Kapitel 7 Zweidimensionale Datensätze Teil 2
7.1 Regressionsanalyse
Mit der Korrelationsanalyse wurde betrachtet, ob ein gleich- oder entgegengerichteter Zusammenhang zwischen zwei Merkmalen vorliegt, ohne dass der Korrelationskoeffizient dabei Auskunft über die Kausalität (Ursache-Wirkungsbeziehung) gibt. Im Rahmen der Regressionsanalyse ist genau festzulegen, welches das abhängige Merkmal, im Folgenden mit y bezeichnet, und welches das erklärende (unabhängige) Merkmal, im Folgenden mit x bezeichnet, ist. y ist somit eine Funktion von x. Wir beschränken uns dabei auf lineare Abhängigkeiten der Form y=a+b⋅x Tabelle 7.1 zeigt für einen Händler von Edelfischen an 10 unterschiedlichen Verkaufstagen den vom Händler festgelegten Preis in € pro kg (x) und die nachgefragte Menge in kg (y). In das zugehörige Streudiagramm in Abbildung 7.2 wurde die Regressionsgerade y=a+b⋅x eingezeichnet, mit der Zielsetzung, die abgesetzte Menge durch den gewählten Verkaufspreis zu erklären. Es ist deutlich zu erkennen, dass die eingezeichnete Gerade nicht durch alle Punkte verläuft, es also keine perfekt lineare Beziehung zwischen y und x gibt, wie dies der Fall wäre, bei einem Korrelationskoeffizienten nach Bravais-Pearson von rBP=1 bzw. rBP=−1.
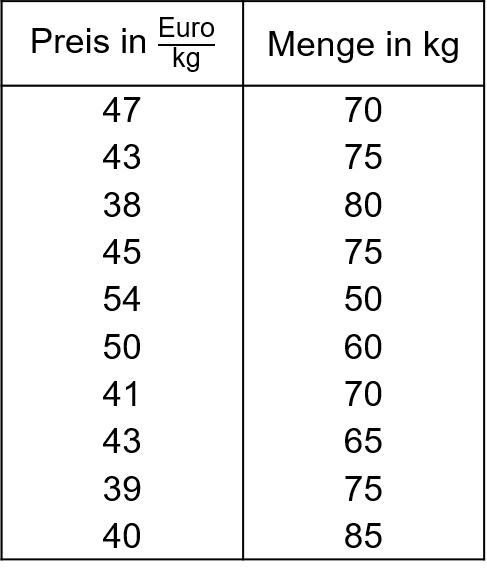
7.1: Beispiel Fischhändler
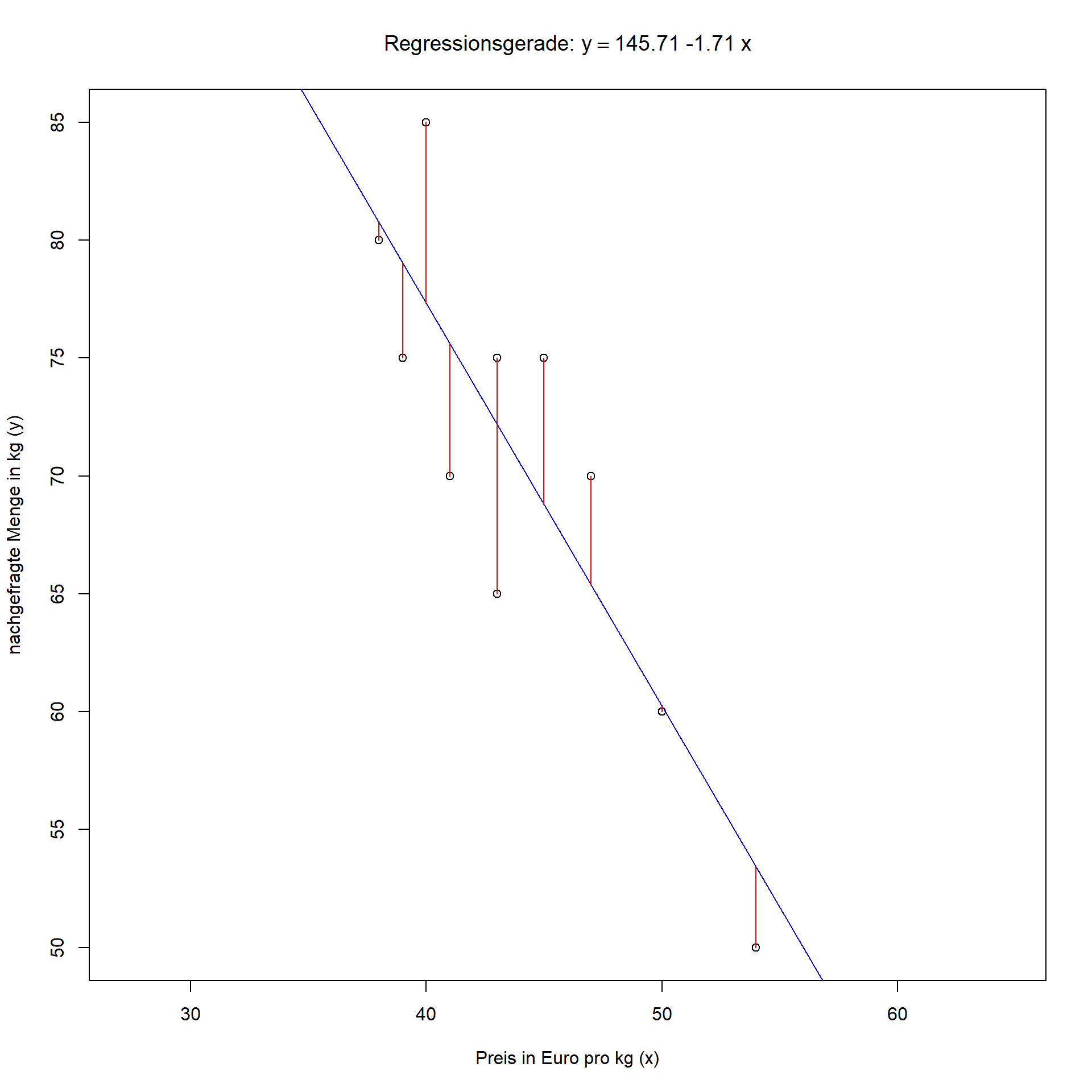
7.2: Regressionsgerade
Die lineare Beziehung von y und x wird also überlagert von Abweichungen,die nicht näher erklärt werden können und auch als Residuen bezeichnet werden. Für die Residuen, als senkrechte Abweichungen zwischen den Punkte (xi,yi) und der Geraden, wird die Variablenbezeichnung ui verwendet. Es gilt somit: yi=a+b⋅xi+ui
Bestimmung der Koeffizienten
Die Methode der Kleinsten Quadrate zur Bestimmung der Koeffizienten wird im Folgenden und unterstützend in diesem Videoclip erläutert:
Nun stellt sich die Frage, wie die Gerade am besten der Punktwolke angepasst werden soll. Dazu wählen wir die Methode der Kleinsten Quadrate. Wie in Abbildung 7.3 durch die Quadrate zu jeder Abweichung dargestellt, werden die Koeffizienten a und b der Regressionsgeraden so gewählt, dass die Summe der quadratischen Abweichungen, also ∑ni=1u2i minimal ausfällt. Mit dieser Zielsetzung erhält man eine eindeutige Lösung für die gilt, dass der größtmögliche Anteil der Variation in der abhängigen Variablen y durch das Modell erklärt werden kann.
