18 Textdeskription und einfache Textvergleiche
Nachdem wir im vergangenen Kapitel die Grundlagen und -begriffe der automatisierten Inhaltsanalyse kennengelernt haben, setzen wir uns nun etwas intensiver mit der deskriptiven Analyse von Texten auseinander und werden auch einige einfache Möglichkeiten betrachten, Texte bzw. Dokumente miteinander zu vergleichen.
Wir arbeiten erneut mit den Tweets von Trump und Biden und führen daher zunächst die uns bereits bekannten Schritte zur Aufbereitung des Tweet-Korpus durch:
# Setup
library(tidyverse)
library(tidytext)
library(quanteda)
# Daten einlesen
tweets <- read_csv("data/trump_biden_tweets_2020.csv")
# Korpus erzeugen
tweets_corpus <- corpus(tweets, docid_field = "id", text_field = "content")
# Tokens erzeugen
tweets_tokens <- tokens(tweets_corpus,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove_url = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("english"))
# DFM erzeugen
tweets_dfm <- dfm(tweets_tokens)18.1 Worthäufigkeiten
Wir haben bereits im vergangenen Kapitel gesehen, dass wir anhand der DFM schon simple Worthäufigkeiten auszählen können. Allgemein erhalten wir in Quanteda die absoluten Feature-Häufigkeiten mit featfreq().
An dieser Stelle sei außerdem auf die Funktion tidy() aus dem Tidytext-Package verwiesen, die Output vieler Quanteda-Funktionen automatisch in tidy data konvertieren kann und uns somit den weiteren Umgang mit den Daten erleichert:
featfreq(tweets_dfm) %>%
tidy() %>% # In tidy data konvertieren
