19 Diktionärbasierte Ansätze
Diktionärbasierte Ansätze verfolgen das Ziel, latente Konstrukte in (Teilmengen von) Textkorpora durch das (vermehrte) Auftreten bestimmter, dem jeweiligen Konstrukt zugeordneter Begriffe zu messen. Kurz gesagt, wird ein Textkorpus anhand einer Liste von Begriffen (Diktionär oder Lexikon), die ein oder mehrere Konstrukte (z. B. die emotionale Polarität, den Populismusgrad etc.) abbilden sollen, ausgezählt – je höher die Anzahl bzw. der Anteil der einem Konstrukt zugeordneten Begriffe, desto stärker ist das jeweilige Konstrukt ausgeprägt.
In den einfachsten (aber auch häufigsten) Fällen handelt es sich bei den verwendeten Diktionären um aus Unigrammen zusammengestellte kategoriale Lexika, die also einzelne Wörter einem bestimmten Konstrukt zuordnen (z. B. “Volk” zum Konstrukt “Populismus”), wobei alle enthaltenen Wörter gleich gewichtet werden. Entsprechend handelt es sich um ein relativ simples Verfahren, das Kontext und Grammatik ausblendet; die Klassifikation einzelner, kurzer Text-Dokumente ist daher recht fehleranfällig, etwa wenn eine Negation nicht als solche erkannt wird (taucht beispielsweise in unserem Lexikon zum Konstrukt “Zufriedenheit” das Wort “glücklich” auf, werden “Ich bin glücklich” als auch “Ich bin nicht glücklich” den gleichen Zufriedenheits-Score erhalten). Gute, etablierte Lexika erzielen jedoch trotz dieser Einschränkungen in der Regel und gerade bei größeren Textmengen zufriedenstellende Ergebnisse. Zudem können und sollten die im Folgenden vorgestellten Techniken für die jeweilige Umsetzung noch verfeinert und verbessert werden, beispielsweise durch Gewichtung, der Berücksichtigung von Bigrammen (um beispielsweise Negationen zu erfassen) etc.
Wir werden uns die technische Umsetzung diktionärbasierter Ansätze in diesem Kapitel erneut anhand des aus den vorherigen Kapiteln bekannten Tweet-Korpus ansehen, wobei wir uns die Grundlagen zunächst anhand eines eigens erstellten Diktionärs aneignen, bevor wir mit der Sentiment-Analyse einen häufigen Anwendungsfall betrachten. Abschließend wird noch auf die Verwendung gewichteter Lexika eingegangen.
Zur Vorbereitung laden wir die uns schon bekannten Packages sowie den Tweet-Datensatz und erzeugen ein Korpus-Objekt. Beim Laden des Tweet-Datensatzes wird zudem eine neue Variable day erzeugt, die das Datum (ohne Uhrzeit) festhält – da wir für jeden Tweet das exakte Erscheinungsdatum in der Form YYYY/MM/DD hh::mm::ss in der Variable date vorliegen haben, können wir hierzu einfach die ersten zehn Zeichen dieser Variable extrahieren. Diese neue Variable erleichtert uns im Folgenden die Auswertung auf Tagesebene.
# Setup
library(tidyverse)
library(tidytext)
library(quanteda)
# Daten einlesen
tweets <- read_csv("data/trump_biden_tweets_2020.csv") %>%
mutate(day = str_sub(date, 1, 10))
# Korpus erzeugen
tweets_corpus <- corpus(tweets, docid_field = "id", text_field = "content")19.1 Grundlagen
Donald Trump ist nicht zuletzt für seinen, nunja, markanten Redestil bekannt, der sich neben dem unverwechselbaren Sprachfluss auch durch die häufige Verwendung bestimmter Wörter, Floskeln und Neologismen (“bigly”) auszeichnet. Wir möchten nun prüfen, ob sich auch in seinen Tweets vermehrt diese Trumpisms finden. Um dieses Konstrukt zu messen, erstellen wir also zunächst ein Wörterbuch, das häufig von Trump verwendete Wörter sammelt. Praktischerweise wird uns diese Arbeit durch diesen Artikel in The Atlantic abgenommen.
Wir erstellen zunächst einen Textvektor, der die Begriffe enthält (bereinigt um einige uneindeutige Begriffe sowie alle Nicht-Unigramme). Um den Aufwand möglichst gering zu halten, nutzen wir die Funktion str_split() aus dem uns bekannten stringr-Package (siehe Kapitel 12.1), mit der wir einen Textstring schnell anhand einer Trennzeichenkette (in diesem Fall " / ") in einzelne Bestandteile aufteilen können. Das Resultat ist ein character-Vektor mit insgesamt 90 Trumpisms.
trump_words <- str_split("amazing / beautiful / best / big league / brilliant / elegant / fabulous / fantastic / fine / good / great / happy / honest / incredible / nice / outstanding / phenomenal / powerful / sophisticated / special / strong / successful / top / tremendous / unbelievable / boring / crooked / disgusting / dishonest / dopey / dumb / goofy / horrible / obsolete / overrated / pathetic / ridiculous / rude / sad / scary / stupid / terrible / unfair / weak / worst / big / huge / major / many / massive / numerous / staggering / substantial / tough / vast / absolutely / badly / basically / certainly / extremely / frankly / greatly / highly / incredibly / totally / truly / unbelievably / very / viciously / way / candy / chaos / choker / clown / disaster / dope / dummy / fool / hatred / idiocy / incompetence / joke / lightweight / loser / lowlife / moron / phonies / problem / terror / weakness",
pattern = " / ",
simplify = TRUE)Um dieses Begriffsliste in Quanteda verwenden zu können, müssen wir ein Dictionary-Objekt erstellen. Hierzu gibt es die Quanteda-Funktion dictionary(), der wir eine Liste mit den enthaltenen Konstrukten übergeben, wobei der Name eines jeden Listeneintrags ein Konstrukt abdeckt, dem die entsprechenden Begriffe zugeordnet werden. In unserem Fall haben wir nur ein Konstrukt, trumpisms:
## Dictionary object with 1 key entry.
## - [trumpisms]:
## - amazing, beautiful, best, big league, brilliant, elegant, fabulous, fantastic, fine, good, great, happy, honest, incredible, nice, outstanding, phenomenal, powerful, sophisticated, special [ ... and 70 more ]Die Auszählung erweist sich denkbar einfach und geschieht innerhalb der uns bereits bekannten dfm()-Funktion. Geben wir mit dem Argument dictionary ein Diktionär an, werden die enthaltenen Kategorien ausgezählt und als einzelne Spalten in der resultierenden DFM angegeben; alle nicht im Diktionär enhaltenen Begriffe werden schlichtweg ignoriert. Wir können uns an dieser Stelle also auch die bisher durchgeführte, schrittweise Tokenisierung sparen – dfm() funktioniert auch mit einem Korpus-Objekt, konvertiert alle Texte in Kleinschreibung und tokenisiert diese automatisch, Stoppwörter etc. sind in unserem Diktionär nicht enhalten und werden daher eh ignoriert.
## Document-feature matrix of: 2 documents, 1 feature (0.0% sparse) and 1 docvar.
## features
## docs trumpisms
## JoeBiden 442
## realDonaldTrump 2233Das Resultat ist eine sehr überschaubare 2x1-DFM: Joe Biden nutzt in seinen Tweets insgesamt 442 Trumpisms, Donald Trump hingegen 2233. Es sieht also danach aus, dass die gewählten Begriffe tatsächlich recht typisch für Trumps Sprach- und auch Tweet-Stil sind.
Allerdings ist die absolute Häufigkeitsauszählung an dieser Stelle nur bedingt für einen Vergleich geeignet, da Trump auch insgesamt deutlich mehr twittert – von Trump liegen uns 2654, von Biden lediglich 1499 Tweets für das erste Halbjahr 2020 vor. Hier ist es also sinnvoll, die DFM vor der Auszählung zu gewichten. Dies erledigen wir mit der Funktion dfm_weight(), wobei unterschiedliche Gewichtungsvarianten mit dem Argument scheme (siehe Funktionsdokumentation) gewählt werden können. Mit scheme = "prop" gewichten wir jedes Feature nach der Gesamtzahl aller Features in einem Dokument.
Für die folgende Analyse erstellen wir also zunächst eine DFM und gruppieren dabei nach Account, sodass alle Tweets eines Accounts ein einziges Dokument darstellen. Anschließend gewichten wir proportional und wenden dann unser Diktionär erneut mit dem dfm()-Befehl auf die gewichtete DFM an:
dfm(tweets_corpus, groups = "account") %>%
dfm_weight(scheme = "prop") %>%
dfm(dictionary = trumpisms_dictionary)## Document-feature matrix of: 2 documents, 1 feature (0.0% sparse) and 1 docvar.
## features
## docs trumpisms
## JoeBiden 0.007872052
## realDonaldTrump 0.028331451Das Ergebnis lässt sich einfach interpretieren: rund 2,8 Prozent aller Wörter in Trumps Tweets sind eines der 90 Trumpisms in unserem Wörterbuch, bei Joe Biden sind dies nur rund 0,8 Prozent – auch proportional verwendet Trump also deutlich mehr Trumpisms als Biden.
Häufig werden diktionärsbasierte Ansätze genutzt, um Veränderungen im (Zeit-)Verlauf aufzuzeigen (z. B.: Wie hat sich etwa der Populismusgehalt in den Reden im Bundestag über die Zeit geändert?). Auch dies ist in Quanteda sehr simpel umzusetzen – wir ziehen einfach eine weitere Variable, die die Zeitebene repräsentiert, beim Gruppieren hinzu. So erhalten wir schnell eine DFM, in der für jeden Account und jeden Tag der Anteil der Trumpisms angegeben ist.
trumpisms_per_day <- dfm(tweets_corpus, groups = c("account", "day")) %>%
dfm_weight(scheme = "prop") %>%
dfm(dictionary = trumpisms_dictionary)
trumpisms_per_day## Document-feature matrix of: 354 documents, 1 feature (6.5% sparse) and 2 docvars.
## features
## docs trumpisms
## realDonaldTrump.2019/12/31 0.03174603
## JoeBiden.2020/01/01 0.02127660
## realDonaldTrump.2020/01/01 0.04477612
## JoeBiden.2020/01/02 0.00400000
## realDonaldTrump.2020/01/02 0.02302632
## JoeBiden.2020/01/03 0
## [ reached max_ndoc ... 348 more documents ]Um dies grafisch darzustellen, konvertieren wir die DFM mit der tidy()-Funktion aus dem tidytext-Package in ein Tibble und können dann auf das uns bekannte Visualisierungspackage ggplot2 (siehe Kapitel 11.2) zurückgreifen. Vorab konvertieren wir die Variable day noch von einer character- in eine date-Variable; ich nutze zum Verschönern des Plots zudem ein paar Funktionen aus dem ggplot2-Package, die uns noch nicht bekannt sind – im Idealfall erschließt sich deren Funktion bereits aus dem Namen und Verwendungszusammenhang.
