Kapitel 3 Quantile und Mittelwerte
3.1 Quantile
Um eine persönliche Leistung einordnen zu können, geht man meistens auf die Suche nach einem Quantil, selbst ohne den Begriff Quantil jemals gehört zu haben. So stellt sich oft die Frage, gehöre ich mit meiner Leistung zu den besseren 50% oder vielleicht sogar zu den besten 10%? Dafür ist zunächst zu klären, welcher Wert in die entsprechenden zwei Hälften über und unter diesem Wert trennt, so dass ich meine Leistung einordnen kann.
Quantile können folglich erst ab Ordinalskalenniveau bestimmt werden.
Mit der Vorgabe eines bestimmten Prozentsatzes, welcher in Form von p als Dezimalwert angegeben wird, mit 0<p<1, wird festgelegt, wie groß der Anteil an der Gesamtzahl der Beobachtungen höchstens ist, welcher unter den gesuchten Wert ˜xp fällt. Zugleich dürfen im Anteil höchstens 1−p der Beobachtungen über ˜xp liegen.
Ob ich mit der erreichten Punktzahl in meiner Klausur nun zu den besten 10% gehöre, erkenne ich daran, ob meine Punktzahl oberhalb von ˜x0,9 liegt. Im folgenden Beispiel finden sich die Punktzahlen von 10 Studierenden für eine Statistik-Klausur, in der höchstens 20 Punkte erzielt werden konnten.

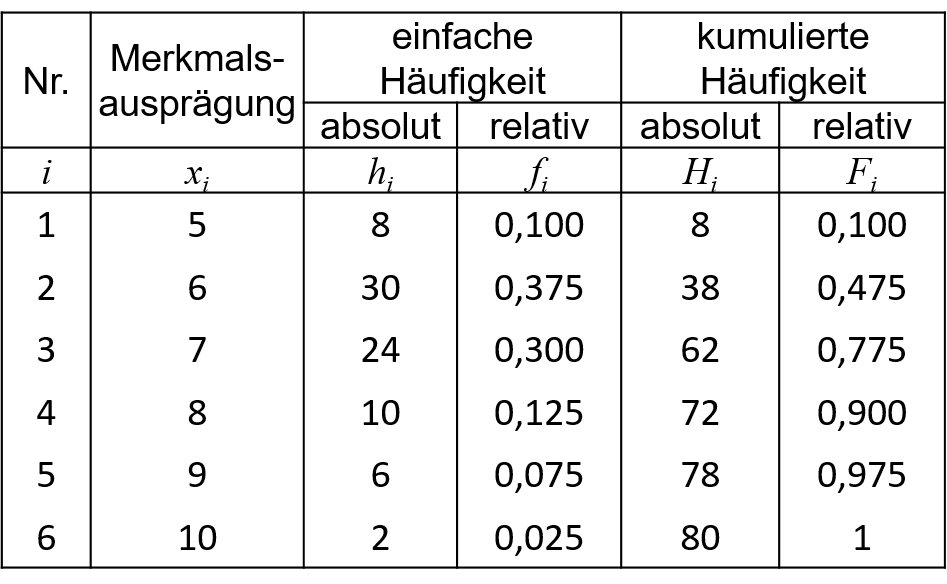
3.1: Datenlage A, Punktzahl in Klausur
Gesucht wird also jener Wert, für den gilt, dass höchstens 90% der Beobachtungen darunter liegen und 10% der Beobachtungen darüber liegen.
Betrachten wir den Beobachtungswert 17, so ist festzuhalten, dass 80% der Beobachtungen unter diesem Wert liegen und 10% über diesem Wert liegen. Zwar erfüllt der Beobachtungswert 17 die Definition des 0,9-Quantils, jedoch wird die Definition ebenfalls vom Beobachtungswert 19 erfüllt, denn 90% der Beobachtungen liegen unter diesem Wert und 0% darüber. Gelöst wird das Problem, indem das arithmetische Mittel aus den beiden Beobachtungen gewählt wird, also ˜x0,9=17+192=18. Für 11 Beobachtungen würde sich hingegen unmittelbar ein eindeutiges 0,9-Quantil finden lassen.
Für die Datenlage A ist somit wie folgt vorzugehen:
3.1.1 Datenlage A
Es wird mit p das gesuchte Quantil festgelegt.
Es wird n⋅p bestimmt und geschaut, ob das Produkt ganzzahlig ist.
Es folgt:
˜xp={x([n⋅p+1])falls n⋅p nicht ganzzahlig12(x(n⋅p)+x(n⋅p+1))falls n⋅p ganzzahlig
Dabei bedeutet die eckige Klammer, dass der Wert auf die nächste ganze Zahl abzurunden ist.
Mit der runden Klammer wird die Position in der geordneten Urliste angegeben.
Für p=0,9 gilt also im Beispiel n⋅p=10⋅0,9=9. Da es sich um einen ganzzahligen Wert handelt, gilt weiter ˜x0,9=12(x(9)+x(10))=12(17+19)=18
Für p=0,75 gilt dann im Beispiel n⋅p=10⋅0,75=7,5.
