2 Tutorial 2: Workflow in R
Wir beschäftigen uns in diesem Tutorial mit den Basics in R. Es geht hier noch nicht darum, selbst Code zu schreiben, sondern ganz grundsätzlich zu verstehen, wie R funktioniert und welche Schritte immer wieder vorkommen - egal, ob Sie eine automatisierte Inhaltsanalyse durchführen, eine Regression rechnen oder eine Grafik mit R erstellen. In Tutorial 2 lernen Sie:
- wie der grundsätzliche Workflow in R funktioniert
2.1 Definition des Arbeitsverzeichnisses
Bevor wir irgendeine Art von Code schreiben, ist es sinnvoll, das eigene Arbeitsverzeichnis zu definieren. Was ist das Arbeitsverzeichnis?
Das Arbeitsverzeichnis ist der Ordner, in dem Sie Dateien ablegen, die Sie mit R einlesen wollen oder Dateien, die Sie mit R erstellt haben, abspeichern.
Erstellen Sie zunächst einen Ordner, den Sie für dieses Tutorial als Arbeitsverzeichnis nutzen wollen oder entscheiden Sie sich für einen bereits vorhandenen Ordner. Gehen Sie zu dem Ordner, klicken Sie oben auf den Ordner-Pfad und kopieren Sie diesen heraus, etwa in dem Sie den Ordner öffnen und dann oben den Ordnerpfad herauskopieren:
Bild: Arbeitsverzeichnis
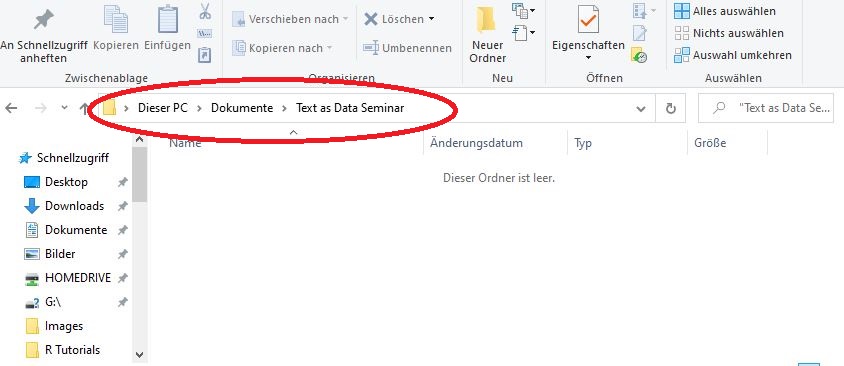
Jetzt wissen Sie, wo dieser Ordner auf Ihrem Rechner liegt, müssen R aber noch mitteilen, dass dies für diese Sitzung Ihr Arbeitsverzeichnis sein soll. Das heisst, Sie müssen in R Ihr Arbeitsverzeichnis definieren (“set working directory”). Wichtig: Die Definition des Arbeitsverzeichnisses unterscheidet sich zwischen Windows- und Mac-Computern.
