10 Tutorial 10: Einlesen & Datentypen
In Tutorial 10 lernen Sie:
- wie Sie Text-Files in R einlesen
- welches die klassischen Datentypen für Texte in R sind
Bitte denken Sie daran, dass wir das Einlesen von text-Files schon einmal besprochen haben. In: Tutorial 4: Daten ein-/auslesen & inspizieren, im Abschnitt 4.1.2. Daher gehen ich hier nur kurz auf das Einlesen von Texten ein.
10.1 Einlesen von Text-Files & Encoding-Probleme
Laden Sie als Beispiel bitte die drei Text-Dateien aus OLAT herunter (via: Materialien / Datensätze für R). Bei diesen Dateien handelt es sich um drei Nachrichtenartikel zum Thema Klimawandel.
Für das Einlesen von Text nutzen wir das readtext-Package. Wir sagen R, dass er alle Files in unserem Arbeitsverzeichnis einlesen soll, die eine .txt-Endung haben. Der Stern * kennzeichnet, dass der Filename beliebige Zeichen enthalten vor der .txt.-Endung enthalten kann. Sie merken also: Hier arbeiten wir wieder mit Regular Expressions.
Anders gesagt: R soll alle Dateien im Arbeitsverzeichnis einlesen, die ein Text-Format haben.
Wichtig: Achten Sie beim Einlesen von Texten auf das Character Encoding von Texten.
Was ist Character Encoding?
Der Computer speichert einzelne Zeichen - etwa die Buchstaben “w”, “o”, “r” und “t”, die für “wort” stehen - über einen bestimmten numerischen Code (Bytes) ab, die jedem Zeichen zugeteilt werden. Ein Beispiel: “word” wird in Bytes als “01110111 01101111 01110010 01100100” abgespeichert.
Durch die Nutzung einer spezifischen Zeichencodierung, d.h. eines Character Encodings wird bestimmt, welcher numerische 01-Code für welches Zeichen, also beispielsweise für welchen Buchstaben steht. Character Encodings sind also quasi der Schlüssel, mit dem der Computer bestimmt, in welche Zeichen Bytes als numerische Informationen “übersetzt” werden - also für welches Zeichen der Binärcode “01110111” steht.
Das Problem: Es gibt unterschiedliche Encodings. Wie Sie wissen, enthalten viele Sprachen eigene Sonderzeichen - in der deutschen Sprache etwa die Buchstaben “ü” und “ä”. Diese werden vom Computer oft falsch eingelesen, falls dem Computer nicht klar gemacht wird, dass ein spezifisches Character Encoding für das Einlesen der Texte benutzt werden muss (und bspw. nicht das Standard-Encoding, mit dem Ihr Computer arbeitet).
Ein Beispiel: Das deutsche Wort “Übung” enthält das Sonderzeichen “ü”, was von R oft falsch eingelesen wird. Wir weisen das Wort Übung dem Objekt word zu und fragen jetzt das Encoding ab:
## [1] "latin1"Was passiert, wenn wir das Encoding ändern, z.B. auf das oft genutzte Standard-Encoding “UTF-8”?
Dann hat R den falschen “Schlüssel”, um das Wort für uns verständlich auszugeben:
## [1] "<dc>bung"R nutzt das festgelegte Encoding Ihres Computers, das Sie folgendermassen erfragen können (und welches sich von dem unterscheiden kann, das für meinen Computer ausgegeben wird):
## [1] "German_Switzerland.1252"Sie können R beim Einlesen von Texten R mittels readtext anweisen, mit welchem Encoding Texte eingelesen werden sollen.
Bild: Encoding beim Einlesen von Texten definieren
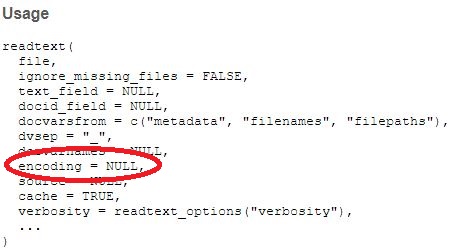
Wir haben hier kein Encoding spezifiert, weil wir keine Encoding-Probleme haben. R erkennt das richtige Encoding meist von alleine. Sie könnten aber auch andere Encodings spezifizieren, falls es Probleme beim Einlesen von Texten gibt. Oder - andernfalls - Encoding-Probleme durch Manipulation von Strings nachträglich bereinigen.
Schauen wir uns nun das Ergebnis an, sehen wir, dass R einen Dataframe eingelesen hat:
- docid: enthält Titel der eingelesenen Text-Datei
- text: enthält den Text der eingelesenen Text.Datei
Bild: Eingelesene Textdateien
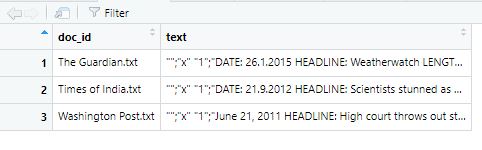
dataframe-Objekte sind ein Objekttyp, mit dem Sie in R Texte verarbeiten. Es gibt aber noch weitere - und zu diesen kommen wir jetzt.
