15 Loesungen zu den Aufgaben
Hier finden Sie die Lösungen zu den jeweiligen Übungsaufgaben.
15.1 Lösungen zu Tutorial 3
Hier finden Sie die Lösungen zu Tutorial 3.
15.1.1 Aufgabe 3.1
Aufgabenstellung: Definieren Sie einen Vektor Preis, der aus 5 beliebigen Zahlen besteht. Definieren Sie dann einen Vektor Eissorten, der aus 5 beliebigen Eissorten besteht. Definieren Sie anschliessend einen Vektor Marke, der nur aus dem Wort “Ben & Jerrys” besteht, das fünf mal wiederholt wird. Kombinieren Sie alle drei Vektoren zu einem Dataframe Eis, der die Variablen Eissorten, Preis und Marke in dieser Reihenfolge enthält. Berechnen Sie dann den Mittelwert des Eispreises.
Lösung:
#Wir definieren den Vektor Preis
Preis <- c(1.2,2,1.5,3,2.4)
#Wir definieren den Vektor Eissorten
Eissorten <- c("Vanille","Schokolade","Himbeere","Straciatella","Nuss")
#Für die Definition des Vektors Marke gibt es zwei Lösungen.
#Eine aufwendige:
Marke <- c("Ben & Jerrys","Ben & Jerrys","Ben & Jerrys","Ben & Jerrys","Ben & Jerrys")
#und eine simplere:
Marke <- rep("Ben & Jerrys",5) #Befehl "rep" ggf. mit ? nachschauen:
#Wir definieren den Dataframe Eis mit den drei Variablen:
#(1) Eissorten, (2) Preis und (3) Marke
Eis <- data.frame(Eissorten = c(Eissorten), Preis = c(Preis), Marke = c(Marke))
#Wir lassen uns den Mittelwert des Eispreises herausgeben
mean(Eis$Preis)## [1] 2.0215.1.2 Aufgabe 3.2
Aufgabenstellung: Erstellen Sie jetzt eine Liste mit dem Namen list. Das erste Elemente von list sollte der Dataframe Eis sein, das zweite Element erneut der Vektor Preis.
Lösung:
15.2 Lösungen zu Tutorial 4
Hier finden Sie die Lösungen zu Tutorial 4.
15.2.1 Aufgabe 4.1
Aufgabenstellung: Lesen Sie den Datensatz ein. Lassen Sie sich die Anzahl an Teilnehmer:innen sowie die Anzahl der erhobenen Variablen über die entsprechenden Befehle in R ausgeben.
Lösung:
## [1] 20## [1] 515.2.2 Aufgabe 4.2
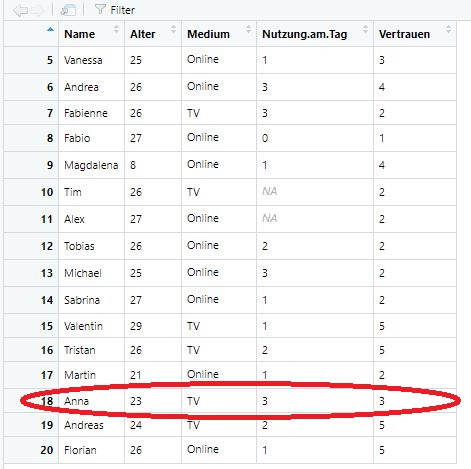
Aufgabenstellung: Schreiben Sie einen Befehl, der Ihnen angibt, welches das meist genutzte Medium von der 18. Teilnehmerin der Umfrage ist (dh., der Teilnehmerin in der 18. Zeile).
Können Sie diesen Befehl so anpassen, dass R Ihnen das meist genutzte Medium von der Teilnehmerin mit dem Namen “Anna” ausgibt? Achtung: Hier ist Googlen angesagt, diese Befehle kennen Sie noch nicht. Können Sie sie eigenständig herausfinden?
Lösung:
Variante 1: Lazy, but works
Der Befehl, den wir schon kennen: erlaubt uns, uns den Datensatz anzeigen zu lassen. Dann könnten wir manuell anschauen, welches Medium Anna nutzt - das funktioniert allerdings für grössere Datensätze nicht (und ist auch nicht sinnvoll).
Bild: Daten der Teilnehmerin “Anna”
Variante 2: Still lazy, but works
Wir schauen uns an, in welcher Zeile Informationen zur Teilnehmerin mit dem Namen Anna abgespeichert sind. Wir sehen: Es ist Zeile 18.
Bild: Daten der Teilnehmerin “Anna”
Dann sagen wir R, dass er uns das bevorzugte Medium für Zeile 18 (Informationen zur Teilnehmerin mit dem Namen Anna) ausgeben soll.
## [1] TV
## Levels: Online TV ZeitungVariante 3: die elegante Version
Ein neuer Befehl: Wir sagen R, dass er uns den Vektor “Medium” ausgeben soll - aber nur den Wert, den die Teilnehmer:in mit dem Namen Anna hat. D.h., R gibt den Wert “Medium” nur für Fälle aus, bei denen die Bedingung “Name” ist “Anna” erfüllt ist. Das ist eine neue Lösung, die wir im nachfolgenden Tutorial 5 genauer kennen lernen werden - und die Sie präferieren sollten, weil Sie dafür nicht im Datensatz nachschauen müssen, in welcher Zeile Informationen zur Teilnehmerin “Anna” stehen.
## [1] TV
## Levels: Online TV Zeitung15.2.3 Aufgabe 4.3
Aufgabenstellung: Berechnen Sie den Mittelwert des Alters der Teilnehmer:innen.
Lösung:
#der Befehl, den wir schon kennen: berechnet den Mittelwert des Alters.
