6 Tutorial 6: Deskriptive Statistik
In Tutorial 6 lernen Sie:
- wie Sie sich die deskriptive Statistik für Daten ausgeben lassen können
- wie Sie Daten zu einem höheren Level aggregieren können
Bitte arbeiten Sie dafür weiter mit dem fiktiven Datensatz aus Tutorial 5: Daten_Tutorial 5.csv. Laden Sie diesen bitte aus OLAT herunter (via: Materialien / Datensätze für R).
Der Name der Datei lautet: Daten_Tutorial 5. (Achtung, nicht den Datensatz zur Aufgabe 5 aus Versehen wählen, der dort auch hochgeladen ist!) Es geht um den Datensatz OHNE den Anhang “Aufgabe”.
Zur Erinnerung: Der Datensatz sah folgendermassen aus:
## 'data.frame': 1000 obs. of 6 variables:
## $ Alter : int 38 55 43 53 65 60 38 35 48 64 ...
## $ Land : Factor w/ 4 levels "Deutschland",..: 1 4 2 3 1 4 2 3 1 4 ...
## $ Vertrauen : int 3 2 2 3 3 2 2 1 2 2 ...
## $ Geschlecht: Factor w/ 2 levels "männlich","weiblich": 2 1 NA 1 2 1 1 2 1 1 ...
## $ Medium : Factor w/ 4 levels "Internet","Internet-Medien",..: 1 1 3 3 4 4 1 2 2 2 ...
## $ X : logi NA NA NA NA NA NA ...Bild: Datensatz für Tutorial 5
6.1 Deskriptive Statistik
Sie können sich in R sehr einfach die wichtigsten deskriptiven Werte zu Ihren Variablen ausgeben lassen. Folgende Befehle können Sie dafür nutzen.
6.1.1 Absolute Werte
Die absoluten Werte, d.h. wie oft eine individuelle Ausprägung vorkommt, können Sie sich über den Befehl table() ausgeben lassen. Das ist v.a. für nominale Variablen sinnvoll, wo Sie eher daran interessiert sind, wie oft eine Ausprägung vorkommt:
##
## Deutschland Frankreich Italien Schweiz
## 250 250 250 250Sie können sich auch für z.B. metrische Variablen wie das Alter das Vorkommen aller Ausprägungen dieser Variablen ausgeben lassen (auch wenn diese Information in vielen Fällen wenig nützlich sein wird):
##
## 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57
## 17 23 22 16 16 22 13 20 26 20 18 18 18 9 25 26 12 19 19 14 24 25 21 18 19 30 20 22 29 24 16 24 29 29 14 17 20 21 26 25
## 58 59 60 61 62 63 64 65
## 26 19 19 20 25 19 20 266.1.2 Mittelwert, Standardabweichung, etc.
Für metrische Variablen ist der Mittelwert vermutlich interessanter:
## [1] 42.392Vielleicht interessiert Sie aber auch der Medien:
## [1] 43Sie können sich auch die Standardabweichung ausgeben lassen:
## [1] 13.73904… oder die kleinsten (Minimum) oder grössten Werte (Maximum), die diese Variable in Ihrem Datensatz annimmt:
## [1] 18## [1] 65Eine schöne Zusammenfassung aller dieser und weiterer Werte bietet der Befehl summary():
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 18.00 31.00 43.00 42.39 54.00 65.00Zuletzt wissen Sie ja bereits, wie Sie diese Werte auf beliebig viele Nachkommastellen runden - mit dem Befehl round():
## [1] 42.392## [1] 42.39## [1] 42.3926.1.3 Fehlende Werte
Zuletzt wollen Sie ggf. wissen, wie viele fehlende Werte Sie in Ihren Daten haben. Ob Sie fehlende Werte haben, können Sie mit dem bereits bekannten Befehl is.na() herausfinden. Probieren wir den Befehl einmal für die Variable “Geschlecht”:
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE
## [20] FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE TRUE
## [39] TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
## [58] FALSE TRUE FALSE TRUE FALSE TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE FALSE TRUE TRUE TRUE
## [77] FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE
## [96] TRUE TRUE TRUE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
## [115] FALSE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE TRUE FALSE
## [134] TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE TRUE
## [153] FALSE TRUE FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE
## [172] TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
## [191] FALSE TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE
## [210] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
## [229] FALSE TRUE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
## [248] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE
## [267] FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
## [286] FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE FALSE TRUE TRUE FALSE FALSE
## [305] TRUE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE
## [324] FALSE TRUE TRUE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE
## [343] FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
## [362] TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE
## [381] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE TRUE FALSE FALSE
## [400] FALSE TRUE FALSE TRUE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE
## [419] FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE FALSE
## [438] TRUE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
