22 Keyword Assisted Topic Models
Wie bereits im vorherigen Kapitel 21 geschrieben, handelt es sich bei Topic Modeling um eine ganze Klasse an ähnlichen, aber in Details auch recht unterschiedlichen Verfahren zum Ergründen von ‘Themen’ in Textkorpora. Eine noch sehr neue, aber besonders vielversprechende Weiterentwicklung des wegweisenden LDA-Ansatzes nennt sich Keyword Assisted Topic Models.
Das besondere an diesem Verfahren ist, dass es gewissermaßen die Unterscheidung zwischen überwachten und unüberwachtem maschinellen Lernen auflöst. Es können zum einen, wie auch bei anderen Topic-Modeling-Verfahren, Themen ganz automatisch in einem Textkorpus ermittelt werden; es können jedoch auch zudem – und darauf verweist der Name – auch vorab bereits Themen anhand von einigen Schlüsselwörtern definiert werden.
22.1 Keyword Assisted Topic Models in R mit keyATM
Durch das Package keyATM ist das Verfahren bereits in R implementiert. Wir installieren also zunächst das Package:
Wie gehabt laden wir unsere wichtigsten Packages:58
Da das Anwendungsbeispiel in der offiziellen Dokumentation von keyATM – Themen in der “Inaugural Address”, also der Antrittsrede bei der Amtseinführung des Präsidenten der Vereinigten Staaten – so schön in die Zeit passt, sehen wir uns die Funktionsweise des Packages ebenfalls an diesem Beispiel an. Das hat den zusätzlichen Vorteil, dass ein entsprechender Textkorpus bereits zum Umfang von Quanteda gehört – wir können einen entsprechenden Korpus mit den 58 Antrittsreden aller 45 US-Präsidenten bis einschließlich Donald Trump also direkt über das Objekt data_corpus_inaugural verwenden, ohne Daten selbst einlesen zu müssen:
## Corpus consisting of 58 documents and 4 docvars.
## 1789-Washington :
## "Fellow-Citizens of the Senate and of the House of Representa..."
##
## 1793-Washington :
## "Fellow citizens, I am again called upon by the voice of my c..."
##
## 1797-Adams :
## "When it was first perceived, in early times, that no middle ..."
##
## 1801-Jefferson :
## "Friends and Fellow Citizens: Called upon to undertake the du..."
##
## 1805-Jefferson :
## "Proceeding, fellow citizens, to that qualification which the..."
##
## 1809-Madison :
## "Unwilling to depart from examples of the most revered author..."
##
## [ reached max_ndoc ... 52 more documents ]22.1.1 Preprocessing
Wie gehabt setzen wir alle Preprocesing-Schritte mit Quanteda um: Wir erstellen eine DFM und entfernen dabei Satzzeichen, Zahlen sowie Symbole und URLs (die in den Reden vermutlich nicht vorkommen dürften, aber da die Text-Daten von einer Website gescraped wurden, ist es dennoch sinnvoll, sicher zu gehen); außerdem entfernen wir Stoppwörter sowie einige zusätzliche häufig vorkommenden Wörter:
inaug_dfm <- dfm(data_corpus_inaugural,
remove_punct = TRUE,
remove_url = FALSE,
remove_numbers = TRUE,
remove_symbols = TRUE,
remove = c(stopwords('english'),
"may", "shall", "can", "must", "upon", "with", "without"),
verbose = TRUE)## Creating a dfm from a corpus input...## ...lowercasing## ...found 58 documents, 9,277 features## ...removed 143 features