#Da wir einen fehlenden Wert (missing, auch "NA") haben,
#müssen wir R anweisen, fehlende Werte zu ignorieren.
mean(data$Alter, na.rm = TRUE) ## [1] 24.415.2.4 Aufgabe 4.4
Aufgabenstellung: Eine/r der Teilnehmer:innen hat ein sehr niedriges Alter angegeben (8 Jahre alt). Hier scheint es sich um einen Tippfehler ersetzen. Können Sie das Alter dieses Teilnehmers/der Teilnehmerin ersetzen, d.h. aus der 8 eine 18 machen?
Lösung:
## [1] 20 25 29 22 25 26 26 27 8 26 27 26 25 27 29 26 21 23 24 2615.3 Lösungen zu Tutorial 5
15.3.1 Aufgabe 5.1
Aufgabenstellung: Lesen Sie den Datensatz ein. Lassen Sie sich die Anzahl an Teilnehmer:innen sowie die Anzahl der erhobenen Variablen über die entsprechenden Befehle in R ausgeben.
Lösung:
## [1] 5000## [1] 5## 'data.frame': 5000 obs. of 5 variables:
## $ Alter : int 36 54 71 61 62 67 21 25 29 73 ...
## $ Geschlecht : Factor w/ 2 levels "männlich","weiblich": 1 1 NA 1 NA 1 NA 2 1 2 ...
## $ Einkommen : Factor w/ 3 levels "0-3000","3000-6000",..: 2 1 NA 3 1 3 NA 3 2 3 ...
## $ Schulabschluss: Factor w/ 4 levels "Bachelor","Master",..: 3 1 3 2 3 1 3 4 4 3 ...
## $ Land : Factor w/ 4 levels "Deutschland",..: 4 2 1 4 1 1 3 1 1 4 ...15.3.2 Aufgabe 5.2
Aufgabenstellung: Lassen Sie sich die Werte, die die Variable “Land” annimmt, ausgeben. Wie können Sie R ausgeben lassen, wie häufig jedes Land insgesamt vorkommt?
Sie sehen, dass das Land Deutschland einmal ausgeschrieben (“Deutschland”) und einmal verkürzt (“Dt”) angegeben ist. Das scheint ein Fehler zu sein. Ersetzen Sie für alle Fälle, bei denen das Land Deutschland mit “Dt” abgekürzt wurde, die Werte mit “Deutschland”.
Lösung:
##
## Deutschland Dt Italien Schweiz
## 1242 1227 1265 1266data$Land[data$Land=="Dt"] <- "Deutschland" #so ersetzen Sie "Dt" durch "Deutschland"
table(data$Land) #schauen Sie, dass die Manipulation funktioniert hat##
## Deutschland Dt Italien Schweiz
## 2469 0 1265 126615.3.3 Aufgabe 5.3
Aufgabenstellung: Reduzieren Sie Ihre Daten: Erstellen Sie einen neuen Datensatz data_schweiz, der nur Befragte enthält, die aus der Schweiz kommen. Ausserdem sollen hier nur die Variablen “Alter”, “Geschlecht” “Land”, und “Einkommen” (in dieser Reihenfolge der Variablen) vorhanden sein.
Lösung:
data_schweiz <- data[data$Land=="Schweiz", c("Alter", "Geschlecht", "Land", "Einkommen")]
str(data_schweiz) #schauen Sie, dass die Manipulation funktioniert hat## 'data.frame': 1266 obs. of 4 variables:
## $ Alter : int 36 61 73 69 20 34 19 51 28 66 ...
## $ Geschlecht: Factor w/ 2 levels "männlich","weiblich": 1 1 2 1 NA NA 1 NA NA 2 ...
## $ Land : Factor w/ 4 levels "Deutschland",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ Einkommen : Factor w/ 3 levels "0-3000","3000-6000",..: 2 3 3 3 NA 2 2 NA NA 1 ...15.3.4 Aufgabe 5.4
Aufgabenstellung: Reduzieren Sie Ihre Daten noch weiter. Bitte überschreiben Sie Ihren Datensatz data_schweiz und behalten Sie nur Fälle, in denen die Befragten NICHT 25, 35, 45 oder 55 Jahre alt sind.
Lösung:
15.4 Lösungen zu Tutorial 6
15.4.1 Aufgabe 6.1
Aufgabenstellung: Lesen Sie den Datensatz ein. Lassen Sie sich folgende deskriptive Statistiken herausgeben:
- wie oft welcher Schulabschluss im Datensatz vorkommt (absolute Anzahl)
- den Mittelwert des Alters (gerundet auf 1 Nachkommastelle)
- die Standardabweichung des Alters (gerundet auf 1 Nachkommastelle)
Lösung:
##
## Bachelor Master Matura Realschule
## 1277 1252 1230 1241## [1] 46.5## [1] 16.515.4.2 Aufgabe 6.2
Aufgabenstellung: Können Sie mit R berechnen, wie oft welcher Schulabschluss je Land vorkommt (in absoluten Werten)? Erstellen Sie einen neuen Dataframe mit dem Namen data2, in dem Sie die absolute Anzahl an Schulabschlüssen je Land abspeichern.
Tipp: Sie müssen sich die absolute Häufigkeit der Schulabschlüsse ausgeben lassen und diese als Dataframe abspeichern. Der Dataframe data2 soll drei Spalten (d.h., Variablen) beinhalten, die Spaltennamen “Land”, “Schulabschluss” und “absolut” tragen.
Achtung: Hier könnte googlen helfen, um herauszufinden, wie man Spaltennamen eines Dataframes setzt.