Da es sich hier um einen nicht ganzzahligen Wert handelt, gilt weiter
˜x0,75=x([7,5+1])=x(8)=14
3.1.2 Datenlage B
Bei Vorliegen einer Datenlage B kann zur Bestimmung der Quantile auf die kumulierten relativen Häufigkeiten abgestellt werden. Es gilt dann
˜xp={xifür Fi−1<p<Fi12(xi+xi+1)für p=Fi
Falls also p mit einem Fi übereinstimmt, erfüllen zwei unterschiedliche Merkmalsausprägungen die Definition des p-Quantils und es wird wiederum das arithmetische Mittel der beiden Merkmalsausprägungen ausgewählt.
Betrachtet wird in Tabelle 3.2 noch einmal das Beispiel aus Kapitel 2.
Es sollen das 0,5 Quantil und das 0,9 Quantil bestimmt werden.
3.2: Datenlage B, Fachsemester
Zur Bestimmung des 0,5 Quantils (auch Median genannt):
F2<0,5<F3 →˜x0,5=7 Die 0,5 wird mit F3=0,775 erstmalig überschritten. Somit liegt das 0,5-Quantil bei der dritten Ausprägung, also ˜x0,5=x3=7.
Zur Bestimmung des 0,9 Quantils:
0,9=F4 →˜x0,9=12(8+9)=8,5 Da die 0,9 mit der kumulierten relativen Häufigkeit F4 genau übereinstimmt, erfüllen die Werte x4 und x5 die Definition des 0,9-Quantils. Es liegen also höchsten 90% der Beobachtungen unter diesen beiden Werten und höchstens 10% der Beobachtungen über diesen Werten. Somit wird das arithmetische Mittel aus x4 und x5 bestimmt.
Die ausschlaggebende Information zur Bestimmung der Quantile steckt in den kumulierten relativen Häufigkeiten Fi und somit in der Verteilungsfunktion. Abbildung 3.3 zeigt, wie sich die Quantile aus der bildlichen Darstellung der Verteilungsfunktion ablesen lassen.
Wenn p also mit einer der kumulierten relativen Häufigkeiten Fi übereinstimmt und somit p in der Grafik genau auf der Höhe einer der “Treppenstufen” liegt, erfüllen die beiden Werte am Stufenanfang und am Stufenende die Definition, so dass als Quantil das arithmetische Mittel der beiden Werte zu verwenden ist.
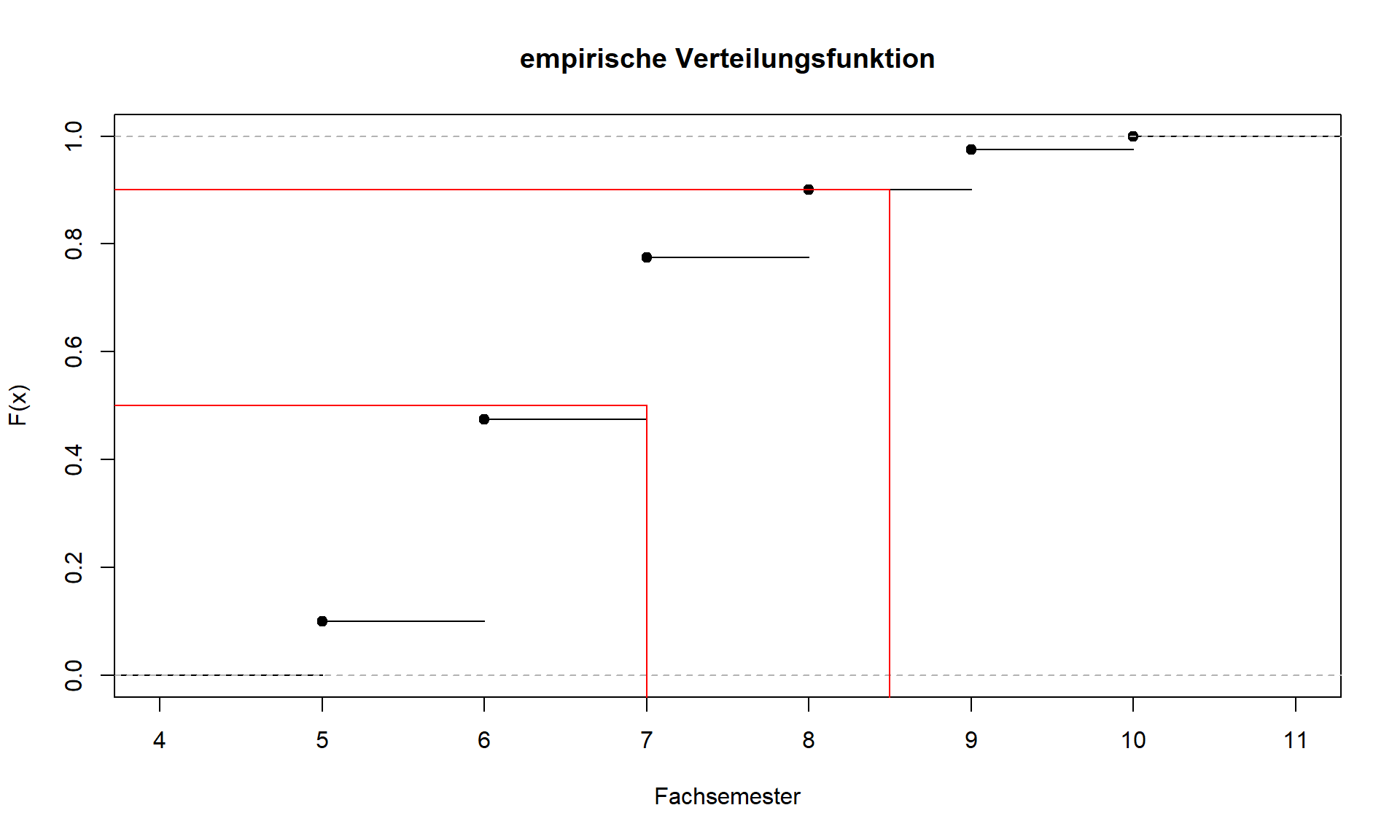
3.3: Verteilungsfunktion Merkmal Fachsemester
3.1.3 Datenlage C
Für gruppierte Daten (Datenlage C) erhält man die Quantile aus der approximierenden empirischen Verteilungsfunktion ˆF(x). Abbildung 3.5 zeigt, dass es zu jedem p, mit 0<p<1, einen eindeutigen Wert x gibt, für den gilt: p=ˆF(x). Rot gekennzeichnet sind die Koordinaten zum 0,5-Quantil, also zum Median.
