ambos data frames combinada. Si una ciudad en df_ciudades no tiene un estado correspondiente en df_estados, las columnas de df_estados tendrán valores NA para esa ciudad.
Veamos un ejemplo concreto. Supongamos que tenemos los siguientes data frames:
df_ciudades <- data.frame(
ciudad = c("Nueva York", "Los Ángeles", "Chicago", "Houston"),
estado = c("Nueva York", "California", "Illinois", "Texas")
)
df_estados <- data.frame(
estado = c("California", "Texas", "Florida"),
gobernador = c("Gavin Newsom", "Greg Abbott", "Ron DeSantis")
)
# Unir los data frames por la columna "estado"
df_ciudades_estados <- left_join(df_ciudades, df_estados, by = "estado")
df_ciudades_estados
#> ciudad estado gobernador
#> 1 Nueva York Nueva York <NA>
#> 2 Los Ángeles California Gavin Newsom
#> 3 Chicago Illinois <NA>
#> 4 Houston Texas Greg AbbottEn este ejemplo, left_join() combina los data frames df_ciudades y df_estados por la columna estado. Observa que las ciudades “Nueva York” y “Chicago” tienen valores NA en la columna gobernador, ya que sus estados (“Nueva York” e “Illinois”) no están presentes en el data frame df_estados.
Las otras funciones de unión (right_join(), inner_join() y full_join()) funcionan de manera similar, pero con diferentes criterios para combinar las filas de los data frames.
right_join()hace lo opuesto aleft_join(): mantiene todas las filas del data frame de la derecha y solo las filas del data frame de la izquierda que coinciden.inner_join()solo mantiene las filas que tienen coincidencias en ambos data frames.full_join()mantiene todas las filas de ambos data frames, añadiendoNAdonde no hay coincidencias.
Puedes consultar la documentación de dplyr para obtener más información sobre estas funciones.
3.4.7 Ejemplos
Las funciones de dplyr que hemos visto nos permiten realizar transformaciones de datos complejas para responder preguntas específicas sobre nuestra mudanza a Estados Unidos. Veamos algunos ejemplos con código en R:
Filtrar las ciudades con un buen sistema educativo y un bajo costo de vida:
Ordenar los estados por su PIB per cápita:
Unir un data frame de ciudades con un data frame de información climática:
Con estas herramientas, podrás explorar y analizar la información sobre Estados Unidos para tomar la mejor decisión sobre tu mudanza.
3.5 Ejercicios
- Reporta las columnas abreviación del estado
abby la poblaciónpopulationdel data framemurders
- Reporta todos los datos de data frame que no sean de la región sur (“South” en inglés).
Si queremos filtrar todos los registros que sean de la región South y West usaremos
%in%en vez de==para comparar versus un vector
- Crea el vector sur_y_oeste que contenga los valores “South” y “West”. Luego filtra los registros que sean de esas dos regiones.
- Agrega la columna
ratioal data framemurderscon el ratio de asesinatos por 100 mil habitantes. Luego, filtra los que tengan un ratio menor a 0.5 y sean de las regiones “South” y “West”. Reporta las columnasstate,abbyratio.
Solución
Para ordenar usando pipeline utilizamos la función
arrange(x), dondexes el nombre de la columna que queremos tomar tomo referencia la cual ordenará de forma ascendente oarrange(desc(x))para ordenar en forma descendente.
- Modifica el código generado en el ejercicio anterior para ordenar el resultado por el campo
ratio.
Solución
Así, finalmente podemos saber qué opciones de estados tenemos para poder mudarnos y resolver el caso presentado.3.6 Data frames en gráficos
Ahora veremos algunas funciones que nos permiten visualizar nuestra data. Poco a poco iremos construyendo gráficos más complejos y visualmente más estéticos para presentar. Primero veamos las funciones más básicas que R nos presenta. En el siguiente capítulo veremos más a detalle los tipos de gráficos y en qué situaciones es recomendable usar uno u otro gráfico.
