12 Tutorial 12: Deskriptive Statistik & Diktionaere
In Tutorial 12 lernen Sie erste Analyseverfahren für Text kennen, spezifisch:
- Wie Sie deskriptive Statistiken zu Ihrem Korpus enthalten
- wie Sie die (gruppierte) Häufigkeit von Features analysieren
- Was Keywords-in-Context sind und wie Sie diese analysieren
- Was Ko-Okkurrenzen sind und wie Sie diese analysieren
- Was Dikitionäre sind und wie Sie mit Hilfe dieser Text analysieren
Wir arbeiten wieder mit einem Text-Korpus, der im R-Package Quanteda bzw. Quanteda-Corpora Quanteda-Corpora-Package zurzeit im Entwicklungsmodus bereits enthalten ist.
Sie finden den Korpus in OLAT (via: Materialien / Datensätze für R) mit dem Namen immigration_news.rda. Bei diesen Dateien handelt es sich um Nachrichtenartikel aus Grossbritannien zum Thema Immigration aus dem Jahr 2014, die (leicht bearbeitet) bereits als R-Environment abgespeichert wurde. Die Daten befinden sich in einem ähnlichen Format, wie Sie sie erhalten würden, wenn Sie ihre Text mit dem readtext-Package einlesen würden.
Quelle der Daten: Nulty, P. & Poletti, M. (2014). “The Immigration Issue in the UK in the 2014 EU Elections: Text Mining the Public Debate.” Presentation at LSE Text Mining Conference 2014. Geladen via dem Quanteda-Corpus_Package.
Bitte laden Sie den Datensatz in Ihr R-Environment.
Wir bereiten den Korpus zunächst für eine Analyse grob vor (wie bereits in den letzten Tutorials gezeigt):
- Wir speichern den Publikationsmonat der Dokumente ab, um diesen später für Vergleiche über Zeit anwenden zu können.
- Wir entfernen das pattern für einen Zeilenumbruch \n
- Wir führen die üblichen Preprocessing-Schritte durch, die im vorherigen Tutorial bereits erklärt wurden. Hier nutzen wir allerdings nur einige der vorab genannten Schritte.
#Wir lesen den Publikationsmonat heraus
library("stringr")
library("quanteda")
data$month <- str_extract(string = data$text,
pattern = "january|february|march|april|may|june|july|
august|september|october|november|december")
#Entfernung pattern Zeilenumbruch
data$text <- gsub(pattern = "\n", replacement = " ", x = data$text)
#Bereinigung durch Entfernung von Satzzeichen, Nummern, Kleinschreibung, etc.
tokens <- data$text %>%
tokens(what = "word",
remove_punct = TRUE,
remove_numbers = TRUE,
remove_url = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("english"))
#Entfernung häufiger/seltener Wörter
dfm <- dfm_trim(dfm(tokens), min_docfreq = 0.005, max_docfreq = 0.99,
docfreq_type = "prop", verbose = TRUE)## Removing features occurring:## - in fewer than 14.165 documents: 33,992## - in more than 2804.67 documents: 2## Total features removed: 33,994 (86.8%).## Document-feature matrix of: 2,833 documents, 5,162 features (97.1% sparse).
## features
## docs support ukip continues grow labour heartlands miliband scared leo mckinstry
## text1 2 7 1 1 8 2 4 1 1 1
## text2 0 1 0 0 0 0 0 0 0 0
## text3 0 1 0 0 0 0 0 0 0 0
## text4 0 0 0 0 0 0 0 0 0 0
## text5 0 1 0 0 0 0 0 0 0 0
## text6 0 0 0 0 0 0 0 0 0 0
## [ reached max_ndoc ... 2,827 more documents, reached max_nfeat ... 5,152 more features ]12.1 Deskriptive Statistiken zu Ihrem Korpus
12.1.1 Anzahl Dokumente
Zunächst wollen Sie wissen, wie viele Dokumente der Korpus enthält. Dafür nutzen den ndoc()-Befehl. Wir sehen: Es sind rund 2,800 Artikel.
## [1] 283312.1.2 Anzahl Features
Dann wollen wir wissen, wie viele Features der Korpus enthält. Wir sehen: Es sind etwas mehr als 5,000 Features nach der Bereinigung übrig geblieben.
## [1] 516212.1.3 Feature-Vorkommen
Lassen wir uns für jedes Feature jetzt ausgeben, wie häufig dieses vorkommt. Wir nutzen dafür den featfreq()-Befehl und speichern das Ergebnis in einem neuen dataframe-Objekt ab.
Die Namen der jeweiligen Features sind jetzt noch in den Zeilennamen abgespeichert, aber nicht als eigene Spalte. Wir nutzen den rownames-Befehl, um die Namen der jeweiligen Features als Variablen abzuspeichern:
## freq feature
## support 716 support
## ukip 3606 ukip
## continues 60 continues
## grow 72 grow
## labour 2144 labour
## heartlands 29 heartlands
## miliband 580 miliband
## scared 57 scared
## leo 29 leo
## mckinstry 20 mckinstrySo können wir uns z.B. ausgeben lassen, wie häufig ein bestimmtes Feature vorkommt, etwa das Wort crisis. Da wir kein Stemming benutzt haben, sollten wir daran denken, dass Features hier nicht mit ihren Wortstämmen vorliegen. Sonst müssten wir z.B. nach dem pattern cris suchen.
Jetzt suchen wir also z.B. nach dem pattern crisis:
## [1] 228Das Wort Krise kommt also insgesamt 228 Mal vor.
12.1.4 Häufigste & seltenste Features
Jetzt wollen wir wissen: Welches sind die Features, die am häufigsten vorkommen?
## said mr ukip immigration people party one uk britain farage
## 5513 3779 3606 3533 3386 2821 2644 2511 2395 2329
## rights eu may labour © reserved news british last telegraph
## 2326 2324 2183 2144 2090 1979 1970 1900 1899 1830Und welche Features kommen am seltensten vor?
## giles reminds successive bureaucrats enduring alarm dire stating contender pursuit
## 15 15 15 15 15 15 15 15 15 15
## hinted swiftly indicator backfired onslaught shore veterans extensive avoided uncertain
## 15 15 15 15 15 15 15 15 15 1512.1.5 Können wir das auch visualisieren?
Ein beliebter (aber unter vielen Wissenschaftler:innen inzwischen eher verpönter) Trend ist es, häufige Wörter zu visualisieren. Wie sehr das hilft, die eigenen Texte zu verstehen, sei mal dahingestellt. Zumindest sieht es schön aus.