Lösung:
##
## Deutschland Dt Italien Schweiz
## 1242 1227 1265 1266#Wir vereinheitlichen die Namen für die Länder
data$Land[data$Land=="Dt"] <- "Deutschland"
table(data$Land) #Vereinheitlicht?##
## Deutschland Dt Italien Schweiz
## 2469 0 1265 1266#Wir geben uns die Schulabschlüsse je Land aus (und zwar in Form eines Dataframes, um Spalten benennen zu können)
data2 <- as.data.frame(table(data$Land, data$Schulabschluss))
#Wir benennen die Spalten richtig
colnames(data2) <- c("Land", "Schulabschluss", "absolut")
str(data2)## 'data.frame': 16 obs. of 3 variables:
## $ Land : Factor w/ 4 levels "Deutschland",..: 1 2 3 4 1 2 3 4 1 2 ...
## $ Schulabschluss: Factor w/ 4 levels "Bachelor","Master",..: 1 1 1 1 2 2 2 2 3 3 ...
## $ absolut : int 609 0 346 322 606 0 319 327 604 0 ...15.4.3 Aufgabe 6.3
Aufgabenstellung: Erstellen Sie einen neuen Dataframe mit dem Namen data3, der nur Teilnehmer:innen enthält, die weiblich sind und über 54, aber unter 68 Jahre alt. Lassen Sie sich dann die Anzahl Teilnehmer:innen ausgeben, indem Sie die Zeilen dieses Dataframes zählen.
Wichtig: Achten Sie darauf, dass Sie nur Teilnehmer:innen behalten, die sowohl Alter als auch Geschlecht angegeben haben, d.h. es sollten im Dataframe data3 keine fehlenden Werte bei diesen Variablen vorhanden sein.
Lösung:
#Wir filtern nach Geschlecht & Alter
#Ausserdem schliessen wir fehlende Angaben bei Geschlecht & Alter aus.
data3 <- data[data$Geschlecht=="weiblich" & data$Alter>54 & data$Alter<68 &
is.na(data$Geschlecht) == FALSE & is.na(data$Alter)==FALSE,]
nrow(data3)## [1] 39015.4.4 Aufgabe 6.4
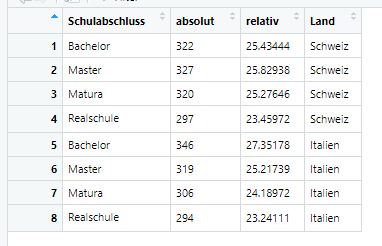
Aufgabenstellung: Bitte erstellen Sie einen neuen Dataframe data4, der nur für Befragte aus der Schweiz und Italien folgende Informationen enthält:
- die absolute Anzahl an Schulabschlüssen (getrennt ausgewiesen für Schweizer und Italiener Befragte)
- die relative Anzahl an Schulabschlüssen (getrennt ausgewiesen für Schweizer und Italiener Befragte)
Der endgültige Dataframe soll so aussehen:
Zu erstellender Datensatz in Aufgabe 6.5
Lösung: Hier gibt es nicht eine Lösung, sondern mehrere. Viele Packages bieten Funktionen dafür. Wir gehen hier “händisch”, d.h. ohne Hilfe eines Packages vor - es gibt aber zahlreiche andere (effizientere und schnellere) Lösungen.
#Wir reduzieren unseren Datensatz auf Schweizer:innen und Italiener:innen:
data4 <- data[data$Land=="Schweiz"|data$Land == "Italien",]
#Wir lassen uns die absoluten und relativen Beobachtungen herausgeben,
#allerdings getrennt nach Land
#Schweiz
#absolut
data4a <- as.data.frame(table(data$Schulabschluss[data$Land=="Schweiz"]))
#relativ
data4a$relativ <- data4a$Freq/sum(data4a$Freq)*100
#Land
data4a$Land <- rep("Schweiz",4)
#Italien
#absolut
data4b <- as.data.frame(table(data$Schulabschluss[data$Land=="Italien"]))
#relativ
data4b$relativ <- data4b$Freq/sum(data4b$Freq)*100
#Land
data4b$Land <- rep("Italien",4)
#wir führen beide Dataframes zusammen
data4 <- rbind(data4a,data4b)
colnames(data4) <- c("Schulabschluss", "absolut", "relativ", "Land")
str(data4)## 'data.frame': 8 obs. of 4 variables:
## $ Schulabschluss: Factor w/ 4 levels "Bachelor","Master",..: 1 2 3 4 1 2 3 4
## $ absolut : int 322 327 320 297 346 319 306 294
## $ relativ : num 25.4 25.8 25.3 23.5 27.4 ...
## $ Land : chr "Schweiz" "Schweiz" "Schweiz" "Schweiz" ...15.5 Lösungen zu Tutorial 7
15.5.1 Aufgabe 7.1
Aufgabenstellung: Lesen Sie den Datensatz ein. Schreiben Sie eine if_else-Bedingung, die Variable Land folgendermassen verändert:
Alle Teilnehmer:innen, die aus “Deutschland” oder der “Schweiz” kommen, sollen für die Variable Land den Wert “deutschsprachig” aufweisen. Alle Teilnehmer:innen, die aus “Frankreich” oder “Italien” kommen, sollen für die Variable Land den Wert “nicht deutschsprachig” aufweisen.
Wichtig: Diese Transformation soll nur durchgeführt werden, falls nicht mehr als 100 Befragte aus Deutschland an der Umfrage teilgenommen werden. Ansonsten sollen die Werte der Variable Land für alle Teilnehmer:innen, die aus “Deutschland” kommen den Wert “deutschsprachig” und für alle anderen Teilnehmer:innen den Wert “nicht deutschsprachig” annehmen.