arrange(desc(x)) # Absteigend nach Anzahl sortieren## # A tibble: 8,534 x 2
## names x
## <chr> <dbl>
## 1 great 619
## 2 trump 512
## 3 president 449
## 4 people 423
## 5 thank 380
## 6 donald 352
## 7 need 338
## 8 just 325
## 9 now 308
## 10 country 296
## # ... with 8,524 more rowsQuanteda bietet außerdem einige rudimentäre Möglichkeiten, Textdaten zu visualisieren. Erinnert sich noch jemand an den Trend, alles in Wortwolken zu visualisieren? Mit textplot_wordcloud() erzeugen wir eine solche:
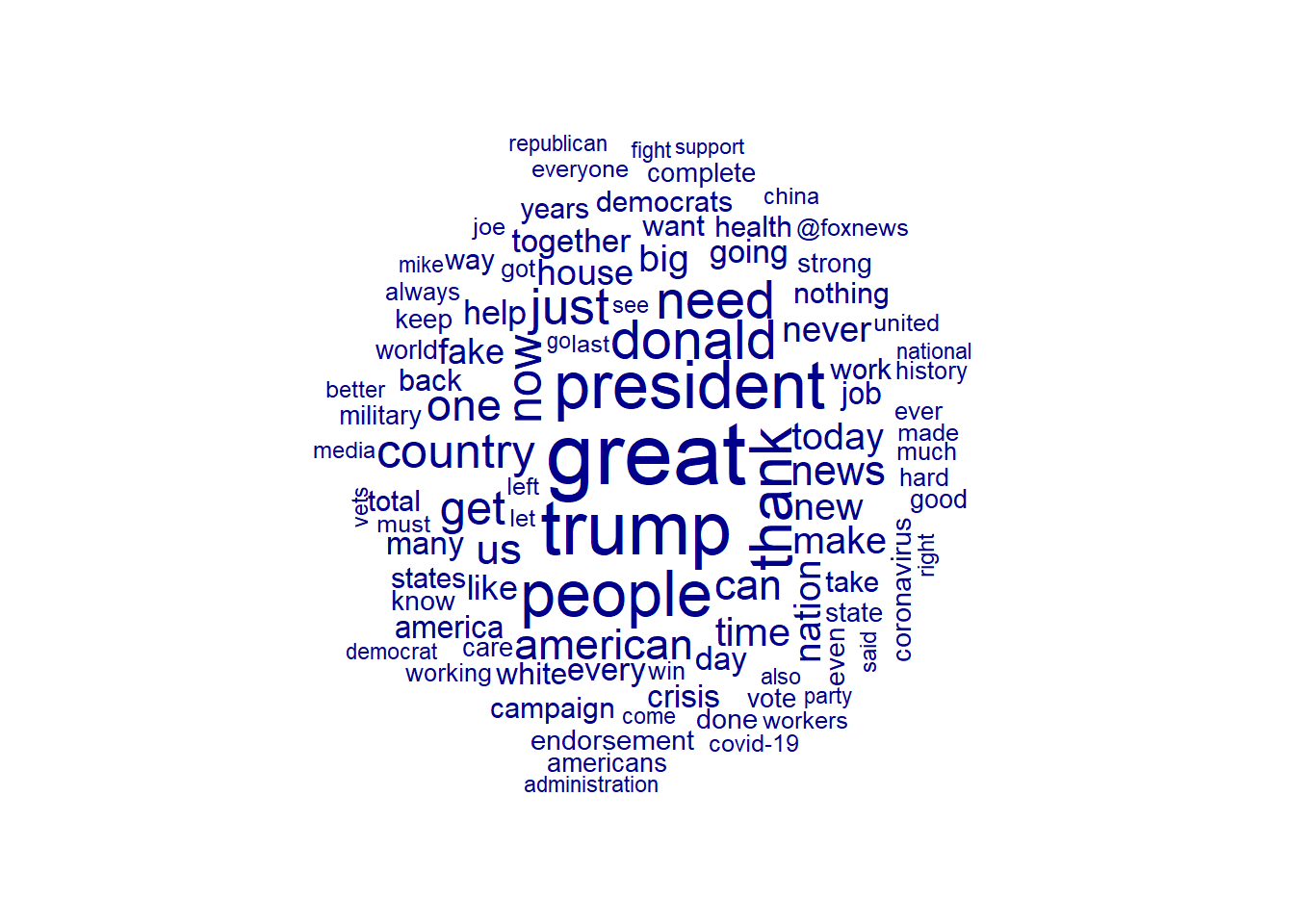
An dieser Stelle ist es sinnvoll, eine zweite DFM zu erstellen, die nicht auf den einzelnen Dokumenten (= einzelne Tweets), sondern auf den beiden Accounts basiert. Dies führt dazu, dass alle Tweets eines Accounts als ein langes Dokument betrachtet werden, ermöglicht uns aber bereits einfache Vergleiche zwischen den beiden Accounts. Dies erreichen wir im dfm()-Befehl mit dem Argument groups, wobei wir basierend auf unseren Docvars gruppieren können:
## Document-feature matrix of: 2 documents, 8,534 features (36.8% sparse) and 1 docvar.
## features
## docs final fundraising deadline just hours away need help every donation
## JoeBiden 9 4 4 132 5 46 282 120 151 8
## realDonaldTrump 5 0 0 193 2 30 56 72 33 0
## [ reached max_nfeat ... 8,524 more features ]Diese DFM hat also nur noch zwei Zeilen (= zwei Dokumente, eines pro Account) und summiert die Feature-Häufigkeiten über alle Tweets, getrennt nach Account, hinweg.