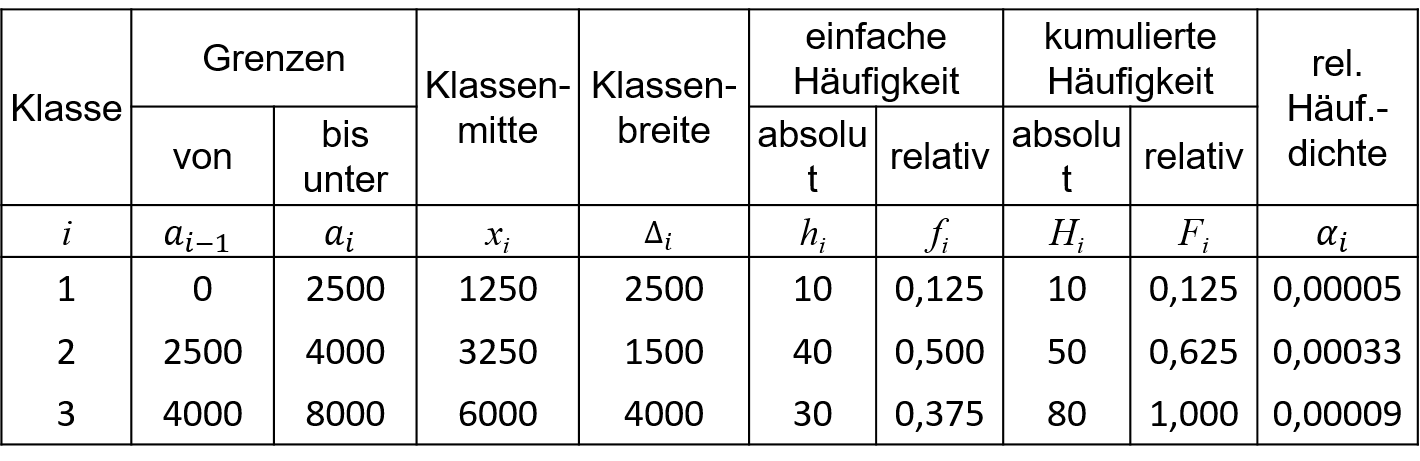
3.4: Datenlage C, monatl. Einkommen in Tsd. €
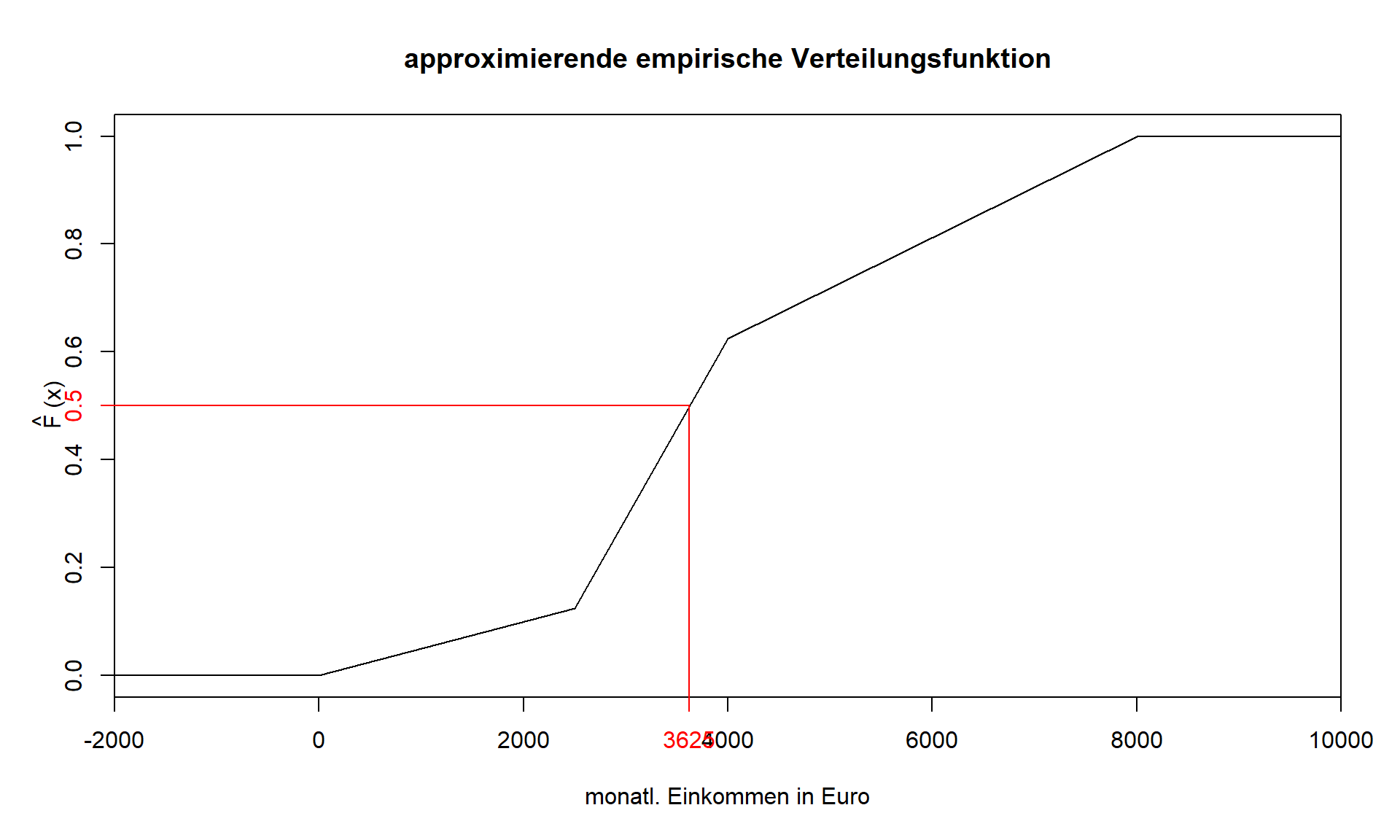
3.5: appr. emp. Verteilungsfunktion an der Stelle x=3000
Zur rechnerischen Ermittlung der Quantile ist es erforderlich, zunächst den relevanten Teil der Verteilungsfunktion zu bestimmen. Dazu wird geschaut, in welche Klasse das gesuchte Quantil fällt. Entscheidend ist also, der Vergleich von p mit den kumulierten relativen Häufigkeiten. Das Quantil fällt in die Klasse, on der p erstmalig kleiner oder gleich der kumulierten relativen Häufigkeit ist oder formal ausgedrückt: Fi−1<p≤Fi→˜xp∈[ai−1,ai) Wenn ich also zu den Klassengrenzen aus den kumulierten relativen Häufigkeiten weiß, dass 62,5% der Studierenden Einkommen bis 4000€ haben und 12,5% der Studierenden Einkommen bis 2500€ haben, dann muss mein 0,5-Quantil irgendwo dazwischen liegen. Um ein eindeutiges Ergebnis angeben zu können, betrachtet man die approximierende empirische Verteilungsfunktion für die betreffende Einkommensklasse, die in dem Beispiel für die Klasse i=2 wie folgt lautet: ˆF(x)=F1+f2Δ2(x−a1) für a1≤x<a2 Nun legt man p!=ˆF(x) fest und löst die Gleichung nach x auf. x⏟≈˜xp=a1+p⏞F(x)−F1f2Δ2 Das ≈ Zeichen wird verwendet, da es sich um eine Näherungslösung handelt, welche unter der Annahme der Gleichverteilung innerhalb der Klassen zustande kommt. Nachdem die Klasse i des gesuchten Quantils ermittelt wurde, gilt dann allgemein: ˜xp≈ai−1+p−Fi−1fiΔibzw.˜xp≈ai−1+p−Fi−1Fi−Fi−1(ai−ai−1)
