5 Tutorial 5: Daten manipulieren
In Tutorial 5 lernen Sie:
- wie Sie ein Objekt spalten-/zeilenweise filtern
- wie Sie einzelne oder mehrere Werte eines Objektes manipulieren können
- wie Sie mehrere Objekte zusammenführen bzw. mergen können
Für das Tutorial arbeiten wir mit einem neuen, wiederum fiktiven Datensatz: Daten_Tutorial 5.csv. Laden Sie diesen bitte aus OLAT herunter (via: Materialien / Datensätze für R).
Der Name der Datei lautet: Daten_Tutorial 5. (Achtung, nicht den Datensatz zur Aufgabe 5 aus Versehen wählen, der dort auch hochgeladen ist!)
Bei dem Datensatz handelt es sich um eine fiktive Umfrage unter 1000 Bürger:innen (N = 1000), für die fünf Variablen erfasst wurden:
Datensatz Tutorial 5:
- Alter: das Alter der Person
- Land: das Land, in dem diese wohnt
- Vertrauen: ihr Vertrauen in die Medien (auf einer Skala von 1 = gar nicht zufrieden bis 5 = sehr zufrieden)
- Geschlecht: das Geschlecht der jeweiligen Person
- Medium: das Medium, welches diese Person am häufigsten nutzt, um sich über Politik zu informieren
Legen Sie das CSV-File in dem Ordner ab, den Sie zuvor als Arbeitsverzeichnis definiert haben. Jetzt sollten Sie die Datei einlesen können.
Werfen Sie kurz einen Blick in die Daten, um die Struktur des Datensatzes zu verstehen und sich zu vergewissern, dass alles korrekt eingelesen wurde. Sie können sich den Datensatz visuell anschauen, ähnlich wie in SPSS.
Bild: Datensatz für Tutorial 5
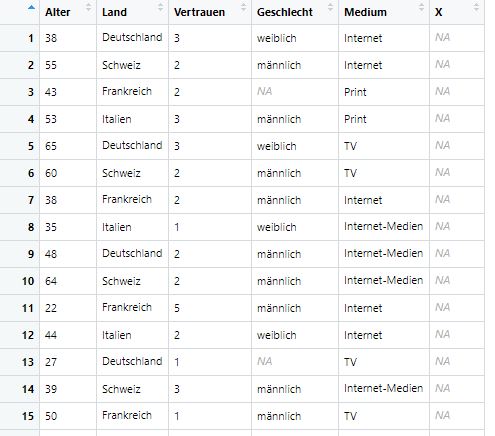
Ein anderer Weg wäre, den Ihnen bereits bekannten Befehl str() zu nutzen, der Ihnen einen Einblick in die Struktur eines R-Objektes gibt:
## 'data.frame': 1000 obs. of 6 variables:
## $ Alter : int 38 55 43 53 65 60 38 35 48 64 ...
## $ Land : Factor w/ 4 levels "Deutschland",..: 1 4 2 3 1 4 2 3 1 4 ...
## $ Vertrauen : int 3 2 2 3 3 2 2 1 2 2 ...
## $ Geschlecht: Factor w/ 2 levels "männlich","weiblich": 2 1 NA 1 2 1 1 2 1 1 ...
## $ Medium : Factor w/ 4 levels "Internet","Internet-Medien",..: 1 1 3 3 4 4 1 2 2 2 ...
## $ X : logi NA NA NA NA NA NA ...Sie sehen hier schon, dass etwas nicht stimmt: Da sich in der sechsten Spalte der Datei ein Buchstabe befindet (scheinbar ein Tippfehler), hat R eine sechste Variable mit dem Namen X eingelesen, die nur fehlende Werte enthält. Wir lernen jetzt wie wir unseren Datensatz so manipulieren, dass wir derartige Dinge bereinigen können.