Wir können nun die Wortwolke auch für unsere beiden Accounts getrennt erzeugen lassen, indem wir das Argument comparison = TRUE verwenden – mit der alten DFM auf Tweet-Ebene würde hier für jedes Dokument (Tweet) getrennt eine Wolke erzeugt werden, was natürlich kaum sinnvoll darstellbar und interpretierbar wäre.
textplot_wordcloud(tweets_dfm_grouped,
max_words = 100,
comparison = TRUE,
color = c("blue", "red"))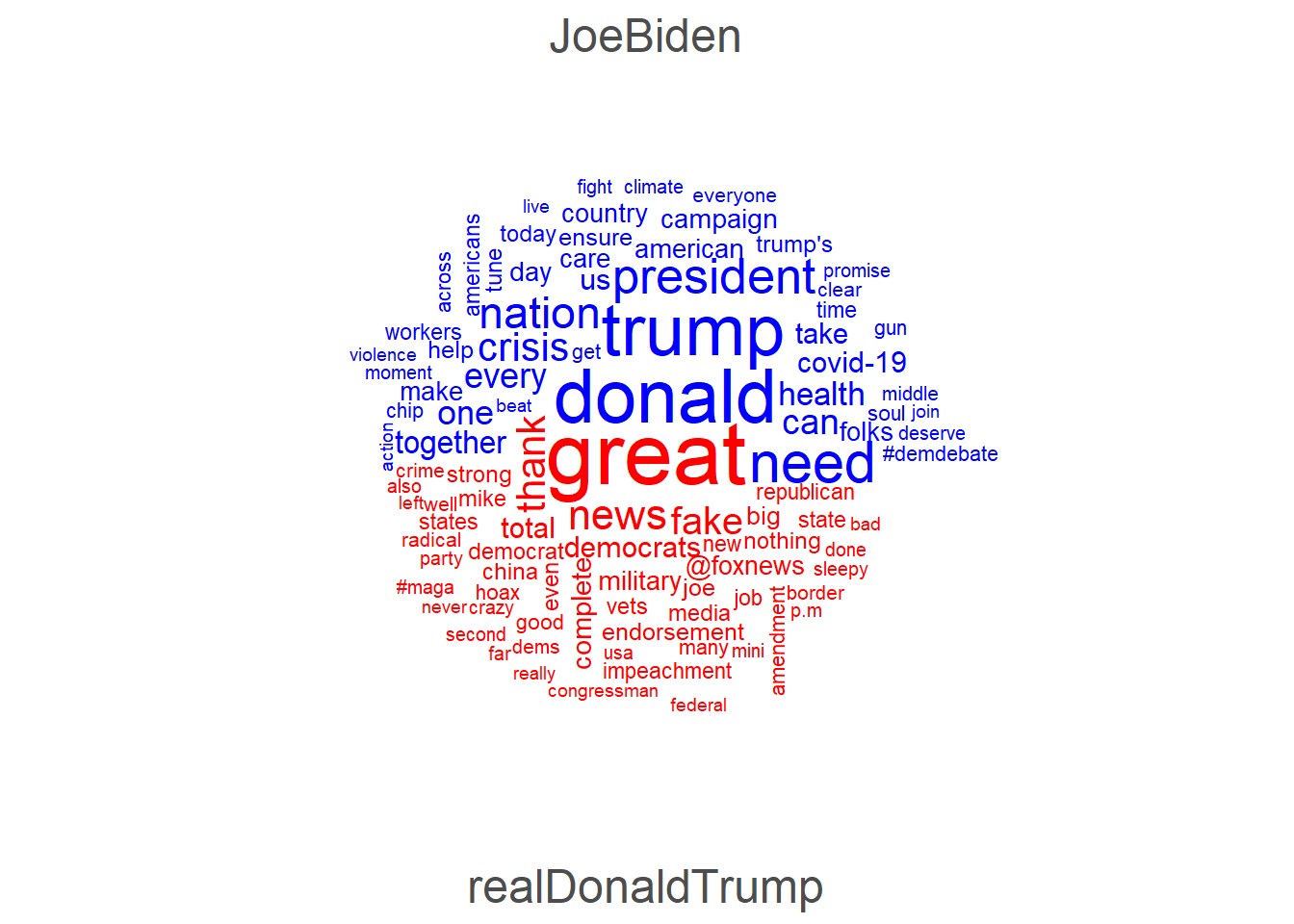
18.2 Konkordanzen (Keywords in context)
Durch den Bag-of-Word-Approach verlieren wir den Kontext, in dem Begriffe fallen. Daher kann es oft sinnvoll sein, für ausgewählte Schlüsselbegriffe auch die zugehörigen Textstellen samt Kontext auszugeben. Dies wird auch als Konkordanz bezeichnet.
