Capítulo 7 Probabilidades discretas
Empezaremos con algunos principios básicos de la data categórica. A las probabilidades de este tipo se les llama probabilidades discretas. Entender los principios básicos de las probabilidades discretas nos ayudar a entender las probabilidades continuas que son las más comunes en aplicaciones de data science.
Recordemos que una variable discreta es una variable que no puede tomar algunos valores dentro de un mínimo conjunto numerable, quiere decir, no acepta cualquier valor, únicamente aquellos que pertenecen al conjunto.
Por ejemplo, si tenemos en un salón sentados a 4 mujeres y 6 hombres e hiciésemos un sorteo de 1 premio intuitivamente sabríamos que la probabilidad de que el sorteado sea hombre es de 60%.
7.1 Cálculo usando la definición matemática
La probabilidad que obtuvimos por intuición en el ejemplo anterior se puede expresar de la siguiente forma:
\(P(A) = probabilidad\ del\ evento\ A = \frac{Veces\ en\ que\ el\ evento\ A\ se\ puede\ dar}{Total\ de\ resultados\ posibles}\)
\(P(Sorteado\ sea\ hombre) = \frac{6}{10} = 60\%\)
7.2 Simulación de Montecarlo para variables discretas
La simulación o método de Montecarlo es un método estadístico utilizado para resolver problemas matemáticos complejos a través de la generación de variables aleatorias. En este caso el problema no es complejo, pero se puede utilizar Montecarlo para ir familiarizándonos con un método que usaremos constantemente.
Usaremos simulación Montecarlo para estimar la proporción qué obtendríamos si repitiésemos este experimento de forma aleatoria un número determinado de veces. Es decir, la probabilidad del evento usando esta estimación sería la proporción de veces en que ocurrió ese evento en nuestra simulación.
En R podemos crear fácilmente muestras aleatorias utilizando la función sample(). Por ejemplo, creemos un vector de estudiantes y luego usemos la función sample(), para escoger uno al azar.
estudiantes <- c("mujer", "mujer", "mujer", "mujer", "hombre",
"hombre", "hombre", "hombre", "hombre", "hombre")
sample(estudiantes, 1)También podríamos usar la función rep() para crear más rápido el vector estudiantes. Para ello ingresaríamos como primer argumento un vector y como segundo otro vector indicando cuántas veces queremos que se creen. Así, crearíamos más rápido el vector estudiantes.
estudiantes <- rep(c("mujer", "hombre"), times = c(4, 6))
estudiantes
#> [1] "mujer" "mujer" "mujer" "mujer" "hombre" "hombre" "hombre" "hombre"
#> [9] "hombre" "hombre"Ahora tenemos que simular un determinado número de veces el experimento de sacar un elemento aleatorio. Para ello usaremos la función replicate(). Repliquemos este experimento 100 veces:
estudiantes <- rep(c("mujer", "hombre"), times = c(4, 6))
num_veces <- 100
resultados <- replicate(num_veces, {
sample(estudiantes, 1)
})
resultados
#> [1] "mujer" "hombre" "mujer" "hombre" "hombre" "hombre" "hombre" "hombre"
#> [9] "mujer" "hombre" "mujer" "mujer" "mujer" "mujer" "mujer" "mujer"
#> [17] "mujer" "mujer" "hombre" "hombre" "hombre" "hombre" "mujer" "mujer"
#> [25] "mujer" "hombre" "hombre" "hombre" "hombre" "mujer" "hombre" "hombre"
#> [33] "mujer" "mujer" "hombre" "mujer" "hombre" "hombre" "hombre" "hombre"
#> [41] "hombre" "mujer" "hombre" "hombre" "hombre" "mujer" "mujer" "mujer"
#> [49] "mujer" "mujer" "hombre" "hombre" "hombre" "mujer" "mujer" "hombre"
#> [57] "hombre" "mujer" "mujer" "hombre" "mujer" "hombre" "hombre" "hombre"
#> [65] "mujer" "mujer" "mujer" "hombre" "mujer" "mujer" "mujer" "hombre"
#> [73] "hombre" "hombre" "mujer" "hombre" "hombre" "mujer" "hombre" "mujer"
#> [81] "mujer" "hombre" "hombre" "mujer" "hombre" "hombre" "hombre" "mujer"
#> [89] "mujer" "mujer" "mujer" "mujer" "hombre" "hombre" "mujer" "hombre"
#> [97] "hombre" "hombre" "hombre" "hombre"Podemos ver cuál fue el resultado de cada uno de los 100 sorteos que simulamos.
Ahora usaremos la función table() para transformar nuestro vector resultados en una tabla resumida que nos muestre cuantas veces apareció cada valor.