## ...complete, elapsed time: 0.17 seconds.
## Finished constructing a 58 x 9,135 sparse dfm.Wie auch bei den anderen Modellen und Verfahren, die wir uns bisher angesehen haben, ist es erneut sinnvoll, die DFM um Wörter mit geringem Informationsgehalt (also Wörter, die sehr selten oder sehr häufig vorkommen) zu ‘trimmen’, um die Rechenzeit zu senken und Interpretierbarkeit zu erhöhen. Bisher haben wir anhand prozentualer Anteile gemacht; in einem vergleichsweise kleinen Korpus mit nur 58 Dokumenten können wir dies aber auch anhand absoluter Häufigkeiten machen:
trimmed_dfm <- dfm_trim(inaug_dfm,
min_termfreq = 5,
min_docfreq = 2,
termfreq_type = "count",
docfreq_type = "count")Entfernt wurden also alle Wörter, die nicht mindestens 5 mal insgesamt und nicht in mindestens 2 verschiedenen Reden vorkommen. Mit termfreq_type = "count" und docfreq_type = "count" legen wir fest, dass diese Zahlen nun als absolute Häufigkeiten (anstatt wie bisher prop, also prozentualer Anteile) interpretiert werden sollen (hierbei handelt es sich auch um die Standardeinstellung, allerdings ist es sinnvoll, dies dennoch im Code zu explizieren, damit andere schneller erfassen können, was hier geschieht).
Abschließend müssen wir die DFM in ein Format konvertieren, mit dem keyATM umgehen kann. Bisher haben wir dies mit der Funktion convert() von Quanteda erledigt; da das keyATM-Package noch sehr neu ist, bietet Quanteda aber noch keine Konvertierungsmöglichkeit. Allerdings bietet keyATM selbst eine Konvertierungsfunktion namens keyATM_read():
## Using quanteda dfm.22.1.2 A-priori-Themen und zugehörige Schlüsselwörter definieren
Die große Neuerung ist wie bereits erwähnt, dass wir nun bereits vorab einige Themen und zugehörige Schlüsselwörter definieren können. Bei den Antrittsreden würden wir erwarten, dass immer wieder echte Dauerbrenner wie Regierungs- und Kongressbezüge, Verweise auf die Verfassung, aber auch auf Friedensbemühungen und Außenpolitik vorkommen. Wir definieren diese als Liste, wobei wir der Themenbezeichnung jeweils einen Vektor an Schlüsselwörtern zuorden (diese Vektoren können auch unterschiedlich lang sein, also eine unterschiedliche Anzahl an Schlüsselwörtern aufweisen):