5.1 Objekte zeilen-/spaltenweise filtern
Als ersten Schritt lernen wir, wie wir ein Objekt filtern, d.h. Informationen nur für bestimmte Zeilen oder Spalten eines Objektes ausgeben lassen. Beispielsweise kann es sein, dass wir nur bestimmte Zeilen oder Spalten eines Datensatzes für die weitere Analyse behalten wollen.
5.1.1 Spaltenweise filtern
In unserem Fall kann es sein, dass wir nur die ersten 5 Variablen (Alter, Land, Vertrauen, Geschlecht und Medium) behalten wollen, da die sechste Spalte Variable X ja fälschlicherweise eingelesen wurde. Es gibt mehrere Variante, wie wir nur bestimmte Variablen behalten bzw. spezifische Variablen ausschliessen:
- per Position
- per Name der Spalte
5.1.1.1 Variante 1: per Position
Wir können Variablen über ihre Position einschliessen, etwa, indem wir R anweisen, nur Variable 1-5 zu behalten. Der folgende Befehl gibt ein neues Objekt data_subset aus, in dem nur die ursprünglichen Spalten 1-5 des Datensatzes data enthalten sind:
Wir können eine Variable aber auch über ihre Position im Datensatz ausschliessen. Der folgende Befehl gibt ein neues Objekt data_subset aus, in dem alle Spalten bis auf die Spalte 6 des ursprünglichen Datensatzes data enthalten sind. Das Minus-Zeichen schliesst also eine Spalte explizit aus. Das Objekt ist genau das gleiche, wie das, was mit unserem letzten Befehl erzeugt haben. Sie sehen also bereits wieder: Es gibt verschiedene Wege, mit R ans richtige Ziel zu kommen (die meist unterschiedlich effizient sind).
5.1.1.2 Variante 2: per Namen
Für längere Datensätze mit vielen Spalten ist es sinnvoller, Spalten über ihren Namen als über ihre Position aus- oder einzuschliessen, weil wir uns sonst leicht bei der Position der auszuschliessenden Spalte verzählen könnten. Für unseren Dataframe würde das dann so aussehen, wenn nur spezifizieren, welche Variablen wir einschliessen wollen:
Einfacher wäre aber wieder, nicht alle Variablen aufzuzählen, die wir behalten wollen, sondern in R nur zu spezifizieren, welche Variable wir ausschliessen wollen. Die Funktion subset erlaubt uns, Variablen über select anhand ihres Namens auszuwählen. Durch das Minusszeichen spezifizieren wir dann wieder, dass die Variable mit dem Namen X ausgeschlossen und nicht behalten werden soll. Wichtig ist dabei, dass der entsprechende Variablennamen hier ohne Anführungszeichen angegeben wird.
5.1.2 Zeilenweise filtern
Zudem könnte es sein, dass wir nur bestimmte Fälle (im Datensatz: Zeilen) analysieren wollen. Dafür müssten wir unseren Datensatz zeilenweise filtern. Beispielsweise könnte es sein, dass uns für unsere Analyse nur die Befragten aus der Schweiz und Italien interessieren. Diese Fälle (im Datensatz: Zeilen) können wir also nicht über die Spalten herausfiltern (im Datensatz: Variablen), sondern wir müssen über bestimmte Zeilen (im Datensatz: Fälle) filtern.
Aufgrund der grossen Fallzahl macht es keinen Sinn, hier nur nach Position der Fälle zu filtern, auch wenn das theoretisch auch ein (sehr aufwendiger) Weg wäre, ähnlich wie wir es für die Filterung von Spalten schon gelernt haben. Theoretisch könnten wir in den Datensatz schauen und die Zeilennummern aller Fälle rausschreiben, in denen die Befragten angegeben haben, aus der Schweiz oder Italien zu stammen. Das ist aber natürlich wenig sinnvoll.