Windows: Achten Sie darauf, dass die Schrägstriche in die richtige Richtung zeigen (beim Kopieren aus dem Ordnerpfad sehen diese so aus “\”, Sie müssen diese dann durch “/” ersetzen)
Mac: Hier müssen Sie ein “/” Zeichen am Anfang einfügen, etwa so:
Wenn Sie sich mal nicht mehr sicher sind, wo Ihre Dateien aktuell abgespeichert werden, können Sie das Arbeitsverzeichnis auch über einen einfachen Befehl erfragen (“get working directory”):
Sie können aber nicht nur Code oder Dateien, die Sie mittels R erzeugt haben, in diesem Ordner abspeichern. Oft macht es auch Sinn, Dateien, die Sie mit R verarbeiten wollen, in Ihrem Arbeitsverzeichnis abzuspeichern und dann mittels R einzulesen. Laden Sie als Beispiel bitte die Excel-Datei “Beispiel_CSV” aus OLAT herunter (via: Materialien / Datensätze für R). Bei dieser Datei handelt es sich um eine fiktive Umfrage unter 20 Studierenden (N = 20), für die fünf Variablen erfasst wurden:
- die ID des Teilnehmers/der Teilnehmerin
- ihr Alter
- ihr Wohnort
- ihre Zufriedenheit mit der Universität Zürich (auf einer Skala von 1 = gar nicht zufrieden bis 5 = sehr zufrieden)
- das Datum, an dem die Teilnehmer:innen befragt wurden
Legen Sie das CSV-File in dem Ordner ab, den Sie zuvor als Arbeitsverzeichnis definiert haben. Jetzt sollten Sie die Datei in ihr R-Environment einlesen können (wir gehen später auf den Befehl ein, den Sie dafür nutzen). Im Prinzip sagen Sie R, dass Sie aus dem Arbeitsverzeichnis das CSV-File mit dem Titel “Beispiel-CSV” einlesen wollen, die erste Zeile dieses CSV-Files die Variablennamen enthält und dann im Environment diese Datei als Objekt mit dem Titel “survey” abspeichern möchten.
Schauen Sie jetzt in Ihr Environment, sehen Sie jetzt, dass das Objekt “survey” dort auftaucht. Wir können also Dateien aus unserem Arbeitsverzeichnis in R einlesen und dann weiterverarbeiten, etwa für Analysen. Sie können die Datei entweder über das Environment anschauen, indem Sie auf den blauen Button drücken (listet Elemente des Datensatzes “survey” auf).
Bild: Aufruf des Datensatzes via Environment
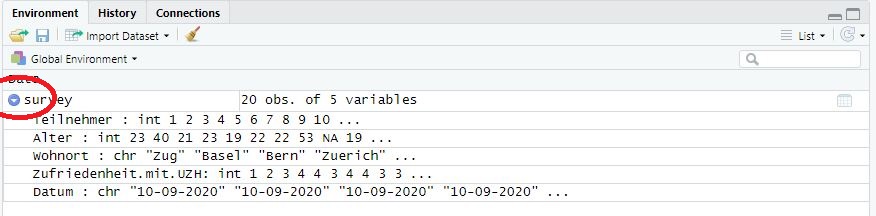
Sie können den Datensatz auch via Befehl in R öffnen und - ähnlich wie in SPSS - die Daten inspizieren.
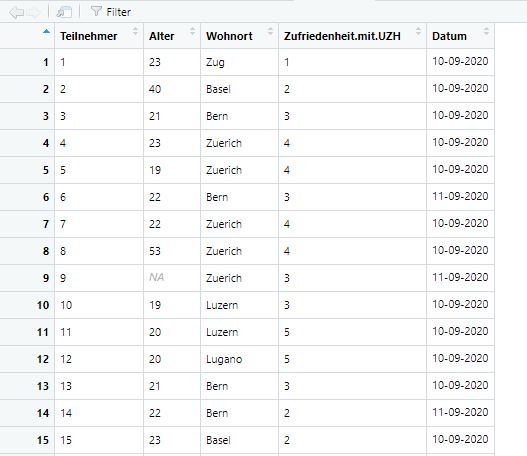
Anschliessend sehen Sie dann den Datensatz:
Bild: Ansicht des Datensatzes im Environment
2.2 Packages
In der “Standard-Version” von R sind viele nützliche Funktionen erhalten, mithilfe derer Sie Analysen durchführen können. Ganz im Sinne der “Open Science”-Philosophie von und mit R kann aber jede:r eigene Funktionen schreiben und diese via themenspezifischen R-Packages publizieren. Der sogenannte “Source-Code” dieser Packages ist öffentlich einsehbar.
Packages sind also Sammlungen von themen-spezifischen Funktionen, die helfen, die Basis-Funktionen von R zu erweitern.
Eine Liste aller R-Packages finden Sie hier. Wir werden in diesem Seminar beispielsweise mit Packages wie Quanteda oder STM arbeiten, die spezifische Erweiterungen für automatisierte Inhaltsanalysen bieten.
