20 Textklassifikation durch überwachtes maschinelles Lernen
In diesem Kapitel wenden wir uns der Textklassifikation zu, also der automatisierten Einteilung von Textdokumenten in Klassen, die uns interessierende Kategorien repräsentieren. Zugleich ist dieses Kapitel unser Einstieg in das maschinelle Lernen, bei dem mittels Algorithmen und statistischen Modellen Muster in Daten “erlernt” werden, um z. B. auf Basis dieser Muster Fälle zu gruppieren oder zuzuordnen.
Genauer gesagt steigen wir in Verfahren des überwachten maschinellen Lernens (supervised machine learning) ein. Dies bedeutet, dass wir einen bereits annotierten Datensatz verwenden, um Modelle zu trainieren; wir geben also vor, welche Klassen in den Daten existieren und versuchen Muster zu finden, die die Zuordnung zu diesen Klassen ermöglichen. Anschließend kann das trainierte Modell auf einen nicht annotierten Datensatz angewendet werden, um dort die Klassenzugehörigkeit vorherzusagen. Bei Verfahren des unüberwachten maschinellen Lernens (unsupervised machine learning) sind diese Klassen hingegen nicht vorgeben und die Modelle sollen die Daten selbst einteilen.
Im Kontext der automatisierten Inhaltsanalyse wird überwachtes maschinelles Lernen vor allem dann eingesetzt, wenn ein Teildatensatz eines großen Textkorpus in einer manuellen Inhaltsanalyse annotiert wurde (z. B. ob ein Text populistisch ist oder nicht, ob er Hassrede enthält, oder ob er zu einem von zuvor festgelegten Themen gehört); auf Basis dieses Teildatensatzes wird nun ein Modell trainiert, das anschließend den gesamten Datensatz möglichst reliabel codieren kann. Zudem können die trainierten Modelle genutzt werden, um ein Verständnis über die erlernten Muster zu erhalten – welche Features (bei Textdaten also vor allem N-Gramme) tragen auf welche Art dazu bei, dass das Modell zu einem bestimmten Klassfikationsergebnis kommt, welche Wörter sind also beispielsweise besonders gut dazu geeignet, den Populismusgehalt von Texten vorherzusagen.
Im Folgenden trainieren wir Modelle, die Anhand des bekannten Tweet-Datensatzes die Account-Zugehörigkeit vorhersagen sollen. Der Datensatz ist bereits annotiert, da wir für jeden Tweet auch den Account angeben haben. Zudem handelt es sich um die einfachst mögliche Klassfikation, da nur zwei verschiedene (Account-)Klassen im Datensatz vorkommen: Donald Trump (“realDonaldTrump”) oder Joe Biden (“JoeBiden”). Natürlich ist es aber auch möglich, Modelle zur Klassifikation in mehr als zwei Klassen zu trainieren.
Wir beginnen wie immer damit, unsere bekannten Packages sowie den Datensatz zu laden. Während eine Zeit lang Verfahren zur Textklassifikation in Quanteda von Haus aus enthalten waren, sind diese inzwischen in ein eigenes Package, quanteda.textmodels, ausgelagert. Wir müssen dieses also vorab noch einmalig mit install.packages("quanteda.textmodels") installieren.
library(quanteda)
library(quanteda.textmodels)
library(tidyverse)
tweets <- read_csv("data/trump_biden_tweets_2020.csv")Nochmals ein kurzer Überblick über unseren Datensatz – zentral sind hier die Variablen account und content. Wir werden also versuchen, ein Modell zu trainieren, das auf Basis von content, dem Inhalt der Tweets, den account hinreichend zuverlässig vorhersagen kann.