Si este resultado lo almacenamos en un vector tabla_resultados, podemos luego usar la función prop.table() para saber la proporción de cada valor:
tabla_resultados <- table(resultados)
prop.table(tabla_resultados)
#> resultados
#> hombre mujer
#> 0.54 0.46No nos debemos de preocupar por si la probabilidad de que sea hombre no nos ha salido 60% exacto. Recordemos que estamos estimando la probabilidad usando un método que depende del número de veces que simulemos el experimento. Mientras más veces repitamos el experimento más cercano estaremos al valor. Por ejemplo, repliquemos este experimento ahora 10,000 veces.
estudiantes <- rep(c("mujer", "hombre"), times = c(4, 6))
num_veces <- 10000
resultados <- replicate(num_veces, {
sample(estudiantes, 1)
})
tabla_resultados <- table(resultados)
prop.table(tabla_resultados)
#> resultados
#> hombre mujer
#> 0.5985 0.4015Vemos cómo el valor va convergiendo a 60%. No nos debemos de preocupar si el valor varía por algunos dígitos al presentado en este libro dado que estamos simulando un evento al azar.
Finalmente, para este ejemplo sencillo también podríamos haber utilizado la función mean(). Si bien esto nos calcula el promedio de un conjunto de números, podríamos convertir nuestro vector estudiantes a valores númericos, donde cada valor lo convirtamos en 1 o 0 dependiendo de alguna condicion.
Para ello, R nos hace muy sencilla la conversión de vectores a 1 y 0 utilizando el operador comparador ==:
Cuando aplicamos la función mean() a este resultado, ésta coerciona a los valores TRUE hacia 1 y los valores FALSE por 0. Así, si aplicamos el promedio de esta lista, tendríamos el porcentaje de hombres y con ello la probabilidad de que al escoger una persona ésta sea hombre:
7.2.1 Otras funciones para crear vectores
Ya hemos aprendido la función rep() para crear más rápido vectores. Otra función que encontramos en R es la función expand.grid(x, y) la cual nos crea un data frame de todas las combinaciones entre los vectores x e y.
saludos <- c("Hola", "Chau")
nombres <- c("Andrés", "Josep", "Alonso", "Andrés", "Cesar", "Jeremy")
resultado <- expand.grid(saludo = saludos, nombre = nombres)
resultado
#> saludo nombre
#> 1 Hola Andrés
#> 2 Chau Andrés
#> 3 Hola Josep
#> 4 Chau Josep
#> 5 Hola Alonso
#> 6 Chau Alonso
#> 7 Hola Andrés
#> 8 Chau Andrés
#> 9 Hola Cesar
#> 10 Chau Cesar
#> 11 Hola Jeremy
#> 12 Chau JeremyFinalmente, tenemos la función paste(x,y), la cual nos concatena dos cadenas o vectores de cadenas agregando un espacio en el medio.
paste(resultado$saludo, resultado$nombre)
#> [1] "Hola Andrés" "Chau Andrés" "Hola Josep" "Chau Josep" "Hola Alonso"
#> [6] "Chau Alonso" "Hola Andrés" "Chau Andrés" "Hola Cesar" "Chau Cesar"
#> [11] "Hola Jeremy" "Chau Jeremy"Así, podemos generar fácilmente, por ejemplo, una baraja de cartas distribuidas en 4 palos: corazones, diamantes, picas y tréboles. Las cartas de cada palo están numeradas del 1 al 10, donde el 1 es el As, y seguidas por Jack, la Reina y el Rey.
Para esto, tendríamos que crear un vector de palos y un vector de números para luego crear la combinatoria y tener la baraja completa.
numeros <- c("As", "Dos", "Tres", "Cuatro", "Cinco", "Seis", "Siete",
"Ocho", "Nueve", "Diez", "Jack", "Reina", "Rey")
palos <- c("de Corazones", "de Diamantes", "de Picas", "de Tréboles")
# Creamos la combinatoria de cartas
combinatoria <- expand.grid(numero = numeros, palo = palos)
# Concatenamos vectores para tener nuestra combinación final
paste(combinatoria$numero, combinatoria$palo)
#> [1] "As de Corazones" "Dos de Corazones" "Tres de Corazones"
#> [4] "Cuatro de Corazones" "Cinco de Corazones" "Seis de Corazones"
#> [7] "Siete de Corazones" "Ocho de Corazones" "Nueve de Corazones"
#> [10] "Diez de Corazones" "Jack de Corazones" "Reina de Corazones"
#> [13] "Rey de Corazones" "As de Diamantes" "Dos de Diamantes"
#> [16] "Tres de Diamantes" "Cuatro de Diamantes" "Cinco de Diamantes"
#> [19] "Seis de Diamantes" "Siete de Diamantes" "Ocho de Diamantes"
#> [22] "Nueve de Diamantes" "Diez de Diamantes" "Jack de Diamantes"
#> [25] "Reina de Diamantes" "Rey de Diamantes" "As de Picas"
#> [28] "Dos de Picas" "Tres de Picas" "Cuatro de Picas"
#> [31] "Cinco de Picas" "Seis de Picas" "Siete de Picas"
#> [34] "Ocho de Picas" "Nueve de Picas" "Diez de Picas"
#> [37] "Jack de Picas" "Reina de Picas" "Rey de Picas"
#> [40] "As de Tréboles" "Dos de Tréboles" "Tres de Tréboles"
#> [43] "Cuatro de Tréboles" "Cinco de Tréboles" "Seis de Tréboles"
#> [46] "Siete de Tréboles" "Ocho de Tréboles" "Nueve de Tréboles"
#> [49] "Diez de Tréboles" "Jack de Tréboles" "Reina de Tréboles"
#> [52] "Rey de Tréboles"Una vez creada nuestra baraja podemos calcular algunas probabilidades fácilmente con el vector creado.