Besser ist, wir weisen R an, uns anzugeben, welche Zeilen die Bedingung Wohnort “Italien” oder “Schweiz” erfüllt haben - und genau das ist es was, was R macht:
5.1.2.1 Variante 1: Position mit logischer Bedingung
Wir können den Datensatz anhand der Werte, die jede Zeile für die Spalte Land haben soll, filtern. Wir greifen auf den Dataframe zu, indem wir die eckigen Klammern nutzen, s. dazu als Wiederholung Tutorial 4: Daten ein-/auslesen & inspizieren. Ich nenne diese Variante “Position mit logischer Bedingung”, weil wir R im Prinzip anweisen, eine bestimmte Spalte zu nehmen und nur die Zeilen herauszufiltern, die für diese Spalte einen bestimmten Wert annehmen. D.h., wir lassen uns von R nur die Zeilen ausgeben, die für die Variable Land den Wert “Schweiz” oder “Italien” annehmen. Diese “Oder”-Bedingung wird durch den logischen Operator | spezifiziert.
Wichtig ist, dass diese Bedingung vor dem Komma spezifiziert wird, denn: Die Bedingung gilt nur für alle Zeilen, da R nur bestimmte Zeilen herausfiltern soll. Die zweite Bedingung nach dem Komma bleibt leer, da R uns alle Spalten zurückgeben soll.
Schauen wir uns das Ergebnis an:
##
## Deutschland Frankreich Italien Schweiz
## 0 0 250 250Die Maipulation scheint also geklappt zu haben und im bearbeiteten Datensatz data_subset abgespeichert worden zu sein.
Wir wissen, dass wir im Originaldatensatz data insgesamt Menschen in vier Ländern befragt haben: der Schweiz, Italien, Deutschland und Frankreich:
##
## Deutschland Frankreich Italien Schweiz
## 250 250 250 250Wir könnten also auch hier wieder nicht über den Einschluss, sondern den Ausschluss bestimmter Fälle arbeiten. D.h., wir weissen R nicht an, bestimmte Fälle einzuschliessen (die, wo der Wohnort Schweiz oder Italien ist), sondern bestimmte Fälle auszuschliessen (die, wo der Wohnort Frankreich und Deutschland ist). Der logische Operator != bedeutet, dass R nur Fälle einschliessen soll, in denen beide Bedingungen nicht erfüllt sind: Die gesuchten Fälle haben weder Frankreich noch Deutschland als Land angegeben. Beide Bedingungen müssen erfüllt sein, weshalb hier der logische Operator & verwendet wird.
Wir sehen: Das Ergebnis ist - wenig überraschend - das gleiche:
##
## Deutschland Frankreich Italien Schweiz
## 0 0 250 2505.1.2.2 Variante 2: subset
Die Funktion subset erlaubt uns, einen Datensatz anhand von Werten, die Zeilen für eine oder mehrere Variable haben, zu filtern. Der Befehl funktioniert also ganz ähnlich wie der vorherige, den wir für die Filterung von Spalten genutzt haben. Wir nutzen wieder eine logische Bedingung, die erfüllt sein muss, damit R Fälle aufgreift - diesmal aber nicht über die Bedingungen, die für den Dataframe in bestimmten Positionen, d.h. Spalten und Zeilen erfüllt sein müssen, wie zuvor mit der eckigen Klammer [].
Stattdessen nehmen wir den Datensatz und weisen R an, uns ein neues Objekt auszugeben, für das nur eine Bedingung erfüllt sein muss: Dass die Spalte Land den Wert “Schweiz” oder “Italien” annimmt. Wir lassen uns also einfach alle Fälle eines Dataframes zurückgeben, für die eine Bedingung erfüllt ist (ohne bspw. zu spezifizieren, welche Spalten R uns ausgeben soll).