10.2 Datentypen
Bevor wir mit der inhaltlichen Arbeit am Text beginnen, sollten Sie die vier Objekttypen kennen, in denen Ihnen Texte begegnen werden:
- data-frame-Objekte
- corpus-Objekte
- tokens-Objekte
- document-feature-matrizen oder DFM-Objekte
Wir arbeiten heute mit einem Text-Korpus, der im R-Package Quanteda-Corpora-Package bereits enthalten ist. Dieses Package ist noch im Entwicklungsstatus, d.h. noch nicht offiziell auf CRAN publiziert sondern nur über die Entwicklerplattform Github verfügbar. Der Einfachheit halber habe ich Ihnen den benötigen Korpus heruntergeladen und bereits in ein R-Environment eingelesen.
Sie finden den Korpus in OLAT (via: Materialien / Datensätze für R) mit dem Namen immigration_news.rda.
Bei diesen Dateien handelt es sich um Nachrichtenartikel aus Grossbritannien zum Thema Immigration aus dem Jahr 2014, die (leicht bearbeitet) bereits als R-Environment abgespeichert wurde. Die Daten befinden sich in einem ähnlichen Format, wie Sie sie erhalten würden, wenn Sie ihre Text mit dem readtext-Package einlesen würden.
Quelle der Daten: Nulty, P. & Poletti, M. (2014). “The Immigration Issue in the UK in the 2014 EU Elections: Text Mining the Public Debate.” Presentation at LSE Text Mining Conference 2014. Geladen via Quanteda-Corpus_Package.
10.2.1 Dataframes
Der Textkorpus zu Immigration, mit dem wir in dieser Sitzung arbeiten, wurde mit dem readtext-Package eingelesen.
Das Package speichert Ihre Texte in einem dataframe-Objekt ab, das aus so vielen Zeilen besteht, wie Sie Texte eingelesen haben, d.h. der Anzahl Ihrer Beobachtungen, und aus zwei Spalten, nämlich docid und text.
## 'data.frame': 2833 obs. of 2 variables:
## $ doc_id: chr "text1" "text2" "text3" "text4" ...
## $ text : chr "support for ukip continues to grow in the labour heartlands and miliband should be scared\nby leo mckinstry \"| __truncated__ " \nnews\n30 lawless migrants try to reach uk each night\ngiles sheldrick \n402 words\n14 april 2014\nthe dai"| __truncated__ " \nnews\n30 lawless migrants try to reach uk each night\ngiles sheldrick \n610 words\n14 april 2014\nthe dai"| __truncated__ " \nnews\n£10m benefits scandal\nmartyn brown \n151 words\n14 april 2014\nthe daily express\ntheexp\n1 nation"| __truncated__ ...Bild: Immigration-News Datensatz

Wenn Sie sich also einen einzelnen Text anschauen wollen, können Sie diesen über den Vektor text im dataframe-Objekt data ganz bequem aufrufen. Wir wollen uns hier als Beispiel den Text Nr. 100 im Korpus anschauen:
## [1] "nick cleggs blunt solution to knife crime\nby nick ferrari \n1304 words\n11 may 2014\n0100\nexpresscouk\nexco\nenglish\ncopyright 2014 \nit is very easy to have a go at deputy prime minister nick clegg\nindeed last week the labour party bizarrely decided to devote its entire party political broadcast to belittling him seeking to portray him as a bullied put upon wimp who is routinely ignored by coalition cabinet colleagues\nnever mind that top of most sane people's worry list is the economy jobs immigration national security or the state of the health service labour lavished a considerable sum to send up nick clegg in a film that was humourless pointless and left most people feeling they could not care less\nas someone in the media who probably knows mr clegg as well as anyone i can assure you he is too robust and steadfast for this to have fazed him for even a heartbeat\nhowever what desperately does require more scrutiny is his avowed intent to block conservative plans for a crackdown on knife crime\nthis was promised in david cameron's manifesto in 2010 but was another victim of the fact that the tories managed to blast the ball over the bar in front of the empty goal of that general election and needed a coalition with the lib dems to get into power\nin truth the commentators and political chatterati have been deeply dismayed by how little the coalition has fought and how well in most areas it has performed\nhence they seize on any bit of discord and treat it as if it were fisticuffs across the cabinet table\nthis bold stance by clegg could be the one however that causes a good old-fashioned rumpus and possibly demonstrates that despite taking all the calls we have done together down the months he might not always have been listening\npartly spurred on by the stabbing to death of a teacher in her classroom the conservatives want to introduce automatic jail terms for repeat knife offenders a \"two strikes and you're in\" kind of policy but clegg is adamantly against it\nhe dismisses it as an attempt to introduce \"headline-grabbing solutions\" in the wake of the killing of ann maguire\nhe goes on to claim it could \"turn the young offenders of today into the hardened criminals of tomorrow\" and calls it \"a backwards step that will undermine the government's rehabilitation revolution\"\nthis is high stakes stuff for mr clegg and if as is being mooted the labour party opts to support the conservatives at a time when the lib dems' poll ratings are bouncing on the bottom and in one case they are being beaten even by the green party clegg's party risks being stranded on a political peninsula\nclegg is a shrewd strategist and is that rare politician who usually actually stands by his beliefs however unpopular they might be\nas the calls came in last week he did not move an inch on his trenchant opposition"10.2.2 Corpus
Ein zweiter Objekttyp, mit dem Sie für die Analyse von Text via quanteda arbeiten werden, ist der Objekttyp corpus.