2.2.1 Installation von Packages
Um ein Package nutzen zu können, müssen Sie dieses zuerst installieren. Sagen wir, Sie wollen Quanteda nutzen. So installieren Sie das Package:
Jetzt ist das Package auf unserem Rechner “abgespeichert” bzw. steht lokal zur Verfügung. Diesen Befehl müssen wir nur einmal durchführen.
2.2.2 Aktivierung von Packages
Bevor wir ein Package nutzen können, müssen wir es zu Beginn jeder Session einmal aktivieren. Es macht daher Sinn, ganz zu Beginn einer Session nicht nur das Arbeitsverzeichnis zu definieren, sondern auch alle benötigten Packages einmal zu aktivieren. Das ist auch wichtig, weil teils unterschiedliche Packages Funktionen mit gleichem Namen nutzen. Das Aktivieren von Funktionen machen Sie über folgenden Befehl:
2.2.3 Infos zu Packages
Das Package ist geladen - aber wir wissen noch nicht, welche nützlichen Funktionen es bietet. Die Autor:innen von Packages fassen Informationen zu ihren Packages daher in “Reference Manuals” und/oder “Vignetten” zusammen. Reference Manuals geben eine Uebersicht über alle Funktionen eines Packages. Vignetten sind mehr oder weniger Tutorials, die beschreiben, welche Funktionen ein Package hat und wie man mit diesen arbeitet. Auch hier ist Google unsere erste Anlaufstation: Googlen wir “CRAN” (das Verzeichnis für R-Packages) und “Quanteda”, kommen wir zu dieser Webseite:
Bild: Cran-Seite zum Package Quanteda
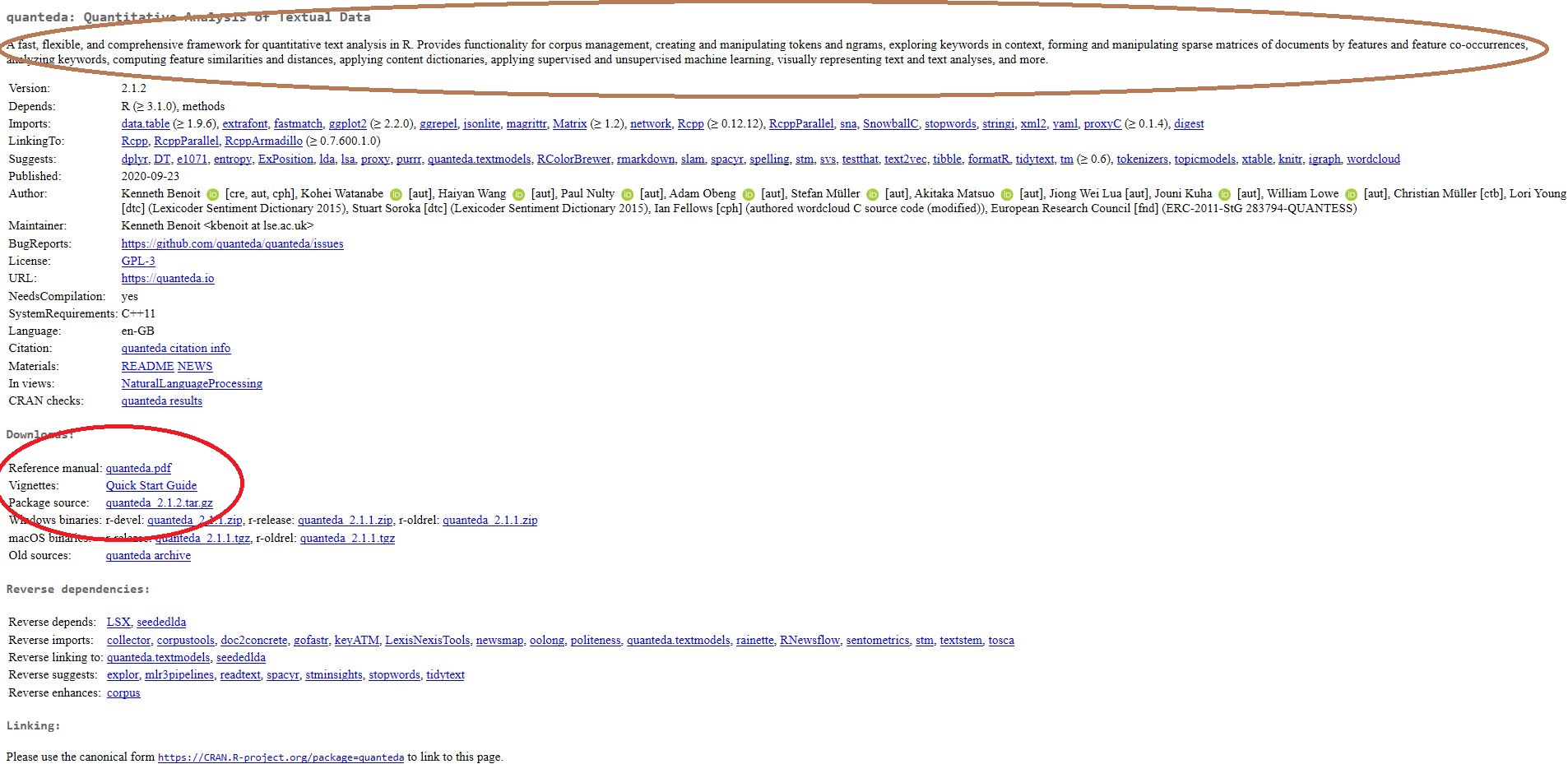
Zwei Dinge interessieren uns dabei: Der erste, rot markierte Absatz gibt eine kurze Zusammenfassung, wofür das Package nützlich sein kann. Der zweite, rot markierte Absatz verlinkt zum Reference Manual (“Benutzerhandbuch”) und der Vignette (“Tutorial”). Sind wir uns nicht sicher, wofür welche Funktion nützlich ist, lohnt es sich, hier etwas genauer nachzuschauen.
