4 Tutorial 4: Daten ein-/auslesen & inspizieren
In Tutorial 4 lernen Sie:
- wie Sie Objekte (in den meisten Fällen Daten) ein- und auslesen
- wie Sie sich einzelne Elemente dieser Objekte anzeigen lassen
4.1 Objekte ein- und auslesen
Ob Excel-, Word-, oder PDF-Files: R kann so ziemlich jede Art von Daten über spezifische Funktionen ein- und auslesen. Wir besprechen hier nur die häufigsten Befehle je nach Datenformat.
4.1.1 .csv Files
Am häufigsten werden Sie CSV-Files einlesen. CSV-Files sind Text-Files, bei denen Werte - etwa Spalten, die häufig Variablen darstellen - durch einen Separator (etwa ein Komma oder ein Semikolon) abgetrennt werden. Viele Dateien, die Sie aus Excel kennen, sind beispielsweise CSV-Files.
4.1.1.1 Einlesen
Uns ist schon ein CSV-File über den Weg gelaufen: Unsere Umfrage, abgespeichert als “Beispiel-CSV”. Wir hatten dieses Excel-File mit folgendem Befehl eingelesen:
Wofür steht dieser Befehl? Schauen wir uns kurz die Hilfe an:
Bild: Hilfe zum Befehl

Der Befehl read.csv2 ist Teil des Packages utils. Für das Einlesen von CSV-Files gibt es zwei häufig genutzte Befehle: read.csv liest Dateien ein, in denen Spalten mit Komma abgetrennt werden; read.csv2 liest Dateien ein, in denen Spalten mit Semikolon abgetrennt werden. Ansonsten sind diese Funktionen gleich aufgebaut und bestehen aus mehreren Elementen, von denen wir nur einige spezifiziert müssen, um den Befehl wie gewünscht auszuführen.
- file: Hier wird der Name des einzulesenden CSV-Files identifiziert (inklusive der Endung der Datei, hier csv). Wir wissen, dass Text durch Anführungszeichen gekennzeichnet wird, daher definieren wir file als: file = “Beispiel-CSV.csv”
- header: Hier wird angegeben, ob die erste Zeile des Datensatzes die Namen der Variablen beinhaltet. Da dies in unserem CSV-File der Fall ist, definieren wir diese Bedingung als erfüllt, damit die Daten richtig eingelesen werden: header = TRUE
In den meisten Fällen wird es reichen, diese beiden Optionen zu definieren, damit R den Befehl korrekt ausführen und den Datensatz richtig einlesen kann.
Wichtig: R unterscheidet zwischen Funktions-Elementen, die definiert werden müssen und solchen, die definiert werden können. Die Elemente, welche nicht nur durch ein = gekennzeichnet sind, müssen definiert werden. Für den Befehl read.csv2 müssen Sie z.B. das Element file definieren, damit der Befehl funktioniert. Das erscheint sinnvoll: Wenn Sie R nicht sagen, was (file) R einlesen soll, kann der Befehl nicht durchgeführt werden. Alle anderen Befehle, bei denen mögliche Optionen durch ein = angegeben werden, sind obligatorisch. Das heisst, in den meisten Fällen wird der Befehl ohne Spezifikation dieser funktionieren - es kann aber Sinn machen, diese Element für Ihre Daten zu spezifizieren, damit diese richtig eingelesen werden. file (rot markiert) muss also spezifiziert werden, damit der Befehl ausgeführt werden kann. header (grün markiert) kann spezifiziert werden, etwa, damit die Daten richtig eingelesen werden. Theoretisch würde der Befehl auch ohne funktionieren - dann würde R aber fälschlicherweise die erste Zeile unseres Datensatzes nicht als Namen der Variablen sondern als erste Beobachtung einlesen (probieren Sie es einmal probeweise aus!).
Bild: Hilfe zum Befehl

Wichtig ist ausserdem, dass Sie die Elemente dieser Funktion auf zwei Arten füllen können.
- über ihren Namen, d.h., in dem Sie “file” und “header” in der Funktion spezifizieren:
- über ihre Position. D.h., Sie geben nicht an, welches Element wie genutzt werden soll, sondern R wird dies anhand der Reihenfolge der Elemente testen. Das erste Element “Beispiel-CSV.csv” wird file zugewiesen, das zweite Element “TRUE” header.
