15 Web Scraping
Web Scraping bezeichnet allgemein Verfahren zur automatisierten Extraktion von Inhalten auf Webseiten. In unserem Fall setzen wir hierzu ein Skript in R auf, das die uns interessierenden Elemente auf Webseiten identifziert und in einem R-Objekt speichert. Hierfür benötigen wir das zum Tidyverse gehörige Package rvest, das wir auch einzeln über install.packages("rvest") installieren können:
rvest zählt jedoch nicht zu den Kernpackages des Tidyverse und muss daher separat geladen werden:
Mittels rvest laden wir zunächst den HTML-Quelltext einer Webseite herunter und wählen anschließend die HTML-Elemente aus, die uns interessieren. Wir benötigen also zunächst eine Möglichkeit, schnell für uns interessante HTML-Elemente auf einer Webseite identifizieren zu können.
15.1 HTML-Elemente identifizieren
Keine Angst: wir müssen nicht den gesamten Quellcode einer Webseite durchlesen, um entsprechende HTML-Elemente zu finden. Moderne Browser bieten in der Regel eine Untersuchen-Funktion, mit der HTML-Elemente per Klick im Code der Webseite hervorgehoben werden. In Google Chrome klicken wir hierzu per Rechtsklick auf das Element, das wir identifizieren möchten, und gehen dann auf Untersuchen. Möchten wir z. B. auf meiner Insitutswebseite meinen Namen scrapen, zeigt sich folgendes Bild:37
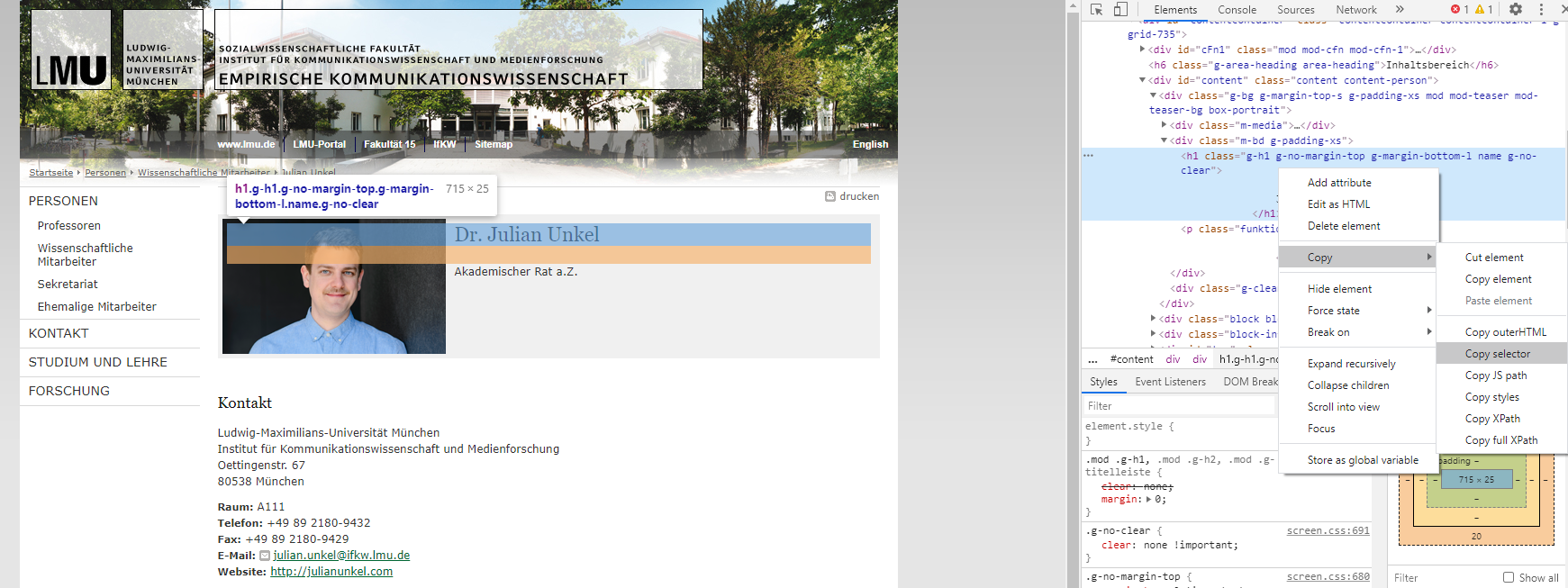
Untersuchen-Funktion in Google Chrome
Im rechten Bildschirmbereich (oder je nach Einstellung auch links, oben oder unten) öffnet sich der Quellcode, wobei das gewählte Element grau hervorgehoben ist (<h1 class="g-h1 usw.). Mit einem Rechtsklick im Codebereich auf ein Element öffnet sich ein weiteres Menü, über das wir via Copy - Copy selector den zugehörigen CSS Selector (also die genaue Kombination aus Tags, Klassen und IDs, die dieses Element identifiziert) kopieren, was in diesem Fall #content > div.g-bg.g-margin-top-s.g-padding-xs.mod.mod-teaser.mod-teaser-bg.box-portrait > div.m-bd.g-padding-xs > h1 entspricht.38
Noch komfortabler gelingt die Identifikation mit dem Tool Selector Gadget, das vom rvest-Team zur Verfügung gestellt wird. Hierbei handelt es sich um ein Bookmarklet, das per Klicks die Identifikation von einem oder auch mehreren HTML-Elementen ermöglicht.
