23 Validierung automatisierter Inhaltsanalysen
In ihrem wegweisenden Artikel Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts bringen die Politikwissenschaftler Justin Grimmer und Brandon M. Stewart eines der Grundprinzipien einer jeden guten, automatisierten Inhaltsanyalyse mit drei Worten59 auf den Punkt: “Validate, Validate, Validate”.
Automated text analysis methods can substantially reduce the costs and time of analyzing massive collections of political texts. When applied to any one problem, however, the output of the models may be misleading or simply wrong. […] What should be avoided, then, is the blind use of any method without a validation step (Grimmer & Stewart, 2013, S. 5).
Computationale Verfahren der automatisierten Inhaltsanalyse kommen in der Regel immer zu einem Ergebnis: ein Klassifikationsmodell klassifiziert alle Dokumente, ein Diktinär spuckt für jedes Dokument ein Ergebnis aus, ein Topic Model findet immer die vorgegebene Anzahl an Themen. Ob es sich dabei auch um inhaltlich sinnvolle Ergebnisse handelt, kann und muss durch manuelle Validierungen festgestellt werden.
Wie auch bei manuellen Erhebungs- und Analyseverfahren ist die Bestimmung der Validität einer automatisierten Messung komplex und mit Schwierigkeiten behaftet, da es gerade bei den bei uns so häufig untersuchten Konstrukten wie Themen und emotionaler Valenz oder der Kategorisierung von Texten nach inhaltlichen Kategorien letztlich keine abschließende Möglichkeit gibt, die Validität einer Untersuchung 100%ig zu bestimmen. Je nach verwendetem Verfahren werden daher unterschiedliche Optionen angewandt und/oder kombiniert, um sich der Bestimmung der Validität zumindest anzunähern:
- ähnlich wie bei den Intercoderreliabilitätstests der manuellen Inhaltsanalyse können die automatisierten Codierungen (eines Teilsamples) mit manuellen Codierungen verglichen werden; die manuellen Codierungen gelten hierbei meist als Goldstandard60, es wird also berechnet, wie gut (=reliabel) die automatisierten Codierungen die manuellen Codierungen replizieren können (Reliabilität als notwendige Voraussetzung von Validität).
- für bestimmte Verfahren können statistische Kennwerte herangezogen werden, die angeben, wie gut die automatisierten Codierungen zu den Daten passen (Validität im Sinne von Kriteriumsvalidität).
- sinnhafte Beziehungen zwischen den automatisierten Codierungen und anderen Variablen des Textkorpus können überprüft werden (Validität im Sinne von Konstruktvalidität). Haben wir beispielsweise in einem Topic Model ein “Terrorismus”-Thema identifiziert, so würden wir auch erwarten, dass dieses Thema häufiger auftritt, wenn das Veröffentlichungsdatum der jeweiligen Artikel kurz nach Terroranschlägen liegt.
Im Folgenden wird ein Überblick über konkrete Validierungsmöglichkeiten bei unterschiedlichen Verfahrensklassen gegeben. Wir werden uns außerdem mit einem Package auseinandersetzen, das Verfahren zur Validierung insbesondere von diktionärbasierten Ansätzen und Themenmodellen in R implementiert: oolong.
23.1 Validierung von Textklassifikationen
Textklassifikationen bzw. Verfahren des überwachten maschinellen Lernens allgemein haben den Vorteil, dass – zumindest wenn ein eigenes Klassifikationsmodell erstellt wird und nicht auf eine Out-of-the-Box-Lösung zurückgegriffen wird – bereits ein manuell codierter oder anderweitig annotierter (Teil-)Datensatz vorliegt. In Kapitel 20.1 haben wir bereits die Unterteilung in Trainings- und Testdatensätze kennengelernt und uns anhand dieser eine Confusion Matrix (siehe Kapitel 20.2.1) ausgeben lassen, auf Basis dieser dann wiederum statistische Messgrößen zur Beurteilung der Klassifikationsgüte berechnet werden können.