Zur Bestimmung des 0,5-Quantils wurde festgehalten, dass dieses wegen F1=0,125<0,5<F2=0,625 in Klasse 2 fällt.
Die Feinberechnung erfolgt dann mit
˜xp≈2500+0,5−0,1250,51500=3625
3.1.4 spezielle Quantile
Besonders häufig gilt das Interesse den drei Quartilen, welche wichtige Kennzahlen zur Charakterisierung der Verteilung darstellen.
- (unteres) Quartil = 0,25-Quantil
- (mittleres) Quartil = 0,5-Quantil (Median)
- (oberes) Quartil = 0,75-Quantil
Darüber hinaus existieren noch die sogenannten Dezile. Wie der Name schon vorgibt, sind dies die 10%-,20%-… Quantile.
3.2 Mittelwerte
Mittelwerte haben zum Ziel, durch Angabe eines einzelnen, typischen Wertes für ein Merkmal, die Grundgesamtheit (statistische Masse) möglichst gut zu repräsentieren. Je nach Mittelwert werden dabei unterschiedliche Ansätze verfolgt. Dabei ist zwischen lagetypischen und rechnerischen Mittelwerten zu unterscheiden.
3.2.1 lagetypische Mittelwerte
Kennzeichnend für die lagetypischen Mittelwerte ist, dass diese über die Häufigkeitsinformationen zu den einzelnen Merkmalsausprägungen identifiziert werden können. Für diese Mittelwerte ist eine bestimmte Position (Lage) entscheidend. Die lagetypischen Mittelwerte sind sehr robust gegenüber Ausreißern in den Daten.
