A Lösungen der Übungsaufgaben
Kapitel 2: Objekte und Datenstrukturen
Lösung zur Übungsaufgabe 2.1:
Am sinnvollsten ist eine Liste list(), da diese heterogene Objekttypen beinhalten kann. Ein Dataframe lohnt sich bei nur einem Fall eher nicht.
myself <- list(
name = "Julian", # Texte als character
year = 1988L, # Jahr als numeric - oder noch präziser als Integer
from_bavaria = FALSE # Binäre Entscheidung als logical
)Auch wenn wir hier alle Werte z. B. als Text repräsentieren könnten, ist es immer sinnvoll, den Objekttypen zu verwenden, der am besten zu den Werten passt – numerische (year) und logische Objekte (from_bavaria) ermöglichen uns mehr Rechenoptionen, einfacheres Filtern von Datensätzen etc.
Lösung zur Übungsaufgabe 2.2:
values <- c(1.2, 1.3, 0.8, 0.7, 0.7, 1.5, 1.1, 1.0, 1.1, 1.2, 1.1)
average <- mean(values)
above_average <- values > average
sum(above_average) / length(values)## [1] 0.6363636- In der ersten Zeile ordnen wir
valueseinen numerischen Vektor aus einigen Zahlen zu - In der zweiten Zeile berechnen wir den Mittelwert von
valuesund weisen diesenaveragezu. values > averageprüft nun für jeden Wert invalues, ob dieser größer als der Mittelwert (gespeichert inaverageist). Dies erzeugt einenlogical-Vektor, den wirabove_averagezuweisen.sum(above_average)zählt, wie vieleTRUE-Werte in dem Vektor sind. Das ist darauf zurückzuführen, dassTRUEdie numerische Entsprechung1,FALSEdie numerische Entsprechung0hat;sum()wandelt den logischen Vektor automatisch in einen numerischen um. Wir teilen dies durch die Anzahl der Werte invaluesund bekommen als Ergebnis, dass 63.6 % der Werte invaluesüber dem Mittelwert liegen. (Etwas schneller hätten wir dieses Ergebnis auch bekommen, wenn wir die letzte Zeile durchmean(above_average)ersetzen.)
Lösung zur Übungsaufgabe 2.3:
## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...mtcars enthält 11 Variablen, allesamt numeric, und 32 Fälle.
## [1] 6.1875Im Durchschnitt haben die Fahrzeuge ca. 6.2 Zylinder.
Um einen Teildatensatz cars_short, der lediglich die Variablen mpg und hp enthält, zu erstellen, führen viele Wege zum Ziel, z. B.:
Kapitel 3: Funktionen
Lösung zur Übungsaufgabe 3.1:
Um die gewünschte Sequenz zu erzeugen, benötigen wir die Argumente from (Startwert), to (Endwert) und by (Zunahmewert).
## [1] 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100Da es sich, wie wir der Funktionsdokumentation entnehmen können, dabei um die ersten drei Funktionsargumente handelt, können wir diese auch unbenannt übergeben:
## [1] 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100Lösung zur Übungsaufgabe 3.2:
Unsere Funktion benötigt lediglich ein Argument, die Temperatur in Grad Fahrenheit (als numerischen Wert), und soll diese in Grad Celsius mit der Formel \(°C = (°F - 32) × 5/9\) umwandeln:
fahrenheit_to_celsius <- function(fahrenheit) {
celsius <- (fahrenheit - 32) * 5/9
return(celsius)
}
# Unsere neue Funktion kann sogar mehrere Temperaturwerte auf einmal umrechnen
fahrenheit_to_celsius(c(0, 50, 80, 100))## [1] -17.77778 10.00000 26.66667 37.77778Lösung zur Übungsaufgabe 3.3:
Für das erste zusätzliche Feature, der Anzahl der fehlenden Werte, müssen wir descriptives_vector lediglich ein Element hinzufügen (das wir z. B. Missing nennen), in dem eben diese Anzahl festgehalten wird. Mit der Funktion is.na() prüfen wir jeden Wert eines Vektors darauf, ob es sich um einen fehlenden Wert NA handelt, mit der Summenfunktion sum() können wir diese addieren. Wir ändern descriptives_vector daher wie folgt:
descriptives_vector <- c(
n = length(x),
Missing = sum(is.na(x)), # Hier zählen wir die fehlenden Werte
M = mean(x, na.rm = na.rm),
SD = sd(x, na.rm = na.rm),
Minimum = min(x, na.rm = na.rm),
Maximum = max(x, na.rm = na.rm),
Median = median(x, na.rm = na.rm)
)Für das zweite zusätzliche Feature, Rundung auf eine gewünsche Anzahl an Nachkommastelle, benötigen wir die round()-Funktion, mit dem wir descriptives_vector abschließend runden, und ein zusätzliches Argument, mit dem die gewünschte Anzahl an Nachkommastellen übergeben werden kann. Da dieses Argument bei der round()-Funktion digits heißt, nennen wir es aus Konsistenzgründen auch in unserer Funktion so. Um standardmäßig auf zwei Nachkommastellen zu runden, geben wir dem Argument den Default-Wert 2. Der vollständige Funktionscode sieht also wie folgt aus:
descriptives <- function(x, na.rm = FALSE, digits = 2) { # Zusätzliches Argument digits mit Default-Wert 2
# Vektor mit Variablenbeschreibung erstellen
descriptives_vector <- c(
n = length(x),
Missing = sum(is.na(x)), # Hier zählen wir die fehlenden Werte
M = mean(x, na.rm = na.rm),
SD = sd(x, na.rm = na.rm),
Minimum = min(x, na.rm = na.rm),
Maximum = max(x, na.rm = na.rm),
Median = median(x, na.rm = na.rm)
)
# Vektor runden
descriptives_vector <- round(descriptives_vector, digits = digits)
return(descriptives_vector)
}Wir haben nun eine flexibel einsetzbare Funktion, um schnell relevante Kennwerte einer numerischen Variablen zu erhalten:
## n Missing M SD Minimum Maximum Median
## 150.00 0.00 5.84 0.83 4.30 7.90 5.80## n Missing M SD Minimum Maximum Median
## 32.0 0.0 6.2 1.8 4.0 8.0 6.0Kapitel 4: Kontrollstrukturen
Lösung zur Übungsaufgabe 4.1:
Erneut gibt es verschiedene Möglichkeiten, den Entscheidungsbaum abzubilden. Wenn wir uns pro if () bzw. else () oder else if () auf das Prüfen einer Bedingung beschränken wollen, benötigen wir einen verschachtelten Baum, also eine Bedinung in einer Bedingung:
if (news_channel != "Internet") { # Prüfen, ob news_channel NICHT "Internet" ist...
news_category <- "Offline" # dann news_category "Offline" zuweisen
} else { # Falls das nicht der Fall ist, also news_channel "Internet" ist..
if (news_website == "Twitter") { # dann prüfen wir ob news_category "Twitter" ist
news_category <- "SNS" # falls das so ist, weisen wir news_category "SNS" zu
} else if (news_website == "Facebook") { # analog verfahren wir mit Facebook
news_category <- "SNS" #
} else if (news_website == "Instagram") { # analog mit Instagram
news_category <- "SNS" #
} else { # falls das alles nicht zutrifft
news_category <- "Online: Sonstige" # weisen wir "Online: Sonstige" zu
}
}Das erzeugt allerdings einen ziemlich langen Entscheidungsbaum und einige Redundanzen, da wir für "Twitter", "Facebook" und "Instagram" jeweils dieselbe Aktion, news_category <- "SNS" ausführen. Wir können diese Bedingungen also auch verknüpfen:
if (news_channel != "Internet") { # Prüfen, ob news_channel NICHT "Internet" ist...
news_category <- "Offline" # dann news_category "Offline" zuweisen
} else { # Falls das nicht der Fall ist, also news_channel "Internet" ist..
if (news_website == "Twitter" | news_website == "Facebook" | news_website == "Instagram") {
news_category <- "SNS" # Alle Bedingungen mit ODER verbunden, dann SNS zuweisen
} else { # falls das nicht zutrifft
news_category <- "Online: Sonstige" # weisen wir "Online: Sonstige" zu
} # und haben uns einige Zeilen gespart
}Tatsächlich können wir auch die Verschachtelung aufheben, da nach if (news_channel != "Internet") folgt, dass bei allen anschließenden else if()-Bedingungen news_channel == "Internet" ist:
if (news_channel != "Internet") {
news_category <- "Offline"
} else if (news_website == "Twitter" | news_website == "Facebook" | news_website == "Instagram") {
news_category <- "SNS"
} else {
news_category <- "Online: Sonstige"
}Und noch kürzer wir der Entscheidungsbaum, wenn wir den %in%-Operator verwenden:
SNS <- c("Twitter", "Facebook", "Instagram")
if (news_channel != "Internet") {
news_category <- "Offline"
} else if (news_website %in% SNS) {
news_category <- "SNS"
} else {
news_category <- "Online: Sonstige"
}Lösung zur Übungsaufgabe 4.2:
Beim ersten Platzhalter müssen wir einen for-Loop, wie in Kapitel 4.2.2 beschrieben, einfügen und uns für einen Namen für das Iterator-Objekt entscheiden. Da wir über den Vektor variables loopen, bietet sich der Singular variable an (aber natürlich funktioniert auch jeder andere Objektname). Diesen müssen wir dann bei den folgenden Platzhaltern ergänzen:
numeric_summary <- function(data) {
# Alle Variablennamen in Vektor speichern
variables <- names(data)
# Leere Liste für Ausgabe vorbereiten
summary_list <- list()
# Über alle Variablen iterieren
for (variable in variables) { # Wir loopen über variables
variable_vector <- data[[variable]] # Und arbeiten nun immer mit dem Iterator-Objekt variable
if (is.numeric(variable_vector)) { # Prüfen ob die Variable numerisch ist
# Mittelwert und Standardabweichung dieser Variablen der summary_list hinzufügen
summary_list[[variable]] <- c(
M = mean(variable_vector),
SD = sd(variable_vector)
)
}
}
# Summary List ausgeben
return(summary_list)
}Diese Funktion erzeugt uns nun auf einen Schlag eine Kurzzusammenfassung anhand von Mittelwert und Standardabweichung aller numerischen Variablen in einem Datensatz:
## $Sepal.Length
## M SD
## 5.8433333 0.8280661
##
## $Sepal.Width
## M SD
## 3.0573333 0.4358663
##
## $Petal.Length
## M SD
## 3.758000 1.765298
##
## $Petal.Width
## M SD
## 1.1993333 0.7622377## $mpg
## M SD
## 20.090625 6.026948
##
## $cyl
## M SD
## 6.187500 1.785922
##
## $disp
## M SD
## 230.7219 123.9387
##
## $hp
## M SD
## 146.68750 68.56287
##
## $drat
## M SD
## 3.5965625 0.5346787
##
## $wt
## M SD
## 3.2172500 0.9784574
##
## $qsec
## M SD
## 17.848750 1.786943
##
## $vs
## M SD
## 0.4375000 0.5040161
##
## $am
## M SD
## 0.4062500 0.4989909
##
## $gear
## M SD
## 3.6875000 0.7378041
##
## $carb
## M SD
## 2.8125 1.6152Kapitel 8: Daten laden, modifizieren und speichern
Lösung zur Übungsaufgabe 8.1:
Wir benötigen die read_csv()-Funktion, da alle Werte durch Kommas getrennt sind. Falls der Datensatz im Hauptverzeichnis des Projektordners liegt, genügt die Angabe von "facebook_europawahl.csv" als Argument:
Liegt der Datensatz in einem Unterordner, muss der Dateipfad entsprechend als Argument angepasst werden, z. b. "data/facebook_europawahl.csv".
