Capítulo 5 Ggplot y dplyr
Hemos aprendido hasta el momento cómo realizar visualizaciones simples y rápidas. Ahora que ya tenemos una noción de los gráficos utilizaremos gráficos más complejos y estéticamente mejores para presentar.
Para ello utilizaremos el objeto ggplot incluida en la librería tidyverse (el paquete tidyverse incluye un paquete llamado ggplot2 el cual nos permite usar el objeto ggplot). Anteriormente ya hemos instalado el paquete tidyverse, así que ahora solo tenemos que cargar la librería:
Vamos a aprender técnicas de visualización utilizando nuestro caso/problemática anterior, de tal forma que aprendamos a usar el objeto ggplot de forma gradual con un caso/problema ya conocido.
5.1 Creando el objeto ggplot
Vamos a empezar creando el objeto ggplot a partir de la data murders utilizando el operador pipeline %>%. Recordemos también haber cargado la data murders de la librería dslabs.

Este código solo nos muestra un cuadro vacío. Esto es porque no le hemos específicado qué variables tomar del data frame ni tampoco qué tipo de gráfico queremos.
Para agregar cada componente del gráfico que estamos creando usaremos capas. El objeto ggplot nos permite ir agregando capa por capa qué componente del gráfico queremos agregar. El símbolo para agregar capas al objeto ggplot es el símbolo +.
5.2 Capa aesthetic mapping
Primero vamos a enfocarnos en la estética básica, esto es: qué va en el eje x y qué ponemos en el eje y. Para ello usaremos la función aesthetic (estética en inglés) que en R es aes(). Por ejemplo, agreguemos en el eje x la data de population y en el eje y la data del total. No tenemos que usar el accesador $ porque la función aes toma como referencia la tabla murders antes del pipeline.
Ahora tenemos un cuadro con los ejes señalados, pero aun sin ningún dato dentro del cuadro.
5.3 Capa geoms
Agreguemos una capa más que nos indique qué tipo de gráfico queremos. Para ello usaremos los llamados geoms. Existen diferentes tipo de geoms. Por ejemplo, un gráfico de dispersión es mostrado con puntos, por ende usaremos la función geom_point(). Para más detalle podemos ver la documentación de geom_point() aquí.
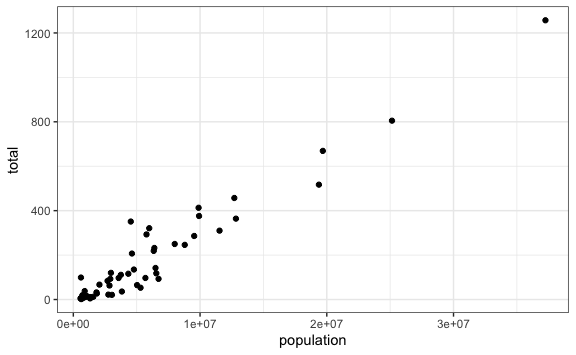
De la misma forma, podemos mostrar líneas que conecten los datos en vez de puntos con la función geom_line().
Hasta este punto hemos creado el mismo gráfico de dispersión que vimos en el capítulo anterior. La potencia de ggplot está en la facilidad para agregar componentes. Por ejemplo, si en el gráfico de dispersión queremos que cada punto tenga el nombre del estado, o mejor aun la abreviación abb, solo tenemos que agregarlo como atributo label dentro del aes y agregar la capa geom_text().

En este gráfico ya podemos ver que el punto superior derecho corresponde a CA que es la abreviación del estado de California.
5.3.1 Retoques en aes y geoms
Podemos retocar de múltiples formas nuestro gráficos agregando atributos a nuestras funciones.