Sie können den corpus-Objekttyp ähnlich verstehen wie einen dataframe, der Ihnen zeilenweise einzelne Texte ausgibt und spaltenweise Variablen zu diesen Texten, wie den Namen des jeweiligen Textes.
Warum brauchen wir corpus-Objekte, wenn wir ähnliche Informationen schon im dataframe-Format haben?
Ganz einfach: Weil es im quanteda-Package viele sinnvolle Funktionen gibt (etwa, dass wir uns als einzelne Zeilen nicht ganze Texte, sondern einzelne Sätze aus Texten ausgeben lassen), die sich nicht direkt auf ein dataframe-Objekt anwenden lassen.
Wie erstellen wir einen corpus-Objekttyp in R?
Ganz einfach: Indem wir das quanteda-Package aktivieren und dann den corpus-Befehl nutzen. Falls Sie das Package noch nicht installiert haben, müssen Sie dies zuerst machen:
## Corpus consisting of 2,833 documents.
## text1 :
## "support for ukip continues to grow in the labour heartlands ..."
##
## text2 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text3 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text4 :
## " news £10m benefits scandal martyn brown 151 words 14 a..."
##
## text5 :
## " news taxpayers £150m bill to oust illegal immigrants gile..."
##
## text6 :
## " news un expert hits at boys club sexism in britain helene..."
##
## [ reached max_ndoc ... 2,827 more documents ]Sie sehen also, dass R ein corpus-Objekt erstellt hat. Dieses besteht aus 2,833 Dokumenten - was nicht überraschend ist, denn genau diese Anzahl Zeilen hatte das dataframe-Objekt data, das wir in ein Corpus-Objekt umgewandelt haben.
Der Vorteil an einem corpus-Objekt ist, dass Sie Dokument-Variablen zu den einzelnen Texten abspeichern können, die Sie später für Analysen nutzen können. Beispielsweise hatten wir die Namen unserer Texte im Dataframe data in der Spalte doc_id abgespeichert:
## [1] "text1" "text2" "text3" "text4" "text5" "text6"Wenn Sie später Analysen mit Text durchführen, wollen Sie ggf. in die ursprünglichen Texte schauen, die Sie in Ihrem Arbeitsverzeichnis als .txt-Dateien abgespeichert hatten. Dafür müssen Sie natürlich wissen, welches Dokument zu welchem Text gehört.
Das heisst: Sie wollen die jeweiligen Dokumentnamen eines Textes, jetzt abgespeichert in data$doc_id, dem richtigen Text im corpus-Objekt corpus zuordnen.
quanteda lässt dies ganz einfach zu, in dem Sie beim Einlesen des corpus sogenannte document-level-Variablen definieren, die den jeweiligen Texten zugeordnet werden. Diese können Sie sich via docvar() dann ausgeben lassen:
## Corpus consisting of 2,833 documents and 1 docvar.
## text1 :
## "support for ukip continues to grow in the labour heartlands ..."
##
## text2 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text3 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text4 :
## " news £10m benefits scandal martyn brown 151 words 14 a..."
##
## text5 :
## " news taxpayers £150m bill to oust illegal immigrants gile..."
##
## text6 :
## " news un expert hits at boys club sexism in britain helene..."
##
## [ reached max_ndoc ... 2,827 more documents ]## ID
## 1 text1
## 2 text2
## 3 text3
## 4 text4
## 5 text5
## 6 text6Ein häufiges Beispiel für eine document-level-Variable, die wir benötigen, ist, das Publikationsdatum eines Artikels.
Das Poblem: Wir haben das Publikationsartikel der Artikel nicht vorliegen. Wie bekommen wir diese Information?
Wir wissen, dass unsere Texte nur aus dem Jahr 2014 kommen. Dh., wir können bereits das Jahr 2014 als document-level-Variable abspeichern:
corpus <- corpus(data$text,docvars = data.frame(ID = data$doc_id, year = rep("2014", nrow(data))))
print(corpus)## Corpus consisting of 2,833 documents and 2 docvars.