2.3 Hilfe
Eines ist sicher: Wenn Sie mit R arbeiten, wird nicht von Anfang an alles so funktionieren, wie Sie sich das wünschen. Selbst erfahrene R-Programmierer:innen brauchen immer mal Hilfe, weil etwas nicht funktioniert.
2.3.1 Hilfe zu Funktionen
Ein Beispiel: Sie haben die Datei “Beispiel-CSV” mit den Umfragedaten eingeladen. Jetzt wollen Sie mit R das Durchschnittsalter der Befragten auswerten (mehr zu deskriptiver Statistik in R später). Zur Berechnung des Mittelswertes nutzen Sie die Funktion mean. Sie spezifizieren, dass die Funktion den Mittelwert für die Variable Alter im Datensatz survey ausgeben soll. Bei der Berechnung des Mittelwertes erhalten Sie folgendes Ergebnis:
## [1] NADer Mittelwert wird als “NA” ausgegeben. “NA” steht für “not available” also einen fehlenden Wert. Aber haben wir wirklich nur fehlende Werte? Schauen wir uns den Datensatz nochmal an:
Bild: Ansicht des Datensatzes
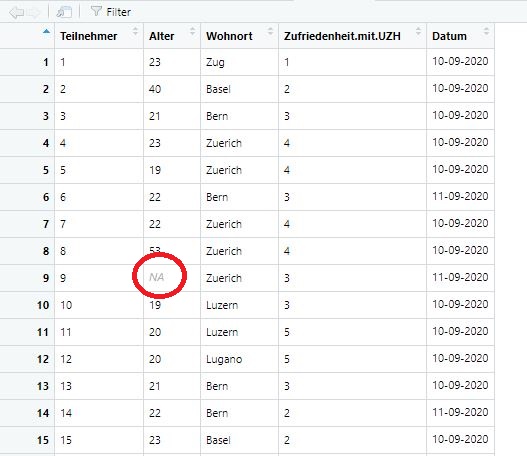
Wir sehen, dass alle Teilnehmer:innen ihr Alter angegeben haben. Nur in Zeile 9 bei Teilnehmer:in 9 haben wir einen fehlenden Wert. Wieso gibt uns unser Befehl also nicht den Mittelwert für alle Teilnehmer:innen aus, die keine fehlenden Werte haben? Um das herauszufinden, nutzen wir die Hilfe-Funktion. Mittels dieser können wir z.B. bestimmte Funktionen suchen. Genutzt werden dafür die Befehle ? oder help() (beides führt zum gleichen Resultat):
Jetzt sehen wir zum ersten Mal den Mehrwert von Fenster 4 (Files/Plots/Packages etc.): Hier taucht nämlich Hilfe zur gesuchten Funktion auf.