## # A tibble: 4,153 x 7
## id account link content date retweet_count favorite_count
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 1 JoeBiden https://twitter.com/JoeBid~ "Our final fundraising deadline of 2019 is just hours away and we need y~ 2020/01/01~ 278 975
## 2 2 JoeBiden https://twitter.com/JoeBid~ "Every single human being deserves to be treated with dignity. Everyone.~ 2020/01/01~ 2523 11900
## 3 3 JoeBiden https://twitter.com/JoeBid~ "With just over one month until the Iowa Caucus, we need all hands on de~ 2020/01/02~ 382 1509
## 4 4 JoeBiden https://twitter.com/JoeBid~ "This election is about the soul of our nation — and Donald Trump is poi~ 2020/01/02~ 10545 45928
## 5 5 JoeBiden https://twitter.com/JoeBid~ "Every day that Donald Trump remains in the White House puts the future ~ 2020/01/02~ 2071 9825
## 6 6 JoeBiden https://twitter.com/JoeBid~ "It was a privilege to work with @JulianCastro during the Obama Administ~ 2020/01/02~ 2359 17534
## 7 7 JoeBiden https://twitter.com/JoeBid~ "Like Vicky said, we need a president who will restore integrity to the ~ 2020/01/02~ 1344 6835
## 8 8 JoeBiden https://twitter.com/JoeBid~ "I'm excited to share that we raised $22.7 million this last quarter — o~ 2020/01/02~ 2448 14719
## 9 9 JoeBiden https://twitter.com/JoeBid~ "If you're a teacher or a firefighter, you're probably paying more in ta~ 2020/01/02~ 3043 18565
## 10 10 JoeBiden https://twitter.com/JoeBid~ "Before the holidays, Jill walked across the Gateway International Bridg~ 2020/01/03~ 1165 3231
## # ... with 4,143 more rowsAuch die nächsten Schritte sind uns bereits bekannt – wir erstellen eine Korpus, Tokens und abschließend eine DFM. Wir fügen mit dem Befehl docvars(tweet_corpus, "tweet_id") <- docid(tweet_corpus) außerdem unserem Korpus eine zusätzliche Docvar "tweet_id" hinzu, in der wir die ID des jeweiligen Tweets festhalten. Dies erleichert uns nachher die Auswahl einzelner Dokumente im Korpus.
# Korpus
tweet_corpus <- corpus(tweets, docid_field = "id", text_field = "content")
docvars(tweet_corpus, "tweet_id") <- docid(tweet_corpus)
# Tokens
tweet_tokens <- tokens(tweet_corpus,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove_url = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("english"))
# DFM
tweet_dfm <- dfm(tweet_tokens)Im Übrigen: Wenn wir bisher von Features gesprochen haben, dann haben wir den Begriff weitestgehend synonym mit N-Grammen, bzw. im Falle von Unigrammen auf Wortebene, mit Wörtern verwendet. Das ist bei der automatisierten Inhaltsanalyse auch die häufigste Art von Feature, tatsächlich kann ein Feature aber jede beliebige Eigenschaft eines Dokuments sein; wir könnten unsere aktuell rein aus Wörtern bestehende Feature-Liste also problemlos um weitere Texteigenschaften (z. B. Länge in Zeichen, Anzahl Substantive, Anzahl Großbuchstaben etc.) oder weitere Dokumenteigenschaften (z. B. Anzahl der Retweets) erweitern.
20.1 Training- und Test-Datensätze
Eines der häufigsten Probleme beim Einsatz von überwachtem maschinellen Lernen ist Overfitting: das Modell wird sehr gut an den annotierten Datensatz angepasst, performt aber bei neuen Datensätzen schlecht, da es beispielsweise nicht zwischen allgemeingültigen und datensatzspezifischen Mustern unterscheiden kann. In der Regel sollten wir beim überwachten maschinellen Lernen ein Klassifikationsmodell daher nicht nur trainieren, sondern auch dessen Güte testen.
Hierzu wird der annotierte Datensatz einem Train-Test-Split unterzogen: man teilt den Datensatz in zwei Teildatensätze, einen Trainings-Datensatz sowie einen Test-Datensatz auf. Das Modell wird anschließend nur anhand des Trainings-Datensatzes trainiert. Zum Überprüfen der Klassifikationsgüte werden dann die Klassen des Test-Datensatzes mit dem trainierten Modell vorhergesagt und anschließend mit den tatsächlichen, annotierten Klassen verglichen. So sehen wir, ob unser trainiertes Modell auch außerhalb des Trainings-Datensatzes zufriedenstellend performt.
Das richtige Verhältnis von Trainings- zu Test-Datensatz ist eine Wissenschaft für sich. Als Faustregel gilt jedoch, dass man meistens mit einem 80/20-Split (80% der Fälle in den Trainings-, 20% der Fälle in den Test-Datensatz) ganz ordentlich fährt. Im Folgenden wählen wir daher zunächst 80% der Tweet-IDs zufällig aus unserem Ursprungsdatensatz aus.