## text1 :
## "support for ukip continues to grow in the labour heartlands ..."
##
## text2 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text3 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text4 :
## " news £10m benefits scandal martyn brown 151 words 14 a..."
##
## text5 :
## " news taxpayers £150m bill to oust illegal immigrants gile..."
##
## text6 :
## " news un expert hits at boys club sexism in britain helene..."
##
## [ reached max_ndoc ... 2,827 more documents ]## ID year
## 1 text1 2014
## 2 text2 2014
## 3 text3 2014
## 4 text4 2014
## 5 text5 2014
## 6 text6 2014Jetzt wollen wir aber noch den Publikations-Monat erhalten. Nur wie?
Schauen wir uns beispielhaft noch einmal zwei zufällige Texte an:
## [1] " \nfrontpage\nshould nigel farage have stuck to his guns newark might just have voted him in\njonathan brown \n725 words\n1 may 2014\n1002\nindependent online\nindop\nenglish\n© 2014 independent print ltd all rights reserved \nnigel farage will never know whether newark was set to join the ranks of bermondsey hamilton or bradford west in the political atlas of great by-election upsets\nyet if the mood in the nottinghamshire town's georgian market place was anything to go by yesterday the decision not to contest the vacant seat could go down as one of missed opportunity rather than inspired tactical retreat\nbutcher michael thorne 48 was an unabashed fan of mr farage having spent 15 minutes in the ukip leader's company at a recent market day\n\"he is a down-to-earth bloke and he doesn't beat around the bush it's about time we had someone like that\" he said \"it's about british people for british jobs as far as i'm concerned we need to support as many local people as we can\" he added\ncustomer terence dilger 65 was pondering what to have for his dinner he was less equivocal in voicing his support for mr farage\n\"i think he is right on immigration - it is as simple as that\" he said \"when i first came to newark it was an ordinary town now it is a league of nations you feel like a stranger in your own town even if he didn't win he would have got his message across\"\naccording to the 2011 census figures newark and neighbouring sherwood remain remarkably homogenous from a population of 114000 some 94 per cent describe themselves as white british the number of residents from eu accession states was just 18 per cent - just over 2000 people and lower than the english average but that is not the perception\napril 2014 a month of ukip gaffes and controversies\nshopper yvonne mastin 61 was happy to repeat one of ukip's slogans she had read on a leaflet recently put through her door \"we do want britain back to how it used to be it's got totally out of hand\" she said \"i believe in immigration if they have got something to bring\" she said\nover at his stall selling mobility scooters was kevin walker 54 also a farage fan \"a vote for him is a vote not for the other two\" he said \"there are too many of them [immigrants] whoever said they are not taking our jobs is talking rubbish if you go to the fields around here see how many of them speak english\n\"it's the same anywhere you go now i do a lot of care homes and they are all foreign staff it's not because we won't do the jobs it's because they won't kick up a fuss and they are cheaper they will work long hours but it is not right\" he added\nukip is currently looking for a candidate to stand in the seat in which it came fourth with just 38 per cent of the vote in 2010\nthe conservatives have selected robert jenrick - international business director at christie's - i"## [1] " \nexpats wish you lived here\nby christopher middleton \n1727 words\n26 april 2014\n0810\nthe telegraph online\nteluk\nenglish\nthe telegraph online © 2014 telegraph media group ltd \nas more brits bid adios to spain we seek new destinations for the expat dream\nfor us brits it's been the equivalent of a property dunkirk for years we have been happily sending out thousands of citizens to start a new life in spain - about 760000 sun-seekers have moved there since 1995 all of a sudden though the economic sun has gone behind the clouds and our bucket-and-spade brigades are withdrawing at an alarming rate according to official figures some 90000 of us have forsaken the costas and returned to these shores\nthe news has sent the nation rushing to our atlases to seek out new spots in which to settle it's estimated that between 45 and 47 million british citizens live abroad for at least part of the year\nquestion is when the world is your oyster how do you find a place to live that is a genuine pearl here are some suggestions…\naustralia\nestimated number of expat brits 11 to 12 million\nmost popular areas sydney melbourne perth\nproperty prices in sydney you pay £550000 for a three-bed hou>se in perth you pay the same for a four-bed house with sea views\nflight time to uk 20 hrs 45mins from sydney\nclimate sydney averages 26c 78f and 16c 60f in summer and winter perth 31c 87f and 18c 64f\ncost of a pint of beer 65 australian dollars £360\ncost of restaurant meal 40 australian dollars £22\nthe good points australia tops the natwest international personal banking quality of life survey it's been in the top three since 2009 you'll still get your uk pension too albeit frozen from when you arrive\nnot-so-good points more british expats than any other country in the world\nwhat you'd miss about the uk understatement\nunited states of america\nestimated expat brits 829000\nmost popular areas there's a smattering of us in the big cities but we're at our most concentrated in florida one study says more brits migrate to the us than from any other nation legally that is\nproperty prices in florida you can get a humble one-bed condominium apartment for £25-£40000 or an up-market four-bedroom villa for under £250000\nflight time to uk 11 hours from the west coast seven hours from the east\nclimate average minimum 167c 62f average maximum 28c 82f orlando has 107 days per year where temperatures are 32c 89f or more\ncost of a pint of beer $382 £227\ncost of restaurant meal $30 £17\nthe good points big portions big country year-round warmth that's why they call florida the sunshine state - or is it the orange juice state\nnot-so-good points if you're working you get very little holiday per year nine-10 days and the cost of health insurance is enough to make you feel quite ill\nwhat you'd miss pessimism\ncanada\nestimated expat br"Wir sehen, dass die Texte nach der Überschrift und der Anzahl von Wörtern zu Beginn jedes Textes das Publikationsdatum enthalten. Die komische Zeichenabfolge //n ignorieren wir hier erstmal - ich gehe später darauf ein, wofür sie steht.