Genutzt wird dafür die beliebte Wordcloud, die Wörter visualisiert - je grösser diese dargestellt werden, desto häufiger kommen sie vor. Wir lassen uns hier die häufigsten 50 Wörter visualisieren:
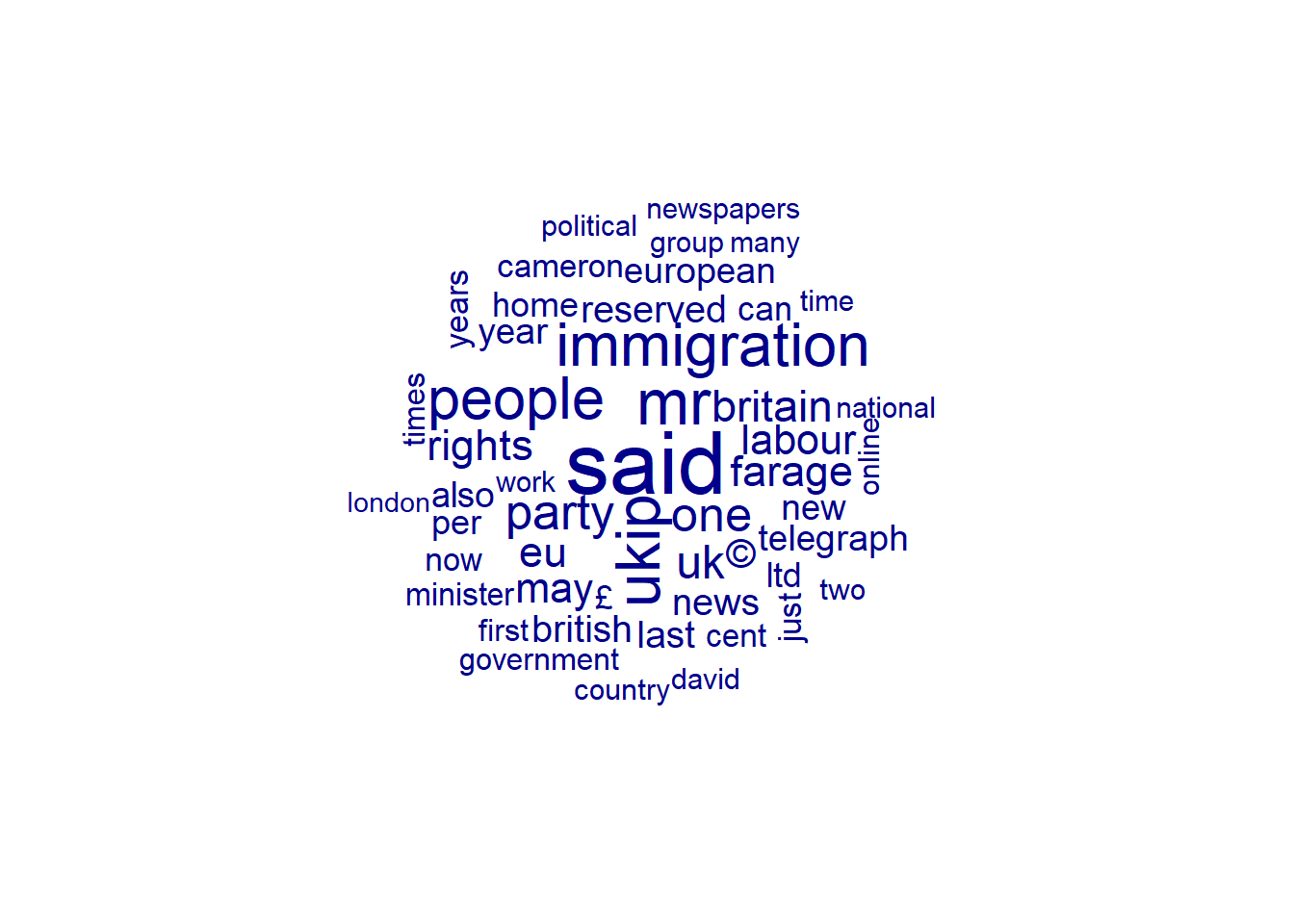
Anhand der Wordcloud können wir zumindest einige Dinge über unsere Texte erfahren - nämlich, dass diese englischsprachig sind und sich um britische Politik und/oder Immigration drehen.
12.2 Gruppierte Frequenz von Features
Eine simple deskriptive Analyse könnte z.B. sein, dass wir wissen wollen, wie sich das Vorkommen von Features über die Monate hinweg unterscheidet.
Um das herauszufinden, könnten wir uns die Frequenz dieses Features über verschiedene Gruppen hinweg - hier z.B. den Monat der Publikation des Artikels - ausgeben lassen:
Dazu setzen wir zunächst den Monat als Gruppierungsvariable, d.h. als Variable, anhand derer wir uns die Frequenz eines patterns ausgeben lassen wollen.
Wir weisen den jeweiligen Monat, in dem ein Artikel publiziert wurde, dabei sowohl als Character-Vektor als auch als numerischen Wert der DFM zu, damit wir die Entwicklung über Monate später von Monat 1 des Jahres (Januar) bis Monat 5 des Jahres (Mai) aufzeigen können, indem wir die Daten nach Monat chronologisch sortieren.
dfm$month <- data$month
dfm$month_numeric[dfm$month=="january"] <- 1
dfm$month_numeric[dfm$month=="february"] <- 2
dfm$month_numeric[dfm$month=="march"] <- 3
dfm$month_numeric[dfm$month=="april"] <- 4
dfm$month_numeric[dfm$month=="may"] <- 5Dann lassen wir uns ein nach Monat gruppiertes document_feature_matrix-Objekt ausgeben.
Sie sehen hier, dass das Vorkommen von Features nicht mehr nach Dokument, sondern nach Monat gestaffelt wird.
## Document-feature matrix of: 5 documents, 5,162 features (23.0% sparse) and 2 docvars.
## features
## docs support ukip continues grow labour heartlands miliband scared leo mckinstry
## april 220 1096 19 26 627 12 150 21 9 7
## february 72 123 5 3 112 2 36 3 3 2
## january 0 0 0 0 0 0 0 0 0 0
## march 236 894 19 23 638 6 133 11 15 9
## may 188 1493 17 20 767 9 261 22 2 2
## [ reached max_nfeat ... 5,152 more features ]Da wir uns die Frequenz von Features später geordnet nach Zeit (d.h., beginnen mit Januar als erstem Monat und Mai als fünftem Monat des Untersuchungszeitraums) ausgeben lassen wollen, nutzen wir die numerische Gruppierungsvariable month_numeric, mit Hilfe derer uns der erste Monat automatisch als erstes und der letzte Monat automatisch als letztes angezeigt wird.
Dokument 1 entspricht also allen Texten, die im Januar publiziert wurden, Dokument 2 allen Texten, die im Februar publiziert wurden, etc.
## Document-feature matrix of: 5 documents, 5,162 features (23.0% sparse) and 2 docvars.
## features
## docs support ukip continues grow labour heartlands miliband scared leo mckinstry
## 1 0 0 0 0 0 0 0 0 0 0
## 2 72 123 5 3 112 2 36 3 3 2
## 3 236 894 19 23 638 6 133 11 15 9
## 4 220 1096 19 26 627 12 150 21 9 7
## 5 188 1493 17 20 767 9 261 22 2 2
## [ reached max_nfeat ... 5,152 more features ]Dann nutzen wir den textstat_frequency()-Befehl. Dieser gibt uns das absolute als auch relative Vorkommen unserer Features aus.
## feature frequency rank docfreq group
## 1 two 4 1 1 1
## 2 much 3 2 1 1
## 3 kirsten 3 2 1 1
## 4 january 3 2 1 1
## 5 faces 3 2 1 1
## 6 thriller 3 2 1 1
## 7 make 2 7 1 1
## 8 us 2 7 1 1
## 9 may 2 7 1 1
## 10 really 2 7 1 1Vielleicht wollen wir jetzt wissen, ob bestimmte Features über die Monate hinweg häufiger oder weniger häufig vorgekommen. Z.B. interessiert uns, ob das Wort immigration über die Monate hinweg häufiger oder weniger häufig vorgekommen ist.
Dazu lassen wir uns nur das Vorkommen eines Features, nämlich immigration über die Monate hinweg ausgeben:
## feature frequency rank docfreq group
## 27 immigration 1 20 1 1
## 135 immigration 359 2 1 2
## 4502 immigration 1413 2 1 3
## 9625 immigration 833 7 1 4
## 14746 immigration 927 8 1 5Schliesslich visualisieren wir die Entwicklung über Zeit, indem wir das absolute Vorkommen des Features mit dem ggplot-Package, einem R-Package für Visualisierungen, plotten.
