13 Tutorial 13: Unueberwachtes maschinelles Lernen: Topic Modeling
In Tutorial 13 lernen Sie ein weiterführendes Verfahren kennen: Themenodelle bzw. unüberwachtes maschinelles Lernen in Form von Topic Modeling.
Wir arbeiten wieder mit einem Text-Korpus, der im R-Package Quanteda bzw. Quanteda-Corpora Quanteda-Corpora-Package zurzeit im Entwicklungsmodus bereits enthalten ist.
Sie finden den Korpus in OLAT (via: Materialien / Datensätze für R) mit dem Namen immigration_news.rda. Bei diesen Dateien handelt es sich um Nachrichtenartikel aus Grossbritannien zum Thema Immigration aus dem Jahr 2014, die (leicht bearbeitet) bereits als R-Environment abgespeichert wurde. Die Daten befinden sich in einem ähnlichen Format, wie Sie sie erhalten würden, wenn Sie ihre Text mit dem readtext-Package einlesen würden.
Quelle der Daten: Nulty, P. & Poletti, M. (2014). “The Immigration Issue in the UK in the 2014 EU Elections: Text Mining the Public Debate.” Presentation at LSE Text Mining Conference 2014. Geladen via dem Quanteda-Corpus_Package.
Bitte laden Sie den Datensatz in Ihr R-Environment.
Wir bereiten den Korpus zunächst für eine Analyse grob vor (wie bereits in den letzten Tutorials gezeigt):
- Wir speichern den Publikationsmonat der Dokumente ab, um diesen später für Vergleiche über Zeit anwenden zu können.
- Wir entfernen das pattern für einen Zeilenumbruch \n
- Wir führen die üblichen Preprocessing-Schritte durch, die im vorherigen Tutorial bereits erklärt wurden. Hier nutzen wir allerdings nur einige der vorab genannten Schritte.
#Wir lesen den Publikationsmonat heraus
library("stringr")
library("quanteda")
data$month <- str_extract(string = data$text,
pattern = "january|february|march|april|may|june|july|
august|september|october|november|december")
#Entfernung pattern Zeilenumbruch
data$text <- gsub(pattern = "\n", replacement = " ", x = data$text)
#Bereinigung durch Entfernung von Satzzeichen, Nummern, Kleinschreibung, etc.
tokens <- data$text %>%
tokens(what = "word",
remove_punct = TRUE,
remove_numbers = TRUE,
remove_url = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords("english"))
#Entfernung häufiger/seltener Wörter
dfm <- dfm_trim(dfm(tokens), min_docfreq = 0.005, max_docfreq = 0.99,
docfreq_type = "prop", verbose = TRUE)## Removing features occurring:## - in fewer than 14.165 documents: 33,992## - in more than 2804.67 documents: 2## Total features removed: 33,994 (86.8%).## Document-feature matrix of: 2,833 documents, 5,162 features (97.1% sparse).
## features
## docs support ukip continues grow labour heartlands miliband scared leo mckinstry
## text1 2 7 1 1 8 2 4 1 1 1
## text2 0 1 0 0 0 0 0 0 0 0
## text3 0 1 0 0 0 0 0 0 0 0
## text4 0 0 0 0 0 0 0 0 0 0
## text5 0 1 0 0 0 0 0 0 0 0
## text6 0 0 0 0 0 0 0 0 0 0
## [ reached max_ndoc ... 2,827 more documents, reached max_nfeat ... 5,152 more features ]Um sicherzugehen, dass wir keine wenig informativen Features übersehen haben, schauen wir uns noch einmal die Top Features unseres Datensatz an:
## © rights reserved said ltd immigration news one people may
## 2085 2014 1970 1766 1704 1687 1545 1522 1520 1458
## last newspapers also uk britain group mr new can now
## 1262 1250 1190 1177 1142 1088 1086 1085 1082 1076
## british national years just march party year david document first
## 1068 1040 1038 1033 1028 1010 1002 986 973 959
## home two time european april online many labour ukip country
## 948 931 931 919 913 897 879 876 874 870
## even political times minister media eu government like work made
## 854 828 828 827 825 822 811 794 787 785
## next london nigel says back make told cameron get immigrants
## 783 770 750 746 741 725 720 715 705 703
## election leader week come since farage much three say us
## 700 699 698 693 685 683 669 668 664 660
## per daily think public copyright way want £ telegraph right
## 650 636 635 633 625 611 607 604 600 596
## europe office well cent take tory number elections voters still
## 594 589 588 587 581 575 572 564 562 547
## prime secretary go world support yesterday part need found migrants
## 545 524 521 517 507 507 507 503 500 500Wir sehen, dass uns noch noch ein paar Feature entgangen sind, die eher aus den formalen Infos zu den Korpora stammen, etwa das häufigste Feature “©” oder Wörter, die auf Copyright-Verordnungen der Texte hinweisen, etwa “rights” und “reserved”. Wir können diese, sofern nötig, noch entfernen, da sie vmtl. wenig Substanzielles zur Analyse beitragen.