Formal wird die Summe der quadrierten Residuen als Funktion der Variablen a und b notiert und im Folgenden mit:
Q(a,b)=n∑i=1u2i=n∑i=1(yi−(a+bxi))2
bezeichnet, für welche die Minimierungsaufgabe mina,b(Q(a,b)) zu lösen ist.
Dazu werden die partiellen Ableitungen nach a und b bestimmt und jeweils mit Null gleichgesetzt.
Schließlich können aus den beiden resultierenden Gleichungen durch Umstellen und Einsetzen die folgenden Berechnungsvorschriften für a und b bestimmt werden (zur Herleitung):
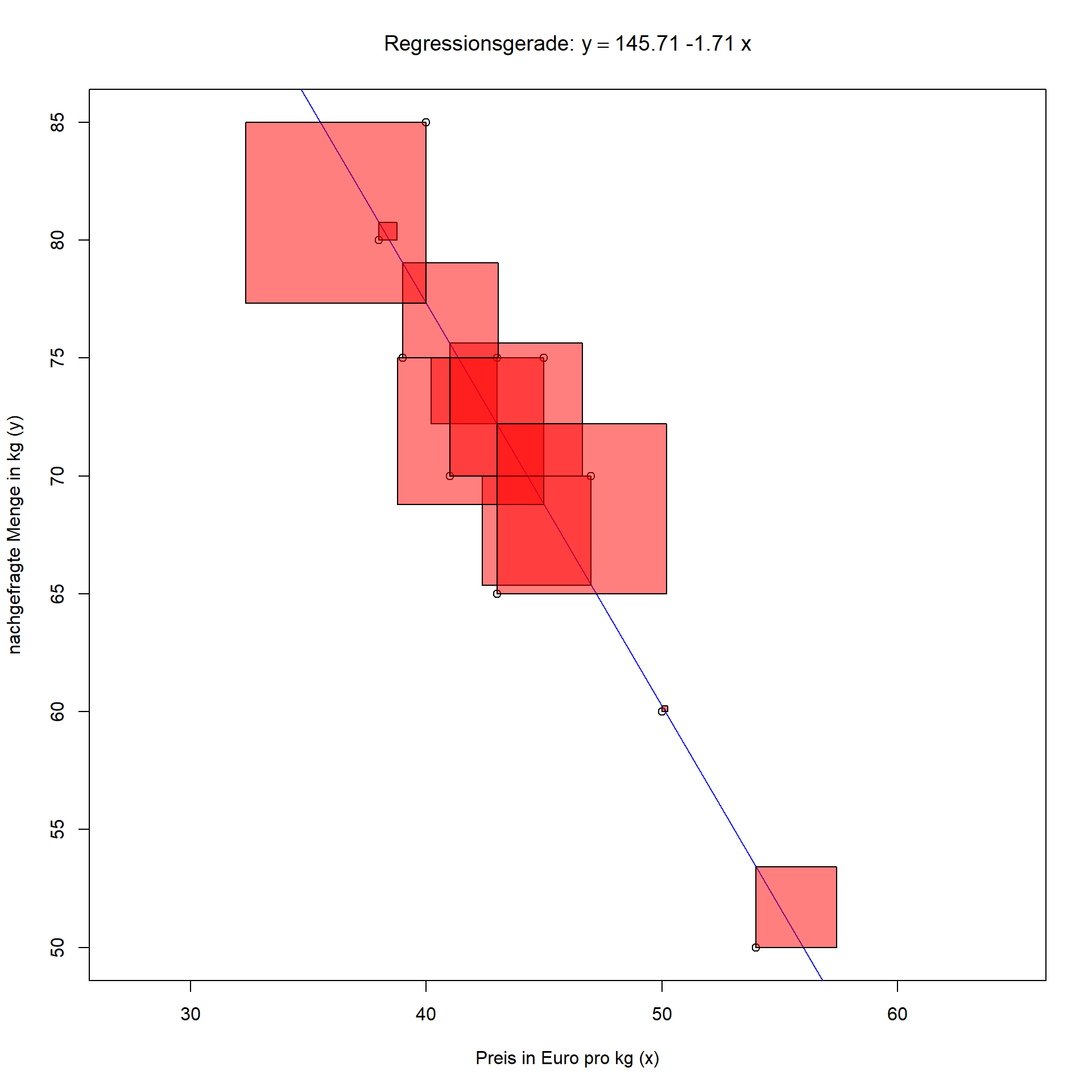
7.3: Regressionsgerade mit quadratischen Abweichungen
1) b=∑ni=1(xi−¯x)(yi−¯y)∑ni=1(xi−¯x)2=SxyS2x2) a=¯y−b¯x
Eine Lösung existiert nur dann, sofern eine Variation für das Merkmal x vorliegt, also der Nenner aus 1) größer Null ist.
Im Beispiel des Fischhändlers lautet die Regressionsgerade:
y=145,71−1,71⋅x
Die einzelnen Rechenschritte sind in Abbildung 7.4 dargestellt.

7.4: Beispiel Fischhändler Berechnung der Koeffizienten
Interpretation der Koeffizienten
Der Koeffizient b besagt somit, dass jede Erhöhung des Preises um einen Euro pro kg im Durchschnitt mit einem Rückgang der nachgefragten Menge um 1,71 kg einhergeht.