Lösung:
data$Land <- as.character(data$Land)
# Die Funktion in der if-Bedingung wird nur durchgeführt,
# falls maximal 100 Teilnehmer:innen aus Deutschland kommen
if (sum(nrow(data[data$Land=="Deutschland",])) < 101){
data$Land[data$Land=="Deutschland"|
data$Land=="Schweiz"] <- "deutschsprachig"
data$Land[data$Land=="Frankreich"|
data$Land=="Italien"] <- "nicht deutschsprachig"
# ansonsten wird die nachfolgende Funktion durchgeführt
} else {
data$Land[data$Land=="Deutschland"] <- "deutschsprachig"
data$Land[data$Land=="Frankreich"|
data$Land=="Italien"|data$Land=="Schweiz"] <- "nicht deutschsprachig"
}
table(data$Land)##
## deutschsprachig nicht deutschsprachig
## 250 75015.5.2 Aufgabe 7.2
Aufgabenstellung: Schreiben Sie einen for-Loop, der für alle Fälle der Variablen Vertrauen_Politik die ursprünglichen Werte um 0.5 erhöht, d.h., für jeden Fall .5 zum ursprünglichen Variablenwert hinzufügt.
Lösung: Sie müssen für jede Zeile i des Dataframes data eine Summe von 0.5 hinzufügen.
## [1] 2.545#Loop wird durchgeführt
for (i in 1:nrow(data)){
data$Vertrauen_Politik[i] <- data$Vertrauen_Politik[i]+.5
}
# Mittelwert nach Loop
mean(data$Vertrauen_Politik)## [1] 3.04515.6 Lösungen zu Tutorial 9
15.6.1 Aufgabe 9.1
Aufgabenstellung:
Bitte ersetzen sie alle Leerzeichen im Text durch das Wort Leerzeichen und speichern die manipulierten Sätze im Vektor sentences_new ab.
Lösung:
sentences <-c("Climate change is a crisis all across the world - but how come we've not taken it serious?",
"CLIMATE CHANGE - the world issue that strikes specifically the poorest around the globe.",
"Global warming is a problem, but we've known that for a while now.",
"Climate scepticism under the microscope: A debate between scientists and scepticists across the world",
"No one's safe? Why this might, after all, not be true when it comes to global warming",
"We've failed: The climate crisis is dooming")Wir ersetzen dann mit der gsub-Funktion alle Leerzeichen, die dem pattern [[:blank:]] entsprechend, durch das replacement Leerzeichen.
sentences_new <- gsub(pattern="[[:blank:]]", replacement = "Leerzeichen", x = sentences)
sentences_new## [1] "ClimateLeerzeichenchangeLeerzeichenisLeerzeichenaLeerzeichencrisisLeerzeichenallLeerzeichenacrossLeerzeichentheLeerzeichenworldLeerzeichen-LeerzeichenbutLeerzeichenhowLeerzeichencomeLeerzeichenwe'veLeerzeichennotLeerzeichentakenLeerzeichenitLeerzeichenserious?"
## [2] "CLIMATELeerzeichenCHANGELeerzeichen-LeerzeichentheLeerzeichenworldLeerzeichenissueLeerzeichenthatLeerzeichenstrikesLeerzeichenspecificallyLeerzeichentheLeerzeichenpoorestLeerzeichenaroundLeerzeichentheLeerzeichenglobe."
## [3] "GlobalLeerzeichenwarmingLeerzeichenisLeerzeichenaLeerzeichenproblem,LeerzeichenbutLeerzeichenwe'veLeerzeichenknownLeerzeichenthatLeerzeichenforLeerzeichenaLeerzeichenwhileLeerzeichennow."
## [4] "ClimateLeerzeichenscepticismLeerzeichenunderLeerzeichentheLeerzeichenmicroscope:LeerzeichenALeerzeichendebateLeerzeichenbetweenLeerzeichenscientistsLeerzeichenandLeerzeichenscepticistsLeerzeichenacrossLeerzeichentheLeerzeichenworld"
## [5] "NoLeerzeichenone'sLeerzeichensafe?LeerzeichenWhyLeerzeichenthisLeerzeichenmight,LeerzeichenafterLeerzeichenall,LeerzeichennotLeerzeichenbeLeerzeichentrueLeerzeichenwhenLeerzeichenitLeerzeichencomesLeerzeichentoLeerzeichenglobalLeerzeichenwarming"
## [6] "We'veLeerzeichenfailed:LeerzeichenTheLeerzeichenclimateLeerzeichencrisisLeerzeichenisLeerzeichendooming"15.6.2 Aufgabe 9.2
Aufgabenstellung:
Bitte weisen Sie R an, auszugeben, wie oft das pattern climate change in Klein- oder Grossschreibung in jedem Satz im Vektor sentences vorkommt.
Lösung:
Wir suchen dann nach dem pattern climate change. Dabei formulieren wir unsere Suchanfrage so, dass jeder Buchstabe des Wortes climate change in Gross- oder Kleinschreibung gefunden wird.
str_count(string = sentences,
pattern = "[c|C][l|L][i|I][m|M][a|A][t|T][e|E] [c|C][h|H][a|A][n|N][g|G][e|E]")## [1] 1 1 0 0 0 015.6.3 Aufgabe 9.3
Aufgabenstellung:
Bitte weisen Sie R an, auszugeben, wie oft das pattern climate change in Klein- oder Grossschreibung in jedem Satz im Vektor sentences vorkommt.
Lösung:
sum(str_count(string = sentences,
pattern = "[c|C][l|L][i|I][m|M][a|A][t|T][e|E] [c|C][h|H][a|A][n|N][g|G][e|E]"))## [1] 215.6.4 Aufgabe 9.4
Aufgabenstellung:
Sagen wir, Sie wollen diese Sätze etwas “formaler” umschreiben.
Ersetzen Sie alle englischen, etwas umgangssprachlichen Verkürzungen in Form des patterns we’ve (egal ob in Klein- oder Grossschreibung) durch das pattern we have und speichern sie die manipulierten Sätze im Vektor sentences_new ab.