##
## Deutschland Frankreich Italien Schweiz
## 0 0 0 05.1.2.3 Variante 3: dplyr
Als sogenanntes Tidyverse sind in R eine Kollektion mehrere Packages bekannt geworden, die gerade Einsteiger:innen das Arbeiten mit Daten vereinfacht, effizienter und auf Basis einer wiederkehrenden Funktionsweise und Datenstruktur erlauben. Dieses Seminar weist Sie auf einige dieser Pakete (etwa dplyr oder ggyplot in nachfolgenden Tutorials) hin, bietet aber keine grundlegende Einführung in tidyverse. Für eine solche Einführung sei etwa auf folgende Quellen verwiesen:
- Tutorial 7: Einführung in das Datenhandling von J. Unkel
- Tutorial 12: Tidy data von G. Grolemund und H. Wickham
Das Package dplyr ist eines der bekanntesten Packages aus dem Tidyverse. Das Packet bietet uns einige nützliche Funktionen zur Datenmanipulation, von denen hier nur einige genannt werden. Wichtig ist dabei zu wissen, dass viele dieser Pakete mit dem sogenannten “Pipe-Operator” arbeiten: %>%
Der Pipe-Operator hat einen ganz bestimmten Zweck: Er nimmt ein bestimmtes Objekt und übergibt dieses Objekt einer oder mehrerer rechts neben ihm stehenden Funktionen. Durch diese Pipeline können wir unser Objekt, welches bearbeitet werden soll, R als Objekt übergeben und dann durch eine “Pipeline” von mehreren Funktionen jagen.
Zunächst müssen wir das Paket dafür installieren und aktivieren:
Nehmen wir dann unsere Daten als Beispiel dafür, wie wir mit dpylr Daten manipulieren können. Mit filter() könnten wir uns ein neues Objekt data_subset ausgeben lassen, das nur Fälle enthält, die für die Variable Land den Wert “Schweiz” oder “Italien” annehmen. Der Befehl funktioniert also von der Logik her ganz genauso wie Variante 1 und 2:
- Wir filtern unseren Datensatz nach bestimmten Bedingungen
- Wir lassen uns nur die Fälle zurückgeben, für die diese Bedingungen erfüllt sind.
Nur der Aufbau dieses Befehl ist etwas anders, wenn man mit dem dplyr-Package arbeitet:
##
## Deutschland Frankreich Italien Schweiz
## 0 0 250 250Ablauf der Befehle in dplyr:
- Wir definieren das Objekt, den Dateframe data, mit dem wir arbeiten wollen: data
- Wir übergeben dieses Objekt an unsere Pipeline: %>%
- Dann filtern wir nur solche Fälle aus dem Datensatz heraus heraus, in denen die Befragten aus der Schweiz oder Italien kommen. Das Objekt, das wir filtern wollen, muss in diesem Befehl nicht erneut definiert werden, weil wir R bereits gesagt haben, dass wir mit data arbeiten wollen: filter(Land == “Schweiz”|Land == “Italien”)
- Dann weisen wir das Ergebnis einem neuen Objekt data_subset zu: data_subset <-
Den Filter-Befehl hätten wir bereits etwas kürzer definieren können: Nämlich, indem wir R nicht anweisen, uns Fälle auszugeben, in denen die Variable Land entweder den Wert “Schweiz” oder den Wert “Italien” annimmt. Stattdessen könnten wir R auch anweisen, uns Fälle auszugeben, in denen die Variable Land einen der Werte annimmt, die in einem folgenden Vektor, hier c(“Schweiz”, “Italien”), definiert werden. Das hat den Vorteil, dass wir dieser “oder”-Bedingungen nicht einzeln definieren müssen:
Das praktische an dyplr-Funktionen ist, dass man beliebig viele Funktionen effizient verschachteln kann. Beispielsweise kann man nicht nur eine Datenmanipulation innerhalb der Pipeline durchführen. Sagen wir, Sie wollen den Datensatz erst nach Befragten aus Italien und der Schweiz filtern und sich dann nur die Fälle ausgeben lassen, in denen die Teilnehmer:innen ihr Geschlecht angegeben haben, d.h. dort keine fehlenden Werte existieren.