Jetzt haben wir unseren (grob) bereinigten Korpus - los geht’s mit Topic Modeling.
13.1 Grundsätzliches zur Funktionsweise von Topic Modeling
Topic Modeling - hier auch als “Themenanalyse” bezeichnet - beschreibt ein Verfahren des unüberwachten maschinellen Lernens, bei dem latente Themen auf Basis häufig gemeinsam auftretender Wörter explorativ identifiziert werden. Wir versuchen also durch das gemeinsame Auftreten von Wörtern auf latente Themen, die dieses Vorkommen erklären, zu schliessen.
Anders als beim unüberwachten maschinellen Lernen sind Themen nicht a priori bekannt, d.h. wir versuchen nicht, bekannte Themen zu identifizieren. Stattdessen wird die Analyse genutzt, um bisher unbekannte Themen in Texten zu identifizieren und interpretieren.
Im Groben folgen Themenmodelle - zumindest die Variante, die wir im Folgenden lernen - der folgenden Logik:
Der/die Forscher:in legt die vermutete Anzahl an Themen K fest, die er/sie in einem Korpus erwartet (z.B. K = 5, d.h. 5 Themen). Das Modell versucht dann, anhand der Verteilung von häufig gemeinsam vorkommenden Features induktiv 5 Themen im Korpus zu identifizieren. Dafür wird ein Algorithmus genutzt.
Die Wahl von K, d.h. ob ich mein Modell anweise 5 oder 100 Themen zu identifizieren, hat entsprechend einen grossen Einfluss auf die Ergebnisse. Je kleiner K, desto “gröber” und meist exklusiver die Themen; die grösser K, desto klarer identifizieren Themen einzelne Events oder Ereignisse, desto mehr überschneiden sich diese aber ggf. auch. Sie sehen: Die Wahl der Anzahl Themen K ist eine der wichtigsten, aber auch schwierigsten Schritte bei Themenmodellen.
Das Modell generiert zur Identifikation und Interpretation dieser 5 Themen zwei zentrale Ergebnisse:
- Wort-Topic-Matrix (beta-Matrix): Diese Matrix beschreibt die bedingte Wahrscheinlichkeit, mit der ein Feature in einem bestimmten Thema prävalent ist. Diese Matrix wird genutzt, indem man die wahrscheinlichsten Features je Thema interpretiert, um z.B. das latente Thema zu verstehen bzw. benennen. Es handelt sich also um Wortlisten, die ein Thema beschreiben.
- Dokument-Topic-Matrix (theta-Matrix): Diese Matrix beschreibt die bedingte Wahrscheinlichkeit, mit der ein Thema in einem bestimmten Dokument prävalent ist. Diese Matrix wird genutzt, um z.B. Artikel ein oder mehrere Hauptthemen zuzuordnen. Es handelt sich also um Themenlisten, die ein Dokument beschreiben.