Lösung:
sentences_new <- gsub(pattern = "we've|We've",
replacement = "we have", x = sentences)
sentences_new## [1] "Climate change is a crisis all across the world - but how come we have not taken it serious?"
## [2] "CLIMATE CHANGE - the world issue that strikes specifically the poorest around the globe."
## [3] "Global warming is a problem, but we have known that for a while now."
## [4] "Climate scepticism under the microscope: A debate between scientists and scepticists across the world"
## [5] "No one's safe? Why this might, after all, not be true when it comes to global warming"
## [6] "we have failed: The climate crisis is dooming"15.7 Lösungen zu Tutorial 10
15.7.1 Aufgabe 10.1
Aufgabenstellung: Laden Sie den Textkorpus über das R-Environment immigration_news.rda. Können Sie R anweisen, Ihnen auszugeben, wie viele Types und Tokens im ersten Dokument vorkommen? Lösung:
library("quanteda")
#So lassen wir uns die Summer aller Tokens im ersten Dokument ausgeben
ntoken(data$text[1])## text1
## 449## text1
## 26615.7.2 Aufgabe 10.2
Aufgabenstellung: Können Sie R dann anweisen, Ihnen auszugeben, wie viele Types und Tokens in allen Dokumenten vorkommen, d.h. die Summe aller Types bzw. Tokens?
Erklären Sie kurz, wieso Sie die sich die Summe aller Types und die Summe aller Tokens unterscheiden.
Lösung:
## [1] 1217545Da die Aufgabenstellung etwas unklar formuliert war, gibt es zwei Lösungen für die Summe aller Types, die aber zu unterschiedlichen Ergebnissen führen.
## [1] 688285## [1] 41995Lösung 1:
Die erste Lösung gibt euch die Anzahl aller individuellen Features (= Types) je Text als Summe aus und zählt diese dann zusammen. D.h., wenn ein Typ in mehreren Doks vorkommt (etwa “and” in Text 1 und Text 2, wird es mehrfach gezählt, d.h. wird zweifach gewertet. Das Ergebnis (688,284) bezeichnet die Summe aller Types je Text, addiert für alle Texte. D.h., Types werden ggf. mehrfach gezählt, wenn sie in mehr als einem Text vorkommen.
Lösung 2:
Die zweite Lösung gibt euch die Anzahl aller individuellen Features (= Types) über alle Texte hinweg aus. D.h., wenn ein Typ in mehreren Doks vorkommt, wird es nur einmal gezählt. Das Ergebnis (41,995) bezeichnet die Anzahl aller Types über Texte hinweg, d.h. jedes individuelle Feature wird nur einmal gezählt.
Sinnvoller ist vermutlich die zweite Lösung - da die Aufgabenstellung aber nicht eindeutig war, sind beide möglich.
15.7.3 Aufgabe 10.3
Aufgabenstellung: Können Sie R anweisen, Ihnen nur Texte vom 15. April oder vom 15. Mai in einem corpus-Objekt mit dem Namen Texte_Tage auszugeben? Wie viele Dokumente erhalten Sie?
Lösung: Wir müssen die Monate und die Tage aus den Texten herauslesen, um die Texte nach Publikationsdatum zu filtern-
Wir könnten uns z.B. entschliessen, den Monat und den Tag der Publikation in jeweils einer separaten Variable abzuspeichern. Wir lesen zunächst den ganzen Text-String heraus, der sowohl den Monat als auch den Tag enthält. Dann speichern wir den Monat ab - diesen Befehl kennen Sie schon.
library("stringr")
#Wir lesen den String aus
data$month <- str_extract(string = data$text,
pattern = "[0-9]+ (january|february|march|april|may|june|july|
august|september|october|november|december) 2014")
#Wir behalten nur den Monats-String
data$month <- str_extract(string = data$month,
pattern = "january|february|march|april|may|june|july|
august|september|october|november|december")
table(data$month)##
## april february march may
## 835 252 933 813Jetzt müssen wir einen angepassten Search-String benutzen, der nur den Tag herausliest.
Wir lesen zunächst den ganzen Text-String heraus, der sowohl den Monat als auch den Tag enthält.
Dann können wir einen Trick verwenden: Wir wissen, dass die Anzahl an Tagen ganz am Anfang des Textes vorkommt. str_extract() gibt immer nur den ersten Match zurück, den das pattern im string enthält. Wir suchen also nach einer mindestens einstelligen Zahlenkombination am Anfang des Strings:
#Wir lesen den String aus
data$day <- str_extract(string = data$text,
pattern = "[0-9]+ (january|february|march|april|may|june|july|
august|september|october|november|december) 2014")
#Wir behalten nur den Tages-String
data$day <- str_extract(string = data$day,
pattern = "[0-9]+")
table(data$day)##
## 1 10 11 12 13 14 15 16 17 18 19 2 20 21 22 23 24 25 26 27 28 29 3 30 31 4 5 6 7 8
## 81 100 99 41 55 106 92 63 115 68 85 98 93 96 163 68 114 103 116 93 146 66 121 47 30 84 65 96 124 97
## 9
## 108Das sieht gut aus: R hat nur Zahlen zwischen 1 und 31 ausgelesen.
Jetzt erstellen wir eine neue Variable, die Datum heisst, indem wir die Vektoren data\(day_ sowie _data\)month aneinander “kopieren”. Dafür nutzen wir den paste()-Befehl:
## [1] "10 april"Danach behalten wir nur noch die Texte, die am 15. April oder Mai vorkommen.
Wir wandeln den Dataframe zu einem corpus-Objekt um und lassen uns die Anzahl Dokumente ausgeben. Wir erhalten einen Corpus mit 68 Dokumenten.