Por ejemplo, si queremos identificar cada punto a qué región pertenece (si es del norte de EEUU, sur, etc) tendríamos que editar el aes() y hacer que el color tome en cuenta la variable region de la siguiente forma:
murders %>%
ggplot() +
aes(x = population, y = total, label=abb, color=region) +
geom_point() +
geom_text()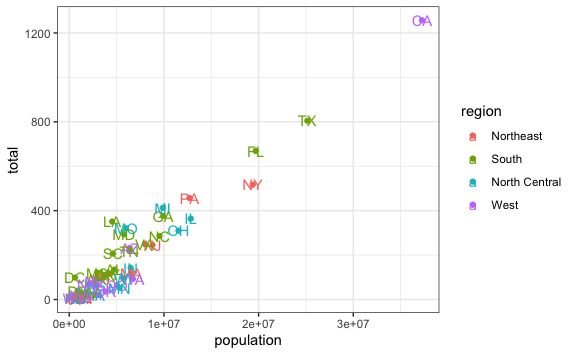
Luego, también podemos editar los atributos de los geoms. Por ejemplo, hagamos que el tamaño de los puntos sea más grande. Para ello editamos dentro de geom_points():
murders %>%
ggplot() +
aes(x = population, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text()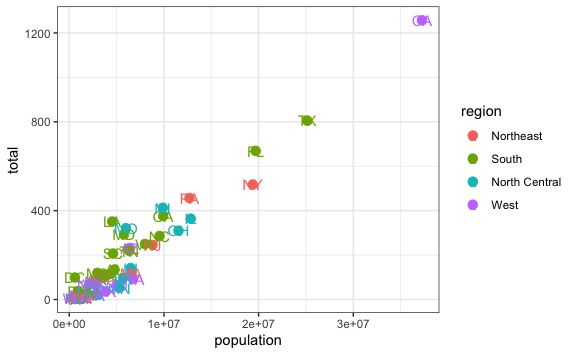
Al haber incrementado el tamaño de los puntos ya no podemos ver bien el texto de las abreviaciones de los estados. Podemos empujar (nudge en inglés) el texto en el eje x o en el eje y. Dado que hablamos de varios millones de personas, vamos a empujar las letras 1.5 millón a la derecha.
murders %>%
ggplot() +
aes(x = population, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 1500000)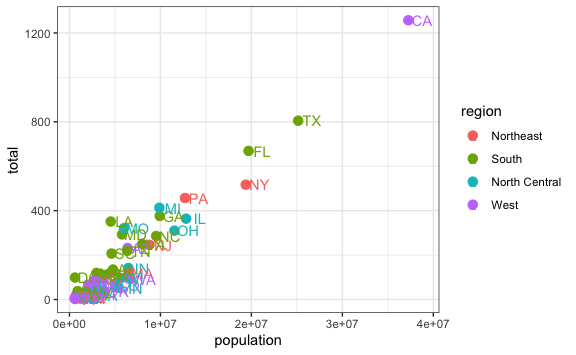
Para no tener que ingresar números tan grandes podemos transformar la población en el eje x en la función aes(). Así, una vez que expresamos los datos sin contar los millones tendríamos que empujar el texto solo 1.5 puntos a la derecha:
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 1.5)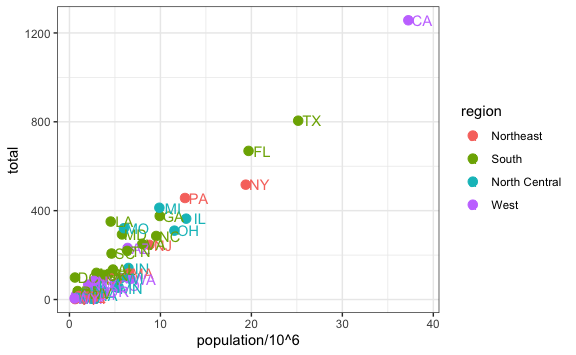
Esta transformación nos da el mismo resultado anterior y el eje x ahora es más fácil de comprender ahora que podemos ver los números.