3.6.1 Gráficos de dispersión
Uno de los gráficos más utilizados en R es el gráfico o diagrama de dispersión, el cual es un tipo de diagrama matemático que utiliza las coordenadas cartesianas para mostrar los valores de dos variables para un conjunto de datos (Jarrell 1994, 492). Por defecto asumimos que las variables a analizar son independientes. Así, el diagrama de dispersión mostrará el grado de correlación (no causalidad) entre las dos variables.
La manera más sencilla de graficar un gráfico de dispersión es con la función plot(x,y), donde x y y son vectores que indican las coordenas del eje-x y las coordenadas del eje-y de cada punto que queremos graficar. Por ejemplo, veamos la relación entre el tamaño de la población y el total de asesinatos.
# Almacenemos en el objeto eje_x los datos de población
eje_x <- murders$population
# Almacenemos en el objeto eje_x los datos de población
eje_y <- murders$total
# Con este código creamos el gráfico de dispersión
plot(eje_x, eje_y)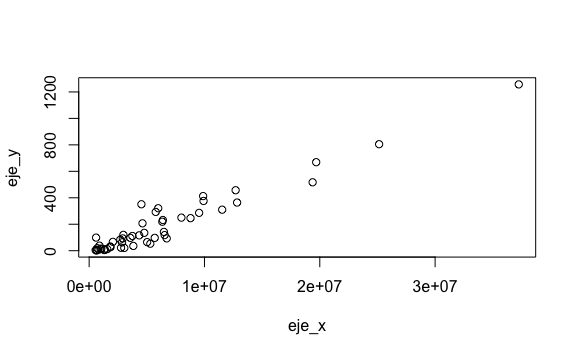
Podemos ver una correlación entre la población y el número de casos. Transformemos el eje_x dividiendo por un millón (\({10}^6\)). Así tendremos el eje x expresado en millones.
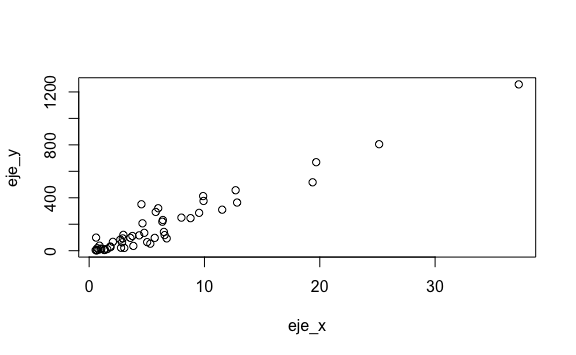
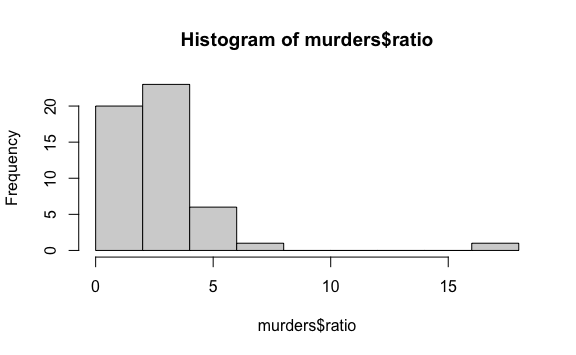
3.7 Interpretación de datos
Hemos visto gráficos que se pueden generar con una línea de código, pero necesitamos interpretarlos. Para ello, necesitamos aprender o recordar algunos estadísticos. Vamos a aprender a lo largo de este libro concepto estadísticos no entrando a profundidad en la parte matemática, sino desde la parte práctica y aprovechando que ya existen las funciones en R.