Calculemos la probabilidad de que al escoger una carta ésta sea “Rey de Diamantes”:
# Almacenamos la combinatoria en la variable baraja
baraja <- paste(combinatoria$numero, combinatoria$palo)
mean(baraja == "Rey de Diamantes")
#> [1] 0.01923077O también podemos calcular la probabilidad de que al escoger una carta ésta sea alguna Reina:
7.3 Ejercicios
- Almacena en la variable
probla probabilidad de que al tirar un dado no te salga el número 1. Utilizando la variableprob, ahora calcula la probabilidad de que al tirar 3 veces seguidas, una tras otra, en ninguna de esas veces salga el número 1.
- Dada un recipiente que contiene 5 canicas azules, 3 amarillas y 4 grises. ¿Cuál es la probabilidad de que si escoges una canica al azar ésta sea azul?
Solución
canicas <- rep(c("azul", "amarillo", "gris"), times = c(5, 3, 4))
# Solución utilizando simulación de montecarlo, repitiendo el evento 10,000 veces:
resultados <- replicate(10000, {
sample(canicas, 1)
})
prop.table(table(resultados))
# Solución utilizando la función `mean()`:
mean(canicas == "azul")Matemáticamente sería:
Dado el evento: \(X = canica\ elegida\ sea\ de\ color\ azul\):
\(P(X)=\frac{5}{5+3+4}=\frac{5}{12}=41.67\%\)
La probabilidad de que la canica sea azul es de 41.67%.
- ¿Cuál es la probabilidad de que al escoger una canica al azar del recipiente anterior ésta no sea de color azul?
Solución
La probabilidad es de 58.33%.
Matemáticamente sería:
Dado el evento \(X = canica\ elegida\ sea\ de\ color\ azul\):
\(P(\sim~X)=1-P(X)=1-\frac{5}{12}=1-41.67\%=58.33\%\)
- Ahora vamos a sacar primero una canica, colocarla fuera de la caja y sacar otra canica adicional de la caja. ¿Cuál es la probabilidad de que la primera sea azul y la segunda no sea azul?. Esta vez, en vez de crear el vector canicas, crea las variables numéricas: azul, amarillo y gris asigándole como valor el número de canicas. Luego calcula matemáticamente las probabilidades.
Solución
# Creamos las variables
azul <- 5
amarillo <- 3
gris <- 4
# Calculamos la probabilidad de que la primera canica sea azul:
p_1 <- azul / (azul + amarillo + gris)
# Calculamos primero la probabilidad de que la segunda sea azul:
p_aux <- (azul - 1) / (azul - 1 + amarillo + gris)
# Calculamos el complemento porque piden que la segunda NO sea azul:
p_2 <- 1 - p_aux
# Calculamos lo que nos piden:
p_1 * p_2A esto se le llama muestreo sin reemplazamiento. Tenemos dos eventos, estamos sacando dos canicas. El segundo evento depende del primero. Estos dos eventos no son independientes uno del otro.
- Ahora repetiremos el experimento anterior, pero después de sacar la primera canica volvemos a colocarla en la caja y sacamos una canica más al azar. ¿Cuál es la probabilidad de que la primera canica sea azul y la segunda no sea azul? Modifica el código en R que creaste anteriormente para calcular esta probabilidad.
Solución
# Creamos las variables
azul <- 5
amarillo <- 3
gris <- 4
# Calculamos la probabilidad de que la primera canica sea azul:
p_1 <- azul / (azul + amarillo + gris)
# Calculamos primero la probabilidad de que la segunda sea azul:
p_aux <- azul / (azul + amarillo + gris)
# Calculamos el complemento porque piden que la segunda NO sea azul:
p_2 <- 1 - p_aux
# Calculamos lo que nos piden:
p_1 * p_2A esto se le llama muestreo con reemplazamiento. Tenemos dos eventos, estamos sacando dos canicas nuevamente. El segundo evento no depende del primero. Estos dos eventos son independientes.
7.4 Combinaciones y permutaciones
Algunas situaciones de probabilidad implican múltiples eventos. Cuando uno de los eventos afecta a otros, se llaman eventos dependientes. Por ejemplo, cuando objetos son escogidos de una lista o grupo y no son devueltos, la primera elección reduce las opciones para futuras elecciones.
Existen dos maneras de ordenar o combinar resultados de eventos dependientes. Las permutaciones son agrupaciones en las que importa el orden de los objetos. Las combinaciones son agrupaciones en las que el contenido importa pero el orden no.