Hierzu muss das Tool erst einmal durch Ziehen des Links auf die Lesezeichenleiste des Browsers installiert werden. Im Anschluss kann das Tool durch Klicken auf das Lesezeichen auf jeder Webseite gestartet werden. Ein Klick auf ein Element und das Tool versucht, es zu identifzieren; der zugehörige Selector wird in der Leiste unten angezeigt:
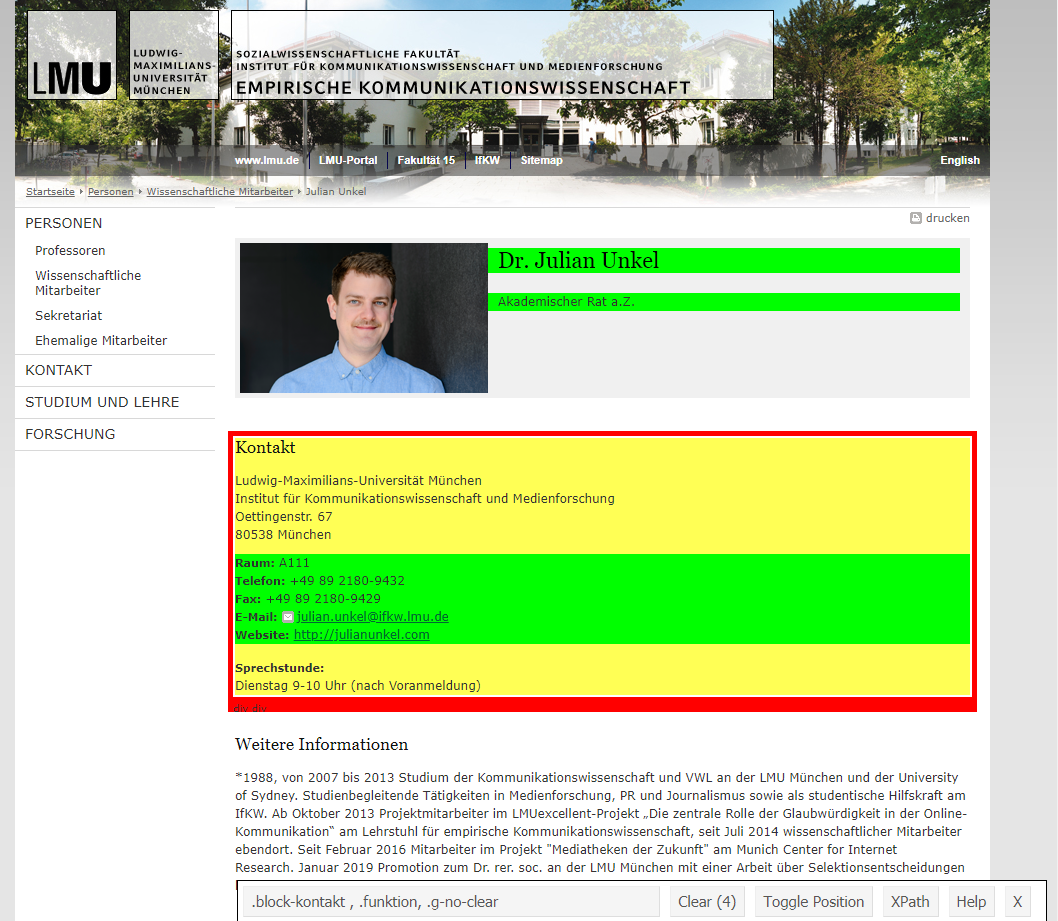
Selector Gadget in Aktion
- grün hervorgehoben sind Elemente, die bewusst per Klick ausgewählt wurden
- gelb hervorgehoben sind Elemente, die mit dem aktuellen Selector ebenfalls ausgewählt werden. Per Klick auf diese werden diese deselektiert und das Tool versucht einen Selector zu finden, das diese Elemente nicht mit umfasst.
