11 Daten visualisieren
Ein wichtiger Schritt bei der Datenexploration – und später auch bei der Veröffentlichung und Kommunikation – ist die Visualisierung von Daten, da wir so Auffälligkeiten und Zusammenhänge finden und verdeutlichen können, die uns durch reine deskriptive Auswertungen verborgen bleiben.
Die Basisversion von R bietet bereits einige Funktionen zur Datenvisualisierung, darunter die Funktion plot(), die je nach übergebenem Objekt (bzw. übergebenen Objekten) eine zugehörige Visualiserung erzeugt, beispielsweise Scatterplots für numerische Objekte oder diagnostische Plots für Regressionsmodelle.
Im Tidyverse übernimmt das Package ggplot2 sämtliche Schritte der Datenvisualisierung und stellt hierfür eine eigene Syntax – ein “grammar of graphics” – bereit, die sehr viele Möglichkeiten und Flexibilität bei der Datenvisualisierung eröffnet, aber auch entsprechend eine eigene Lernkurve aufweist. Daher ist es sinnvoll, sich zunächst mit einigen Grundlagen der Datenvisualisierung vertraut zu machen.
11.1 Grundlagen der Datenvisualisierung
Auch wenn uns in den Medien häufig Datenvisualisierungen begegnen und wir im Studium auch schon selbst Datenvisualisierungen erstellt haben, lohnt es sich, die Entscheidungen, die hinter einer solchen Visualisierung stehen, zu verdeutlichen. Wir können solche Entscheidungen auf drei wesentliche Elemente einschränken:
- Encodings (bzw. Aesthetics): Welche Daten bzw. welche Variablen sollen in welche visuellen Elemente (z. B. X-Achse, Y-Achse, Farben) übertragen werden?
- Geometrics: Wie sollen diese visuellen Elemente in dem (zumeist) zweidimensionalen Raum, den uns eine grafische Darstellung zur Verfügung stellt, dargestellt werden (z. B. als Punkte, Linien, Balken)?
- Scales: Auf welchen Skalen sollen die betreffenden Skalen abgebildet werden?
Nehmen wir als aktuelles Beispiel Ergebnisse aus dem ARD Deutschlandtrend:
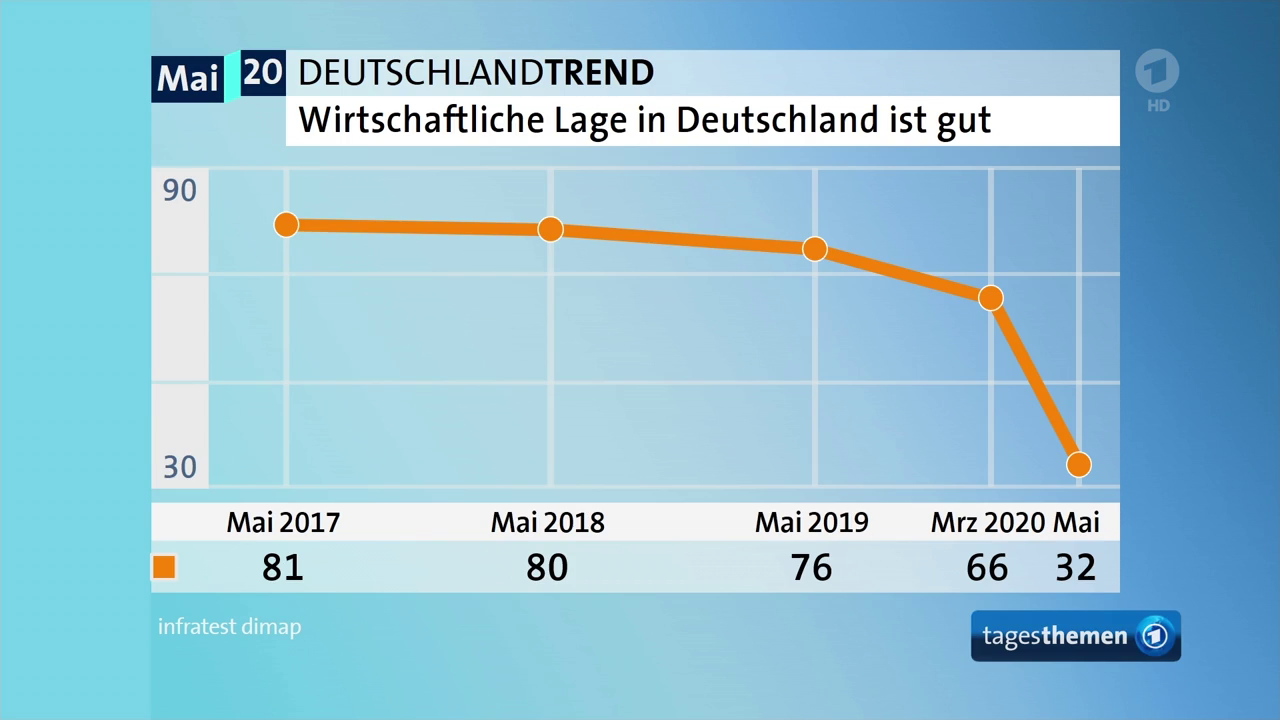
Quelle: Screenshot Das Erste tagesthemen, 22:30 Uhr, 07.05.2020
Wir können diese Grafik intuitiv vermutlich schnell erfassen und “lesen”, ohne uns groß über diese Entscheidungen Gedanken zu machen. Versuchen wir dennoch, diese Visualisierung und die dahinterstehenden Daten zu entschlüsseln:
- Die Grafik basiert auf zwei Variablen: eine Zeitvariable (in Monaten) sowie eine numerische Variable, in der die prozentuale Zustimmung zur Aussage “Die wirtschaftliche Lage in Deutschland ist gut” festgehalten ist. Diese beiden Variablen sind in verschiedenen visuellen Elementen kodiert (→ Encodings): die Zeit ist auf der X-Achse abgetragen, die Zustimmung auf der Y-Achse.
- Die in diesen visuellen Elementen kodierten Werte werden nun durch geometrische Formen (→ Geometrics) dargestellt: die einzelnen Wert-Kombinationen aus beiden Variablen (z. B. Mai 2017 / 81 Prozent) sind als Punkte im Koordinatensystem abgetragen und werden zusätzlich durch Linien verbunden.
- Die Darstellung wird maßgeblich durch Entscheidungen zur Skalierung (→ Scales) beeinflusst: Die Zeitvariable (X-Achse) beginnt im Mai 2017 und endet im Mai 2020. Die Prozentvariable (Y-Achse) zeigt nicht den gesamten möglichen Wertebereich, sondern umfasst lediglich den Bereich von 30 bis 90 Prozent.
Alle anderen Grafikbestandteile – Farben, Wertebeschriftungen etc. – lassen in diesem Fall keine zusätzlichen Aussagen über die zugrundeliegenden Daten aus bzw. kommunizieren keine weiteren Daten, sondern dienen dem Erscheinungsbild.
Ziehen wir noch eine zweite Visualisierung aus derselben tagesthemen-Ausgabe heran, vermutlich eine der bekanntesten Visualisierungen politischer Kommunikationsdaten in Deutschland: die Sonntagsfrage (“Welche Partei würden Sie wählen, wenn am nächsten Sonntag Bundestagswahl wäre?”).
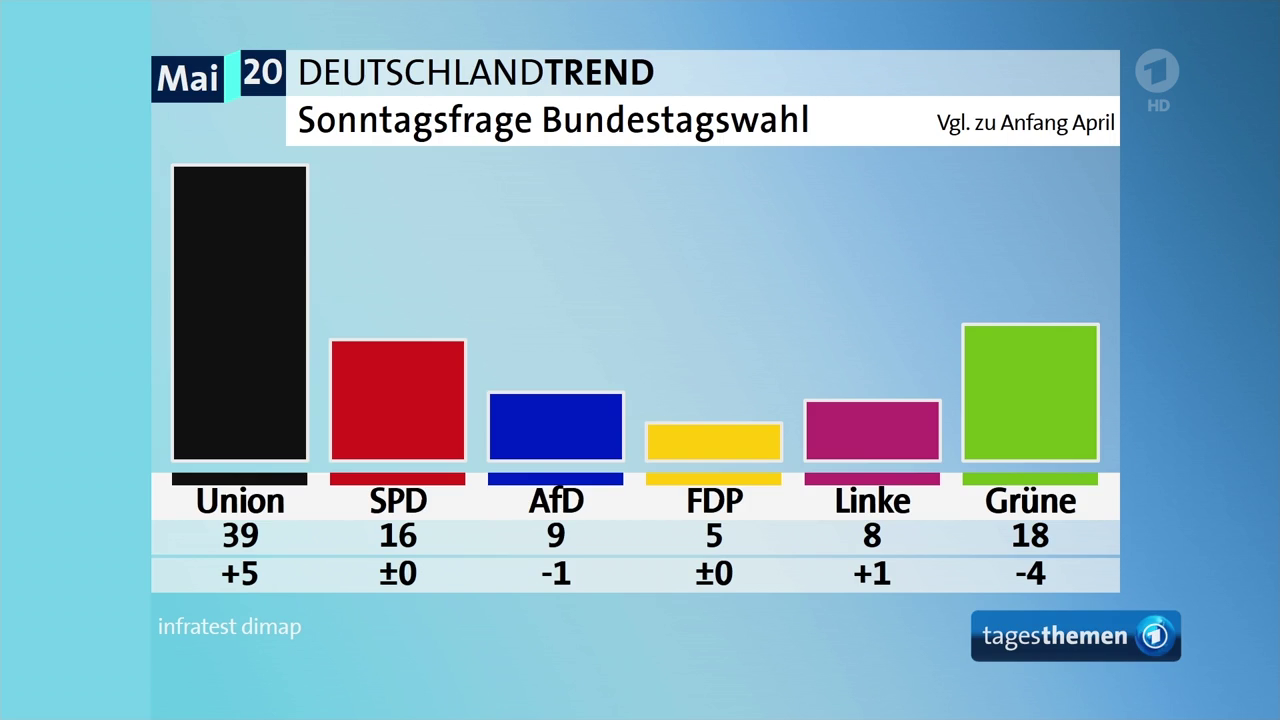
Quelle: Screenshot Das Erste tagesthemen, 22:30 Uhr, 07.05.2020
- in dieser Grafik sind erneut zwei Variablen kodiert: die kategoriale Variable Partei und die numerische Variable Wahlabsicht.24 Partei ist dabei gleich doppelt visuell kodiert: zum einen auf der X-Achse, zum anderen auch farblich – eine solche doppelte Kodierung erfolgt aus Gründen der Ästhetik und Lesbarkeit, fügt der Visualisierung aber keine weiteren Informationen hinzu25. Wichtig ist, dass wir eine Variable zwar mehrfach kodieren, niemals aber dieselbe visuelle Kodierung für mehrere Variablen verwenden können. Die aktuelle Wahlabsicht ist auf der Y-Achse abgetragen.
- als geometrische Form der Datenrepräsentation wurden Balken (bzw. Säulen) gewählt, deren Form und Aussehen entsprechend der visuellen Kodierungen durch Wahlabsicht (Höhe der Balken) und Partei (Farbe der Balken, Position auf der X-Achse) bestimmt wird.