Grundsätzlich ist es ratsam, Klassifikationsmodelle immer anhand eines Teils des codierten Materials zu validieren, das nicht für die Berechnung des Modells verwendet wurde. In der Praxis wird häufig auch eine Dreiteilung des Ursprungsmaterials vorgenommen:
- Trainings-Datensatz: der Datensatz, anhand dem das Modell bzw. die Modelle trainiert werden. Um ein geeignetes Modell zu finden, müssen in der Regel mehrere Modelle berechnet werden (z. B. unterschiedliche Klassifikations-Algorithmen, Optimierung von Hyperparametern).
- Validierungs-Datensatz: der Datensatz, anhand dem die Performance der trainierten Modelle bewertet wird. Das Modell mit der besten Performance wird dann zum finalen Modell auserkoren.
- Test-Datensatz: der Datensatz, an dem die Performance des finalen Modells bewertet wird; der Testdatensatz war also weder an der Berechnung noch an der Validierung der Zwischenmodelle beteiligt.
Zudem können einige Modellklassen der Textklassifikation auf Kreuzvalidierungsverfahren schon bei der Berechnung der Modelle zurückgreifen. Hierbei wird der annotierte Textkorpus in \(k\) Teildatensätze aufgeteilt (bei einer 10-fachen Kreuzvalidierung also in 10 Teildatensätze), wobei das Modell dann automatisiert \(k\) mal jeweils auf Basis von \(k-1\) Teildatensätzen trainiert und anhand des verbleiben Teildatensatzes validiert wird.
23.2 Validierung von diktionärsbasierten Ansätzen
Diktionärsbasierte Ansätze resultierten in der Regel in metrischen Werten je Dokument, die etwa den Anteil der im Diktionär enthaltenen Begriffe an allen Wörtern jeweiligen Dokument oder, bei gewichteten Lexika, den Mittelwert der numerischen Gewichtung der einzelnen Wörter im Dokument. Bei einem Vergleich mit manuellen Codierungen kann also entweder diese ebenfalls eine gewichtete Abstufung des untersuchten Konstrukts berücksichtigen, oder es wird mit Cutoff-Werten gearbeitet, ab denen ein Dokument als einer Diktionärkategorie zugehörig gewertet wird (z. B. ob ein Dokument als ‘negativ’ gilt, wenn der Anteil der negativen Wörter im Dokument einen Anteil von soundsoviel Prozent übersteigt).
Mittels oolong wird die erste Variante umgesetzt. In einem sogenannten Gold-Standard-Test wird zunächst ein zufälliges Sample des gesamten Textmaterials von manuellen Codern (im Idealfall mindestens zweien) eingestuft und anschließend mit den automatisierten Einstufungen verglichen.
Kehren wir hierzu noch einmals zum bekannten Tweet-Datensatz von Donald Trump und Joe Biden zurück (siehe Kapitel 19):
library(tidyverse)
library(quanteda)
library(tidytext)
tweets <- read_csv("data/trump_biden_tweets_2020.csv") %>%
mutate(day = str_sub(date, 1, 10))
tweets## # A tibble: 4,153 x 8
## id account link content date retweet_count favorite_count day
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 1 JoeBiden https://twitter.com/JoeBi~ "Our final fundraising deadline of 2019 is just hours away and we ~ 2020/01/0~ 278 975 2020/0~