Recordemos nuestro caso/problemática. Tenemos un listado de asesinatos en cada uno de los 51 estados. Si los ordenemos por la columna total tendríamos:
murders %>%
arrange(total) %>%
head()
#> state abb region population total ratio
#> 1 Vermont VT Northeast 625741 2 0.3196211
#> 2 North Dakota ND North Central 672591 4 0.5947151
#> 3 New Hampshire NH Northeast 1316470 5 0.3798036
#> 4 Wyoming WY West 563626 5 0.8871131
#> 5 Hawaii HI West 1360301 7 0.5145920
#> 6 South Dakota SD North Central 814180 8 0.9825837R nos provee con la función summary(), la cual nos da un resumen de los datos de un vector.
Min.: Mínimo valor del vector1st Qu.: Primer cuartilMedian: Mediana o segundo cuartilMean: Promedio3rd Qu.: Tercer cuartilMax.: Máximo valor del vector
3.7.1 Cuartiles
Para comprender los cuartiles visualicemos el total de los datos de forma ordenada. Para solo obtener una sola columna en pipeline usaremos .$ antes del nombre de la variable:
murders %>%
arrange(total) %>%
.$total
#> [1] 2 4 5 5 7 8 11 12 12 16 19 21 22 27 32
#> [16] 36 38 53 63 65 67 84 93 93 97 97 99 111 116 118
#> [31] 120 135 142 207 219 232 246 250 286 293 310 321 351 364 376
#> [46] 413 457 517 669 805 1257Los cuartiles dividen nuestro vector en 4 partes con la misma cantidad de datos. Dado que tenemos 51 valores, tendríamos grupos de 51/4 = 12.75. Tendríamos grupos de 13 valores (3 grupos de 13 elementos y uno de 12 elementos).
Por ejemplo, el primer grupo estaría compuesto por estos números:
#> [1] 2 4 5 5 7 8 11 12 12 16 19 21 22El segundo grupo estaría compuesto por estos números:
#> [1] 27 32 36 38 53 63 65 67 84 93 93 97 97Y así sucesivamente. En total 4 grupos conformado por el 25% de los datos c/u.
3.7.1.1 Primer cuartil
Por lo tanto, cuando veamos el 1er cuartil, 1st Qu., pensemos que ese es el corte que nos indica hasta dónde puedo encontrar al 25% de los datos.
En nuestro ejemplo 24.5 indica que todo número menor o igual que es número estará dentro del 25% de los primeros datos (25% de 51 datos = 12.75, redondeado a 13 datos).
Si listamos los números menores o iguales a 24.5 tendremos este listado:
murders %>%
arrange(total) %>%
filter(total <= 24.5) %>%
.$total
#> [1] 2 4 5 5 7 8 11 12 12 16 19 21 22Que es exactamente el mismo listado que obtuvimos anteriormente para el primer grupo.
3.7.1.2 Segundo cuartil o mediana
El segundo cuartil, también llamado la mediana (Median), nos indica el corte del segundo grupo. El primer grupo contiene los primeros 25% datos, el segundo grupo tiene 25% adicionales. Así que este corte nos daría exactamente el valor que se encuentra al medio.
En nuestro ejemplo 97 indica que debajo de es número encontraremos 50% del total de datos (50% de 51 datos = 25.5, redondeado a 26 datos).
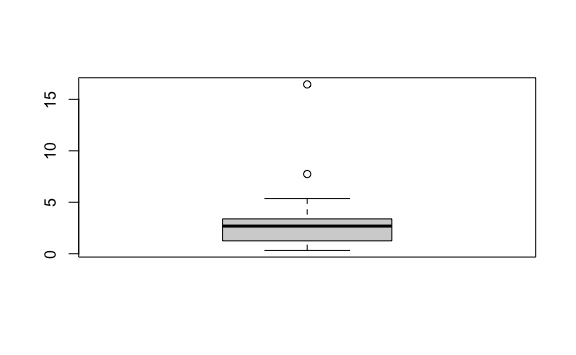
3.7.2 Interpretación del gráfico de cajas
Ya estamos listos para crear un gráfico de cajas con el total de asesinatos e interpretar los resultados.