5.4 Capa de escala
Visualmente aun podemos mejorar más nuestro gráfico. Vemos varios datos concentrados en valores menores y solo algunos extremos. En esos casos es mejor tener una vista escalando los ejes usando logaritmos. Para ello, usaremos las capas scale_x_continuous() y scale_y_continuous(). Por ejemplo, si queremos transformar la escala a logaritmo en base 2 tendríamos que agregar capas, pero también cambiar el valor de nudge_x, por el cambio de escala:
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.23) +
scale_x_continuous(trans = "log2") +
scale_y_continuous(trans = "log2")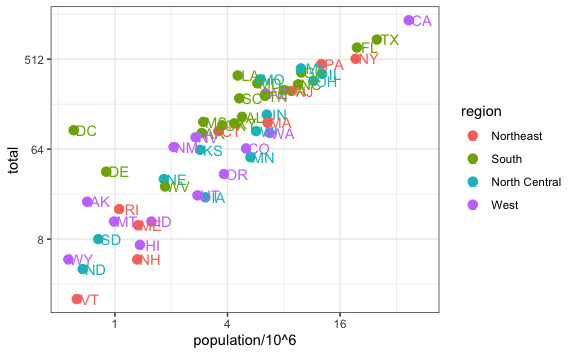
De la misma forma, podríamos hacer la transformación a logaritmo en base 10:
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_continuous(trans = "log10") +
scale_y_continuous(trans = "log10")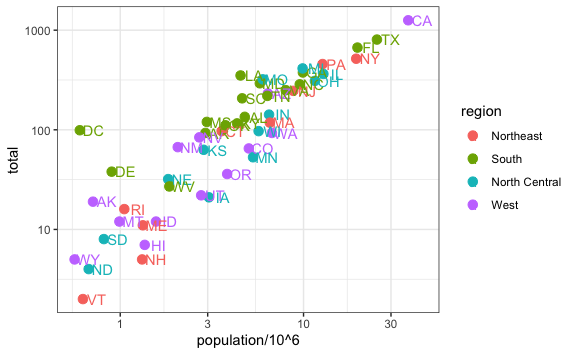
La transformación de la escala a logaritmo en base 10 es muy utilizada en estadística y R nos provee de una función más rápida para poder hacer esta transformación de escala, la función scale_x_log10(), la cual nos da el mismo resultado del gráfico anterior.
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_log10() +
scale_y_log10()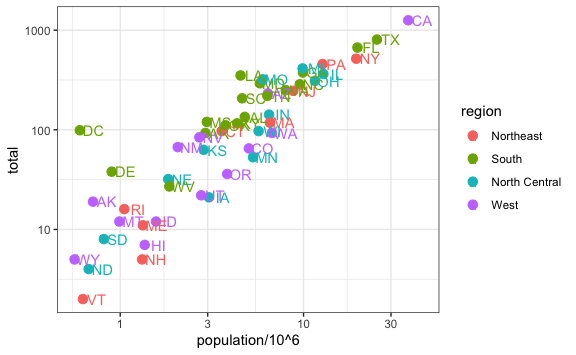
5.5 Capa de etiquetas, título y leyenda
También podemos cambiar las etiquetas (label en inglés) al gráfico. Hasta el momento en el eje x vemos que aparece population/10^6 y lo podemos cambiar con la función xlab(). De la misma forma podemos cambiar en el eje y usando ylab(). Para agregar un títutlo al gráfico usaremos la función ggtitle(). Para cambiar el nombre a la leyenda usaremos la función scale_color_discrete().
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_log10() +
scale_y_log10() +
xlab("Población expresada en millones (escala logarítmica)") +
ylab("Total número de asesinatos (escala logarítmica)") +
ggtitle("Asesinatos con armas de fuego en EEUU en 2010") +
scale_color_discrete(name = "Regiones")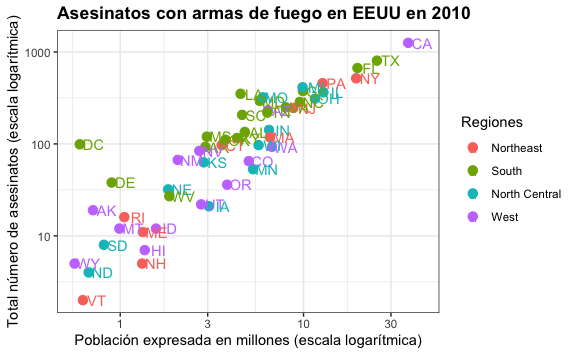
5.6 Líneas de referencia
Podemos agregar líneas de referencia, ya sean verticales con geom_vline(xintercept = ), horizontales con geom_hline(yintercept = ...) o diagonales con geom_abline(intercept = ), ésta última nos pide en qué punto corta el eje y y dibuja una línea con pendiente por default de 1.
Por ejemplo, podríamos calcular el promedio del total de asesinatos y dibujar una línea de referencia horizontal.