Dabei enthalten Themenmodelle oft sogenannte Hintergrundthemen. Dies sind Themen, die wenig kohärent und damit nicht sinnvoll interpretierbar sind, weil sie z.B. keine ähnlichen Themen oder Ereignisse beschreiben. Oft identifizieren Themenmodelle aufgrund eines ähnlichen Schreibstils oder formaler Features, die häufig gemeinsam vorkommen, Themen, die wir als Hintergrundthemen einordnen würden. Solche Themen können für die Analyse ignoriert werden. Ein wichtiger Schritt der Interpretation des Themenmodells ist also auch, zu entscheiden, welche Themen sinnvoll interpretierbar sind und welche als Hintergrundthemen eingestuft und daher ignoriert werden. Je mehr Hintergrundthemen ein Modell aufweist, desto weniger hilft dieses, einen Korpus zu verstehen. Ein Modell, das nur Hintergrundthemen enthält, würde entsprechend nicht helfen, Themen in unserem Korpus zu identifizieren. Allerdings müssen Forscher:innen oft verhältnismässig subjektiv entscheiden, welche Themen einbezogen und welche als Hintergrundthemen eingestuft und damit ignoriert werden.
Wichtig ist dabei, dass allen Features eine bedingte Wahrscheinlichkeit > 0 und < 1 zugeordnet wird, mit der ein Feature in einem Dokument prävalent ist, d.h. kein Wert der Wort-Topic-Matrix _ nimmt genau den Wert null an. Ebenso wird allen Dokumenten eine bedingte Wahrscheinlichkeit > 0 und < 1 zugeordnet, mit der dieses ein bestimmtes Thema aufweist, d.h. keine Zelle der Dokument-Topic-Matrix nimmt genau den Wert null an. Das bedeutet vor allem, dass Themenmodelle nicht ein Hauptthema je Dokument identifieren, sondern alle Themen mit unterschiedlich hoher oder geringer Wahrscheinlichkeit in jedem Dokument vorkommen. Deswegen werden Themenmodelle auch als Mixed-Membership-Modelle bezeichnet, da sie eben eine Zuordnung von Dokumenten zu mehreren Themen und Features zu mehreren Themen mit unterschiedlich hoher Wahrscheinlichkeit erlauben. Wie Forscher:innen auf Basis der bedingten Wahrscheinlichkeiten entscheiden, ob ein Thema oder mehrere Themen in einem Dokument prävalent sind, ist entsprechend eine weitere Frage, die im Analyseprozess gestellt werden muss.
Sie sehen also: Themenmodelle bedürfen einiges an menschlicher (teils subjektiver) Interpretationsleistung, was u.a.
- die Wahl an K Themen angeht
- die Identifikation und Exklusion von Hintergrundthemen angeht
- die Interpretation der als relevant identifizierten Themen angeht
- die “Zuordnung” von Themen zu Dokumenten angeht
Sie haben bereits in der Seminarsitzung eine grundsätzliche Einführung zu Themenmodellen enthalten. An dieser Stelle sei daher nur noch einmal kurz auf die wichtigsten Aspekte bei der Anwendung von Themenmodellen bzw. Topic Modeling verwiesen:
Wichtige Hinweise für Topic Modeling:
Es gibt keine eindeutigen Kriterien dafür, wie Sie die Anzahl an Themen K festlegen bzw. welche Anzahl an Themen die “beste” ist oder welche Themen Sie ggf. als Hintergrundthemen ausschliessen. Ich würde Ihnen empfehlen, sich auf statistische Kriterien (etwa: statistischer Fit) und inhaltliche Interpretierbarkeit von Modellen (etwa: Interpretierbarkeit und Kohärenz der Themen auf Basis der Top-Wörter) zu verlassen.
Schauen Sie sich die Themen immer (!) manuell an, etwa über Top Features und Top Dokumente. Im bestmöglichen Fall sollten diese systematisch manuell validiert werden (s. nachfolgendes Tutorial).