Für einen x Wert von Null (Preis von 0€) entspricht y (die nachgefragte Menge) dem Koeffizienten a. Hier ist jedoch Vorsicht bei der Interpretation geboten. Die lineare Beziehung zwischen zwei Merkmalen kann in vielen Fällen, wenn überhaupt, nur für einen gewissen Wertebereich sinnvoll unterstellt werden. Wenn man für die erklärende Variable das Intervall der Beobachtungswerte weit verlässt, so gilt die lineare Abhängigkeit häufig nicht mehr. Man sollte also nicht davon ausgehen, dass der Fischhändler 145,71 kg absetzen würde, falls er seinen Fisch verschenkt.
Prognosen
Die Werte für y, welche sich aus der Vorschrift ˆy=a+b⋅x ergeben und somit genau auf der Regressionsgeraden liegen, werden theoretische y-Werte genannt und mit ˆy bezeichnet. Zu jedem xi aus dem Paar der Beobachtungswerte (xi,yi) lässt sich somit auch ein theoretischer Wert ˆyi angeben. Zudem können natürlich auch für Ausprägungen von x, zu denen keine Beobachtungen vorliegen, theoretische y-Werte bestimmt werden. So kann z.B. für einen Preis von 42 € pro kg die abgesetzte Menge prognostiziert werden: ˆy=145,71−1,71⋅42=73,89
Varianzzerlegung
Die Gesamtvarianz der abhängigen Variablen y lässt sich in die beiden folgenden Varianzen zerlegen: 1nn∑i=1(yi−¯y)2Gesamtvarianz=1nn∑i=1(ˆyi−¯y)2erklärte Varianz +1nn∑i=1u2inicht erklärte Varianz
Folgende Eigenschaften führen zu der oben dargestellten Varianzzerlegung:
- ui=yi−ˆyi sind die Residuen, welche aus der Differenz der beobachteten Werte yi und der theoretischen Werte ˆyi ermittelt werden.
- Es gilt: ∑ni=1ui=0.
- Außerdem gilt: ∑ni=1ˆyiui=0
- Für die theoretischen y-Werte ˆyi gilt: ¯ˆy=¯y
Determinationskoeffizient
Das Verhältnis aus erklärter Varianz zur Gesamtvarianz, also
d=1n∑ni=1(ˆyi−¯y)21n∑ni=1(yi−¯y)2
wird als Determinationskoeffizient oder mit den Synonymen Bestimmtheitsmaß und R2 bezeichnet.
d gibt an, wie hoch der Anteil in der Varianz der abhängigen Variablen ausfällt, welcher durch die Regression erklärt wird und dient somit als Gütekriterium.
Eine alternative Berechnungsmöglichkeit für d besteht mit:
d=r2BP
Es kann also gezeigt werden, dass der Determinationskoeffizient dem Quadrat des Korrelationskoeffizienten nach Bravais-Pearson entspricht. Daher resultiert auch das Synonym R2.
Wie aus Abbildung 7.4 hervorgeht, konnten im Beispiel somit rund 74% der Variation in der nachgefragten Menge durch das Regressionsmodell erklärt werden. In der Beurteilung der Güte stützt man sich häufig auf den Richtwerten der Korrelationskoeffizienten. Von einer starken Korrelation haben wir beispielsweise gesprochen, falls |rBP|>0,8. Für d=r2BP kann folglich von einem hohen Erklärungsgrad gesprochen werden, falls d>0,64 ist.
Ausreißer
Genau wie beim Korrelationskoeffizienten nach Bravais-Pearson besteht für die Koeffizienten der Regressionsgerade eine Empfindlichkeit gegenüber Ausreißern, was besonders stark in kleinen Datensätzen zum Tragen kommt. Im Code der folgenden Anwendung können Sie das Wertepaar für einen möglichen Ausreißer frei wählen und sehen, wie die Koeffizienten dadurch beeinflusst werden.
7.2 Zeitreihenanalyse
Man unterscheidet Querschnittsdaten und Zeitreihendaten voneinander.
Querschnittsdaten beziehen sich für Bestandsgrößen auf einen festgelegten Zeitpunkt (Beispiel: Alter der Absolventen beim Examen) und für Stromgrößen auf einen festgelegten Zeitraum (Beispiel: Konsumausgaben einzelner Haushalte im Jahr 2019). Betrachtet werden mehrere Merkmalsträger, über die sich für das erhobene Merkmal oder die erhobenen Merkmale der “Querschnitt” ergibt.
Es ist aber auch möglich, für nur einen Merkmalsträger ein bestimmtes Merkmal im Zeitablauf immer wieder neu zu erheben. Man spricht dann von Zeitreihendaten. Dabei müssen die Zeitabstände immer gleich groß gewählt werden. Sofern es sich bei dem Merkmal um eine Stromgröße (Beispiel: Bruttoinlandsprodukt quartalsweise) handeln sollte, so sind die Zeitintervalle für die Stromgröße in gleicher Länge zu wählen (monatlich, quartalsweise, jährlich). Häufig vernachlässigt man dabei allerdings, dass z.B. nicht alle Monate gleich lang sind oder Schaltjahre einen Tag länger dauern. Für Bestandsgrößen (Beispiel: Zahl der Arbeitslosen am Monatsende) gilt, dass die Zeitabstände zwischen den gewählten Zeitpunkten gleich groß zu wählen sind.
Um der zeitlichen Anordnung Rechnung zu tragen, werden die aufeinanderfolgenden Beobachtungen xt mit einem Zeitindex t versehen und fortlaufend mit natürlichen Zahlen durchnummeriert.
x1,x2,…,xn
Zu jeder Modellzeit t existiert ein eindeutiger Bezug zur Realzeit. Beginnt beispielsweise die Zeitreihe der Arbeitslosenzahlen im Jahr 2018 mit dem Monat Januar, so erhält dieser die Modellzeit t=1.
7.2.1 additives Komponentenmodell
Dem Komponentenmodell liegt die Idee zugrunde, dass sich Zeitreihendaten aus unterschiedlichen Einflüssen zusammensetzen, welche als Komponenten bezeichnet werden. Sind die beobachteten Zeitreihenwerte das Resultat aus der Summe dieser Komponenten, so spricht man vom additiven Komponentenmodell. Das folgende Komponentenmodell eignet sich häufig zur Modellierung ökonomischer Zeitreihen: xt=Tt+Zt⏟Gt+St+Rt
Dabei gilt:
- xt ist der beobachtete Zeitreihenwert zur Modellzeit t.
- Tt ist die Trendkomponente zur Modellzeit t. Mit der Trendkomponente wird die langfristige Entwicklung der Zeitreihe abgebildet.