4.1.1.2 Ausschreiben
Nehmen wir an, dass wir unseren Datensatz in R verändert haben. Zum Beispiel könnte es sein, dass wir eine neue Variable Land hinzugefügt haben, die beschreibt, ob die Teilnehmer:innen aus der Schweiz kommen oder nicht (mehr zu diesen Formen von Datenmanipulation gibt es im nächsten Tutorial). Wir wissen, dass alle Teilnehmer:innen aus der Schweiz kommen. Wir erstellen die Variable Land, indem wir einen Vektor (Objektart) des Types Text (Datentyp) erstellen, der nur aus dem Wort “Schweiz” besteht. Dafür haben wir zwei Optionen: Entweder wir schreiben 20 mal hintereinander das Wort Schweiz aus (die weniger elegante Lösung) oder wir nutzen den Befehl rep, der das Wort “Schweiz” zwanzig mal wiederholt (die elegantere Lösung, die uns in der Lösung zur Übungsaufgabe im Tutorial 2 begegnet ist).
#die weniger elegante Lösung
Land <- c("Schweiz", "Schweiz","Schweiz", "Schweiz","Schweiz",
"Schweiz","Schweiz", "Schweiz","Schweiz", "Schweiz",
"Schweiz", "Schweiz","Schweiz", "Schweiz","Schweiz",
"Schweiz","Schweiz", "Schweiz","Schweiz", "Schweiz")
#die elegantere Lösung
Land <- rep("Schweiz",20)Nachdem wir den Vektor erstellt haben, können wir die Variable Land im Datensatz survey erstellen, indem wir die Variable Land im Datensatz survey als Vektor Land definieren. Im Prinzip sagen wir R, dass das Programm eine neue Variable Land erstellen soll, die aus dem Vektor Land besteht.
Wir könnten dies auch schneller machen, ohne den Vektor Land extra abzuspeichern, indem wir den Vektor erstellen und im gleichen Befehl als Variable Land im Datensatz survey definieren.
Vergewissern Sie sich, dass die fiktive Umfrage jetzt eine neue Variable beinhaltet, die das Land der Teilnehmer:innen beschreibt.
Wir schreiben das CSV-File jetzt über einen ähnlichen Befehl aus, wie der Befehl, mit dem wir es eingelesen haben:
Der Befehl funktioniert ähnlich wie der read.csv-Befehl. Schauen Sie sich die zu definierenden Elemente der Funktion an:
- x: Hier wird das Objekt, welches wir als CSV-File ausschreiben wollen, definiert. Das ist unsere fiktive Umfrage, also definieren wir dieses als: x = survey.
- file: Hier sagen wir R, wie das neue CSV-File heissen soll. Wichtig ist hier, dass wir wieder die Datei-Endung csv angeben müssen. Wir nennen unser neues CSV-File also: file = Umfrage-bearbeitet.csv
Sie sehen jetzt, dass die neuen Daten in ihrem aktuellen Work Space lokal auf Ihrem Rechner erscheinen.
4.1.2 Text-Files
Ein weiterer Dateityp, den Sie in diesem Seminar oft einlesen werden, sind Texte, die im einfachen “.txt”-Format abgespeichert sind.
Laden Sie als Beispiel bitte die drei Text-Dateien aus OLAT herunter (via: Materialien / Datensätze für R). Bei diesen Dateien handelt es sich um drei Nachrichtenartikel zum Thema Klimawandel:
- Washington Post.txt: einen Artikel der Washington-Post aus dem Jahr 2011 mit dem Titel “High court throws out states’ climate lawsuit”
- Times of India.txt: einen Artikel der Times of India aus dem Jahr 2012 mit dem Titel “Scientists stunned as Arctic ice cover plummets to record low”
- Guardian.txt: einen Artikel des Guardian aus dem Jahr 2015 mit dem Titel “Weatherwatch”
Legen Sie diese drei Text-Files in dem Ordner ab, den Sie zuvor als Arbeitsverzeichnis definiert haben.
4.1.2.1 Einlesen
Für das Einlesen von Text nutzen wir ein bestimmtes Package: Das readtext-Package. Das Package enthält Funktionen zum Import von Excel-Files, aber auch Word- oder PDF-Files. Hier finden Sie einen Link zum Package und zur zugehörigen Vignette. Wir laden das Package also herunter und aktivieren es:
Bei der Menge an Texten, mit denen wir arbeiten, macht es keinen Sinn, diese einzeln einzulesen. Bei drei Texten wäre es ggf. noch möglich, diese einzeln einzulesen - aber wir arbeiten im Seminar mit mehr als 1,000 Artikeln. Daher sollten wir diese alle zusammen und nicht einzeln einlesen.