##
## -- Column specification ----------------------------------------------------------------------------------------------------------------------------------------
## cols(
## id = col_double(),
## URL = col_character(),
## party = col_character(),
## timestamp = col_datetime(format = ""),
## type = col_character(),
## message = col_character(),
## link = col_character(),
## comments_count = col_double(),
## shares_count = col_double(),
## reactions_count = col_double(),
## like_count = col_double(),
## love_count = col_double(),
## wow_count = col_double(),
## haha_count = col_double(),
## sad_count = col_double(),
## angry_count = col_double()
## )Lösung zur Übungsaufgabe 8.2:
Um den Datensatz zu filtern, benötigen wir zunächst die Schreibweisen der Partei-Accounts. Hierzu bietet es sich an, die party-Variable auszuzählen:
## # A tibble: 14 x 2
## party n
## <chr> <int>
## 1 alternativefuerde 79
## 2 B90DieGruenen 67
## 3 CDU 64
## 4 CSU 103
## 5 DiePARTEI 96
## 6 FamilienParteiDeutschlands 30
## 7 FDP 94
## 8 freie.waehler.bundesvereinigung 30
## 9 linkspartei 38
## 10 oedp.de 71
## 11 Piratenpartei 73
## 12 SPD 49
## 13 tierschutzpartei 33
## 14 VoltDeutschland 75Ebenfalls optional, aber hilfreich ist es, die entsprechenden Parteiseiten in einem Vektor zu speichern:
Nun filtern wir den Datensatz zunächst nach Parteien:
Dann wählen wir nur die gewünschten Variablen aus:
df_reduziert <- select(df_bt_parteien, party, timestamp, type,
comments_count, shares_count, reactions_count)Und schließlich erzeugen wir die neue Variable total_count:
df_mit_tc <- mutate(df_reduziert,
total_count = sum(c(comments_count, shares_count, reactions_count), na.rm = TRUE))
df_mit_tc## # A tibble: 494 x 7
## party timestamp type comments_count shares_count reactions_count total_count
## <chr> <dttm> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 B90DieGruenen 2019-04-28 06:00:01 video 70 28 215 871753
## 2 FDP 2019-04-28 11:49:59 photo 16 9 262 871753
## 3 CDU 2019-04-28 09:12:19 video 239 136 398 871753
## 4 SPD 2019-04-28 13:06:09 photo 180 54 699 871753
## 5 CSU 2019-04-28 08:21:00 photo 174 61 458 871753
## 6 alternativefuerde 2019-04-28 14:55:00 link 1163 1499 3944 871753
## 7 FDP 2019-04-28 06:18:18 photo 47 110 622 871753
## 8 FDP 2019-04-28 14:03:00 video 358 89 463 871753
## 9 FDP 2019-04-28 10:40:57 photo 14 19 226 871753
## 10 CSU 2019-04-28 12:35:00 photo 133 20 330 871753
## # ... with 484 more rowsWarum addieren wir nicht einfach alle Spalten ohne die Summenfunktion?
df_mit_total2 <- mutate(df_reduziert, total_count = comments_count + shares_count + reactions_count)
df_mit_total2## # A tibble: 494 x 7
## party timestamp type comments_count shares_count reactions_count total_count
## <chr> <dttm> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 B90DieGruenen 2019-04-28 06:00:01 video 70 28 215 313
## 2 FDP 2019-04-28 11:49:59 photo 16 9 262 287
## 3 CDU 2019-04-28 09:12:19 video 239 136 398 773
## 4 SPD 2019-04-28 13:06:09 photo 180 54 699 933
## 5 CSU 2019-04-28 08:21:00 photo 174 61 458 693
## 6 alternativefuerde 2019-04-28 14:55:00 link 1163 1499 3944 6606
## 7 FDP 2019-04-28 06:18:18 photo 47 110 622 779
## 8 FDP 2019-04-28 14:03:00 video 358 89 463 910
## 9 FDP 2019-04-28 10:40:57 photo 14 19 226 259
## 10 CSU 2019-04-28 12:35:00 photo 133 20 330 483
## # ... with 484 more rowsDies führt augenscheinlich zunächst zum gleichen Ergebnis, hat aber ein Problem: kommen in einer der drei Facebook-Metriken fehlende Werte in Form von NA vor, ist das Ergebnis in total_count ebenfalls NA. Der Summenfunktion sum() können wir mit dem Argument na.rm = TRUE mitteilen, dass fehlende Werte nicht berücksichtigt werden sollen:
## [1] 0
## [1] 5Wählen wir diese +-Variante, haben wir also 5 fehlende Werte in unserem total_count, bei der ersten Variante keine.
Nun können wir den Datensatz abspeichern:
Lösung zur Übungsaufgabe 8.3:
Zunächst wählen wir nur die Woche vor der Wahl aus. Hierzu können wir die timestamp-Variable anfiltern – Text, der wie ein Datum aussieht, wir dabei automatisch in ein Datum konvertiert:
Nun gruppieren wir den Datensatz nach party:
Und schließlich berechnen wir mit summarize() die gewünschten Kennwerte:
summarize(df_group_by_party,
M_comments = mean(comments_count, na.rm = TRUE),
SD_comments = sd(comments_count, na.rm = TRUE),
M_shares = mean(shares_count, na.rm = TRUE),
SD_shares = sd(shares_count, na.rm = TRUE),
M_reactions = mean(reactions_count, na.rm = TRUE),
SD_reactions = sd(reactions_count, na.rm = TRUE))## # A tibble: 14 x 7
## party M_comments SD_comments M_shares SD_shares M_reactions SD_reactions
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 alternativefuerde 1210. 1250. 1819. 2491. 4690. 3109.
## 2 B90DieGruenen 106. 67.0 211. 244. 740. 682.
## 3 CDU 508. 897. 113. 293. 870. 1548.
## 4 CSU 182. 148. 58.5 45.3 579. 421.
## 5 DiePARTEI 92.5 137. 147. 175. 1874. 1879.
## 6 FamilienParteiDeutschlands 0.714 1.50 14 9.78 14.9 14.9
## 7 FDP 106. 108. 111. 107. 802. 564.
## 8 freie.waehler.bundesvereinigung 10.7 12.3 25.7 20.3 86 33.7
## 9 linkspartei 161. 100. 217. 176. 1176. 1142.
## 10 oedp.de 8.30 11.7 30.3 24.6 141. 108.
## 11 Piratenpartei 15.3 25.9 44.2 50.1 163. 213.
## 12 SPD 240. 277. 137. 120. 658. 510.
## 13 tierschutzpartei 82 110. 288 378. 999. 1193.
## 14 VoltDeutschland 27.7 70.8 54.7 88.7 316. 365.Kapitel 9: Der Pipe-Operator %>%
Lösung zur Übungsaufgabe 9.1:
Dank Pipes können wir uns bei Übungsaufgabe 8.2 die ganzen Zwischendatensätze sparen. Es ist jedoch sinnvoll, vor dem Speichern ein Datensatz-Objekt zuzuweisen, da wir dieses auf zweierlei Arten speichern möchten. Auch nach dem erstmaligen Laden bietet es sich an, den Originaldatensatz zunächst als Objekt zuzuweisen:
facebook_europawahl <- read_csv("data/facebook_europawahl.csv")
bt_parteien <- c("alternativefuerde", "B90DieGruenen", "CDU", "CSU", "FDP", "linkspartei", "SPD")
df_reduziert <- facebook_europawahl %>%
filter(party %in% bt_parteien) %>%
select(party, timestamp, type, comments_count, shares_count, reactions_count) %>%
mutate(total_count = sum(c(comments_count, shares_count, reactions_count), na.rm = TRUE))
df_reduziert## # A tibble: 494 x 7
## party timestamp type comments_count shares_count reactions_count total_count
## <chr> <dttm> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 B90DieGruenen 2019-04-28 06:00:01 video 70 28 215 871753
## 2 FDP 2019-04-28 11:49:59 photo 16 9 262 871753
## 3 CDU 2019-04-28 09:12:19 video 239 136 398 871753
## 4 SPD 2019-04-28 13:06:09 photo 180 54 699 871753
## 5 CSU 2019-04-28 08:21:00 photo 174 61 458 871753
## 6 alternativefuerde 2019-04-28 14:55:00 link 1163 1499 3944 871753
## 7 FDP 2019-04-28 06:18:18 photo 47 110 622 871753
## 8 FDP 2019-04-28 14:03:00 video 358 89 463 871753
## 9 FDP 2019-04-28 10:40:57 photo 14 19 226 871753
## 10 CSU 2019-04-28 12:35:00 photo 133 20 330 871753
## # ... with 484 more rowsAnschließend können wir den Datensatz wieder speichern:
Die Schritte aus Übungsaufgabe 8.3 können wir ebenfalls in eine Pipe verpacken – da wir den Datensatz nicht speichern bzw. weiter mit diesem arbeiten, ist auch keine Objektzuweisung erforderlich:
facebook_europawahl %>%
filter(timestamp >= "2019-05-20") %>%
group_by(party) %>%
summarize(M_comments = mean(comments_count, na.rm = TRUE),
SD_comments = sd(comments_count, na.rm = TRUE),
M_shares = mean(shares_count, na.rm = TRUE),
SD_shares = sd(shares_count, na.rm = TRUE),
M_reactions = mean(reactions_count, na.rm = TRUE),
SD_reactions = sd(reactions_count, na.rm = TRUE))## # A tibble: 14 x 7
## party M_comments SD_comments M_shares SD_shares M_reactions SD_reactions
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 alternativefuerde 1210. 1250. 1819. 2491. 4690. 3109.