Para ello vamos a utilizar el paquete gtools, el cual nos incluye librerías como gtools que nos provee intuitivas funcionalidades para trabajar con permutaciones y combinaciones.
# Primero instalamos el paquete gtools
install.packages("gtools")
# Para empezar a usarlo cargamos la librería gtools
library(gtools)7.4.1 Permutaciones
Importa el orden cuando calculamos, por ejemplo, los ganadores de una competencia. Supongamos que tenemos 10 estudiantes que están compitiendo en igualdad de condiciones por quién construye el modelo en machine learning más preciso.
data_scientists <- c("Jenny", "Freddy", "Yasan", "Iver", "Pamela", "Alexandra",
"Bladimir", "Enrique", "Karen", "Christiam")Solo los top 3 recibirán el premio. En este caso el orden importa, entonces usaremos la función permutations(total, seleccion, data) donde el total me indica el tamaño del vector, seleccion indica el tamaño del resultado que quiero, y finalmente data es mi vector fuente.
Ya hemos calculado todos los resultados posibles. Podemos sobre este resultado calcular la probabilidad de que Fredy gane la competencia y que Pamela quede en segundo lugar.
7.4.2 Combinaciones
No importa el orden cuando, por ejemplo, formamos grupos de a 2 para que participen en la competencia.
Si ahora es un solo equipo el que va a ganar el premio, podríamos calcular la probabilidad de que el equipo conformado por Pamela y Enrique sean quienes ganen.
resultados <- combinations(10, 2, v = data_scientists)
# Total de resultados:
nrow(resultados)
#> [1] 45
# Probabilidad:
mean((resultados[, 1] == "Pamela" & resultados[, 2] == "Enrique") |
(resultados[, 1] == "Enrique" & resultados[, 2] == "Pamela"))
#> [1] 0.02222222Si bien podemos obtener la probabilidad calculando todas las combinaciones, en R será muy frecuente utilizar Montecarlo para estimar la probabilidad por simulación. Para el caso anterior no tendríamos que generar todas las combinaciones, sino simplemente sacar una muestra de dos personas que serían los miembros del equipo ganador. Recordemos que hemos asumido que todos tienen igualdad de posibilidades de ganar.
Luego, tendríamos que replicar este experimento una y otra vez, almacenar los resultados del muestreo y calcular la proporción de cuántas veces el equipo ganador fue compuesto por Pamela y Enrique.
n <- 10000
resultado <- replicate(n, {
equipo <- sample(data_scientists, 2)
cumple_condicion <- (equipo[1] == "Pamela" & equipo[2] == "Enrique") |
(equipo[2] == "Pamela" & equipo[1] == "Enrique")
cumple_condicion
})
mean(resultado)
#> [1] 0.0226Nótese que, como vimos anteriormente, el valor converge conforme aumentamos la cantidad de veces que repetimos el experimento n. Hemos simulado repetir el experimento 10 mil veces. Sin embargo, ¿cuántas veces se necesitaría replicar el experimento para confiar en los resultados de la simulación?
7.5 Experimentos suficientes con Simulación de Montecarlo
Intuitivamente podemos indicar que a mayor cantidad de experimentos es más precisa la probabilidad estimada. Podemos, así, hacer varias simulaciones con diferente número de experimentos para cada simulación. De esta forma podríamos encontrar un número razonable de experimentos para nuestra simulación. Para ello, primero creemos un vector numérico donde se indique la cantidad de veces que vamos a simular el experimento. Nuestro vector contendrá los siguientes valores: 10, 20, 40, 80, 160,…, etc. Esto quiere decir que la primera vez simularemos 10 veces el experimento, la segunda 20 veces y así sucesivamente.
num_veces <- 10*2^(1:17)
num_veces
#> [1] 20 40 80 160 320 640 1280 2560 5120
#> [10] 10240 20480 40960 81920 163840 327680 655360 1310720Luego, utilizamos el código que creamos para replicar el experimento para crear una función llamada probabilidad_por_muestra:
probabilidad_por_muestra <- function(n) {
resultado <- replicate(n, {
equipo <- sample(data_scientists, 2)
cumple_condicion <- (equipo[1] == "Pamela" & equipo[2] == "Enrique") |
(equipo[2] == "Pamela" & equipo[1] == "Enrique")
cumple_condicion
})
mean(resultado)
}Ya tenemos una función que nos permite replicar el experimento cuantas veces querramos. Por ejemplo, en la sección anterior simulamos 10 mil experimentos. Ahora que tenemos creada la función haríamos:
Nuevamente, esta es una simulación. Así que cada vez que ejecutemos esa función la probabilidad variará al ser una muestra al azar.