Ich werde hier nicht genauer in das Package einführen - eine fantastische Einführung, wie ggplot-funktioniert liefert das folgende, online frei verfügbare Handbuch:
- Chang, W. (2020). R Graphics Codebook, 2nd edition. Link
Das Package extrafont, das hier zusätzlich installiert und geladen wird, installiert über die loadfonts-Funktion zusätzliche Schriftarten, wenn wir unseren Graphen etwas individualisiert gestalten wollen - hier z.B., in dem wir nicht mit der Standard-Schrift, sondern der Garamond-Schriftart arbeiten wollen.
Was bedeutet der untenstehende Befehl?
Kurz zusammengefasst:
- ggplot(plot, aes(x = group, y = frequency, group = 1)): R nutzt die Daten im dataframe-Objekt plot, um auf der x-Achse die Monate und auf der y-Achse das absolute Vorkommen des Features Immigration im jeweiligen Monat zu plotten. Dabei könnten wir auch mehrere Linien auf einmal plotten - dadurch, dass wir group hier auf 1 setzen, weisen wir R an, nur eine Variable als Linie zu visualisieren.
- geom_line(): Wir weisen R an, die Entwicklung des Features über Zeit über eine Linie zu visualisieren. Size und color bestimmen hier, wie dick diese Linie sein soll und welche Farbe sie annehmen soll.
- scale_x_discrete(“Monat”, labels = c(“Januar”, “Februar”, “März”, “April”, “Mai”)): Wie wir uns erinnern, hatten wir uns die Monate als Zahlenwerte von 1-5 ausgeben lassen. Damit jede/r Leser:in versteht, was mit diesen Werten gemeint ist, lassen wir uns die Werte von 1-5, die die x-Achse annehmen kann, mit den entsprechend zugehörigen Monaten ausgeben.
- labs(y = “Absolutes Vorkommen des Features Immigration”, title = “Absolutes Vorkommen des Wortes Immigration über Zeit”): Wir weisen R an, welchen Titel die Y-Achse und der Graph insgesamt tragen soll.
- theme(text=element_text(size=12, family=“Garamond”)): Wir weisen R an, uns sämtliche Text-Elemente in der Schriftart “Garamond” auszugeben.
Damit kreiern wir folgenden Graph:
library("ggplot2")
#Vorbereitung der zu plottenden Daten
plot <- freq[freq$feature=="immigration"]
plot## feature frequency rank docfreq group
## 27 immigration 1 20 1 1
## 135 immigration 359 2 1 2
## 4502 immigration 1413 2 1 3
## 9625 immigration 833 7 1 4
## 14746 immigration 927 8 1 5#Plot
ggplot(plot, aes(x = group, y = frequency, group = 1)) +
geom_line(size = 1, color = "darkgreen") +
scale_x_discrete("Monat", labels = c("Januar", "Februar", "März", "April", "Mai"))+
labs(y = "Absolutes Vorkommen des Features Immigration", title = "Absolutes Vorkommen des Wortes Immigration über Zeit") +
theme(text=element_text(family="Garamond"))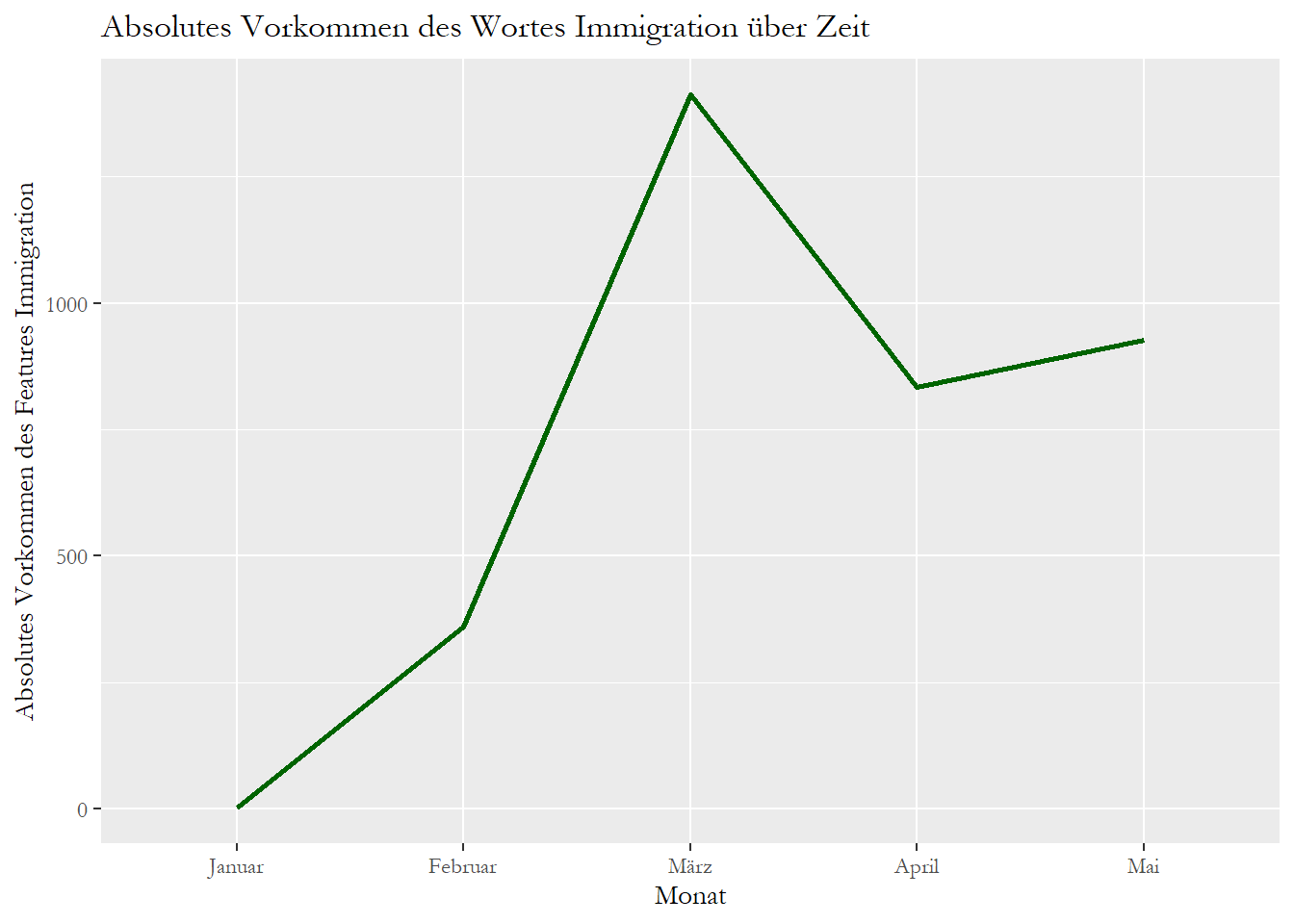
Wir sehen also, dass das Wort immigration in einigen Monaten häufiger vorkam als in anderen (hier: frequency).
Wir sehen aber auch, dass wir bei der Interpretation der absoluten Vorkommens dieses Features vorsichtig sein sollten.
Beispielweise könnte bei Blick auf die Ausgabe denken, dass Immigration im Januar fast nie ein Thema war.