- bei der Skalierung der X-Achse wurde eine Anordnung der kategorialen Ausprägungen – d.h., der Parteien – nach dem Ergebnis der Bundestagswahl 2017 (und nicht etwa alphabetisch, oder absteigend nach aktueller Wahlabsicht etc.) gewählt. Die Y-Achse reicht von 0 bis zum Maximalwert der Daten (in diesem Fall also 39 Prozent); und auch die Farbskalierung folgt einer bewussten Entscheidung – nämlich, dass den kategorialen Ausprägungen der Partei-Variablen die zugehörige Parteifarbe zugeordnet wurde.
Diese drei Schritte – Encoding, Geometrics, Scales – stellen also die wesentliche Entscheidungen der Datenvisualisierung dar. Schauen wir uns nun an, wir diese Schritte in R umsetzen können.
11.2 Datenvisualisierung mit ggplot2
Das Package ggplot2 – das zu den Kernpackages des Tidyverse gehört und entsprechend mit library(tidyverse) direkt mitgeladen wird – orientiert sich an dieser schrittweisen Erstellung von Datenvisualisierungen. Vorab aber der Hinweis, dass es sich bei ggplot2 um ein sehr umfangreiches und mächtiges Package handelt, das zudem mit einer eigenen Logik aufwartet und das man daher kaum an einem Nachmittag verinnerlichen wird. Es geht also zunächst darum, einige Grundprinzipien zu verstehen. Nicht zuletzt findet man online zahlreiche Vorlagen bzw. Code-Beispiele, sodass man in der Regel nach etwas herumprobieren zur gewünschten Darstellung kommt.

Illustration von @allison_horst: https://twitter.com/allison_horst
Wir nutzen erneut den Facebook-Europawahl-Datensatz, den wir wie gewohnt laden. Aus Gründen der Übersichtlichkeit filtern wir zudem erneut nur im Bundestag vertretenen Parteien an::
library(tidyverse)
bt_parteien <- c("alternativefuerde", "B90DieGruenen", "CDU", "CSU", "FDP", "linkspartei", "SPD")
facebook_europawahl <- read_csv("data/facebook_europawahl.csv") %>%
filter(party %in% bt_parteien)Die Hauptfunktion im ggplot2-Package lautet ggplot() und benötigt wie alle anderen Tidyverse-Funktionen auch zunächst den Datensatz, auf dessen Basis wir plotten möchten. Entsprechend können wir auch wieder Pipes verwenden:

ggplot() initialisiert die Visualisierung mit einer leeren Diagrammfläche; Daten sind darauf natürlich noch nicht abgetragen, da wir noch keine Encodings, Geometrics und Scales angegeben haben.
11.2.1 Encodings (aesthetics) definieren
Encodings heißen in ggplot2 Aesthetics und werden innerhalb des Funktionsaufrufs von ggplot() als zweites Funktionsargument über die Funktion aes() angegeben. Optionen für Aesthetics sind unter anderem:
x: Werte auf X-Achsey: Werte auf Y-Achsecolor: Linienfarben (für Punkte, Linien, Konturen von Flächen)fill: Füllfarben (für Flächen, z. B. Balken)shape: Punkform (nur bei Verwendung von Punktdiagrammen)linetype: Linienart (z. B. durchgezogen, gestrichelt etc.; entsprechend nur bei Liniendiagrammen)alpha: Transparenz
Um beispielsweise die Partei (Variable party im Datensatz) auf der X-Achse zu kodieren, geben wir an:
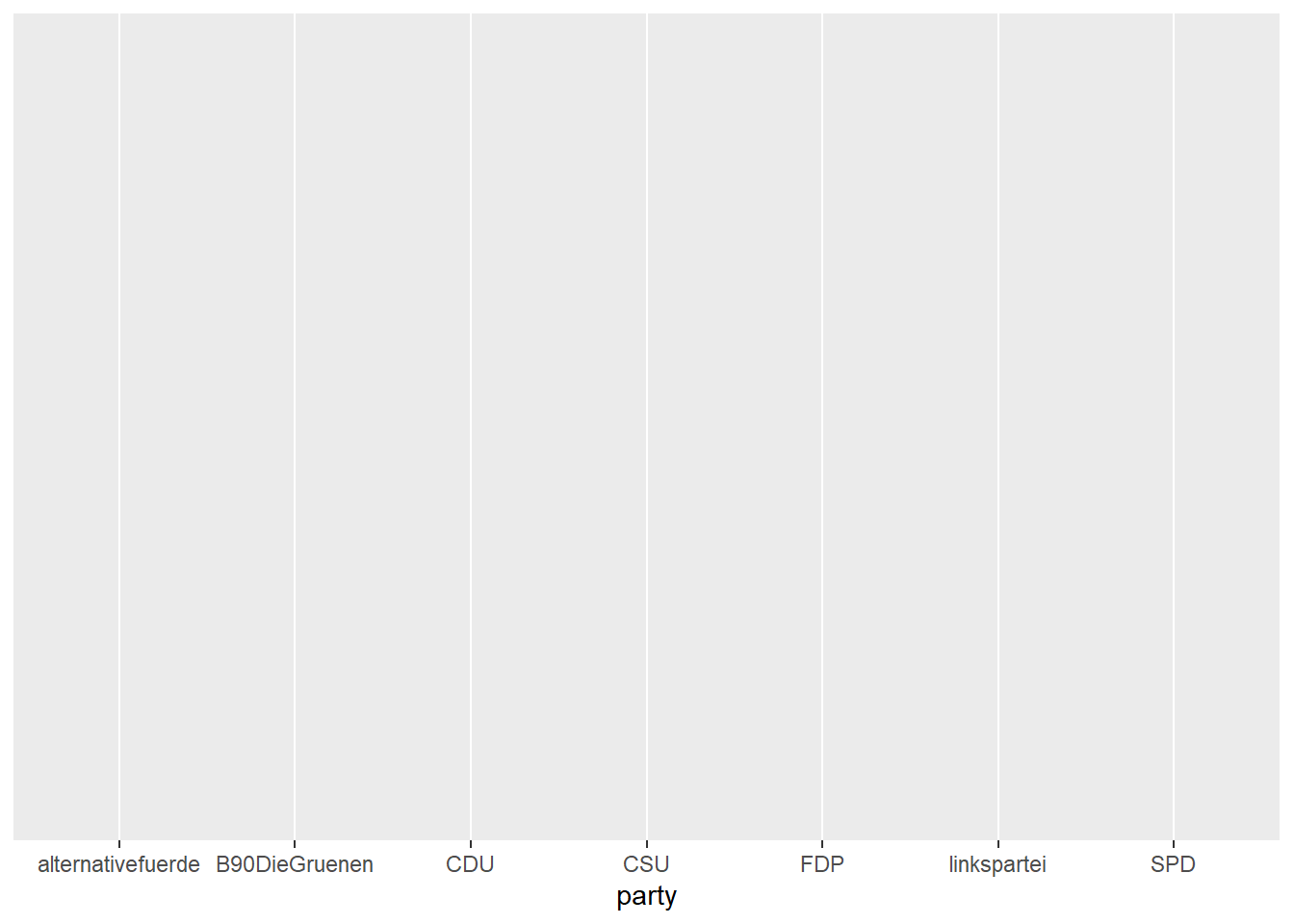
Wir sehen, dass die X-Achse nun schon für die Parteien vorbereitet wurde; mehr haben wir noch nicht definiert, entsprechend ist auch noch nicht mehr zu sehen.
Möchten wir stattdessen die Anzahl der Kommentare (Variable comments_count) im Zeitverlauf (Variable timestamp) und farblich getrennt nach Parteien (Variable party) zeigen, definieren wir die Aesthetics wie folgt:
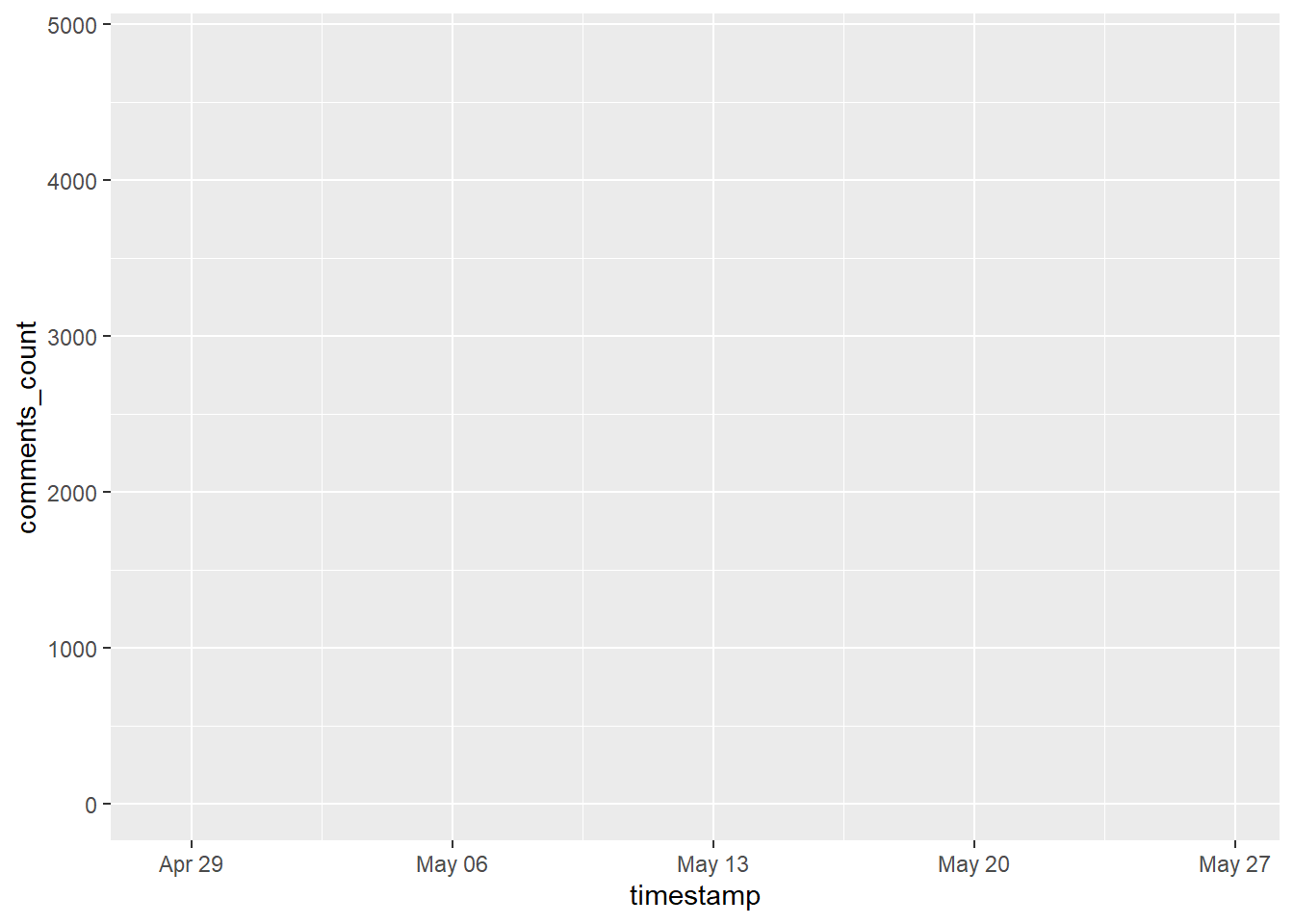
Auch hier sehen wir, dass im Koordinatensystem bereits auf der X- und Y-Achse die entsprechenden Variablen eingetragen sind. Sichtbar ist aber weiterhin noch nicht viel mehr, da wir noch nicht definiert haben, in welchen Geometrics unsere Daten repräsentiert werden sollen:
11.2.2 Geometrics hinzufügen
Dem Ausgangsaufruf von ggplot() können wir nun beliebige Diagramm-Elemente der Reihe nach hinzufügen – für Geometrics stehen hierbei verschiedene Funktionen zur Verfügung, die allesamt mit geom_ beginnen. Dazu gehören:
geom_point(): Punktegeom_line(): Liniengeom_bar(): Balken für Häufigkeiten derx-Variable (y-Kodierung muss nicht angegeben werden)geom_col(): Balken, deren Höhe durch einey-Variable spezifiziert wirdgeom_hist(): Histogrammegeom_boxplot(): Boxplots
…und viele weitere. Eine Besonderheit ist, dass diese und alle weiteren Elemente dem Ausgangsplot nicht per Pipe %>%, sondern per + hinzugefügt werden.