- Mit der Tidyverse-Funktion
slice_sample()wählen wir zufällige Zeilen eines Datensatzes aus. Mit dem Argumentproplegen wir fest, welchen Anteil der Zeilen wir auswählen möchten, in unserem Fall also 80% bzw..8.50 - Anschließend extrahieren wir mit der
pull()-Funktion die Variableidals Vektor - Zuvor wird mit der Funktion
set.seed()ein Seed für den Zufallsgenerator festgelegt. Das führt dazu, dass die nachfolgende Zufallsauswahl reproduzierbar wird – wenn Sie zu Hause den Code ausfällen, werden also zufällig exakt die gleichen IDs ausgewählt wir hier im Beispiel. Führen Sie den Code ohneset.seed()aus, erhalten Sie andere zufällig ausgewählte IDs. Die Zahl667als Seed ist dabei völlig willkürlich gewählt; geben Sie eine andere Zahl als Seed ein, lässt sich eine andere Zufallsauswahl reproduzieren.
Das Resultat ist ein Vektor train_ids, der zufällig ausgewählte Tweet-IDs in unserem Datensatz enthält. Er umfasst 3322 Elemente (zur Erinnerung: der Ausgangsdatensatz enthält 4143 Zeilen; 3322 / 4143 = 0.802).
## [1] 2605 2926 1353 505 6272 3347
## [1] 3322Mit der Quanteda-Funktion dfm_subset() können wir unsere DFM tweet_dfm nun anhand dieser IDs in einen Trainings- und einen Testdatensatz aufteilen. Hierzu wählen wir für die Trainings-DFM alle Tweet-IDs aus, die in unserem neu erzeugten Vektor train_ids enthalten sind, und für Test-DFM alle Tweet-IDs, die darin nicht enthalten sind:
train_dfm <- dfm_subset(tweet_dfm, tweet_id %in% train_ids)
test_dfm <- dfm_subset(tweet_dfm, !tweet_id %in% train_ids)Wie wir sehen, enthält die Trainings-DFM train_dfm wie gewünscht 3322 Zeilen:
## Document-feature matrix of: 3,322 documents, 8,534 features (99.8% sparse) and 6 docvars.
## features
## docs final fundraising deadline just hours away need help every donation
## 1 1 1 1 1 1 1 1 2 1 1
## 2 0 0 0 0 0 0 0 0 1 0
## 3 0 0 0 1 0 0 1 0 0 0
## 4 0 0 0 0 0 0 0 0 0 0
## 6 0 0 0 0 0 0 0 0 0 0
## 7 0 0 0 0 0 0 1 0 0 0
## [ reached max_ndoc ... 3,316 more documents, reached max_nfeat ... 8,524 more features ]Die Test-DFM test_dfm enthält die verbleibenden 831 Tweets:
## Document-feature matrix of: 831 documents, 8,534 features (99.8% sparse) and 6 docvars.
## features
## docs final fundraising deadline just hours away need help every donation
## 5 0 0 0 0 0 0 0 0 1 0
## 8 0 0 0 0 0 0 0 0 0 0
## 20 0 0 0 0 0 0 0 0 0 0
## 24 0 0 0 0 0 0 0 0 0 0
## 26 0 0 0 0 0 1 0 0 0 0
## 30 0 0 0 0 0 0 1 0 0 0
## [ reached max_ndoc ... 825 more documents, reached max_nfeat ... 8,524 more features ]Die Anzahl der Features ist bei beiden DFMs weiterhin gleich; das ist wichtig, da wir ein Modell, das mit bestimmten Features trainiert wurde, nur auf Daten anwenden können, die ebenfalls Informationen zu exakt diesen Features enthalten.
20.2 Naive Bayes-Klassifikation
Wir sind nun bereit, unser erstes Klassifikationsmodell zu trainieren. Hierzu nutzen wir einen sogenannten Naïve Bayes classifier. Der Name ergibt sich zum einen aus Satz von Bayes, den sich das Klassifikationsmodell zu Nutze macht, zum anderen von der “naiven” Annahme, dass alle Features voneinander unabhängig sind. Dass dies bei Textdaten in der Regel nicht der Fall ist, haben wir bereits daran gesehen, dass die Auftrittswahrscheinlichkeit von bestimmten Begriffen (z. B. “oval”) durchaus vom Auftreten anderer Begriffe (z. B. “office”) beeinflusst wird; dennoch liefert der naive Bayes-Klassifikator häufig gute Ergebnisse, die mit anderen, deutlich komplexeren Klassifikationsmodellen mithalten können. Zugleich hat naive Bayes-Klassifikation die Vorteile, dass sie nicht sehr rechenaufwändig ist und oft auch bereits mit geringen Datenmengen ganz passable Ergebnisse liefert.