- rot hervorgehoben sind Elemente, die gezielt deselektiert wurden
Im Anschluss kann der zugehörige Selector einfach aus der Leiste unten kopiert werden.
15.2 Web Scraping mit rvest
Nachdem wir die uns interessierenden HTML-Elemente identifziert haben, können wir uns ans eigentliche Web Scraping machen.
15.2.1 Quellcode einlesen mit read_html()
Als erstes laden wir hierzu den Quellcode der betreffenden Webseite herunter. Hierzu stellt uns rvest (bzw. ein Package, auf dem rvest aufbaut) die Funktion read_html() zur Verfügung, der wir einfach die jeweilige URL als String übergeben können:
Alle folgenden Funktionen können in einer Pipe verwendet werden.
15.2.2 Elemente auswählen mit html_nodes()
Zur Auswahl von HTML-Elementen nutzen wir die Funktion html_nodes(), der wir einen CSS-Selector als Argument übergeben. Wir haben z. B. oben gesehen, dass der Name auf den IfKW-Profilseiten in einem Element mit der Klasse g-h1 steht:
## {xml_nodeset (1)}
## [1] <h1 class="g-h1 g-no-margin-top g-margin-bottom-l name g-no-clear">\n Dr.\n Julian Unkel\n </h1>Dies hat nun das gesamte Element ausgewählt. Bei sehr verschachtelten HTML-Dokumenten können wir die Funktion auch mehrfach hintereinander aufrufen, um uns nach und nach zu dem uns interessierenden Element “vorzutasten”. Hier wählen wir zunächst den Inhaltsbereich der Seite aus (ID: content) und wählen innerhalb dieses Bereichs alle Elemente mit dem HTML-Tag <span> aus:
## {xml_nodeset (12)}
## [1] <span class="g-label label-raum">Raum:</span>
## [2] <span class="raum">A111</span>
## [3] <span class="g-label label-telefon">Telefon:</span>
## [4] <span class="telefon">+49 89 2180-9432</span>
## [5] <span class="g-label label-fax">Fax:</span>
## [6] <span class="fax">+49 89 2180-9429</span>
## [7] <span class="g-label label-email">E-Mail:</span>
## [8] <span class="email"><a href="mailto:julian.unkel@ifkw.lmu.de" class="g-link-mail" title="E-Mail senden an: julian.unkel@ifkw.lmu.de">julian.unkel@ifkw.l ...
## [9] <span class="g-label label-website">Website:</span>
## [10] <span class="website"><a href="http://julianunkel.com">http://julianunkel.com</a></span>
## [11] <span class="g-label label-sprechstunde">Sprechstunde:</span>
## [12] <span class="sprechstunde">Dienstag 9-10 Uhr (nach Voranmeldung)</span>Zum Vergleich: Beschränken wir die Auswahl zuvor nicht mittels der ID content, erhalten wir auch alle <span>-Elemente, die im Menübereich etc. stehen.
## {xml_nodeset (18)}
## [1] <span class="m-separator"><a href="http://www.uni-muenchen.de" class="m-link" target="_blank" title="www.lmu.de - Startseite">www.lmu.de</a></span>
## [2] <span class="m-separator"><a href="http://www.portal.lmu.de" target="_blank" class="m-link" title="LMU-Portal">LMU-Portal</a></span>
## [3] <span class="m-separator"><a href="https://www.sozialwissenschaften.uni-muenchen.de/index.html" target="_blank" class="m-link" title="Fakultät 15">Fakul ...
## [4] <span class="m-separator"><a href="https://www.ifkw.uni-muenchen.de/index.html" target="_blank" class="m-link" title="IfKW">IfKW</a></span>
## [5] <span class="m-separator"><a href="../../../funktionen/sitemap2/index.html" class="m-link" title="Sitemap">Sitemap</a></span>
## [6] <span class="m-separator"><a href="https://www.en.ls1.ifkw.uni-muenchen.de/index.html" class="m-link" title="English">English</a></span>
## [7] <span class="g-label label-raum">Raum:</span>
## [8] <span class="raum">A111</span>
## [9] <span class="g-label label-telefon">Telefon:</span>
## [10] <span class="telefon">+49 89 2180-9432</span>
## [11] <span class="g-label label-fax">Fax:</span>
## [12] <span class="fax">+49 89 2180-9429</span>
## [13] <span class="g-label label-email">E-Mail:</span>
## [14] <span class="email"><a href="mailto:julian.unkel@ifkw.lmu.de" class="g-link-mail" title="E-Mail senden an: julian.unkel@ifkw.lmu.de">julian.unkel@ifkw.l ...
