14 Tutorial 14: Validierung automatisierter Analysen
In Tutorial 14, dem letzten Tutorial des Semesters, beschäftigen wir uns mit der Validierung automatisierter Analysen.
Sie haben im Seminar bereits gelernt, warum die Validierung automatisierter Analysen wichtig ist: Sie sollten den Ergebnissen automatisierter Inhaltsanalysen nicht blind vertrauen, weil oft unklar ist, inwiefern automatisiert gemessen wird/werden kann, was Sie theoretisch interessiert.
Daher empfehlen Grimmer und Stewart (2013, S. 271): “Validate, Validate, Validate. […] What should be avoided, […] is the blind use of any method without a validation step.”
Stellen Sie sich bei der Auswertung und Interpretation Ihrer Ergebnisse inbesondere folgende Fragen:
- Inwiefern kann und sollte ich theoretische Konstrukte, die für meine Studie von Interesse sind, überhaupt automatisiert messen?
- Wie sehr überlappt die automatisierte Analyse mit einer manuellen Codierung der gleichen Variable(n) - und wo finden sich Unterschiede?
- Wie lassen sich diese Unterschiede erklären, d.h., inwiefern messen manuelle und automatisierte Codierungen ggf. unterschiedliche Dinge und wieso?
Grimmer und Stewart erläutern verschiedene Wege, wie Sie ihre Ergebnisse validieren können. Wir arbeiten hier nur mit einer Variante der Validierung: dem Vergleich mit einem manuellen “Goldstandard”.
Im Prinzip werden bei dieser Form der Validierung die automatisierte und manuelle Codierung der gleichen Variablen für die gleichen Texte verglichen. Oft wird dabei die manuelle Codierung als “Goldstandard” bezeichnet, d.h. es wird impliziert, dass manuelle Analysen in der Lage sind, den “wahren” Wert von Variablen in Texten zu erfassen.
Inwiefern manuelle Codierungen (oder jegliche Form von Codierungen) dazu in der Lage sind, lässt sich natürlich hinterfragen, wie di Maggio (2013, S. 3f.) und Song et al. (2020, S. 553ff.) kritisch zusammenfassen. Z.B. unterscheiden sich manuelle Codierer:innen oft in Ihren Codierungen; zudem lässt sich aus erkenntnistheoretischer Perspektive diskutieren, inwiefern der “wahre” Wert von Variablen überhaupt messbar ist.
Was sich anhand der Validierung durch Vergleich zu einer manuellen Codierung in jedem Fall zeigen lässt, ist, inwiefern sich automatisierte und manuelle Codierung unterscheiden - und wieso dies der Fall sein könnte. Entsprechend können Sie durch eine Validierung in jedem Fall besser verstehen, welche (theoretischen) Konstrukte Sie mit ihrer automatisierten Analyse messen (können).
Wir lernen heute dabei zwei Vorgehensweisen, anhand derer Sie Diktionäranalysen und Themenmodelle validieren können:
- die Validierung mit dem Paket caret, anhand dessen Sie gängige Metriken wie Precision, Recall und den F1-Wert leicht berechnen können.
- die Validierung mit dem Paket oolong, das es v.a. leichter erlaubt, innerhalb von R eine Stichprobe für die manuelle Codierung und zur Validierung zu ziehen und diese zu codieren.
Wir arbeiten wieder mit dem Korpus zu Immigration, den Sie in OLAT (via: Materialien / Datensätze für R) mit dem Namen immigration_news.rda finden.
Quelle der Daten: Nulty, P. & Poletti, M. (2014). “The Immigration Issue in the UK in the 2014 EU Elections: Text Mining the Public Debate.” Presentation at LSE Text Mining Conference 2014. Geladen via dem Quanteda-Corpus_Package.
Bitte laden Sie den Datensatz in Ihr R-Environment.
14.1 Validierung mit dem Paket caret
Wir starten mit der Validierung auf Basis des caret-Paketes.
