Kapitel 4 Streuungsmaße
Streuungsmaße sind Kennzahlen zur Beschreibung der Variabilität eines Merkmals. Das Streuungsmaß soll darüber Aufschluss geben, inwieweit der Mittelwert tatsächlich die zentrale Tendenz einer statistischen Masse repräsentiert. Streuungsmaße sind wichtige Ergänzungen zu Mittelwerten und können als Gütekriterium für den Mittelwert interpretiert werden. Bei geringer Streuung ist der Mittelwert eher ein typischer Wert einer Verteilung als bei einer starken Variabilität der Daten.
4.1 Spannweite
Die Spannweite R (R für range) ist die Differenz zwischen den größten und dem kleinsten Beobachtungswert.
Die Spannweite setzt mindestens Intervallskalenniveau voraus und wird für die unterschiedlichen Datenlagen wie folgt berechnet:
Datenlage A
Als Differenz zwischen dem größten und kleinsten Beobachtungswert der geordneten Urliste. R=x(n)−x(1) Datenlage B
Als Differenz zwischen dem größten und kleinsten Beobachtungswert der Häufigkeitstabelle. R=xm−x1 Datenlage C
Als Differenz zwischen der Obergrenze der letzten Klasse und der Untergrenze der ersten Klasse. R=ak−a0
Eigenschaften der Spannweite
Durch die eingeschränkte Betrachtung auf die beiden Extremwerte, welche möglicherweise starke Ausreißer darstellen, ist die Aussagekraft der Spannweite für die Variabilität des Datensatzes insgesamt sehr begrenzt. Die Spannweite kann daher eher zur Ausreißerkontrolle verwendet werden.
4.2 Quartilsabstand
Der Quartilsabstand ist die Differenz zwischen dem oberen und unteren Quartil Quartilsabstand=Q3−Q1 Durch die Beschränkung auf die mittleren 50% der Verteilung ist der Quartilsabstand unempfindlich gegenüber Ausreißern. Andererseits wird die Variabilität unterhalb des unteren Quartils und oberhalb des oberen Quartils völlig außer Acht gelassen. Auch der Quartilsabstand kann wegen der erforderlichen Differenzenbildung erst ab Intervallskalenniveau bestimmt werden.
4.3 Boxplot
Der Boxplot vereint die Spannweite und den Quartilsabstand in einer graphischen Darstellung. Zudem wird noch der Median abgetragen.
Abbildung 4.1 zeigt den Aufbau eines Boxplots am Beispiel des wöchentlichen Fernsehkonsums in Stunden für 100 Rentnerinnen und Rentner. Das Rechteck wird an den Seiten durch die beiden äußeren Quartile begrenzt. Der Median ist ebenfalls einzuzeichnen. Die “Antennen”, welche nach links und rechts vom Rechteck wegführen, werden in ihrer Ausdehnung vom Minimum und vom Maximum beschränkt. Es können somit die Spannweite und der Quartilsabstand einfach aus der Zeichnung abgelesen werden.
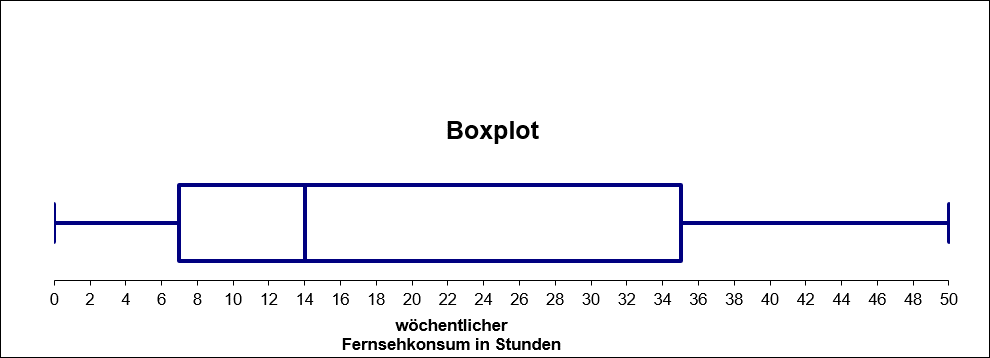
4.1: Boxplot
Aus dem Boxplot kann unmittelbar gefolgert werden, ob die Verteilung linkssteil, rechtssteil oder symmetrisch ist. Ausschlaggebend ist die Position des Medians. Liegt dieser näher am Minimum als am Maximum, so handelt es sich um eine linkssteile Verteilung. Im umgekehrten Fall liegt eine rechtssteile Verteilung vor. Falls der Median genau in der Mitte liegt, so handelt es sich um eine symmetrische Verteilung.