## Corpus consisting of 68 documents and 3 docvars.
## text116 :
## " news migration soaring as another 167000 get jobs in brit..."
##
## text117 :
## " news brick attack on ukip mep in new raid by left thugs a..."
##
## text118 :
## " editorial opinion columns dont be fooled by a tiny drop i..."
##
## text119 :
## "'extremist thugs' threw a brick at my home says ukip mep by ..."
##
## text330 :
## " comment politically scotland has already left the union b..."
##
## text380 :
## " national news lifted visa curbs loosen no flood of immigr..."
##
## [ reached max_ndoc ... 62 more documents ]15.7.4 Aufgabe 10.4
Aufgabenstellung: Können Sie im dataframe data, d.h. für den vollen Korpus, eine Variable data$headline erstellen, welche nur die Überschrift des jeweiligen Artikels enthält? Die Überschrift des jeweiligen Artikels wird hier als der Text verstanden, der vor der Wörteranzahl im Artikel erscheint. Sie wollen also einfach den gesamten Text auslesen, der vor der Wörteranzahl des jeweiligen Artikels genannt wird.
Lösung: Wir wissen, dass die Überschrift des jeweiligen Artikels immer dem Ausdruck words genannt wird.
Wir nutzen einen Trick: Wir lesen den gesamten Text heraus, der nach dem pattern mindestens einstellige Zahl, Leerzeichen, words genannt wird und ersetzen ihn durch ein Leerzeichen. So erhalten wir nur den Text vor dem Stoppwort word, d.h., die Überschrift:
15.8 Lösungen zu Tutorial 11
15.8.1 Aufgabe 11.1
Aufgabenstellung:
Wandeln Sie das dataframe-Objekt data in ein corpus-Objekt um, das den Präsidenten, der eine Rede gehalten hat, als auch den Monat der Rede als document-level-Variable enthält.
Brechen Sie den Korpus dann durch Tokenization auf seine Features herunter, wobei Sie den Text nicht auf einzelne Wörter als Features, sondern auf einzelne Sätze als Analyseeinheit herunterbrechen sollen. (Tipp: Schauen Sie sich den corpus_reshape-Befehl an).
Lösung:
Zunächst laden wir den Korpus.
Wir lesen zunächst den Monat der Rede als neue Variable heraus:
library("stringr")
data$month <- str_extract(data$Date, pattern = "-[0-9]{2}-")
data$month <- str_extract(data$month, pattern = "[0-9]{2}")Anschliessen wandeln wir unsere Texte in ein corpus-Objekt um und lesen die beiden document-level-Variablen ein:
library("quanteda")
#Umwandlung in ein Corpus-Objekt
data_sentences <- corpus(data$text, docvars = data.frame(president = data$President,
month = data$month))Zuletzt nutzen wir den Befehl corpus_reshape, um uns in jeder Zeile nicht einen ganzen Text, sondern einzelne Sätze ausgeben zu lassen:
15.8.2 Aufgabe 11.2
Aufgabenstellung:
Entfernen Sie alle Satzzeichen & Nummern aus dem corpus-Objekt data_sentences, wandeln Sie den Text in Kleinschreibung um und entfernen Sie die von quanteda-vorgegebene Liste von English-language-Stopwörtern.
Lösung:
Wir wandeln unser corpus-Objekt zu einem tokens-Objekt um und nutzen die entsprechenden Befehle zur Bereinigung. Wir nutzen hier die dplyr-Pipe, um alle Befehle in einem verketteten Befehl durchzuführen.
15.8.3 Aufgabe 11.3
Aufgabenstellung:
Können Sie herausfinden, wie viele Sätze Ihr Korpus insgesamt enthält?
Lösung:
## [1] 7013715.9 Lösungen zu Tutorial 12
Hier finden Sie die Lösungen zu Tutorial 12.
15.9.1 Aufgabe 12.1
Aufgabenstellung: Laden Sie den Korpus. Lassen Sie sich nur die Reden der demokratischen und republikanischen Präsidenten ausgeben (“Democratic” oder “Republican” in der party-Variable). Was sind die 10 Top Features bei Reden demokratischer vs. republikanischer Präsidenten?
Hinweis: Sie brauchen hier und in späteren Aufgaben keine Bereinigungs-Schritte vornehmen. Wandeln Sie den Text einfach so, wie er vorliegt, um.
Lösung: Zunächst laden wir den Korpus.
Dann filtern wir nach Partizugehörigkeit, wandeln den Datensatz in einen Corpus mit den entsprechenden document-level-Variablen um und erstellen mit dem gefilterten Datensatz ein DFM-Objekt:
data_grouped <- data[data$party=="Democratic"|data$party=="Republican",]
data_grouped <- corpus(data_grouped$text,docvars = data.frame(party = data_grouped$party))
dfm <- dfm(data_grouped) %>%
dfm_group(groups = "party")
dfm## Document-feature matrix of: 2 documents, 32,675 features (28.1% sparse) and 1 docvar.
## features
## docs fellow citizens of the senate and house representatives : it
## Democratic 126 805 42465 66813 271 29688 244 202 927 6795
## Republican 72 734 50092 78151 300 31256 224 275 807 7228
## [ reached max_nfeat ... 32,665 more features ]## $Democratic
## the of , . to and in a that our
## 66813 42465 39523 31233 30002 29688 17951 13099 10699 9748
##
## $Republican
## the of , . and to in a that for
## 78151 50092 43909 34556 31256 30083 21127 14833 10597 1054715.9.2 Aufgabe 12.2
Aufgabenstellung: Lassen Sie sich für den vollen Datensatz mit allen 241 Reden das relative Vorkommen der Features “threat” über die Jahre hinweg ausgeben.