Die niedrige Frequenz des Wortes ist aber einzig damit zu begründen, dass wir nur ein Dokument aus dem Monat Januar vorliegen haben:
##
## april february january march may
## 827 248 1 908 849Hilfreicher ist die relative Frequenz des Features immigration. Wir untersuchen also: Wie oft kam das Wort Immigration über die Monate hinweg im Vergleich zu allen anderen Wörtern vor?
Quanteda bietet die Möglichkeit, über die dfm_weight()-Funktion die relative Prozentanzahl, mit der ein Feature im Verhältnis zu allen anderen Features vorkommt, auszugeben.
Diese Option ist wichtig und nötig, weil das absolute Vorkommen eines Features nur bedingt etwas über die Wichtigkeit dieses Features aussagt. Wenn, wie erwähnt, z.B. in manchen Gruppen, zwischen denen wir das Vorkommen eines Features vergleichen wollen, mehr Texte publiziert wurden, ist es schwer, diese Gruppen zu vergleichen.
Z.B.: Wenn in einem Monat 10 Artikel und im nächsten 100 publiziert wurden, kommt das Features immigration vielleicht im zweiten Monat absolut gesehen viel häufiger vor - aber nur, weil im Monat mehr Artikel publiziert wurden, in denen das Feature jeweils einmal nebenbei genannt wird. Es kann sein, dass im ersten Monat verhältnismässig mehr über Immigration in 10 Texten gesprochen wurde als im zweiten in 100 Texten. Deshalb sollten wir uns immer das relative Vorkommen eines Features, z.B. wie viel % aller Tokens das Features immigration einnimmt, anschauen:
dfm_group_relative <- dfm_weight(dfm_group, scheme = "prop")
freq <- textstat_frequency(dfm_group_relative, group = "month_numeric")
freq[1:10]## feature frequency rank docfreq group
## 1 two 0.02515723 1 1 1
## 2 much 0.01886792 2 1 1
## 3 kirsten 0.01886792 2 1 1
## 4 january 0.01886792 2 1 1
## 5 faces 0.01886792 2 1 1
## 6 thriller 0.01886792 2 1 1
## 7 make 0.01257862 7 1 1
## 8 us 0.01257862 7 1 1
## 9 may 0.01257862 7 1 1
## 10 really 0.01257862 7 1 1Dann visualisieren wir diese relative Häufigkeit wieder:
## feature frequency rank docfreq group
## 27 immigration 0.006289308 20 1 1
## 135 immigration 0.007442111 2 1 2
## 4502 immigration 0.007941415 2 1 3
## 9625 immigration 0.005196020 7 1 4
## 14746 immigration 0.005385809 8 1 5#Plot
ggplot(plot, aes(x = group, y = frequency, group = 1)) +
geom_line(size = 1, color = "darkgreen") +
scale_x_discrete("Monat", labels = c("Januar", "Februar", "März", "April", "Mai"))+
labs(y = "Relatives Vorkommen des Features Immigration", title = "Relatives Vorkommen des Wortes Immigration über Zeit") +
theme(text=element_text(family="Garamond"))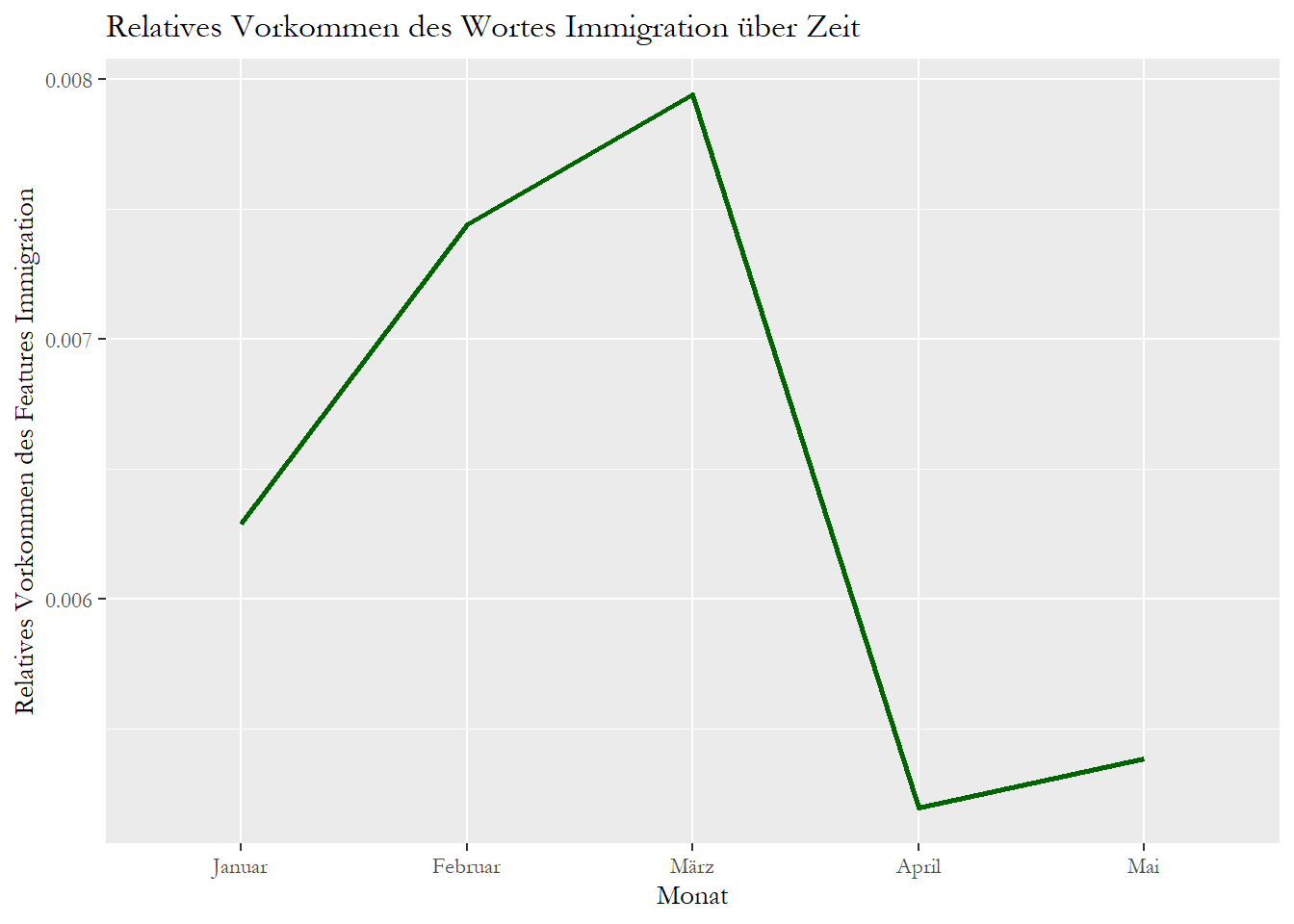
Vergleichen Sie beide Dateien, sehen Sie, dass sich beide Graphen unterscheiden.
12.3 Keywords-in-Context
Wir haben im Rahmen der Bereinigung viel über die Probleme gesprochen, die bag-of-words-Ansätze, durch die u.a. die Reihenfolge und der Kontext von Wörtern ignoriert wird, mit sich bringt.
Das gilt insbesondere für die Frage nach Beziehungen zwischen patterns - etwa der Frage danach, mit welchen Wörtern - negativ oder positiv - ein Akteur oder Thema bezeichnet wird.
Nehmen wir einmal an, wir wollen wissen, ob das Wort Immigration in unserem Korpus eher mit negativen oder mit eher positiven Wörtern beschrieben wird.
Um dies herauszufinden, können wir uns sogenannte Keywords-in-Context anschauen.