trumpisms_per_day %>%
tidy() %>%
separate(document, c("account", "day"), sep = "\\.") %>%
mutate(day = as.Date(day)) %>%
ggplot(aes(x = day, y = count, color = account, group = account)) +
geom_line() +
scale_color_manual(values = c("blue", "red")) +
scale_x_date(date_breaks = "1 month", date_labels = "%b %Y") +
scale_y_continuous(labels = scales::percent) +
theme_bw() +
theme(legend.position = "bottom") +
labs(x = "Datum", y = "Anteil Trumpisms", color = "Twitter-Account")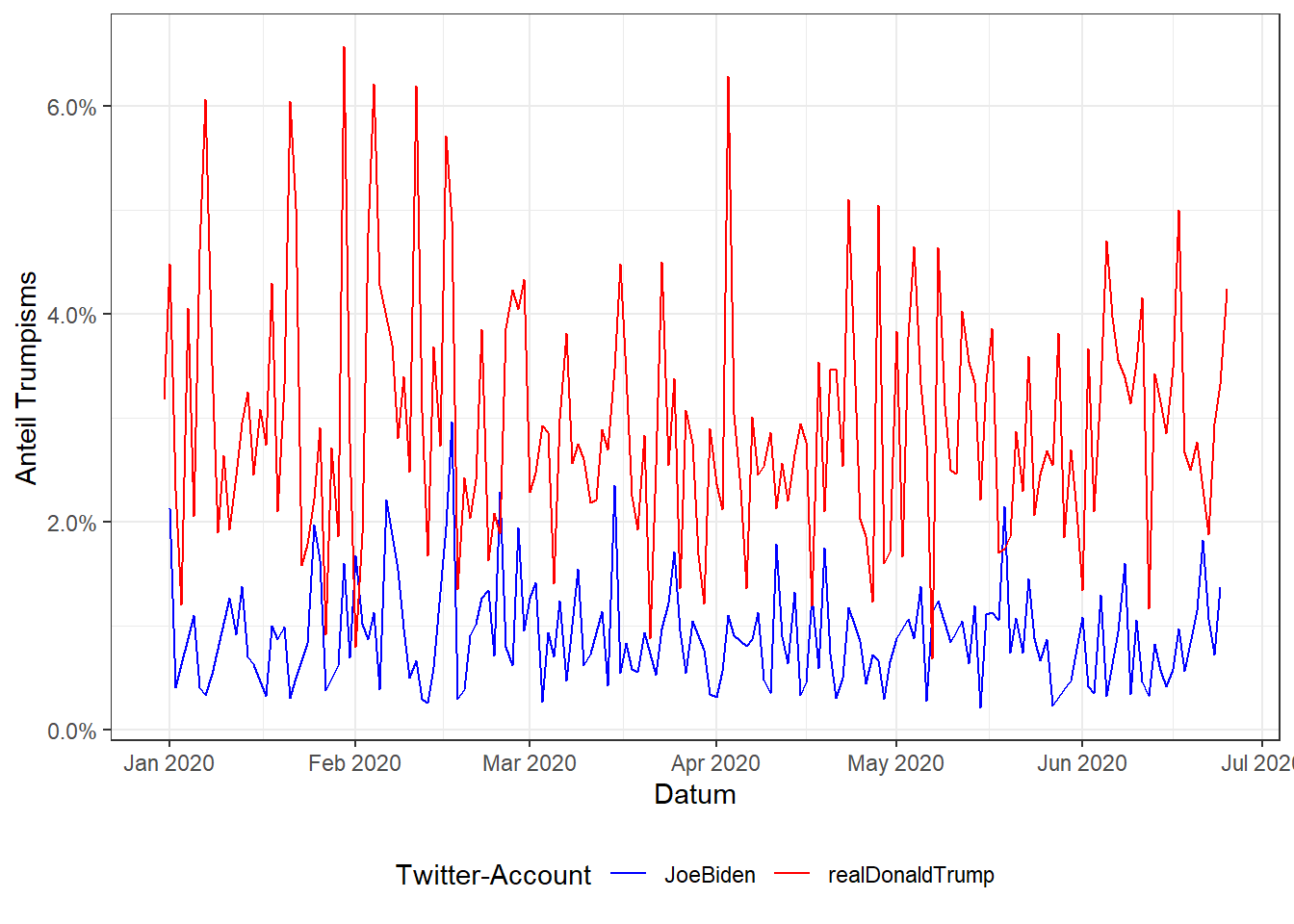
Zwar ist Trump fast immer trumpiger als Biden unterwegs, bei beiden variiert der Anteil der Trumpisms aber deutlich. In einem nächsten Schritt könnten wir nun also versuchen, die Ausschläge nach oben auf bestimmte Ereignisse am jeweiligen Datum zurückzuführen.
19.2 Beispiel-Anwendung: Sentiment-Analyse
Da der wissenschaftliche Gehalt des vorherigen Beispiels eher gering ist, wenden wir uns nun einem gebräuchlicherem Anwendungsfall zu: Sentiment-Analysen, also die Bestimmung der (emotionalen) Valenz bzw. Polarität von Texten, greifen sehr häufig auf Diktionäre zurück. Ein bekanntes und weitverbreitetes Sentiment-Dictionary für englischsprachige Texte ist das Sentiment Lexicon von Bing Liu, das aus zwei Wortlisten, einmal positive Begriffe, einmal negative Begriffe, besteht. Es wird nicht zuletzt häufig für Social-Media-Sentiment-Analysen herangezogen, da es auch weitverbreitete misspellings enthält. Insgesamt sind knapp 6800 Wörter (2006 positive, 4783 negative) enthalten.