Überlegen Sie genau, welche theoretischen Konzepte Sie mit Themen messen können. Seien Sie vorsichtig, Ihre Ergebnisse nicht “überzuinterpretieren” (s. etwa hier zu einer kritischen Diskussion dazu, ob man mittels Topic Modeling z.B. Frames erheben kann)
13.1.1 Grundlagentexte zu Topic Modeling
Folgende Texte bieten wertvolle Hinweise zur Methode:
Grundlegende, kommunikationswissenschaftliche Einführungstexte:
- Jacobi, C., van Atteveldt, W., & Welbers, K. (2016). Quantitative analysis of large amounts of journalistic texts using topic modelling. Digital Journalism, 4(1), 89–106. Link
- Maier, D., Waldherr, A., Miltner, P., Wiedemann, G., Niekler, A., Keinert, A., Pfetsch, B., Heyer, G., Reber, U., Häussler, T., Schmid-Petri, H., & Adam, S. (2018). Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology. Communication Methods and Measures, 12(2–3), 93–118. Link
Weitere, interdisziplinäre Einführungstexte:
- Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM, 55(4), 77–84. Link
- Heyer, G., Wiedemann, G., & Niekler, A. (2018). Topic-Modelle und ihr Potenzial für die philologische Forschung. In Lobin H., Schneider R., & Witt A. (Eds.), Digitale Infrastrukturen für die germanistische Forschung (pp. 351-368). Berlin; Boston: De Gruyter. Link
- Mohr, J. W., & Bogdanov, P. (2013). Introduction—Topic models: What they are and why they matter. Poetics, 41(6), 545–569. Link
- Roberts, M. E., Stewart, B. M., Tingley, D., Lucas, C., Leder-Luis, J., Gadarian, S. K., Albertson, B., & Rand, D. G. (2014). Structural Topic Models for Open-Ended Survey Responses: STRUCTURAL TOPIC MODELS FOR SURVEY RESPONSES. American Journal of Political Science, 58(4), 1064–1082. Link
- Schmidt, B. M. (2012) Words Alone: Dismantling Topic Modeling in the Humanities. Journal of Digital Humanities, 2(1). Link
- Quinn, K. M., Monroe, B. L., Colaresi, M., Crespin, M. H., & Radev, D. R. (2010). How to Analyze Political Attention with Minimal Assumptions and Costs. American Journal of Political Science, 54(1), 209–228. Link
- Wilkerson, J., & Casas, A. (2017). Large-Scale Computerized Text Analysis in Political Science: Opportunities and Challenges. Annual Review of Political Science, 20(1), 529–544. Link
13.2 Wie berechne ich ein Themenmodell?
Wir arbeiten im Folgenden mit dem Package stm Link und Structural Topic Modeling (STM). Während eine Vielzahl anderer Ansätze bzw. Themenmodelle existieren, z.B. Keyword-Assisted Topic-Modeling, Seeded LDA oder Latent Dirichlet Allocation (LDA) sowie Correlated Topics Models (CTM), gehen wir hier mit dem Structural Topic Modeling nur auf einen der vielen Ansätze ein.
STM hat mehrere Vorteile. So erlaubt das Verfahren unter anderem Korrelationen zwischen Themen. Mit STM können Sie zudem explizit zu modellieren, welche Variablen Einfluss auf die Prävalenz von Themen haben. Z.B. lässt sich so berechnen, inwiefern Themen über Jahre hinweg mehr oder weniger prävalent sind oder inwiefern bestimmte Medien mehr über ein Thema berichten
Wie berechnen wir also ein Themenmodell?
Zunächst müssen Sie Ihre DFM in das richtige Format bringen, um mittels dem stm-Packet Themenmodelle berechnen zu können. Dies geschieht folgendermassen:
Wir wollen jetzt beispielhaft ein Modell berechnen, bei dem 15 Themen identifiziert werden. Wie genau Sie die Anzahl an Themen festlegen können, lernen Sie im nächsten Abschnitt. Hier sollen Sie erstmal grundsätzlich verstehen, wie Themenmodelle aufgebaut sind, weshalb wir mehr oder minder willkürlich mit einem Modell mit K = 15 Themen arbeiten.
Zur Berechnung eines Themenmodells nutzen wir den Befehl stm. Folgende Parameter werden dabei für die stm-Funktion benötigt:
- document: Hier weisen wir die Funktion an, das Themenmodell mittels der Artikel unseres Korpus auszuführen. Diese sind im Objekt dfm_stm, d.h. der leicht angepassten Document-Feature-Matrix für das stm-Package, unter dfm_stm$documents zu finden.
- vocab: Hier weisen wir die Funktion an, das Themenmodell mittels der Features unseres Korpus auszuführen. Diese sind im Objekt dfm_stm unter dfm_stm$vocab zu finden.
- K: Hier weisen wir die Funktion an, 15 Themen zu identifizieren.