Ich erspare an dieser Stelle detaillierte Formeln, aber grob gesagt funktioniert der Klassifikator wie folgt:
- für jede Klasse wird eine Grundwahrscheinlichkeit (Prior) angenommen; in der Regel nutzt man hierfür die relative Häufigkeit der Klassen im Korpus. In unserem Fall liegt die Grundwahrscheinlichkeit der Klasse
realDonaldTrumpüber der Grundwahrscheinlichkeit der KlasseJoeBiden, da wir mehr Tweets von Trump als von Biden im Datensatz haben. - nun wird für jedes Feature und jede Klasse eine Wahrscheinlichkeit zur Klassenzugehörig berechnet. In unserem Fall wird also für jedes Wort, das in unserem Korpus vorkommt, die Wahrscheinlichkeit berechnet, dass es in Tweets von Trump bzw. Biden vorkommt.51
- schließlich wird für jedes Dokument (hier also jeden Tweet) und für jede Klasse die Zugehörigkeitswahrscheinlichkeit berechnet. Hierzu werden je Klasse die Wortwahscheinlichkeiten miteinander und schließlich mit der Grundwahrscheinlichkeit multipliziert; der Klassifikator entscheidet sich sodann je Dokument für diejenige Klasse, die die höchste Zugehörigkeitswahrscheinlichkeit erhält.
Wir fitten ein naives Bayes-Klassifikations-Modell in Quanteda mit der Funktion textmodel_nb(). Als Input benötigen wir als erstes Argument eine DFM, anhand das Modell trainiert werden soll (also unsere train_dfm), und als zweites Argument die annotierten Klassenzugehörigkeiten, die in unserem Fall in der Docvar account, die sich auch über die $-Notation aufrufen lässt. Mit dem Argument prior geben wir außerdem die Grundwahrscheinlichkeit an; Default-Wert ist hier uniform, also die gleiche Wahrscheinlichkeit für alle Klassen (bei zwei Klassen als jeweils 50%), aber wie oben angegeben, nutzen wir hier die relative Dokumenthäufigkeit mit dem Wert "docfreq".
Das Resultat ist ein textmodel_nb-Objekt, das sämtliche Informationen über unser trainiertes Modell enthält. Wir können uns die einzelnen “Bestandteile” mit str() anzeigen lassen. Besonders relevant ist für uns der Eintrag param, der die Parameterschätzer des Modells – also die Klassenzugehörigkeitswahrscheinlichkeiten für jedes Feature – enthält.
## List of 7
## $ call : language textmodel_nb.dfm(x = train_dfm, y = train_dfm$account, prior = "docfreq")
## $ x :Formal class 'dfm' [package "quanteda"] with 8 slots
## $ y : Factor w/ 2 levels "JoeBiden","realDonaldTrump": 1 1 1 1 1 1 1 1 1 1 ...
## $ distribution: chr "multinomial"
## $ smooth : num 1
## $ priors : Named num [1:2] 0.363 0.637
## ..- attr(*, "names")= chr [1:2] "JoeBiden" "realDonaldTrump"
## $ param : num [1:2, 1:8534] 0.000208 0.000162 0.000139 0.000027 0.000139 ...
## ..- attr(*, "dimnames")=List of 2
## - attr(*, "class")= chr [1:3] "textmodel_nb" "textmodel" "list"20.2.1 Vorhersagen und Klassifikationsgüte
Wie gut funtkioniert unser Modell nun? Wir haben bewusst einen Teil der Tweets als test_dfm zurückgehalten und nicht in das Modelltraining einbezogen. Wir können nun die predict()-Funktion nutzen, um Vorhersagen auf Basis unseres Klassifikationsmodells zu treffen. Hier benötigen wir als erstes Argument das Modell, mit dem wir unsere Vorhersagen treffen wollen, und geben mit dem Argument newdata einen Datensatz an, auf den wir unser Modell nun anwenden möchten.52
Das Resultat ist ein Vektor mit den vorhersagten Klassen, in unserem Fall also Twitter-Accounts, für jeden Fall im Test-Datensatz:
## 5 8 20 24 26 30
## JoeBiden JoeBiden JoeBiden JoeBiden JoeBiden JoeBiden
## Levels: JoeBiden realDonaldTrumpUm diesen auszuzählen, nutzen wir wir die table()-Funktion:
## predicted_account
## JoeBiden realDonaldTrump
## 307 524Unser Modell klassifiziert 307 der 831 Tweets in test_dfm als von Joe Biden stammend, 524 werden Donald Trump zugeschrieben.
Wie verhält sich das zu den tatsächlichen Accounts?