## 2 B90DieGruenen 106. 67.0 211. 244. 740. 682.
## 3 CDU 508. 897. 113. 293. 870. 1548.
## 4 CSU 182. 148. 58.5 45.3 579. 421.
## 5 DiePARTEI 92.5 137. 147. 175. 1874. 1879.
## 6 FamilienParteiDeutschlands 0.714 1.50 14 9.78 14.9 14.9
## 7 FDP 106. 108. 111. 107. 802. 564.
## 8 freie.waehler.bundesvereinigung 10.7 12.3 25.7 20.3 86 33.7
## 9 linkspartei 161. 100. 217. 176. 1176. 1142.
## 10 oedp.de 8.30 11.7 30.3 24.6 141. 108.
## 11 Piratenpartei 15.3 25.9 44.2 50.1 163. 213.
## 12 SPD 240. 277. 137. 120. 658. 510.
## 13 tierschutzpartei 82 110. 288 378. 999. 1193.
## 14 VoltDeutschland 27.7 70.8 54.7 88.7 316. 365.Kapitel 10: Daten umstrukturieren und zusammenfügen
Lösung zur Übungsaufgabe 10.1:
Da wir den Datensatz vom Wide- ins Long-Format transformieren, benötigen wir die Funktion pivot_longer():
facebook_europawahl <- read_csv("data/facebook_europawahl.csv")
facebook_europawahl %>%
select(id, party, timestamp, comments_count, shares_count, reactions_count) %>%
pivot_longer(c(comments_count, shares_count, reactions_count), names_to = "metric")## # A tibble: 2,706 x 5
## id party timestamp metric value
## <dbl> <chr> <dttm> <chr> <dbl>
## 1 1 oedp.de 2019-04-28 09:00:00 comments_count 0
## 2 1 oedp.de 2019-04-28 09:00:00 shares_count 4
## 3 1 oedp.de 2019-04-28 09:00:00 reactions_count 9
## 4 2 tierschutzpartei 2019-04-28 13:57:00 comments_count 17
## 5 2 tierschutzpartei 2019-04-28 13:57:00 shares_count 130
## 6 2 tierschutzpartei 2019-04-28 13:57:00 reactions_count 395
## 7 3 B90DieGruenen 2019-04-28 06:00:01 comments_count 70
## 8 3 B90DieGruenen 2019-04-28 06:00:01 shares_count 28
## 9 3 B90DieGruenen 2019-04-28 06:00:01 reactions_count 215
## 10 4 FDP 2019-04-28 11:49:59 comments_count 16
## # ... with 2,696 more rowsLösung zur Übungsaufgabe 10.2:
Wir laden zunächst den zusätzlichen Datensatz:
## # A tibble: 902 x 23
## id topic100 topic200 topic310 topic320 topic331 topic332 topic330 topic341 topic342 topic343 topic340 topic350 topic360 topic370 topic380 topic391
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 34 0 1 0 0 1 1 1 0 0 1 1 0 0 0 1 0
## 2 62 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
## 3 122 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0
## 4 178 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0
## 5 300 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
## 6 303 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0
## 7 419 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0
## 8 421 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
## 9 429 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
## 10 448 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0
## # ... with 892 more rows, and 6 more variables: topic392 <dbl>, topic390 <dbl>, topic400 <dbl>, topic300 <dbl>, topic998 <dbl>, topic999 <dbl>Wie wir sehen, ist die id-Variable anders sortiert als im Datensatz facebook_europawahl. Wollen wir die Datensätze mittels bind_cols() zusammenfügen, müssten wir facebook_codings vorab mittels arrange() entsprechend facebook_europawahl sortieren.
Sicherer und genauso simpel ist allerdings left_join():
## # A tibble: 902 x 38
## id URL party timestamp type message link comments_count shares_count reactions_count like_count love_count wow_count haha_count sad_count
## <dbl> <chr> <chr> <dttm> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 http~ oedp~ 2019-04-28 09:00:00 video "Guido~ http~ 0 4 9 9 0 0 0 0
## 2 2 http~ tier~ 2019-04-28 13:57:00 photo "Aus u~ http~ 17 130 395 354 23 3 11 2
## 3 3 http~ B90D~ 2019-04-28 06:00:01 video "Beim ~ http~ 70 28 215 174 14 3 16 0
## 4 4 http~ FDP 2019-04-28 11:49:59 photo "Unser~ http~ 16 9 262 254 7 0 1 0
## 5 5 http~ tier~ 2019-04-28 08:24:15 link "Eine ~ http~ 6 46 145 129 14 2 0 0
## 6 6 http~ CDU 2019-04-28 09:12:19 video "Freih~ http~ 239 136 398 292 8 0 58 2
## 7 7 http~ SPD 2019-04-28 13:06:09 photo "Katar~ http~ 180 54 699 576 34 4 79 1
## 8 8 http~ Pira~ 2019-04-28 17:36:30 video "Unser~ http~ 0 NA 7 6 0 1 0 0
## 9 9 http~ DieP~ 2019-04-28 07:44:28 link "Der a~ http~ 35 76 612 509 49 0 54 0
## 10 10 http~ CSU 2019-04-28 08:21:00 photo "#Klar~ http~ 174 61 458 334 3 5 90 2
## # ... with 892 more rows, and 23 more variables: angry_count <dbl>, topic100 <dbl>, topic200 <dbl>, topic310 <dbl>, topic320 <dbl>, topic331 <dbl>,
## # topic332 <dbl>, topic330 <dbl>, topic341 <dbl>, topic342 <dbl>, topic343 <dbl>, topic340 <dbl>, topic350 <dbl>, topic360 <dbl>, topic370 <dbl>,
## # topic380 <dbl>, topic391 <dbl>, topic392 <dbl>, topic390 <dbl>, topic400 <dbl>, topic300 <dbl>, topic998 <dbl>, topic999 <dbl>Wir sehen, dass der neue Datensätze weiterhin 902 Zeilen hat, aber nun alle 38 Variablen aus beiden Datensätzen umfasst. Zur Sicherheit sollten wir überprüfen, ob doppelte Werte in der id-Variablen vorkommen, um auszuschließen, dass Fälle bei der Join-Operation verdoppelt wurden. Dafür können wir die distinct()-Funktion nutzen, die nur einzigartige Werte der angegebenen Variablen ausgibt:
## # A tibble: 902 x 1
## id
## <dbl>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 10
## # ... with 892 more rows902 einzigartige Werte in id – es wurden also keine Fälle verdoppelt oder sind weggefallen.
Kapitel 11: Daten visualisieren
Für alle Aufgaben benötigen wir das Tidyverse und den Datensatz facebook_europawahl.csv. Zudem filtern wir in diesem nur die im Bundestag vertretenen Parteien an:
library(tidyverse)
bt_parteien <- c("alternativefuerde", "B90DieGruenen", "CDU", "CSU", "FDP", "linkspartei", "SPD")
facebook_europawahl <- read_csv("data/facebook_europawahl.csv") %>%
filter(party %in% bt_parteien)Lösung zur Übungsaufgabe 11.1:
Als Aesthetics weisen wir die Kommentarzahl (comments_count) der x-Achse, die Anzahl an Shares (shares_count) der y-Achse zu (oder andersum). Für Punktediagramme benötigen wie das Geometric geom_point():
## Warning: Removed 5 rows containing missing values (geom_point).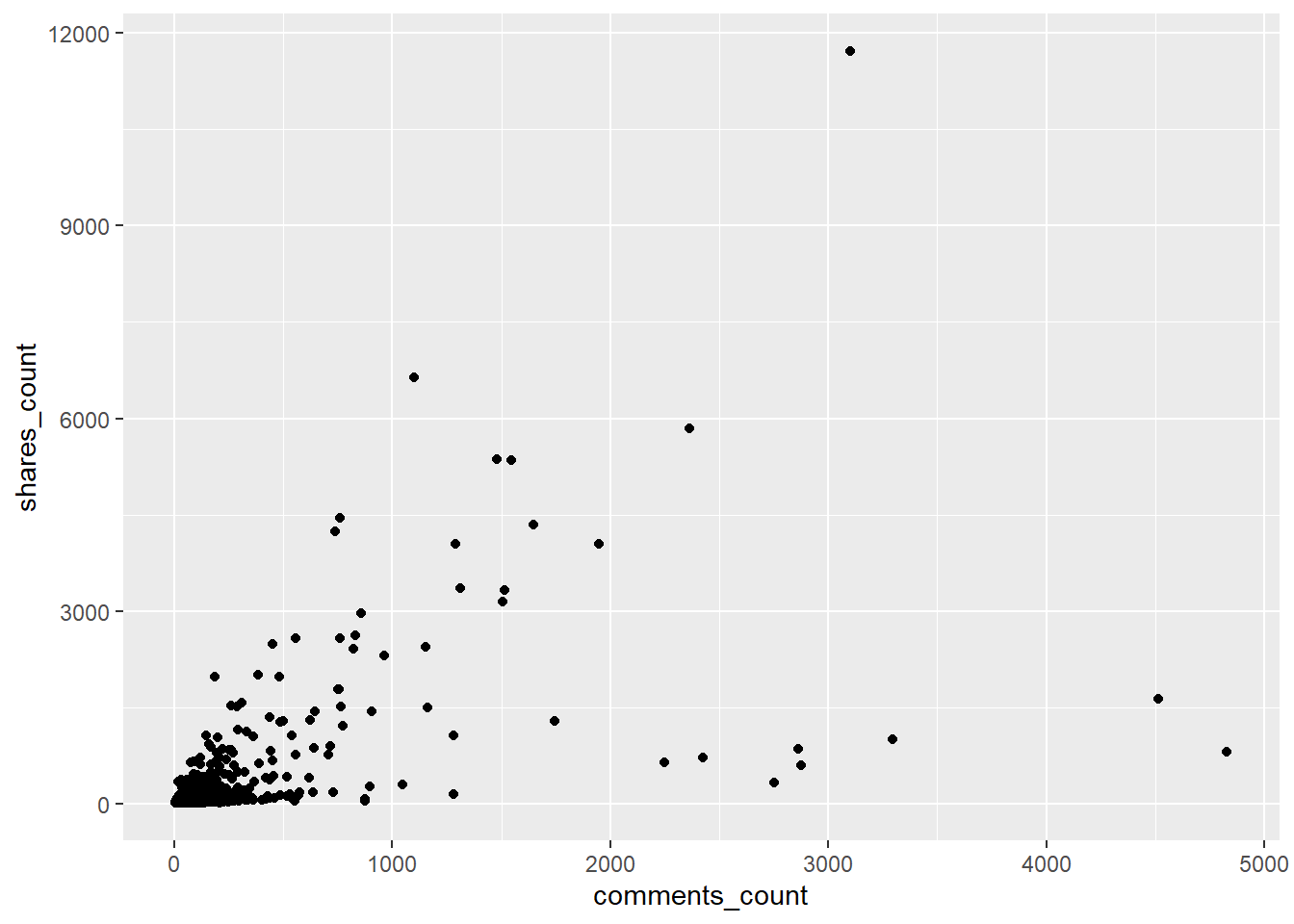
An der Warnmeldung sehen wir im Übrigen, dass 5 Posts nicht abgebildet werden – hierbei handelt es sich um NA-Werte.