## 2 2 JoeBiden https://twitter.com/JoeBi~ "Every single human being deserves to be treated with dignity. Eve~ 2020/01/0~ 2523 11900 2020/0~
## 3 3 JoeBiden https://twitter.com/JoeBi~ "With just over one month until the Iowa Caucus, we need all hands~ 2020/01/0~ 382 1509 2020/0~
## 4 4 JoeBiden https://twitter.com/JoeBi~ "This election is about the soul of our nation — and Donald Trump ~ 2020/01/0~ 10545 45928 2020/0~
## 5 5 JoeBiden https://twitter.com/JoeBi~ "Every day that Donald Trump remains in the White House puts the f~ 2020/01/0~ 2071 9825 2020/0~
## 6 6 JoeBiden https://twitter.com/JoeBi~ "It was a privilege to work with @JulianCastro during the Obama Ad~ 2020/01/0~ 2359 17534 2020/0~
## 7 7 JoeBiden https://twitter.com/JoeBi~ "Like Vicky said, we need a president who will restore integrity t~ 2020/01/0~ 1344 6835 2020/0~
## 8 8 JoeBiden https://twitter.com/JoeBi~ "I'm excited to share that we raised $22.7 million this last quart~ 2020/01/0~ 2448 14719 2020/0~
## 9 9 JoeBiden https://twitter.com/JoeBi~ "If you're a teacher or a firefighter, you're probably paying more~ 2020/01/0~ 3043 18565 2020/0~
## 10 10 JoeBiden https://twitter.com/JoeBi~ "Before the holidays, Jill walked across the Gateway International~ 2020/01/0~ 1165 3231 2020/0~
## # ... with 4,143 more rowsWir möchten die positive und negative Valenz dieser Tweets nun durch das AFINN-Dictionary bewerten lassen (siehe Kapitel 19.3) und diese automatisierte Einstufung auch manuell validieren. All dies kann direkt in R und RStudio mittels oolong erfolgen:
Mit der Funktion create_oolong() können wir ein Test-Objekt erzeugen. Hierzu übergeben wir die Texte der Tweets als Argument input_corpus und benennen das Attribut, das wir codieren möchten, mit dem Argument construct. Oolong sieht vor, dass dieses Konstrukt mit einem passenden Adjektiv bezeichnet wird, hier würde sich z. B. “positive” anbieten, da höhere AFINN-Werte einem positiveren Tweet entsprechen:
## An oolong test object (gold standard generation) with 41 cases, 0 coded.
## Use the method $do_gold_standard_test() to generate gold standard.
## Use the method $lock() to finalize this object and see the results.Wir sehen, dass das neue Objekt ein Testobjekt ist, in dem automatisch 1% des Textkorpus – in unserem Fall also 41 Tweets – zufällig ausgewählt wurden. Als nächstes weist uns das Package an, einen Gold-Standard-Test mit der Methode $do_gold_standard_test() durchzuführen.
Es öffnet sich nun in RStudio eine Codiermaske, in der wir diese 41 Tweets auf einer fünfstufigen Skala bewerten können.61
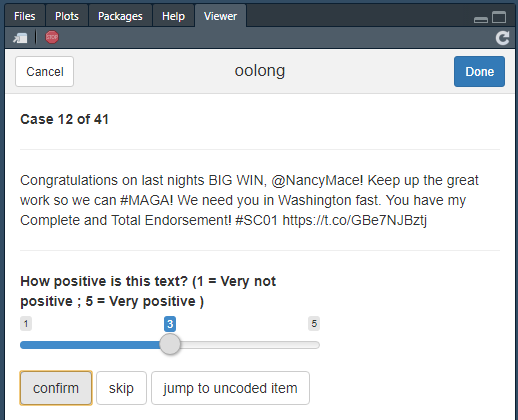
Gold-Standard-Test in oolong
Nach der Codierung sperren wir das Test-Objekt mit der Methode $lock, damit diese nicht mehr verändert werden können:
Nun können wir anhand des Test-Objekts die automatisierte Codierung vornehmen. Mit der Methode $turn_gold() erzeugen wir automatisch einen Quanteda-Korpus aus den zu codierenden Tweets:
## Corpus consisting of 41 documents and 1 docvar.
## text1 :
## "....He is Strong on Crime, the Border, and Second Amendment...."
##
## text2 :
## "After last night, we are one step closer to restoring decenc..."
##
## text3 :
## "Congratulations to @serenawilliams on another big win. She i..."
##
## text4 :
## "We need a president who demonstrates the leadership to addre..."
##
## text5 :
## "Mini Mike, you’re easy! https://t.co/rxFiqSB9RQ https://t.co..."
##
## text6 :
## "....very often FAKE NEWS. Lamestream Media should be forced ..."
##
## [ reached max_ndoc ... 35 more documents ]
## Access the answer from the coding with quanteda::docvars(obj, 'answer')Nun können wir wie bereits bekannt den AFINN-Score berechnen:62
tweets_afinn <- gs_corpus %>%
convert("data.frame") %>% # In Dataframe konvertieren
unnest_tokens(word, text, token = "tweets") %>% # Text in Token splitten
left_join(get_sentiments("afinn")) %>% # AFINN-Scores hinzufügen
mutate(value = if_else(is.na(value), 0, value)) %>% # fehlende Werte (= Wort nicht im AFINN-Dictionary) durch 0 ersetzen
group_by(doc_id) %>% # Nach Texten gruppieren
summarise(afinn = mean(value), .groups = "drop") # Durchschnittlichen AFINN-Score berechnen
tweets_afinn## # A tibble: 41 x 2
## doc_id afinn
## <chr> <dbl>
## 1 text1 0.1
## 2 text10 -0.0217
## 3 text11 -0.0513
## 4 text12 0.387
## 5 text13 0
## 6 text14 0
## 7 text15 0.0952
## 8 text16 0
## 9 text17 0.111
## 10 text18 0.2
## # ... with 31 more rowsNun extrahieren wir die AFINN-Scores als Vektor, um diese anschließend mit den manuellen Codierungen zu vergleichen:
Der Vergleich erfolgt über die Funktion summarize_oolong():
Die Resultate können am einfachsten über eine mitgelieferte Visualisierung betrachtet werden, die in vier Subgrafiken unterteilt ist:
- links oben ist die Korrelation zwischen den manuellen Codierungen und den automatischen Codierungen. Hier möchten wir natürlich eine möglichst hohe Korrelation erreichen; im Beispiel ist das offensichtlich nicht der Fall (das kann aber auch an meiner sehr schludrigen Codierung liegen).
- rechts oben ist ein sogenannter Bland-Altmann-Plot, der den Mittelwert zweier Messungen (hier also manueller und automatischer Codierung eines Tweets) gegen deren Differenz abträgt. Hier sollten im Idealfall keinen Muster erkennbar sein (damit keine systematischen Unterschiede zwischen manueller und automatischer Codierung vorliegen) und keine allzu großen Schwankungen vorliegen (damit manuelle und automatische Codierung im Mittel nicht zu stark voneinander abweichen).