#Calculamos el promedio del total
promedio_total <- mean(murders$total)
#Y agregamos la línea de referencia horizontal
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_log10() +
scale_y_log10() +
xlab("Población expresada en millones (escala logarítmica)") +
ylab("Total número de asesinatos (escala logarítmica)") +
ggtitle("Asesinatos con armas de fuego en EEUU en 2010") +
scale_color_discrete(name = "Regiones") +
geom_hline(yintercept = promedio_total)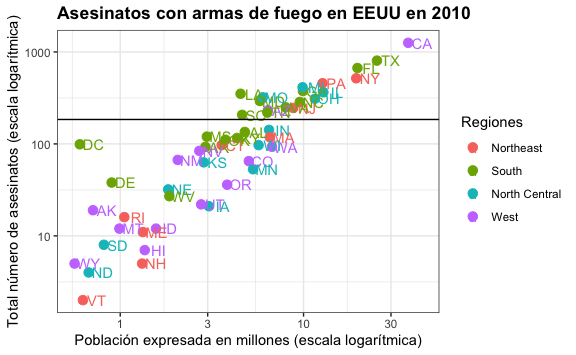
O podríamos calcular el ratio de asesinatos por millón de habitantes en todo EEUU y dibujar una diagonal de referencia. En el caso de la diagonal tenemos que expresarlo en la misma escala del eje, por ende tenemos que convertirlo a log10.
# Calculamos el ratio promedio
ratio <- sum(murders$total)/sum(murders$population) * 10^6
# Calculamos el logaritmo en base 10 para obtener la intercepción en el "eje y"
ratio_log10 <- log10(ratio)
#Y agregamos la línea de referencia diagonal
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_log10() +
scale_y_log10() +
xlab("Población expresada en millones (escala logarítmica)") +
ylab("Total número de asesinatos (escala logarítmica)") +
ggtitle("Asesinatos con armas de fuego en EEUU en 2010") +
scale_color_discrete(name = "Regiones") +
geom_abline(intercept = ratio_log10)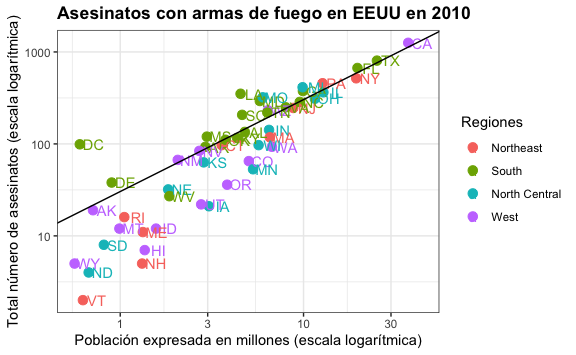
Podemos mejorar esta línea de referencia haciéndola punteada y de color gris. Para ello basta con editar la función geom_abline() de la siguiente forma:
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_log10() +
scale_y_log10() +
xlab("Población expresada en millones (escala logarítmica)") +
ylab("Total número de asesinatos (escala logarítmica)") +
ggtitle("Asesinatos con armas de fuego en EEUU en 2010") +
scale_color_discrete(name = "Regiones") +
geom_abline(intercept = ratio_log10, lty = 2, color = "darkgrey")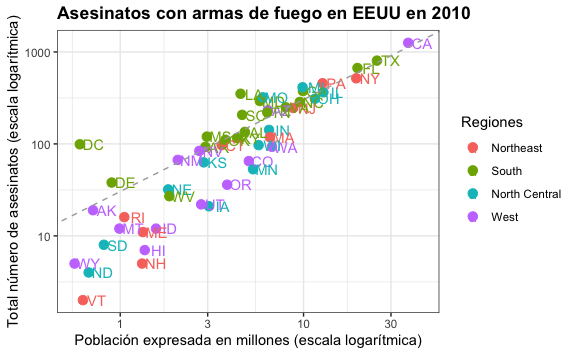
5.7 Cambiando el estilo del gráfico
El estilo del gráfico usando ggplot() puede ser fácilmente cambiado. Existen múltiples temas que podemos usar cargando la librería ggthemes. Podemos, por ejemplo utilizar un tema muy utilizado: el tema de the economist agregando la capa theme_economist().