Das Sentiment Lexicon kann unter obigem Link kostenfrei heruntergeladen werden und muss zunächst entpackt werden.46 Beide Wortlisten sind jeweils als Textdatei (positive-words.txt bzw. negative-words.txt) vorhanden, wobei – nach einem Einführungstext – jedes Wort in einer eigenen Zeile steht.
Um die Wortlisten zu verwenden, nutzen wir die Basis-Funktion scan(), mit der Textdateien in einen Vektor eingelesen werden können. Neben dem Dateipfad geben wir mit dem Argument what den Objekttypen des Ziel-Vektors an, in unserem Fall also character(). scan() trennt automatisch bei Whitespace und Zeilenumbrüchen, sodass wir in diesem Fall kein weiteres Trennzeichen definieren müssen. Mit dem Argument skip geben wir zudem an, dass die ersten 30 bzw. 31 Zeilen übersprungen werden sollen, da diese in den jeweiligen Dateien den Einführungstext beinhalten (Tipp: öffnet man die Textdateien in RStudio, werden diese mit Zeilennummerierung angezeigt).
positive_words <- scan("data/positive-words.txt", what = character(), skip = 30)
negative_words <- scan("data/negative-words.txt", what = character(), skip = 31)Nun erstellen wir auch schon das entsprechende Dictionary-Objekt. Nachdem wir vorher nur eine Kategorie (Trumpisms) definiert haben, sind nun zwei Kategorien nötig – eine für positives Sentiment, eine für negatives –, die entsprechend die jeweilige Wortliste zugeordnet bekommen. Prinzipiell ist die Anzahl der Kategorien in dictionary() nicht beschränkt und auch verschachtelte Kategorien sind möglich:
sentiment_dictionary <- dictionary(list(
positive = positive_words,
negative = negative_words
))
sentiment_dictionary## Dictionary object with 2 key entries.
## - [positive]:
## - a+, abound, abounds, abundance, abundant, accessable, accessible, acclaim, acclaimed, acclamation, accolade, accolades, accommodative, accomodative, accomplish, accomplished, accomplishment, accomplishments, accurate, accurately [ ... and 1,986 more ]
## - [negative]:
## - 2-faced, 2-faces, abnormal, abolish, abominable, abominably, abominate, abomination, abort, aborted, aborts, abrade, abrasive, abrupt, abruptly, abscond, absence, absent-minded, absentee, absurd [ ... and 4,763 more ]Der Rest erfolgt wie gehabt. Zunächst zählen wir wieder die absoluten Häufigkeiten, gruppiert nach Account, aus:
## Document-feature matrix of: 2 documents, 2 features (0.0% sparse) and 1 docvar.
## features
## docs positive negative
## JoeBiden 2483 1467
## realDonaldTrump 3806 2512Joe Biden verwendet also ca. 1,6-mal so viele positive Wörter wie negative Wörter, Donald Trump 1,5-mal so viele. Wir können dieses Verhältnis auch darstellen, indem wir die DFM nachträglich gewichten:
dfm(tweets_corpus, dictionary = sentiment_dictionary, groups = "account") %>%
dfm_weight(scheme = "prop")## Document-feature matrix of: 2 documents, 2 features (0.0% sparse) and 1 docvar.
## features
## docs positive negative
## JoeBiden 0.6286076 0.3713924
## realDonaldTrump 0.6024058 0.3975942In beiden Fällen lassen also rund 60% aller in den Tweets verwendeten und im Sentiment Lexicon enthaltenen Begriffe auf positives Sentiment schließen. Zu beachten ist, dass es durchaus eine Rolle spielt, wann wir die DFM gewichten; führen wir die Gewichtung, wie oben, vor der Anwendung des Diktionärs durch, erhalten wir den Anteil, den positive bzw. negative Begriffe am gesamten Text aller Tweets der beiden Kandidaten ausmachen.
dfm(tweets_corpus, groups = "account") %>%
dfm_weight(scheme = "prop") %>%
dfm(dictionary = sentiment_dictionary)## Document-feature matrix of: 2 documents, 2 features (0.0% sparse) and 1 docvar.
## features
## docs positive negative
## JoeBiden 0.04422241 0.02618081
## realDonaldTrump 0.04828907 0.03187130Wir sehen: Trumps Tweets enthalten anteilig sowohl mehr positive als auch mehr negative Begriffe; dies deutet darauf hin, dass Trump insgesamt eine emotionalere Sprache verwendet (natürlich sind auch einige beliebte Trumpisms wie “great” und “sad” im Sentiment Lexicon enthalten).
Betrachten wir erneut den Zeitverlauf. Auch hier ergeben sich kaum Änderungen gegenüber dem Vorgehen bei den Trumpisms – wir gruppieren erneut zusätzlich nach day, gewichten aber dieses Mal erst im Anschluss an die Diktionär-Auszählung, um das Verhältnis von positivem zu negativem Sentiment zu erhalten.
sentiment_ratio_per_day <- dfm(tweets_corpus, groups = c("account", "day"), dictionary = sentiment_dictionary) %>%
dfm_weight(scheme = "prop")
sentiment_ratio_per_day## Document-feature matrix of: 354 documents, 2 features (0.565% sparse) and 2 docvars.