14.1.1 Validierung mit caret: Diktionäranalyse
Nehmen wir an, Sie hätten mit R automatisiert die Negativität von Texten codiert. Wir verwenden hier jetzt beispielsweise einen sehr simplen (und vermutlich nicht besonders validen) Ansatz:
Beispielsweise haben Sie bereits geschaut, wie viel % der Features aus dem Immigration_News-Korpus negativ bzw. positiv sind. Dann haben Sie alle Artikel automatisiert als negativ klassifiziert, in denen relativ gesehen mehr negative als positive Features vorkommen:
#Erfassung negativer und positiver Features
#mittels des Off-the-Shelf-Diktionärs "Lexicoder Sentiment Dictionary":
library("quanteda")
automated <- dfm(data$text) %>%
dfm_weight("prop") %>%
dfm(dictionary = data_dictionary_LSD2015[1:2]) %>%
convert(to="data.frame")
#Wie sehen die ersten 5 Fälle dieses Dataframes aus?
automated[1:5,]## doc_id negative positive
## 1 text1 0.048997773 0.03118040
## 2 text2 0.050724638 0.01449275
## 3 text3 0.050387597 0.01937984
## 4 text4 0.005882353 0.04705882
## 5 text5 0.077083333 0.02708333#Wir berechnen die rel. Differenz zwischen positiven und negativen Features
automated$relative <- automated$positive-automated$negative
#Wie sehen die ersten 5 Fälle dieses Dataframes jetzt aus?
automated[1:5,]## doc_id negative positive relative
## 1 text1 0.048997773 0.03118040 -0.01781737
## 2 text2 0.050724638 0.01449275 -0.03623188
## 3 text3 0.050387597 0.01937984 -0.03100775
## 4 text4 0.005882353 0.04705882 0.04117647
## 5 text5 0.077083333 0.02708333 -0.05000000#Wir klassifizieren Texte mit mehr negativen als positiven Features als negativ
automated$negativity[automated$relative<0] <- 1
#Wir klassifizieren Texte mit mehr/gleich viel positiven als negativen Features als positiv
automated$negativity[automated$relative>=0] <- 0
#Wie viele Texte mit negativem Sentiment erhalten wir?
table(automated$negativity)##
## 0 1
## 1402 1431Jetzt haben Sie jeden Text also dichotom klassifiziert:
- entweder als Text mit negativem Sentiment (1)
- oder als Text ohne positives Sentiment (0).
Nun wollen Sie als nächstes schauen, inwiefern die automatisierte Messung von Negativität mit einer manuellen Codierung, d.h. einem manuellen “Goldstandard”, übereinstimmt.
Sie ziehen dazu als erstes eine zufällige Stichprobe aus Ihrem Korpus, die manuell validiert werden soll.
Song et al. (2020, S. 564) empfehlen, für die Validierung automatisierter Inhaltsanalysen möglichst mehr als 1.300 Artikel manuell zur Erstellung eines “Goldstandards” zu codieren. Dabei sollte die manuelle Codierung von mehr als eine/r Codierer:in durchgeführt werden und die Intercoderreliabilität mindestens .7 betragen - im Rahmen dieses Seminars ist das natürlich nicht möglich.
Für dieses Seminar beschränken wir uns aus praktischen Gründen auf eine kleinere Stichprobe, hier als Beispiel 30 Artikel, und die Codierung durch eine Codierer:in.
Zunächst ziehen wir eine zufällige Stichprobe für die manuelle Validierung. Mit der Funktion sample können Sie dabei z.B. aus allen Texten des Korpus, hier den Zeilen des Dataframes data, 30 Texte zufällig auswählen.
Wir erstellen jetzt einen Datafrane mit dem Namen validation_set, der als Grundlage für die manuelle Validierung dient.
Er enthält 30 zufällig ausgewählte Texte aus unserem Korpus, inklusive der folgenden Informationen:
- Die Variable “ID” enthält die ID der manuell zu codierenden Texte.
- Die Variable “Text” enthält die zu manuell codierenden Texte.
- Die Variable “Manual Coding” enthält leere Zellen, in die wir unsere Codierung eintragen können.
validation_set <- data.frame("ID" = data$doc_id[rows],
"text" = data$text[rows],
"manual_coding" = rep(NA,30))Dann speichern wir den Dataframe als CSV-File ausserhalb von R in umserem Working Directory ab.
Sie würden als nächstes ausserhalb von R Ihre Validierung vornehmen. D.h., Sie lesen jeden Text und tragen dann in der jeweiligen Zeile der Spalte manual_coding Ihre manuelle Codierung ein:
- eine 1, wenn der Text “Negativität” enthält (1 = “Negativität kommt vor”)
- eine 0, wenn der Text keine “Negativität” enthält (0 = “Negativität kommt nicht vor”)
Dabei sollten Sie sich wie bei jeder manuellen Inhaltsanalyse an ein klares Codebuch mit Codieranweisungen halten.
Bitte lesen Sie diesen manuellen “Goldstandard”, den ich - sehr grob - beispielhaft codiert habe, nun ein. Sie finden das ausgefüllte Excel_File in OLAT (via: Materialien / Datensätze für R) mit dem Namen validation_dictionary_example.csv.