Lösung zur Übungsaufgabe 11.2:
Eine Möglichkeit, sowohl Partei (party) als auch Typ des Posts (type) eine Aesthetic zuzuweisen – z. B. color (Punkt- bzw. Linienfarbe) für die Partei, shape (Punktform) für die den Typ des Beitrags:
facebook_europawahl %>%
ggplot(aes(x = comments_count, y = shares_count, color = party, shape = type)) +
geom_point()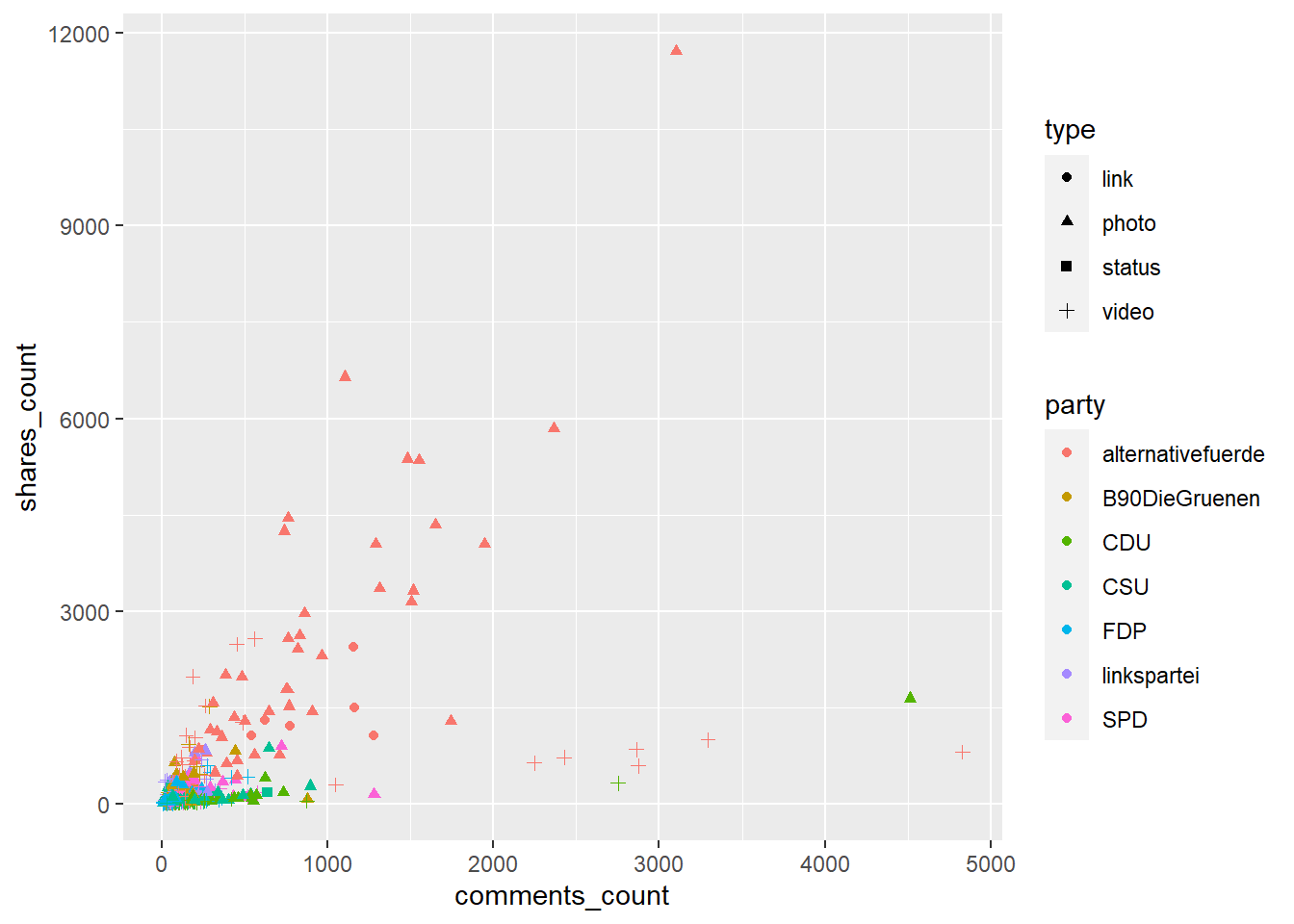
Eine andere Möglichkeit besteht darin, zusätzlich mit Facets zu arbeiten:
facebook_europawahl %>%
ggplot(aes(x = comments_count, y = shares_count, color = party)) +
geom_point() +
facet_wrap(~type)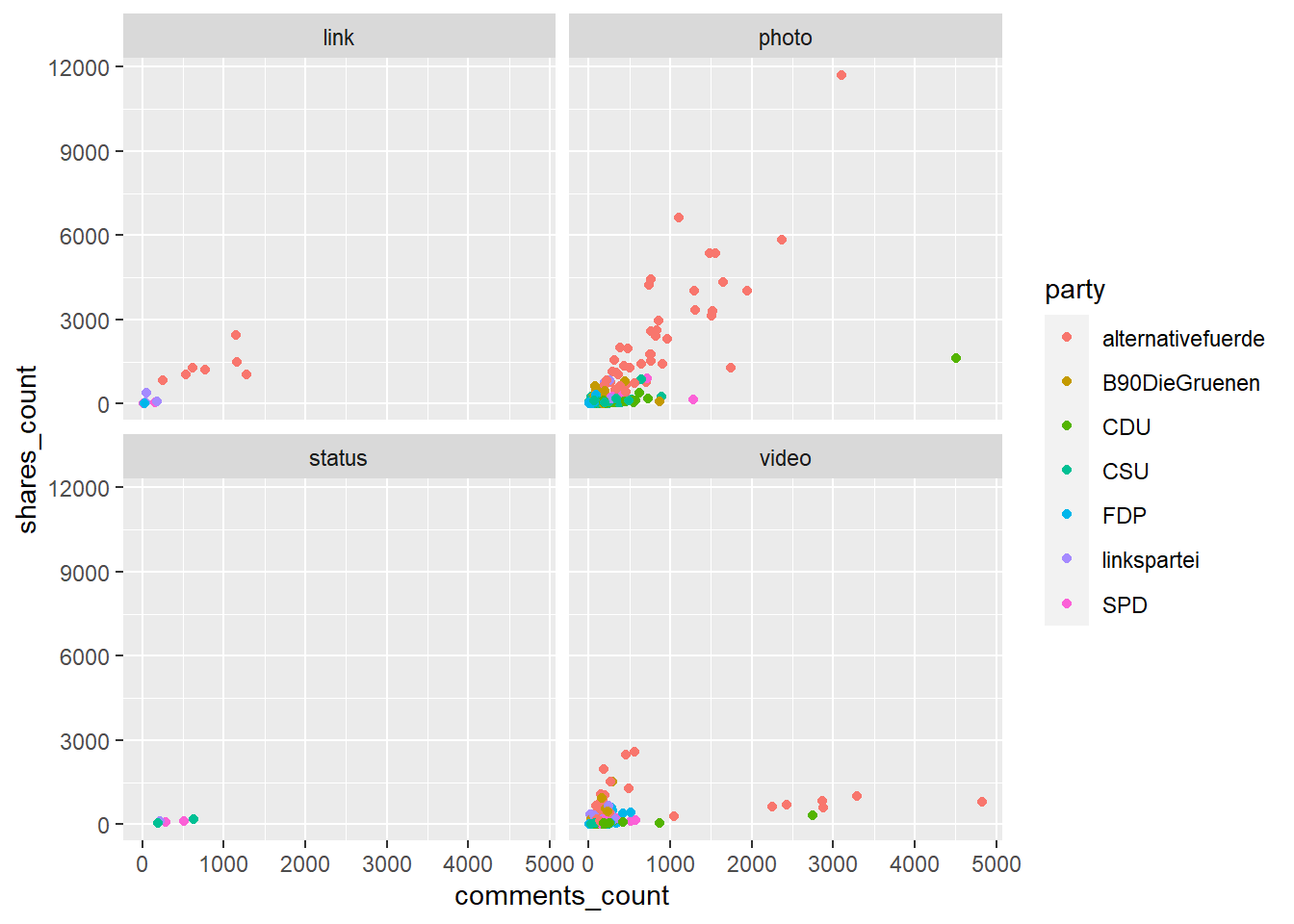
Lösung zur Übungsaufgabe 11.3:
Einige Möglichkeiten zur Verbesserung und Verschönerung des Plots:
- Verwendung eines Themes
- Achsen-/Skalenbeschriftungen
- Verwendung der tatsächlichen Parteifarben
- Gleiche Skalierung von x- und y-Achse (da gleiche zugrundeliegende Einheit); der bisher noch unbekannte Befehl
coord_fixed()sorgt dafür, dass Einheiten auf der x- und y-Achse gleich dargestellt werden:
facebook_europawahl %>%
ggplot(aes(x = comments_count, y = shares_count, color = party, shape = type)) +
geom_point() +
scale_y_log10(name = "Anzahl der Shares", ) +
scale_x_log10(name = "Anzahl der Kommentare",) +
scale_color_manual(name = "Partei",
values = c("CDU" = "#000000",
"CSU" = "#6E6E6E",
"SPD" = "#FE2E2E",
"alternativefuerde" = "#81BEF7",
"FDP" = "#FFFF00",
"linkspartei" = "#DF01A5",
"B90DieGruenen" = "#01DF01"),
labels = c("alternativefuerde" = "AfD",
"linkspartei" = "Linke",
"B90DieGruenen" = "Grüne")) +
scale_shape_discrete(name = "Art des Beitrags") +
theme_bw() +
coord_fixed()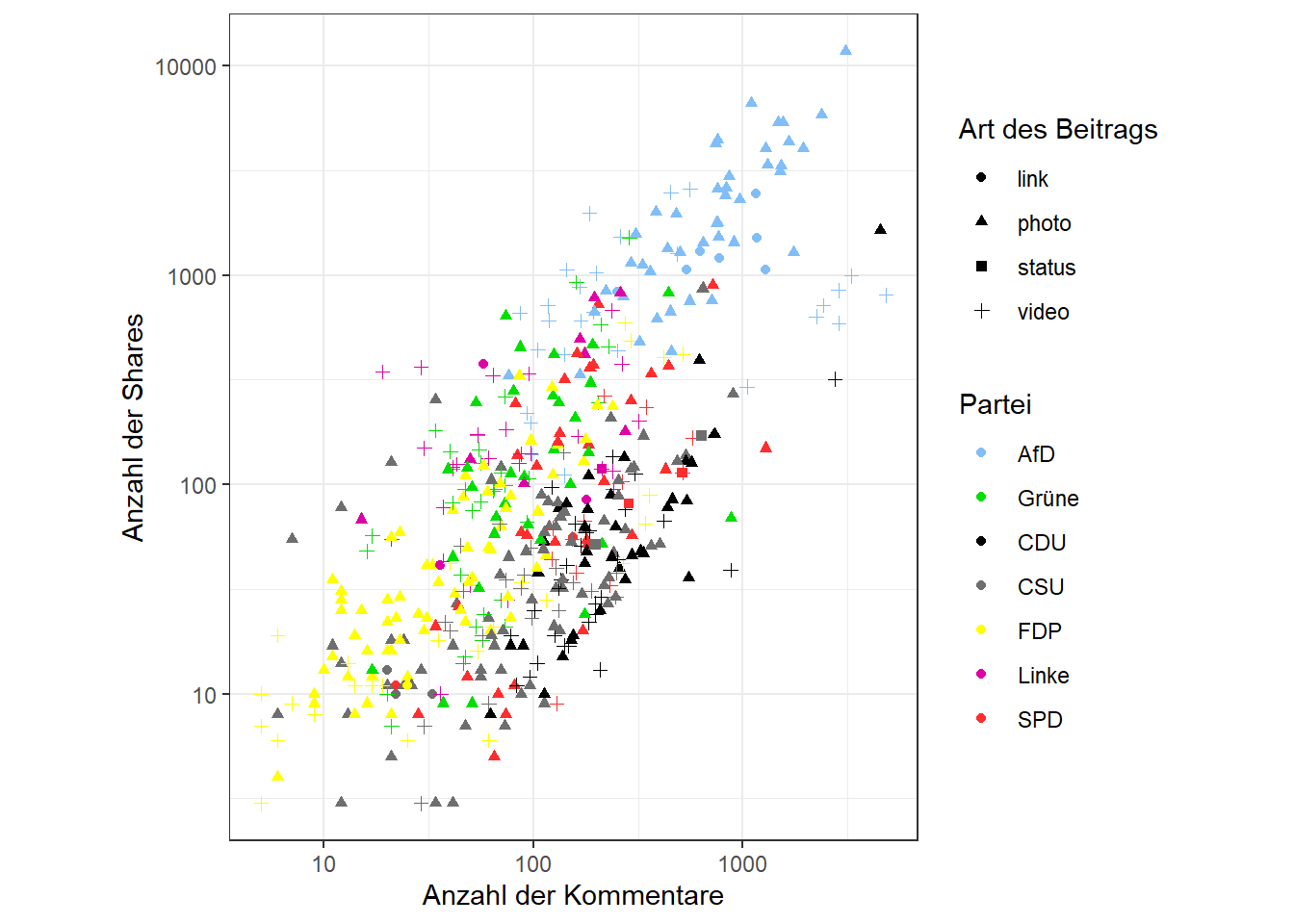
Kapitel 12: Arbeiten mit Textdaten
Lösung zur Übungsaufgabe 12.1:
Ziel war es, lediglich die Gruppenkennung in einer neuen Spalte hinzuzufügen. Dafür gibt es viele verschiedene Möglichkeiten, z. B.:
str_sub(): Lediglich das letzte Zeichen als Substring auswählen
## # A tibble: 4 x 2
## experimentalgruppe gruppe_kurz
## <chr> <chr>
## 1 Gruppe A A
## 2 Gruppe B B
## 3 Gruppe A A
## 4 Gruppe C Cstr_replace():"Gruppe "durch einen leeren String""ersetzen:
## # A tibble: 4 x 2
## experimentalgruppe gruppe_kurz
## <chr> <chr>
## 1 Gruppe A A
## 2 Gruppe B B
## 3 Gruppe A A
## 4 Gruppe C CLösung zur Übungsaufgabe 12.2:
imdb_urls <- c(
"https://www.imdb.com/title/tt6751668/?ref_=hm_fanfav_tt_4_pd_fp1",
"https://www.imdb.com/title/tt0260991/",
"www.imdb.com/title/tt7282468/reviews",