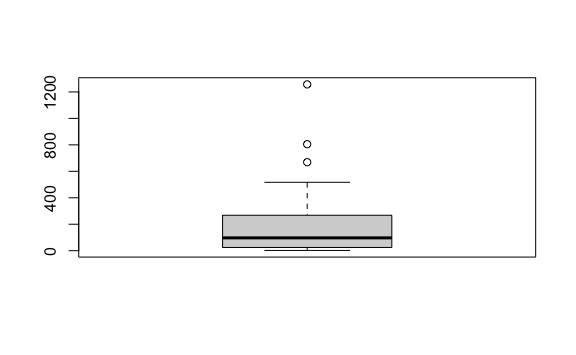
La caja empieza en el valor 24.5 (primer cuartil) y termina en el valor de 268 (tercer cuartil). La línea ancha representa la mediana (segundo cuartil), 97 en nuestro ejemplo.
Entre el primer cuartil y el tercer cuartil (entre 24.5 y 97 para nuestro ejemplo) encontraremos 50% de la data, también llamado rango intercuartil or IQRpor sus siglas en inglés.
Fuera de la caja vemos una línea vertical hacia arriba y otra hacia abajo, mostrando el rango de nuestros datos. Fuera de esas líneas vemos unos puntos que son datos atípicos muy alejados de la media, conocidos como outliers.
Podemos encontrar rápidamente a qué estados pertenecen estos datos extremos si ordenamos la tabla descendentemente usando la función desc:
murders %>%
arrange(desc(total)) %>%
head()
#> state abb region population total ratio
#> 1 California CA West 37253956 1257 3.374138
#> 2 Texas TX South 25145561 805 3.201360
#> 3 Florida FL South 19687653 669 3.398069
#> 4 New York NY Northeast 19378102 517 2.667960
#> 5 Pennsylvania PA Northeast 12702379 457 3.597751
#> 6 Michigan MI North Central 9883640 413 4.178622Vemos que en California se reportaron 1257 casos. Ese es uno de los datos extremo que vemos en el gráfico de cajas.
3.7.3 Ejemplos
- Crea la variable
pob_log10y almacena los datos del logaritmo 10 de la población (funciónlog10()). Realiza la misma transformación a logaritmo 10 para el total de asesinatos y almacénalo en la variabletot_log10. Genera un gráfico de dispersión de estas dos variables.

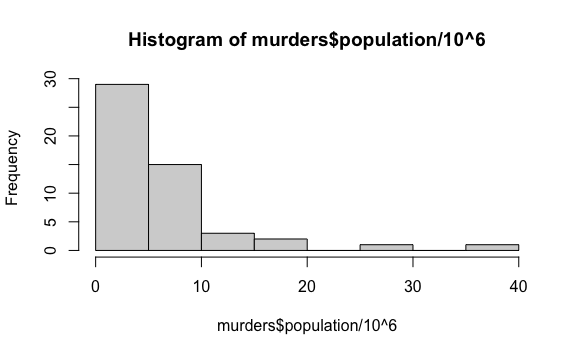
- Crea un histograma de la población en millones (dividido por \({10}^6\)).
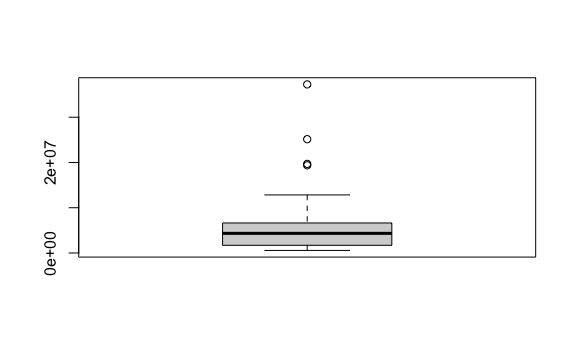
- Crea un diagrama de cajas de la población.