Nun fügen wir die automatisierte und die manuelle Analyse der gleichen Texte über die ID der jeweiligen Texte in einem Dataframe mit dem Namen confusion zusammen. Dafür nutzen wir den merge-Befehl.
Wieso das Objekt confusion heisst, werden Sie gleich verstehen.
confusion <- merge(automated[,c("doc_id", "negativity")],
validation_set[,c("ID", "manual_coding")],
by.x="doc_id", by.y="ID")
colnames(confusion) <- c("ID", "automated", "manual")Schauen wir uns das Ergebnis einmal an:
Output: Negativität laut automatisierter/manueller Analyse
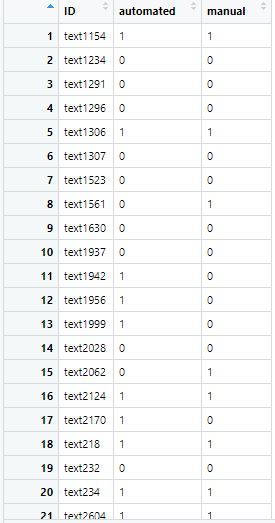
Sie sehen neben der ID des jeweiligen Textes die Klassifikation des Textes auf Basis der automatisierten Codierung, hier in der Spalte automated, und der manuellen Codierung, hier in der Spalte manual.
Hier wird schon klar: Automatisierte und manuelle Codierung stimmen teilweise überein - aber nicht immer.
Wie können wir nun einen Kennwert erhalten, der uns angibt, wie stark die manuelle und die automatisierte Inhaltsanalyse übereinstimmen?
Um dies zu beurteilen, greifen wir auf Precision, Recall und den F1-Wert als gängige Kennwerte zurück, die Sie im Seminar bereits kennengelernt haben und die in vielen Studien - siehe etwa Nelson et al. (2018) - genutzt werden, um automatisierte und manuelle Codierungen zu vergleichen.
Precision:
Der Kennwert Precision gibt Ihnen an, wie gut Ihre automatisierte Analyse darin ist, nur Artikel als “negativ” zu klassifizieren, die laut manuellem Goldstandard tatsächlich Negativität enthalten.
\(Precision = \frac{True Positives}{True Positives + False Positives}\)
Dieser Kennwert reicht von minimal 0 bis maximal 1 und sagt folgendes aus: Wie gut ist Ihre Methode darin, nicht zu viele Artikel fälschlicherweise (im Vgl. zum manuellen Goldstandard) als “negativ” zu klassifizieren, d.h. “False Positives” zu erzeugen? Je näher der Wert bei 1 liegt, desto besser Ihre Analyse.
Recall:
Der Kennwert Recall gibt Ihnen an, wie gut Ihre automatisierte Analyse darin ist, alle Artikel, die laut manuellem Goldstandard tatsächlich negatives Sentiment enthalten, als negativ zu klassifizieren.
\(Recall = \frac{True Positives}{True Positives + False Negatives}\)
Dieser Kennwert reicht ebenfalls von minimal 0 bis maximal 1 und sagt folgendes aus: Wie gut ist Ihre Methode darin, nicht zu viele Artikel fälschlicherweise (im Vgl. zum manuellen Goldstandard) als “nicht negativ” zu klassifizieren, d.h. “False Negatives” zu erzeugen? Je näher der Wert bei 1 liegt, desto besser Ihre Analyse.
F1-Wert:
Der F1-Wert ist der harmonische Mittelwert aus beiden Kennwerten. Er wird meist angegeben, wenn man eine übergreifende Metrik benötigt, die Precision und Recall zugleich einbezieht.
\(F_{1} = 2 * \frac{Precision * Recall}{Precision + Recall}\)
Nachfolgend lassen wir uns Precision, Recall und den F1-Wert ausgeben.
Dafür benötigen wir das Packet caret und nutzen den Befehl confusionMatrix.
Wichtig ist, dass wir dabei
- alle Klassifikationsvariablen im Faktoren-Format vorliegen müssen.
- via data R anweisen müssen, in welchem Objekt die automatisierte Codierung zu finden ist.
- via reference R anweisen müssen, in welchem Objekt der Goldstandard zu finden ist.
- via mode R anweisen müssen, dass wir Kennwerte wie Precision, Recall etc. erhalten wollen.
- via positive R anweisen müssen, welcher Wert das Vorkommen der Variable bezeichnet, d.h. hier, dass die Ausprägung “Negativität kommt in diesem Text vor” im Goldstandard mit einer 1 codiert wurde.