"https://m.imdb.com/title/tt4768776/"
)Zur Extraktion der IDs bietet sich str_extract() an mit RegEx an. Mit dem RegEx-String "tt\\d{7}" matchen wir jegliche IMDb-ID, die immer dem Schema "tt", gefolgt von 7 Ziffern folgen:
## [1] "tt6751668" "tt0260991" "tt7282468" "tt4768776"Lösung zur Übungsaufgabe 12.3:
adressen = c(
"Platz der Republik 1, D-11011 Berlin",
"Dr.-Karl-Renner-Ring 3, A-1017 Wien",
"Bundesplatz 3, CH-3005 Bern"
)Sinnvoll ist es, nach und nach die einzelnen Adress-Bestandteile auszuwählen.
- Der Straßenname ist dabei der komplizierteste Part, da er aus Groß- und Kleinbuchstaben, Bindestrichen, Leerzeichen und Punkten bestehen kann. Eine Möglichkeit ist es daher, all diese Zeichen als eigene Übereinstimmungsgruppe zu definieren:
[A-Za-z-\\s\\.]+. Da keine Ziffern im Straßennamen vorkommen, können wir das jedoch abkürzen, indem wir für den Straßennamen alles matchen, was keine Ziffer ist:\\D+. Durch Klammern können wir angegeben, dass dies der erste Bestandteil der Adresse ist, den wir extrahieren möchten:"(\\D+)". - Es folgt (in diesem Beispiel) stets Whitespace und die Hausnummer, was wir mit
\\s\\d+matchen können. Da wir das Leerzeichen nicht extrahieren möchten, ziehen wir die nächsten Klammern lediglich um das\\d+:"(\\D+)\\s(\\d+)". - Es folgen nun ein Komma, Whitespace und ein oder zwei Großbuchstaben für den Ländercode; letztere können wir beispielsweise mit
[A-Z]{1,2}matchen. Erneut wollen wir nur die 1-2 Großbuchstaben extrahieren:"(\\D+)\\s(\\d+),\\s([A-Z]{1,2})". - Nun kommt ein Bindestrich und die 4-5-stellige Postleitzahl:
"(\\D+)\\s(\\d+),\\s([A-Z]{1,2})-(\\d{4,5})". - Schließlich folgt noch ein Whitespace und die Stadt, die wir z. B. schnell mittels
\\D+(alles außer Ziffern) matchen können:"(\\D+)\\s(\\d+),\\s([A-Z]{1,2})-(\\d{4,5})\\s(\\D+)"
Diesen String können wir nun str_match() übergeben:
adr_string <- "(\\D+)\\s(\\d+),\\s([A-Z]{1,2})-(\\d{4,5})\\s(\\D+)"
adressen %>%
str_match(adr_string)## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] "Platz der Republik 1, D-11011 Berlin" "Platz der Republik" "1" "D" "11011" "Berlin"
## [2,] "Dr.-Karl-Renner-Ring 3, A-1017 Wien" "Dr.-Karl-Renner-Ring" "3" "A" "1017" "Wien"
## [3,] "Bundesplatz 3, CH-3005 Bern" "Bundesplatz" "3" "CH" "3005" "Bern"Als Resultat erhalten wir eine Matrix, in der in der ersten Spalten der komplette gematchte String sowie in den folgenden Spalten die einzelnen gematchten Bestandteile, definiert durch runde Klammern () stehen.