- links unten wird die Korrelation zwischen der Anzahl der Wörter und der automatisierten Codierung abgetragen. Hier sollte im Idealfall ebenfalls keine Korrelation erkennbar sein, damit unser Dictionary nicht systematisch durch die Textlänge beeinflusst wird.
- rechts unten wird schließlich der Cook-Abstand zur Beurteilung von besonders einflussreichen Fällen ausgegeben. Hier sollte im Idealfall kein Wert über der gestrichelten Linie liegen.
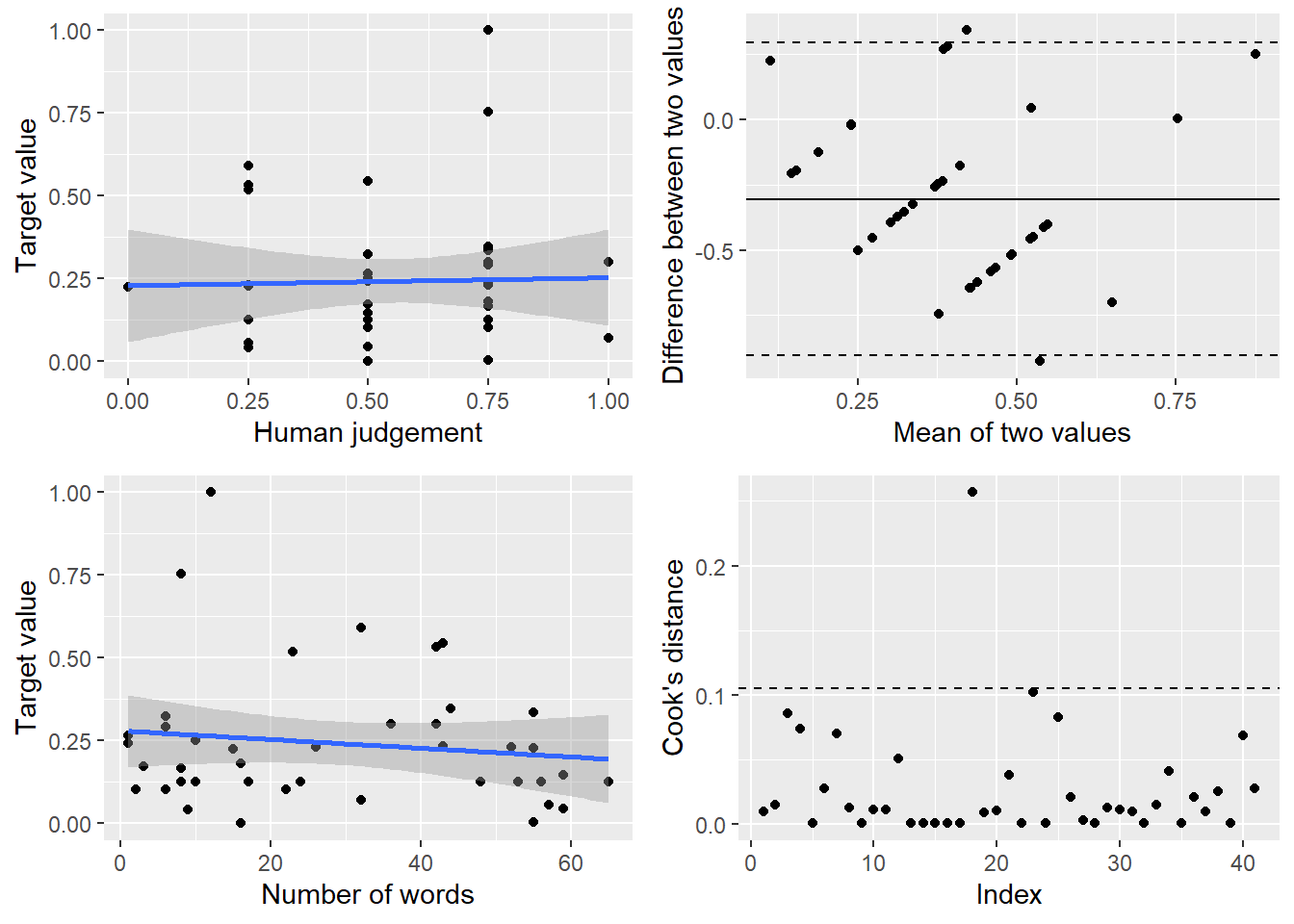
In diesem Falle würden wir insgesamt also auf keine sonderlich valide Codierung schließen – wobei fraglich ist, ob dies an der manuellen oder der automatisierten Codierung liegt.
23.3 Validierung von Themenmodellen
Neben den uns bereits bekannten Möglichkeiten zur statistischen und interpretativen Validierung von Themenmodellen (siehe Kapitel 21), bringt Oolong zwei weitere manuelle Valdierungsverfahren mit, die jeweils auf das Paper Reading Tea Leaves: How Humans Interpret Topic Models63 zurückgehen: Word Intrusion Tests und Topic Intrusion Tests.
Für die Beispiele verwenden wir das bereits bekannte Ted-Talks-Themenmodell mit 30 Themen, das wir im Rahmen des Kapitels zu Themenmodellen (siehe Kapitel 21) erstellt haben. Falls Sie das Modell nicht gespeichert haben, können Sie es mit folgendem Code erneut berechnen:
library(stm)
ted_talks <- read_tsv("data/ted_main_dataset.tsv")
ted_talks <- ted_talks %>%
filter(!is.na(speaker_image_nr_faces)) %>%
mutate(id = 1:n(),
date = lubridate::ymd(date, truncated = 1)) %>%
select(id, date, title, text)
ted_corpus <- corpus(ted_talks, text_field = "text")
ted_dfm <- dfm(ted_corpus,
stem = TRUE,
tolower = TRUE,
remove_punct = TRUE,
remove_url = FALSE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove = stopwords('english'))
ted_dfm <- dfm_trim(ted_dfm,
max_docfreq = 0.50,
min_docfreq = 0.01,
docfreq_type = 'prop')
stm_dfm <- convert(ted_dfm, to = "stm")
ted_model <- stm(documents = stm_dfm$documents,
vocab = stm_dfm$vocab,
K = 30)23.3.1 Word Intrusion Tests
Im Word Intrusion Test werden manuelle Codern zu jedem Topic (in zufälliger Reihenfolge) sechs zufällig ausgewählte Wörter vorgelegt, von denen alle bis auf eines eine hohe Themenwahrscheinlichkeit aufweisen; das letzte Wort, das sogenannte Intruder Word, weist eine geringe Themenwahrscheinlichkeit für dieses Thema auf, allerdings eine hohe Themenwahrscheinlichkeit bei mindestens einem anderen Thema. Das Ziel ist es nun, die Intruder Words manuell zu identifizieren – gelingt dies gut, so handelt es sich um eine brauchbare Themenlösung. Das Ergebnis wird als Precision bezeichnet und gibt den Anteil der korrekt identifizierten Intruder Words an allen Intrusion Tests an.