- verbose: Dieser Befehl führt dazu, dass R uns explizit ausgibt, welche Berechnungen aktuell durchgeführt werden.
library("stm")
model <- stm(documents = dfm_stm$documents,
vocab = dfm_stm$vocab,
K = 15,
verbose = TRUE)Schauen wir uns das Ergebnis an:

Was sehen Sie hier?
Der plot-Befehl gibt uns alle 15 Themen aus. Wie Sie bereits wissen, werden Themen durch häufig gemeinsam auftretende Wörter identifiziert.
- Die Features, die nach dem jeweiligen Thema (Topic 1, Topic 2, usw.) angezeigt werden, sind solche, die dieses Thema bestimmten. Z.B. sehen wir, dass sich Thema 7 um Steuern bzw. Finanzen zu drehen scheint: Hier kommen Features wie das Pfund-Zeichen “£”, aber auch Begriffe wie “tax” und “benefits” häufig vor.
- Die x-Achse (die horizontale Linie) gibt uns die “Expected Topic Proportions” an. Hier sehen wir z.B., dass die bedingte Wahrscheinlichkeit, dass Thema 13 vorkommt, bei 13% liegt. Damit ist das Thema von allen Themen das am häufig vorkommenste. Thema 4, das ganz unten steht, hat dagegen eine bedingte Wahrscheinlichkeit von 3-4% und ist damit vergleichsweise wenig prävalent.
Gehen wir auf die erste relevante Verteilung, die Wort-Topic-Matrix etwas genauer ein. Um unser Modell zu verstehen, müssen wir wissen, welche Wörter welches Thema auszeichnen.
Mit dem Befehl labelTopics können wir uns nächste die bezeichnenden Begriffe für jedes Thema ausgeben lassen. Der folgende Befehlt weist R an, uns die wichtigsten 5 Features für die ersten 5 Topics auszugeben (Parameter topics).
## Topic 1 Top Words:
## Highest Prob: immigration, minister, british, mr, said
## FREX: nanny, cable, cheap, brokenshire, metropolitan
## Lift: brokenshires, gita, tradesmen, lima, stewart
## Score: nanny, brokenshire, stewart, lima, cable
## Topic 2 Top Words:
## Highest Prob: per, cent, people, ethnic, britain
## FREX: ethnic, minority, cent, per, communities
## Lift: qualified, researchers, minorities, census, ethnic
## Score: cent, per, ethnic, qualified, minority
## Topic 3 Top Words:
## Highest Prob: scotland, newspapers, express, news, document
## FREX: scotland, scottish, sun, express, theexp
## Lift: 6en, ec3r, photo, salmonds, snp
## Score: photo, scotland, express, scottish, theexp
## Topic 4 Top Words:
## Highest Prob: telegraph, online, group, media, daily
## FREX: telegraph, teluk, dt, media, lords
## Lift: nelson, bulletin, dt, telegraph, teluk
## Score: telegraph, teluk, nelson, dt, media
## Topic 5 Top Words:
## Highest Prob: ukip, farage, party, said, mr
## FREX: racist, poster, posters, candidates, bnp
## Lift: thandi, henwood, lampitt, lizzy, mercer
## Score: farage, ukip, thandi, racist, lampittR gibt Ihnen dabei die wichtigsten Features je Topic auf vier verschiedene Arten und Weisen aus. Ich würde Ihnen dabei empfehlen, sich auf die FREX-Gewichtung zu konzentrieren. Grob gesagt zeigt Ihnen diese an, welche Wörter bei einem Thema vergleichsweise häufig vorkommen und exklusiv für ein Thema sind, d.h. vergleichsweise genau dieses Thema (und weniger stark andere Themen) auszeichnen. Im Vergleich zu den anderen Arten und Weisen, wie sich die wichtigsten Features je Thema gewichten bzw. ausgeben lassen, ist die FREX-Gewichtung meist besser zu interpretieren.
Sie sehen z.B. dass sich Thema 2 um das Thema “Minderheiten” zu drehen scheint, während die anderen Themen nicht eindeutig auf Basis der häufigsten 5 Wörter zu interpretieren sind.
Wollen wir jetzt die wichtigsten oder gar die Wahrscheinlichkeit aller Features für alle Themen nach FREX-Gewichtung sehen, können wir folgende Befehle verwenden.