In Quanteda können wir über die Funktion kwic() (für Keywords in context) solche Konkordanzen ausgeben lassen. Dies kann anhand eines Korpus- oder eines Token-Objekts geschehen; da wir die Tokens bereits um Stoppwörter bereinigt haben, ist es hier sinnvoller den Korpus zu nutzen, damit sich der Kontext im ursprünglichen Satzzusammenhang erschließen lässt. Als zweites Argument benötigen wir noch das Suchmuster, nach dem gesucht werden soll – in der Regel also ein bestimmter Schlüsselbegriff (kwic() ist per Default case-insesitive, ignoriert also Groß- und Kleinschreibung, sodass wir mit “news” auch “News” und “NEWS” finden):
## # A tibble: 248 x 7
## docname from to pre keyword post pattern
## <chr> <int> <int> <chr> <chr> <chr> <fct>
## 1 36 10 10 off on commenting on the news tonight until we know more news
## 2 150 2 2 Great news out of Utah . No news
## 3 282 21 21 already - but I've got news for them : We're not news
## 4 446 5 5 I'm heartbroken at the news of yet another mass shooting news
## 5 674 28 28 live-tweeting her appearances on cable news . We need a president news
## 6 882 3 3 This morning's news of another rise in unemployment news
## 7 943 2 2 Today's news that more than 22 million news
## 8 1113 15 15 numbers we see in the news are more than just statistics news
## 9 1268 17 17 toll we see in the news is so much more than news
## 10 1435 7 7 , I've got some big news : Next week , I'm news
## # ... with 238 more rowsZu den Informationen, die wir erhalten, zählen die Dokument-ID, die Textstelle (in Tokens) in diesem Dokument, ab dem unser Begriff auftritt, sowie der vorherige und nachfolgende Satzkontext (per Default bis zu 5 Wörter, kann mit dem window-Argument angepasst werden).
Das Suchmuster kann einen RegEx-Ausdruck beinhalten, um beispielsweise schnell nach allen Hashtags zu suchen:
## # A tibble: 374 x 7
## docname from to pre keyword post pattern
## <chr> <int> <int> <chr> <chr> <chr> <fct>
## 1 74 9 9 step on stage for tonight's #DemDebate "in Iowa . Make sure" #*
## 2 75 42 42 be Commander in Chief . #DemDebate "" #*
## 3 77 49 49 an increasingly dangerous world . #DemDebate "" #*
## 4 78 47 47 advance our common security . #DemDebate "" #*
## 5 79 18 18 of the American people . #DemDebate "" #*
## 6 80 53 53 Kim regime's bad behavior . #DemDebate "" #*
## 7 81 39 39 don't share our values . #DemDebate "" #*
## 8 82 38 38 system easier to navigate . #DemDebate "" #*
## 9 83 12 12 prices with drug companies . #DemDebate "" #*
## 10 86 41 41 affordable for every parent . #DemDebate "" #*
## # ... with 364 more rows18.3 Kollokationen
Als Kollokation wird das gemeinsame Auftreten von zwei oder mehr Wörtern bezeichnet. Wir können uns solche Kollokationen mit textstat_collocations() ausgeben lassen, wobei auch hier entweder ein Korpus- oder ein Token-Objekt angegeben werden muss. Hier zunächst mit dem Korpus:
## # A tibble: 11,805 x 6
## collocation count count_nested length lambda z
## <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 of the 434 0 2 1.75 31.2
## 2 in the 396 0 2 1.91 32.2
## 3 thank you 309 0 2 8.11 34.8
## 4 donald trump 302 0 2 8.17 47.7
## 5 will be 254 0 2 4.33 49.9
## 6 to the 251 0 2 0.469 6.96
## 7 for the 245 0 2 1.67 22.9
## 8 on the 229 0 2 2.05 26.2
## 9 is a 225 0 2 2.36 30.7
## 10 we need 223 0 2 5.04 42.1
## # ... with 11,795 more rowsDas sagt uns also noch nicht sonderlich viel über die Dokumente aus, da die häufigsten Kollokationen aus Stoppwörtern (“of the”, “in the” etc.) bestehen. Wir können dies umgehen, indem wir die bereits um diese Wörter bereinigten Tokens übergeben:
## # A tibble: 6,231 x 6
## collocation count count_nested length lambda z
## <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 donald trump 302 0 2 7.50 44.4
## 2 fake news 151 0 2 7.67 38.4
## 3 white house 145 0 2 9.28 30.7
## 4 complete total 104 0 2 8.93 31.2
## 5 total endorsement 103 0 2 8.42 32.9
## 6 united states 87 0 2 8.63 28.7
## 7 american people 79 0 2 4.37 29.8
## 8 health care 73 0 2 7.12 32.4
## 9 president trump 65 0 2 3.26 22.7
## 10 military vets 60 0 2 7.64 28.8
## # ... with 6,221 more rowsEine andere Möglichkeit besteht darin, nicht nach der absoluten Häufigkeit, sondern nach dem ebenfalls berechneten Lambda-Koeffizienten zu sortieren. Dieser fällt, vereinfacht gesagt, umso höher aus, je wahrscheinlicher exakt diese Kombination aus Wörtern ist (so gehören etwa sowohl “donald trump” als auch “president trump” zu den absolut am häufigsten vorhandenen Kollokationen; diese weisen aber ein geringeres Lambda auf, da “trump” sowohl mit “donald” als auch mit “president” auftritt und entsprechend die Wahrscheinlichkeit geringer ist als bei Wortpaaren, die nahezu immer in dieser Kombination in diesem Korpus auftreten, z. B. “oval office”). Mit dem min_count-Argument können wir festlegen, dass die jeweilige Kollokation mindestens x mal im Korpus vorkommen muss:
## # A tibble: 1,200 x 6
## collocation count count_nested length lambda z
## <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 town hall 28 0 2 15.1 9.19
## 2 swine flu 10 0 2 14.1 8.48
## 3 prime minister 11 0 2 13.3 8.66
## 4 THANK YOU 50 0 2 13.3 14.2
## 5 witch hunt 21 0 2 13.1 8.89
## 6 approval rating 26 0 2 12.8 13.3
## 7 george floyd 14 0 2 12.8 8.63
## 8 FAKE NEWS 17 0 2 12.2 14.1
## 9 oval office 12 0 2 11.8 8.05
## 10 KEEP AMERICA 13 0 2 11.6 7.97
## # ... with 1,190 more rowsZwar werden in der Regel Kollokationen von zwei Wörtern untersucht, mit dem size-Argument können wir aber auch das gemeinsame Auftreten von mehr als zwei Wörtern ausgeben lassen:
## # A tibble: 2,249 x 6
## collocation count count_nested length lambda z
## <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 approval rating republican party 20 0 4 9.43 2.28
## 2 radical left nothing democrats 19 0 4 2.43 0.671
## 3 donald trump white house 15 0 4 6.15 1.62
## 4 end gun violence epidemic 15 0 4 1.82 0.441
## 5 white house news conference 14 0 4 1.51 0.414
## 6 get donald trump white 12 0 4 1.25 0.347
## 7 help keep momentum going 12 0 4 -1.44 -0.436
## 8 rating republican party thank 12 0 4 -1.87 -0.462
## 9 complete total endorsement vote 10 0 4 -3.91 -1.00
## 10 military vets second amendment 9 0 4 8.45 2.30
## # ... with 2,239 more rows18.4 Kookkurenzen
Während bei Kollokationen zwei oder mehr Wörter genau in dieser Wortfolge gemeinsam auftreten müssen, untersucht man mittels Kookkurenzen das gemeinsame Auftreten von Wörtern (oder anderen lexikalischen Einheiten) innerhalb einer höher geordneten Einheit, z. B. in einem Dokument. Hierfür wird zunächst eine Co-occurence-Matrix aufgestellt, die für jeden Token prüft, wie oft dieser mit jeweils allen anderen Tokens im Korpus gemeinsam in einem Dokument auftritt. Das Ergebnis ist also eine Matrix, die genausoviele Zeilen wie Spalten (= alle Tokens im Korpus) aufweist. Wir können diese Matrix mit der Funktion fcm() (für feature co-occurence matrix) erstellen:
## Feature co-occurrence matrix of: 8,534 by 8,534 features.
## features
## features final fundraising deadline just hours away need help every donation
## final 0 2 2 7 1 3 6 7 8 3
## fundraising 0 0 3 3 1 1 2 4 2 2
## deadline 0 0 0 2 1 1 2 5 2 2
## just 0 0 0 14 2 22 39 50 37 6
## hours 0 0 0 0 0 1 4 4 2 1
## away 0 0 0 0 0 8 13 10 8 3
## need 0 0 0 0 0 0 40 73 43 6
## help 0 0 0 0 0 0 0 21 28 9
## every 0 0 0 0 0 0 0 0 14 6
## donation 0 0 0 0 0 0 0 0 0 0
## [ reached max_feat ... 8,524 more features, reached max_nfeat ... 8,524 more features ]Auch hier können wir wieder die tidy()-Funktion aus dem Tidytext-Package nutzen, um schnell die häufigsten Kookkurenzen zu erhalten – zu beachten ist hier, dass die Reihenfolge der Wörter keine Rolle spielt:
## # A tibble: 370,365 x 3
## document term count
## <chr> <chr> <dbl>
## 1 donald trump 329
## 2 news fake 191
## 3 white house 154
## 4 trump president 153
## 5 endorsement complete 113
## 6 need president 110
## 7 total complete 108
## 8 endorsement total 107
## 9 care health 98
## 10 united states 95
## # ... with 370,355 more rows18.5 Textkomplexität
um die Komplexität von Texten zu quantifizieren, gibt es mehrere Herangehensweisen, wobei insbesondere die folgenden beiden weit verbreitet sind:
- Lesbarkeit: Hier wird quantifiziert, wie einfach ein Text lesbar ist. Das wohl bekannteste Lesbarkeitsmaß ist der Flesch Reading Ease (FRE), bei dem die durchschnittliche Satzlänge in Wörtern und die durchschnittliche Silbenzahl pro Wort miteinander verrechnet werden. In Quanteda können zahlreiche Lesbarkeitsmaße mit der Funktion
textstat_readability()berechnet werden – für kurze Tweets sind solche Berechnungen aber weniger sinnvoll, weshalb dies hier ausgespart wird. - Lexikalische Diversität: Hier wird quantifiziert, wie vielfältig (‘lexically rich’) ein Text ist. Das wohl bekannteste Maß ist das Type-Token-Ratio (TTR), wobei einfach die Anzahl an Types, also einzigartigen Tokens, durch die Anzahl an Token geteilt wird. Ein hohes TTR steht demnach für einen großen Wortschatz, wohingegen ein geringes TTR dafür spricht, dass sich viele Wörter häufig wiederholen. Allerdings ist zu beachten, dass das TTR von der Textlänge beeinflusst wird, da es naturgemäß immer schwieriger wird, keine Wörter mehrfach zu verwenden, je länger ein Text ist. Mit der Funktion
textstat_lexdiv()lassen sich neben dem TTR (Default-Maß) daher auch noch einige andere Maße berechnen.