Bild: Hilfe zur Funktion “mean”
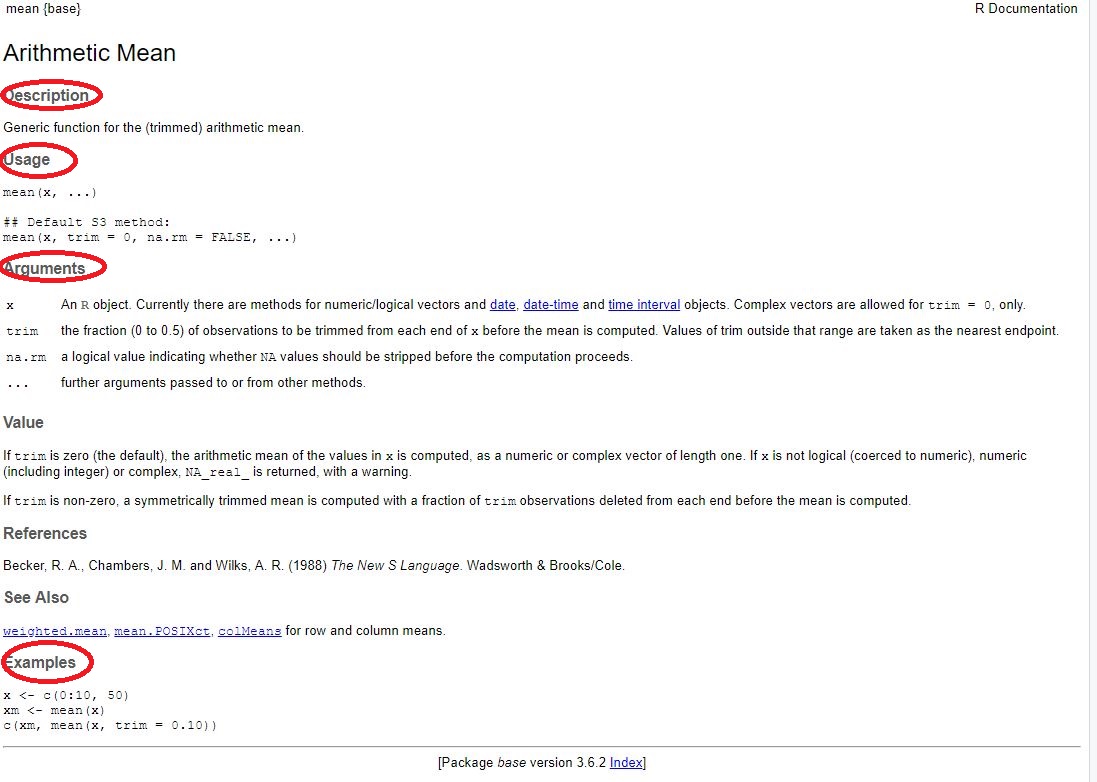
Der Abschnitt liefert einige wichtige Hinweise, auf einige ausgewählte wird hier eingegangen:
- Description: beschreibt, wofür die Funktion mean genutzt wird
- Usage: beschreibt, wie die Funktion mean aufgebaut ist
- Arguments: beschreibt, welche Elemente bei Nutzung von mean zu definieren sind und wie man diese Argumente füllen sollte
- Examples: gibt Beispiele, wie die Funktion mean anzuwenden ist.