3.2.1.1 Modus
Als Modus wird jener Beobachtungswert bezeichnet, welcher im Datensatz am häufigsten auftritt. Insofern geht mit dem Modus eine gewisse Vorstellung von “Normalität” oder “Üblichkeit” einher. In manchen Alltagssituation, in denen man eine Auswahl hat, orientiert man sich am Modus, ohne dabei explizit an Mittelwerte zu denken. Ich bin unentschlossen und schaue mal, wofür sich die meisten anderen so entscheiden. Ich richte dann also meine Entscheidung am Modus aus.
Der Modus kann bereits ab Nominalskalenniveau und somit für jedes Skalenniveau bestimmt werden.
Datenlage A
Aus der Urliste kann der Modus nicht direkt abgelesen werden. Notwendig ist es, zu jeder Merkmalsausprägung die einfache absolute oder relative Häufigkeiten anzugeben und somit erfolgt eine Transformation der Datenlage A in die Datenlage B.
Datenlage B
Hier kann der Modus leicht über die einfachen Häufigkeiten abgelesen werden.
Modus:=Merkmalsausprägung mit der größten absoluten oder relativen Häufigkeit
Im Beispiel aus Tabelle 3.2 liegt der Modus also bei x2=6 Fachsemestern, da maxi(hi)=h2=30. Anstelle auf die absoluten Häufigkeiten hi, hätte man natürlich auch auf die relativen Häufigkeiten fi schauen können.
Datenlage C
Da bei gruppierten Daten die einzelnen Beobachtungswerte unbekannt sind, lässt sich der Modus nicht einfach über die relativen Häufigkeiten angeben. Für stetige Merkmale, bei denen alle Beobachtungswerte voneinander verschieden sind, kann ohnehin kein Modus aus den Beobachtungswerten abgeleitet werden, da jeder Wert ja nur genau einmal vertreten ist. Als Modus wird dann auf Basis der Datenlage C der Wert mit der größten Häufigkeitsdichte bestimmt. Wie aus dem Histogramm gut zu erkennen ist, verteilt sich die Häufigkeitsmasse in Form der Rechteckflächen über alle Klassen. Als Modus ist nun jener Wert mit der größten Häufigkeitsdichte zu bestimmen. In Abbildung 3.6 wird noch einmal das Histogramm zum Zahlenbeispiel aus Tabelle 3.4 betrachtet. Die modale Klasse ist also die Klasse 2 mit der größten Häufigkeitsdichte. Nun wird aber aufgrund der Gleichverteilungsannahme innerhalb der Klassen für alle Werte von 2500 bis 4000 dieselbe Häufigkeitsdichte angenommen, was durch das Histogramm anschaulich wiedergegeben wird. In vielen Fällen gibt man sich mit der Angabe der modalen Klasse zufrieden oder wählt stellvertretend die Klassenmitte aus, um einen Wert als Modus angeben zu können. Mit der Auswahl der Klassenmitte geht dann eigentlich die Annahme einher, dass sich dort die größte Häufigkeitsdichte innerhalb der modalen Klasse befindet.
Im Beispiel aus Tabelle 3.4 liegt der Modus also bei x2=12(2500+4000)=3250 Euro, da maxi(αi)=α2=0,00033.
Es existieren noch weitere Verfahren zur Abschätzung des Modus, welche noch zusätzliche Informationen aus den Nachbarklassen mit berücksichtigen, aber hier nicht weiter thematisiert werden sollen.
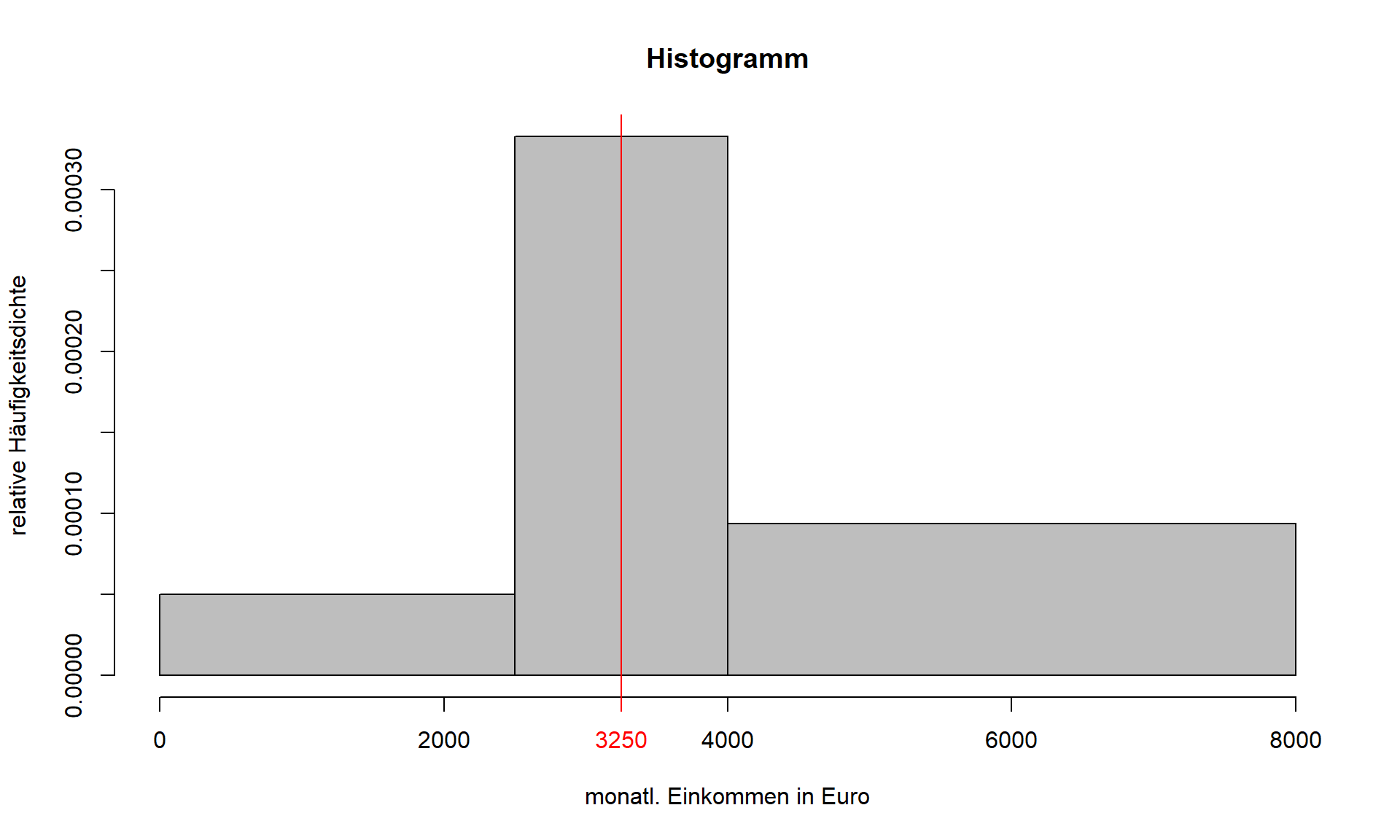
3.6: Histogramm mit Klassenmitte als Modus
3.2.1.2 Median
Als Median wird das 0,5-Quantil bezeichnet. Der Median ist also jener Wert, der die Verteilung in zwei gleich große Hälften teilt.