Keywords-in-Context beschreiben eine Methode, bei der wir nach einem bestimmten Schlüsselbegriff - etwa Immigration - suchen und uns n-beliebig viele Wörter vor oder nach diesem Schlüsselwört ausgeben lassen.
Nehmen wir einmal an, wir wollen uns die drei Features ausgeben lassen, die vor und nach dem Schlüsselwort Immigration stehen, um einen besseren Eindruck von Wörtern zu bekommen, mit denen Immigration beschrieben wird.
Der kwic()-Befehl gibt uns alle n Wörter aus, die vor und nach einem pattern im Text-String x stehen.
##
## [text1, 371] obsessed with mass | immigration | multi-cultural diversity european
## [text2, 132] britains broken open-door | immigration | policy the disease-ridden
## [text2, 343] past year calais | immigration | chief and deputy
## [text2, 402] seeking to evade | immigration | control they are
## [text3, 130] britains broken open-door | immigration | policy the disease-ridden
## [text3, 353] past year calais | immigration | chief and deputy
## [text5, 157] secure units under | immigration | laws at the
## [text5, 241] with the illegal | immigration | issue itself by
## [text5, 386] and deserve an | immigration | system that is
## [text5, 399] crack down on | immigration | offenders when weWenn wir eigene Diktionäre erstellen wollen - z.B. um zu analysieren, ob Immigration positiv oder negativ beschrieben wird, können wir mit Keywords-in-Context z.B. schauen, welche Begriffe rund um das Wort Immigration vorkommen.
Wir könnten Keywords-in-Context aber auch für erste Analysen nutzen. Z.B. könnten wir analysieren, ob rund um den Begriff Immigration das Wort Crime genannt wird, d.h., Immigration mit Kriminalität in Verbindung gebracht wird.
Unsere Frage: Wie oft wird das Thema Immigration mit Kriminalität in Verbindung gebracht?
Um das herauszufinden, lassen wir uns die drei Wörter vor dem pattern immigration, das pattern selbst und die drei Wörter nach dem pattern immigration als einen Text-String ausgeben. Der paste-Befehl fügt diese drei Variablen im Objekt kwic zusammen:
## [1] "obsessed with mass immigration multi-cultural diversity european"
## [2] "britains broken open-door immigration policy the disease-ridden"
## [3] "past year calais immigration chief and deputy"
## [4] "seeking to evade immigration control they are"
## [5] "britains broken open-door immigration policy the disease-ridden"Dann zählen wir ganz einfach aus, wie oft Kriminalität im Kontext von Immigration genannt wird:
## [1] 5Insgesamt kommt das Wort Kriminalität also fünfmal im Kontext von Kriminalität vor - nicht besonders häufig.
12.4 Ko-Okkurenzen
Die vorherige Analyse hat bereits gezeigt, dass uns vielleicht noch andere Dinge interessieren - z.B., ob spezifische Wörter in einem Text zusammen vorkommen. Beispielsweise könnte uns interessieren, ob Texte, die über Immigration sprechen, ganz generell auch Kriminalität oder andere negative Begriffe erwähnen - egal ob im direkten Kontext von Immigration oder an anderen Stellen im Text.
Wir fragen uns also: Kommen die patterns immigration und crime gemeinsam in Texten vor?
Um diese Frage zu beantworten, müssen wir uns die Ko-Okkurrenz von Wörtern anschauen - d.h., ob zwei Wörter gemeinsam in einem Text vorkommen. Damit ist nicht gesagt, dass diese Wörter direkt nacheinander oder auch nur in Nähe voneinander vorkommen - sondern nur, dass beide in einem Text genannt werden.
Eine sogenannte co-occurrence-Matrix ist nicht unähnlich zu einer document-feature-Matrix. Die Spalten einer co-occurrence-Matrix bezeichnen Features, die Zeilen bezeichnen ebenso Features. Die Zellen zeigen an, wie häufig ein Feature zusammen mit einem anderen Feature in Texten vorkommt.
Schauen wir uns ein Beispiel an.
Wir erzeugen zunächst die co-occurrence-Matrix:
## Feature co-occurrence matrix of: 5,162 by 5,162 features.
## features
## features support ukip continues grow labour heartlands miliband scared leo mckinstry
## support 330 1850 24 18 1062 37 198 24 14 12
## ukip 0 9754 84 45 5467 164 1427 160 41 40
## continues 0 0 2 3 45 2 13 1 6 5
## grow 0 0 0 5 24 2 12 1 1 1
## labour 0 0 0 0 3689 181 2277 107 37 37
## heartlands 0 0 0 0 0 9 63 4 4 4
## miliband 0 0 0 0 0 0 639 41 11 11
## scared 0 0 0 0 0 0 0 27 1 1
## leo 0 0 0 0 0 0 0 0 5 22
## mckinstry 0 0 0 0 0 0 0 0 0 1
## [ reached max_feat ... 5,152 more features, reached max_nfeat ... 5,152 more features ]Dann weisen wir R an, uns nur das Vorkommen des Wortes Immigration und anderer Wörter (hier eine Reihe möglicher negativer und positiver Begriffe) ausgeben zu lassen.
Wir reduzieren die Matrix mit dem Befehl fcm_select() also auf die Ko-Okkurrenz ausgewählter Begriffe - Immigration und eine Reihe positiver (chance, good) und negativer (crime, threat) Begriffe.
fcm <- fcm_select(fcm,
pattern = c("immigration", "crime", "chance", "threat",
"good", "bad", "cost", "work", "visa", "illegal",
"immigrant", "border", "control"),
selection = "keep")Dann visualisieren wir die Ko-Okkurrenz als Netzwerk, das visualisiert, wie oft Begriffe zusammen vorkommen.

Was zeigt uns dieses Netzwerk?
Begriffe werden durch Linien verbunden, wenn sie im gleichen Dokument vorkommen. Je öfter zwei Begriffe zusammen vorkommen, desto dicker sind diese Linien. Z.B. kommt das Wort “Immigration” sehr häufig mit dem Wort “Work” zusammen vor, wie man an den Linien sieht, die beide Begriffe verbinden. Weniger häufiger kommen die Wörter “Immigration” und “Crime” zusammen vor - etwas, das wir bereits durch unsere Analyse von Keywords-in-Context herausgefunden hatten-
Wenn wir diese Information nicht aus dem Netzwerk rauslesen wollen, können wir uns die Daten auch selbst anschauen. Um eine co-occurrence-Matrix zu inspizieren, bietet das quanteda-Package die nützliche Funktion convert(). Sehr viele quanteda-Objekte, inklusive der hier genutzten Matrix, lassen sich dadurch in Ihnen bereits bekannte Formate wie z.B. ein dataframe-Objekt umwandeln:
## doc_id threat immigration illegal border control cost work immigrant good crime visa bad chance
## 1 threat 51 237 3 14 20 23 56 11 36 19 9 9 42
## 2 immigration 0 4556 601 692 860 682 1790 372 873 198 605 249 213
## 3 illegal 0 0 187 126 33 48 90 143 43 81 41 11 3
## 4 border 0 0 0 333 128 30 178 28 71 65 74 17 9
## 5 control 0 0 0 0 132 30 203 30 89 13 33 23 37
## 6 cost 0 0 0 0 0 230 131 22 76 15 18 20 16
## 7 work 0 0 0 0 0 0 826 202 359 60 219 125 77
## 8 immigrant 0 0 0 0 0 0 0 78 73 40 57 26 16
## 9 good 0 0 0 0 0 0 0 0 247 42 147 113 43
## 10 crime 0 0 0 0 0 0 0 0 0 236 20 23 21
## 11 visa 0 0 0 0 0 0 0 0 0 0 273 43 5
## 12 bad 0 0 0 0 0 0 0 0 0 0 0 36 18
## 13 chance 0 0 0 0 0 0 0 0 0 0 0 0 42Dann könnten wir uns beispielsweise ausgeben lassen, ob das Wort Immigration häufiger mit dem Begriff work oder häufiger mit dem Begriff crime zusammen in einem Text vorkommt:
## numeric(0)## numeric(0)12.5 Diktionäranalyse
Wenden wir uns jetzt einem beliebten Verfahren der automatisierten Inhaltsanalyse zu: der Analyse via Diktionäre.