Um etwa ein einfaches Säulendiagramm für die Anzahl der Posts pro Partei zu erstellen, definieren wir party als x-Aesthetic und fügen ein geom_bar() hinzu:
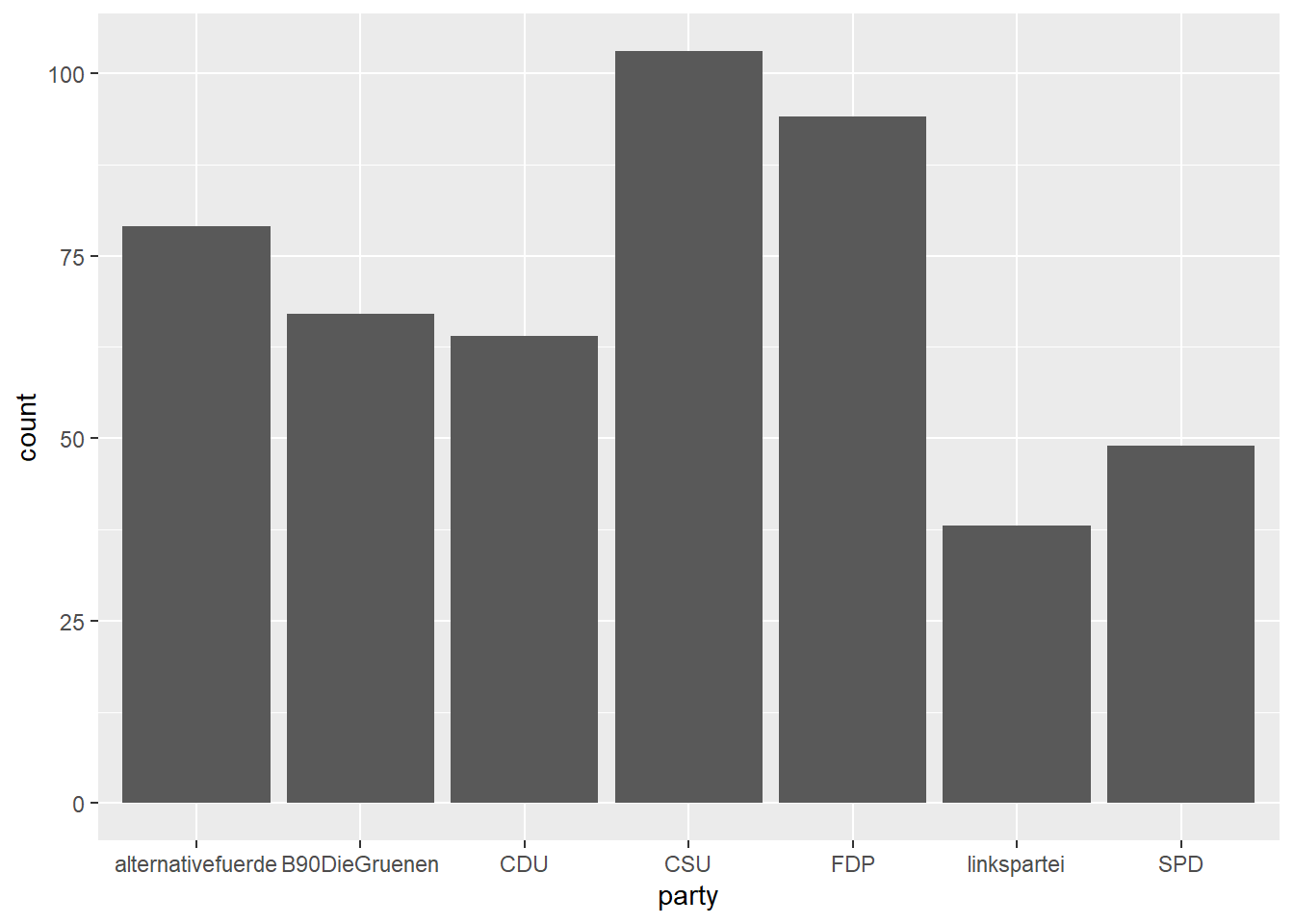
Wollen wir die Balken zusätzlich je nach Partei unterschiedlich einfärben, müssen wir wie im obigen tagesthemen-Beispiel party doppelt kodieren – sowohl als x, als auch als fill (die Füllfarbe der Balken):
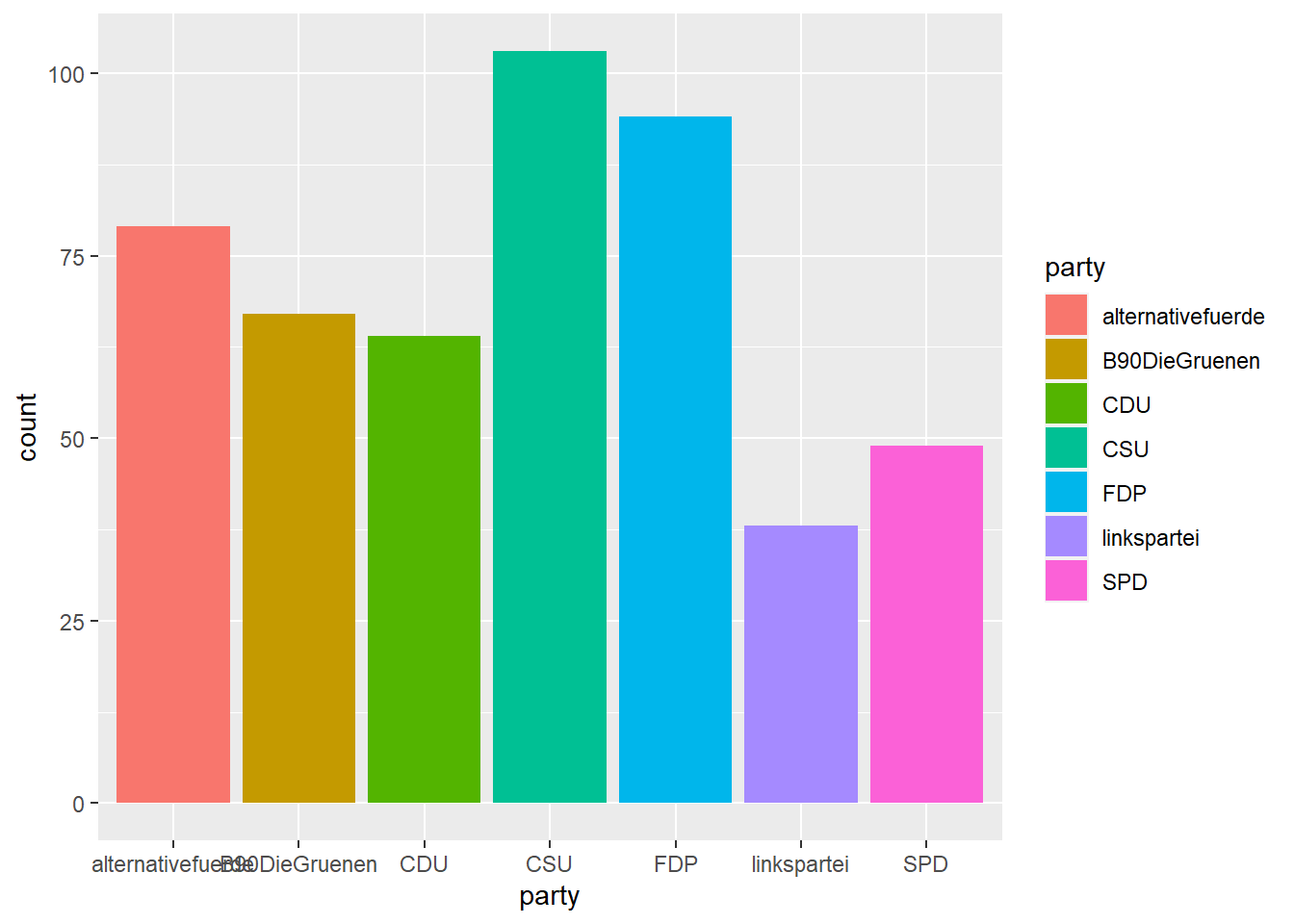
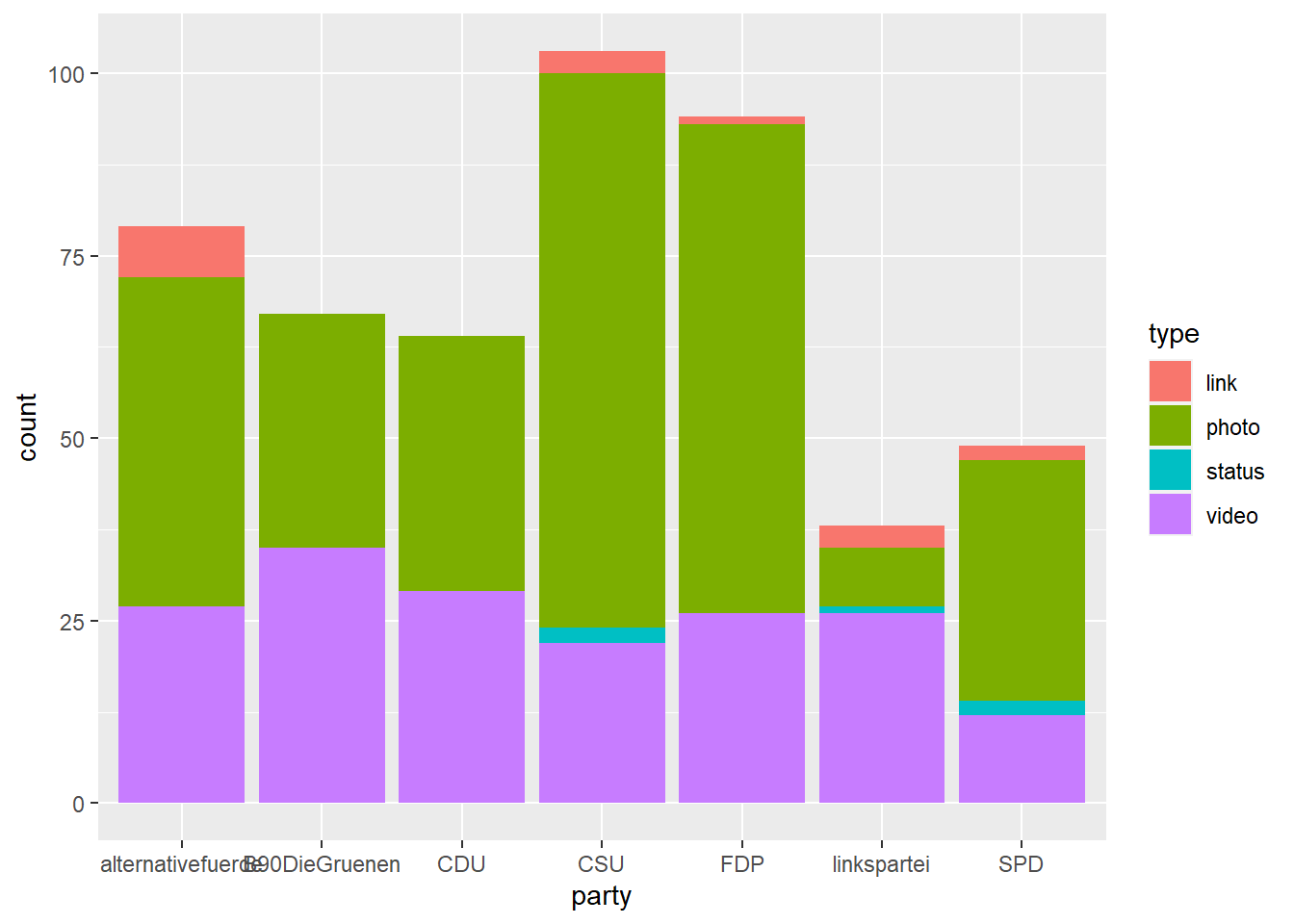
Ändern wir hingegen die Kodierung von fill in type (Art des Facebook-Posts), so haben wir diese Information auch im Balkendiagramm untergebracht:
Im zweiten Beispiel möchten wir die Anzahl der Kommentare im Zeitverlauf und farblich nach Partei getrennt darstellen. Dazu bieten sich z. B. Punkte an:
facebook_europawahl %>%
ggplot(aes(x = timestamp, y = comments_count, color = party)) +
geom_point()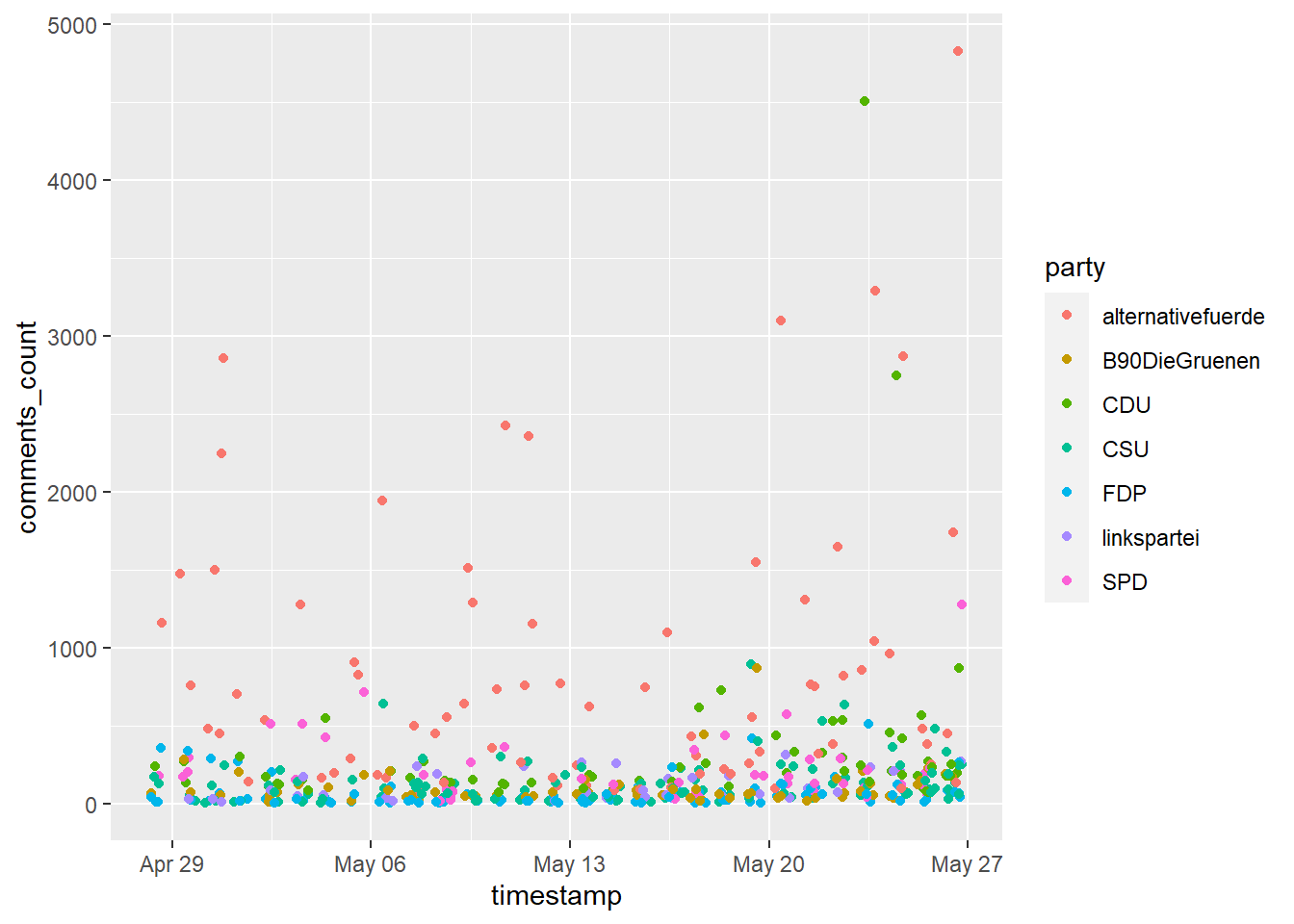
Oder wir stellen je Partei die Verteilung der Kommentaranzahl als Boxplot dar:
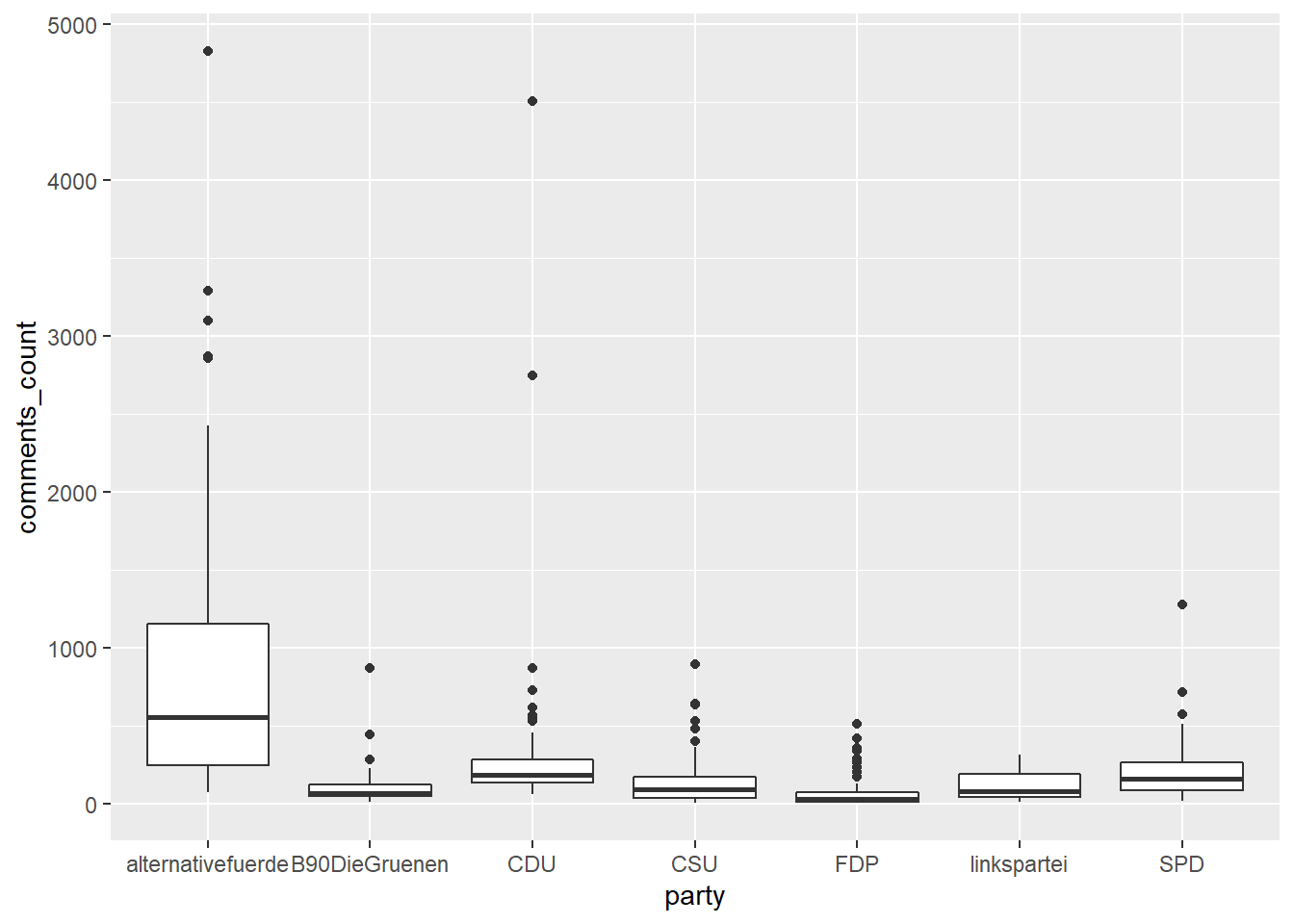
11.2.3 Skalierung anpassen
Jede Aesthetic, die wir in ggplot() definieren, resultiert in einer Skalierung der entsprechenden Variablen, die wir mittels scale_-Funktionen anpassen können. Alle scale_-Funktionen sind nach dem Schema scale_[aesthetic]_[typ] benannt. Mit scale_y_continuous() etwa passen wir kontinuierliche bzw. stetige, metrische Daten auf der Y-Achse an, während wir mittels scale_fill_manual() manuelle Werte für die Füllfarben vergeben können.