Bezogen auf die geordnete Urliste gibt der Median also die mittlere Position an. Der Median kann somit bereits ab Ordinalskalenniveau bestimmt werden. Gerade wenn die zentrale Tendenz einer Verteilung im Interesse steht, so kann diese gut durch den Median beschrieben werden, ohne dass es zu Verzerrungen durch starke Ausreißer an den Rändern der Verteilung kommen kann.
So ist der Median eine Kennzahl, die beispielsweise bei der Betrachtung der Merkmale “Einkommen” oder “Studiendauer in Fachsemestern” häufig dem ausreißerempfindlichen arithmetischen Mittel vorgezogen wird.
Zur genauen Bestimmung des Medians (0,5-Quantil) sei auf Kapitel 3.1 verwiesen.
3.2.2 rechnerische Mittelwerte
In die rechnerischen Mittelwerte fließen alle Merkmalsausprägungen ein, für die Beobachtungswerte vorliegen. Es werden somit mehr Informationen aus den Daten berücksichtigt, als dies bei den lagetypischen Mittelwerten der Fall ist. Dies macht sie jedoch auch anfälliger gegenüber Ausreißern. Die rechnerischen Mittelwerte werden auch als Durchschnittswerte bezeichnet.
Die Schreibweise ¯x macht deutlich, dass es sich um einen rechnerischen Mittelwert über die Beobachtungen handelt, welcher im Hinblick auf die vorliegende Problemstellung geeignet ist.
Erläuterungen zum Umgang mit dem Summenzeichen im folgenden Videoclip
3.2.2.1 arithmetisches Mittel
Das arithmetische Mittel ist der wohl bekannteste Mittelwert und setzt die Merkmalssumme der Grundgesamtheit ins Verhältnis zur Anzahl der Merkmalsträger n der Grundgesamtheit. AM=Merkmalssummen Das arithmetische Mittel kann ab Intervallskalenniveau bestimmt werden und wird für die drei Datenlagen wie folgt berechnet:
Datenlage A
Das ungewichtete arithmetische Mittel lautet: AM=1nn∑i=1xi
Für das Beispiel aus Tabelle 3.1 gilt dann:
¯x=110(5+7+...+19)=11,5
Datenlage B
Das gewichtete arithmetische Mittel lautet: GAM=1nm∑i=1xi⋅hi alternativ mit relativen Gewichten: GAM=m∑i=1xi⋅fi
Für das Beispiel aus Tabelle 3.2 kann das arithmetische Mittel wie folgt berechnet werden:
¯x=180(5⋅8+6⋅30+...+10⋅2)=6,775
Datenlage C
Unter der Annahme der Gleichverteilung innerhalb der Klassen entsprechen die mit xi bezeichneten Klassenmitten den jeweiligen Klassendurchschnittswerten. Somit entspricht dann xi⋅hi der Merkmalssumme für die Klasse i. Folglich ist ∑ki=1xi⋅hi die Merkmalssumme über alle k Klassen und somit über alle n Beobachtungen. Das arithmetische Mittel für die Datenlage C wird dann wie folgt berechnet:
mit den absoluten Häufigkeiten: GAM=1nk∑i=1xi⋅hi mit den relative Häufigkeiten GAM=k∑i=1xi⋅fi
Für das Beispiel aus Tabelle 3.4 kann das arithmetische Mittel wie folgt berechnet werden: ¯x=180(1250⋅10+3250⋅40+6000⋅30)=4031,25
Eigenschaften des arithmetischen Mittels
Als Ersatzwerteigenschaft bezeichnet man die Tatsache, dass sich die Merkmalssumme ganz einfach bestimmen lässt, wenn ¯x bekannt ist. ¯x⋅n=n∑i=1xi
Als Linearität bezeichnet man die Eigenschaft ¯y=a+b¯x für yi=a+bxi a,b∈R Das heißt, dass es für lineare Transformationen der Form yi=a+bxi nicht notwendig ist, alle Beobachtungen zu transformieren, wenn das Interesse ¯y gilt, sondern es kann ¯x direkt transformiert werden.