## document TTR
## 1 JoeBiden 0.1736629
## 2 realDonaldTrump 0.180179418.6 Keyness
Während die bisherigen Auswertungen und Maße auch zur Beschreibung von einzelnen Texten bzw. Dokumenten oder gesamten Korpora verwendet werden können, lernen wir nun ein erstes Vergleichsmaß kennen. Mit Keyness wird quantifiziert, wie distinkt ein Begriff für einen Text im Vergleich zu allen anderen Texten im Korpus ist. Es geht also nicht nur darum, dass ein Wort häufig in einem Text vorkommt, sondern zugleich eher selten in den Vergleichstexten ist und somit besonders gut geeignet ist, um den Zieltext zu identifzieren. Wörter mit hoher Keyness können entsprechend als Keyword für diesen Text bezeichnet werden.
Keyness-Maße werden berechnet, indem die Worthäufigkeiten im Zieltext mit den erwarteten Worthäufigkeiten im Vergleichskorpus in einem statistischen Test (z. B. Chi²-Test oder Likelihood-Ratio-Test) verglichen werden. In Quanteda können wir die Keyness mit der Funktion textstat_keyness() berechnen, wobei eine DFM als erstes Argument sowie mit dem Argument target das Zieldokument angegeben wird (alle anderen Dokumente dienen dann jeweils als Vergleichsdokumente). Per Default wird der Chi²-Test genutzt, andere Testverfahren können über das measure-Argument angefordert werden.
Um besonders distinkte Begriffe für Joe Biden bzw. Donald Trump auszuwerten, müssen wir wieder die gruppierte DFM nutzen, sodass alle Tweets eines Accounts als “ein” Dokument gezählt werden:
## # A tibble: 8,534 x 5
## feature chi2 p n_target n_reference
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 donald 452. 0 342 10