Mit Blick auf den Abschnitt “Arguments” sehen wir etwas sehr wichtiges: mean ist eine Funktion, die vor allem ein Objekt x braucht, für welches ein Mittelwert berechnet werden kann. In diesem Fall ist x der Vektor “Alter” im Dataframe “Survey”, definiert als survey$Alter (was ein Vektor und was eine Dataframe sind, erfahren Sie in Tutorial 3: Objekte & Strukturen in R). Unser x, für das ein Mittelwert berechnet werden soll, ist also die Spalte mit dem Alter je Umfrageteilnehmer:in. Dieses x hatten wir für die Funktion mean bereits definiert.
Aber: Das Hilfe-File weist im Abschnitt Arguments noch auf eine weitere wichtige Information hin, welche die mean-Funktion braucht: Wie fehlende Werte, also NAs, behandelt werden sollen. In der Beschreibung der Funktion unter Arguments steht:
- “na.rm: a logical value indicating whether NA values should be stripped before the computation proceeds”.
Das heisst, wir müssen für die Ausführung der Mittelwertsberechnung definieren, dass fehlende Werte - NAs - ignoriert werden sollen. Indem wir na.rm auf TRUE setzen, sagen wir R, dass fehlende Werte für die Berechnung des Mittelwertes ausgeschlossen werden sollen. Kaum geben wir R diese Info, berechnet das Programm den Mittelwert für die Teilnehmer:innen unter Ausschluss fehlender Werte:
## [1] 24.368422.3.2 R-Skript stoppen
In manchen Fällen kann es sein, dass Sie einen sehr lange dauernden Befehl laufen lassen - und Ihnen mitten in der Berechnung durch R auffällt, dass sich im Code ein Fehler versteckt hat. Jetzt müssen Sie also R bei der Ausführung der Befehle stoppen. Wenn R gerade rechnet, erscheint in der Konsole ein Stop Button, mit Hilfe dessen Sie das Programm unterbrechen können:
Bild: R unterbrechen
Andernfalls können Sie auch via Session / Interrupt R im Menü die Ausführung laufender Befehle stoppen. Wichtig ist, dass R quasi dort aufhört zu rechnen, wo das Programm gerade war - wenn Sie also beispielsweise einen Befehl für einen Datensatz mit sehr vielen Fällen durchgeführt haben, kann es sein, dass der Computer mittendrin bei einem beliebigen Fall stoppt - alle Fälle davor also bearbeitet wurden, alle danach aber nicht.
2.4 Speichern, Laden & Aufräumen
Wie bei jeder Art von Arbeit gilt: Speichern Sie Ihren Code und die Ergebnisse, die Sie mit Ihrem Code produziert haben ab. Wie geht das?
2.4.1 Speichern von Code
Das Abspeichern von Code geht ganz einfach: Entweder Sie wählen File und gehen dann auf die Option Save as. Oder Sie drücken direkt auf den “Speichern”-Button im Fenster Source. Dann können Sie ihren Code mit der Endung -R abspeichern, etwa “MyCode.R”.
Bild: Code abspeichern
2.4.2 Speichern von Work Spaces
Ihr Computer hat alle Befehle erfolgreich durchgeführt und Sie wollen Ihre Ergebnisse sichern? Auch hier gibt es mehrere Optionen: Entweder Sie drücken direkt auf den “Speichern”-Button im Fenster Environment. Dann können Sie ihre Ergebnisse mit der Endung -RDATA abspeichern, etwa “MyData.RDATA”.