Von der Minimaleigenschaft des arithmetischen Mittels wird gesprochen, da mit y=¯x die folgende Funktion f(y) minimiert wird: f(y)=n∑i=1(xi−y)2 Anmerkung: f′(y)=2(∑ni=1xi−ny)!=0→y=1n∑ni=1xi und f″(y)=−2<0→Minimum
Das arithmetische Mittel ist im Gegensatz zum Modus und Median anfällig gegenüber Ausreißern. Dies wird im folgenden Beispiel demonstriert.
3.2.2.2 harmonisches Mittel
Das harmonische Mittel setzt Verhältnisskalenniveau voraus und kommt in bestimmten Fällen bei der Mittelung von Verhältniszahlen zur Anwendung.
Eine Verhältniszahl entspricht dem Quotienten zweier Größen. Verhältniszahlen sind z.B. der Benzinpreis in € pro Liter oder der Anteil weiblicher Studierender an der Gesamtzahl der Studierenden.
Grundsätzlich wird bei der Mittelung von Verhältniszahlen das Ziel verfolgt, über die Grundgesamtheit das Verhältnis aus Zählersumme und Nennersumme zu bestimmen. Das folgende Beispiel soll dies verdeutlichen:
Ein Student betankt seinen Wagen immer für 20€. Beim ersten mal Tanken bezahlt er 1,25€/l und eine Woche später bezahlt er 1,55€/l. Welchen Preis hat er im Durchschnitt über beide Tankvorgänge bezahlt?
Das harmonische Mittel lautet für die entsprechenden Datenlagen
Datenlage A
Das ungewichtete harmonische Mittel lautet:
HM=n∑ni=11xi
Datenlage B
Das gewichtete harmonische Mittel lautet:
GHM=n∑mi=1hixi
alternative Berechnung mit relativen Gewichten:
GHM=1∑mi=1fixi
Datenlage C
Die Berechnung erfolgt, wie bei der Datenlage B, unter Verwendung der Klassenmitten xi=ai−1+ai2. Das harmonische Mittel kommt für die Datenlage C aber eher selten zur Anwendung.
arithmetische Mittel vs. harmonische Mittel
Im nachfolgenden Video wird deutlich, wann welches Mittel für die Mittelung von Verhältniszahlen zur Anwendung kommt.
3.2.2.3 geometrisches Mittel
Das geometrische Mittel kommt bei zeitlich aufeinanderfolgenden Wachstumsprozessen für die Mittelung der Wachstumsfaktoren zur Anwendung und setzt Verhältnisskalenniveau voraus. Voraussetzung für eine sinnvolle Anwendung ist, dass der durch das Wachstum hinzugewonnene Teil in der Folge ebenfalls mitwächst, so wie dies etwa von Zinseszinsen bekannt ist. Die Ausgangsgröße muss nicht zwingend kontinuierlich über den Betrachtungszeitraum wachsen, sondern kann auch schrumpfen.
Datenlage A
GM=(n∏i=1xi)1n=n√x1⋅x2⋅...⋅xn mit den Wachstumsfaktoren xi.
Beispiel:
Angenommen ein Wertpapier wird über einen Zeitraum von drei Jahren gehalten und erzielt in den ersten beiden Jahren eine Rendite von 2% und im dritten Jahr eine Rendite von 3%, so wird die jahresdurchschnittliche Rendite auf Basis der Wachstumsfaktoren ermittelt. Für die Jahre eins und zwei liegen die Wachstumsfaktoren demnach bei 1,02 und für das dritte Jahr liegt der Wachstumsfaktor bei 1,03.
Es ist dann zunächst der Gesamtwachstumsfaktor zu ermitteln, mit 1,02⋅1,02⋅1,03. Der jahresdurchschnittliche Wachstumsfaktor entspricht dann
3√1,02⋅1,02⋅1,03=1,0233
Die jahresdurchschnittliche Rendite liegt demnach bei 2,33%.
Datenlage B
GGM=(m∏i=1xhii)1n mit den Wachstumsfaktoren xi.
Fortsetzung Beispiel:
Da der Wachstumsfaktor 1,02 zweimal auftritt und der Wachstumsfaktor 1,03 einmal, hätte man unter Berücksichtigung der Häufigkeiten auch notieren können:
2+1√1,022⋅1,031=1,0233
Datenlage C
Die Berechnung erfolgt, wie bei der Datenlage B, unter Verwendung der Klassenmitten xi=ai−1+ai2. Das geometrische Mittel kommt für die Datenlage C aber eher selten zur Anwendung.
Beziehung zum arithmetischen Mittel
Der Logarithmus von GM bzw. GGM entspricht dem AM bzw. GAM der logarithmierten Werte.
log(GM)=1nn∑i=1log(xi) bzw. log(GGM)=1nm∑i=1hi⋅log(xi) Dieser Zusammenhang ist für die formale Darstellung von ökonomischen Modellen von Bedeutung, da sich so auch multiplikative Zusammenhänge durch lineare Modelle abbilden lassen, was in vielen Fällen vorteilhaft ist.