#automatisierte und manuelle Klassifikationswerte müssen als Faktoren vorliegen
confusion$automated <- as.factor(confusion$automated)
confusion$manual <- as.factor(confusion$manual)
#calculate confusion matrix
library("caret")
result <- confusionMatrix(data = confusion$automated,
reference=confusion$manual,
mode = "prec_recall",
positive = "1")Am einfachsten zu interpretieren ist dabei die Konfusions-Matrix, die Ihnen anzeigt, welche Fälle automatisiert und manuell gleich oder unterschiedlich codiert wurden.
## Reference
## Prediction 0 1
## 0 14 2
## 1 6 8Diee Matrix zeigt Ihnen, wie viele Texte der automatisierten Codierung (“Prediction”), die mit 0 (“Negativität kommt nicht vor”) bzw. 1 (“Negativität kommt vor”) codiert wurden beim manuellen Goldstandard mit 0 (“Negativität kommt nicht vor”) bzw. 1 (“Negativität kommt vor”) codiert wurden - und andersherum.
Je mehr Texte bei beiden Codierungen also gleichermassen eine 0 ausweisen oder gleichermassen eine 1 ausweisen, desto besser die Übereinstimmung zwischen automatisierter und manueller Analyse.
Je mehr Texte bei einer der Codierungen aber eine 0 und bei einer anderen eine 1 aufweisen (oder andersherum), desto schlechter die Übereinstimmung zwischen automatisierter und manueller Analyse.
Wir sehen hier, dass…
- 8 Texte von Mensch wie Maschine gleichermassen als “Negativität kommt vor” codiert wurden. Der Computer hat also 8 True Positives erkannt von insgesamt 10 Texten, die laut manuellem Goldstandard mit “Negativität kommt vor” codiert werden müssten (2+8 = 10).
- 14 Texte von Mensch wie Maschine gleichermassen als “Negativität kommt nicht vor” codiert wurden. Der Computer hat also 14 True Negatives erkannt von insgesamt 20 Texten, die laut manuellem Goldstandard mit “Negativität kommt nicht vor” codiert werden müssten (14 + 6 = 20).
- Allerdings hat die automatisierte Analyse 6 Texte mit “Negativität kommt vor” codiert, die laut manuellem Goldstandard mit “Negativität kommt nicht vor” codiert werden müssen. Es handelt sich hier also um False Positives, die unseren Precision-Wert vermutlich verschlechtern werden.
- Zudem hat die automatisierte Analyse 2 Texte mit “Negativität kommt nicht vor” codiert, die laut manuellem Goldstandard mit “Negativität kommt vor” codiert werden müssen. Es handelt sich hier also um False Negative, die unseren Recall-Wert vermutlich verschlechtern werden.
Sie könnten auf Basis dieser Matrix Precision, Recall und den F1-Wert bereits manuell berechnen:
\(Precision = \frac{True Positives}{True Positives + False Positives} = \frac{8}{8+6}= .57\)
\(Recall = \frac{True Positives}{True Positives + False Negatives} = \frac{8}{8+2}= .8\)
\(F_{1} = 2 * \frac{Precision * Recall}{Precision + Recall}= 2 * \frac{.57 * .8}{.57 + .8}= .66\)
Diese Werte müssen Sie natürlich nicht immer manuell berechnen, sondern können sich diese auch via R ausgeben lassen (da uns die Ausgabe mehrere ausgibt, beschränken wir uns hier auf die Werte 5-7, d.h. Precision, Recall und F1)
## Precision Recall F1
## 0.5714286 0.8000000 0.6666667Für die Festlegung “guter” Kennwerte, was Precision, Recall und den F1-Wert angeht, gibt es in der Kommunikationswissenschaft (noch) keine einheitlichen Vorgaben. Sie können sich grob an den Vorgaben zu “guten” Intercoder-Reliabilitätswerten orientieren - z.B. würde ein Wert von .8 für Precision, Recall oder den F1-Wert dafür sprechen, dass die automatisierte Analyse valide Ergebnisse liefert.
Insgesamt würden wir auf Basis dieser Ergebnisse davon ausgehen, dass unser Diktionär gut funktioniert, wenn es darum geht, möglichst alle negativen Texte zu erkennen, da Recall = .8, allerdings deutlich zu oft nicht-negative Texte fälschlicherweise als negativ klassifiziert, da Precision = .57.
Das könnte z.B. ein Hinweis darauf sein, dass unser Diktionär zu “breit” ist, d.h. zu viele nicht eindeutig negative Wörter und damit unpräzise Suchbegriffe enthält.
14.1.2 Themenanalyse
Für die Themenanalyse könnten Sie ähnlich vorgehen, wenn Sie mit Precision, Recall oder dem F1-Wert arbeiten wollen.