Kapitel 15: Web Scraping
Für die Lösungen wird das Package polite in Kombination mit rvest verwendet. Die Extraktion der HTML-Elemente unterscheidet sich jedoch nicht, wenn nur rvest verwendet wird.
Lösung zur Übungsaufgabe 15.1:
Wir besuchen zunächst den Artikel und finden über SelectorGadget oder die Untersuchen-Funktion heraus, dass
- der Artikel in der CSS-Klasse
.sz-articlesteht - die gesuchten Inhalte in den CSS-Klassen
.css-11lvjqt(Datum und Uhrzeit),.css-1keap3i(Kicker),.css-1kuo4az(Überschrift) und.css-1psf6fc(Lead) stehen.
Nun stellen wir uns mit bow() dem Server vor (wenn nur rvest genutzt wird, wird dieser Schritt übersprungen):
Und scrapen die Seite (analog zu read_html() in rvest):
Nun extrahieren wir die gewünschten Elemente:
html_content %>%
html_nodes(".css-11lvjqt, .css-1keap3i, .css-1kuo4az, .css-1psf6fc") %>%
html_text() %>%
str_squish()## [1] "9. Juni 2020, 9:20 Uhr"
## [2] "HSV in der zweiten Liga"
## [3] "\"Das sind Dinge, die sehr, sehr weh tun\""
## [4] "So wird es eng mit dem Aufstieg: In einer wilden Schlussphase kassiert der Hamburger SV gegen Holstein Kiel den Ausgleich in der 93. Minute - die Partie endet 3:3. Trainer Hecking wirkt ratlos."Lösung zur Übungsaufgabe 15.2:
Ein Problem ist hier, dass viele Links auf der Seite stehen, wir aber nur einen abgreifen möchten. Dies können wir erreichen, indem wir zunächst lediglich den Artikel selbst über die Klasse .sz-article auswählen, dann nur die Textabsätze mit dem HTML-Tag p und schließlich Links mit dem HTML-Tag a:
html_content %>%
html_nodes(".sz-article") %>%
html_nodes("p") %>%
html_nodes("a") %>%
html_attr("href")## character(0)Lösung zur Übungsaufgabe 15.3:
Wir wandeln den obigen Code in eine Funktion um:
scrape_sz <- function(url) {
# Vorstellen
sz <- bow(url)
# Scrapen
html_content <- scrape(sz)
# Interessierende HTML-Elemente extrahieren
info <- html_content %>%
html_nodes(".css-11lvjqt, .css-1keap3i, .css-1kuo4az, .css-1psf6fc") %>%
html_text() %>%
str_squish()
# In Tibble umwandeln
info_tibble <- tibble(
release = info[1],
kicker = info[2],
headline = info[3],
lead = info[4]
)
# Tibble zurückgeben
return(info_tibble)
}Und testen dies am zweiten Artikel:
## # A tibble: 1 x 4
## release kicker headline lead
## <chr> <chr> <chr> <chr>
## 1 28. Mai 2020, 22~ 2. Bundesl~ Castro schockt den HSV in de~ Der VfB Stuttgart liegt gegen den HSV nach 45 Minuten schon mit 0:2 zurück - doch dann kommen die~Kapitel 17: Automatisierte Inhaltsanalyse: Einführung und Grundbegriffe
Für alle Aufgaben benötigen wir Quanteda und müssen den Facebook-Datensatz wie gewohnt filtern:
library(tidyverse)
library(quanteda)
bt_parteien <- c("alternativefuerde", "B90DieGruenen", "CDU", "CSU", "FDP", "linkspartei", "SPD")
facebook_europawahl <- read_csv("data/facebook_europawahl.csv") %>%
filter(party %in% bt_parteien)Lösung zur Übungsaufgabe 17.1:
Wir erstellen das Korpus-Objekt mit der corpus()-Funktion.
## Warning: NA is replaced by empty stringLösung zur Übungsaufgabe 17.2:
Die einzelnen Schritte zur Tokenisierung können wir in eine Pipe packen:
fb_tokens <- tokens(fb_corpus, # Erzeuge Tokens
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove_url = TRUE) %>%
tokens_tolower() %>% # Kleinschreibung
tokens_remove(stopwords("german")) %>% # Deutsche Stoppwörter entfernen
tokens_ngrams(n = c(1, 2, 3)) # Erzeuge Uni-, Bi- und TrigrammeLösung zur Übungsaufgabe 17.3:
Zunächst erstellen wir die DFM:
Die Top-Features pro Partei:
## $alternativefuerde
## afd unseren dass deutschland finden europawahl kandidaten mai mehr schon
## 85 53 48 37 37 33 32 31 30 30
##
## $B90DieGruenen
## europa wählen mai grün gruene.de teile innen klimaschutz heute freund
## 24 23 18 18 17 17 16 14 14 14
##
## $CDU
## #unsereuropa #26maicdu europa cdu heute
## 46 38 23 21 17
## <U+0001F1EA><U+0001F1FA> annegret kramp-karrenbauer annegret_kramp-karrenbauer sicherheit
## 16 16 16 16 14
##
## $CSU
## manfred weber manfred_weber europa europawahl markus söder markus_söder bayern heute
## 41 41 41 35 33 24 20 20 20 19
##
## $FDP
## #chancennutzen europa <U+0001F1EA><U+0001F1FA> #ep2019
## 75 59 52 51
## #chancennutzen_#ep2019 #europawahl2019 #ep2019_#europawahl2019 #chancennutzen_#ep2019_#europawahl2019
## 48 36 32 32
## dass europa_<U+0001F1EA><U+0001F1FA>
## 24 22
##
## $linkspartei
## europa heute martin schirdewan martin_schirdewan menschen bernd riexinger
## 19 11 8 8 8 7 7 7
## bernd_riexinger özlem
## 7 7
##
## $SPD
## europa #europaistdieantwort mehr katarina soziales barley katarina_barley
## 33 24 15 13 13 12 12
## dafür soziales_europa geht
## 11 10 9Das sich darunter fast keine Trigramme (außer eine Hashtag-Kominbation bei der FDP) befinden, ziehen wir daraus vorerst keinen Mehrwert. Die Zeichenkette \U0001f1ea\U0001f1fa verweist auf Fehler bei der Bereinigung der Texte – hierbei handelt es sich um den Code für das Europaflaggen-Emoji, der eigentlich durch remove_symbols = TRUE hätte entfernt werden sollen. Auch einige URL-Bestandteile wurden nicht korrekt entfernt, ebenso gibt es ein paar falsche Worttrennungen, z. B. wenn ein Gendersternchen enthalten war. Hier sollte also manuell nachgebessert werden.
Um die Hashtags zu analysieren, erstellen wir eine DFM, die nur diese enthält:
Wir können uns nun wieder mittels topfeatures() die häufigsten Hashtags ausgeben lassen:
## #chancennutzen #ep2019 #chancennutzen_#ep2019 #unsereuropa
## 75 51 48 47
## #26maicdu #europawahl2019 #ep2019_#europawahl2019 #chancennutzen_#ep2019_#europawahl2019
## 38 37 32 32
## #europaistdieantwort #europa
## 24 23## $alternativefuerde
## #greding #greding_bayern #greding_bayern_heute #grundrechte
## 1 1 1 0
## #chancennutzen #bpt19 #chancennutzen_#bpt19 #unsereuropa
## 0 0 0 0
## #unsereuropa_steht #unsereuropa_steht_freiheitliche
## 0 0
##
## $B90DieGruenen
## #europawahl #europa #klimaschutz #zusammenhalt
## 11 10 3 3
## #europawahl_mai #europa_einzigartiges #europa_einzigartiges_friedensprojekt #klimaschutz_#zusammenhalt
## 3 3 3 2
## #briefwahl #europawahl_teile
## 2 1
##
## $CDU
## #unsereuropa #26maicdu #unsereuropa_#26maicdu #unsereuropa_<U+0001F1EA><U+0001F1FA> #unsereuropa_<U+0001F1EA><U+0001F1FA>_#26maicdu #europa
## 46 38 11 10 8 7
## #thepowerofwe #cdu #26maicdu_#unsereuropa #frieden
## 6 5 4 3
##
## $CSU
## #klartext #klartext_unseres #klartext_unseres_spitzenkandidaten #klartext_bayerns
## 16 8 8 6
## #klartext_bayerns_ministerpräsident #csutvtipp #wahlarena #miasanbayern
## 6 4 4 3
## #unsereuropa #tvduell
## 1 1
##
## $FDP
## #chancennutzen #ep2019 #chancennutzen_#ep2019 #europawahl2019
## 75 51 48 36
## #ep2019_#europawahl2019 #chancennutzen_#ep2019_#europawahl2019 #live #bpt19
## 32 32 6 4
## #reneweurope #teameurope
## 4 3
##
## $linkspartei
## #1europafueralle #grundrechte #chancennutzen #bpt19
## 1 0 0 0
## #chancennutzen_#bpt19 #unsereuropa #unsereuropa_steht #unsereuropa_steht_freiheitliche
## 0 0 0 0
## #ep2019 #europawahl2019
## 0 0
##
## $SPD
## #europaistdieantwort #europa #grundgesetz #sozialklimbim #europa_<U+0001F1EA><U+0001F1FA> #rezo
## 24 6 3 2 2 2
## #evp #evp_sagen #europa_europa #europaistdieantwort_mehr
## 1 1 1 1Kapitel 18: Textdeskription und einfache Textvergleiche
Auch hier benötigen wir Quanteda und müssen den Facebook-Datensatz wie gewohnt filtern. Zudem laden wir auch Tidytext:
library(tidyverse)
library(tidytext)
library(quanteda)
bt_parteien <- c("alternativefuerde", "B90DieGruenen", "CDU", "CSU", "FDP", "linkspartei", "SPD")
facebook_europawahl <- read_csv("data/facebook_europawahl.csv") %>%
filter(party %in% bt_parteien)Lösung zur Übungsaufgabe 18.1:
Wir erzeugen zunächst wie gehabt Korpus-, Tokens- und DFM-Objekte:
## Warning: NA is replaced by empty stringfb_tokens <- tokens(fb_corpus,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove_url = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("german"))
fb_dfm <- dfm(fb_tokens)Zunächst ein Blick auf die einfachen Worthäufigkeiten:
## # A tibble: 6,896 x 2
## names x
## <chr> <dbl>
## 1 "europa" 208
## 2 "dass" 101
## 3 "europawahl" 96
## 4 "mehr" 92
## 5 "heute" 92
## 6 "afd" 90
## 7 "\U0001f1ea\U0001f1fa" 87
## 8 "wählen" 79
## 9 "#chancennutzen" 75
## 10 "unseren" 72
## # ... with 6,886 more rowsWenig überraschend fallen Begriffe wie “Europa”, “Deutschland” und “Europawahl” sehr häufig. Es zeigen sich aber auch bereits ein paar Probleme, die wir bereits von der vorherigen Übung kennen, z. B. dass Stoppwörter wie “dass” weiterhin im Datensatz verbleiben. Auch das Europaflaggen-Emoji wird offenbar sehr häufig verwendet.