Dabei werden die wichtigsten Wörter erst abgespeichert, dann wird nur die Frex-Ausgabe abgespeichert und schliesslich wird als Spalten-Name die jeweilige Topic-Nummer gesetzt
#Abspeicherung der wichtigsten Features (alle Gewichtungen)
labels <- labelTopics(model, n=20)
#nur FREX-Gewichtung
topwords <- data.frame("features" = t(labels$frex))
#setze Themennamen als Spaltennamen
colnames(topwords) <- paste("Topics", c(1:15))
#Zeig uns das Ergebnis
topwords## Topics 1 Topics 2 Topics 3 Topics 4 Topics 5 Topics 6 Topics 7 Topics 8 Topics 9
## 1 nanny ethnic scotland telegraph racist guardian tax ft asylum
## 2 cable minority scottish teluk poster grdn housing merkel deported
## 3 cheap cent sun dt posters pages income redistribute deportation
## 4 brokenshire per express media candidates guardiancouk prices financial judge
## 5 metropolitan communities theexp lords bnp bbc taxes paste police
## 6 elite minorities thesun online ukip theguardiancom pay web court
## 7 vince groups salmond bill ukips grultd taxpayers please arrested
## 8 wealthy university edinburgh <U+7AB6> candidate pounds wage email officers
## 9 lima white editorial group newark thats budget ftcom airport
## 10 employed suggests scots daily lampitt limited bank post yashika
## 11 workers study opinion lord racism radio spending articles wood
## 12 nannies likely alex reading mep im property ftcma seekers
## 13 downing research snp stel ukip's smith growth angela bageerathi
## 14 speech proportion yes georgia henry weve benefit germany passengers
## 15 citizen survey independence peers farage programme £ movement jail
## 16 employers asian c cardinal sykes humphrys billion ed1 removal
## 17 theresa census javid questions comments copyright money treaty criminals
## 18 james black border tim interview ive banks eu prison
## 19 employ among glasgow <U+51B1> farages theyre benefits german mauritius
## 20 cleaner population thesuk peter thandi cant rate referendum jailed
## Topics 10 Topics 11 Topics 12 Topics 13 Topics 14 Topics 15
## 1 net tories prince film pupils lib
## 2 migration miliband charles theatre school clegg
## 3 tens voters thatcher music visas dems
## 4 bulgarians conservatives miller novel serco dem
## 5 target seats hitler art schools nick
## 6 figures ed maria america places debate
## 7 numbers election royal american nhs debates
## 8 arrivals boris margaret father primary farage
## 9 students vote putin son executive cleggs
## 10 statistics johnson christian dark patients deputy
## 11 romania general russian plays cancer nigel
## 12 thousands labour church writer language leader
## 13 bulgaria win ukraine award test televised
## 14 restrictions leadership religious book investor establishment
## 15 migrants conservative ferguson play route liberal
## 16 pledge polls faith drama skills won
## 17 romanians tory facebook beautiful hospital leaders
## 18 number parties russia characters applicants conference
## 19 arriving poll gay character teachers democrat
## 20 poland party archbishop arts education loveDer Dataframe topwords beruht damit auf der Wort-Topic-Matrix und beschreibt die bedingte (und hier gewichtete) Wahrscheinlichkeit, mit der ein Feature in einem bestimmten Thema prävalent ist. Diese Liste an Features, die ein Thema “ausmachen”, wird vor allem genutzt, um z.B. Themen zu verstehen bzw. benennen. Sie enthält im Prinzip die gleichen Informationen wie die, die sie mit dem Befehl labelTopics enthalten.
Wie zuvor angesprochen, ist aber auch die Dokument-Topic-Matrix von Bedeutung. Diese Matrix beschreibt die bedingte Wahrscheinlichkeit, mit der ein Thema in einem bestimmten Dokument prävalent ist. Diese Matrix wird genutzt, indem man die wahrscheinlichsten Themen je Dokument nutzt, um z.B. Artikel ein oder mehrere Hauptthemen zuzuordnen. Mit dem Befehl make.dt können wir diese Matrix erhalten. Wir lassen uns hier ausgeben, mit welcher bedingten Wahrscheinlichkeit alle Themen im ersten Dokument vorkommen.