Hierfür müssten Sie zunächst jedem Artikel ein oder mehrere Themen zuordnen - beispielweise auf Basis der Dokument-Topic-Matrix. Dann könnten Sie manuell codieren, ob ein (oder mehrere Themen) in einem Artikel vorkommen oder nicht und die Codierung von Themen über die Confusion-Matrix vergleichen.
Da das Vorgehen im Prinzip das gleiche ist, wird dieses hier nicht noch einmal durchgeführt.
14.2 Validierung mit dem Paket oolong
Einen ähnlichen, etwas benutzerfreundlicheren Ansatz bietet das Paket oolong. Das Paket erlaubt vor allem auch die Stichprobenerhebung für eine manuelle Validierung und die Codierung von Inhalten innerhalb von R.
Das Paket oolong ist vergleichsweise neu. Sie können eine Basis-Version via install.packages() laden (aktueller Stand: November 2020).
Wollen Sie allerdings sichergehen, dass Sie auf die allerneueste Version zugreifen - die ggf. noch nicht auf CRAN publiziert wurde - können Sie direkt auf das Repository des Paketes via Github zugreifen. Dafür müssen Sie mit dem Paket devtools arbeiten.
Achtung: Es kann sein, dass die Installation der neuesten oolong-Version bei Ihnen etwas dauert. Führen Sie die Installation also am besten vorab durch. Andernfalls sollte der nachfolgende Code auch mit der regulären Installation via install.packages() funktionieren.
#Entweder:
install.packages("devtools")
library("devtools")
#Oder:
devtools::install_github("chainsawriot/oolong")
library("devtools")14.2.1 Diktionäranalyse
Starten wir mit der Validierung unseres Diktionärs. Wir wollen wieder überprüfen, wie sehr manuelle und automatisierte Codierung von Negativität in Texten übereinstimmen.
Um Texte manuell zu validieren, nutzen wir den Befehl create_oolong. Hier weisen wir R
- via input_corpus an, dass wir als Texte validieren wollen, die in dem Dataframe data in der Spalte text abgespeichert sind.
- via construct an, dass wir validieren wollen, inwiefern in Texten “Negativität” vorkommt.
- via exact_n an, dass wir 30 Texte validieren wollen (je mehr Texte, desto besser).
Mit dem folgenden Befehl können wir jetzt die manuelle Codierung durchführen:
Schauen wir uns den Prozess einmal an:
Output: Validierung von Diktionären mittels oolong
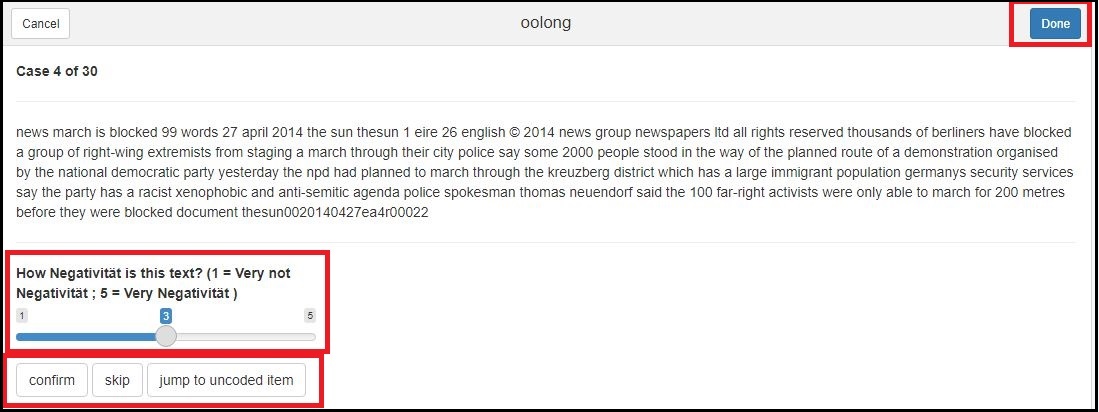
- Das Paket gibt Ihnen den Text, der zu codieren ist, aus.
- Sie sehen als Codier:innen-Anweisung (hier in Englisch) die Frage, wie sehr ein Text als “negativ” einzustufen ist. Dabei erlaubt das Paket aktuell “nur” die Möglichkeit, die zu codierende Variable auf einer 1-5 Likert-Skala einzustufen (was in vielen Fällen aber sehr sinnvoll ist, weil Texte meist vermutlich weder “gar nicht” negativ noch “vollständig” negativ sind, sondern sich verschiedene Grade an Negativität abstufen lassen).