Schauen wir uns nochmals unser Säulendiagramm zur Anzahl der Posts an:
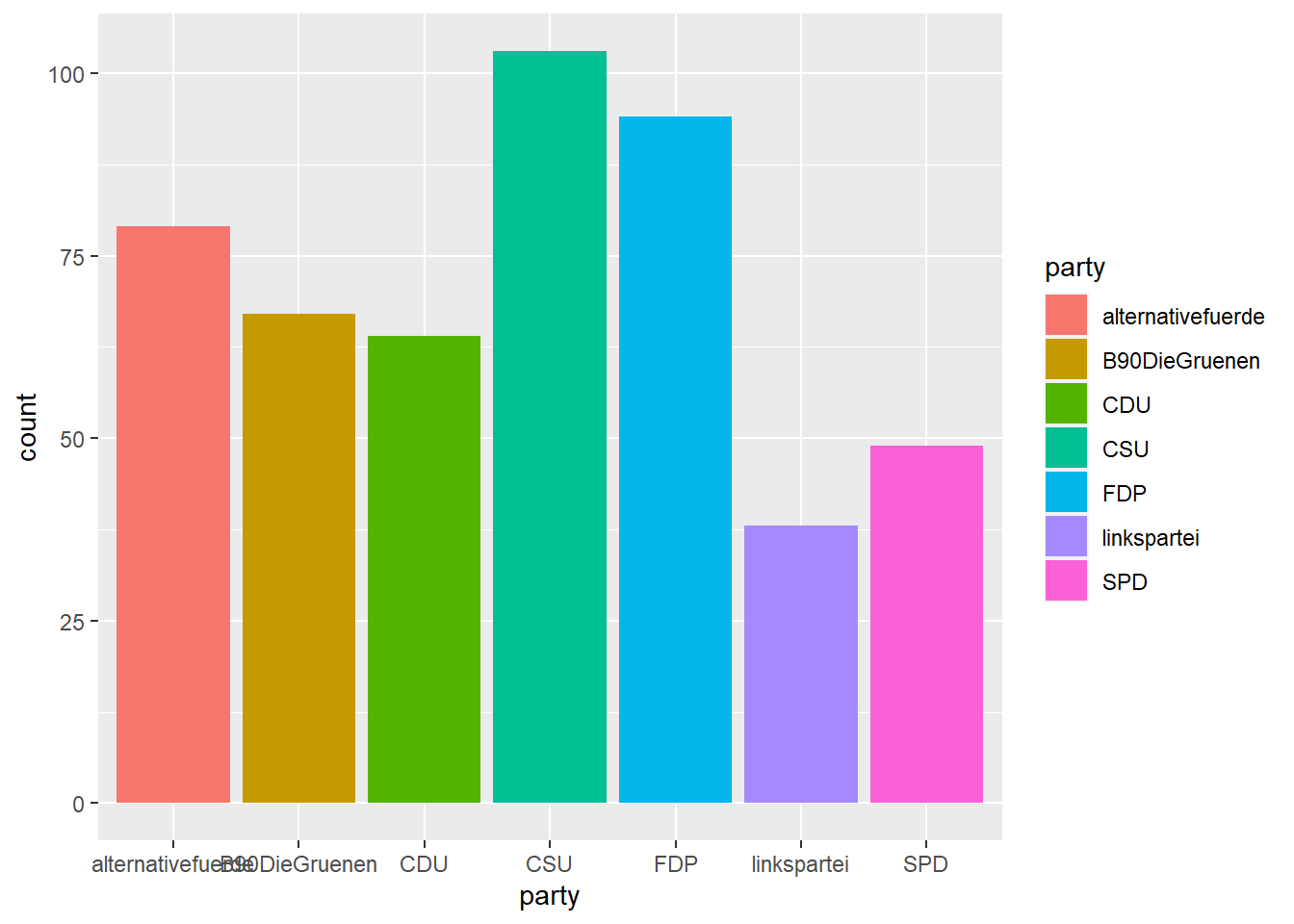
Das sieht allgemein schon ganz ordentlich aus, wir möchten aber vielleicht noch ein paar weitere Anpassungen vornehmen:
- Die Y-Achse möchten wir in 10er-Schritten von 0 bis 110 einstellen.
- Die Anordnung der Parteien auf der X-Achse möchten wir – ähnlich wie im tagesthemen-Beispiel oben – entsprechend des Ergebnisses der Bundestagswahl vornehmen (stellen die beiden Unionsparteien aber nebeneinander).
- Und schließlich sollen die Parteien passende Farben erhalten.
Zudem sollten die Beschriftungen der einzelnen Skalen etwas aussagekräftiger werden als nur party und count.
Wir beginnen mit der Y-Achse; es handelt sich um die Aesthetic y und eine numerische Skala. Die korrekte Skalenfunktion wäre daher scale_y_continuous()26, die wir nun unserem Plot-Objekt per + hinzufügen können.
In dieser Funktion können wir nun Argumente definieren, wie die Skala verändert werden soll – zum Beispiel name für den Namen der Skala, limits für die untere und obere Begrenzung der Skala, und breaks für die Abschnitte der Skala:
facebook_europawahl %>%
ggplot(aes(x = party, fill = party)) +
geom_bar() +
scale_y_continuous(name = "Anzahl Facebook-Posts", limits = c(0, 110), breaks = seq(0, 110, 10))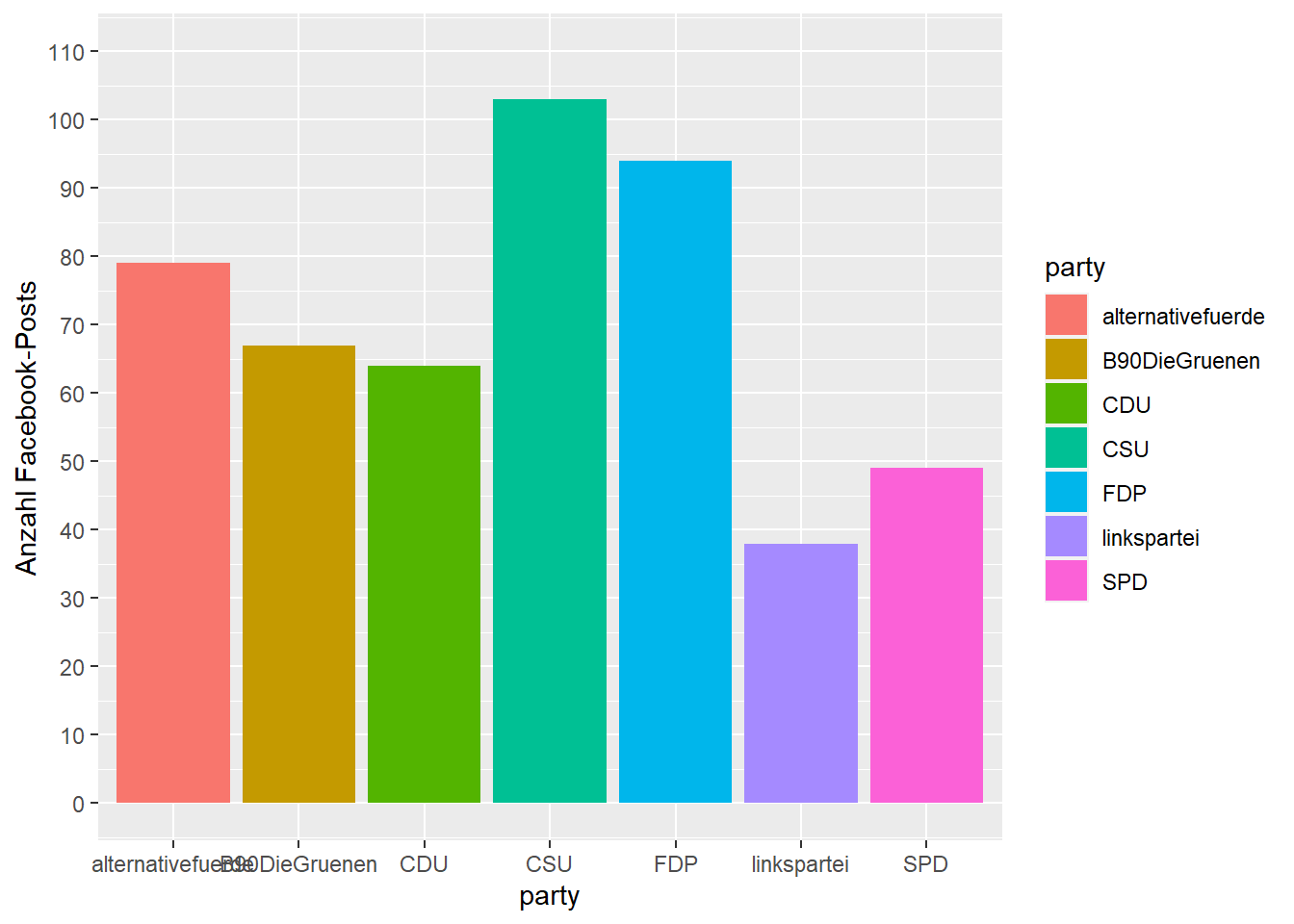
Und schon haben wir die Y-Achse angepasst. Weiter geht es mit der X-Achse. Hierbei handelt es sich um kategoriale, also auch diskrete Werte, die zugehörige Skalenfunktion ist also scale_x_discrete(). Auch hier übergeben wir einen neuen Namen und geben die Ausprägungen in der gewünschten Reihenfolge per limits an. Zudem passen wir mittels labels die Beschriftungen für die drei Facebook-Seiten alternativefuerde, linkspartei und B90DieGruenen" an:
facebook_europawahl %>%
ggplot(aes(x = party, fill = party)) +
geom_bar() +
scale_y_continuous(name = "Anzahl Facebook-Posts", limits = c(0, 110), breaks = seq(0, 110, 10)) +
scale_x_discrete(name = "Partei [Hauptaccount auf Facebook]",
limits = c("CDU", "CSU", "SPD", "alternativefuerde", "FDP", "linkspartei", "B90DieGruenen"),
labels = c("alternativefuerde" = "AfD", "linkspartei" = "Linke", "B90DieGruenen" = "Grüne"))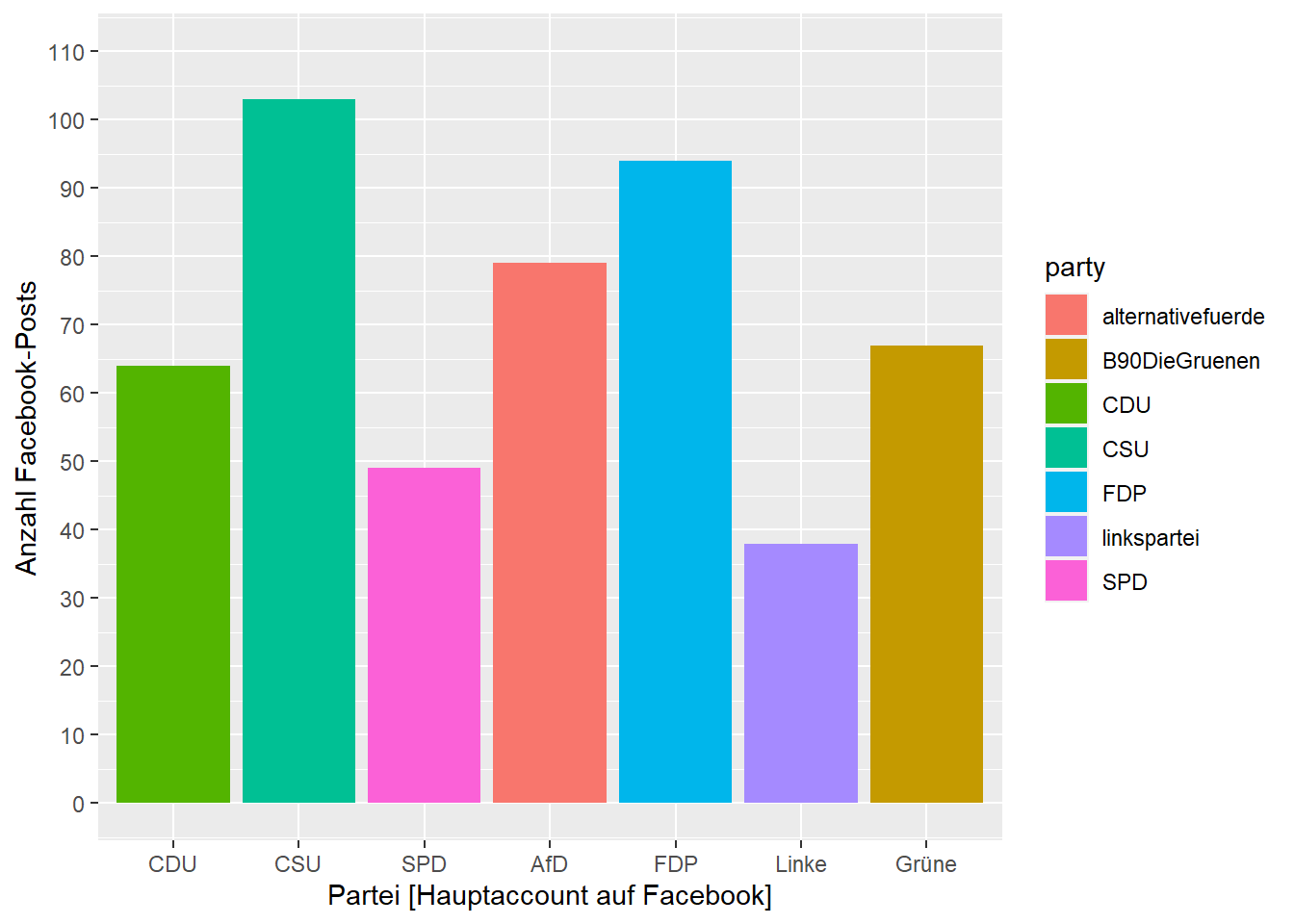