Lösung: Wir lesen zunächst eine Variable aus, die das Jahr der jeweiligen Rede bezeichnet.
#Wir wandeln die Variable in einen Charakter um
data$year <- as.character(data$Date)
#Wir lesen das Jahr aus
library("stringr")
data$year <- str_extract(data$year, "[0-9]{4}")Dann erstellen wir eine DFM, welche uns das relative Vorkommen aller Features nach Jahrausgibt:
data_grouped <- corpus(data$text,docvars = data.frame(year = data$year))
dfm <- dfm(data_grouped) %>%
dfm_group(groups = "year") %>%
dfm_weight(scheme = "prop")
dfm## Document-feature matrix of: 230 documents, 33,752 features (94.5% sparse) and 1 docvar.
## features
## docs fellow-citizens of the senate and house representatives :
## 1790 0.0007496252 0.05922039 0.08208396 0.0014992504 0.03223388 0.002248876 0.0022488756 0.0022488756
## 1791 0.0004046945 0.06434642 0.09793606 0.0012140834 0.02954270 0.001214083 0.0012140834 0.0016187778
## 1792 0.0004382121 0.06091148 0.08545136 0.0008764242 0.02453988 0.001314636 0.0013146363 0.0013146363
## 1793 0.0004725898 0.06238185 0.08506616 0.0009451796 0.02315690 0.001417769 0.0014177694 0.0014177694
## 1794 0.0003132832 0.05858396 0.08552632 0.0006265664 0.02694236 0.001253133 0.0009398496 0.0009398496
## 1795 0.0004653327 0.06049325 0.08096789 0.0018613309 0.03396929 0.001861331 0.0018613309 0.0018613309
## features
## docs i embrace
## 1790 0.007121439 0.0003748126
## 1791 0.002428167 0
## 1792 0.009202454 0
## 1793 0.005671078 0
## 1794 0.005639098 0
## 1795 0.005583993 0
## [ reached max_ndoc ... 224 more documents, reached max_nfeat ... 33,742 more features ]Schliesslich lassen wir uns nur das Vorkommen der Features threat ausgeben:
## feature frequency rank docfreq group
## 37107 threat 1.190902e-04 743 1 1826
## 74588 threat 9.995002e-05 897 1 1844
## 100942 threat 7.951022e-05 1030 1 1855
## 185048 threat 1.343093e-04 740 1 1892
## 218135 threat 9.459843e-05 936 1 1902
## 235413 threat 3.363040e-05 2078 1 1907
## 265837 threat 1.607976e-04 639 1 1922
## 275701 threat 1.043950e-04 873 1 1927
## 279969 threat 8.400538e-05 1052 1 1929
## 286286 threat 2.604845e-04 416 1 1935
## 288404 threat 3.363606e-04 335 1 1937
## 292293 threat 8.296460e-04 147 1 1941
## 295156 threat 1.996008e-04 460 1 1943
## 297714 threat 1.620352e-04 663 1 1945
## 300035 threat 9.703713e-05 1031 1 1946
## 302952 threat 3.020692e-04 428 1 1947
## 304892 threat 1.793722e-04 593 1 1948
## 307613 threat 1.124859e-03 123 1 1951
## 308633 threat 1.013000e-03 144 1 1952
## 310299 threat 2.692225e-04 428 1 1953
## 313435 threat 3.033520e-04 428 1 1954
## 314904 threat 3.728097e-04 347 1 1955
## 316669 threat 3.909686e-04 336 1 1956
## 318507 threat 8.775779e-04 145 1 1957
## 319733 threat 1.273654e-03 102 1 1958
## 322162 threat 1.825484e-04 565 1 1959
## 323811 threat 1.610306e-04 643 1 1960
## 325270 threat 1.576417e-04 733 1 1961
## 328411 threat 1.349346e-04 720 1 1962
## 329162 threat 6.631300e-04 180 1 1963
## 332025 threat 4.100882e-04 291 1 1965
## 335569 threat 1.248284e-04 768 1 1967
## 336449 threat 3.610108e-04 338 1 1968
## 337712 threat 4.358248e-04 262 1 1969
## 341734 threat 1.281504e-04 828 1 1972
## 345746 threat 9.934433e-05 1052 1 1974
## 349862 threat 3.627789e-04 352 1 1976
## 354265 threat 5.442473e-05 1447 1 1978
## 356689 threat 7.342144e-05 1264 1 1979
## 358999 threat 4.213448e-04 325 1 1980
## 363497 threat 3.108560e-04 424 1 1981
## 371519 threat 3.601657e-04 343 1 1984
## 373494 threat 2.116850e-04 512 1 1985
## 374293 threat 5.121639e-04 243 1 1986
## 376867 threat 3.715400e-04 341 1 1988
## 380062 threat 2.319109e-04 444 1 1990
## 380753 threat 4.476276e-04 250 1 1991
## 386840 threat 1.967536e-04 521 1 1995
## 389052 threat 1.423690e-04 661 1 1996
## 390041 threat 2.652168e-04 438 1 1997
## 391728 threat 2.446184e-04 467 1 1998
## 394147 threat 1.191185e-04 770 1 1999
## 395450 threat 1.972970e-04 562 1 2000
## 398777 threat 2.319647e-04 463 1 2002
## 399216 threat 1.657275e-03 74 1 2003
## 401234 threat 3.452443e-04 354 1 2004
## 402690 threat 3.511236e-04 334 1 2005
## 406342 threat 1.625488e-04 628 1 2007
## 409510 threat 1.492760e-04 622 1 2009
## 411200 threat 1.259129e-04 748 1 2010
## 412849 threat 1.307702e-04 724 1 2011
## 414038 threat 2.537427e-04 473 1 2012
## 415433 threat 5.439217e-04 242 1 2013
## 417491 threat 2.609944e-04 473 1 2014
## 419064 threat 3.974036e-04 323 1 2015
## 420918 threat 2.968240e-04 386 1 2016
## 424658 threat 1.488317e-04 672 1 2018
## 426321 threat 1.577536e-04 644 1 2019
## 428084 threat 1.409443e-04 730 1 202015.9.3 Aufgabe 12.3
Aufgabenstellung: Können Sie sich die Länge der Rede, d.h. die durchschnittliche Anzahl an Features je Rede, über die Jahre hinweg ausgeben lassen? Achten Sie darauf, dass es teils mehrere Reden je Jahr gibt. D.h., Sie müssen die durchschnittliche Anzahl an Features über verschiedene Reden hinweg je Jahr berechnen.