D.h.,
- ich definiere erst meinen Datensatz data: data
- übergebe diesen dann der Pipeline: %>%
- wo die Daten zuerst nach der Variable Land gefiltert werden: filter(Land == “Schweiz”|Land == “Italien”)
- wieder in die Pipeline weitergesendet werden: %>%
- und dann nach fehlenden Werten bei der Variable Geschlecht gefiltert werden: filter(is.na(Geschlecht) == FALSE)
- und weise das entstandene Objekt zuletzt data_subset zu: data_subset <-
5.1.3 Spalten- und zeilenweise filtern
Natürlich kann es auch sein, dass Sie Ihren Datensatz auf bestimmte Spalten und Zeilen reduzieren wollen - etwa, weil Sie nur bestimmte Variablen und Fälle analysieren möchten, d.h. bestimmte andere Variablen und Fälle ausschliessen wollen. Sagen wir, Sie wollen einen neuen Datensatz erstellen, der nur Teilnehmer:innen über 21 enthält, und der nur die Variablen “Alter”, “Land”, und “Geschlecht” umfasst. Wollen Sie ihren Datensatz spalten- und zeilenweise manipulieren, sähe dies folgendermassen aus, obgleich hier auch mehrere verschiedene Befehle genutzt werden können:
## 'data.frame': 938 obs. of 3 variables:
## $ Alter : int 38 55 43 53 65 60 38 35 48 64 ...
## $ Land : Factor w/ 4 levels "Deutschland",..: 1 4 2 3 1 4 2 3 1 4 ...
## $ Geschlecht: Factor w/ 2 levels "männlich","weiblich": 2 1 NA 1 2 1 1 2 1 1 ...5.2 Werte eines Objekts manipulieren
Sie wissen jetzt bereits, wie Sie Objekte anhand einzelner oder mehrerer Fälle filtern. Nun kann es sein, dass Sie Objekte nicht nur filtern wollen, sondern für bestimmte Fälle Werte ersetzen wollen.
Wichtig ist, dass Sie verstehen, wie die Manipulation von Werten funktioniert. Im Prinzip brauchen Sie dafür zwei Schritte:
- Schritt 1: Sie filtern den Datensatz nach den Zeilen/Spalten, die Sie manipulieren wollen.
- Schritt 2: Sie ersetzen nur für die identifizierten Zeilen/Spalten die vorhandenen Werte.
Sie können also Ihr Wissen aus dem vorherigen Abschnitt nutzen. Sie filtern erst - und müssen dann nur noch die bestehenden Werte für diese herausgefilterten Zeilen überschreiben.
5.2.1 Ausgewählte Werte ersetzen
Schauen wir uns den Original-Datensatz, den wir ganz am Anfang eingelesen haben, noch einmal an:
## 'data.frame': 1000 obs. of 6 variables:
## $ Alter : int 38 55 43 53 65 60 38 35 48 64 ...
## $ Land : Factor w/ 4 levels "Deutschland",..: 1 4 2 3 1 4 2 3 1 4 ...
## $ Vertrauen : int 3 2 2 3 3 2 2 1 2 2 ...
## $ Geschlecht: Factor w/ 2 levels "männlich","weiblich": 2 1 NA 1 2 1 1 2 1 1 ...
## $ Medium : Factor w/ 4 levels "Internet","Internet-Medien",..: 1 1 3 3 4 4 1 2 2 2 ...
## $ X : logi NA NA NA NA NA NA ...Bild: Datensatz für Tutorial 5
Wir sehen, dass für die Variable Medium sowohl “Internet” als auch “Internet-Medien” als mögliche Ausprägungen bzw. Werte codiert wurden. Ggf. macht es Sinn, diese beiden Ausprägungen zusammenzuführen, weil sich “Internet” und “Internet-Medien” inhaltlich nicht wirklich unterscheiden lassen.
Unser Ziel: Wir wollen eine neue Variable Medium_edited im Datensatz data erstellen, in der diese Ausprägungen “Internet” und “Internet-Medien” zusammengefasst werden.
Dafür können Sie Ihr bereits erworbenes Wissen nutzen.