Schließlich passen wir die Parteifarben an. Diese werden über die Aesthetic fill (für Füllfarbe) definiert und sollen willkürlich festgelegt werden. Wir benötigen daher die Funktion scale_fill_manual(). Hier können wir mit dem Argument values einen Vektor mit den jeweiligen Wertausprägungen zugeordneten Farben übergeben. Zudem blenden wir mittels guide = NULL die Legende aus, da die Partei auch bereits in der X-Achse kodiert ist und die Legende somit redundant ist.
facebook_europawahl %>%
ggplot(aes(x = party, fill = party)) +
geom_bar() +
scale_y_continuous(name = "Anzahl Facebook-Posts", limits = c(0, 110), breaks = seq(0, 110, 10)) +
scale_x_discrete(name = "Partei [Hauptaccount auf Facebook]",
limits = c("CDU", "CSU", "SPD", "alternativefuerde", "FDP", "linkspartei", "B90DieGruenen"),
labels = c("alternativefuerde" = "AfD", "linkspartei" = "Linke", "B90DieGruenen" = "Grüne")) +
scale_fill_manual(guide = NULL,
values = c("CDU" = "black",
"CSU" = "black",
"SPD" = "red",
"alternativefuerde" = "blue",
"FDP" = "yellow",
"linkspartei" = "purple",
"B90DieGruenen" = "darkgreen"))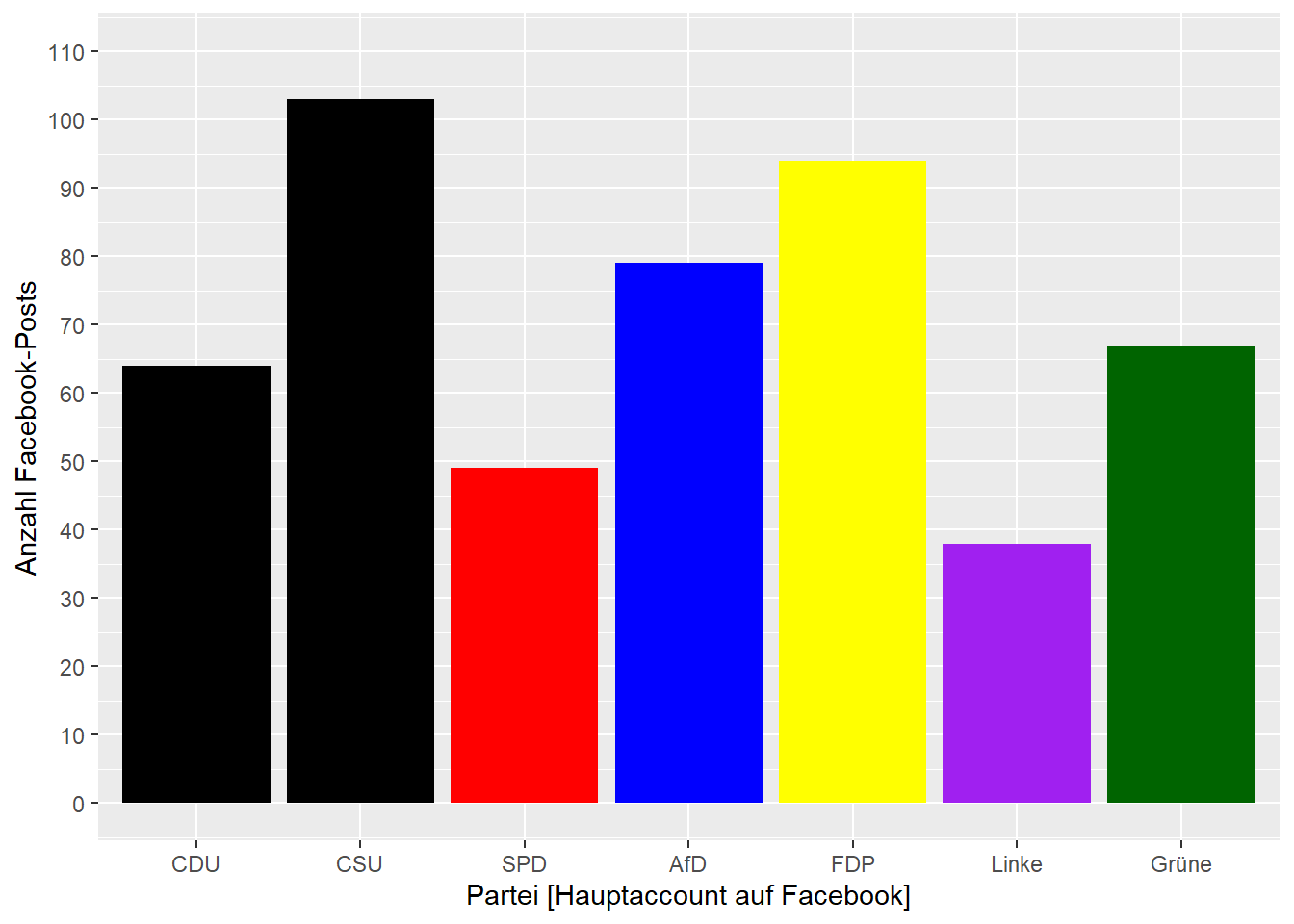
11.2.4 Plots in Facets aufteilen
Sobald wir mehr als drei oder vier Variablen kodieren möchten, wird eine einzelne Grafik oftmals unübersichtlich. Mittels Facets können wir den gleichen Plot auf Basis einer oder mehrerer Variablen erstellen. Die zugehörigen Funktionen lauten facet_wrap() (für eine Facet-Variable) sowie facet_grid() (für mehrere Facet-Variablen).
Wenn wir beispielsweise für obigen Plot noch den type, also die Art des Posts, unterscheiden möchten, könnten wir Facets für eben diese Variable über facet_wrap() anfordern:
facebook_europawahl %>%
ggplot(aes(x = party, fill = party)) +
geom_bar() +
scale_y_continuous(name = "Anzahl Facebook-Posts", limits = c(0, 110), breaks = seq(0, 110, 10)) +
scale_x_discrete(name = "Partei [Hauptaccount auf Facebook]",
limits = c("CDU", "CSU", "SPD", "alternativefuerde", "FDP", "linkspartei", "B90DieGruenen"),
labels = c("alternativefuerde" = "AfD", "linkspartei" = "Linke", "B90DieGruenen" = "Grüne")) +
scale_fill_manual(guide = NULL,
values = c("CDU" = "black",
"CSU" = "black",
"SPD" = "red",
"alternativefuerde" = "blue",
"FDP" = "yellow",
"linkspartei" = "purple",
"B90DieGruenen" = "darkgreen")) +
facet_wrap(~ type, nrow = 2)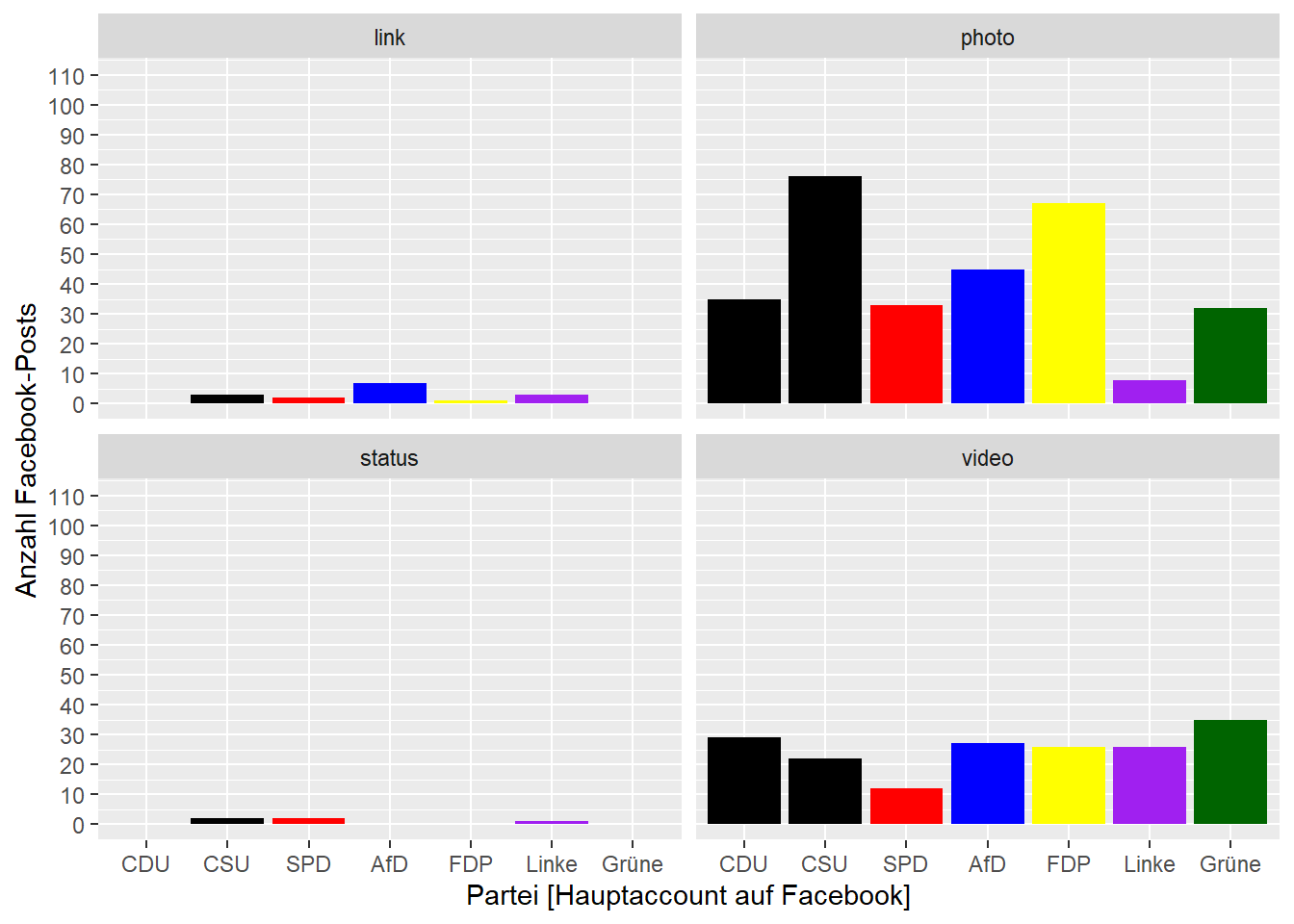
11.2.5 Themes anweden
Alle weiteren, rein ästhetischen Einstellungen werden durch theme_-Funktionen ergänzt. Hier bietet ggplot2 schon einige Vorlagen, um schnell das aussehen des gesamten Plots zu verändern.