## features
## docs positive negative
## realDonaldTrump.2019/12/31 0.5000000 0.5000000
## JoeBiden.2020/01/01 0.5714286 0.4285714
## realDonaldTrump.2020/01/01 0.8750000 0.1250000
## JoeBiden.2020/01/02 0.8333333 0.1666667
## realDonaldTrump.2020/01/02 0.3636364 0.6363636
## JoeBiden.2020/01/03 0.3500000 0.6500000
## [ reached max_ndoc ... 348 more documents ]Zur grafischen Darstellung konviertieren wir das Ergebnis wieder in tidy data. Zu beachten ist, dass tidy() direkt in long data konvertiert, die Werte für positiv/negativ (bzw. allgemeiner gesprochen: die Kategorien des Diktionärs) stehen nun nicht mehr in eigenen Spalten, sondern sind Ausprägungen der Variablen term, wobei der jeweilige Wert in der Variable count steht.
## # A tibble: 704 x 3
## document term count
## <chr> <chr> <dbl>
## 1 realDonaldTrump.2019/12/31 positive 0.5
## 2 JoeBiden.2020/01/01 positive 0.571
## 3 realDonaldTrump.2020/01/01 positive 0.875
## 4 JoeBiden.2020/01/02 positive 0.833
## 5 realDonaldTrump.2020/01/02 positive 0.364
## 6 JoeBiden.2020/01/03 positive 0.35
## 7 realDonaldTrump.2020/01/03 positive 0.522
## 8 JoeBiden.2020/01/04 positive 0.467
## 9 realDonaldTrump.2020/01/04 positive 0.353
## 10 JoeBiden.2020/01/05 positive 0.125
## # ... with 694 more rowsWie oben können wir nun einen Plot erzeugen. Da sich aus dem Anteil des positiven Sentiments automatisch Anteil des negativen Sentiments (da sich beide Werte zu 1 bzw. 100% aufsummieren) ergibt, ist es hier wenig sinnvoll, beide Werte zu plotten; wir filtern daher nur eine der beiden Kategorien an. Ich zeichne außerdem eine horizontale Linie bei 50% ein, um den Übergang von mehrheitlich positivem zu mehrheitlich negativen Sentiment zu kennzeichnen.
sentiment_ratio_per_day %>%
tidy() %>%
separate(document, c("account", "day"), sep = "\\.") %>%
mutate(day = as.Date(day)) %>%
filter(term == "positive") %>%
ggplot(aes(x = day, y = count, color = account, group = account)) +
geom_line() +
geom_hline(aes(yintercept = 0.5), linetype = "dashed") +
scale_color_manual(values = c("blue", "red")) +
scale_x_date(date_breaks = "1 month", date_labels = "%b %Y") +
scale_y_continuous(labels = scales::percent, limits = c(0,1)) +
theme_bw() +
theme(legend.position = "bottom") +
labs(x = "Datum", y = "Anteil positives Sentiment", color = "Twitter-Account")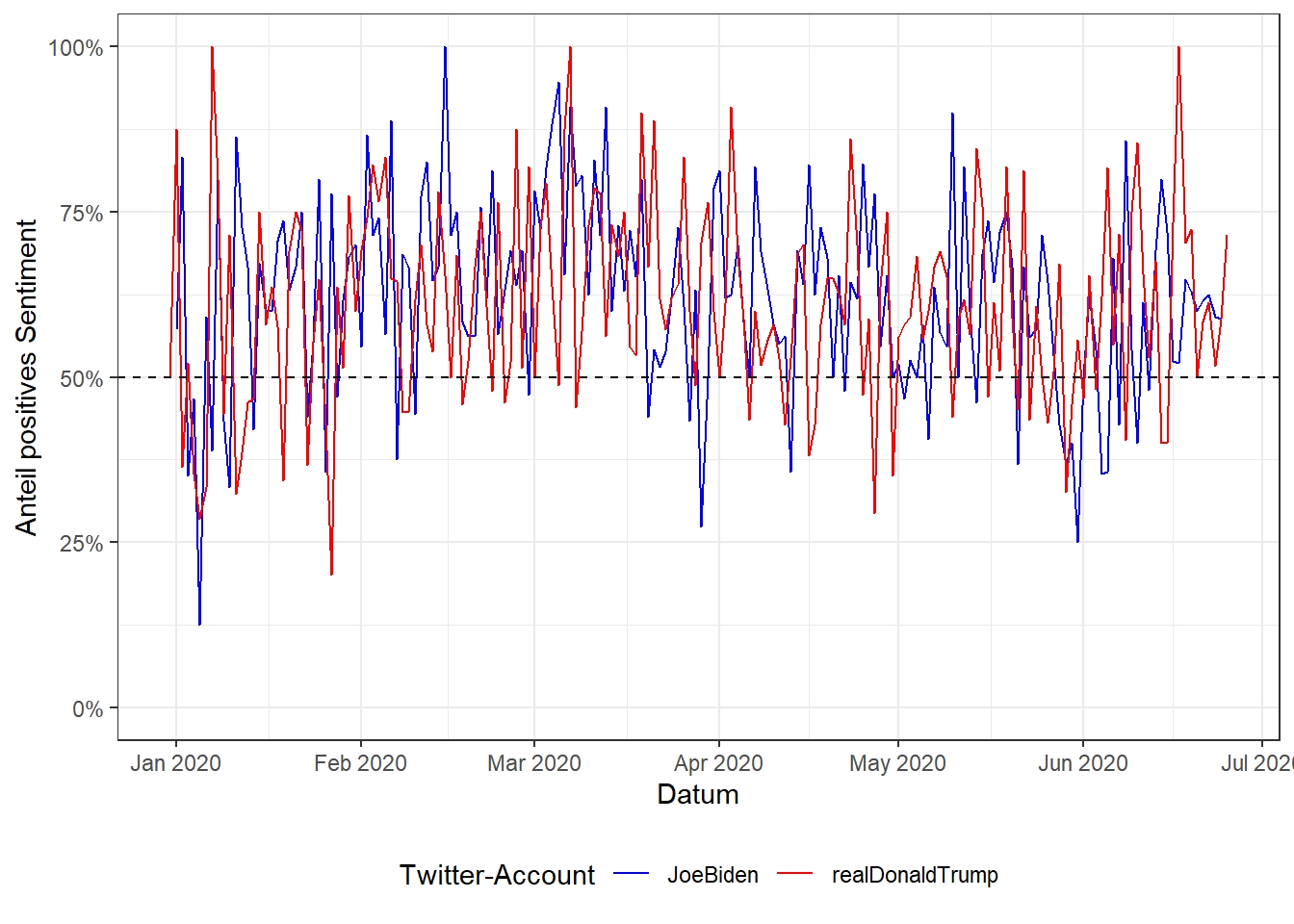
Wir sehen, dass beide Kandidaten mehrheitlich positiv twittern, es aber durchaus auch negative Ausschläge gibt; auch hier könnten wir nun im nächsten Schritt versuchen, diese Ausschläge auf bestimmte Ereignisse zurückzuführen.