Para aplicar una función sobre cada uno de los valores de un vector utilizamos la función sapply(vector, funcion) donde vector es el vector donde están los datos sobre los cuales quiero aplicar la función y funciones la función que quiero aplicar.
prob <- sapply(num_veces, probabilidad_por_muestra)
prob
#> [1] 0.00000000 0.02500000 0.03750000 0.00625000 0.02812500 0.02187500
#> [7] 0.03125000 0.02265625 0.01933594 0.01992187 0.02358398 0.02211914
#> [13] 0.02302246 0.02229004 0.02212524 0.02234497 0.02212143Esto nos da las probabilidades dependiendo del número de veces que repetimos el experimento. Ahora coloquemos estos resultados en un diagrama de dispersión para ver cómo converge
probabilidades <- data.frame(
n = num_veces,
probabilidad = prob
)
probabilidades %>%
ggplot() +
aes(n, probabilidad) +
geom_line() +
geom_point() +
xlab("# de veces del experimento")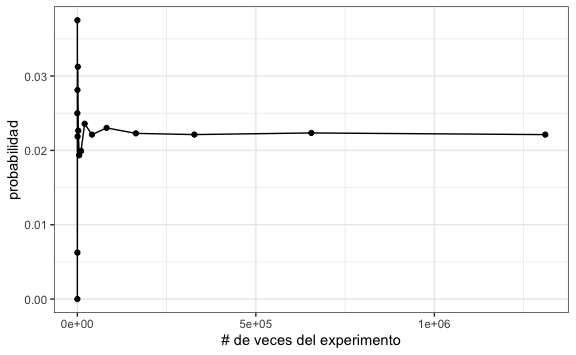
También podemos cambiar la escala para hacer un zoom a las probabilidades para los valores de número de experimentos más pequeños y agregar una línea de referencia con el valor de la probabilidad teórica calculada anteriormente:
probabilidades %>%
ggplot() +
aes(n, probabilidad) +
geom_line() +
geom_point() +
xlab("# de veces del experimento") +
scale_x_continuous(trans = "log2") +
geom_hline(yintercept = 0.022222, color = "blue", lty = 2)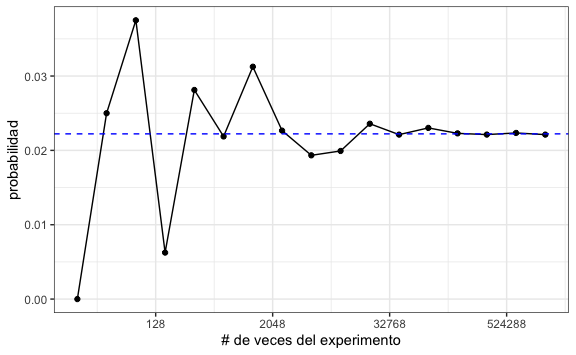
Observamos que, para este experimento, repitiendo el experimento 10 mil veces (eje-x = 3 porque es \(10^3\)) ya nos da una buena aproximación al valor real.
7.6 Caso: Cumpleaños en clases
Repasemos los conceptos aprendidos con otro ejemplo. En una clase de Data Science for Managers hay 50 estudiantes. Utilizando simulación de Montecarlo estimemos cuál es la probabilidad de qué hayan al menos dos personas que cumplan años el mismo día. (Obviemos a los que cumplen años el 29 de febrero).
Primero listemos todos los días del año disponible para cumpleaños:
Generemos una muestra aleatoria de 50 números del vector dias, pero ésta vez con reemplazo porque una persona podría tener el mismo día, y almacenémoslo en la variable colegas.
Para validar si alguno de los valores se repite usaremos la función duplicated() que nos valida si dentro del vector hay valores duplicados:
duplicated(colegas)
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [25] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
#> [37] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE
#> [49] FALSE FALSEFinalmente, para determinar si hubo algún valor TRUE utilizamos la función any():
El resultado nos indica si es verdadero o no que hayan al menos dos personas que cumplan el mismo día años. Para estimar por simulación de Montecarlo cuál es la probabilidad tenemos que repetir el experimento muchas veces y sacar la proporción de cuántas veces nos sale como resultado TRUE.
# Simulación de Montecarlo con 10 mil repeticiones
num_veces <- 10000
resultados <- replicate(num_veces, {
colegas <- sample(dias, 50, replace = TRUE)
# Retorna un valor lógico de si hay duplicados
any(duplicated(colegas))
})
# Probabilidad:
mean(resultados)
#> [1] 0.9687Vemos que la probabilidad estimada es muy alta, arriba del 95%. ¿Qué pasaría si tengo un salón de 25 personas?
Para ello, modificamos el código anterior y creamos la variable clase que nos indicará el número de estudiantes en esa clase:
# Simulación de Montecarlo con 10 mil repeticiones
num_veces <- 10000
clase <- 25
resultados <- replicate(num_veces, { # Retorna un vector lógico
colegas <- sample(dias, clase, replace = TRUE)
any(duplicated(colegas))
})
# Probabilidad:
mean(resultados)
#> [1] 0.5738Creemos ahora la función calcula_probabilidad y estimemos usando esta función la probabilidad de encontrar al menos dos personas con el mismo día de cumpleaños en un salón de 25 personas. Ésta vez tenemos que especificar que el muestreo es con “reemplazo” porque por default la función sample() es “sin reemplazo”.