Lösung:
15.9.4 Aufgabe 12.4
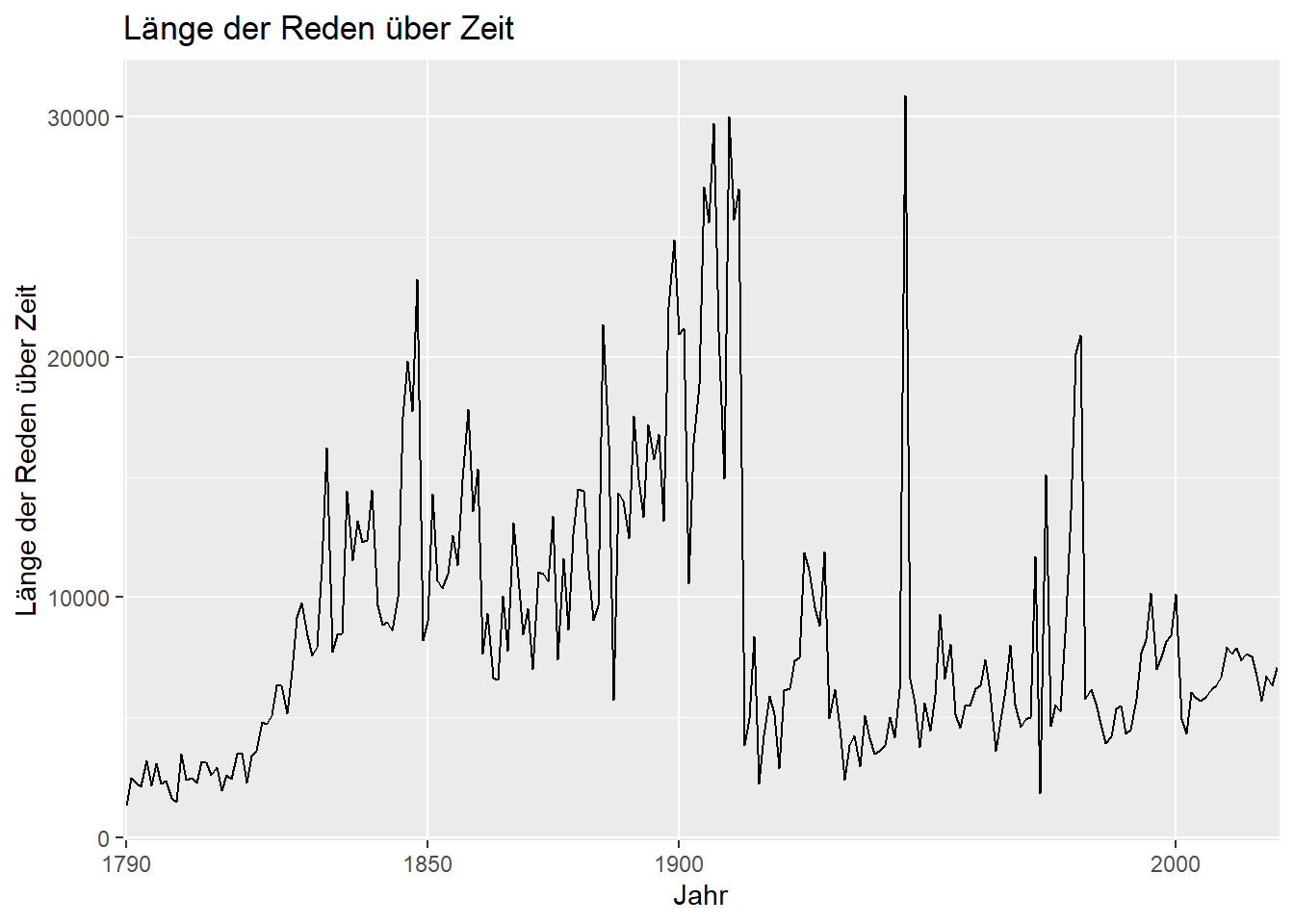
Aufgabenstellung: Visualisieren Sie die Ergebnisse aus Aufgabe 12.3. Welche Art der Visualisierung bzw. welchen Graphentyp Sie nutzen, ist egal. Wichtig ist nur, dass die x-Achse das Jahr der Rede und die y-Achse die durchschnittliche Anzahl an Wörtern der jeweiligen Rede(n) enthält.
Wenn Sie die Aufgabe 12.3 nicht lösen konnten, visualisieren Sie bitte einfach die Anzahl an Reden je Jahr. Wichtig ist dass, dass die x-Achse das Jahr der Rede und die y-Achse die Anzahl an Reden je Jahr enthält.
Lösung:
library("ggplot2")
ggplot(data_grouped, aes(x = year, y = length, group = 1)) +
geom_line() +
labs(y = "Länge der Reden über Zeit", x = "Jahr",
title = "Länge der Reden über Zeit") +
scale_x_discrete(breaks = c("1790", "1850", "1900", "2000"))