## [457] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE TRUE FALSE FALSE
## [476] TRUE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE TRUE TRUE FALSE TRUE
## [495] FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE FALSE FALSE TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE FALSE
## [514] TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE TRUE FALSE
## [533] TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE
## [552] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE TRUE FALSE
## [571] TRUE FALSE TRUE FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE
## [590] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
## [609] TRUE TRUE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
## [628] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
## [647] FALSE FALSE FALSE TRUE FALSE TRUE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
## [666] FALSE TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE FALSE
## [685] TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
## [704] FALSE TRUE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [723] TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE TRUE FALSE FALSE TRUE
## [742] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE TRUE FALSE TRUE TRUE TRUE TRUE
## [761] FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE
## [780] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE
## [799] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE TRUE FALSE
## [818] FALSE FALSE TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE TRUE TRUE FALSE FALSE TRUE FALSE TRUE FALSE
## [837] FALSE FALSE TRUE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE
## [856] TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE
## [875] FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE
## [894] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE FALSE TRUE FALSE
## [913] TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
## [932] TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
## [951] TRUE FALSE TRUE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
## [970] TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE FALSE
## [989] FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUEWir sehen also: Wir haben fehlende Werte. Aber so gross wie unser Datensatz ist, macht es keinen Sinn, die Summe der fehlenden Werte so auszuhälen. Die Summe an fehlenden Werten für diese Variable gibt uns R folgendermassen aus:
## [1] 341Zuletzt können wir uns einen Datensatz data_subset herausgeben lassen, der uns nur die Fälle ausgibt, in denen wir in keiner der Variablen fehlende Werte haben. Das geht über den Befehl complete.cases():
## [1] 06.2 Daten zu einem höheren Level aggregieren
In manchen Fällen kann es sein, dass wir Fälle auf einer höheren Ebene aggregieren, d.h. verdichten, wollen. Beispielsweise könnte es sein, dass wir uns das durchschnittliche Alter der Befragten nach Land ausgeben lassen wollen und diese Werte in einem neuen Objekt in R abspeichern wollen. Hierfür nutzen wir wieder dplyr:
- Wir definieren das Objekt, den Dateframe data, mit dem wir arbeiten wollen: data
- Wir übergeben dieses Objekt an unsere Pipeline: %>%
- Wir aggregieren die Daten auf einer höheren Ebene, hier das Land, dem die individuellen Befragten angehören: group_by(Land)
- Wir erstellen eine neue Variable, hier Alter, die den Mittelwert je Land angibt: summarise(Alter = mean(Alter)
- Wir weisen das Ergebnis einem neuen Objekt data_Land zu: data_Land <-
In R sieht diese Befehlkette so aus:
Der erzeugte Datensatz gibt uns dann den Mittelwert des Alters der Befragten nach Land aus:
## # A tibble: 4 x 2
## Land Alter
## <fct> <dbl>
## 1 Deutschland 43.0
## 2 Frankreich 41.3
## 3 Italien 43.1
## 4 Schweiz 42.3Wir überprüfen unser Ergebnis, indem wir uns den Mittelwert des Alters in unserem ursprünglichen Datensatz ausgeben lassen. Dabei berechnen wir den Mittelwert für die Variable Alter, aber jeweils nur für die Zeilen, die bei der Spalte Land das jeweilige Land vermerkt haben. Hier runden wir das Alter auf zwei Nachkommastellen, ähnlich wie in unserem Datensatz data_Land:
# ungerundeter Mittelwert
mean <- mean(data$Alter[data$Land=="Deutschland"])
#gerundeter Mittelwert
round(mean,1)## [1] 43## [1] 43## [1] 41.3## [1] 43.1## [1] 42.36.3 Take Aways
- Deskriptive Statistik: Befehle: table(), mean(), median(), sd(), summary(), is.na(), sum(is.na(x)), complete.cases(), round()
- Objekte aggregieren: Befehle: group_by, summarize
6.4 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
6.5 Benotete Aufgabe in R I
Achtung: Bei der nachfolgenden Aufgabe handelt es sich um die erste benotete Aufgabe in R. D.h., die fristgerechte Abgabe dieser Aufgabe ist eine benotete Leistungsabgabe.