In Oolong setzen wir Word Intrusion Tests ganz ähnlich zum Vorgehen bei Gold-Standard-Tests mit create_oolong() um, nur dass nun anstatt eines Textkorpus mit dem Argument input_model ein Themenmodell übergeben wird:
## An oolong test object with k = 30, 0 coded.
## Use the method $do_word_intrusion_test() to do word intrusion test.
## Use the method $lock() to finalize this object and see the results.Wie angegeben, können wir mit der Methode $do_word_intrusion_test() nun den Word Intrusion Test umsetzen. Dies erfolgt erneut direkt in RStudio:
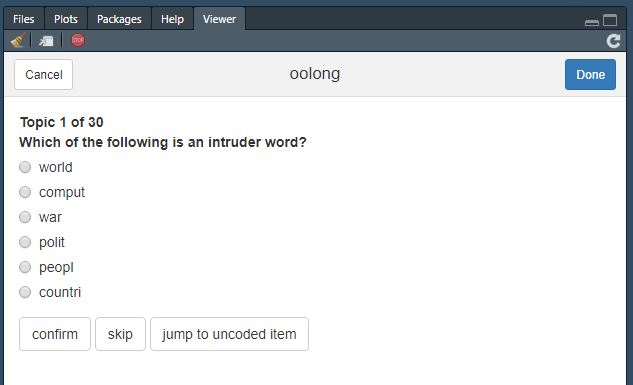
Word Intrusion Test in Oolong
Sind wir mit der manuellen Codierung durch, müssen wir das Oolong-Objekt erneut sperren, um uns die Ergebnisse anzeigen zu können:
Anschließend wird uns das Ergebnis direkt in der Konsole angezeigt:
## An oolong test object with k = 30, 30 coded.
## 70% precision70% der Intruder Words wurden korrekt identifiziert – das ist nicht schlecht, aber sicher verbesserungswürdig.
23.3.2 Topic Intrusion Tests
Beim Topic Intrusion Tests wird überprüft, ob die Zuordnung von Themen zu Dokumenten über die Dokumentwahrscheinlichkeiten auch manuell nachvollziehbar ist. Hierzu werden zufällig Dokumente ausgewählt und vier Topics angezeigt: die drei Topics mit der höchsten Dokumentwahrscheinlichkeit und ein zufällig ausgewähltes Intruder Topic, das eine geringe Dokumentwahrscheinlichkeit aufweist. Erneut ist das Ziel, das Intruder Topic zu identifizieren (hierzu werden zu allen Topics die wichtigsten Wörter angezeigt). Das Ergebnis wird erneut als Topic Log Odds (TLO) ausgewiesen, wobei ein Wert, der möglichst nahe an 0 liegt erreicht werden sollte.
Auch Topic Intrusion Tests werden in Oolong über die Funktion create_oolong() erzeugt, nur dass dieses Mal sowohl ein input_model als auch ein input_corpus angegeben wird. Für ersteres verwenden wir erneut das Themenmodell, für letzteres kann die DFM genutzt werden, auf deren Basis das Themenmodell erzeugt wurde.