3.8 Ejercicios
A continuación, encontrarás una serie de ejercicios con diferentes niveles de dificultad. Es hora de poner en práctica lo que has aprendido en este capítulo. Recuerda que puedes usar las funciones de dplyr como filter(), arrange(), mutate(), summarize(), group_by() y left_join() para manipular los data frames.
Crea un data frame llamado
mis_gastoscon las siguientes columnas:categoria: Un factor con las categorías “Vivienda”, “Transporte”, “Alimentación” y “Entretenimiento”.enero: Gastos en enero para cada categoría.febrero: Gastos en febrero para cada categoría.marzo: Gastos en marzo para cada categoría.
Solución
mis_gastos <- data.frame(
categoria = factor(c("Vivienda", "Transporte", "Alimentación", "Entretenimiento")),
enero = c(1500, 300, 500, 200),
febrero = c(1500, 250, 400, 150),
marzo = c(1500, 350, 550, 250)
)
mis_gastos
#> categoria enero febrero marzo
#> 1 Vivienda 1500 1500 1500
#> 2 Transporte 300 250 350
#> 3 Alimentación 500 400 550
#> 4 Entretenimiento 200 150 250- Usa las funciones
head(),tail(),str()ysummary()para explorar el data framemis_gastos.
Solución
head(mis_gastos)
#> categoria enero febrero marzo
#> 1 Vivienda 1500 1500 1500
#> 2 Transporte 300 250 350
#> 3 Alimentación 500 400 550
#> 4 Entretenimiento 200 150 250
tail(mis_gastos)
#> categoria enero febrero marzo
#> 1 Vivienda 1500 1500 1500
#> 2 Transporte 300 250 350
#> 3 Alimentación 500 400 550
#> 4 Entretenimiento 200 150 250
str(mis_gastos)
#> 'data.frame': 4 obs. of 4 variables:
#> $ categoria: Factor w/ 4 levels "Alimentación",..: 4 3 1 2
#> $ enero : num 1500 300 500 200
#> $ febrero : num 1500 250 400 150
#> $ marzo : num 1500 350 550 250
summary(mis_gastos)
#> categoria enero febrero marzo
#> Alimentación :1 Min. : 200 Min. : 150 Min. : 250.0
#> Entretenimiento:1 1st Qu.: 275 1st Qu.: 225 1st Qu.: 325.0
#> Transporte :1 Median : 400 Median : 325 Median : 450.0
#> Vivienda :1 Mean : 625 Mean : 575 Mean : 662.5
#> 3rd Qu.: 750 3rd Qu.: 675 3rd Qu.: 787.5
#> Max. :1500 Max. :1500 Max. :1500.0- Accede a la columna
febrerodel data framemis_gastosusando el operador$. Luego, accede a la segunda fila del data frame usando corchetes.
Solución
- Filtra el data frame
mis_gastospara obtener solo las filas donde los gastos enenerosean mayores a 400.
Solución
- Ordena el data frame
mis_gastosde forma descendente según los gastos enmarzo.
Solución
- Agrega una columna llamada
totalal data framemis_gastosque contenga la suma de los gastos de enero, febrero y marzo para cada categoría.
- Calcula la media y la desviación estándar de los gastos totales para cada categoría en el data frame
mis_gastos.
Solución
- Agrupa el data frame
mis_gastospor categoría y calcula la suma de los gastos para cada mes.