- Zt ist die zyklische Komponente und dient vor allem für ökonomische Zeitreihen der Modellierung konjunktureller Entwicklungen.
- In Summe bilden Tt und Zt die glatte Komponente Gt=Tt+Zt, deren Bewegung im Zeitablauf nicht durch starke Fluktuationen geprägt ist, also glatt verläuft.
- St ist die Saisonkomponente und spielt nur bei Zeitreihendaten in unterjähriger Frequenz (z.B. monatlich oder quartalsweise) eine Rolle. Es wird unterstellt, dass die Saison starr ist, d.h. es wird davon ausgegangen, dass sich jedes Jahr dasselbe Saisonmuster wiederholt. Beispielsweise für Quartalsdaten gilt dann St=St+4 ∀ t
Zudem soll die Summe der Saisonkomponenten über ein Jahr Null entsprechen. Für Quartalsdaten bedeutet dies etwa: ∑4i=1St+i=0 ∀ t - Rt ist die Restkomponente, in welcher sich unsystematische Einflüsse sammeln, welche nicht durch die übrigen Komponenten abgebildet werden können. Für das Mittel über alle Restkomponenten wird ein Durchschnittswert von Null angenommen.
Die folgende Grafik veranschaulicht beispielhaft den Verlauf einer Zeitreihe sowie ihre Zerlegung in die einzelnen Komponenten:
7.2.2 Bestimmung der Trendkomponente
Wir beschränken uns auf lineare Trends. Im folgenden wird also davon ausgegangen, dass die langfristige Entwicklung der Zeitreihe linear verläuft. Die Trendkomponente Tt kann somit in Abhängigkeit der Modellzeit t formuliert werden als Tt=a+b⋅t Es existieren unterschiedliche Ansätze zur Ermittlung der Koeffizienten a und b.
7.2.2.1 Methode der Reihenhälften
Sofern die Anzahl der vorhandenen Zeitreihenwerte n gerade ist, wird wie folgt vorgegangen:
Die n Zeitreihenwerte werden zunächst in zwei gleichgroße Hälften aufgeteilt, so dass jede Hälfte n′=n2 Zeitreihenwerte enthält.
Anschließend werden für die Zeitreihenwerte jeder Hälfte deren arithmetische Mittel berechnet. Die beiden Mittel der Zeitreihenhälften werden dann mit ¯x(1) und ¯x(2) bezeichnet. ¯x(1) und ¯x(2) werden genau den zeitlichen Mitten der beiden Häften zugeordnet. Unter Verwendung der Modellzeit erhält man so zwei Punkte mit folgenden Koordinaten:
(n′+12,¯x(1)), (3⋅n′+12,¯x(2))
Nun wird die Trendgerade Tt=a+b⋅t durch die beiden Punkte gelegt.
Die Koeffizienten der Trendgeraden bestimmen sich dann wie folgt:
b=¯x(2)−¯x(1)n′
a=¯x(1)−b⋅n′+12
Die Methode der Reihenhälften wird im folgenden Video erläutert:
Falls die Anzahl der Werte ungerade ist, so wird der mittlere Wert einfach ausgelassen.
Zu beachten ist, dass zwischen den beiden arithmetischen Mitteln der beiden Hälften dann n′+1 Werte liegen und der Steigungskoeffizient der Trendgeraden wie folgt zu berechnen ist:
b=¯x(2)−¯x(1)n′+1
Alle übrigen Berechnungen erfolgen wie für eine gerade Anzahl von Zeitreihenwerten.
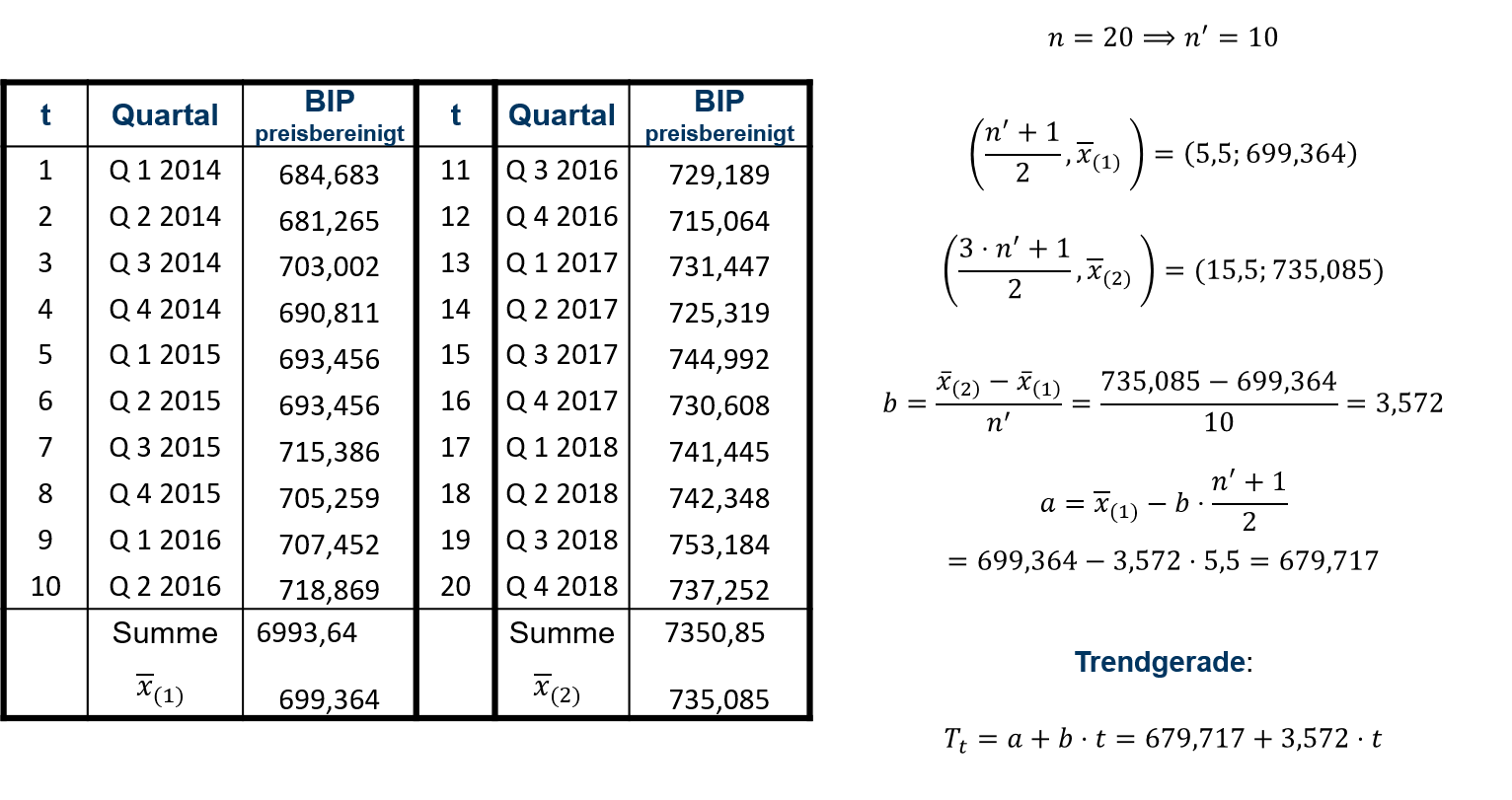
7.5: Methode der Reihenhälften
In Abbildung 7.5 wurde die Trendgerade für das preisbereinigte Bruttoinlandsprodukt in Quartalswerten bestimmt. Die Koeffizienten der Trendgeraden können dann wie folgt interpretiert werden:
- Dem preisbereinigten BIP liegt ein Trendwachstum um 3,572 Mrd. € (Wert von Koeffizient b) pro Quartal zugrunde.