Um vom grauen Standardhintergrund der Plots wegzukommen, können wir beispielsweise das theme_bw() anwenden:
facebook_europawahl %>%
ggplot(aes(x = party, fill = party)) +
geom_bar() +
scale_y_continuous(name = "Anzahl Facebook-Posts", limits = c(0, 110), breaks = seq(0, 110, 10)) +
scale_x_discrete(name = "Partei [Hauptaccount auf Facebook]",
limits = c("CDU", "CSU", "SPD", "alternativefuerde", "FDP", "linkspartei", "B90DieGruenen"),
labels = c("alternativefuerde" = "AfD", "linkspartei" = "Linke", "B90DieGruenen" = "Grüne")) +
scale_fill_manual(guide = NULL,
values = c("CDU" = "black",
"CSU" = "black",
"SPD" = "red",
"alternativefuerde" = "blue",
"FDP" = "yellow",
"linkspartei" = "purple",
"B90DieGruenen" = "darkgreen")) +
facet_wrap(~ type, nrow = 2) +
theme_bw()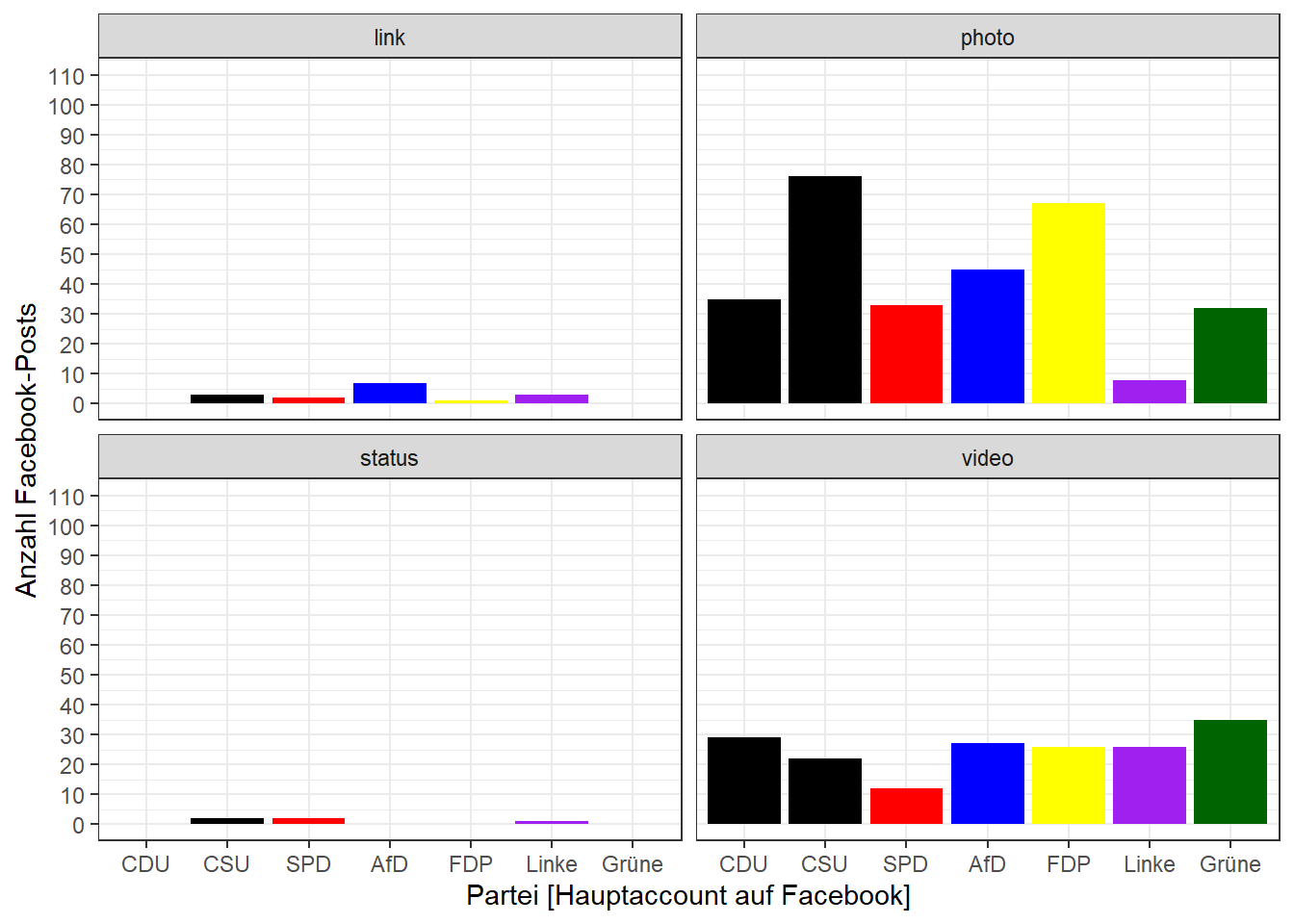
11.2.6 Häufige Probleme und Hilfestellungen
Wir sehen: in so eine Grafik fließen bisweilen sehr viel Code und viel Tüftelei. Nicht nur gibt es eine Menge an geom_-, scale_- und zusätzliche Funktionen, diese können zudem über zusätzliche Argumente noch weiter angepasst werden. Die gute Nachricht ist aber, dass für die reine Datenexploration oft auch schon die Grundschritte Aesthetics und Geometrics ausreichen.
Ein Hauptproblem zu Beginn der Nutzung von ggplot() ist es, die Daten überhaupt in das richtige Format, das die Funktion erwartet zu bekommen: ggplot() erwartet Long Data (siehe Kapitel 10.1.2), wohingegen unsere Datensätze oft zunächst auf Wide Data ausgelegt sind.
Möchten wir beispielsweise pro Partei die Verteilung der jeweiligen Facebook-Metriken plotten, haben wir ein Problem: die jeweiligen Werte sind in drei verschiedenen Variablen gespeichert (comments_count, shares_count und reactions_count); wir können in der Aesthetic y, auf der wir in der Regel abhängige numerische Werte abtragen, nur eine dieser drei Variablen kodieren.