## [15] <span class="g-label label-website">Website:</span>
## [16] <span class="website"><a href="http://julianunkel.com">http://julianunkel.com</a></span>
## [17] <span class="g-label label-sprechstunde">Sprechstunde:</span>
## [18] <span class="sprechstunde">Dienstag 9-10 Uhr (nach Voranmeldung)</span>Wir können zudem mehrere Elemente gleichzeitig auswählen, indem wir die zugehörigen Selektoren durch Kommas , trennen. So stehen in den IfKW-Profilen die Kontaktinformationen beispielsweise in HTML-Elementen, die die Klassen raum, telefon, fax, email und website haben:
## {xml_nodeset (5)}
## [1] <span class="raum">A111</span>
## [2] <span class="telefon">+49 89 2180-9432</span>
## [3] <span class="fax">+49 89 2180-9429</span>
## [4] <span class="email"><a href="mailto:julian.unkel@ifkw.lmu.de" class="g-link-mail" title="E-Mail senden an: julian.unkel@ifkw.lmu.de">julian.unkel@ifkw.lm ...
## [5] <span class="website"><a href="http://julianunkel.com">http://julianunkel.com</a></span>15.2.3 Text aus HTML-Elementen extrahieren mit html_text()
Meistens interessiert uns nicht das gesamte HTML-Element samt Tags und Attributen, sondern lediglich der Text, der in diesem Element steht. Diesen extrahieren wir mit html_text():
## [1] "\n Dr.\n Julian Unkel\n "Das ist schon näher am gewünschten Ergebnis, den Namen zu extrahieren – der String enthält zwar noch viel unnötigen Whitespace (\n steht für Newline, also einen Zeilenumbruch), aber dagegen haben wir ja auch schon eine Lösung gelernt (siehe Kapitel 12.1.5):
## [1] "Dr. Julian Unkel"Das ganze klappt natürlich auch mit mehreren Elementen gleichzeitig. So extrahieren wir den Text aller Kontaktinformationen:
## [1] "A111" "+49 89 2180-9432" "+49 89 2180-9429" "julian.unkel@ifkw.lmu.de" "http://julianunkel.com"15.2.4 Attribute aus HTML-Elementen extrahieren mit html_attr()
Neben dem Text sind zudem Attribute der selektierten HTML-Elemente für uns von Interesse. Diese können wir mit der Funktion html_attr(), wobei wir das uns interessierende Attribut als String übergeben müssen.
Einer der häufigsten Anwendungsfälle ist hierbei die Extraktion von Links aus Webseiten. Aus dem vorhergehenden Kapitel (siehe Kapitel 14.2.1) wissen wir, dass Links in HTML in einem <a>-Tag stehen und das Ziel des Links über das Attribut href definiert wird. So extrahieren wir beispielsweise alle Link-Ziele, die im Inhalt meines IfKW-Profils stehen:
ifkw %>%
html_nodes("#content") %>% # Inhaltsbereich auswählen
html_nodes("a") %>% # Alle Links (<a>-Tag) auswählen
html_attr("href") # Attribut "href" extrahieren## [1] "mailto:julian.unkel@ifkw.lmu.de" "http://julianunkel.com" "publikationen.html" "vortraege.html"Ein weiterer häufiger Anwendungsfall ist das Extrahieren von Bilddaten. Diese werden in HTML durch ein <img>-Tag eingebunden, wobei die zugehörige Bilddatei über das Attribut src angeben wird. So extrahieren wir beispielsweise den (relativen) Dateipfad aller Bilder auf dieser Seite:
## [1] "//cms-static.uni-muenchen.de/default/lmu/img/blank.png" "//cms-static.uni-muenchen.de/default/lmu/img/header-print.gif"
## [3] "julian_unkel.png"Gleichzeitig zeigt dies auch schon eine Schwierigkeit beim Web Scraping auf: oft führen Webseiten-Betreiber*innen Schritte durch, die das Web Scraping erschweren. Wenn Sie beispielsweise den ersten Bildpfad (cms-static.uni-muenchen.de/default/lmu/img/blank.png) in einen Browser kopieren, werden Sie sehen, dass sich dahinter mitnichten das schöne Institutsbild aus dem Seitenkopf befindet, sondern ein Blanko-Bild, das dann anderweitig durch das Bild im Seitenkopf ersetzt wird.