Also bedienen wir uns eines Tricks: Wir sagen R, dass er alle Files in unserem Arbeitsverzeichnis einlesen soll, die eine .txt-Endung haben. Der Stern * kennzeichnet, dass beliebige Zahlen oder Wörter im Dateinamen vorkommen dürfen, solange das File eine .txt.-Endung hat. Anders gesagt: R soll alle Dateien im Arbeitsverzeichnis einlesen, die ein Text-Format haben.
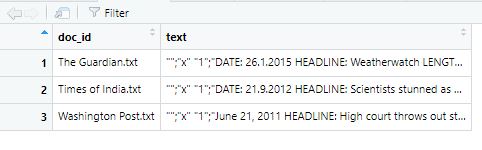
Schauen wir uns nun das Ergebnis an, sehen wir, dass R einen Dataframe eingelesen hat:
- docid: enthält Titel der eingelesenen Text-Datei
- text: enthält den Text der eingelesenen Text.Datei
Bild: Eingelesene Textdateien
4.1.3 Packages für weitere Dateiformate
Wenn Sie andere Dateiformate in R ein- oder auslesen wollen, bieten weitere Packages nützliche Funktionen, etwa:
- readxl: Importiert Excel-Files, vor allem in Excel oft genutzte .xls und .xlsx-Files Link zum Package
- xlsx: Importiert ebenfalls Excel-Files, vor allem in Excel oft genutzte .xls und .xlsx-Files Link zum Package
4.2 Objekte inspizieren
Sie haben bereits verschiedene Dateiformate kennengelernt. Wir lernen jetzt, wie wir uns einzelne Elemente dieser Objekte anschauen können.
Ganz generell können Sie den Befehl str() nutzen, um sich die Struktur des Objektes anzeigen zu lassen, wenn Sie das Objekt nicht mit View() virtuell inspizieren wollen. Dieser Befehl gibt Ihnen nicht nur die Elemente eines Vektores aus (Datentyp), sondern auch, in welchem Format diese abgespeichert sind (Objekttyp). Für unseren Umfrage-Datensatz würde das z.B. so aussehen:
## 'data.frame': 20 obs. of 6 variables:
## $ Teilnehmer : int 1 2 3 4 5 6 7 8 9 10 ...
## $ Alter : int 23 40 21 23 19 22 22 53 NA 19 ...
## $ Wohnort : Factor w/ 7 levels "Basel","Bern",..: 7 1 2 6 6 2 6 6 6 4 ...
## $ Zufriedenheit.mit.UZH: int 1 2 3 4 4 3 4 4 3 3 ...
## $ Datum : Factor w/ 2 levels "10-09-2020","11-09-2020": 1 1 1 1 1 2 1 1 2 1 ...
## $ Land : chr "Schweiz" "Schweiz" "Schweiz" "Schweiz" ...4.2.1 Skalare inspizieren
Skalare bestehen nur aus einem Wert. Entsprechend können Sie diesen Wert ganz einfach aufrufen. Nehmen wir wieder das Beispiel des Objekts word, das aus dem Wort hello besteht.
Sie können sich dieses Objekt über diverse Befehle ausgeben lassen, z.B. in dem Sie das Objekt einfach aufrufen.