- Die Trendkomponente entspricht für t=0 dem Koeffizienten a, also T0=a. T0=679,717 ist folglich der Wert der Trendkomponente im 4. Quartal des Jahres 2013, welchem eine Modellzeit von t=0 zuzuordnen ist.
Der Verlauf der Zeitreihe und der Trendgeraden ist in Abbildung 7.6 zu sehen.
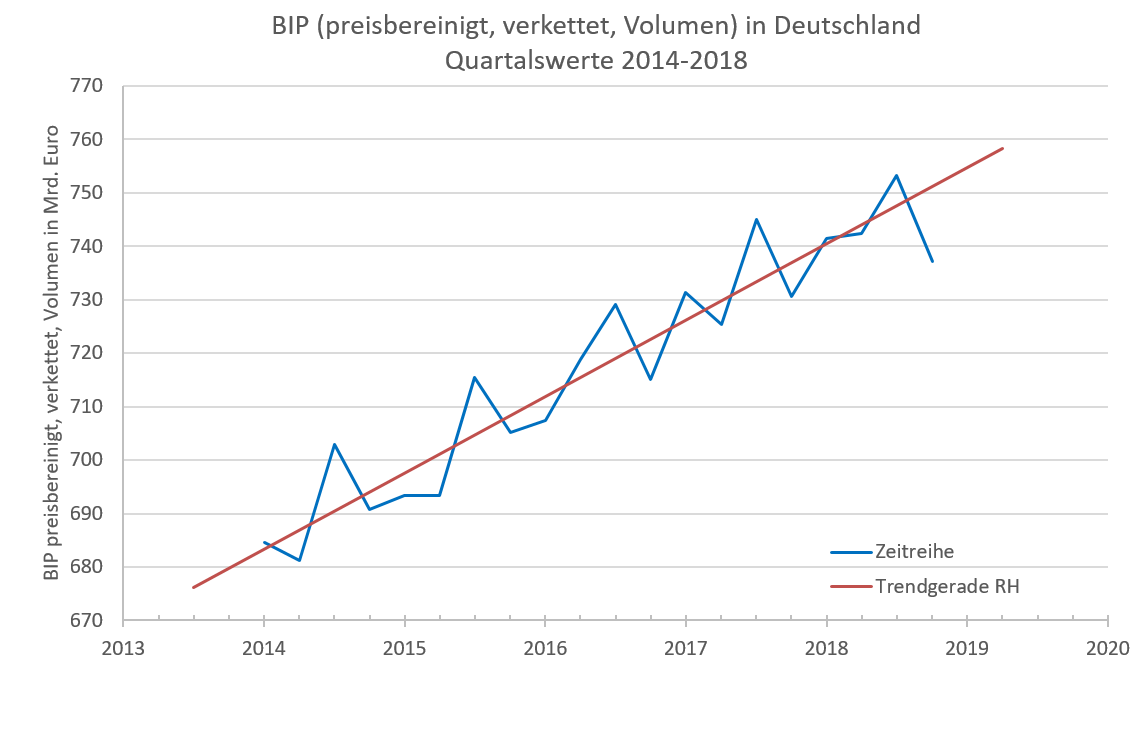
7.6: Zeitreihe BIP, Methode der Reihenhälften
7.2.2.2 Trendbestimmung mit der Methode der Kleinsten Quadrate
Eine weitere, etwas rechenaufwändigere Möglichkeit zur Bestimmung der Trendgeraden bietet die Methode der Kleinsten Quadrate (KQ-Methode).
Es wird analog zu Kapitel 7.1 eine Regressionsanalyse durchgeführt, bei der die Zeitreihenwerte xt die abhängige Variable darstellen und die Modellzeit t die unabhängige (erklärende) Variable.
Das Modell lautet:
xt=a+b⋅t⏟Tt+ut⏟Zt+St+Rt
Die Residuen als xt−Tt=Zt+St+Rt setzen sich also aus den übrigen drei Komponenten zusammen.
Bestimmung der Koeffizienten
Prinzipiell erfolgt die Berechnung von a und b wie in Kapitel 7.1 beschrieben.
Aufgrund der verwendeten Modellzeit kann die Berechnungsvorschrift für den Koeffizienten b unter Rückgriff auf die Verschiebungssätze für Kovarianzen und Varianzen und Einbezug der Summenformeln für natürliche Zahlen wie folgt vereinfacht werden:
b=n⋅∑nt=1xt⋅t−∑nt=1xt⋅∑nt=1tn⋅∑nt=1t2−(∑nt=1t)2
wobei
n∑t=1t=n(n+1)2 und n∑t=1t2=n(n+1)(2n+1)6
Der Koeffizient a bestimmt sich dann aus:
a=∑nt=1xt−b⋅∑nt=1tn=¯x−b⋅n+12
In Abbildung 7.7 wurde die Trendgerade für das preisbereinigte Bruttoinlandsprodukt in Quartalswerten bestimmt.