- Sie können also jeden Text im Hinblick auf das Vorkommen der Variable “Negativität” codieren und Ihre Codierung für jeden Text via confirm bestätigen.
- Sobald Sie mit der Codierung fertig sind (d.h., wieder bei Case 1 of 30 angelangt sind), können Sie die Codierung über den Done-Button beenden.
Als nächstes sollten Sie die Codierung “locken”, d.h., sichergehen, dass die Werte nach Abschluss der manuellen Codierung nicht mehr nachträglich bearbeitet werden können.
Anschliessend speichern wir jetzt genau die Texte ab, die für die manuelle Validierung genutzt wurden, und analysieren diese automatisiert.
#Texte, die für manuelle Codierung genutzt wurden
automated <- validation_set$turn_gold()
#Automatisierte Analyse dieser Texte
automated <- dfm(automated) %>%
dfm_weight("prop") %>%
dfm(dictionary = data_dictionary_LSD2015[1:2]) %>%
convert(to="data.frame")
#Wir berechnen wieder die rel. Differenz zwischen positiven und negativen Features
automated$relative <- automated$positive-automated$negative
#Wir klassifizieren Texte mit mehr negativen als positiven Features als negativ
automated$negativity[automated$relative<0] <- 1
#Wir klassifizieren Texte mit mehr/gleich viel positiven als negativen Features als positiv
automated$negativity[automated$relative>=0] <- 0Anschliessend können Sie die manuelle Codierung und die bereits durchgeführte automatisierte Codierung vergleichen. Da Sie die manuelle Codierung auf einer 1-5er Likert-Skala vorgenommen haben, wäre es vmtl. sinnvoller, hier die metrische Variable automated$negative zu nutzen, die Ihnen angibt, wie viel % aller Features im Text negativ sind.
Der Vergleichbarkeit zum vorherigen Package halber arbeiten wir jetzt hier aber wieder mit der binären Klassifikation “Negativität kommt vor” (1) und “Negativität kommt nicht vor” (0).
Für die Validierung nutzen Sie den summarize_oolong-Befehl und weisen R an, dass Ihre automatisierte Codierung im Dataframe automated in der Spalte negativity zu finden sind:
## New names:
## * NA -> ...1## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'## Correlation: 0.353 (p = 0.0556)
## Effect of content length: 0.039 (p = 0.8376)Was sehen Sie hier?
Sie sehen, dass die Korrelation zwischen manueller und automatisierter Codierung bei .35 liegt - also ziemlich niedrig ist.
Spezifisch zeigt Ihnen dieser Wert die Pearson-Korrelation zwischen Ihrer manuellen Codierung (Negativität, codiert als 1-5) und der automatisierten Codierung (Negativität, 0 oder 1) an.
Sie sehen also: Texte, die im manuell codierten Goldstandard als negativer codiert wurden (Werte Richtung 5), hat auch die automatisierte Analyse als negativer eingestuft (Werte Richtung 1).
Allerdings ist die Korrelation eher gering und der Zusammenhang nicht konsistent, wie der p-Wert von p = .06 aufzeigt.
Sie müssten also feststellen, dass Ihre automatisierte Codierung im Vergleich zu dem manuellen Goldstandard wenig valide ist.
Die Ausgabe zeigt Ihnen ausserdem an, ob es einen Zusammenhang zwischen der Textlänge und der automatisierten Codierung gibt (d.h. längere Texte eher als negativ codiert werden, was einer Verzerrung aufgrund von Textlänge entspräche) - was also schlecht wäre.
Dieser Zusammenhang ist allerdings nicht konsistent, da r = .04, p = .84. Das heisst, dass Sie nicht befürchten müssen, dass die Länge von Texten einen Einfluss auf die automatisierte Codierung hat und damit ggf. die automatisierte Codierung verzerrt. Da unsere Codierung auf Basis der relativen Anzahl negativer Features vorgenommen wurde, scheint es wenig verwunderlich, dass wir uns um den Einfluss Textlänge wenig Sorgen machen müssen.
14.2.2 Themenanalyse
Das Paket oolong bietet zudem sehr hilfreiche Funktionen, wenn es um die Validierung von Themenmodellen angeht. Die Autoren nutzen dafür ein Verfahren, das von Chang et al. (2009) vorgeschlagen wurde: den Word bzw. Topic Intrusion Test.
Worum geht es dabei?
Sie haben bereits im Tutorial 13: Unueberwachtes maschinelles Lernen: Topic Modeling gelernt, dass substanzielle und interpretierbare Themen u.a. aufgrund ihrer wichtigsten Wörter und ihrer wichtigsten Themen interpretiert werden.