- Erst erstellen Sie eine neue Variable “Medium_edited”, damit Sie die ursprünglichen Werte der Variable “Medium” nicht ersetzen (Sie könnten die ursprüngliche Variable “Medium” natürlich auch direkt überschreiben, wenn Sie wollten).
- Dann filtern Sie den Datensatz nach den Fällen, in denen die Variable Medium die Werte “Internet” oder “Internet-Medien” annimmt.
- Dann ersetzen Sie nur für diese identifizierten Fälle die Variable Medium_edited durch “Internetnutzung”.
Variante 1
#Wir erstellen eine neue Variable: Medium_edited
data$Medium_edited <- data$Medium
#Wir ersetzen für ausgewählte Fälle den Wert
data$Medium_edited[data$Medium_edited=="Internet"|
data$Medium_edited=="Internet-Medien"] <- "Internetnutzung"
table(data$Medium_edited) #Wir lassen uns die neuen Werte ausgeben##
## Internetnutzung Print TV
## 503 231 266Es gibt mehrere Varianten, diesen Befehl durchzuführen. Eine weitere Option wäre die folgende:
Variante 2
data$Medium_edited <- data$Medium
data$Medium_edited[data$Medium_edited %in%
c("Internet", "Internet-Medien")] <- "Internetnutzung"
table(data$Medium_edited) #Wir lassen uns die neuen Werte ausgeben##
## Internetnutzung Print TV
## 503 231 266Wir haben jetzt eine neue Variable Medium_edited erstellt, in der die neuen Werte vorhanden sind. Sie können natürlich auch in der Original-Variable die Werte direkt manipulieren - je nachdem, ob Sie eine neue Variable brauchen oder nicht:
5.2.2 Daten sortierten
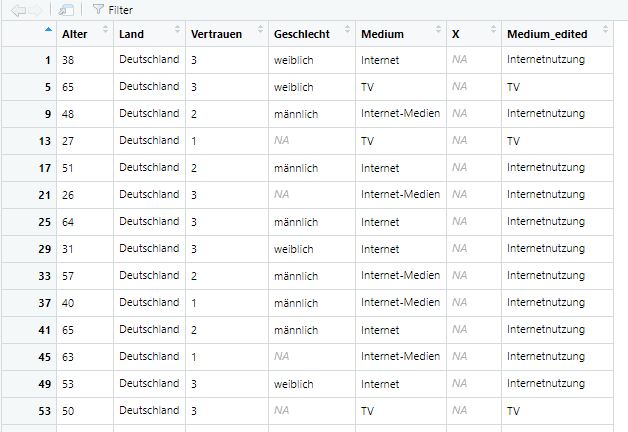
In manchen Fällen kann es auch sein, dass wir unsere Daten in einer bestimmten Reihenfolge haben wollen - beispielsweise numerisch oder alphabetisch. Dafür können wir den Befehl order nutzen. Wenn wir unseren Datensatz beispielsweise nach Land sortiert haben wollen, können wir folgenden Befehl nutzen:
Wir sehen bei Betrachtung des Datensatzes: R zeigt uns jetzt die Fälle sortiert nach dem Land an, in dem die Befragten wohnen - beginnen mit Deutschland, d.h. nach alphabetischer Reihenfolge:
Bild: Sortierung nach Land
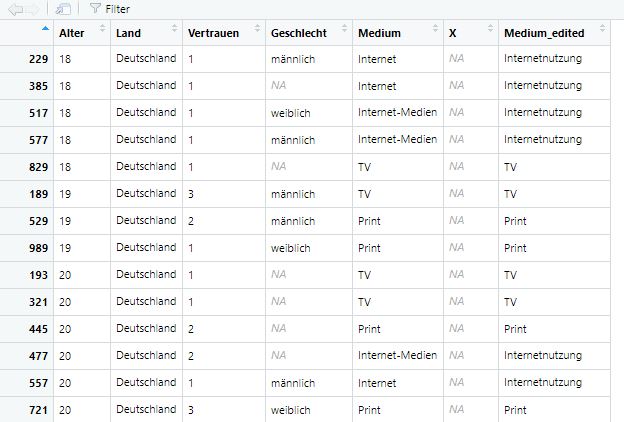
Wir könnten sogar nach mehreren Variablen sortieren - beispielsweise erst nach Land und dann, innerhalb der Länder, nach Alter:
Bild: Sortierung nach Land und Alter
5.3 Take Aways
- Objekte spalten-/zeilenweise filtern & manipulieren: Sie müssen erst die Zeilen/Spalten auswählen, die sie manipulieren wollen & dann konkretisieren, was mit diesen geschehen soll. Befehle: subset(), select(), filter(), %>%, %in%