- Text Nummer 1000 scheint am 1. Mai publiziert worden zu sein, denn der Text enthält den folgenden Text-String: “1 may 2014”
- Text Nummer 2000 scheint am 26. April publiziert worden zu sein, denn der Text enthält den folgenden Text-String: “26 april 2014”
Wie können wir für alle Texte jetzt systematisch den Publikationsmonat herausschreiben und als document-level-Variable abspeichern?
Hier können wir wieder die str_extract()-Funktion nutzen, die Sie schon kennen.
Die Funktion str_extract gibt uns das erste Mal, wenn unser pattern (das Publikationsdatum) in unseren Texten string (unsere Artikel zum Thema Immigration) vorkommt, das entsprechende pattern, das gematched wurde (das Publikationsdatum), zurück:
Die str_extract-Funktion benötigt den folgenden Input:
- string: ein Character-Vektor, in dem wir nach unserem pattern suchen. Hier also einfach die Texte aus unserem Korpus: data$text
- pattern: String, nach dem wir suchen. In unserem Fall ist das der Monat im Jahr 2014, in dem der Artikel publiziert wurde. Dieses pattern müssen wir uns noch überlegen: “?????”
Die Funktion, um den Text-String, der das Publikationsmonat enthält, aus unserem Text zu extrahieren, sähe also etwa so aus:
Jetzt ist einzig die Frage offen, wie wir unser pattern richtig formulieren.
Wir erinnern uns: Der Monat ist z.B. in so einem Format im Text angegeben: “1 may 2014”
Das Search-Pattern soll so flexibel sein, dass es:
- Die Wörter “january” oder “february” oder “march” oder “april” oder “may” oder “june” oder “july” oder “august” oder “september” oder “october” oder “november” oder “december” im Text findet.
- Die zuvor genannten Wörter nur findet, wenn sie nach einer ein- bis zweistelligen beliebigen Zahl und vor dem string 2014 vorkommen.
Denn: Theoretisch könnten Monate auch im Text eines Artikels genannt werden, ohne dass sie dort den Publikationsmonat des Artikels bezeichnen. Z.B. könnte ein Artikel den Satz enthalten: “The financial crisis is going to hit in december”.
Dann wollen wir nicht, dass R aus Versehen den Monat “Dezember”, der im Text genannt wird, für das Publikationsdatum des Artikels hält.
Da wir nun wissen, dass der Publikationsmonat des Artikels immer nach dem Tag der Publikation, d.h., nach einer ein- bis zweistelligen beliebigen Zahl, und vor dem Publikationsjahr, d.h., 2014, vorkommt, können wir diese beiden Strings nutzen, um sicherzustellen, dass R an der richtigen Stelle der Textdateien den Monat ausliest.
Wir nutzen zudem die Funktion str_extract(), die nur den ersten Matches eines patterns ausliest, um sicherzugehen, dass nicht andere Daten im Text ausgelesen werden. Denn: Der erste Match wird vermutlich das Publikationsdatum sein. Wir könnten mit str_extract_all() auch alle Matches für das pattern je Text auslesen - aber da ist die Gefahr grösser, dass wir ein falsches Datum auslesen, das in ähnlichem Format vorkommt, wie das Publikationsdatum des Artikels.
Ein pattern, dass uns den Monat ausgibt, der nach dem String einer ein- bis zweistelligen beliebigen Zahl und vor dem String 2014 vorkommt, sieht so aus:
data$month <- str_extract(string = data$text,
pattern = "[0-9]+ (january|february|march|april|may|june|july|
august|september|october|november|december) 2014")Was sagt uns dieses pattern?
- [0-9]+: Wir weisen R an, nach beliebigen Zahlen von 0-9 zu suchen, [0-9], die mindestens einmal vorkommen sollen, aber auch öfter vorkommen können, +. Denn z.B. könnte der Publikationstag der 1. Mai sein (eine Zahl) als auch der 22. Mai (zwei Zahlen).
- Anschliessend soll ein Leerzeichen folgen. Wir müssen das pattern also so flexibel schreiben, dass es eine ein bis zweistellige Zahl erfasst.
- (january|february|march|april|may|june|july|august|september|october|november|december): Danach soll das Wort january oder das Wort february oder das Wort march oder das Wort april oder das Wort may oder das Wort june oder das Wort july oder das Wort august oder das Wort september oder das Wort october oder das Wort november oder das Wort december vorkommen.
- Anschliessend soll ein Leerzeichen folgen.
- 2014: Anschliessend soll die Zahlenfolge 2014 folgen.
Das scheint funktioniert zu haben: Die Funktion hat uns das richtige String-Pattern für jeden Text extrahiert. Aber: In dem Vektor, der den Monat enthält, sind jetzt noch eine Menge anderer Informationen enthalten, die wir nicht benötigen.