# Creamos la función
estima_probabilidad <- function(clase, num_veces = 10000){
resultados <- replicate(num_veces, { # Retorna un vector lógico
colegas <- sample(dias, clase, replace = TRUE)
any(duplicated(colegas))
})
# Probabilidad:
mean(resultados)
}
estima_probabilidad(25)
#> [1] 0.5757Finalmente, si ya tenemos una función que nos calcula en base al número de personas en un salón podemos crear un vector numérico con el total de personas de diferentes salones y luego aplicarle la función que hemos creado. El resultado lo podemos almacenar en la variable prob.
# Creamos 80 distintos salones de clase
# El primer salón con 1 persona, el último salón con 80 personas
clases <- 1:80
# Estimamos la probabilidad dependiendo del número de estudiantes por salón
prob <- sapply(clases, estima_probabilidad)
prob
#> [1] 0.0000 0.0030 0.0085 0.0155 0.0270 0.0380 0.0515 0.0763 0.0944 0.1141
#> [11] 0.1384 0.1623 0.1918 0.2224 0.2528 0.2832 0.3236 0.3480 0.3786 0.4196
#> [21] 0.4377 0.4766 0.5081 0.5387 0.5772 0.6072 0.6219 0.6569 0.6813 0.7061
#> [31] 0.7345 0.7533 0.7723 0.7890 0.8199 0.8376 0.8463 0.8659 0.8778 0.8910
#> [41] 0.9044 0.9138 0.9284 0.9349 0.9389 0.9487 0.9558 0.9661 0.9683 0.9676
#> [51] 0.9748 0.9790 0.9830 0.9844 0.9848 0.9880 0.9899 0.9906 0.9938 0.9943
#> [61] 0.9957 0.9952 0.9966 0.9976 0.9975 0.9975 0.9987 0.9990 0.9994 0.9991
#> [71] 0.9996 0.9995 0.9996 0.9997 0.9996 0.9998 0.9999 0.9998 0.9996 0.9998Así, si colocamos en un gráfico de dispersión podemos ver cómo incrementa la probabilidad conforme hay más estudiantes:
probabilidades <- data.frame(
n = clases,
probabilidad = prob
)
probabilidades %>%
ggplot() +
aes(n, probabilidad) +
geom_point() +
xlab("Número de alumnos en cada clase")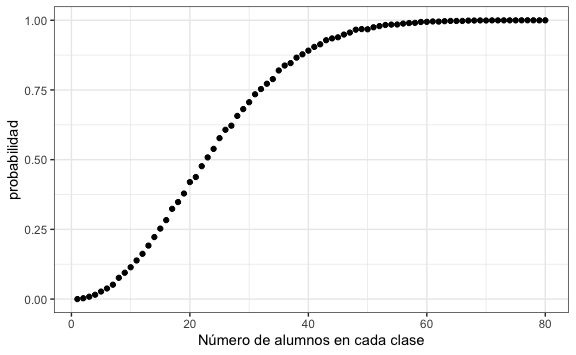
Ya podemos impresionar a nuestros amigos de distintos grupos diciéndoles que, si están en un salón de 60 personas, “les pueden apostar” que hay dos personas en ese salón que cumplen años el mismo día. No es definitiva, pero las chances están muy a nuestro favor.
7.7 Ejercicios
- Dos estudiantes del curso de Data Science con R, Alonso y Georgina, en sus ratos libres suelen jugar ajedrez. Dada la experiencia de Georgina, ella tiene 60% de ganar cada vez que juega con Alonso. Sin utilizar simulación de Montecarlo ¿Cuál es la probabilidad de que al jugar 4 veces seguidas, Alonso haya ganado al menos una vez.
Solución
Calcular la probabilidad de que Alonso haya ganado al menos una vez es el complemento de la probabilidad de que Georgina haya ganado todas las 4 veces. Así, calcularemos primero la probabilidad de que Georgina haya ganado siempre y luego calculamos el complemento.
- Estima la probabilidad anterior utilizando simulación de Montecarlo. Utiliza el siguiente código para generar una muestra de 4 juegos, donde Alonso tiene una probabilidad de 60% de perder ante Georgina.