Der Topic bzw. Word Intrusion Test greift genau auf diese Logik zurück.
Vereinfacht ausgedrückt erfolgt die Validierung von Themen folgendermassen:
- Beim Word Intrusion Text werden den Codierer:innen Features gezeigt, die für ein Thema hohe Wahrscheinlichkeiten aufweisen. Alle bis auf eins dieser Features entstammen den wichtigsten Features (Top Features) für dieses Thema; eines der Features stammt aber aus den Top Features eines anderen Themas. Es geht also im Prinzip darum, die Features, die ein kohärentes Thema beschreiben, zu finden und das abweichende Feature, das eigentlich zu einem anderen Thema gehört, zu identifizieren.
- Beim Topic Intrusion Text werden den Codierer:innen ein Text und verschiedene Themen (auf Basis ihrer Top Features) gezeigt. Alle bis auf eines dieser Themen haben für das angezeigte Dokument eine hohe Wahrscheinlichkeit, d.h. diese Themen sind dort vergleichsweise prävalent; eines der Themen hat aber eine geringe Wahrscheinlichkeit. Es geht also im Prinzip darum, die Themen, die in einem Dokument vorkommen, und finden und das abweichende Thema, das nicht zu diesem Dokument gehört, zu identifizieren.
Der Einfachheit halben arbeiten hier mit einem bereits durchgeführten Themenmodell mit K = 20 Themen auf Basis des Ihnen bereits bekannten Nachrichtenkorpus zum Thema Immigration, das Sie einfach in Ihr R-Environment laden können.
Sie finden das R-Environment in OLAT (via: Materialien / Datensätze für R) mit dem Namen validation_stm.rda. Das STM-Modell wurde hier mit dem Namen model abgespeichert.
14.2.2.1 Word Intrusion Test
Beginnen wir mit dem Word Intrusion Test. Sie nutzen dafür wieder den Ihnen bereits bekannten Befehl summarize_oolong, um die zu validierenden Daten dem Paket zu übergeben.
Wir weisen R dabei zusätzlich an:
- via n_top_terms auf die Top 5 Features jedes Themas zuzugreifen
- via use_frex_words = TRUE auf die FREX gewichteten Top Features jedes Themas zuzugreifen
Der Word Intrusion Test wird dann folgendermassen durchgeführt:
Schauen wir uns den Prozess einmal an:
Word Intrusion Test
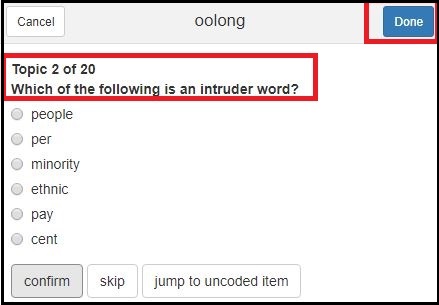
Sie sehen: Sie müssen ganz einfach das Feature bestimmen, das in dieser Reihe nicht dazu gehört.
Sie sehen aber auch: Das ist gar nicht so einfach. Gerade wenn Ihre Themen viele allgemeine Wörter und ggf. Stopwörter enthalten, etwa Begriffe wie “said” or “mr”, ist es oft nicht einfach, das vermeintlich “irrelevante” Feature zu identifizieren. Je kohärenter und exklusiver Ihre Themen, desto einfacher die Identifikation “abweichender” Feature und desto besser wird auch der Word Instrusion Test ausfallen.
Schauen wir uns das Ergebnis an:
## An oolong test object with k = 20, 20 coded.
## 55% precisionSie sehen: Nur 55% der Intruder-Wörter, d.h. der Wörter, die eigentlich wenig prävalent für Themen sind, wurden richtig identifiziert. Das ist insgesamt noch kein guter Wert - und könnte z.B. darauf hindeuten, dass noch viele wenig informative Features im Korpus enthalten sind oder Themen nicht überschneidungsfrei sind, sodass für manuelle Codierer:innen relativ unklar ist, wie sich Themen anhand ihrer Top Features unterscheiden lassen.
14.2.2.2 Topic Intrusion Test
Für den Topic Intrusion Test nutzen wir im Prinzip die gleiche Funtkion. Dabei müssen wir der Funktion nicht nur unser STM-Modell übergeben, sondern auch die “Original”-Texte.
Wir weisen R daher hier an:
- via n_top_topics nur die zwei am meisten prävalente Topic je Dokument neben dem “Aussreisser”-Thema auszugeben.