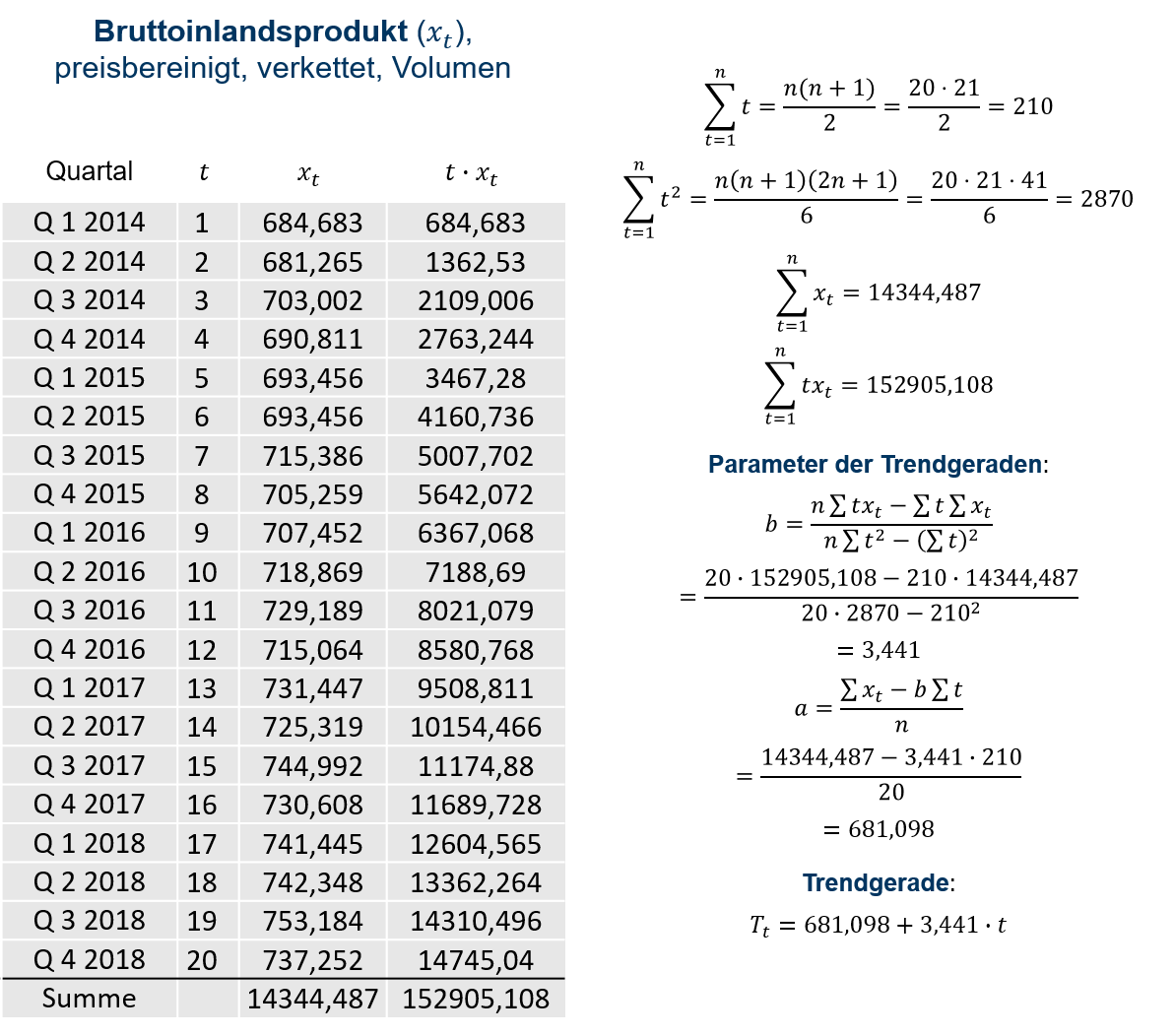
7.7: Trendkomponente, KQ-Methode
Die Interpretation der Koeffizienten erfolgt in analoger Weise zur Methode der Reihenhälften.
Die Bestimmung der Trendgeraden mit der KQ-Methode ist rechenintensiver als die Bestimmung nach der Methode der Reihenhälften. Vorteilhaft ist jedoch, dass mit der KQ-Methode der größtmögliche Teil der Varianz in den Zeitreihenwerten durch die Trendgerade erklärt werden kann.
Abbildung 7.8 zeigt für das BIP von 2014 bis 2018 die Trendgeraden nach beiden Methoden im Vergleich.
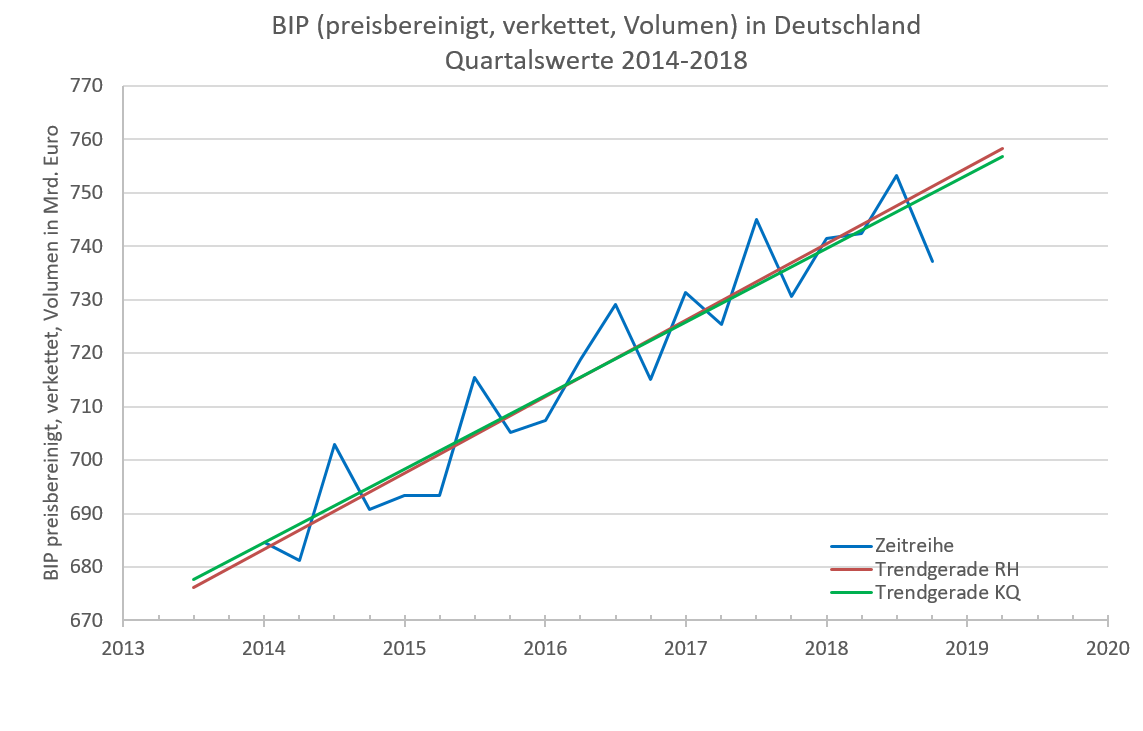
7.8: Trendkomponente, KQ-Methode
7.2.3 Bestimmung der glatten Komponenten
Die glatte Komponente Gt=Tt+Zt kann mit der Methode der gleitenden Durchschnitte bestimmt werden. Dabei wird das Ziel verfolgt, die Saisonkomponente St sowie die Restkomponente Rt durch Mittelung aus der Zeitreihe herauszufiltern und somit zu eliminieren.