19.3 Gewichtete Lexika
Bisher haben wir mit kategorialen Lexika gearbeitet, die alle Begriffe einer Kategorie gleichermaßen gewichten. Für manche Anwendungen ist das aber eine zu simplifizierende Annahme, da man davon ausgehen kann, dass bestimmte Begriffe stärker mit einem Konstrukt in Verbindung stehen als andere; so dürfte beispielsweise das Wort “hate” auf einen stärkeren negativen Affekt hinweisen als das Wort “dislike”. In gewichteten Lexika wird dies versucht zu berücksichtigen, indem jeder Begriff einen numerischen Wert zugeteilt bekommt, der die Stärke der Assoziation mit dem übergeordneten Konstrukt ausdrückt.
Quanteda bietet aktuell (noch) keine einfache Möglichkeit, mit gewichteten Lexika zu arbeiten. Dies ist daher ein guter Zeitpunkt, uns den bisher bekannten Workflow in einem anderen Package, dem tidytext-Package anzusehen. Praktischerweise enthält tidytext eines der bekanntesten gewichteten Lexika, das AFINN von Finn Årup Nielsen, mit dem ebenfalls positives bzw. negatives Sentiment erfasst werden soll. Wir können uns dieses Lexikon mit der Funktion get_sentiments("afinn") anzeigen lassen:47
## # A tibble: 2,477 x 2
## word value
## <chr> <dbl>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
## 7 abhor -3
## 8 abhorred -3
## 9 abhorrent -3
## 10 abhors -3
## # ... with 2,467 more rowsWie wir sehen, ist das Lexikon als Tibble mit zwei Spalten hinterlegt: word enthält die einzelnen Begriffe (2477 an der Zahl, also deutlich weniger umfangreich als das Sentiment Lexicon), value den zugehörigen numerischen Wert, wobei das Sentiment von -5 (stark negativ) bis +5 (stark positiv) skaliert ist.
Der Textkorpus wird in Tidytext durch ein Tibble, in dem je Zeile ein Dokument hinterlegt ist, repräsentiert – in unserem Fall also durch das Objekt tweets, das wir ganz zu Beginn des Kapitels eingelesen haben. Die Tokenisierung erfolgt durch die Funktion unnest_tokens(), wobei der Name der neu zu erstellenden Token-Variable (in diesem Fall word) und der Name der Textvariable im Ausgangsdatensatz (in diesem Fall content) angegeben werden muss. Das Resultat ist ein Tibble, in dem nun jede Zeile für ein Wort eines Dokuments steht – aus ursprünglich 4153 Zeilen (= Dokumente bzw. Tweets) sind nun 119.956 Zeilen (= einzelne Wörter) geworden:
tidy_tweets <- tweets %>%
unnest_tokens(word, content) %>%
select(id, account, day, word) # Auswahl der für uns relevanten Variablen
tidy_tweets## # A tibble: 119,956 x 4
## id account day word
## <dbl> <chr> <chr> <chr>
## 1 1 JoeBiden 2020/01/01 our
## 2 1 JoeBiden 2020/01/01 final
## 3 1 JoeBiden 2020/01/01 fundraising
## 4 1 JoeBiden 2020/01/01 deadline
## 5 1 JoeBiden 2020/01/01 of
## 6 1 JoeBiden 2020/01/01 2019
## 7 1 JoeBiden 2020/01/01 is
## 8 1 JoeBiden 2020/01/01 just
## 9 1 JoeBiden 2020/01/01 hours
## 10 1 JoeBiden 2020/01/01 away
## # ... with 119,946 more rowsIm Gegensatz zu Quanteda müssen wir für die Sentiment-Analyse keine DFM erstellen.48 Sowohl unsere Tokens als auch das AFINN-Dictionary liegen uns als Tibbles vor. Diese sollen nun miteinander verbunden werden, sodass wir die Werte aus dem AFINN-Dictionary mit dem Inhalt der Tweets verknüpfen können. Zwei Tibbles miteinander verbinden – das ruft nach Join-Operationen (siehe Kapitel 10.2.2.2).