- via exact_n den Test nur für 10 Dokumente auszuführen.
validation_stm2 <- create_oolong(input_model = model, input_corpus = data$text,
n_top_topics = 2,
exact_n = 10)Anschliessend führen wir den Test durch:
Schauen wir uns den Prozess an:
Topic Intrusion Test
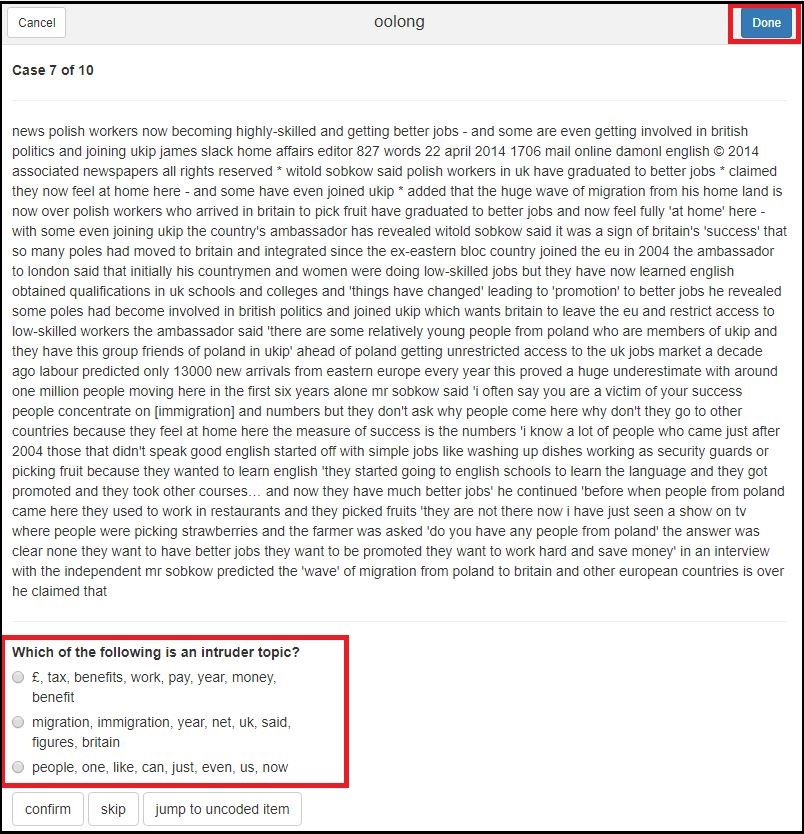
R gibt Ihnen hier den Text aus, den Sie beurteilen müssen. Dabei werden Ihnen drei Themen - hier identifizierbar auf Basis Ihrer Top Features - angezeigt, von denen allerdings nur zwei eine hohe Wahrscheinlichkeit für dieses Dokument haben. Sie müssen also wieder auswählen, welches das “Ausreisser”-Thema ist.
Schauen wir uns das Ergebnis an, sobald wir den Test für alle 10 Themen durchgeführt und den Done-Button gedrückt haben:
## An oolong test object with k = 20, 0 coded.
## 0% precision
## With 10 cases of topic intrusion test. 10 coded.
## TLO: -1.173Die Ausgabe gibt Ihnen den TLO-Wert an. TLO steht für Topic Log Odds - je näher dieser Wert bei 0 liegt, desto klarer sind Themen anhand von Dokumenten identifizierbar. Auch hier gilt: Bislang gibt es keine “Standards”, welcher TLO-Wert akzeptabel ist - in der Praxis eignet sich der TLO-Kennwert vermutlich v.a., um die Validität verschiedener Themenmodelle miteinander zu vergleichen.
14.3 Take Aways
Vokabular:
- Precision, Recall, F1-Wert: Kennwerte, die angeben, inwiefern Informationen präzise (Precision) und umfassend (Recall) gefunden werden, spezifisch:
- Precision: Inwiefern erfasst die automatisierte Klassifikation nur “True Positives”, d.h. relevante Informationen?
- Recall: Inwiefern umfasst die automatisierte Klassifikation alle “True Positives”, d.h. relevante Informationen?
Befehle:
- Validierung: confusionMatrix(), create_oolong(), summarize_oolong()
14.4 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
- Computational Methods in der politischen Kommunikationsforschung von J. Unkel, Tutorial 23
- oolong: An R package for validating automated content analysis tools von C. Chan & M. Sältzer sowie Vignette zum Paper
Und das war’s - zumindest für dieses Semester. Jetzt geht das eigentliche Projekt los: Die Anwendung des Erlernten für Ihr eigenes Projekt, die Bachelor-Arbeit.
Viel Erfolg!