## true_account
## JoeBiden realDonaldTrump
## 294 537Hier gibt es also Unterschiede und somit auch Fehlklassifikationen. Weitaus aussagekräftiger wird die Tabelle, wenn wir wahre Accounts und vorhergesagte Accounts gegeneinander abtragen. Eine solche Darstellung wird auch Confusion Matrix genannt:
## true_account
## predicted_account JoeBiden realDonaldTrump
## JoeBiden 280 27
## realDonaldTrump 14 510Wir sehen: von den Tweets, die von Joe Biden stammen, wurden 280 auch Joe Biden zugeordnet , 14 hingegen wurden als von Donald Trump stammend klassifiziert. Ebenso wurden 510 Tweets von Donald Trump korrekt klassifiziert, wohingegen 27 fälschlicherweise Joe Biden zugeordnet wurden.
Aus den Verhältnissen in der Confusion Matrix lassen sich unterschiedliche Kennwerte zur Beurteilung der Klassifikationsgüte berechnen. Das caret-Package beinhaltet eine Funktion confusionMatrix(), die uns diese Kennwerte zusätzlich berechnet. Hierzu installieren wir zunächst das Package:
Anschließend wird die erweiterte confusionMatrix() angefordert:
## Confusion Matrix and Statistics
##
## true_account
## predicted_account JoeBiden realDonaldTrump
## JoeBiden 280 27
## realDonaldTrump 14 510
##
## Accuracy : 0.9507
## 95% CI : (0.9337, 0.9644)
## No Information Rate : 0.6462
## P-Value [Acc > NIR] : < 2e-16
##
## Kappa : 0.8932
##
## Mcnemar's Test P-Value : 0.06092
##
## Sensitivity : 0.9524
## Specificity : 0.9497
## Pos Pred Value : 0.9121
## Neg Pred Value : 0.9733
## Prevalence : 0.3538
## Detection Rate : 0.3369
## Detection Prevalence : 0.3694
## Balanced Accuracy : 0.9511
##
## 'Positive' Class : JoeBiden
## Die Maße wurden vor allem im Kontext diagnostischer Klassifikation, z. B. in der Medizin (z. B. krank/nicht krank), entwickelt, daher arbeitet die Terminologie mit den Begriffen positiv (Merkmal vorhanden) vs. negativ (Merkmal nicht vorhanden). Im Falle binärer Klassifikation wird also eine Klasse als positiv bezeichnet, die andere als negativ. In diesem Falle gibt uns die Tabelle an, dass “JoeBiden” als positive Klasse dient.
Von besonderer Bedeutung sind für uns folgende Werte:
- Accuracy: wie hoch ist der Anteil korrekt klassifizierter Fälle insgesamt. In unserem Fall werden rund 95% aller Tweets korrekt klassifiziert (
(280 + 510) / 831 = 0.9507). - Sensitivity (auch Recall): wie hoch ist der Anteil als positiv klassifizierter Fälle an allen tatsächlich positiven Fällen. In unserem Fall werden ebenfalls rund 95% aller Tweets, die tatsächlich von Biden stammen, auch als “JoeBiden” klassifiziert (
280 / (280 + 14) = 0.9524). - Specificity: wie hoch ist der Anteil als negativ klassifizierter Fälle an allen tatsächlich negativen Fällen. In unserem Fall werden erneut rund 95% aller Tweets, die tatsächlich von Trump stammen, auch als “realDonaldTrump” klassifiziert (
280 / (280 + 14) = 0.9524).
- Positive Predictive Value (PPV; auch Precision): wie hoch ist der Anteil positiver Fälle an allen als positiv klassifizierten Fällen. In unserem Fall stammen rund 91% aller Tweets, die als von Biden stammend klassifiziert wurden, auch tatsächlich von Biden (
280 / (280 + 27) = 0.9121). - Negative Predictive Value (NPV): wie hoch ist der Anteil negativer Fälle an allen als negativ klassifizierten Fällen. In unserem Fall stammen rund 97% aller Tweets, die als von Trump stammend klassifiziert wurden, auch tatsächlich von Trump (
510 / (510 + 14) = 0.9733).
Insgesamt klassifiziert unser Classifier also rund 19 von 20 Tweets als korrekt; zugleich gibt es aber durchaus Klassenunterschiede, da fast alle Tweets, die als von Trump stammend klassifiziert werden, auch tatsächlich von Trump sind, wohingegen in etwa jeder zehnte Tweet, der als von Biden stammend klassifiziert wird, ebenfalls von Trump stammt.