15.3 Effizientes Scraping
Mit diesen vier Funktionen – read_html(), html_nodes(), html_text() und html_attr()39 – können wir bereits so gut wie alle Web-Scraping-Aufgaben bewältigen. Bisher führen wir unseren Code jedoch nur auf einer einzigen Webseite auf, deren Informationsgehalt wir vermutlich genauso schnell oder schneller von Hand hätten erfassen können. Wirklich effizient scrapen wir daher erst, wenn wir die bisher gelernten Inhalte kombinieren und uns Muster in Webseiten zu Nutze machen, um dieselben Scraping-Schritte auf mehrere Seiten anwenden zu können.
Rufen wir uns nochmals die Schritte in Erinnerung, um die Namens- und Kontaktinformationen von meinen IfKW-Profil zu scrapen:
# Quellcode einlesen
ifkw <- read_html("https://www.ls1.ifkw.uni-muenchen.de/personen/wiss_ma/unkel_julian/index.html")
# HTML-Elemente extrahieren
kontakt <- ifkw %>%
html_nodes(".g-h1, .raum, .telefon, .fax, .email, .website") %>%
html_text() %>%
str_squish()
kontakt## [1] "Dr. Julian Unkel" "A111" "+49 89 2180-9432" "+49 89 2180-9429" "julian.unkel@ifkw.lmu.de"
## [6] "http://julianunkel.com"Wir speichern diese Informationen zur besseren Weiterverarbeitung in einem Tibble:
kontakt_tibble <- tibble(
name = kontakt[1],
raum = kontakt[2],
telefon = kontakt[3],
fax = kontakt[4],
email = kontakt[5],
website = kontakt[6]
)
kontakt_tibble## # A tibble: 1 x 6
## name raum telefon fax email website
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Dr. Julian Unkel A111 +49 89 2180-9432 +49 89 2180-9429 julian.unkel@ifkw.lmu.de http://julianunkel.comWas, wenn wir diese Schritte nun auch auf andere IfKW-Profile anwenden möchten? Es ist zu vermuten, dass dieses Schema auch bei anderen Profilen eingehalten wird. Wir können den Code also in eien Funktion umwandeln, die die jeweilige Profilseite als Argument aufnimmt:
scrape_ifkw <- function(url) {
# Quellcode einlesen
ifkw <- read_html(url)
# HTML-Elemente extrahieren
kontakt <- ifkw %>%
html_nodes(".g-h1, .raum, .telefon, .fax, .email, .website") %>%
html_text() %>%
str_squish()
# In Tibble umwandeln
kontakt_tibble <- tibble(
name = kontakt[1],
raum = kontakt[2],
telefon = kontakt[3],
fax = kontakt[4],
email = kontakt[5],
website = kontakt[6]
)
# 5 Sekunden warten, um den Server bei vielen Anfragen
# nicht zu überlasten
Sys.sleep(5)
# Tibble zurückgeben
return(kontakt_tibble)
}Nun benötigen wir nur noch einen Vektor mit den Profilseiten, die wir scrapen möchten:
to_scrape <- c(
"https://www.ls1.ifkw.uni-muenchen.de/personen/wiss_ma/unkel_julian/index.html",
"https://www.ls1.ifkw.uni-muenchen.de/personen/professoren/brosius_hansbernd/index.html"
)Und schon können wir mithilfe der map_-Funktionen (siehe Kapitel @ref(#tidyiteration)) unsere Scrape-Funktion auf alle Profilseiten anwenden. Da unsere Funktion ein Tibble ausgibt, können wir map_dfr() verwenden, um die resultierenden Tibbles zeilenweise miteinander zu verbinden:
Das Resultat:
## # A tibble: 2 x 6
## name raum telefon fax email website
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Dr. Julian Unkel A111 +49 89 2180-9432 +49 89 2180-9429 julian.unkel@ifkw.lmu.de http://julianunkel.com
## 2 Prof. Dr. Hans-Bernd Brosius 102 +49 89 2180-9455 +49 89 2180-9443 hans-bernd.brosius@ifkw.lmu.de <NA>15.4 Verantwortungsbewusstes Scrapen
Zum Abschluss noch einige “Verhaltensregeln” beim Web Scraping:
- Seitenspezifische Regeln beachten: viele Webseiten legen in einer Datei namens
robots.txtfest, wie nicht-menschliche "Besucher*innen" die Seite aufrufen dürfen; zudem gibt es oft “Terms of Service” oder ähnliches. Wenn eine Webseite Scraping untersagt, sollte das auch beherzigt werden. - Sparsam scrapen: Das heißt zum einen, nur das abzurufen, was wirklich benötigt wird. Zum anderen sollten Server auch nicht mit Anfragen überlastet werden; oft ist es schon ausreichend, eine kleine Wartezeit von ein paar Sekunden in entsprechende Scraping-Funktionen einzubauen.