## An oolong test object with k = 30, 0 coded.
## Use the method $do_word_intrusion_test() to do word intrusion test.
## With 23 cases of topic intrusion test. 0 coded.
## Use the method $do_topic_intrusion_test() to do topic intrusion test.
## Use the method $lock() to finalize this object and see the results.Wie angegeben, starten wir den Test mit do_topic_intrusion_test():
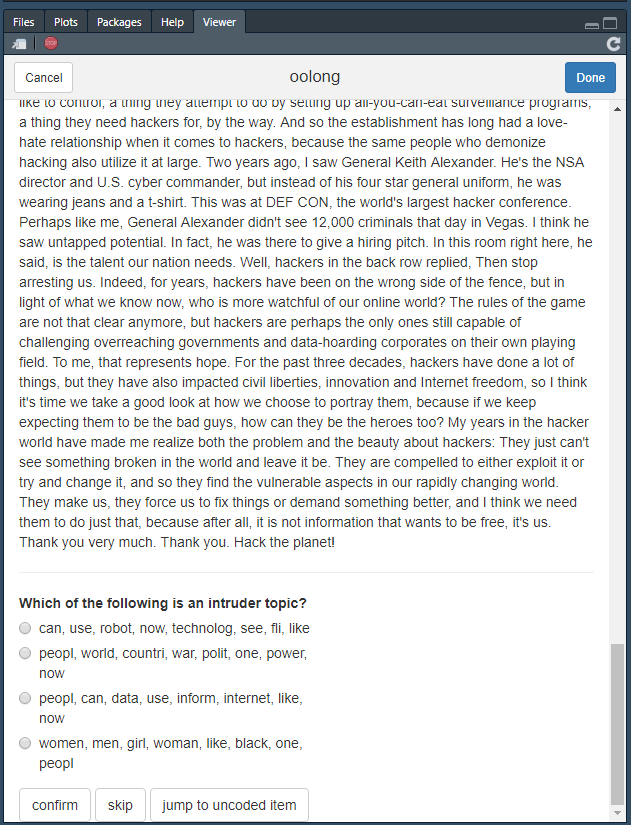
Topic Intrusion Test in Oolong
Und wieder einmal sperren wir das Objekt:
…und lassen uns das Ergebnis ausgeben:
## An oolong test object with k = 30, 0 coded.
## 0% precision
## With 23 cases of topic intrusion test. 23 coded.
## TLO: -4.413Hier haben wir einen Wert, der weit von 0 entfernt ist, und entsprechend als schlecht beurteilt werden würde.
23.3.3 Vorgehen bei mehreren Codern
Wie auch schon bei Gold-Standard-Test ist es sinnvoll, diese Tests mit mehreren manuellen Codern durchzuführen. Hier kann analog zum Gold-Standard-Test das initial erzeugte Oolong-Objekt mit clone_oolong() kopiert werden, sodass zwei Coder beide Tests hintereinander durchführen können:
# Oolong-Objekte erstellen
ti_test_coder1 <- create_oolong(input_model = ted_model, input_corpus = ted_talks$text)
ti_test_coder2 <- clone_oolong(ti_test_coder1)
# Codieren
ti_test_coder1$do_word_intrusion_test()
ti_test_coder1$do_topic_intrusion_test()
ti_test_coder2$do_word_intrusion_test()
ti_test_coder2$do_topic_intrusion_test()
# Sperren
ti_test_coder1$lock
ti_test_coder2$lockAnschließend kann erneut die Funktion summarize_oolong() verwendet werden, um die Ergbenisse mehrerer manueller Codierungen einzubeziehen:
23.4 Übungsaufgaben
Abschließend gibt es keine Übungsaufgaben – für die Projekte sollten Sie aber in allen Fällen auf die dargestellten Validierungsmethoden zurückgreifen. Viel Erfolg!
aber nur einem Feature↩︎
dies unterstellt allerdings, dass die manuelle Codierung bereits valide ist, was, wie oben angeführt, auch nicht unbedingt gegeben sein muss.↩︎
Sinnvoll wäre es, diese Bewertung von mindestens zwei Codern durchführen zu lassen, für das Beispiel nutzen wir aber nur einen Durchgang. Soll die Codierung von mehreren Codern durchgeführt werden, muss das ursprüngliche Testobjekt (in diesem Fall
gs_testmittels der Funktionclone_oolong()entsprechend oft kopiert werden).↩︎Eine alternative Berechnungsweise, die ohne
tidytextauskommt, findet sich in der offiziellen Dokumentation von Oolong.↩︎das wiederum der Namensgeber für das Package ist↩︎