library(ggthemes)
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text(nudge_x = 0.075) +
scale_x_log10() +
scale_y_log10() +
xlab("Población expresada en millones (escala logarítmica)") +
ylab("Total número de asesinatos (escala logarítmica)") +
ggtitle("Asesinatos con armas de fuego en EEUU en 2010") +
scale_color_discrete(name = "Regiones") +
geom_abline(intercept = ratio_log10, lty = 2, color = "darkgrey") +
theme_economist()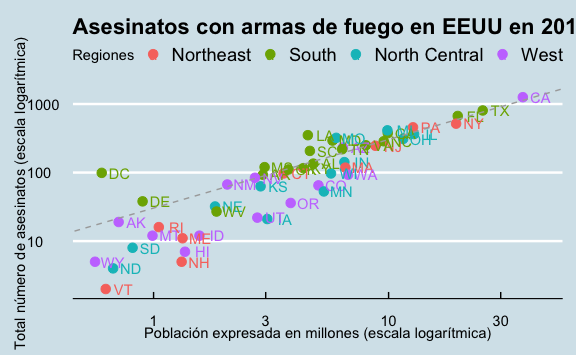
Aun vemos abreviaturas superpuestas. Podemos hacer que los nombres se repelan utilizando la función geom_text_repel() en vez de geom_text() que estamos usando actualmente. Para utilizar esta función necesitamos llamar a la librería ggrepel.
library(ggthemes)
library(ggrepel)
murders %>%
ggplot() +
aes(x = population/10^6, y = total, label=abb, color=region) +
geom_point(size=3) +
geom_text_repel() +
scale_x_log10() +
scale_y_log10() +
xlab("Población expresada en millones (escala logarítmica)") +
ylab("Total número de asesinatos (escala logarítmica)") +
ggtitle("Asesinatos con armas de fuego en EEUU en 2010") +
scale_color_discrete(name = "Regiones") +
geom_abline(intercept = ratio_log10, lty = 2, color = "darkgrey") +
theme_economist()
#> Warning: ggrepel: 1 unlabeled data points (too many overlaps). Consider
#> increasing max.overlaps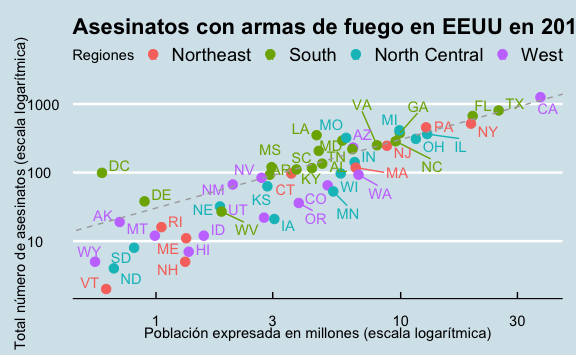
Este gráfico visualmente es mucho más fácil de entender y es estéticamente mucho mejor que el gráfico por default que creamos en capítulos anteriores. Podemos explorar más ejemplos en este enlace.
5.8 Resumiendo datos con dplyr
Una parte importante del análisis exploratorio es el saber resumir una variable en datos sencillos de comprender.
El paquete tidyverse incluye varios paquetes, entre ellos dplyr que nos facilita el resumir los datos de una variable. Cuando hacemos un llamado a la librería tidyvere estamos llamando también a todas las funciones de dplyr. Para comenzar a utilizar las funciones de dplyr vamos a cargar el data frame heights (estaturas en español) que se encuentra en la librería dslabs.
Primero entendemos el data frame heights, podemos hacer aplicar pipeline y luego usar la función head():
heights %>%
head()
#> sex height
#> 1 Male 75
#> 2 Male 70
#> 3 Male 68
#> 4 Male 74
#> 5 Male 61
#> 6 Female 65Este data frame corresponde al listado de atributos de alumnos de una universidad, donde la columna height nos indica la estatura de c/u en pulgadas.
Finalmente, agreguemos la columna estatura donde transformaremos la estatura a metros. Recordemos que un metro tiene 39.37 pulgadas. El resultado almacenémoslo en la variable estaturas.
estaturas <- heights %>%
mutate(estatura = height/39.37)
estaturas %>%
head()
#> sex height estatura
#> 1 Male 75 1.905004
#> 2 Male 70 1.778004
#> 3 Male 68 1.727203
#> 4 Male 74 1.879604
#> 5 Male 61 1.549403
#> 6 Female 65 1.651003La forma más rápida de resumir una listado de datos es indicando cuál es el promedio y cuánto es su desviación estándar6. Si quisiéramos obtener el promedio usaríamos la función mean() y sd() para obtener la desviación estandar. Por ejemplo:
Sin embargo, esto nos resume todos los estudiantes sin tener en cuenta si podrían los hombres ser en promedio más altos que las mujeres. Si quisiéramos calcular el promedio y la desv. estándar tendríamos que filtrar primero, luego almacenar en una variable y finalmente calcular el promedio y desviación estándar. Esto es impráctico y para ello dplyr nos otorga la función summarize().