Diktionäre sind Wörterlisten. Auf Basis des manifesten Vorkommens gewisser Wörter - beispielsweise der Wörter “Krise”, “schlecht” und “verheerend” - wird auf das Vorkommen eines latenten Konstruktes - z.B. negatives Sentiment - geschlossen.
Sie haben im Seminar bereits die grundsätzliche Logik und Probleme des Verfahren kennengelernt. Aber wie setzt man dies in R um?
12.5.1 Erstellung eines Diktionärs
Wir unterscheiden im Seminar zwischen zwei Arten von Diktionären.
- Off-the-Shelf-Diktionäre, d.h. vorgefertigte Wörterlisten, die oft für andere Textarten und Themenbereiche entwickelt wurden
- Organische-Diktionären, d.h. eigens erstellte Wörterlisten
12.5.1.1 Off-the-Shelf Diktionär
Auf die Problematik der Validität sogenannter Off-the-shelf-Diktionären wurde im Seminar und den entsprechenden Literaturhinweisen, etwa Boukes et al., 2020, Chan et al., 2020 oder Stine, 2019, bereits hingewiesen.
Wenn Sie Off-the-shelf-Diktionäre verwenden, validieren Sie bitte sorgfältig, ob diese messen, was Sie meinen, zu messen.
Das quanteda-package enthält unter anderem das Off-the-Shelf-Diktionär Lexicoder Sentiment Dictionary zu negativem und positivem Sentiment von Young & Soroka, 2012a sowie Young & Soroka (2012b): Lexicoder Sentiment Dictionary.
Schauen wir uns das Diktionär einmal an:
## Dictionary object with 4 key entries.
## - [negative]:
## - a lie, abandon*, abas*, abattoir*, abdicat*, aberra*, abhor*, abject*, abnormal*, abolish*, abominab*, abominat*, abrasiv*, absent*, abstrus*, absurd*, abus*, accident*, accost*, accursed* [ ... and 2,838 more ]
## - [positive]:
## - ability*, abound*, absolv*, absorbent*, absorption*, abundanc*, abundant*, acced*, accentuat*, accept*, accessib*, acclaim*, acclamation*, accolad*, accommodat*, accomplish*, accord, accordan*, accorded*, accords [ ... and 1,689 more ]
## - [neg_positive]:
## - best not, better not, no damag*, no no, not ability*, not able, not abound*, not absolv*, not absorbent*, not absorption*, not abundanc*, not abundant*, not acced*, not accentuat*, not accept*, not accessib*, not acclaim*, not acclamation*, not accolad*, not accommodat* [ ... and 1,701 more ]
## - [neg_negative]:
## - not a lie, not abandon*, not abas*, not abattoir*, not abdicat*, not aberra*, not abhor*, not abject*, not abnormal*, not abolish*, not abominab*, not abominat*, not abrasiv*, not absent*, not abstrus*, not absurd*, not abus*, not accident*, not accost*, not accursed* [ ... and 2,840 more ]Wir sehen, dass das Diktionär aus vier Key Entries besteht - hier die Konstrukte, die überprüft werden sollen. Für jedes dieser Konstrukte findet sich eine lange Wörterliste - die patterns, über deren Vorkommen wir Rückschlusse auf das Vorkommen des Konstruktes ziehen wollen.
Vielleicht wollen wir wissen, ob über Zeit mehr positives oder negatives Sentiment in UK-Nachrichten zum Thema Immigration vorkommt.
Wie wir bereits wissen, macht es oft wenig Sinn, sich das absolute Vorkommen von Features über Zeit ausgeben zu lassen. Denn: Das absolute Vorkommen ist auch davon abhängig, wie viele Texte je Gruppe publiziert wurden, etc.
Wir müssen unsere Texte also wieder normalisieren, um zu schauen, schauen wie viel Prozent aller Features in einem Monat negativ oder positiv waren.
Wir wenden drei Schritte an, um herauszufinden, wie oft ein Konstrukt - etwa positives oder negatives gesehen - relativ gesehen über verschiedene Monate hinweg vorkommt:
- Gruppierung
- Normalisierung
- Erfassung des Konstrukts mittels Diktionär
Dafür gruppieren wir als erstes unsere Features nach Monat, gewichten dann das Vorkommen jedes Features nach Monat und analysieren dann, wie oft Features vorkommen, die mit positivem oder negativem Sentiment verbunden werden:
sentiment_grouped_relative <- dfm(dfm, groups = "month_numeric") %>%
dfm_weight(scheme = "prop") %>%
dfm(dictionary = data_dictionary_LSD2015[1:2])
sentiment_grouped_relative## Document-feature matrix of: 5 documents, 2 features (0.0% sparse) and 2 docvars.
## features
## docs negative positive
## 1 0.03144654 0.09433962
## 2 0.04910964 0.06921785
## 3 0.05530327 0.06704397
## 4 0.05786109 0.06326295
## 5 0.05799476 0.06017929Wir sehen also, wie viele negative und positive Wörter über Zeit relativ gesehen in den Artikeln verwendet wurden.
Wir können uns diese Ausgabe auch visualisieren lassen. Dafür wandeln wir unsere gruppierte Document-feature-matrix über den convert-Befehl in ein dataframe-Objekt um.
Damit wir positives und negatives Sentiment getrennt visualisieren können, müssen wir unser dataframe-Objekt plot vom sogenannten wide-Format, bei dem alle Variablen als einzelne Spalten ausgeführt werden, zum long-Format, bei dem die Werte aller Variablen - negatives und positives Sentiment - in einer Spalte aufgeführt werden und eine weitere Gruppierungsvariable die jeweilige Variable kennzeichnet, transformieren.