Wir können uns die wichtigsten Begriffe auch als Wordcloud anzeigen lassen:

Kollokationen verweisen vor allem auf die Namen der Kandidat*innen sowie beliebte Hashtag-Kombinationen:
## # A tibble: 1,007 x 6
## collocation count count_nested length lambda z
## <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 "manfred weber" 55 0 2 13.2 8.68
## 2 "#chancennutzen #ep2019" 48 0 2 9.60 15.8
## 3 "#ep2019 #europawahl2019" 32 0 2 9.47 16.1
## 4 "unseren kandidaten" 30 0 2 8.13 13.9
## 5 "europa \U0001f1ea\U0001f1fa" 27 0 2 3.77 15.5
## 6 "finden infos" 27 0 2 8.97 14.5
## 7 "infos europawahl" 26 0 2 7.54 13.0
## 8 "europawahl unseren" 24 0 2 4.75 17.3
## 9 "markus söder" 23 0 2 10.8 11.4
## 10 "europawahl manfred" 17 0 2 4.58 14.7
## # ... with 997 more rowsKookkurenzen zeigen, dass wohl vor allem die AfD thematisiert wurde (ob durch sich selbst oder andere Parteien, ergeht hieraus nicht). Auch hier sehen wir, dass noch URL-Bestandteile ("https") im Datensatz verbleiben; diese sollten also noch manuell gefiltert werden.
## # A tibble: 472,434 x 3
## document term count
## <chr> <chr> <dbl>
## 1 "afd" afd 109
## 2 "europa" europa 96
## 3 "afd" unseren 85
## 4 "\U0001f1ea\U0001f1fa" europa 70
## 5 "unseren" kandidaten 60
## 6 "afd" finden 59
## 7 "afd" europawahl 59
## 8 "#chancennutzen" europa 58
## 9 "ab" afd 58
## 10 "manfred" weber 58
## # ... with 472,424 more rowsFür Keyness-Analysen benötigen wir zunächst eine nach Parteien gruppierte DFM:
Wir können uns nun die Keywords je Partei ausgeben lassen – im Beispiel für SPD und Grüne:
## # A tibble: 6,896 x 5
## feature chi2 p n_target n_reference
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 #europaistdieantwort 385. 0. 24 0
## 2 katarina 171. 0. 13 2
## 3 barley 143. 0. 12 3
## 4 soziales 130. 0. 13 6
## 5 bullmann 100. 0. 7 0
## 6 udo 100. 0. 7 0
## 7 andrea 83.7 0. 6 0
## 8 nahles 70.2 0. 6 1
## 9 sozialen 53.3 2.90e-13 7 5
## 10 europa 41.6 1.15e-10 33 175
## # ... with 6,886 more rows## # A tibble: 6,896 x 5
## feature chi2 p n_target n_reference
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 grün 219. 0 18 0
## 2 gruene.de 206. 0 17 0
## 3 freund 167. 0 14 0
## 4 innen 158. 0 16 3
## 5 zusammenhalt 154. 0 14 1
## 6 teile 152. 0 17 5
## 7 ska 116. 0 10 0
## 8 #europawahl 88.8 0 11 4
## 9 robert 81.0 0 9 2
## 10 habeck 78.3 0 8 1
## # ... with 6,886 more rowsNeben wenigen inhaltlichen Begriffe ("soziales", "zusammenhalt") werden die Listen dominiert durch Eigennamen; um tatsächliche inhaltliche Keywords zu bestimmen, würde es sich daher lohnen, Namen von Kandidat*innen, Parteien etc. aus der DFM zu löschen.
Kapitel 19: Diktionärbasierte Ansätze
Erneut hier benötigen wir Quanteda und müssen den Facebook-Datensatz wie gewohnt filtern. Zudem laden wir auch Tidytext:
library(tidyverse)
library(tidytext)
library(quanteda)
bt_parteien <- c("alternativefuerde", "B90DieGruenen", "CDU", "CSU", "FDP", "linkspartei", "SPD")
facebook_europawahl <- read_csv("data/facebook_europawahl.csv") %>%
filter(party %in% bt_parteien)Wir laden außerdem, wie in der Aufgabenstellung angegeben, die Dictionaries:
sentiws_pos <- read_delim("data/SentiWS_v2.0_Positive.txt", col_names = c("word", "value", "flections"), delim = "\t") %>%
mutate(sentiment = "positive")
sentiws_neg <- read_delim("data/SentiWS_v2.0_Negative.txt", col_names = c("word", "value", "flections"), delim = "\t") %>%
mutate(sentiment = "negative")
sentiws <- sentiws_pos %>%
bind_rows(sentiws_neg) %>%
separate(word, c("word", "type"), sep = "\\|") %>%
mutate(word = str_c(word, flections, sep = ",")) %>%
select(-flections, -type) %>%
separate_rows(word, sep = ",") %>%
na.omit()Außerdem erzeugen wir einen Korpus der Facebook-Posts:
## Warning: NA is replaced by empty stringLösung zur Übungsaufgabe 19.1:
Wir extrahieren zunächst die positiven und negativen Begriffe als Vektoren mittels filter() und pull():
senti_pos <- sentiws %>%
filter(sentiment == "positive") %>%
pull(word, sentiment)
senti_neg <- sentiws %>%
filter(sentiment == "negative") %>%
pull(word, sentiment)Mit beiden Vektoren können wir nun ein Quanteda-Dictionary mittels dictionary() erstellen. dictionary() konvertiert automatisch in Kleinschreibung – soll dies nicht geschehen, kann das mit dem Argument tolower = FALSE angepasst werden. Für unsere Zwecke ist eine Konvertierung in Kleinschreibung aber sinnvoll, da wir auch für die DFM in der Regel alle Wörter in Kleinschreibung umwandeln.
sentiment_dictionary <- dictionary(list(
positiv = senti_pos,
negativ = senti_neg
))
sentiment_dictionary## Dictionary object with 2 key entries.
## - [positiv]:
## - abmachung, abmachungen, abschluß, abschluss, abschlusse, abschlusses, abschlüsse, abschlüssen, abstimmung, abstimmungen, aktivität, aktivitäten, aktualisierung, aktualisierungen, aktualität, aktualitäten, akzeptanz, akzeptanzen, andrang, andrangs [ ... and 16,311 more ]
## - [negativ]:
## - abbau, abbaus, abbaues, abbauen, abbaue, abbauten, abbruch, abbruches, abbrüche, abbruchs, abbrüchen, abbruche, abdankung, abdankungen, abdämpfung, abdämpfungen, abfall, abfalles, abfälle, abfalls [ ... and 17,846 more ]Um die absoluten Häufigkeiten auszuzählen, genügt der dfm()-Befehl mit Angabe unseres Dictionaries und einer Gruppierung nach party:
## Document-feature matrix of: 7 documents, 2 features (0.0% sparse) and 1 docvar.
## features
## docs positiv negativ
## alternativefuerde 637 467
## B90DieGruenen 119 26
## CDU 224 28
## CSU 197 47
## FDP 444 90
## linkspartei 88 42
## [ reached max_ndoc ... 1 more document ]Das Verhältnis von positivem zu negativem Sentiment erhalten wir durch anschließende Gewichtung mit dfm_weight():
## Document-feature matrix of: 7 documents, 2 features (0.0% sparse) and 1 docvar.
## features
## docs positiv negativ
## alternativefuerde 0.5769928 0.4230072
## B90DieGruenen 0.8206897 0.1793103
## CDU 0.8888889 0.1111111
## CSU 0.8073770 0.1926230
## FDP 0.8314607 0.1685393
## linkspartei 0.6769231 0.3230769
## [ reached max_ndoc ... 1 more document ]Die AfD verzeichnet also den größten Anteil negativen Sentiments, gefolgt von der Linkspartei. Alle anderen Parteien kommunizieren sehr positiv.
Interessieren wir uns für den Anteil, den positive und negative Begriffe am Gesamt-Wortschatz der Parteien-Posts ausmachen, gewichten wir die DFM vor der Anwendung des Dictionaries:
dfm(fb_corpus, groups = "party") %>%
dfm_weight(scheme = "prop") %>%
dfm(dictionary = sentiment_dictionary)## Document-feature matrix of: 7 documents, 2 features (0.0% sparse) and 1 docvar.