Hier kommt die Long-Tranformation ins Spiel, wie wir sie auch in Übungsaufgabe 10.1 vorgenommen haben – der so transformierte Datensatz hat die Werte der jeweiligen Facebook-Metriken in nur einer Variable gespeichert und betrachtet dafür die Art der Facebook-Metrik als eigene Variable:
fb_long <- facebook_europawahl %>%
select(party, comments_count, shares_count, reactions_count) %>%
pivot_longer(cols = c(comments_count, shares_count, reactions_count), names_to = "metric")
fb_long## # A tibble: 1,482 x 3
## party metric value
## <chr> <chr> <dbl>
## 1 B90DieGruenen comments_count 70
## 2 B90DieGruenen shares_count 28
## 3 B90DieGruenen reactions_count 215
## 4 FDP comments_count 16
## 5 FDP shares_count 9
## 6 FDP reactions_count 262
## 7 CDU comments_count 239
## 8 CDU shares_count 136
## 9 CDU reactions_count 398
## 10 SPD comments_count 180
## # ... with 1,472 more rowsUnd schon können wir die Verteilung der Facebook-Metriken in Abhängigkeit von Partei und Art der Metrik darstellen – etwa indem wir party in x, value in y und metric in color kodieren und dann pro Partei verschiedenenfarbige Boxplots plotten:
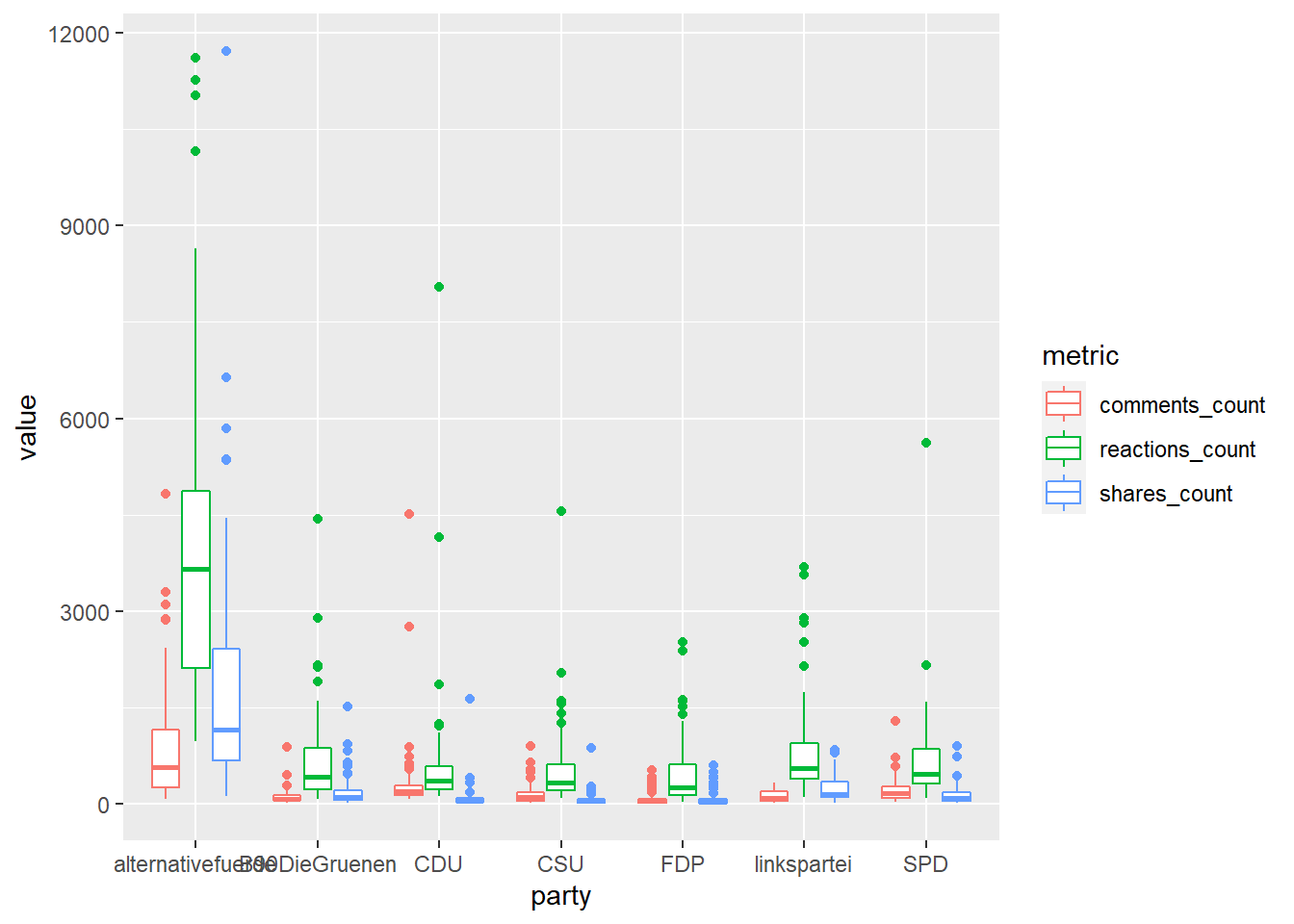
Oft ist es also sinnvoll, ein Plot-Problem dadurch anzugehen, indem die Struktur des zu plottenden Datensatzes nochmals überdacht wird oder zu plottende Werte bereits vorab mittels mutate() angepasst oder mittels summarize() nach Gruppen zusammengefasst werden. Die Funktionen aus den Kapiteln 8 und 10 helfen dabei, Datensätze schnell in die richtige Struktur zu bringen.
Im Internet ist zudem Hilfe nicht fern. Besonders hilfreich sind hier sogenannte Cookbooks, die “Rezepte” für alle möglichen Visualisierungen bereitstellen. Zwei Empfehlungen:
- R Graphics Cookbook: sehr umfangreiche Ressource, die so ziemlich alles abdeckt
- BBC Visual and Data Journalism cookbook for R graphics: Cookbook der BBC für Infografiken im BBC-Stil
11.2.7 Plots speichern
Nach all der Arbeit möchten wir unsere Grafiken natürlich auch in einem passenden Format speichern. Hierfür bietet sich die Funktion ggsave() an, die ähnlich wie saveRDS() zum Speichern von R-Objekten funktioniert.
Zunächst weisen wir unsere schöne Visualisierung einem Objekt zu:
plot_anzahl <- facebook_europawahl %>%
ggplot(aes(x = party, fill = party)) +
geom_bar() +
scale_y_continuous(name = "Anzahl Facebook-Posts", limits = c(0, 110), breaks = seq(0, 110, 10)) +
scale_x_discrete(name = "Partei [Hauptaccount auf Facebook]",
limits = c("CDU", "CSU", "SPD", "alternativefuerde", "FDP", "linkspartei", "B90DieGruenen"),
labels = c("alternativefuerde" = "AfD", "linkspartei" = "Linke", "B90DieGruenen" = "Grüne")) +
scale_fill_manual(guide = NULL,
values = c("CDU" = "black",
"CSU" = "black",
"SPD" = "red",
"alternativefuerde" = "blue",
"FDP" = "yellow",
"linkspartei" = "purple",
"B90DieGruenen" = "darkgreen")) +
facet_wrap(~ type, nrow = 2) +
theme_bw()
plot_anzahl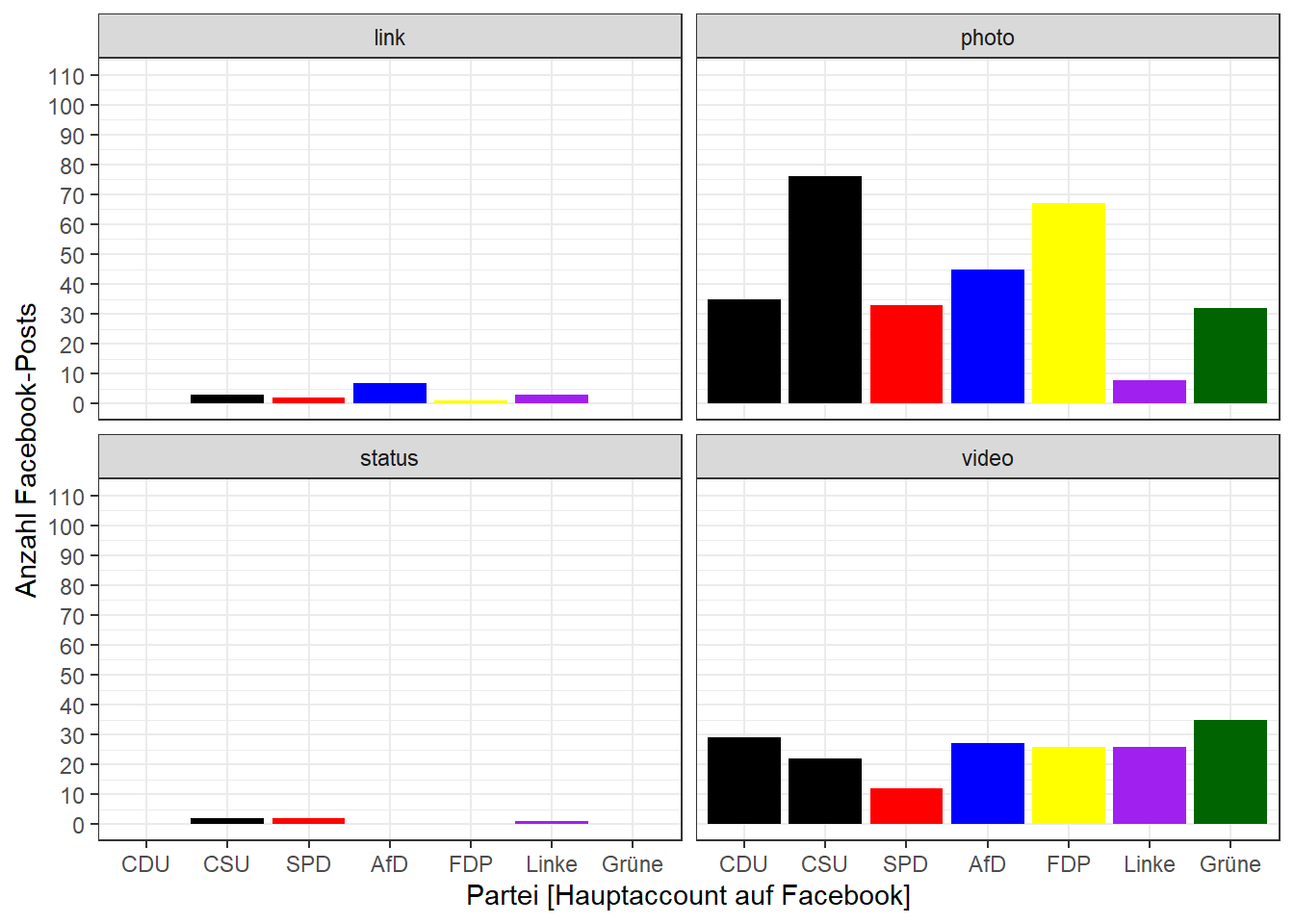
Nun können wir dieses Objekt mittels ggsave() speichern. Das erste Argument gibt hierbei den Speicherort an, das zweite das zu speichernde Plot-Objekt (also genau umgekehrt wie bei saveRDS() oder write_csv()). Mit weiteren Argumenten können wir die Ausgabedatei anpassen:
device: Ausgabeformat, z. B."jpg","png"oder"pdf".width,heightundunit: Breite und Höhe der Datei in einer definierten Maßeinheit fürunit, entweder"in","cm"oder"mm".dpi: Pixel-Auflösung (dots per inch). Für Bildschirmausgabe72, für Druck300.
11.3 Übungsaufgaben
Erstellen Sie für die folgenden Übungsaufgaben eine eigene Skriptdatei oder eine R-Markdown-Datei und speichern diese als ue11_nachname.R bzw. ue11_nachname.Rmd ab.
Laden Sie den Datensatz facebook_europawahl.csv, der schon aus den vorigen Übungen bekannt ist und filtern Sie diesen, sodass lediglich die im Bundestag vertretenen Parteien vorhanden sind.
Stellen Sie die den Zusammenhang der Variablen comments_count und shares_count in einem Punktdiagramm dar.
Fügen Sie dem Diagramm Informationen über die Partei, die für den jeweiligen Post verantwortlich ist (party), sowie die Art des Beitrags (type) hinzu.
Machen Sie das Diagramm “publikationsreif”, indem Sie Skalen und Beschriftungen anpassen und es nach den eigenen ästhetischen Vorlieben verschönern.
Man könnte argumentieren, dass als dritte Variable zusätzlich noch die Veränderung der Wahlabsicht im Vergleich zum Vormonat ersichtlich ist; diese ist aber lediglich als (zusätzliche) Wertbeschriftung abgetragen, nicht jedoch im eigentlichen Diagrammbereich visuell kodiert.↩︎
Wir können das leicht überprüfen, indem wir uns die Grafik jeweils ohne die andere Kodierung feststellen: auch wenn alle Balken gleichfarbig wären, könnten wir ohne Probleme dieselben Schlüsse aus der Grafik ziehen; würde die Kodierung “X-Achse” wegfallen, wären die Parteien also nicht nebeneinander auf der Achse abgetragen, sondern in einem Balken übereinandergestapelt, würden wir die einzelnen Balkenabschnitte durch die Farben auseinanderhalten können.↩︎
Man könnte nun anmerken, dass es sich bei der Anzahl um eine diskrete Skala handelt, da diese nur ganzzahlige Werte annehmen kann; für numerische Daten empfehle ich jedoch, immer kontinuierliche Skalen zu verwenden.↩︎