Dafür benötigen wir das reshape-Package. Mit dem Befehl melt wandeln wir unsere Daten vom wide-Format zum long-Format um. Dabei müssen wir der Funktion anweisen, welche Variable unsere einzelne Beobachtung, d.h. hier den Monat der Beobachtung, kennzeichnet:
## doc_id variable value
## 1 1 negative 0.03144654
## 2 2 negative 0.04910964
## 3 3 negative 0.05530327
## 4 4 negative 0.05786109
## 5 5 negative 0.05799476
## 6 1 positive 0.09433962
## 7 2 positive 0.06921785
## 8 3 positive 0.06704397
## 9 4 positive 0.06326295
## 10 5 positive 0.06017929Anschliessend visualisieren wir die Verteilung von positiven und negativen Features über Zeit:
#Visualisierung
ggplot(plot, aes(x = doc_id, y = value, group = variable, colour = variable)) +
geom_line() +
scale_x_discrete("Monat",
labels = c("Januar", "Februar", "März", "April", "Mai"))+
labs(y = "Relatives Vorkommen des Features Immigration",
title = "Positives und negatives Sentiment über Zeit",
colour = "Sentiment") +
theme(text=element_text(family="Garamond"))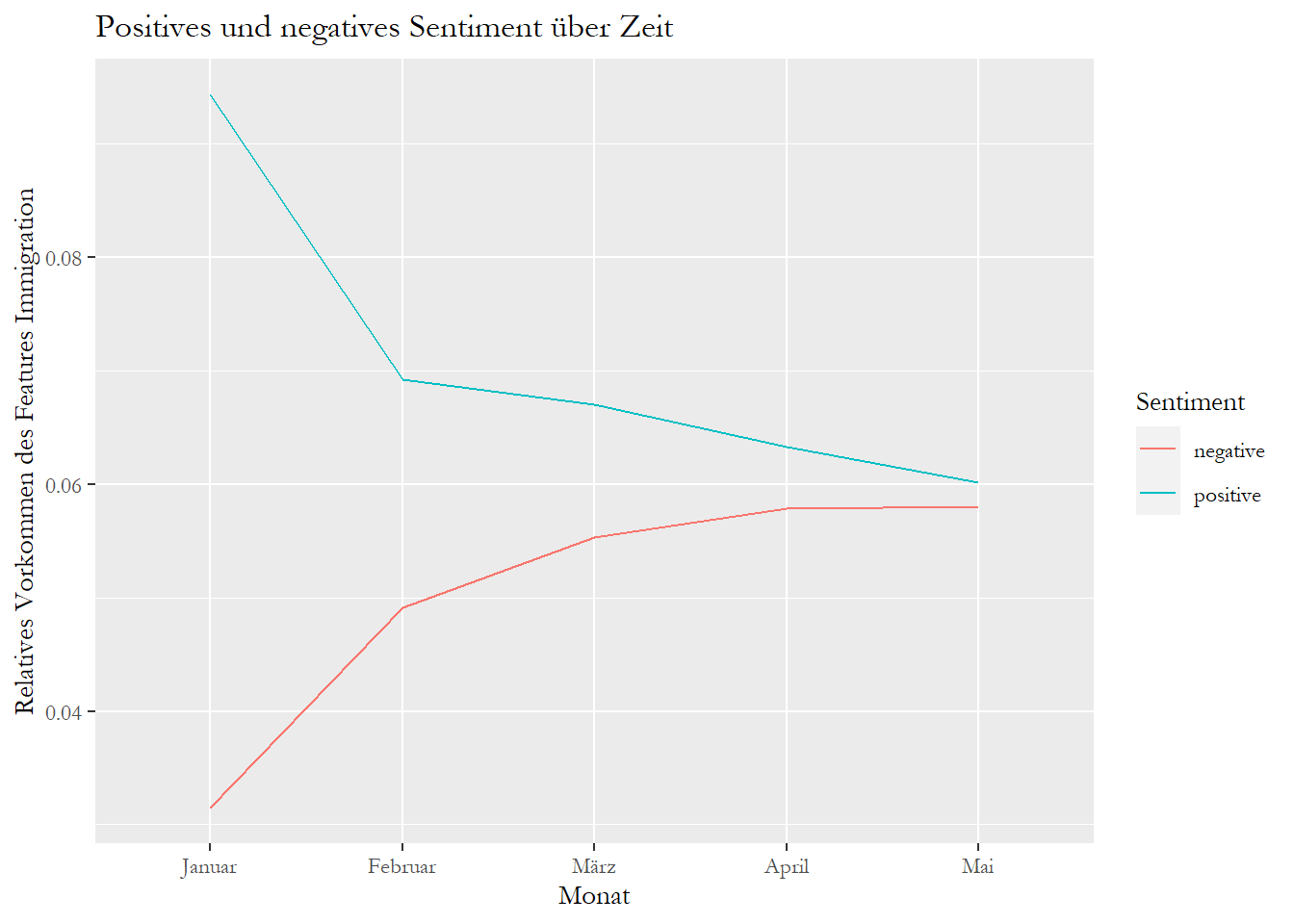
Wir müssen hier wieder vorsichtig sein - denn unser Korpus aus dem Monat Januar enthält nur einen Artikel. Insgesamt scheint es aber so, dass negatives Sentiment über Zeit leicht zugenommen und positives Sentiment leicht abgenommen hat.
12.5.1.2 Organisches Diktionär
Ein besseres Vorgehen ist es oft, eigene Diktionäre zu entwicklen. Sogenannte organische Diktionäre bestehen aus eigens erstellten Wörterlisten s. etwa Muddiman et al. (2019).
Beispielsweise wollen Sie wissen, wie oft in Ihrem Korpus angst-induzierende Sprache vorkommt. Sie haben ein eigenes Diktionär entwickelt, dass aus Wörtern besteht, die angstinduzierende Sprache beschreiben.
Sie könnten den Befehl dictionary nutzen, um ein eigenes, organisches Diktionär im R-Environment zu erstellen.
dict_angst <- dictionary(list(angst = c("anxiety", "anxious", "afraid", "crisis",
"terror", "threat", "carnage",
"disaster", "horror", "tear",
"cry", "nightmare", "kill", "death",
"monster", "defeat", "crime", "violence",
"violent")))
dict_angst## Dictionary object with 1 key entry.
## - [angst]:
## - anxiety, anxious, afraid, crisis, terror, threat, carnage, disaster, horror, tear, cry, nightmare, kill, death, monster, defeat, crime, violence, violentDann nutzen wir die gleichen Logik wie zuvor, um uns das Vorkommen angst-induzierender Sprache über Zeit ausgeben zu lassen:
- Wir gruppieren unsere document-feature-Matrix nach Monaten
- Wir lassen uns das relative Vorkommen aller Features ausgeben
- Wir suchen nur nach Features, die in unserem organischen Diktionär vorkommen
sentiment_grouped_relative <- dfm(dfm, groups = "month_numeric") %>%
dfm_weight(scheme = "prop") %>%
dfm(dictionary = dict_angst)
sentiment_grouped_relative## Document-feature matrix of: 5 documents, 1 feature (20.0% sparse) and 2 docvars.