## [1] "10 april 2014"Diese können wir löschen, indem wir aus unserem String-Pattern nur den Monat behalten. Wir weisen R also an, aus dem extrahierten String data$month nur die Wörter, die einen Monat bezeichnen, zu extrahieren:
data$month <- str_extract(string = data$month,
pattern = "january|february|march|april|may|june|july|
august|september|october|november|december")
data$month[1]## [1] "april"Lassen wir uns die Monatsvariable data$month ausgeben, sehen wir, dass die Monate für alle Texte richtig ausgelesen wurden:
##
## april february march may
## 835 252 933 813Jetzt nehmen wir diesen Vektor data$month im Dataframe data und weisen ihn dem corpus-Objekt als document-level-Variable zu:
corpus <- corpus(data$text,docvars = data.frame(ID = data$doc_id,
year = rep("2014", nrow(data)), month = data$month))
print(corpus)## Corpus consisting of 2,833 documents and 3 docvars.
## text1 :
## "support for ukip continues to grow in the labour heartlands ..."
##
## text2 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text3 :
## " news 30 lawless migrants try to reach uk each night giles..."
##
## text4 :
## " news £10m benefits scandal martyn brown 151 words 14 a..."
##
## text5 :
## " news taxpayers £150m bill to oust illegal immigrants gile..."
##
## text6 :
## " news un expert hits at boys club sexism in britain helene..."
##
## [ reached max_ndoc ... 2,827 more documents ]## ID year month
## 1 text1 2014 april
## 2 text2 2014 april
## 3 text3 2014 april
## 4 text4 2014 april
## 5 text5 2014 april
## 6 text6 2014 aprilZurück zu den Objekttypen für Text in R: Wir haben jetzt also ein corpus-Objekt erstellt, in dem unsere Dokumente mit den zugehörigen Korpus-Variablen abgespeichert wurden. Wollen wir uns für eine kleine Anzahl Dokumente relevante Infos - etwa die Korpus-Variablen - ausgeben lassen, können wir folgenden Befehl nutzen:
## Corpus consisting of 5 documents, showing 5 documents:
##
## Text Types Tokens Sentences ID year month
## text1 266 449 1 text1 2014 april
## text2 245 414 1 text2 2014 april
## text3 295 516 1 text3 2014 april
## text4 120 170 1 text4 2014 april
## text5 293 480 1 text5 2014 aprilDer summary-Befehl gibt uns noch einige weitere nützliche Infos über unseren Korpus: Nicht nur wissen wir jetzt, dass die ersten fünf Texte alle im April publiziert wurden. Der summary-Befehl gibt uns auch aus, wie viele Types, Tokens und Sentences jedes Dokument enthält:
- Types: die Anzahl an unterschiedlichen Features, d.h. die Anzahl an unterschiedlichen Wörtern.
- Tokens: die Anzahl aller Features, d.h. die Anzahl aller Wörter
- Sentences: die Anzahl aller Sätze. Eine Info hierzu: Da der Datensatz immigration_news.rda keine Satzzeichen mehr enthält - also z.B. alle Punkte entfernt wurden - und quanteda die Anzahl Sätze über u.a. Satzzeichen berechnet (jeder Satz endet mit einem Satzzeichen wie Punkten oder Fragezeichen), ist diese Information sicher nicht richtig. Die meisten Artikel bestehen nicht aus nur einem Satz. R ist aber ohne Satzzeichen nicht in der Lage, die Anzahl aller Sätze richtig auszulesen.
Aber was sind Types und was sind Tokens? Und wofür brauchen wir sie? Das lernen wir jetzt:
10.2.3 Tokens & Tokenization
In automatisierten Inhaltsanalysen werden Texte nicht als Ganzes analysiert, sondern auf einzelne Features heruntergebrochen.
Features sind also die Analyseeinheit automatisierte Inhaltsanalysen und können sowohl einzelne Wörter, Wortketten, ganze Sätze, aber auch Nummern oder Satzzeichen sein.
Diesen Prozess der Umwandlung ganzer Texte in einzelne Features nennt man Tokenization.
In R funktioniert die Tokenization von Texten zu einzelnen Features mit diesem Befehl:
Das erste Dokument unseres Korpus würde nach der Tokenization folgendermassen aussehen:
## Tokens consisting of 1 document and 3 docvars.
## text1 :
## [1] "support" "for" "ukip" "continues" "to" "grow" "in" "the"
## [9] "labour" "heartlands" "and" "miliband"
## [ ... and 437 more ]Wir haben unsere Texte also jeweils in Listen verwandelt, in denen die Features des jeweiligen Textes einzeln aufgelistet werden.
Bei Features als Analyseeinheit von Texten kann man zwischen Types und Tokens unterscheiden:
- Types bezeichnet alle unterschiedlichen Features in Texten.
- Tokens bezeichnet alle Features in Texten.
Der Unterschied zwischen Types und Tokens lässt sich an einem einfachen Beispiel verdeutlichen:
sentence <- "Nach diesem Tutorial in R brauche ich erstmal eine Pause,
um mich zu sammeln und in R weiter machen zu können."