In diesem Fall ist ein inner_join() angebracht. Wir gleichen also für jede Zeile im Tokens-Tibble ab, ob sich ein passender Eintrag dafür im AFINN-Dictionary findet; falls ja, wird der zugehörige Wert angefügt, falls nein, fliegt die Zeile aus dem Datensatz. Das Resultat ist ein verbundenes Tibble mit nun 10.132 Zeilen – unter den rund 120,000 Tokens insgesamt sind also 10.132, für die eine entsprechende emotionale Polarität im 2.477 Einträge umfassenden AFINN-Dictionary gefunden wurde.
## Joining, by = "word"## # A tibble: 10,132 x 5
## id account day word value
## <dbl> <chr> <chr> <chr> <dbl>
## 1 1 JoeBiden 2020/01/01 help 2
## 2 1 JoeBiden 2020/01/01 big 1
## 3 1 JoeBiden 2020/01/01 helping 2
## 4 1 JoeBiden 2020/01/01 help 2
## 5 1 JoeBiden 2020/01/01 reach 1
## 6 2 JoeBiden 2020/01/01 poor -2
## 7 2 JoeBiden 2020/01/01 powerless -2
## 8 2 JoeBiden 2020/01/01 vulnerable -2
## 9 2 JoeBiden 2020/01/01 faith 1
## 10 3 JoeBiden 2020/01/02 join 1
## # ... with 10,122 more rowsVon hier an können wir Auswertungen mit den uns bekannten Tidyverse-Funktionen vornehmen. Um etwa pro Account und Tag das durchschnittliche Sentiment der Tweets zu berechnen, gruppieren wir zunächst mittels group_by() nach account und day und berechnen anschließend den Mittelwert des Sentiments mit summarise().49
afinn_per_day <- tidy_sentiments %>%
group_by(account, day) %>%
summarise(mean_sentiment = mean(value), .groups = "drop")
afinn_per_day## # A tibble: 354 x 3
## account day mean_sentiment
## <chr> <chr> <dbl>
## 1 JoeBiden 2020/01/01 0.333
## 2 JoeBiden 2020/01/02 0.944
## 3 JoeBiden 2020/01/03 -1.29
## 4 JoeBiden 2020/01/04 0.0667
## 5 JoeBiden 2020/01/05 -1.12
## 6 JoeBiden 2020/01/06 -0.133
## 7 JoeBiden 2020/01/07 -0.571
## 8 JoeBiden 2020/01/08 1
## 9 JoeBiden 2020/01/09 -0.192
## 10 JoeBiden 2020/01/10 -1.31
## # ... with 344 more rowsAuch hier bietet sich natürlich wieder eine grafische Darstellung an:
afinn_per_day %>%
mutate(day = as.Date(day)) %>%
ggplot(aes(x = day, y = mean_sentiment, color = account, group = account)) +
geom_line() +
geom_hline(aes(yintercept = 0), linetype = "dashed") +
scale_color_manual(values = c("blue", "red")) +
scale_x_date(date_breaks = "1 month", date_labels = "%b %Y") +
scale_y_continuous(limits = c(-2,2)) +
theme_bw() +
theme(legend.position = "bottom") +
labs(x = "Datum", y = "AFINN-Sentiment", color = "Twitter-Account")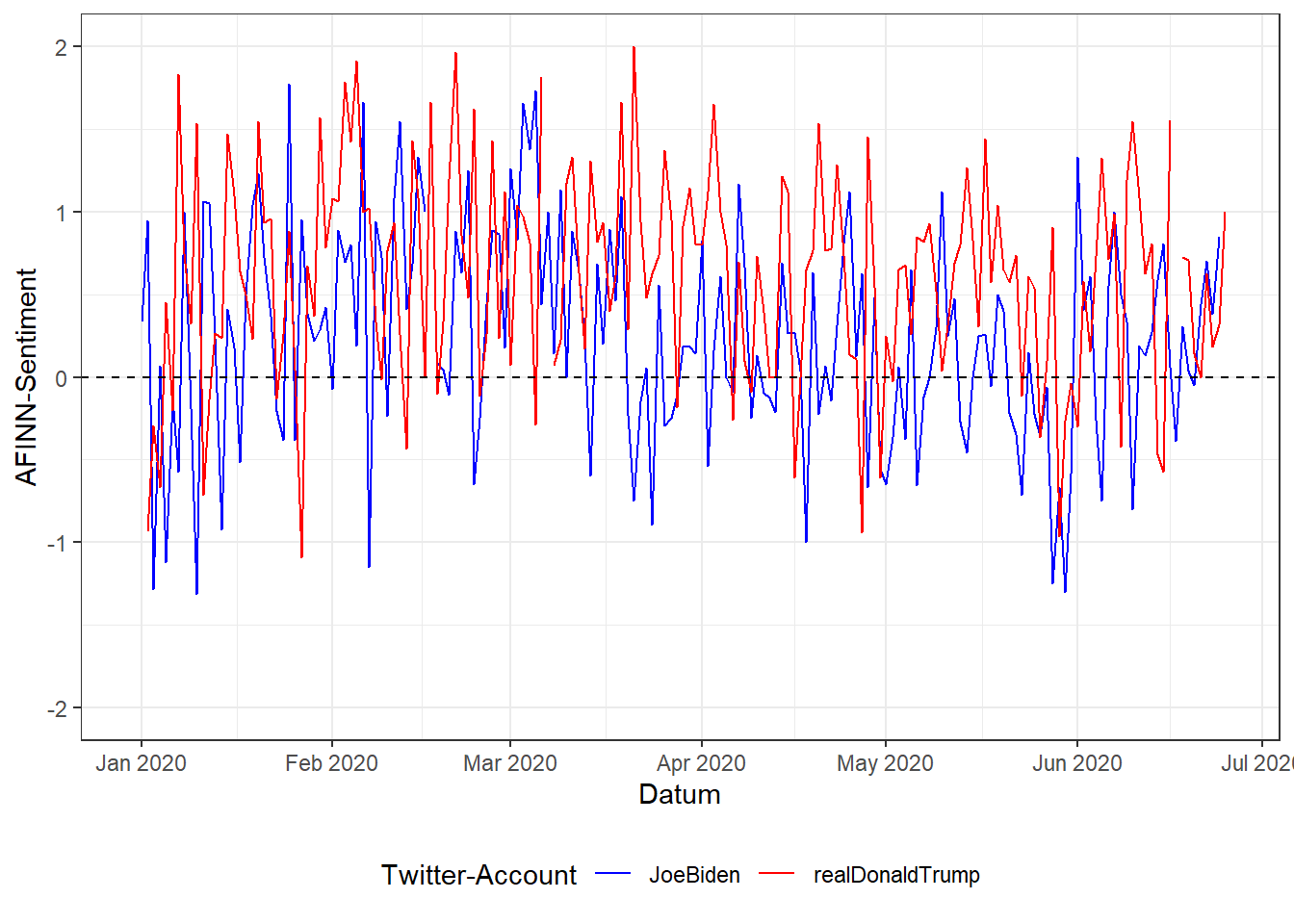
Das berechnete Sentiment der Tweets mittels AFINN-Dictionary ist also durchaus mit der vorherigen Sentiment-Analyse, basierend auf Bing Lius Sentiment Lexicon, vergleichbar: auch hier überwiegt bei beiden Kandidaten positives Sentiment, die Ausschläge nach unten kommen zu denselben Zeitpunkten, wenn auch die absoluten Wertausprägungen natürlich unterschiedlich (und auch unterschiedlich skaliert) sind.