## features
## docs angst
## 1 0
## 2 0.002010821
## 3 0.002197518
## 4 0.002794498
## 5 0.002521511Dann wandeln wir unseren Data-Frame in long-Format um und visualisieren unsere Ergebnisse:
plot <- convert(sentiment_grouped_relative, to = "data.frame")
plot <- melt(plot, id.vars = "doc_id")
ggplot(plot, aes(x = doc_id, y = value, group = variable, colour = variable)) +
geom_line() +
scale_x_discrete("Monat",
labels = c("Januar", "Februar", "März", "April", "Mai"))+
labs(y = "Relatives Vorkommen angst-induzierender Sprache",
color = "Angst-induzierende Sprache")+
theme(text=element_text(family="Garamond"))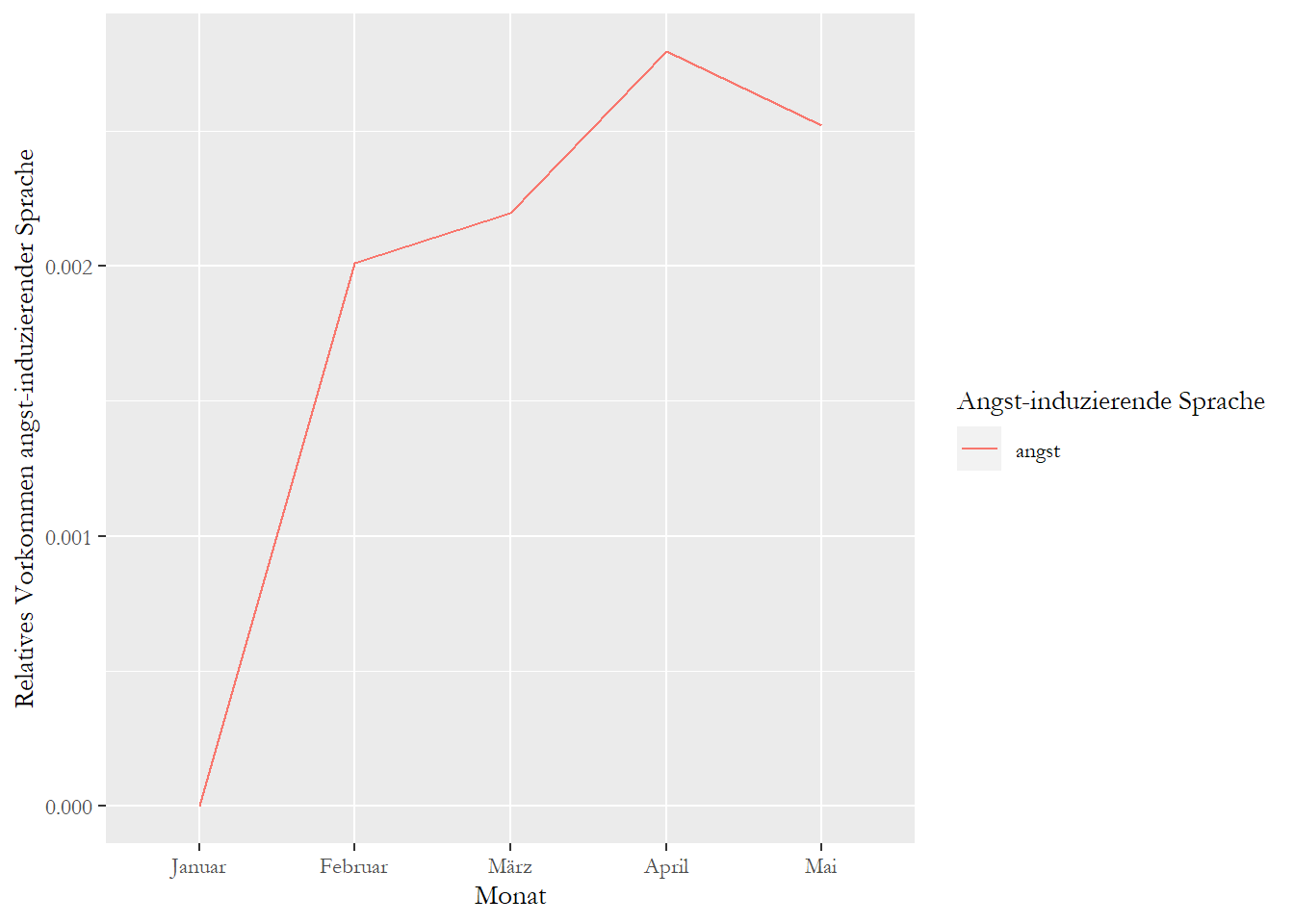
12.6 Take Aways
Vokabular:
- Keywords-in-Context bzw. Keywords-in-Context-Analyse: Analyse, welche Wörter im Kontext eines Schlüsselworts vorkommen
- Ko-Okkurrenzen bzw. Ko-Okkurrenzen-Analyse: Analyse, welche Wörter gemeinsam in einem Dokument vorkommen
- Diktionär: Diktionäre sind Wörterlisten. Auf Basis des manifesten Vorkommens dieser Wörter wird auf das Vorkommen eines latenten Konstruktes - z.B. Sentiment - geschlossen.
- Off-the-Shelf-Diktionäre: vorgefertigte Wörterlisten, die oft für andere Textarten und Themenbereiche entwickelt wurden
- Organische-Diktionären: eigens erstellte Wörterlisten
Befehle:
- Anzahl Dokumente & Features: ndoc(), nfeat()
- Vorkommen von Features: featfreq(), topfeatures(), textstat_frequency(), dfm_weight(), textplot_wordcloud(), dfm_group()
- Keywords-in-Context: kwic()
- Ko-Okkurrenzen: fcm(), fcm_select(), textplot_network()
- Umwandlung von quanteda-Formaten: convert()
- Diktionär-Analyse: dictionary()
12.7 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
12.8 Benotete Aufgabe in R III
Achtung: Bei der nachfolgenden Aufgabe handelt es sich um die dritte benotete Aufgabe in R. D.h., die fristgerechte Abgabe dieser Aufgabe ist eine benotete Leistungsabgabe. Die Abgabe soll zum 14.12.2020 um 12 Uhr erfolgen.
Bitte bearbeiten Sie die Aufgabe in Gruppen von mind. 2 und max. 3 Personen.
Bitte nutzten Sie für die Abgabe Ihrer Lösungen das vorgegebene R-Template (via OLAT: Materialien / Templates/ Benotete Aufgabe in R_3.R).
Wir arbeiten für die Aufgabe wieder mit dem Textkorpus: speeches.rda
Sie finden den Korpus in OLAT (via: Materialien / Datensätze für R) mit dem Namen speeches.rda.
Bei diesen Dateien handelt es sich um “State of the Union Addresses” von US-Präsidenten seit 1790, die bereits als R-Environment abgespeichert wurde. Die Daten befinden sich in einem ähnlichen Format, wie Sie sie erhalten würden, wenn Sie ihre Text mit dem readtext-Package einlesen würden und zusätzlich noch einige document_level-Variablen bereits abgespeichert hätten.
Quelle der Daten: The American Presidency Project. Geladen via dem Quanteda-Corpus_Package.
12.8.1 Aufgabe 12.1
Laden Sie den Korpus. Lassen Sie sich nur die Reden der demokratischen und republikanischen Präsidenten ausgeben (“Democratic” oder “Republican” in der party-Variable). Was sind die 10 Top Features bei Reden demokratischer vs. republikanischer Präsidenten?
Hinweis: Sie brauchen hier und in späteren Aufgaben keine Bereinigungs-Schritte vornehmen. Wandeln Sie den Text einfach so, wie er vorliegt, um.
12.8.2 Aufgabe 12.2
Lassen Sie sich für den vollen Datensatz mit allen 241 Reden das relative Vorkommen der Features “threat” über die Jahre hinweg ausgeben.
12.8.3 Aufgabe 12.3.
Können Sie sich die Länge der Rede, d.h. die durchschnittliche Anzahl an Features je Rede, über die Jahre hinweg ausgeben lassen? Achten Sie darauf, dass es teils mehrere Reden je Jahr gibt. D.h., Sie müssen die durchschnittliche Anzahl an Features über verschiedene Reden hinweg je Jahr berechnen.
12.8.4 Aufgabe 12.4.
Visualisieren Sie die Ergebnisse aus Aufgabe 12.3. Welche Art der Visualisierung bzw. welchen Graphentyp Sie nutzen, ist egal. Wichtig ist nur, dass die x-Achse das Jahr der Rede und die y-Achse die durchschnittliche Anzahl an Wörtern der jeweiligen Rede(n) enthält.
Wenn Sie die Aufgabe 12.3 nicht lösen konnten, visualisieren Sie bitte einfach die Anzahl an Reden je Jahr. Wichtig ist dass, dass die x-Achse das Jahr der Rede und die y-Achse die Anzahl an Reden je Jahr enthält.
Die Lösungen finden Sie bei Lösungen zu Tutorial 12.
Wir machen weiter: mit [Tutorial 13: Unüberwachtes maschinelles Lernen: Topic Modeling]