#Anzahl an Tokens im Satz
ntoken(sentence)## text1
## 23## text1
## 20Der Satz “Nach diesem Tutorial in R brauche ich erstmal eine Pause, um mich zu sammeln und in R weiter machen zu können.” besteht aus 23 Tokens (d.h., aus insgesamt 23 Features) und aus 20 Types (d.h. von diesen 23 Features sind 20 Features unterschiedlich). Denn: Die Wörter “R”, “in” und “zu” kommen im Satz jeweils zweimal vor, zählen also als 6 tokens, aber nur als 3 unterschiedliche types.
10.2.4 Document-Feature-Matrix
In vielen Fällen wollen wir aber nicht nur wissen, welche Features, hier Wörter, je Dokument vorkommen, wie durch die Tokenization im Objekt tokens angegeben.
Viel wichtiger ist die Frage: Welche Features kommen über verschiedene Dokumente hinweg vor? Wie ähneln oder unterscheiden sich Dokumente, wenn wir sie anhand ihrer Features vergleichen?
Um diese Frage zu beantworten, können wir eine sogenannte Document-Feature-Matrix (kurz DFM) nutzen.
Die Document-Feature-Matrix ist eine Matrix, in der die Zeilen die Dokumente bezeichnen, die unser Korpus enthält, und die Spalten die Features beinhalten, die über alle Dokumente hinweg vorkommen.
Nachdem wir unsere Texte auf Features heruntergebrochen haben, hilft die DFM uns also, Texte anhand ihrer unterschiedlichen Features, d.h. Types, miteinander zu vergleichen. Mittels der DFM können wir schauen, welche Gemeinsamkeiten oder Unterschiede sich zwischen Texten zeigen, wenn wir das Vorkommen von Features vergleichen.
## Document-feature matrix of: 2,833 documents, 41,995 features (99.4% sparse) and 3 docvars.
## features
## docs support for ukip continues to grow in the labour heartlands
## text1 2 5 7 1 5 1 17 28 8 2
## text2 0 1 1 0 19 0 9 26 0 0
## text3 0 1 1 0 22 0 10 28 0 0
## text4 0 4 0 0 3 0 2 8 0 0
## text5 0 9 1 0 8 0 11 17 0 0
## text6 0 1 0 0 4 0 8 11 0 0
## [ reached max_ndoc ... 2,827 more documents, reached max_nfeat ... 41,985 more features ]Was zeigt uns die Ausgabe an?
Unser Korpus besteht aus 2,833 Dokumenten. Die erste Zeile der DFM beschreibt den ersten Artikel, die zweite den zweiten Artikel, usw.
Wir haben 41,995 Features, die über alle 2,833 Dokumente hinweg vorkommen. Diese Features sind also Types, d.h. unterschiedliche Features, die im Text vorkommen. In unserem Fall haben wir durch die Tokenization unsere Texte auf Wörter heruntergebrochen, d.h. unser ganzer Korpus enthält 41,995 Wörter. Die erste Spalte der DFM beschreibt das erste Feature, was gefunden wurde: das Wort support.
Die Zellen beschreiben, wie oft jedes Feature in jedem Dokument vorkommt. Beispielsweise kommt das Feature support zweimal im ersten Artikel vor, aber nie in Artikel 2-6, die hier auch angezeigt werden. Das Feature support scheint also nicht in allen Dokumenten vorzukommen. Hier zeigen sich bereits grosse Unterschiede zum Feature the in der achten Spalte: Sie sehen, dass the in allen Dokumenten vorkommt, teils sehr häufig.
Zudem zeigt uns R an, dass unsere DFM zu 99.4% “spare” ist. Was heisst das? Sparsity bezeichnet die Anzahl an Zellen, die eine 0 enthalten. D.h., 99.4% unserer Zellen in der DFM enthalten eine 0. Das ist nicht überraschend - während Wörter wie “the” oder “to” in vielen Texten vorkommen, wird das bei vielen anderen Wörtern wie “support” oder “continutes” nicht unbedingt der Fall sein. Viele Features kommen also in nur sehr wenigen Texten vor, während einige Features (the, and, or) in fast allen Texten vorkommen.
Wir können uns über die DFM auch ausgeben lassen, welche Features über alle Dokumente hinweg am häufigsten vorkommen, d.h. welche Wörter am häufigsten sind:
## the to of a and in that is for on it he was by as with are be from "
## 69066 34040 30360 27229 25144 22655 13396 12510 11042 9630 8257 8162 7997 7538 7530 6769 6469 6137 5975 5966Hier sehen wir schon, dass die Top-Features uns (noch) wenig Information einbringen. Die häufigsten Features sind klassische Stopwörter, d.h. Wörter, die wenig informativen Gehalt haben: the, to, of, a oder and. Wenn wir uns nur die häufigsten Wörter anschauen, würden wir z.B. kein Gefühl dafür kriegen, womit sich die Texte in unserem Korpus inhaltlich beschäftigen. Ausserdem sehen wir, dass R Satzzeichen - hier Anführungszeichen - als Wörter eingelesen und abgespeichert hat (letztes Top-Feature). Wenn wir als Features nur Wörter haben wollen, müssen wir diese also noch entfernen.