- Vorstellig werden: HTTP-Anfragen enthalten im Header einen sogenannten User-Agent, eine Textzeile, die dem Server mitteilt, wer gerade eine Anfrage stellt. Bei der Nutzung von Webbrowsern wird hier z. B. der Name und die Versionsnummer des verwendeten Browsers mitgeteilt. Diese Textzeile kann jedoch beliebig angepasst werden, um den Servern weitere Informationen bereitzustellen.
Ein R-Package, das beim verantwortungsbewussten Scrapen viel Hilfestellung leistet, ist polite, das hier näher beschrieben wird.
Mit der enthaltenen Funktion bow() stellen wir uns dem Server zunächst (optional mit eigenem User-Agent) vor; dabei werden auch die seitenspezifischen Regeln in der robots.txt abgerufen:
library(polite)
session <- bow("https://www.ls1.ifkw.uni-muenchen.de/personen/wiss_ma/unkel_julian/index.html",
user_agent = "R-Kurs Computational Methods in der politischen Kommunikationsforschung")
session## <polite session> https://www.ls1.ifkw.uni-muenchen.de/personen/wiss_ma/unkel_julian/index.html
## User-agent: R-Kurs Computational Methods in der politischen Kommunikationsforschung
## robots.txt: 1 rules are defined for 1 bots
## Crawl delay: 5 sec
## The path is scrapable for this user-agentWir sehen, dass wir hier prinzipiell scrapen dürfen, zwischen einzelnen Crawls jedoch 5 Sekunden warten sollten. Die Funktion scrape() ersetzt nun read_html() aus rvest und berücksichtigt automatisch die zugehörigen Regeln.40 Anschließend können die gewohnten HTML-Extraktionsfunktionen aus rvest genutzt werden:
## [1] "Dr. Julian Unkel"15.5 Übungsaufgaben
Erstellen Sie für die folgenden Übungsaufgaben eine eigene Skriptdatei oder eine R-Markdown-Datei und speichern diese als ue15_nachname.R bzw. ue15_nachname.Rmd ab.
Scrapen Sie von diesem Artikel folgende Informationen:
- Erscheinungsdatum und Uhrzeit (‘9. Juni 2020, 9:20 Uhr’)
- Kicker (‘HSV in der zweiten Liga’)
- Überschrift (‘Das sind Dinge, die sehr, sehr weh tun"’)
- Lead-Absatz (‘So wird es eng mit dem Aufstieg…’)
Im Artikeltext verbirgt sich ein Link zu einer Themenseite von suedeutsche.de. Extrahieren Sie den Ziellink.
Erstellen Sie eine Funktion, um die Informationen aus Aufgabe 1 von einem beliebigen sueddeutsche.de-Artikel zu extrahieren. Testen Sie Ihre Funktion zusätzlich zum obigen Artikel auch anhand von diesem Artikel.
Wir üben mit meinem Profil, nicht weil ich eine ausgeprägte narzisstische Ader habe, sondern weil ich hier relativ sicher sein kann, dass ich die Zustimmung habe, auch auf diese Daten zugreifen zu dürfen.↩︎
Copy selector erzeugt oft eine sehr lange Kette, die in der Regel jedoch gar nicht nötig ist, um das jeweilige Element eindeutig zu identifizieren. Tatsächlich wären wir hier z. B. auch nur mit der Klasse
.g-h1schon erfolgreich.↩︎Eine fünfte Funktion,
html_table()soll nicht unerwähnt bleiben. Hierbei handelt es sich um eine Convenience-Funktion, die eine gesamte Tabelle extrahiert und automatisch in einen Dataframe umwandelt.↩︎Das heißt auch, dass
scrape()die Arbeit verweigert, wenn Scrapen nicht erlaubt ist.↩︎