Der Boxplot kann außerdem zur Identifikation von Ausreißern dienen.
Dazu werden die Grenzen des folgenden Intervalls in die Zeichnung abgetragen.
[Q1−12⋅Quartilsabstand,Q3+12⋅Quartilsabstand]
Werte, die außerhalb des Intervalls liegen, gelten als mögliche Ausreißer.
Abbildung 4.2 zeigt für das Zahlenbeispiel mit dem Merkmal “Fachsemester bis zum Bachelorabschluss” die Berechnung der Spannweite und des Quartilsabstands sowie deren Visualisierung durch den Boxplot. Die Verteilung ist linkssteil, da der Median näher am Minimum, als am Maximum liegt.
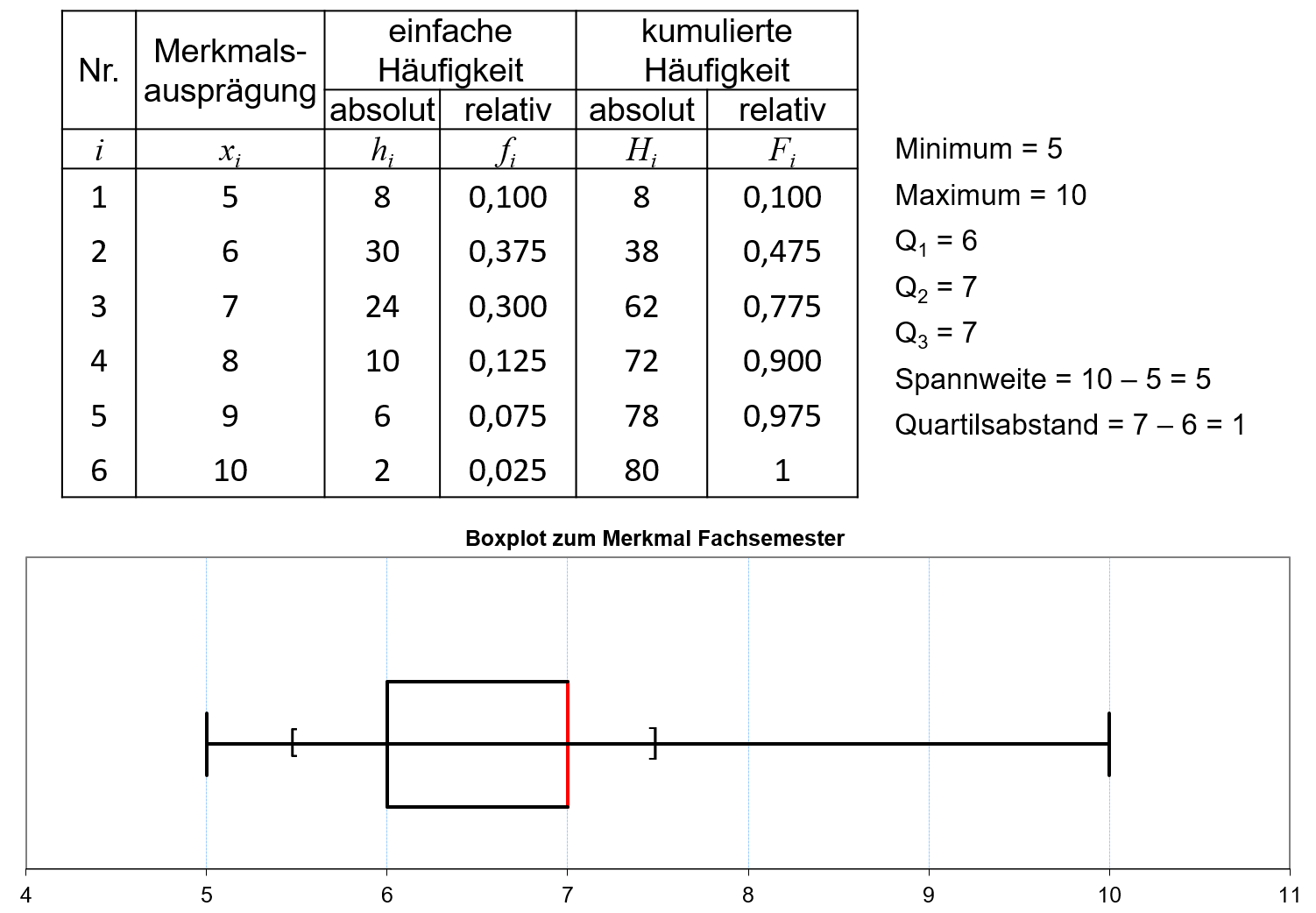
4.2: Boxplot, Merkmal Fachsemester bis zum Bachelorabschluss
4.4 mittlere Spannweite
Betrachtet man die Preise in Supermärkten für einen bestimmten Joghurt und stellt dabei fest, dass die Preise zwischen 50 Cent und einem Euro liegen, so wird man dies als erhebliche Preisdifferenz wahrnehmen. Die Spannweite liegt also bei R=50 Cent. Erhebt man für ein bestimmtes Smartphone die Preise verschiedener Anbieter und stellt eine Preisdifferenz von wiederum 50 Cent zwischen dem günstigsten und dem teuersten Anbieter fest, so wird man diese vermutlich als gering auffassen.
Automatisch setzt man die Preisdifferenz in Bezug zur Größenordnung der Beobachtungswerte und erhält somit ein relatives Streuungsmaß.
Als Bezugspunkt wählt man für die mittlere Spannweite (MSP) den Median. Voraussetzung ist, dass das Merkmal mindestens verhältnisskaliert ist.