- Objekte sortieren: Befehle: order()
5.4 Weitere Tutorials zu diesen Schritten
Sehr hilfreich für die zahlreichen Funktionen in R, nicht nur was die Manipulation von Daten angeht, sind sogenannte “Cheat-Sheets”. Diese bieten Ihnen auf einen Blick eine Übersicht über nützliche Funktionen zu verschiedenen Themen.
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
- R for Data science von G. Grolemund und H. Wickham, Tutorial 5
- R Codebook von J.D. Long und P. Teetor, Tutorial 5
- Wegweisr von M. Haim, Ep II und Ep III
- YaRrr! The Pirate’s Guide to R von N.D.Phillips, Tutorial 7 und 8
- Computational Methods in der politischen Kommunikationsforschung von J. Unkel, Tutorial 7-10
5.5 Übungsaufgabe
Sie haben das Tutorial erfolgreich durchgearbeitet? Dann finden Sie hier einige Aufgaben zum Selbsttest, mit denen Sie Ihr Wissen testen können. Wir arbeiten wieder mit einem neuen, fiktiven Datensatz: Daten_Tutorial 5 Aufgabe.csv (via OLAT: Materialien / Datensätze für R). Bei dieser Datei handelt es sich um eine fiktive Umfrage unter Bürger:innen, für die folgende Variablen erfasst wurden:
- das Alter
- das Geschlecht
- das monatliche Einkommen
- der Schulabschluss
- das Land, in dem der/die Befragte lebt
5.5.1 Aufgabe 5.1
Lesen Sie den Datensatz ein. Lassen Sie sich die Anzahl an Teilnehmer:innen sowie die Anzahl der erhobenen Variablen über die entsprechenden Befehle in R ausgeben.
5.5.2 Aufgabe 5.2
Lassen Sie sich die Werte, die die Variable “Land” annimmt, ausgeben. Wie können Sie R ausgeben lassen, wie häufig jedes Land insgesamt vorkommt?
Sie sehen, dass das Land Deutschland einmal ausgeschrieben (“Deutschland”) und einmal verkürzt (“Dt”) angegeben ist. Das scheint ein Fehler zu sein. Ersetzen Sie für alle Fälle, bei denen das Land Deutschland mit “Dt” abgekürzt wurde, die Werte mit “Deutschland”.
5.5.3 Aufgabe 5.3
Reduzieren Sie Ihre Daten: Erstellen Sie einen neuen Datensatz data_schweiz, der nur Befragte enthält, die aus der Schweiz kommen. Ausserdem sollen hier nur die Variablen “Alter”, “Geschlecht” “Land”, und “Einkommen” (in dieser Reihenfolge der Variablen) vorhanden sein.
5.5.4 Aufgabe 5.4
Reduzieren Sie Ihre Daten noch weiter. Bitte überschreiben Sie Ihren Datensatz data_schweiz und behalten Sie nur Fälle, in denen die Befragten NICHT 25, 35, 45 oder 55 Jahre alt sind.
Die Lösungen finden Sie bei Lösungen zu Tutorial 5.
Wir machen weiter: mit Tutorial 6: Deskriptive Statistik.