19.4 Übungsaufgaben
Erstellen Sie für die folgenden Übungsaufgaben eine eigene Skriptdatei oder eine R-Markdown-Datei und speichern diese als ue19_nachname.R bzw. ue19_nachname.Rmd ab.
Laden Sie den Datensatz facebook_europawahl.csv und filtern Sie lediglich Posts der im Bundestag vertretenen Parteien.
Für diese Übungsaufgaben wechseln wir also die Sprache. Entsprechend benötigen wir auch ein neues Lexikon: Der SentimentWortSchatz (kurz SentiWS) von Robert Remus, Uwe Quasthoff und Gerhard Heyer enthält die positive bzw. negative Polarität (skaliert von -1 bis 1) von rund 3.500 deutschen Wörtern + zugehörige Flexionsformen, zusammen also rund 34.000 Wörter. Die aktuelle Version (v2.0) lässt sich auf der oben verlinkten Seite kostenfrei herunterladen.
Positive und negative Wörter liegen in zwei Textdateien ab, deren Import nicht ganz trivial ist. Mit folgendem Code (Dateipfad natürlich eventuell anpassen) werden beide Wörterbücher geladen und in einem Tibble sentiws vereint. Natürlich schadet es nicht, die einzelnen Schritte selbst nachzuvollziehen.
sentiws_pos <- read_delim("data/SentiWS_v2.0_Positive.txt", col_names = c("word", "value", "flections"), delim = "\t") %>%
mutate(sentiment = "positive")
sentiws_neg <- read_delim("data/SentiWS_v2.0_Negative.txt", col_names = c("word", "value", "flections"), delim = "\t") %>%
mutate(sentiment = "negative")
sentiws <- sentiws_pos %>%
bind_rows(sentiws_neg) %>%
separate(word, c("word", "type"), sep = "\\|") %>%
mutate(word = str_c(word, flections, sep = ",")) %>%
select(-flections, -type) %>%
separate_rows(word, sep = ",") %>%
na.omit()Erstellen Sie ein Quanteda-Dictionary mit den Kategorien positiv und negativ aus den SentiWS-Lexikon. Gibt es Unterschiede zwischen den Parteien hinsichtlich des Sentiments ihrer Posts zur Europawahl?
- Um die beiden Wortlisten aus dem Tibble als Vektoren zu extrahieren, können Sie mit den Tidyverse-Funktionen
filter()undpull()arbeiten. - (Wann) Ist es sinnvoll, die Wortlisten in Kleinschreibung zu konvertieren?
Berechnen Sie das durchschnittliche Sentiment pro Partei auf Basis der Polaritäts-Werte (value) in SentiWS. Unterscheiden sich die Ergebnisse von der obigen Variante, bei der nur die Kategorien verwendet werden?
Hierfür ist ein Kompressionsprogramm, das mit
.rar-Dateien umgehen kann, etwa WinRar oder 7Zip, nötig.↩︎Falls eine Fehlermeldung auftritt, muss zunächst noch das
textdata-Package installiert werden:install.packages("textdata")und das Lexikon anschließend heruntergeladen werden.↩︎Dies geht in Tidytext mit der Funktion
cast_dfm().↩︎Das uns noch unbekannte Argument
.groupsist ein neues Argument ab derdplyr-Version1.0.0, das es ermöglicht, vorhandene Gruppierungen nach dem Zusammenfassen mit dem Wert"drop"auch ohne anschließendesungroup()aufzuheben oder mit dem Wert"keep"beizubehalten.↩︎