## [1] "hello"4.2.2 Vektoren inspizieren
Vektoren bestehen aus einer Reihe von Werten gleichen Typs, also beispielsweise einer Reihe von Zahlen oder Wörtern. Nehmen wir an, Sie hätten als Vektor das Objekt numbers, dem Sie eine Reihe von Nummern von 1 bis 20 zugewiesen haben:
Auch hier können Sie wieder den Namen des Objekts eingeben, um sich den Inhalt des Objekts ausgeben zu lassen:
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20Vielleicht wollen Sie aber nur ein Element des Vektors inspizieren. Dann geben Sie einfach an, welches Element Sie sich ausgeben lassen wollen. Wollen Sie beispielsweise wissen, welches Element an fünfter Stelle in diesem Vektor ist, nutzen Sie eckige Klammern hinter dem jeweiligen Objekt, um das Element zu identifizieren, das R ausgeben soll:
## [1] 5Dieser Befehl funktioniert genauso, wenn wir mit einem Vektor von Text arbeiten. Nehmen wir wieder unseren Vektor, der aus verschiedenen Früchtenamen besteht:
Welches Element wird hier nochmal als drittes genannt? Das zeigt uns folgender Befehl:
## [1] "Orange"4.2.3 Dataframes inspizieren
Dataframes bestehen aus mehreren Vektoren gleicher Länge. In vielen Fällen sind die Spalten eines Dataframes Variablen, während die Zeilen Fälle umfassen. Genauso ist z.B. unser Datensatz survey aufgebaut:
Wenn wir uns nur eine Spalte bzw. Variable dieses Datensatz anschauen lassen können, können wir diese Variable über ihren Namen aufrufen. Dabei spezifizieren wir den Dataframe survey, weisen R über den Operator $ dann an, eine Spalte innerhalb dieses Dataframes auszugeben und spezifieren dann den Namen dieser Spalte. Z.B. könnten wir die Variable Wohnort im Datensatz survey folgendermassen aufrufen:
## [1] Zug Basel Bern Zuerich Zuerich Bern Zuerich Zuerich Zuerich Luzern
## [11] Luzern Lugano Bern Bern Basel Winterthur Zuerich Winterthur Bern Bern
## Levels: Basel Bern Lugano Luzern Winterthur Zuerich ZugEventuell wollen wir uns nicht nur eine Spalte bzw. Variable ausgeben lassen, sondern den Wert einer ganz bestimmten Person für eine ganz bestimmte Variable. Z.B. könnten wir uns nur für die dritte Person im Datensatz den Wohnort ausgeben lassen. R ermöglicht es uns, sich innerhalb eines Dataframes nur einen Wert für eine bestimmte Zeile und eine bestimmte Spalte ausgeben zu lassen. Wir können diesen Wert z.B. durch seine Position im Datensatz aufrufen (Zeile und Spalte). Wollen wir uns den Wohnort für die dritte Person im Datensatz angeben lassen, benötigen wir also den Wert, der in der dritten Spalte (dritte Person) und in der dritten Spalte (Wohnort) steht.
Bild: Gesuchter Wert im Datensatz
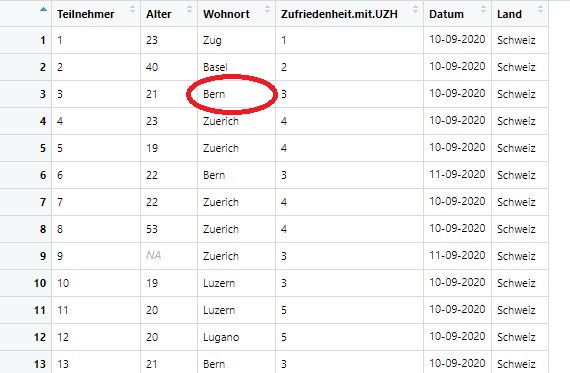
Variante 1: Wir weisen R an, uns auszugeben, welcher Wert in der gesuchten Zeile (Zeile 3, da die Zeilen Teilnehmer:innen umfassen) und der gesuchten Spalte (Spalte 3, da die dritte Variable den Wohnort umfasst) steht. Durch eckige Klammern weisen wir R an, welche Zeile (erster Wert) und welche Spalte (zweiter Wert) gesucht ist.
## [1] Bern
## Levels: Basel Bern Lugano Luzern Winterthur Zuerich ZugWenn wir auf einen Wert in einem Dataframe über seine Position zugreifen wollen, können wir diesen Wert über seine Position im Dataframe bestimmen.
- Wir greifen auf Werte im Dataframe zu, indem wir eckige Klammern [,] nutzen.
- Der erste Wert in den eckigen Klammern steht für die Zeilen, auf die wir zugreifen wollen. Der Befehl dataframe[1,] hiesse z.B., dass wir uns die erste Zeile und alle Spalten für einen Dataframe ausgeben lassen wollen.
- Der zweite Wert in den eckigen Klammern steht für die Spalten, auf die wir zugreifen wollen. Der Befehl dataframe[,2] hiesse z.B., dass wir uns alle Zeilen und die zweite Spalte für einen Dataframe ausgeben lassen wollen.