5.8.1 Función summarize
Podemos usar la función summarize usando el operador pipeline. Así, podríamos calcular el promedio y la desv. estándar de esta forma:
estaturas %>%
filter(sex == "Male") %>%
summarize(promedio = mean(estatura), desv_est = sd(estatura))
#> promedio desv_est
#> 1 1.760598 0.09172018Esta función nos genera también un data frame. Podemos validarlo si almacenamos el resultado en la variable estaturas_hom y luego reportamos la clase de la variable:
estaturas_hom <- estaturas %>%
filter(sex == "Male") %>%
summarize(promedio = mean(estatura), desv_est = sd(estatura))
class(estaturas_hom)
#> [1] "data.frame"Podemos reportar el data frame estaturas_hom y usarlo para futuros análisis accediendo con el accesador $.
Vemos que el promedio de estatura de los hombres es de 1.76 metros con una desviación estándar de 0.09 metros.
De la misma forma, podemos usar summarize para calcular otras funciones como:
estaturas %>%
filter(sex == "Male") %>%
summarize(minimo = min(estatura), maximo = max(estatura), mediana = median(estatura))
#> minimo maximo mediana
#> 1 1.270003 2.100004 1.752604El estudiante más alto mide más de 2.1 metros. La mitad de los estudiantes hombres mide más de 1.75 metros.
Sin embargo, tendríamos que cambiar ahora por “Female” para calcular los datos de las mujeres. Necesitamos agrupar y después resumir la data teniendo en cuenta la agrupación. Para ello existe la función group_by()
5.8.2 Función Group By
Esta función nos permite crear data frames agrupados lo cual nos facilita el resumir los datos. Solo tendríamos que seleccionar en base a qué queremos agrupar y ya no filtrar por sexo. En este caso la agrupación sería en base a la columna sex:
estaturas %>%
group_by(sex) %>%
summarize(promedio = mean(estatura), desv_est = sd(estatura))
#> # A tibble: 2 × 3
#> sex promedio desv_est
#> <fct> <dbl> <dbl>
#> 1 Female 1.65 0.0955
#> 2 Male 1.76 0.0917En promedio, las mujeres son más bajas que los hombres.
Si ahora recordamos nuestro caso de peligrosidad en EEUU. Podemos calcular el ratio de total de delitos respecto a la población y luego compararlo por región de esta forma:
murders %>%
mutate(ratio = total / population * 100000) %>%
group_by(region) %>%
summarize(ratio_promedio = mean(ratio))
#> # A tibble: 4 × 2
#> region ratio_promedio
#> <fct> <dbl>
#> 1 Northeast 1.85
#> 2 South 4.42
#> 3 North Central 2.18
#> 4 West 1.83En promedio, la región Sur es más peligrosa.
5.9 Ejercicios
Esta vez vamos a realizar ejercicios dentro del campo de la biología y para ello debemos de recordar las partes de una flor. Así le daremos más sentido al problema:
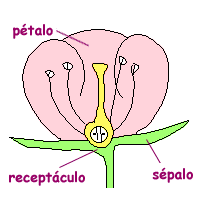
- Carga el data frame
irisa tu ambiente de variables (data(iris)). En este data frame encontramos un listado de características de 150 flores de 3 distintos tipos de especies. Reporta un diagrama de dispersión de la longitud del sépalo y pétalos del data frameiris.
- A partir de la visualización creada en la pregunta anterior, colorea los puntos de acuerdo a la especie a la que pertenece.
Solución
- Modifica en tu gráfico anterior para que figuen los siguientes elementos:
- Título del gráfico: Relación entre tamaño del sépalo y pétalo de diferentes flores
- Etiqueta en el eje-x: Longitud del sépalo (en cm)
- Etiqueta en el eje-y: Longitud del pétalo (en cm)
- Título de la leyenda: Especies
Solución
- Calcula un resumen del ratio entre la longitud del sépalo y la longitud del pétalo. Este resumen debe de mostrar un data frame con el promedio, desviación estandar y la mediana del ratio de estas dos dimensiones mencionadas..
Solución
- Haz un resumen del ratio entre la longitud sépalo y pétalo mostrando una fila por especie.
¿Qué es la desviación estándar?↩︎