Bild: Work Space abspeichern
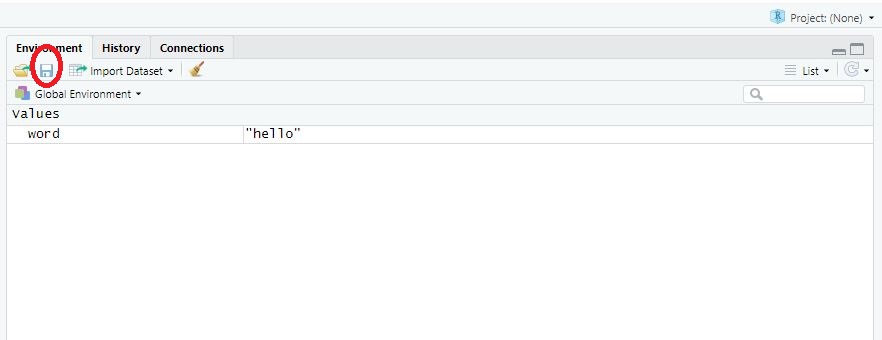
Oder Sie nutzen einen einfachen R-Befehl dafür:
Wichtig: Das Abspeichern von Work Spaces muss nicht immer sein - sinnvoll ist dies vor allem, wenn R lange für die Ausführung des Codes gebraucht hat und Sie bei erneutem Einstieg in die Analyse nicht den gesamten Code von Anfang an wieder durchlaufen lassen wollen. Sie brauchen hier nicht immer den Work Space abspeichern - in vielen Fällen, können Sie Ihren Code auch einfach noch einmal ausführen und Ihre Ergebnisse so schnell replizieren. Das ist einer der grossen Vorteile von R.
2.4.3 Laden von Work Spaces
Sagen wir, Sie wollen Ihre Ergebnisse bei der nächsten R-Session wieder laden. Auch dafür können Sie einen Befehl nutzen. Definieren Sie wie gewohnt zu Beginn ihrer R-Session das Arbeitsverzeichnis, hier der Ordner, in dem Sie Ihren Work Space abgespeichert haben. Laden Sie dann den Work Space in Ihre aktuelle R-Session.
2.4.4 Aufräumen des Work Spaces
Ihr Work Space ist völlig unaufgeräumt? Dann können Sie den folgenden Befehl nutzen, um alle Elemente aus Ihrem Work Space zu löschen:
Wenn Sie nur ein ausgewähltes Objekt löschen wollen, können Sie auch nur dieses Objekt löschen lassen. Stellen wir uns vor, wir hätten aus Versehen unsere Umfrage zweimal abgespeichert:
Sie sehen jetzt, dass die Umfrage zweimal im Work Space ist - einmal als Objekt mit dem Namen “survey” und einmal als Objekt mit dem Namen “duplicate”. Wenn Sie jetzt nur das Objekt “duplicate” löschen wollen, können Sie folgenden Befehl nutzen:
2.4.5 Take Aways
- Arbeitsverzeichnis: Ordner, auf den R automatisch zugreift, um Daten einzulesen oder Daten abzuspeichern. Sollte zu Beginn jeder Session definiert werden. Befehle: setwd() und getwd()
- Packages: Sammlungen von themen-spezifischen Funktionen, etwa zur automatisierten Inhaltsanalyse, die helfen, die Basis-Funktionen von R zu erweitern. Müssen auf dem eigenen Computer einmal installiert und anschliessend zur Beginn jeder Session aktiviert werden. Wenn Sie die benötigen Packages nicht aktivieren, kann R Funktionen aus diesem Package nicht nutzen. Befehle: install.packages() und library()
- Hilfe: Braucht jeder, der mit R arbeitet. Erste Anlaufstelle: Google. Es ist normal, dass nicht alles direkt klappt - eine gewisse Frustrationstoleranz gehört zum Arbeiten mit R dazu! Befehle: ? oder help()
- Speichern, Laden & Aufräumen: Speichern Sie Ihren Code und Ihr Working Environment immer wieder ab. Befehle: save.image, load(), rm(list = ls())
2.5 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
- Computational Methods in der politischen Kommunikationsforschung von J. Unkel, Tutorial 5 und 6
- R Cookbook von Long et al., Tutorial 2
- YaRrr! The Pirate’s Guide to R von N.D.Phillips, Tutorial 2 und 9
- Cheat sheet: Base R
Wir machen weiter: mit Tutorial 3: Objekte & Strukturen in R