- Wollen wir einen Wert in einer bestimmten Zeile und Spalte spezifizieren, können wir einfach beide Werte angeben: dataframe[1,1] hiesse z.B., dass wir den Wert ausgeben lassen wollen, den dataframe in der ersten Zeile in der zweiten Spalte hat.
Ein Beispiel:
## Teilnehmer Alter Wohnort Zufriedenheit.mit.UZH Datum Land
## 1 1 23 Zug 1 10-09-2020 Schweiz## [1] 23 40 21 23 19 22 22 53 NA 19 20 20 21 22 23 24 29 21 20 21## [1] 23Variante 2: Eine zweite Variante wäre, dass wir R anweisen, uns die dritte Beobachtung für die Variable Wohnort auszugeben. Dafür spezifizieren wir, dass wir die dritte Zeile im Dataframe angezeigt bekommen wollen und zwar nur für die Variable Wohnort. Dafür definieren wir erst wieder die Zeilennummer des Dataframes survey an erster Stelle der eckigen Klammern und geben an zweiter Stelle dann an, für welche Variablen wir diesen Wert suchen. Wichtig ist dabei im Unterschied zu zuvor, dass wir die richtige Variable nicht über ihre Position, sondern ihren Namen aufrufen.
## [1] Bern
## Levels: Basel Bern Lugano Luzern Winterthur Zuerich ZugVariante 3: Eine dritte Variante wäre schliesslich, dass wir gar nicht den gesamten Dataframe aufrufen, sondern direkt auf die Variable Wohnort zugreifen. Wir wissen bereits, dass es sich bei dieser um einen Vektor handelt, d.h. eine Aneinanderreihung von Wohnorten für jede Teilnehmer:in. Wie im Abschnitt Vektoren inspizieren gelernt, können wir auf einzelne Werte eines Vektors ganz einfach zugreifen, in dem wir R sagen, an welcher Stelle im Vektor dieser Wert vorkommt. Wir greifen also nur auf die Variable Wohnort im Datensatz survey zu und lassen uns für diese den dritten Wert (d.h., den Wert der dritten Person innerhalb unseres Datensatzes) ausgeben.
## [1] Bern
## Levels: Basel Bern Lugano Luzern Winterthur Zuerich ZugSie sehen also: Es gibt eine Vielzahl an möglichen Lösungen - wie es auch in R ganz generell meist nicht die eine richtige Lösung gibt, sondern mehrere Variante (unterschiedlich schnell und effizient) zum Ziel führen.
4.2.4 Listen inspizieren
Schliesslich können wir auch einzelne Elemente einer Liste inspizieren. Nehmen wir an, wir hätten zwei Objekte: Unseren Dataframe survey und den Vektor words. Wir haben beide Objekte als Elemente einer Liste abgespeichert:
Wenn wir jetzt nur den Vektor (das zweite Element dieser Liste) ansehen wollen, könnten wir dieses einfach durch zweifache eckige Klammern aufrufen:
## [1] "Apfel" "Banane" "Orange" "Zitrone"4.3 Informationen über Objekte
Oft wollen wir nicht nur einzelne Elemente unseres Objekts inspizieren, sondern mehr Informationen über das Objekt als Ganzes haben, etwa:
- Wie viele Fälle umfasst unser Datensatz?
- Wie viele Variablen enthält er?
Im Folgenden schauen wir uns an, wie wir diese Informationen für einen Dataframe erhalten, hier für das Beispiel der fiktiven Umfrage survey.
4.3.1 Anzahl an Elementen, Zeilen & Spalten
Wollen wir wissen, wie viele Zeilen (im englischen: rows) unser Datensatz umfasst, d.h. in unserem Fall, wie viele Teilnehmer:innen wir befragt haben, nutzen wir folgenden Befehl:
## [1] 20Wollen wir wissen, wie viele Spalten (im englischen: columns) unser Datensatz umfasst, d.h. in unserem Fall, wie viele Variablen wir erhoben haben, nutzen wir folgenden Befehl:
## [1] 6Wollen wir wissen, wie viele Werte eine spezifische Spalte (hier: ein Vektor) enthält, nutzen wir folgenden Befehl.
## [1] 20In diesem Fall entspricht das Ergebnis der Anzahl an Zeilen und damit der Anzahl an Teilnehmer:innen, da alle Vektoren in einem Dataframe gleich lang sind.