Bitte bearbeiten Sie die Aufgabe in Gruppen von mind. 2 und maximal 3 Personen. Die Gruppenaufteilung wird in der Seminarsitzung vom 03. November vorgenommen.
Bitte nutzten Sie für die Abgabe Ihrer Lösungen das vorgegebene R-Template (via OLAT: Materialien / Templates/ Benotete Aufgabe in R_1.R).
Laden Sie für die Bearbeitung der Aufgaben den folgenden Datensatz herunter: Daten_Tutorial 6_Aufgabe.csv (via OLAT: Materialien / Datensätze für R).
Es handelt sich hierbei um den Datensatz, den Sie schon aus der Aufgabe zu Tutorial 5 kennen. Der Datensatz ist eine fiktive Umfrage unter Bürger:innen, für die folgende Variablen erfasst wurden:
- das Alter
- das Geschlecht
- das monatliche Einkommen
- der Schulabschluss
- das Land, in dem der/die Befragte lebt
6.5.1 Aufgabe 6.1
Lesen Sie den Datensatz ein. Lassen Sie sich folgende deskriptive Statistiken herausgeben:
- wie oft welcher Schulabschluss im Datensatz vorkommt (absolute Anzahl)
- den Mittelwert des Alters der Teilnehmer:innen (gerundet auf 1 Nachkommastelle)
- die Standardabweichung des Alters der Teilnehmer:innen (gerundet auf 1 Nachkommastelle)
6.5.2 Aufgabe 6.2
Können Sie mit R berechnen, wie oft welcher Schulabschluss je Land vorkommt (in absoluten Werten)? Erstellen Sie einen neuen Dataframe mit dem Namen data2, in dem Sie die absolute Anzahl an Schulabschlüssen je Land abspeichern.
Tipp: Sie müssen sich die absolute Häufigkeit der Schulabschlüsse ausgeben lassen und diese als Dataframe abspeichern. Der Dataframe data2 soll drei Spalten (d.h., Variablen) beinhalten, die Spaltennamen “Land”, “Schulabschluss” und “absolut” tragen.
Achtung: Hier könnte googlen helfen, um herauszufinden, wie man Spaltennamen eines Dataframes setzt.
6.5.3 Aufgabe 6.3
Erstellen Sie einen neuen Dataframe mit dem Namen data3, der nur Teilnehmer:innen enthält, die weiblich sind und über 54, aber unter 68 Jahre alt. Lassen Sie sich dann die Anzahl Teilnehmer:innen ausgeben, indem Sie die Zeilen dieses Dataframes zählen.
Wichtig: Achten Sie darauf, dass Sie nur Teilnehmer:innen behalten, die sowohl Alter als auch Geschlecht angegeben haben, d.h. es sollten im Dataframe data3 keine fehlenden Werte bei diesen Variablen vorhanden sein.
6.5.4 Aufgabe 6.4
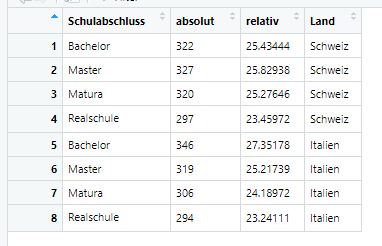
Bitte erstellen Sie einen neuen Dataframe data4, der nur für Befragte aus der Schweiz und Italien folgende Informationen enthält:
- die absolute Anzahl an Schulabschlüssen (getrennt ausgewiesen für Schweizer und Italiener Befragte)
- die relative Anzahl an Schulabschlüssen (getrennt ausgewiesen für Schweizer und Italiener Befragte)
Der endgültige Dataframe soll so aussehen:
Zu erstellender Datensatz in Aufgabe 6.5
Die Lösungen finden Sie bei Lösungen zu Tutorial 6.
Wir machen weiter: mit Tutorial 7: Funktionen & Bedingungen in R.