3.2.3 allgemeine Aussagen
Sofern keine Variation in den Beobachtungswerten vorhanden ist, also für jeden Merkamlsträger der gleiche Beobachtungswert vorliegt, also xi=c ∀ i∈ {1,...,n}, gilt:
Modus=Median=AM=HM=GM
Aus den Mittelwerten Modus, Median und arithmetische Mittel lassen sich zudem Aussagen über den Typ der Häufigkeitsverteilung ableiten. Die Lageregeln von Fechner besagen für:
Modus<Median<AM→linkssteile Verteilung
Modus>Median>AM→rechtssteile Verteilung
Modus=Median=AM→symmetrische Verteilung
In der praktischen Beurteilung spricht man auch von einer symmetrischen Verteilung, wenn die drei Mittelwerte sehr nahe beieinander liegen: Modus≈Median≈AM→symmetrische Verteilung
Abbildung 3.7 zeigt die linkssteile Verteilung der monatlichen Haushaltsnettoeinkommen in Deutschland für das Jahr 2013.
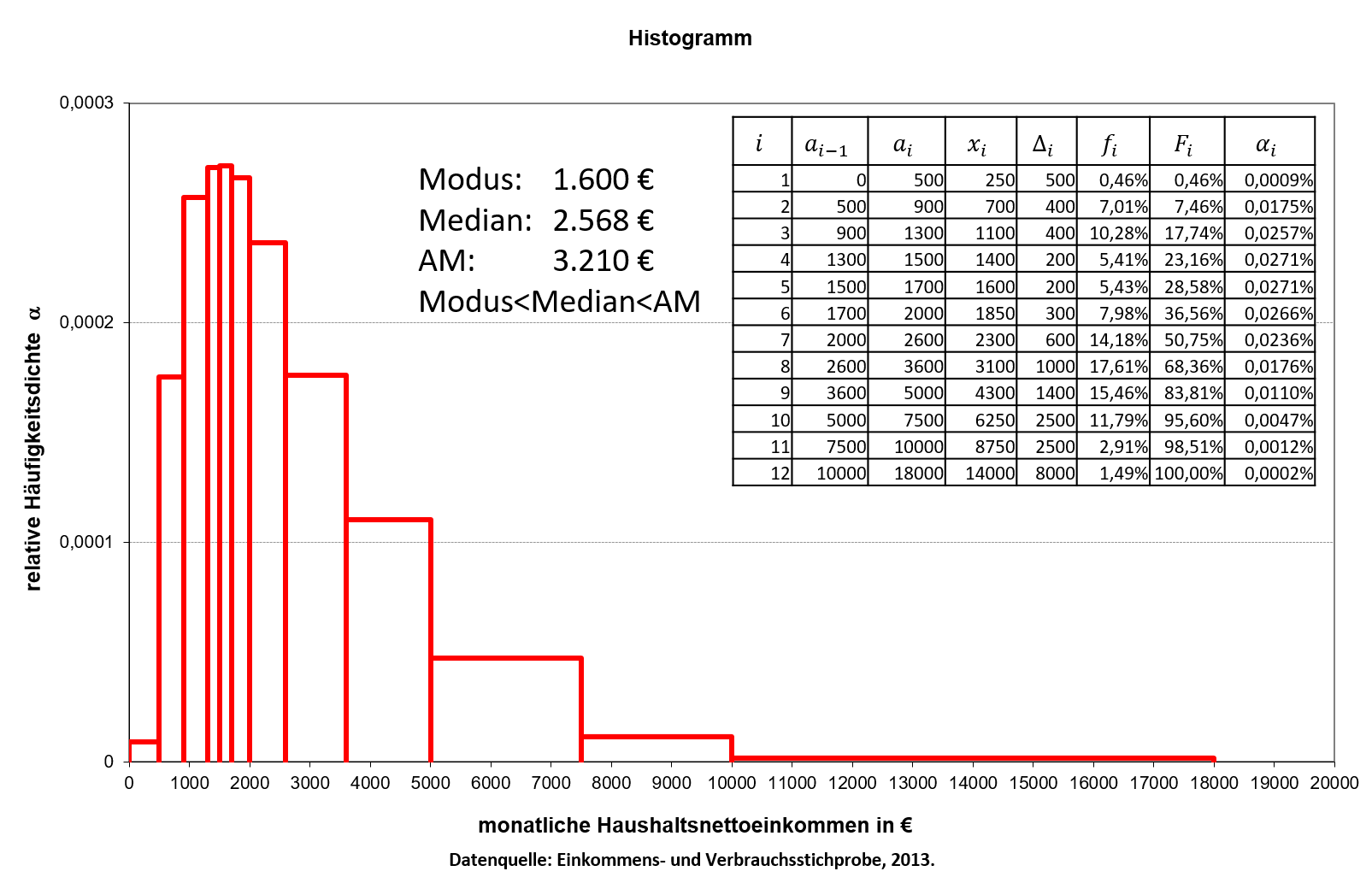
3.7: linkssteile Verteilung
Im folgenden Video werden Modus, Median und arithmetisches Mittel bezugnehmend auf die Datenlage C aus Abbildung 3.7 berechnet.