Saisonbehaftet sind nur Zeitreihen in unterjähriger Frequenz, beispielsweise Quartals- oder Monatswerte. Zeitreihen in jährlicher Frequenz weisen also keine Saisonalität auf.
Da sich die Saisonfigur (das saisonale Muster) per Annahme jedes Jahr in gleicher Weise wiederholt, führt die Mittelung über jene Anzahl aufeinanderfolgender Zeitreihenwerte, welche eine Länge von genau einem Jahr bilden, zu einem Ausschalten der Saisonfigur. Für Quartalsdaten bedeutet dies, dass die Mittelung über 4 aufeinanderfolgende Zeitreihenwerte die Saisonfigur ausschaltet. So könnten beispielsweise die 4 Zeitreihenwerte vom 3. Quartal 2015 bis zum 2. Quartal 2016 gemittelt werden.
Ein Problem besteht nur in der zeitlichen Zuordnung des so gewonnenen Mittelwertes. Grundsätzlich soll das Ziel verfolgt werden, zu einem bestimmten Quartal die glatte Komponente zu bestimmen. Dies gelingt aber nur, wenn im Rahmen der Mittelung aus Perspektive des festgelegten Zeitintervalls genauso viel Vergangenheit wie Zukunft in die Mittelung einfließen.
Abbildung 7.9 zeigt die Berechnung der glatten Komponente für das 3. Quartal 2015. In die Mittelung fließen die gelb unterlegten Zeitreihenwerte ein. Ausgehend vom 3. Quartal 2015 fließt also genauso viel Vergangenheit, wie Zukunft, in die Berechnung ein. Der Mittelwert kann also zeitlich dem 3. Quartal 2015 zugeordnet werden. Die Mittelung erstreckt sich allerdings über 5 Quartale, obwohl bereits 4 aufeinanderfolgende Quartale das vollständige Saisonmuster abbilden. Problematisch scheint, dass das erste und letzte Quartal in der Mittelung, jeweils vom gleichen Saisontyp (jeweils Q1) ist. Damit die Saisonalität aller Quartale insgesamt ein gleiches Gewicht erhält, werden der erste und letzte Wert in der Mittelung mit dem Faktor 12 gewichtet. Schließlich sind somit die saisonalen Besonderheiten aller Quartale in gleicher Stärke vertreten und die Mittelung führt dazu, dass die Saisonfigur eliminiert wird.
Zudem schwindet auch die Restkomponente Rt mit zunehmender Mittelung von Zeitreihenwerten, weshalb der mit ¯x7=703,641 gewonnene Mittelwert als glatte Komponente G7 bezeichnet werden kann.
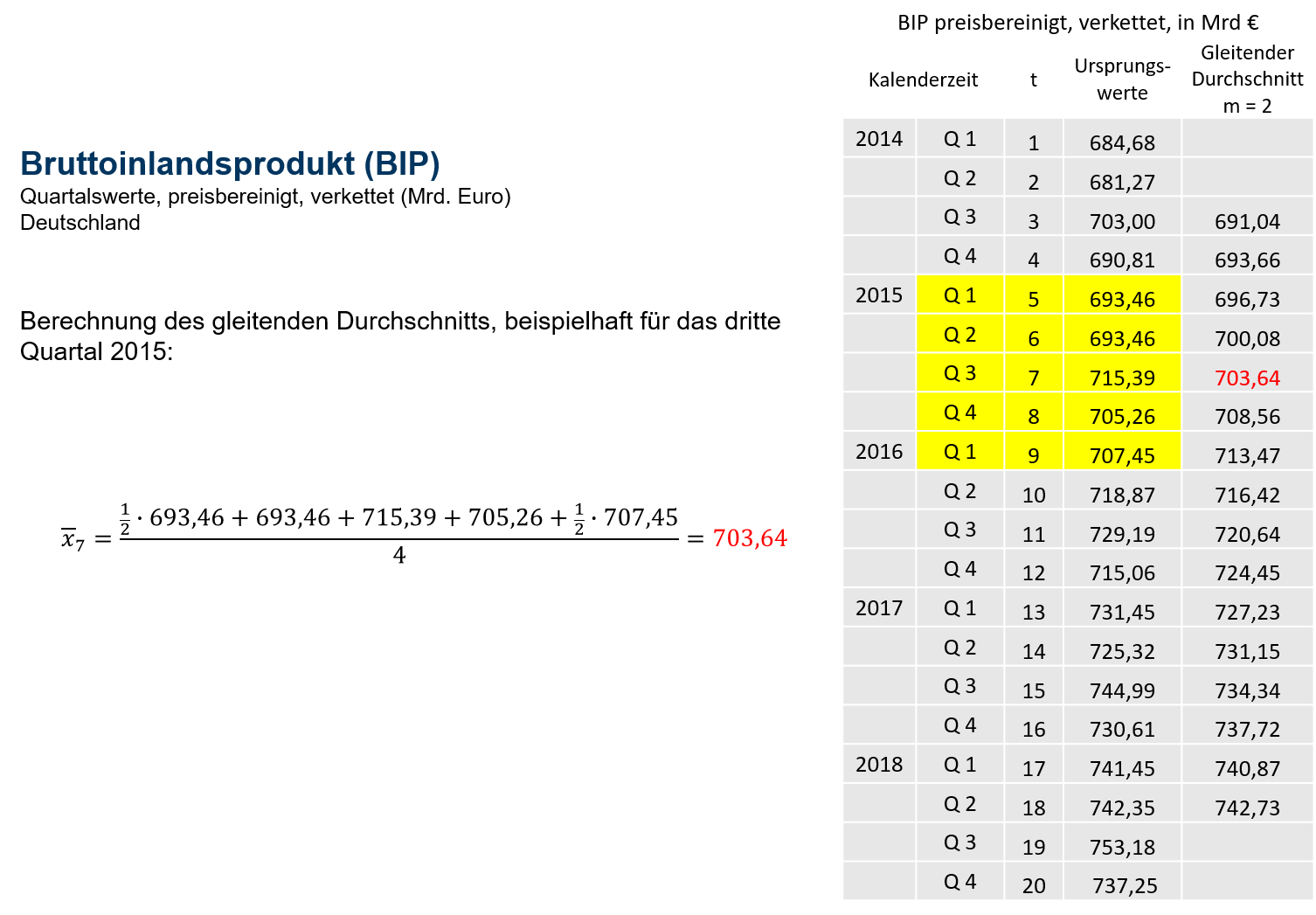
7.9: glatte Komponente, Methode der gleitenden Durchschnitte
gleitende Durchschnitte über Quartalswerte
Wie in Abbildung 7.9 zu sehen, ist also für Zeitreihen in vierteljährlicher Frequenz die folgende Berechnungsformel zu verwenden:
¯xt=12⋅xt−2+xt−1+xt+xt+1+12⋅xt+24
Das gelb unterlegte Fenster zeigt den sogenannten Stützbereich an, also welche Werte in die Berechnung einfließen. Das Fenster ist um einen Wert weiter nach unten zu verschieben, falls für die Modellzeit t=8 die glatte Komponente G8=¯x8 zu berechnen ist usw.