keywords <- list("Government" = c("laws", "law", "executive"),
"Congress" = c("congress", "party"),
"Peace" = c("peace", "world", "freedom"),
"Constitution" = c("constitution", "rights"),
"ForeignAffairs" = c("foreign", "war"))Das Package bietet uns zudem eine Funktion, mit der wir vorab überprüfen können, ob es sich um sinnvolle Schlüsselwörter handelt. Mit visualize_keywords() erzeugen wir eine Grafik, die den prozentualen Anteil aller vorab definierten Schlüsselwörter ausgibt. Die Autoren des Packages empfehlen, dass jedes Schlüsselwort einen Anteil von über 0,1% aufweisen sollte – dies ist hier bei allen definierten Schlüsselwörtern der Fall:
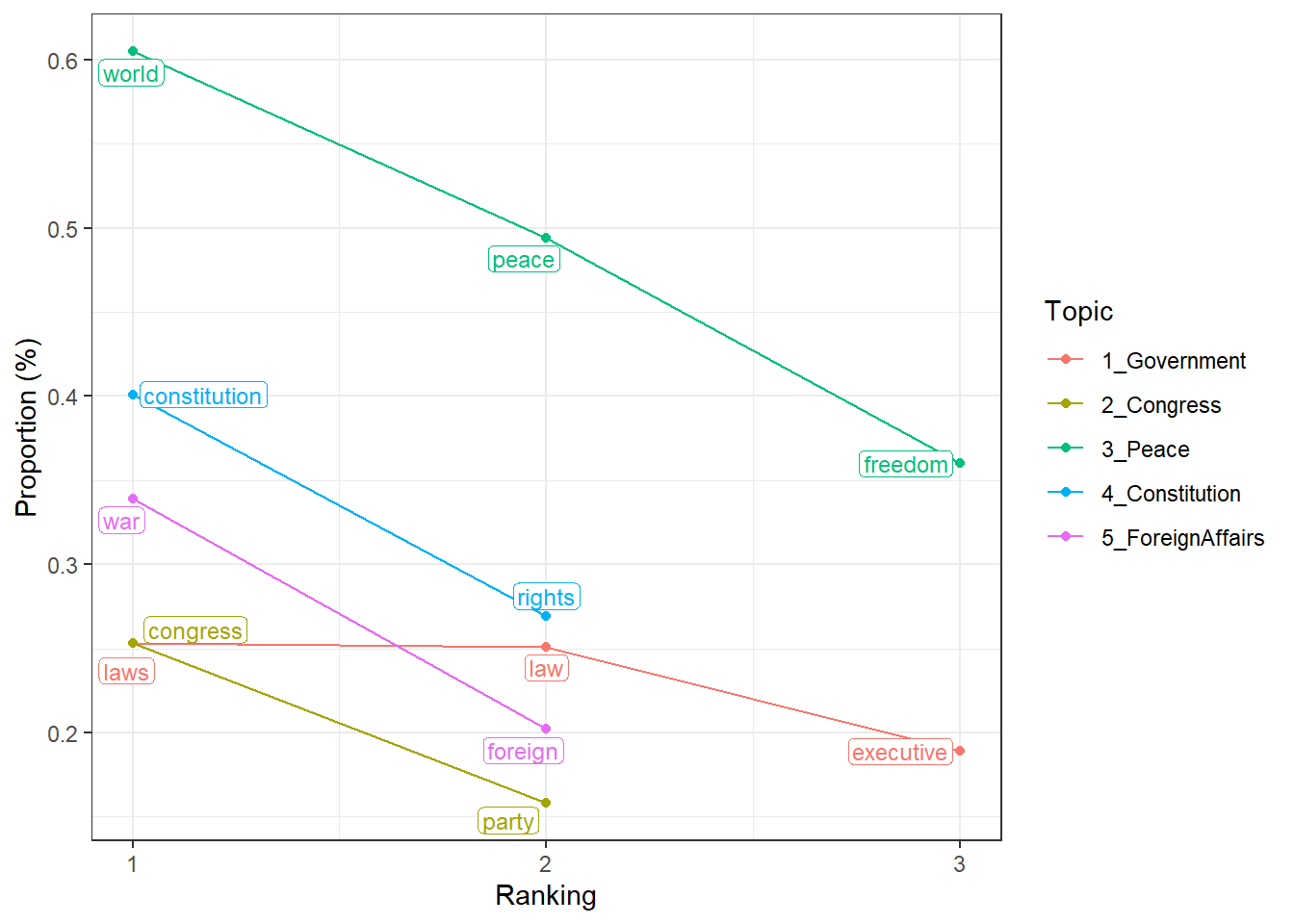
Außerdem würde die Funktion eine Warnung ausgeben, sollte ein Schlüsselwort gar nicht im Korpus vorkommen – auch dies ist hier nicht der Fall, wir können also gut mit diesen Schlüsselwörtern arbeiten. Wichtig ist: ob diese Wörter die vorab definierten Themen auch inhaltlich sinnvoll beschreiben, ist eine inhaltliche, menschliche Beurteilung, die keine Statistik ersetzen kann.
22.1.3 Modell berechnen und interpretieren
Nun können wir das Modell mit der Funktion keyATM() berechnen. Hier sind folgende Argumente relevant:
docs: unsere konvertierte DFM, anhand der das Modell berechnet werden soll.no_keyword_topics: die Anzahl an weiteren Topics, die das Modell zusätzlich zu den vorab definierten Themen beinhalten soll.keywords: die Liste der vorab definierten Topics mit zugehörigen Schlüsselwörtern.model: hier geben wir"base"an, um das Standard-keyATM zu rechnen. Weitere Modellvarianten können, ebenso wie bei STM, beispielsweise auch Kovariaten enthalten, mit denen die Prävalenz der Themen geschätzt werden kann. Dies könnte im Beispiel dazu genutzt werden, um die Prävalenz bestimmter Themen etwa durch den Zeitverlauf oder die Parteizugehörigkeit der Präsidenten zu erklären. Wir blenden dies der Einfachheit halber an dieser Stelle aus, die offizielle Dokumentation verfügt jedoch über lange, gute Erklärungen der weiteren Modellvarianten.options: hier können wir weitere Optionen festlegen; da die initiale Themenlösung zufällig erzeugt wird, können wir mit der Angabe eines Seeds sichern, dass unser Modell exakt replizierbar ist.