Die mittlere Spannweite wird in Form der prozentualen Abweichungen des Minimums und des Maximums zum Median angegeben.
MSP=(Min−Q2Q2⋅100,Max−Q2Q2⋅100)
Eine Daumenregel besagt, dass eine starke Streuung vorliegt, sofern die Beträge der beiden prozentualen Abweichungen in Summe 200% übersteigen.
Für das Beispiel aus Abbildung 4.2 errechnet sich eine mittlere Spannweite von MSP=(5−77⋅100;10−77⋅100)=(−28,57%; 42,86%) Da |−28,57%|+42,86%=71,43%<200% ist die Streuung im Beispiel gering. Der Median, als einzelne Kennzahl, ist somit ein guter Repräsentant für die Verteilung.
4.5 mittlerer Quartilsabstand
Ersetzt man für die mittlere Spannweite Minimum und Maximum durch das untere und obere Quartil, so erhält man den mittleren Quartilsabstand (MQA). Anwendungsvoraussetzung ist wiederum, dass das betrachte Merkmal mindestens verhältnisskaliert ist.
MQA=(Q1−Q2Q2⋅100,Q3−Q2Q2⋅100)
Der mittlere Quartilsabstand gibt Auskunft über die mittleren 50% der Verteilung und ist somit unempfindlich gegenüber Ausreißern.
Der Daumenregel nach liegt in der Mitte der Verteilung eine starke Streuung vor, sofern die Beträge der beiden prozentualen Abweichungen in Summe 100% übersteigen.
Für das Beispiel aus Abbildung 4.2 errechnet sich ein mittlerer Quartilsabstand von MQA=(6−77⋅100;7−77⋅100)=(−14,29%; 0%) Da |−14,29%|+0%=14,29%<100% ist die Streuung im Beispiel in der Mitte gering. Der Median, als einzelne Kennzahl, ist somit ein guter Repräsentant für die mittleren 50% der Verteilung.