## features
## docs positiv negativ
## alternativefuerde 0.03748571 0.02828571
## B90DieGruenen 0.04621212 0.01060606
## CDU 0.08509848 0.01412114
## CSU 0.06289111 0.01752190
## FDP 0.07307567 0.01607665
## linkspartei 0.04972973 0.02540541
## [ reached max_ndoc ... 1 more document ]Lösung zur Übungsaufgabe 19.2:
Um den SentiWS als gewichtetes Lexikon zu nutzen und die Polaritätswerte zu berücksichtigen, benutzen wir Tidytext. Zunächst Tokenisieren wir unseren Datensatz. Auch dabei wird direkt in Kleinschreibung konvertiert:
tidy_facebook <- facebook_europawahl %>%
unnest_tokens(word, message) %>%
select(id, party, word)
tidy_facebook## # A tibble: 32,031 x 3
## id party word
## <dbl> <chr> <chr>
## 1 3 B90DieGruenen beim
## 2 3 B90DieGruenen wahlkampf
## 3 3 B90DieGruenen camp
## 4 3 B90DieGruenen in
## 5 3 B90DieGruenen berlin
## 6 3 B90DieGruenen waren
## 7 3 B90DieGruenen gestern
## 8 3 B90DieGruenen hunderte
## 9 3 B90DieGruenen freiwillige
## 10 3 B90DieGruenen die
## # ... with 32,021 more rowsPer inner_join() können wir nun die Sentimentwerte anfügen:
## Joining, by = "word"## # A tibble: 1,969 x 5
## id party word value sentiment
## <dbl> <chr> <chr> <dbl> <chr>
## 1 3 B90DieGruenen freiwillige 0.004 positive
## 2 3 B90DieGruenen mobilisieren 0.004 positive
## 3 3 B90DieGruenen freiwilligen 0.004 positive
## 4 3 B90DieGruenen freiwillige 0.004 positive
## 5 3 B90DieGruenen gewinnen 0.004 positive
## 6 4 FDP neuer 0.004 positive
## 7 6 CDU gute 0.372 positive
## 8 7 SPD gut 0.372 positive
## 9 7 SPD zusammenhält 0.0834 positive
## 10 10 CSU langsam -0.0167 negative
## # ... with 1,959 more rowsSchließlich gruppieren wir per group_by() nach party und berechnen den Mittelwert des Sentiments:
## # A tibble: 7 x 2
## party mean_sentiment
## <chr> <dbl>
## 1 alternativefuerde -0.0277
## 2 B90DieGruenen 0.0530
## 3 CDU 0.0643
## 4 CSU 0.0125
## 5 FDP 0.0341
## 6 linkspartei 0.0425
## 7 SPD 0.0925Auch hier weist die AfD das negativste Sentiment auf. Allerdings erscheint die Kommunikation der Linkspartei auf diesem Wege deulich positiver als zuvor.
Kapitel 21: Topic Modeling
Wie in der Aufgabenstellung geschrieben, laden wir die Daten dieses Mal aus dem quanteda.corpora-Package. Wir laden außerdem die bereits bekannten Packages zum tidyverse zum Datenhandling, quanteda zur Vorbereitung der Textdaten, sowie stm für das Topic Modeling.
library(tidyverse)
library(stm)
library(quanteda)
guardian_corpus <- quanteda.corpora::download("data_corpus_guardian")
guardian_corpusLösung zur Übungsaufgabe 21.1:
Die Preprocessing-Schritte führen wir wie gehabt mit Quanteda durch. Wir erzeugen zunächst eine DFM mit dfm() und können dabei irrelevante Token wie Satzzeichen, Zahlen, Symbole und Stoppwörter entfernen. Um die Berechnung zu erleichtern, trimmen wir die DFM zusätzlich um besonders seltene und häufige Wörter mit dfm_trim() (ich habe mich hier für alle Wörter die in mehr als 50% der Artikel sowie in weniger als 2% der Artikel vorkommen entschieden). Schließlich muss die DFM noch mit convert() in ein Format konvertiert werden, das das stm-Package erwartet.
# DFM Erzeugen
guardian_dfm <- dfm(guardian_corpus,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove_url = TRUE,
remove = stopwords("english"))
# Trimmen
trimmed_dfm <- dfm_trim(guardian_dfm,
min_docfreq = 0.02,
max_docfreq = 0.50,
docfreq_type = "prop")
# Konvertieren
stm_dfm <- convert(trimmed_dfm, to = "stm")Nun berechnen wir das Modell mit K = 20 Themen. Da die Berechnung eine Zeit dauern kann, ist es sinnvoll, das Modellobjekt im Anschluss abzuspeichern.
guardian_model <- stm(stm_dfm$documents, stm_dfm$vocab, K = 20)
saveRDS(guardian_model, "data/stm_guardian_model.rds")Anschließend können wir uns eine Übersicht der wichtigsten Wörter je Thema mittels labelTopics() ausgeben lassen:
## Topic 1 Top Words:
## Highest Prob: year, game, friday, music, team, best, christmas
## FREX: music, game, christmas, stores, football, tv, store
## Lift: sorry, music, football, players, game, christmas, stores
## Score: sorry, game, stores, music, store, players, retailers
## Topic 2 Top Words:
## Highest Prob: party, labour, vote, election, leader, mps, cameron
## FREX: corbyn, labour, mps, party, tory, mp, conservative
## Lift: corbyn, electorate, ukip, tory, tories, miliband, lib
## Score: electorate, labour, corbyn, party, vote, election, ukip
## Topic 3 Top Words:
## Highest Prob: growth, year, market, economy, prices, markets, uk
## FREX: prices, growth, markets, economy, quarter, market, inflation
## Lift: ftse, forecasts, output, pound, monetary, economists, recession
## Score: ftse, growth, prices, eurozone, markets, inflation, oil
## Topic 4 Top Words:
## Highest Prob: us, security, military, syria, war, foreign, attacks
## FREX: syria, military, isis, russian, de, syrian, islamic
## Lift: de, afghanistan, syria, fighters, russian, troops, isis
## Score: de, syria, isis, syrian, military, russian, islamic
## Topic 5 Top Words:
## Highest Prob: climate, energy, countries, change, world, global, china
## FREX: climate, energy, gas, emissions, environmental, china, development
## Lift: climate, india, environmental, carbon, emissions, energy, gas
## Score: india, climate, emissions, energy, china, carbon, countries
## Topic 6 Top Words:
## Highest Prob: government, minister, australia, monday, australian, bill, law
## FREX: monday, australian, australia, labor, bill, legislation, federal
## Lift: monday, australians, australian, malcolm, labor, australia, abbott
## Score: monday, australian, labor, australia, minister, senate, abbott
## Topic 7 Top Words:
## Highest Prob: health, better, care, nhs, services, staff, doctors
## FREX: better, health, nhs, doctors, care, patients, mental
## Lift: patients, better, doctors, cancer, health, nhs, mental
## Score: better, nhs, health, patients, doctors, care, mental
## Topic 8 Top Words:
## Highest Prob: says, can, london, get, money, now, years
## FREX: games, buy, space, london, products, says, small
## Lift: games, design, space, waste, product, products, buy
## Score: games, says, products, london, business, buy, product
## Topic 9 Top Words:
## Highest Prob: city, many, country, video, south, rights, years
## FREX: video, church, city, park, gay, religious, protests
## Lift: video, protests, church, religious, gay, protesters, park
## Score: video, muslim, church, protesters, religious, gay, city
## Topic 10 Top Words:
## Highest Prob: like, think, just, can, us, even, going
## FREX: really, think, thing, things, like, something, feel
## Lift: watching, film, stuff, book, feels, thinking, books
## Score: watching, film, like, think, really, story, bbc
## Topic 11 Top Words:
## Highest Prob: children, school, food, water, local, child, education
## FREX: children, water, school, food, students, schools, girls
## Lift: storm, girls, students, children, water, schools, school
## Score: storm, children, water, school, food, girls, schools
## Topic 12 Top Words:
## Highest Prob: block-time, published-time, says, updated-timeupdated, photograph, today, morning
## FREX: block-time, published-time, updated-timeupdated, photograph, pic.twitter.com, today's, morning
## Lift: block-time, updated-timeupdated, published-time, today's, pic.twitter.com, photograph, getty
## Score: block-time, published-time, today's, updated-timeupdated, pic.twitter.com, says, photograph
## Topic 13 Top Words:
## Highest Prob: eu, uk, european, europe, britain, cameron, british
## FREX: eu, europe, european, refugees, britain, brexit, migrants
## Lift: cars, eu, refugees, migrants, migration, europe, italy
## Score: cars, eu, european, brexit, refugees, greece, referendum
## Topic 14 Top Words:
## Highest Prob: information, data, online, media, users, using, internet
## FREX: internet, users, google, apple, information, facebook, app
## Lift: weekly, user, google, privacy, app, users, internet
## Score: weekly, google, users, app, apple, data, facebook
## Topic 15 Top Words:
## Highest Prob: told, family, two, back, home, time, man
## FREX: late, son, man, father, died, friends, went
## Lift: late, son, sister, daughter, brother, father, bus
## Score: late, family, died, mother, daughter, man, son
## Topic 16 Top Words:
## Highest Prob: tax, government, pay, budget, cuts, spending, workers
## FREX: tax, cuts, housing, budget, income, osborne, spending
## Lift: innovation, tax, councils, income, osborne's, budget, cuts
## Score: innovation, tax, osborne, budget, cuts, income, housing
## Topic 17 Top Words:
## Highest Prob: trump, clinton, republican, sanders, campaign, obama, donald
## FREX: clinton, republican, sanders, trump, cruz, hillary, trump's
## Lift: bernie, hillary, republican, sanders, trump's, clinton, cruz
## Score: bernie, trump, clinton, sanders, cruz, republican, hillary
## Topic 18 Top Words:
## Highest Prob: police, court, officers, case, investigation, told, evidence
## FREX: police, officers, arrested, prison, investigation, trial, criminal
## Lift: custody, suspect, jury, prosecution, prosecutors, officers, police
## Score: suspect, police, officers, court, arrested, investigation, prison
## Topic 19 Top Words:
## Highest Prob: company, bank, business, companies, executive, chief, financial
## FREX: company, bank, banks, banking, executive, shares, shareholders
## Lift: investments, executives, shareholders, directors, banking, company's, profit
## Score: investments, bank, shareholders, company, shares, customers, companies
## Topic 20 Top Words:
## Highest Prob: women, report, found, research, year, number, years
## FREX: women, study, research, drug, drugs, report, female
## Lift: equivalent, researchers, gender, study, drugs, drug, women
## Score: equivalent, women, drug, report, drugs, violence, research