inaug_model <- keyATM(docs = keyATM_docs,
no_keyword_topics = 5,
keywords = keywords,
model = "base",
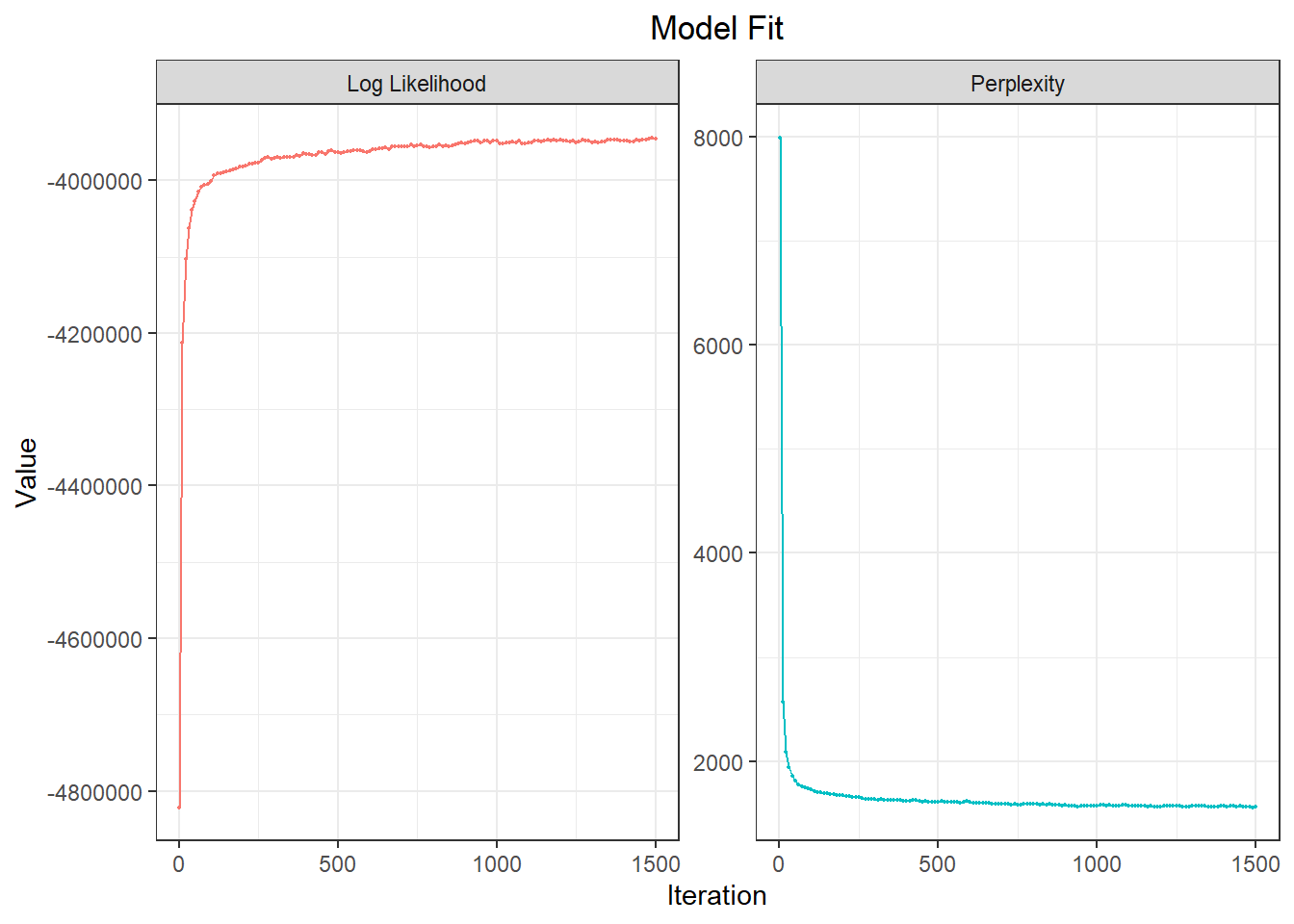
options = list(seed = 667))Zunächst sollten wir den Modelfit überprüfen. keyATM bietet hierfür die Funktion plot_modelfit(), die zwei Kennwerte – Log-Likelihood und Perplexity – im Verlauf der Modelliterationen darstellt. Bei einem Modell, das gut zu den Daten passt, sollte sich im Verlauf der Iterationen die Log-Likelihood auf einem höheren, die Perplexity auf einem geringeren Wert einpendeln. Beides ist hier der Fall (erneut gilt jedoch: ob das Modell auch inhaltlich sinnvoll ist, muss manuell und inhaltlich interpretiert werden):
Die inhaltliche Interpretation des Modells erfolgt vor allem anhand der Funktionen top_words() und top_docs(). Erstere stellt uns die – per Standardeinstellung 10 – wichtigsten Wörter je Thema dar:
## 1_Government 2_Congress 3_Peace 4_Constitution 5_ForeignAffairs Other_1 Other_2 Other_3 Other_4 Other_5
## 1 laws [<U+2713>] country us government states political hope american every great
## 2 congress [2] best nation people public duties free government now war [5]
## 3 law [<U+2713>] well peace [<U+2713>] constitution [<U+2713>] union free faith world [3] citizens made
## 4 executive [<U+2713>] much new power united federal good future us national
## 5 policy necessary people rights [<U+2713>] interests prosperity yet progress spirit neverBei einigen Wörtern fallen Ihnen hinter den Wörtern zusätzliche Zeichenketten auf. Die Zeichenkette "<U+2713>" sollte eigentlich ein Häkchensymbol darstellen (es handelt sich bei der kryptischen