Solución
# Veces en que ejecuto la simulación
num_veces <- 10000
# Generamos los resultados de los experimentos de que gane Alonso
alonso_gana <- replicate(num_veces, {
resultado_juegos <- sample(c("pierde","gana"), 4, replace = TRUE, prob = c(0.6, 0.4))
any(resultado_juegos == "gana")
})
# Estimamos la probabilidad
mean(alonso_gana)- En el ejercicio anterior usamos como probabilidad de que Alonso gane como 40%. Ahora, crea la función
probabilidad_de_ganarque tome como input la probabilidadpde que Alonso gane. Luego, asigna esta secuenciaseq(0.4, 0.95, 0.025)en un vectorppara, finalmente, aplicar la función creada a cada valor del vectorpy almacena el resultado en la variableprob. Reporta un diagrama de dispersión del vectorpen el eje-x y del vectorproben el eje-y
Solución
# Creamos la función
probabilidad_de_ganar <- function(p){
num_veces <- 10000
alonso_gana <- replicate(num_veces, {
resultado_juegos <- sample(c("pierde","gana"), 4, replace = TRUE, prob = c(1-p, p))
any(resultado_juegos == "gana")
})
mean(alonso_gana)
}
# Creamos nuestro vector con distintas probabilidades
p <- seq(0.4, 0.95, 0.025)
prob <- sapply(p, probabilidad_de_ganar)
plot(p, prob, xlab="p: probabilidad de que Alonso gane en cada juego",
ylab="prob: prob. que Alonso gane al menos un juego")7.8 Ejercicio integrador
Vamos a resolver juntos este ejercicio que integra todo lo que hemos aprendido en este capítulo, llamado el problema de Monty Hall.
7.8.1 Problema de Monty Hall
Monty Hall era un presentador de TV que hizo famoso un concurso en su show el cual vamos a replicar a continuación. Tenemos tres puertas frente a nosotros:
Detrás de una de estas puertas hay un auto cero kilómetros, mientras que en las otras dos hay una cabra. Nosotros, como participantes del concurso, tenemos que elegir juntos qué puerta abrir. Lo que haya detrás será nuestro.
Supongamos que hemos elegido la puerta número 2. Una vez anuncias nuestra elección, Monty Hall nos dice que él nos va a ayudar y abrirá una puerta por nosotros ahora mismo. Él abre una de las otras puertas y resulta que hay una cabra en la puerta 3 que abrió.
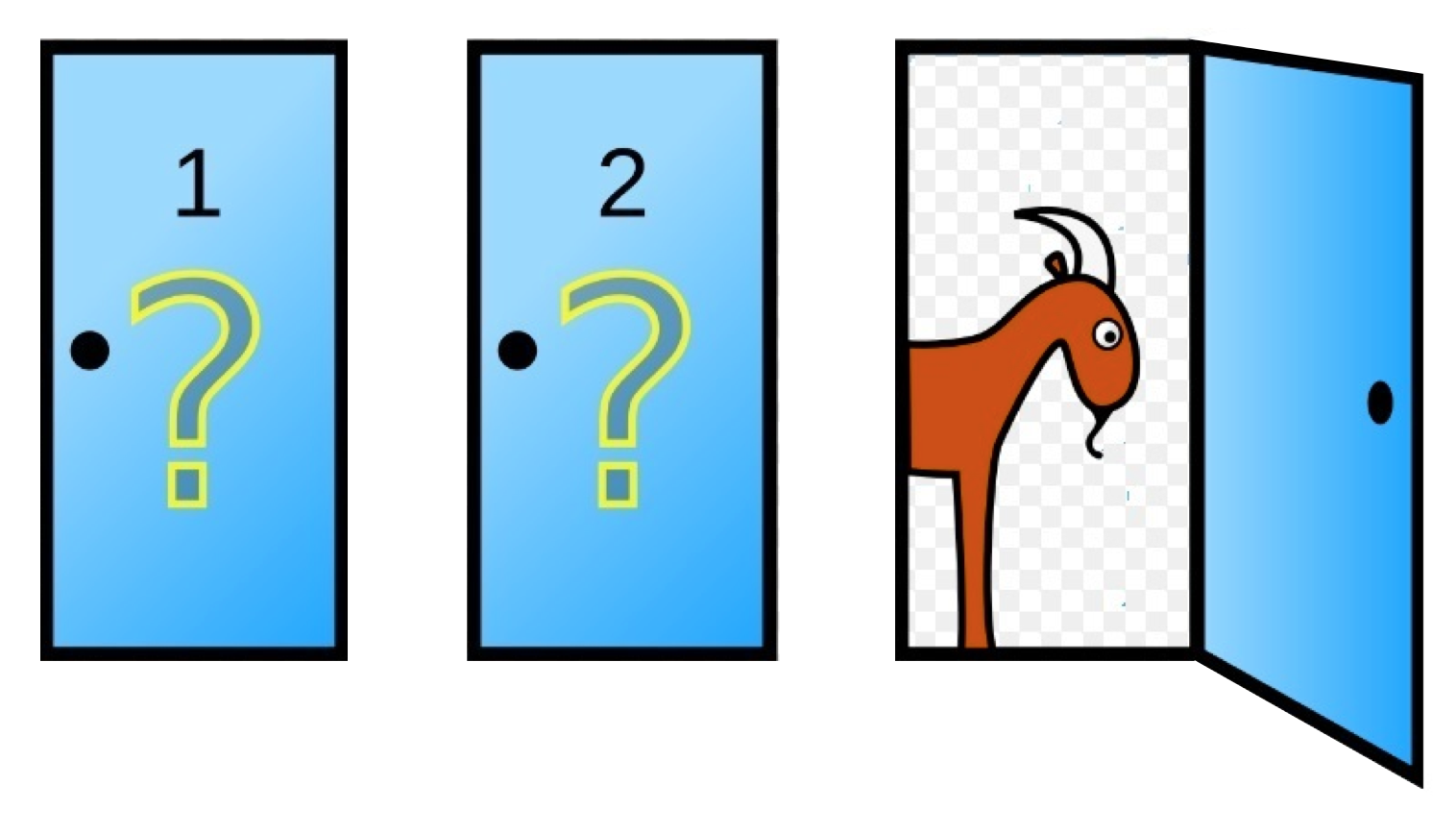
Monty Hall nos pregunta:
Les voy a dar una oportunidad de cambiar de puerta y esa será su elección final, ¿Cambiarían de puerta o se quedan con la puerta elegida al inicio?