20.2.2 Parameter extrahieren
Welche Features sind nun besonders wichtig für die Klassifikation? Hierzu können wir auf die berechneten Parameter des Modells zurückgreifen, die für jedes Feature die Zugehörigkeitswahrscheinlichkeiten pro Klasse (also in unserem Fall für beide Twitter-Accounts) umfassen. Diese sind als Matrix "param" im Modellobjekt hinterlegt und können leicht über die $-Notation abgerufen werden.
## final fundraising deadline just hours
## JoeBiden 0.0002081382 0.0001387588 0.0001387588 0.003538349 2.081382e-04
## realDonaldTrump 0.0001622016 0.0000270336 0.0000270336 0.004028007 5.406721e-05Wir können also die Features mit dem höchsten Wert pro Klasse heraussuchen, um so ein Gefühl dafür zu bekommen, welche Features besonders wichtig für die jeweiligen Klassen sind. Hier bietet sich eine grafische Darstellung an:
tweets_nbc$param %>%
t() %>% # Transponiert die Matrix, vertauscht also Zeilen und Spalten
as_tibble(rownames = "Word") %>%
pivot_longer(c("JoeBiden", "realDonaldTrump"), names_to = "Account", values_to = "Estimate") %>%
group_by(Account) %>%
top_n(20, Estimate) %>%
mutate(Word = tidytext::reorder_within(Word, Estimate, Account)) %>%
ggplot(aes(x = Word, y = Estimate, fill = Account)) +
facet_wrap(~ Account, scales = "free_y") +
geom_col(show.legend = FALSE) +
scale_fill_manual(values = c("blue", "red")) +
tidytext::scale_x_reordered() +
coord_flip()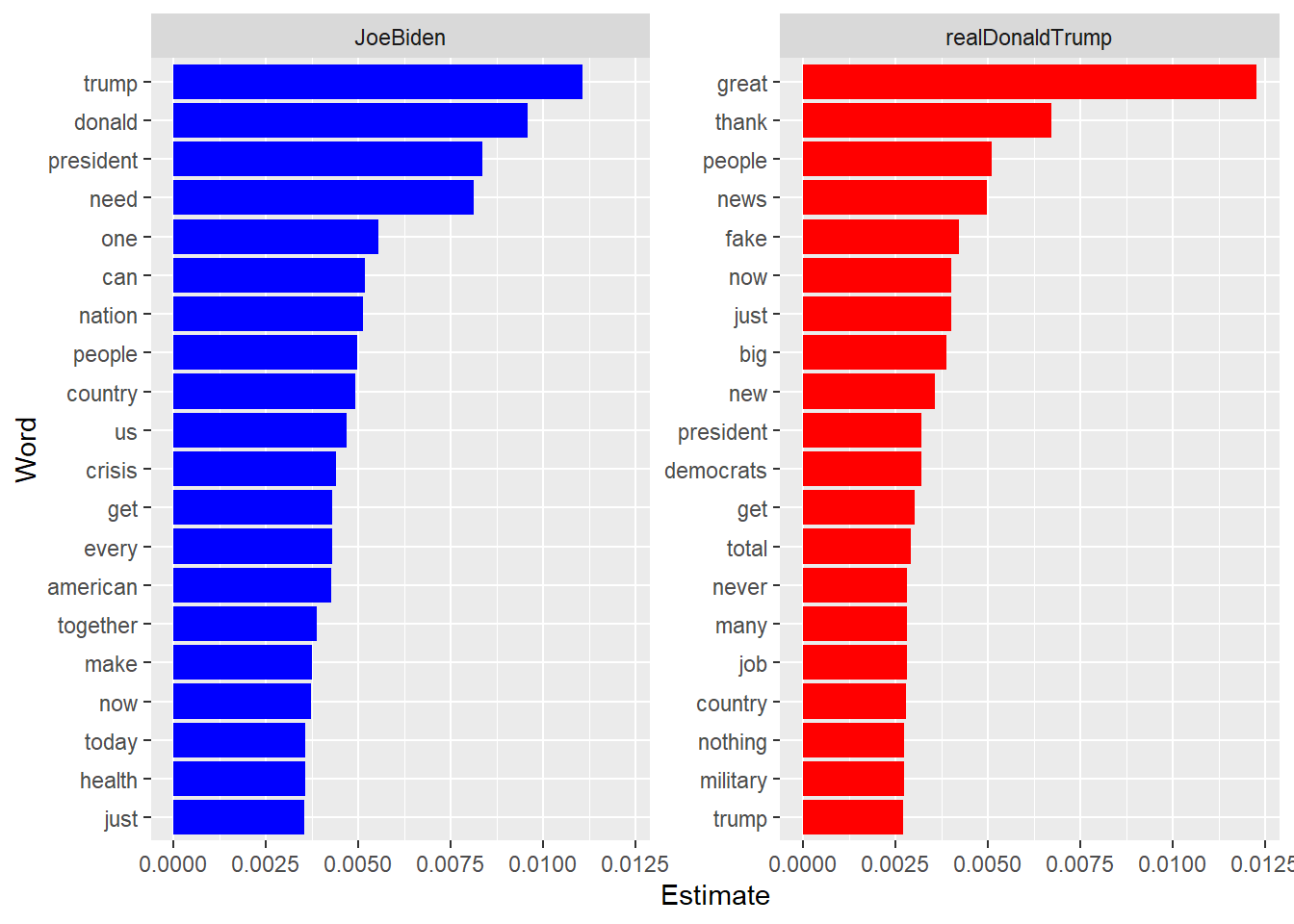
Die Ergebnisse sind vergleichbar mit den wichtigsten Begriffen, die wir über andere Verfahren, beispielsweise Keyness-Analysen erhalten haben (siehe Kapitel 18.6). Zu beachten ist, dass bei naiver Bayes-Klassifikation Features für beide Klassen eine hohe Bedeutung haben können, da die Parameter schlichtweg anhand der relativen Häufigkeit berechnet werden, in diesem Fall z. B. “trump”. Andere Klassifikationsverfahren suchen hier stärker nach Features, die besonders distinkt für die jeweiligen Klassen sind.
20.2.3 Klassifikation unannotierter Texte
Da unser Modell eine hohe Klassifikationsgüte aufweist, können wir es nun auch guten Gewissens bei unannotierten Daten einsetzen. Natürlich wissen im Falle von Tweets stets, von wem dieser Tweet stammt, weshalb die Vorhersage unannotierter Daten in diesem Beispiel eher eine Spielerei ist. In Anwendungsfällen, in denen wir einen Teil-Datensatz manuell annotiert haben, um dann den Klassifikator auf den gesamten Datensatz anzuwenden, wäre dies aber das eigentliche Ziel. Wir gehen daher die dafür notwendigen Schritte anhand des Tweet-Beispiels durch.