Ggf. wollen wir uns probeweise die ersten Zeilen eines Datensatzes angucken. Dafür ist der folgende Befehl hilfreich:
## Teilnehmer Alter Wohnort Zufriedenheit.mit.UZH Datum Land
## 1 1 23 Zug 1 10-09-2020 Schweiz
## 2 2 40 Basel 2 10-09-2020 Schweiz
## 3 3 21 Bern 3 10-09-2020 Schweiz
## 4 4 23 Zuerich 4 10-09-2020 Schweiz
## 5 5 19 Zuerich 4 10-09-2020 Schweiz
## 6 6 22 Bern 3 11-09-2020 Schweiz4.4 Take Aways
- Daten ein- und auslesen: R kann alle möglichen Dateitypen ein- und aus-lesen. Befehle: read.csv(), read.csv2(), write.csv(), write.csv2(), readtext()
- Objekte inspizieren: Wir können uns via view nicht nur ein Objekt als Ganzes ähnlich wie in SPSS anzeigen lassen. Wir können uns auch einzelne Elemente in der Konsole anzeigen lassen:
Befehle:
- für die Struktur eines Objektes allgemein: str()
- für Skalare: Name des Vektors
- für Vektoren: Name des Vektors[Nummer des Elements]
- für Dataframes:
- bei einzelnen Werten: Name des Dataframes[Nummer der Zeile, Nummer der Spalte] oder Name des Dataframes$Name der Spalte[Nummer der Zeile]
- bei Spalten bzw. Variablen des Dataframes: Name des Dataframes$Name der Variable
- für Listen: Name der Liste[[Nummer des Elements]]
- Informationen über Objekte: Wir können uns in R Informationen über ein Objekt als ganzes (etwa die Anzahl Elemente, Zeilen oder Spalten) anzeigen lassen. Befehle: length(), nrows(), ncol(), head()
4.5 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
4.6 Übungsaufgabe
Sie haben das Tutorial erfolgreich durchgearbeitet? Dann finden Sie hier einige Aufgaben zum Selbsttest, mit denen Sie Ihr Wissen testen können. Laden Sie dafür bitte die Excel-Datei “Daten_Tutorial 4” aus OLAT herunter (via: Materialien / Datensätze für R).
Bei dieser Datei handelt es sich um eine fiktive Umfrage unter Schweizer Bürger:innen, für die folgende Variablen erfasst wurden:
- der Name des Teilnehmers/der Teilnehmerin
- ihr Alter
- das meist genutzte Medium (TV, Online oder Print)
- die Anzahl Stunden, in denen dieses Medium täglich genutzt wird
- das Vertrauen, das sie in die Medien haben (1= gar kein Vertrauen bis 5 = sehr hohes Vertrauen)
4.6.1 Aufgabe 4.1
Lesen Sie den Datensatz ein. Lassen Sie sich die Anzahl an Teilnehmer:innen sowie die Anzahl der erhobenen Variablen über die entsprechenden Befehle in R ausgeben.
4.6.2 Aufgabe 4.2
Schreiben Sie einen Befehl, der Ihnen angibt, welches das meist genutzte Medium von der 18. Teilnehmerin der Umfrage ist (dh., der Teilnehmerin in der 18. Zeile).
Können Sie diesen Befehl so anpassen, dass R Ihnen das meist genutzte Medium von der Teilnehmerin mit dem Namen “Anna” ausgibt? Achtung: Hier ist Googlen angesagt, diese Befehle kennen Sie noch nicht. Können Sie sie eigenständig herausfinden?
4.6.3 Aufgabe 4.3
Berechnen Sie den Mittelwert des Alters der Teilnehmer:innen.
4.6.4 Aufgabe 4.4
Eine/r der Teilnehmer:innen hat ein sehr niedriges Alter angegeben (8 Jahre alt). Hier scheint es sich um einen Tippfehler zu handeln.
Können Sie das Alter dieses Teilnehmers/der Teilnehmerin ersetzen, d.h. aus der 8 eine 18 machen? Achtung: Hier ist Googlen angesagt, diese Befehle kennen Sie noch nicht. Können Sie sie eigenständig herausfinden?
Die Lösungen finden Sie bei Lösungen zu Tutorial 4.
Wir machen weiter: mit Tutorial 5: Daten manipulieren.