Intuitivamente sabíamos que, cuando todas las puertas estaban cerradas, el auto está en una de 3 las puertas. La probabilidad de ganar sería \(\frac{1}{3} = 0.3333\) así que daba lo mismo cuál puerta elegir. Pero cuando abre la puerta número tres nos brinda información y lo primero que deberíamos de preguntarnos es si las probabilidades se han visto afectadas o no. Si bien este es un ejercicio de matemática avanzada usando el cambio de variable, podemos ejecutar una simulación de Montecarlo para estimar las probabilidades y resolverlo sin usar casi ninguna fórmula matemática.
Comencemos simulando el experimento. Al inicio teníamos tres puertas, puerta 1, 2 y 3. Crearemos la variable puertas.
Luego, sabemos que detrás de las puertas hay un auto y dos cabras distribuídos aleatoriamente. Usaremos la función sample para ordernarlos de forma aleatoria.
Como Monty Hall sabe dónde está el premio. Vamos a crear una variable puerta_premio donde almacenaremos donde está el auto.
Ahora escogemos una puerta aleatoriamente y almacenamos nuestro resultado en la variable eleccion.
Dado que ya tenemos mostrada la puerta elegida simularemos el que Monty Hall elija la puerta a abrir. Como él es el presentador elegirá cualquier puerta que no sea la puerta donde está el premio o tu puerta.
Finalmente, vamos a poner todo el código junto y en la última línea agregamos la comparación de si la puerta del premio coincide con nuestra elección. En esta oportunidad vamos a elegir no cambiar de puerta, así que nuestra elección no varía.
puertas <- c("puerta 1", "puerta 2", "puerta 3")
premios <- sample(c("auto", "cabra", "cabra"))
puerta_premio <- puertas[premios == "auto"]
eleccion <- sample(puertas, 1)
puerta_que_abre <- sample(puertas[!puertas %in% c(eleccion, puerta_premio)],1)
eleccion == puerta_premioYa con nuesro experimento creado vamos a simular qué pasaría si nos quedamos con la elección y qué pasaría si la cambiamos.
7.8.1.1 Quedarse con la puerta elegida
Repliquemos unas 10 mil veces para ver la proporción de veces que ganaríamos si nos quedamos con nuestra puerta.
num_veces <- 10000
resultados <- replicate(num_veces, {
puertas <- c("puerta 1", "puerta 2", "puerta 3")
premios <- sample(c("auto", "cabra", "cabra"))
puerta_premio <- puertas[premios == "auto"]
eleccion <- sample(puertas, 1)
puerta_que_abre <- sample(puertas[!puertas %in% c(eleccion, puerta_premio)],1)
eleccion == puerta_premio
})
mean(resultados)
#> [1] 0.3338Vemos que la probabilidad obtenida simulación de Montecarlo es una estimación muy cercana a la probabilidad que intuitivamente habíamos calculado. Es decir, si mantenemos nuestra elección de la puerta que elegimos tenemos un 33.33% de probabilidad de ganar.
Pero, ¿qué pasa si cambiamos de puerta? ¿la probabilidad de ganar es la misma?
7.8.1.2 Cambiar de puerta
Vamos a utilizar el código y lo modificaremos creando la variable nueva_eleccion para hacer el cambio de puerta.
num_veces <- 10000
resultados <- replicate(num_veces, {
puertas <- c("puerta 1", "puerta 2", "puerta 3")
premios <- sample(c("auto", "cabra", "cabra"))
puerta_premio <- puertas[premios == "auto"]
eleccion <- sample(puertas, 1)
puerta_que_abre <- sample(puertas[!puertas %in% c(eleccion, puerta_premio)],1)
nueva_eleccion <- puertas[!puertas %in% c(eleccion, puerta_que_abre)]
nueva_eleccion == puerta_premio
})
mean(resultados)
#> [1] 0.6765Como vemos, cambiar la puerta en este show nos daba una probabilidad de 66.66% de ganar, mientras que mantener nuestra elección solo 33.33%.
Puede sonar contraintuitivo, pero estadísticamente hablando es mejor cambiar de puerta en vez de confiar en nuestra suerte y mantener la elección inicial.