Um unsere Texte nur auf informative Features zu reduzieren, d.h. auf die Wörter, anhand derer sich Dokumente tatsächlich unterscheiden, müssen wir die Texte also bereinigen. Das hat auch den Vorteil, dass wir unsere Datenmenge, spezifisch die Menge an unterschiedlichen Features, reduzieren und damit einige Analyseverfahren schneller vorangehen. Wie das geht, lernen Sie im nächsten Tutorial.
10.3 Take Aways
Vokabular:
- Character-Encoding: Character Encoding bezeichnet den “Schlüssel”, mit dem der Computer bestimmt, in welche Zeichen Bytes als numerische Informationen “übersetzt” werden - und andersherum. Es geht also darum, wie der Computer Zeichen (z.B. Buchstaben oder Wörter) zu Zahlen zuordnet und verarbeitet.
- Ein Korpus ist wie ein Dataframe. Er beinhaltet als Zeilen die Artikel Ihre Korpus, also einzelne Texte, und als Spalten die zugehörigen document-level-Variablen, wie das Publikationsdatum.
- Als Tokenization bezeichnet man einen Prozess, bei dem Artikel Ihres Korpus auf einzelne Features - z.B. Wörter oder Sätze - heruntergebrochen werden.
- Als Features bezeichnet man die Analyseeinheit einer automatisierten Inhaltsanalyse, z.B. einzelne Wörter oder einzelne Sätze.
- Als Tokens bezeichnet man alle Features, die ein Text/Korpus enthält.
- Als Types bezeichnet man alle unterschiedlichen Features, die ein Text/Korpus enthält.
- Eine Document-Feature-Matrix bezeichnet eine Matrix, deren Zeilen die Artikel Ihres Korpus kennzeichnen und deren Spalten die Features Ihres Korpus kennzeichnen. In jeder Zelle wird angegeben, wie oft ein Feature in einem bestimmten Artikel vorkommt.
Befehle:
- Einlesen von Text-Files: readtext()
- Erstellung eines Korpus: corpus(), docvars()
- Tokenization: tokens()
- Erstellung einer Document-Feature-Matrix: dfm()
10.4 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
10.5 Benotete Aufgabe in R II
Achtung: Bei der nachfolgenden Aufgabe handelt es sich um die zweite benotete Aufgabe in R. D.h., die fristgerechte Abgabe dieser Aufgabe ist eine benotete Leistungsabgabe. Die Abgabe soll zum 30.11.2020 um 12 Uhr erfolgen.
Bitte bearbeiten Sie die Aufgabe in Gruppen von mind. 2 und max. 3 Personen.
Bitte nutzten Sie für die Abgabe Ihrer Lösungen das vorgegebene R-Template (via OLAT: Materialien / Templates/ Benotete Aufgabe in R_2.R).
Wir arbeiten wieder mit dem Textkorpus von Nachrichten zu Immigration.
Sie finden den Korpus in OLAT (via: Materialien / Datensätze für R) mit dem Namen immigration_news.rda. Bei diesen Dateien handelt es sich um Nachrichtenartikel aus Grossbritannien zum Thema Immigration aus dem Jahr 2014, die (leicht bearbeitet) bereits als R-Environment abgespeichert wurde. Die Daten befinden sich in einem ähnlichen Format, wie Sie sie erhalten würden, wenn Sie ihre Text mit dem readtext-Package einlesen würden.
Quelle der Daten: Nulty, P. & Poletti, M. (2014). “The Immigration Issue in the UK in the 2014 EU Elections: Text Mining the Public Debate.” Presentation at LSE Text Mining Conference 2014. Geladen via dem Quanteda-Corpus_Package.
10.5.1 Aufgabe 10.1
Laden Sie den Textkorpus über das R-Environment immigration_news.rda. Können Sie R anweisen, Ihnen auszugeben, wie viele Types und Tokens im ersten Dokument vorkommen?
10.5.2 Aufgabe 10.2
Können Sie R dann anweisen, Ihnen auszugeben, wie viele Types und Tokens in allen Dokumenten vorkommen, d.h. die Summe aller Types bzw. Tokens?
Erklären Sie kurz, wieso Sie die sich die Summe aller Types und die Summe aller Tokens unterscheiden.
10.5.3 Aufgabe 10.3.
Können Sie R anweisen, Ihnen nur Texte vom 15. April oder vom 15. Mai in einem corpus-Objekt mit dem Namen Texte_Tage auszugeben? Wie viele Dokumente erhalten Sie?
10.5.4 Aufgabe 10.4.
Können Sie im dataframe-Objekt data, d.h. für den vollen Korpus, eine Variable data$headline erstellen, welche nur die Überschrift des jeweiligen Artikels enthält?
Die Überschrift des jeweiligen Artikels wird hier als der Text verstanden, der vor der Wörteranzahl im Artikel erscheint. Sie sollen also einfach den gesamten Text auslesen, der vor der Wörteranzahl des jeweiligen Artikels genannt wird.
Die Lösungen finden Sie bei Lösungen zu Tutorial 10.
Wir machen weiter: mit Tutorial 11: Bereinigung von Text.