Hierzu benötigen wir zunächst natürlich unannotierte Tweets, also ohne Account-Zuordnung. Bei den folgenden beiden aktuellen Tweets dürfte es uns leicht fallen, zu erahnen, ob sie von Biden oder Trump stammen. Ob unser Klassifikator das auch schafft?
new_tweets <- c("Big Senate Race in Alabama on Tuesday. Vote for @TTuberville, he is a winner who will never let you down. Jeff Sessions is a disaster who has let us all down. We don’t want him back in Washington!",
"I want every single American to know: If you're sick, struggling, or worried about how you're going to get throug the day, I will not abandon you. We're all in this together. And together, we'll emerge stronger than before.")Unser Klassifikationsmodell benötigt als Input eine DFM; entsprechend konvertieren wir unsere neuen Text-Dokumente ebenfalls in eine DFM:
## Document-feature matrix of: 2 documents, 66 features (44.7% sparse).
## features
## docs big senate race in alabama on tuesday . vote for
## text1 1 1 1 2 1 1 1 3 1 1
## text2 0 0 0 1 0 0 0 3 0 0
## [ reached max_nfeat ... 56 more features ]Allerdings enthält diese DFM natürlich andere (und deutlich weniger) Features als die DFM, anhand das Modell trainiert wurde. Nutzen wir nun die predict()-Funktion, erzeugt dies eine Fehlermeldung, da das Modell alle ihm bekannten Features erwartet:
## Error in force_conformance(newdata, colnames(object$param), force): newdata's feature set is not conformant to model terms.Um dieses Problem zu beheben, nutzen wir die Quanteda-Funktion dfm_match(), mit der wir eine bestehende DFM an eine vorgegebene Struktur anpassen können. Mit dem Argument features geben wir an, welche Features unsere neue DFM beinhalten soll – nämlich alle, die in der ursprünglichen Trainings-DFM enthalten sind:
## Document-feature matrix of: 2 documents, 8,534 features (99.8% sparse).
## features
## docs final fundraising deadline just hours away need help every donation
## text1 0 0 0 0 0 0 0 0 0 0
## text2 0 0 0 0 0 0 0 0 1 0
## [ reached max_nfeat ... 8,524 more features ]Unsere neue DFM enthält nun alle Features der ursprünglichen DFM – Wörter, die in unseren beiden neuen Tweets nicht vorkommen, haben eine 0 erhalten, Wörter in unseren neuen Tweets, die nicht in der alten DFM enthalten waren, wurden gelöscht.