Solución
mis_gastos %>%
group_by(categoria) %>%
summarize(suma_enero = sum(enero),
suma_febrero = sum(febrero),
suma_marzo = sum(marzo))
#> # A tibble: 4 × 4
#> categoria suma_enero suma_febrero suma_marzo
#> <fct> <dbl> <dbl> <dbl>
#> 1 Alimentación 500 400 550
#> 2 Entretenimiento 200 150 250
#> 3 Transporte 300 250 350
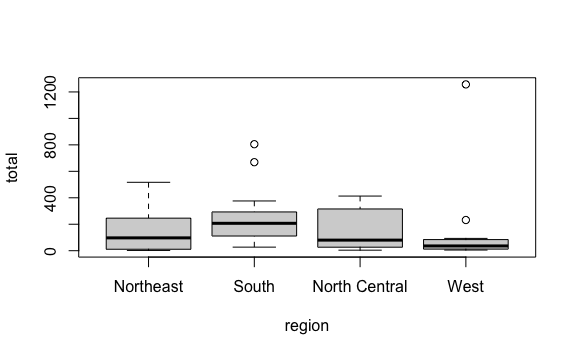
#> 4 Vivienda 1500 1500 1500- Analiza visualmente el siguiente gráfico que describe la distribución del total de asesionatos por regiones. Solo visualizándolo podrías señalar ¿qué región tiene el menor rango de datos, obviando outliers? ¿qué región tiene la mediana más alta?
Solución
El oeste (West) tiene el menor rango de datos y tiene dos outliers. El sur (South) tiene la mediana más alta entre todas las regiones.
Analizar únicamente viendo un gráfico nos permite colocarnos en los zapatos del observador final y comprender si solo con la información presentada se puede tomar decisiones.- Crea el vector
surdonde almacenes los datos filtrados del total de asesinatos que ocurrieron en la región sur. Luego, crea un histograma del vectorsur.
- Crea un nuevo data frame llamado
df_ciudades_climaque combine la información dedf_ciudadesydf_clima(debes crear el data framedf_climacon información climática de las ciudades). Asegúrate de que el data frame resultante contenga todas las ciudades dedf_ciudades, incluso si no tienen información climática endf_clima.
Solución
- Crea un data frame con algunos valores faltantes (
NA). Luego, reemplaza los valores faltantes por la media de los valores no faltantes en la misma columna.
Solución
# Crear un data frame con valores faltantes
df_con_na <- data.frame(
x = c(1, 2, NA, 4, 5),
y = c(NA, 7, 8, NA, 10)
)
df_con_na
#> x y
#> 1 1 NA
#> 2 2 7
#> 3 NA 8
#> 4 4 NA
#> 5 5 10
# Reemplazar los valores faltantes por la media
df_con_na <- df_con_na %>%
mutate(x = ifelse(is.na(x), mean(x, na.rm = TRUE), x),
y = ifelse(is.na(y), mean(y, na.rm = TRUE), y))
df_con_na
#> x y
#> 1 1 8.333333
#> 2 2 7.000000
#> 3 3 8.000000
#> 4 4 8.333333
#> 5 5 10.000000- Crea una función llamada
limpiar_data_frame()que reciba un data frame como argumento y reemplace los valores faltantes por la media de los valores no faltantes en cada columna.
Solución
limpiar_data_frame <- function(df) {
for (col in names(df)) {
if (is.numeric(df[[col]])) {
df[[col]] <- ifelse(is.na(df[[col]]), mean(df[[col]], na.rm = TRUE), df[[col]])
}
}
return(df)
}
## Probar la función creada
# Crear un data frame con valores faltantes para probar la función
df_prueba <- data.frame(
edad = c(25, 30, NA, 28, 35),
altura = c(1.75, 1.80, 1.65, NA, 1.70),
peso = c(70, 80, 75, 65, NA)
)
df_prueba
#> edad altura peso
#> 1 25 1.75 70
#> 2 30 1.80 80
#> 3 NA 1.65 75
#> 4 28 NA 65
#> 5 35 1.70 NA
# Aplicar la función al data frame de prueba
df_limpio <- limpiar_data_frame(df_prueba)
# Mostrar el data frame limpio
df_limpio
#> edad altura peso
#> 1 25.0 1.750 70.0
#> 2 30.0 1.800 80.0
#> 3 29.5 1.650 75.0
#> 4 28.0 1.725 65.0
#> 5 35.0 1.700 72.5