Nummernfolge um den zugehörigen Unicode); führen Sie den Code nicht an einem deutschen Windows-Rechner aus, sollter dies auch bereits funktionieren. In jedem Fall signalisiert Ihnen das, dass es sich um ein vorab definiertes Schlüsselwort handelt. Das vorab definierte Thema 3, Peace, enthält beispielsweise als drittwichtigstes Schlüsselwort “peace”, ebenfalls gehören jedoch auch neue Wörter wie “us”, “nation” etc. dazu. Eine Zahl in eckigen Klammern signalisiert hingegen, dass das betreffende vorab definierte Schlüsselwort auch einem anderen Thema zugeordnet wurde. Das Schlüsselwort “war” im neuen Thema “Other_5” entstammt beispielsweise dem vorab definierten Thema 5, “ForeignAffairs”.
top_docs() wiederum reiht uns pro Thema die wichtigsten Dokumente auf, also diejenigen Dokumente, in denen das jeweilige Thema den größten Anteil hat.
## 1_Government 2_Congress 3_Peace 4_Constitution 5_ForeignAffairs Other_1 Other_2 Other_3 Other_4 Other_5
## 1 31 16 46 14 15 23 51 36 2 9
## 2 19 21 53 3 6 13 44 41 7 20
## 3 26 3 45 2 8 11 46 34 39 22
## 4 23 22 52 10 9 15 54 33 30 32
## 5 24 18 47 1 10 36 47 38 6 8Thema 1, “Government”, ist also am stärksten in Antrittrede 31 enthalten, gefolgt von Antrittsrede 19 usw.
Ansonsten gestaltet sich die Interpretation analog zu den im vorigen Kapitel berechneten Themenmodellen mit STM. Zentral sind erneut die Matrizen mit den Themenwahrscheinlichkeiten je Dokument, bei keyATM als \(\theta\) bezeichnet, und die Wortwahrscheinlichkeiten je Thema, hier als \(\phi\) bezeichnet, die wir über das Modellobjekt mit inaug_model$theta bzw. inaug_model$phi abrufen können.