4.6 mittlere quadratische Abweichung
Die mittlere quadratische Abweichung s2 (auch Varianz genannt) ist das wohl bekannteste Streuungsmaß. Sie entspricht der durchschnittlichen quadratischen Abweichung der Beobachtungswerte zum arithmetischen Mittel. In die Berechnung von s2 fließen alle Beobachtungswerte und somit alle Informationen aus dem Datensatz ein. s2 kann ab Intervallskalenniveau bestimmt werden und wird für die drei Datenlagen wie folgt berechnet:
Datenlage A s2=1n⋅n∑i=1(xi−¯x)2 Datenlage B s2=1n⋅m∑i=1hi⋅(xi−¯x)2 bzw. s2=m∑i=1fi⋅(xi−¯x)2 bei Verwendung der relativen Häufigkeiten
Datenlage C
Mit xi sind die Klassenmitten für die Berechnung heranzuziehen. s2=1n⋅k∑i=1hi⋅(xi−¯x)2 bzw. s2=k∑i=1fi⋅(xi−¯x)2 bei Verwendung der relativen Häufigkeiten
Der Verschiebungssatz von Steiner
Eine für die Taschenrechnernutzung freundlichere Berechnung der mittleren quadratischen Abweichung bietet der Verschiebungssatz nach Steiner, dessen Herleitung für die Datenlage A im folgenden Video gezeigt wird.
Die Anwendung des Verschiebungssatzes führt zu folgenden Berechnungsvorschriften für die einzelnen Datenlagen.
Datenlage A s2=1n⋅n∑i=1x2i−¯x2 Datenlage B s2=1n⋅m∑i=1hi⋅x2i−¯x2 bzw. s2=m∑i=1fi⋅x2i−¯x2 bei Verwendung der relativen Häufigkeiten
Datenlage C
Mit xi sind die Klassenmitten für die Berechnung heranzuziehen. s2=1n⋅k∑i=1hi⋅x2i−¯x2 bzw. s2=k∑i=1fi⋅x2i−¯x2 bei Verwendung der relativen Häufigkeiten
4.7 Standardabweichung
Die mit s bezeichnete Standardabweichung ist die positive Quadratwurzel der mittleren quadratischen Abweichung. s=+√s2
Im Hinblick auf die Interpretation der Streuung bietet die Standardabweichung gegenüber der mittleren quadratischen Abweichung folgende Vorteile:
s ist eher als eine Art Durchschnittsabweichung zum arithmetischen Mittel zu verstehen und somit einfacher zu interpretieren als die quadratische Form mit s2. Jedoch ist anzumerken, dass s keineswegs 1n⋅∑ni=1(xi−¯x) entspricht, wobei n∑i=1(xi−¯x)=n∑i=1xi−n⋅¯x⏟1n∑ni=1xi=0
s besitzt dieselbe Dimension wie das Merkmal. Für das Merkmal Einkommen ist s beispielsweise in der Einheit € anzugeben. s2 ist hingegen in der schlechter interpretierbaren Einheit €2 anzugeben.
4.8 Variationskoeffizient
Allein aus s2 bzw. s lässt sich nicht folgern, ob die Streuung für den vorliegenden Datensatz groß ausfällt.
Eine Standardabweichung von s=60 Cent zeigt für Joghurtpreise einer bestimmten Sorte sicherlich schon eine starke Streuung an. Jedoch wäre dieselbe Standardabweichung für die Preise eines bestimmten Smartphones als Beleg für eine geringe Preisvariation anzusehen. Die Standardabweichung ist also in Relation zum Größenniveau der Beobachtungswerte zu betrachten.
Der Variationskoeffizient v setzt die Standardabweichung ins Verhältnis zum arithmetischen Mittel und wird in Prozent angegeben. v kann ab Verhältnisskalenniveau sinnvoll bestimmt werden, falls alle Merkmalsausprägungen größer oder gleich Null sind.
v=s¯x⋅100 (in %)
Nach der Daumenregel fällt die Streuung groß aus für v>100%.
Im folgenden Video wir der Variationskoeffizient für das Beispiel aus Abbildung 4.2 bestimmt.