Man erkennt schnell, dass für den aktuellen Rand, mit den Quartalen 3 & 4 des Jahres 2018, keine glatten Komponenten bestimmt werden können, weil dafür die Werte der Quartale 1 & 2 aus dem Jahr 2019 benötigt würden. Gleiches Problem stellt sich für die Quartale 1 & 2 aus dem Jahr 2014 ein.
Abbildung 7.10 zeigt die Zeitreihe der Ursprungswerte xt sowie den Verlauf der glatten Komponente Gt. Die zyklische Komponente Zt kann aus der glatten Komponente Gt mit der Differenz Zt=Gt−Tt isoliert werden. Die Trendkomponente kann dabei mit der Methode der Reihenhälften oder der Methode der Kleinsten Quadrate bestimmt werden.
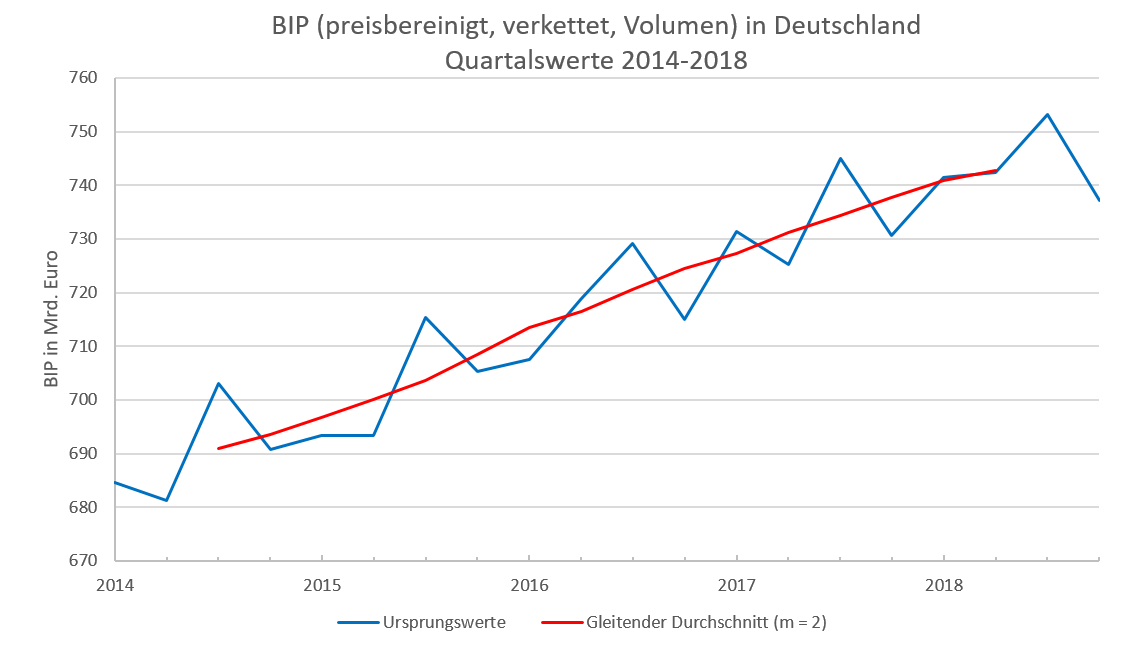
7.10: Ursprungswerte und glatte Komponente
gleitende Durchschnitte über Monatswerte
Liegt die Zeitreihe in monatlicher Frequenz vor, so ist die folgende Berechnungsformel für die glatte Komponente zu verwenden:
¯xt=12⋅xt−6+xt−5+…xt+…xt+5+12⋅xt+612
allgemeine Berechnungsvorschrift für eine gerade Anzahl unterjähriger Zeitreihenwerte
Allgemeiner lässt sich schreiben: ¯xt=12⋅xt−m+⋯+xt+⋯+12⋅xt+m2m
m legt das Berechnungsfenster (Stützbereich) fest und gibt somit die Anzahl der Zeitreihenwerte an, welche vor bzw. nach xt in die Berechnung einfließen.
- m=1 für Halbjahresdaten
- m=2 für Quartalsdaten
- m=6 für Monatsdaten
Isolation der zyklischen Komponente
Durch Kombination der Methode der Reihenglättung und einer der Methoden der Trendbestimmung, kann die zyklische Komponente isoliert werden, denn Gt=Tt+Zt⇔Zt=Gt−Tt Die zyklische Komponente des dritten Quartals zum Jahr 2015, also Z7, kann für das vierteljährliche BIP durch Kombination der Methode der Reihenglättung und der Trendbestimmung mit der Methode der Kleinsten Quadrate wie folgt berechnet werden:
T7=681,098+3,441⋅7=705,185 Unter Rückgriff auf die schon berechnete glatte Komponente G7=703,641 gilt dann:
Z7=703,641−705,185=−1,544