Mit etwas Umformung erhalten wir beispielsweise wieder einen Datensatz, der uns pro Thema die 7 wichtigste Wörter in einem String verbindet:
top_terms <- inaug_model$phi %>%
t() %>%
as_tibble(rownames = "word") %>%
pivot_longer(-word, names_to = "topic", values_to = "phi") %>%
group_by(topic) %>%
top_n(7, phi) %>%
arrange(topic, desc(phi)) %>%
group_by(topic) %>%
summarise(top_words = paste(word, collapse = ", "), .groups = "drop")
top_terms## # A tibble: 10 x 2
## topic top_words
## <chr> <chr>
## 1 1_Government laws, congress, law, executive, policy, administration, states
## 2 2_Congress country, best, well, much, necessary, party, ever
## 3 3_Peace us, nation, peace, new, people, freedom, america
## 4 4_Constitution government, people, constitution, power, rights, one, duty
## 5 5_ForeignAffairs states, public, union, united, interests, foreign, powers
## 6 Other_1 political, duties, free, federal, prosperity, men, far
## 7 Other_2 hope, free, faith, good, yet, strength, come
## 8 Other_3 american, government, world, future, progress, justice, purpose
## 9 Other_4 every, now, citizens, us, spirit, just, power
## 10 Other_5 great, war, made, national, never, many, supportEbenso können wir die Themen mit ihrem durchschnittlichen Anteil in den Dokumenten nach Wichtigkeit sortieren:
top_topics <- inaug_model$theta %>%
as_tibble(rownames = "speech") %>%
pivot_longer(-speech, names_to = "topic", values_to = "theta") %>%
group_by(topic) %>%
summarise(mean_theta = mean(theta), .groups = "drop") %>%
arrange(desc(mean_theta))
top_topics## # A tibble: 10 x 2