## 2 trump 274. 0 396 116
## 3 need 246. 0 282 56
## 4 crisis 196. 0 157 8
## 5 nation 195. 0 188 24
## 6 health 140. 0 127 13
## 7 president 135. 0 307 142
## 8 every 125. 0 151 33
## 9 covid-19 115. 0 99 8
## 10 folks 109. 0 77 0
## # ... with 8,524 more rows## # A tibble: 8,534 x 5
## feature chi2 p n_target n_reference
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 great 346. 0. 589 30
## 2 news 144. 0. 238 10
## 3 fake 139. 0. 196 0
## 4 total 87.6 0. 138 4
## 5 democrats 86.3 0. 143 6
## 6 complete 83.5 0. 125 2
## 7 thank 81.9 0. 309 71
## 8 @foxnews 76.7 0. 108 0
## 9 military 74.9 0. 120 4
## 10 vets 61.0 5.55e-15 86 0
## # ... with 8,524 more rowsEin mittels textstat_keyness() erzeugtes Objekt kann zudem der Funktion textplot_keyness() übergeben werden, um die Keywords auch grafisch darzustellen:
textstat_keyness(tweets_dfm_grouped, target = "realDonaldTrump") %>%
textplot_keyness(n = 10, color = c("red", "blue"))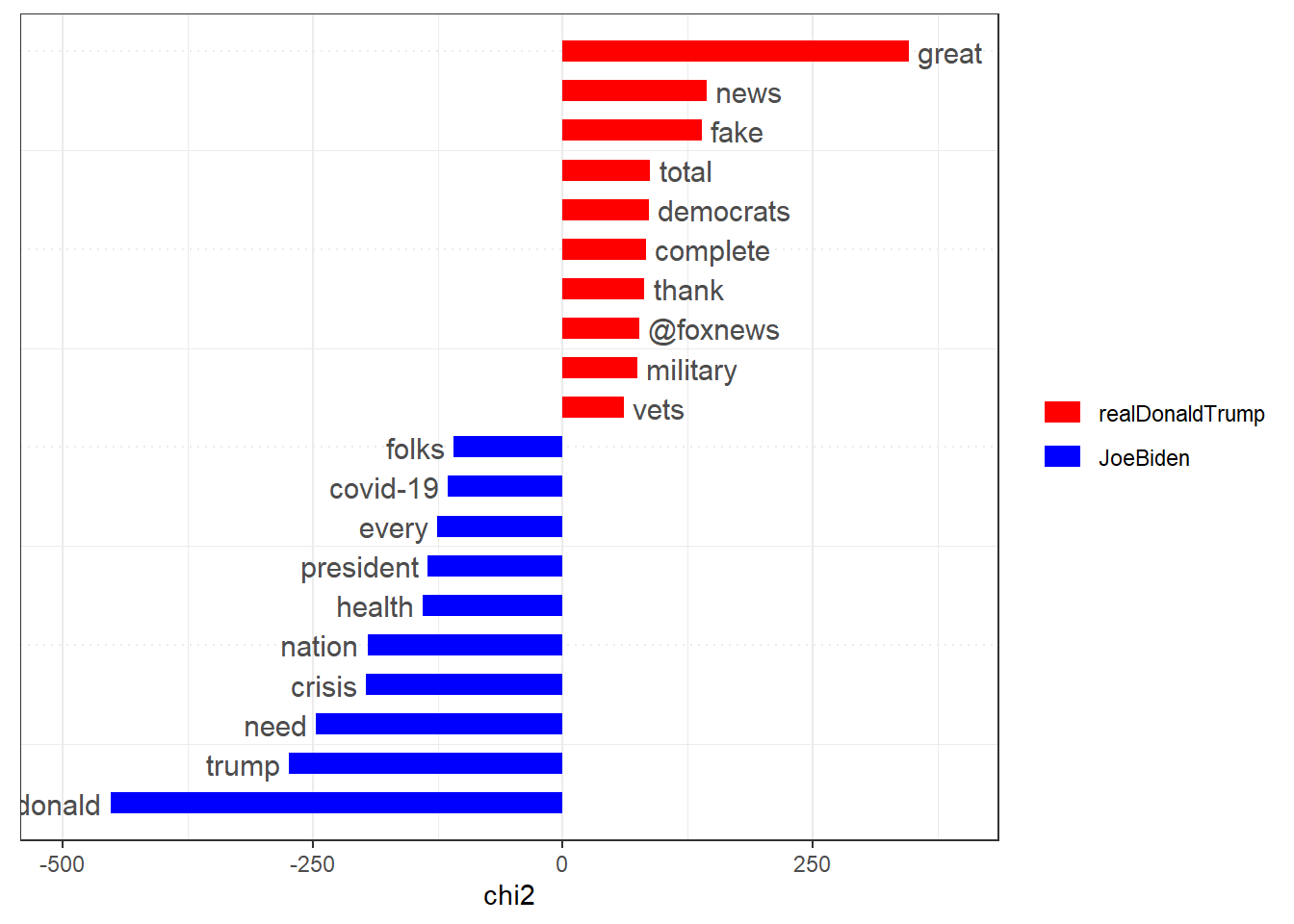
18.7 Übungsaufgaben
Erstellen Sie für die folgende Übungsaufgabe eine eigene Skriptdatei oder eine R-Markdown-Datei und speichern diese als ue18_nachname.R bzw. ue18_nachname.Rmd ab.
Laden Sie den Datensatz facebook_europawahl.csv und filtern Sie lediglich Posts der im Bundestag vertretenen Parteien.
Führen Sie selbstständig eine Textdeskription der Facebook-Posts (und die dazu notwendigen Vorbereitungsschritte) durch. Welche Verfahren bieten sich dafür an? Welche Probleme fallen Ihnen dabei auf?
Betrachten Sie abschließend Keywords für mindestens drei der im Datensatz vorhandenen Parteien. Beschreiben Sie zudem Möglichkeiten, wie man die Ergebnisse (noch) aussagekräftiger gestalten könnte.