Sehen wir uns nun an, zu welchem Ergebnis unser Klassifikator kommt:
## text1 text2
## realDonaldTrump JoeBiden
## Levels: JoeBiden realDonaldTrumpTatsächlich wurden beide Tweets korrekt klassifiziert. Unser Modell hat also offensichtlich “erlernt”, auch unannotierte Tweets von Trump und Biden zu unterscheiden.
Falls Sie das erneut mit anderen Tweets der beiden Kandidaten ausprobieren möchten – hier ist das Verfahren in eine Funktion verpackt, die Sie mit trump_or_biden() aufrufen und anschließend den Text eines beliebigen Tweets der beiden Kandidaten einfügen können, um den Urheber vorherzusagen:
trump_or_biden <- function(model = tweets_nbc) {
text <- rstudioapi::showPrompt("Tweet-Text", "Text des Tweets:")
new_dfm <- dfm(text)
new_dfm_matched <- dfm_match(new_dfm, features = featnames(model))
prediction <- predict(model, newdata = new_dfm_matched) %>%
as.character()
print(paste("Dieser Tweet stammt wahrscheinlich von", prediction))
}20.3 Ausblick
Dies war ein erster Einblick in Textklassifikation durch überwachtes maschinelles Lernen. Unser Klassifikator funktioniert hier sehr gut, es handelt sich aber auch um ein eher einfaches Klassifikationsproblem, da wir nur binär zwischen zwei Klassen unterscheiden und diese auch sehr verschieden sind, da beide Kandidaten einen jeweils distinkten Tweet-Stil pflegen. Im Forschungsalltag ist in der Regel deutlich mehr Aufwand erforderlich, um zufriedenstellende Ergebnisse zu erhalten.
Textklassifikation ist – neben den Ausgangsdaten – inbesondere von zwei Schritten abhängig:
- Preprocessing des Textmaterials: Durch eine sorgsame Aufbereitung und Bereinigung des Textmaterials, also Schritte wie Stemming und Lemmatisierung, die Verwendung von Bi-Grammen, Tri-Grammen etc. sowie die Entfernung von Stoppwörtern (siehe Kapitel 17.2) lässt sich die Klassifikationsgüte oft deutlich verbessern. Zusätzlich können Transformationen der DFM, z. B. durch tf-idf, helfen, die Performance von Klassifikationsmodellen zu steigern. Auch unbalancierte Klassen stellen Klassifikatoren oft vor Probleme, die z. B. durch Over- und Undersampling angegangen werden können.
- Wahl des Klassifikationsmodells: Wir haben mit einem denkbar simplen Klassifikationsmodell, dem naiven Bayes-Klassifikator, gearbeitet. Oftmals müssen komplexere Modelle und Algorithmen wie (logistische) Regressionen, Support Vector Machines oder Random Forests, kombiniert mit Verfahren der Regularization, Kreuzvalidierung, Techniken der automatisierten Feature-Auswahl und/oder der Kombination von verschiedenen Klassifikationsalgorithmen durch Boosting, ausprobiert werden. Je nach zur Verfügung stehender Rechenleistung und Umfang des Datenmaterials kann die Berechnung eines einzelnen solchen Modells einige Stunden bis mehrere Tage beanspruchen.
Sollte sich aus den Forschungsprojekten die Notwendigkeit von Textklassifikation ergeben, werden wir uns in der zweiten Hälfte des Masterprojekts eingehender mit solch komplexeren Verfahren beschäftigen. Zudem folgen noch Verfahren des unüberwachten maschinellen Lernens, insbesondere Topic Modeling, sowie die manuelle Validierung von automatisierten Inhaltsanalysen.
Nun aber erst einmal: schöne Semesterferien :)

Illustration von @allison_horst: https://twitter.com/allison_horst
Alternativ lässt sich mit dem Argument
neine genaue Anzahl an auszuwählenden Zeilen angeben↩︎Das könnten wir, viel Zeit vorausgesetzt, problemlos von Hand machen: wir zählen, wie häufig das jeweilige Wort in den Dokumenten einer Klasse vorkommt, und teilen dies durch die Anzahl aller Wörter in der jeweiligen Klasse. Anschließend wird noch eine Korrektur vorgenommen, um 0-Wahrscheinlichkeiten (wenn ein Wort in einer Klasse gar nicht vorkommt) zu vermeiden.↩︎
Die
predict()-Funktion ist eine Funktion aus der Basisversion von R, die auf unterschiedlichste Modellobjekte angewendet werden kann.↩︎