## topic mean_theta
## <chr> <dbl>
## 1 3_Peace 0.187
## 2 Other_4 0.112
## 3 Other_5 0.103
## 4 5_ForeignAffairs 0.0990
## 5 Other_2 0.0965
## 6 4_Constitution 0.0946
## 7 Other_3 0.0842
## 8 2_Congress 0.0792
## 9 Other_1 0.0785
## 10 1_Government 0.0660Und wenn wir beides verbinden, erhalten wir wieder die bereits bekannte Grafik, die uns Themenprävalenz und wichtigste Wörter zusammen darstelle:
top_topics %>%
left_join(top_terms, by = "topic") %>%
mutate(topic = reorder(topic, mean_theta)) %>%
ggplot(aes(topic, mean_theta, label = top_words, fill = topic)) +
geom_col(show.legend = FALSE) +
geom_text(hjust = 0, nudge_y = 0.0005, size = 3) +
coord_flip() +
scale_y_continuous(expand = c(0, 0), limits = c(0, 0.35), labels = scales::percent) +
theme_bw() +
theme(panel.grid.minor = element_blank(),
panel.grid.major = element_blank()) +
labs(x = NULL, y = expression(theta))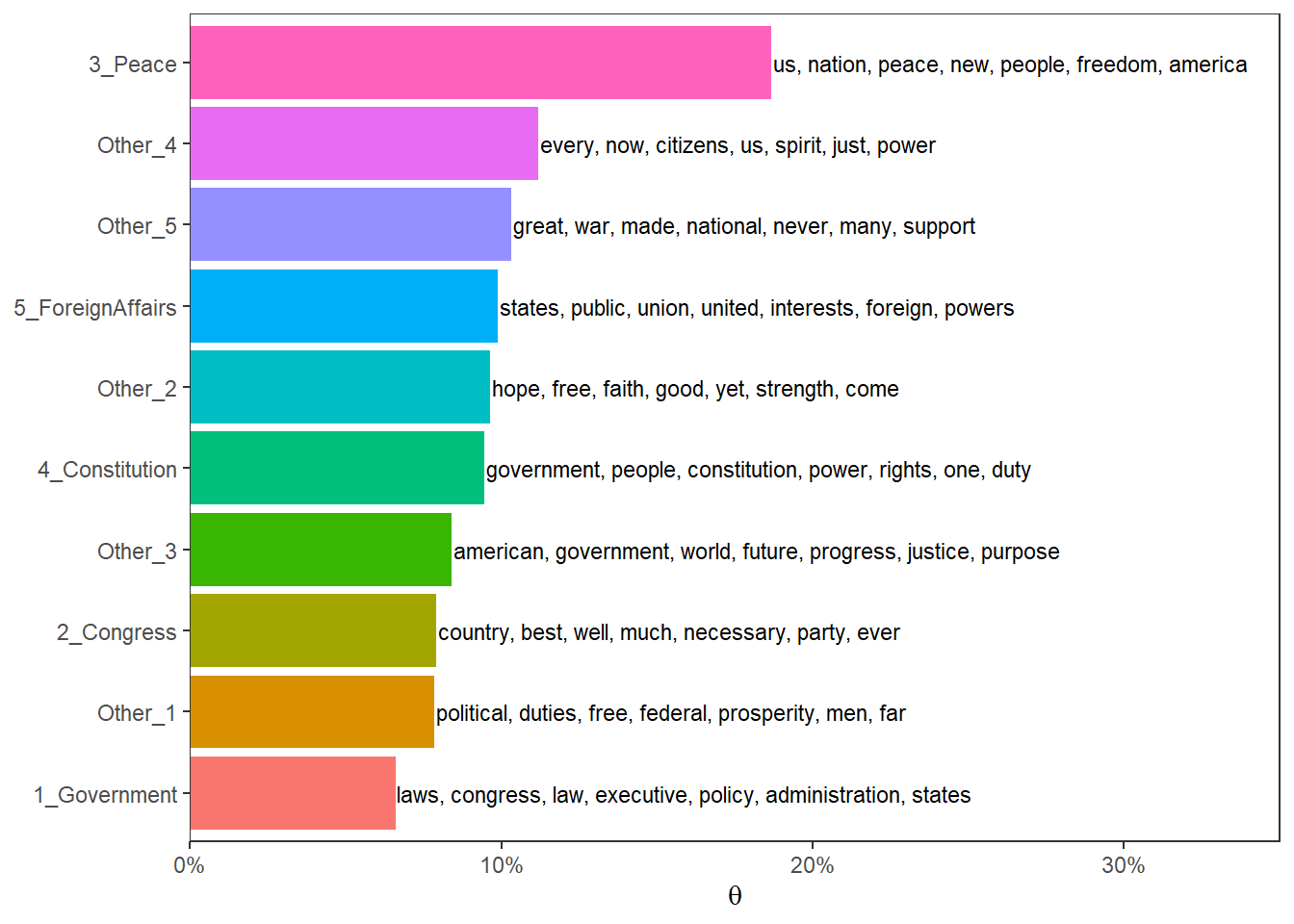
22.2 Übungsaufgaben
Erstellen Sie für die folgende Übungsaufgabe eine eigene Skriptdatei oder eine R-Markdown-Datei und speichern diese als ue22_nachname.R bzw. ue22_nachname.Rmd ab.
Für die Übungsaufgabe verwenden wir erneut den Korpus aus Artikeln des Guardian (siehe Übungsaufgabe 21.1.
Rechnen Sie ein Keyword Assisted Topic Model mit mindestens 3 vorab definierten Themen und 20 Themen insgesamt. Orientieren Sie sich bei den vorab definierten Themen an den Ergebnissen der vorherigen Übungsaufgabe.
wir verzichten an dieser Stelle auf das
tidytext-Package, da dieses (noch) keinetidy()-Funktion für Themenmodelle aufweist, die mitkeyATMgerechnet werden. Das dürfte sich jedoch bald ändern.↩︎