## docnum Topic1 Topic2 Topic3 Topic4 Topic5 Topic6 Topic7 Topic8 Topic9
## 1: 1 0.003935035 0.04556144 0.004846942 0.003014408 0.009297329 0.004452513 0.005698955 0.00926361 3.567387e-05
## Topic10 Topic11 Topic12 Topic13 Topic14 Topic15
## 1: 0.00426147 0.7872743 0.001564772 0.001601545 0.0009265871 0.1182654Sie sehen hier also, welche Themen (in den Spalten) in welchen Artikeln (in den Zeilen) mit welcher Wahrscheinlichkeit prävalent sind.
Jetzt wissen Sie grundsätzlich, wie Themenmodelle aufgebaut sind. Gehen wir nun also wieder einen Schritt zurück: Wie lässt sich entscheiden, wie viele Themen K Sie dem Modell als Vorgabe geben und damit identifizieren werden sollen?
13.2.1 Wie lege ich fest, wie viele Themen identifiziert werden sollen?
Wie bereits erwähnt, sollten Sie zwei grundsätzliche Kriterien beachten, um sich zu entscheiden, für welches K Sie eine Themenanalyse durchführen:
- statistischer Fit
- Interpretierbarkeit der Themen
Wichtig ist, dass statistischer Fit und Interpretierbarkeit von Themen nicht immer Hand in Hand gehen. So zeigen Studien, dass Modelle mit gutem statistischem Fit oft menschlich schwer interpretierbar sind und nicht unbedingt sinnvolle Themen enthalten. Entsprechend liegt es an Ihnen als Forscher:innen, diesen Kriterien mehr oder weniger Raum zu geben.
Wir schauen uns hier zudem nur sehr beispielhaft an, wie sich Forscher:innen für die Anzahl an Themen entscheiden würden. In Ihrer eigenen Studien würden Sie nicht nur diese und mehr Kriterien einbeziehen, sondern auch nicht, wie es nachfolgend geschieht, nur Modelle mit 4 und 6 Themen vergleichen. Der nachfolgend aufgeführte Entscheidungspfad bzgl. einer Anzahl K von Themen für die eigene Analyse wird hier also sehr verkürzt dargestellt.
Eben weil sich die Anzahl an Themen K nicht eindeutig durch einen Kennwert o.ä. bestimmen lässt, sollten Sie immer transparent machen, wie Sie an die Wahl von K herangegangen sind und weshalb Sie sich schlussendlich für eine bestimmte Anzahl an Themen K entschieden haben.
13.2.2 Kriterium 1: Statischer Fit
Mit dem stm-Package lässt sich die Anzahl Themen grob durch statistische Indizes eingrenzen (aber nicht eindeutig bestimmen).
Der Befehl searchK gibt Ihnen den statistischen Fit für Modelle mit unterschiedlichem K an. Wir greifen hier der Einfachheit halber nur auf zwei Kriterien, die semantische Kohärenz und die Exklusivität von Themen, zu, die beide möglichst hoch sein sollten. Der hier verwendete Code ist eine Adaption von Julia Silge’s STM Tutorial, das hier verfügbar ist.
- Semantische Kohärenz: Dieser Wert gibt Ihnen an, wie kohärent Themen in einem Modell sind, d.h., wie oft für Themen relevante Wörter gemeinsam vorkommen und Themen damit (scheinbar) ein klares Thema beschreiben.
- Exklusivität: Dieser Wert gibt an, wie exklusiv Themen in einem Modell sind, d.h., wie stark sie sich voneinander unterscheiden und Themen damit (scheinbar) verschiedene Dinge beschreiben.
Zunächst berechnen wir beide Werte für Themenmodelle mit 4 und 6 Themen:
Anschliessend lassen wir uns beide Kennwerte als Visualisierung ausgeben. Dies bietet sich v.a. an, wenn Sie mehr Modelle als zwei vergleichen.
plot <- data.frame("K" = rep(K,2),
"Metrik" = c(fit$results$semcoh, fit$results$exclus))
plot$Beschreibung <- c(rep("Kohärenz",length(K)), rep("Exklusivität", length(K)))
plot## K Metrik Beschreibung
## 1 4 -44.365386 Kohärenz
## 2 6 -47.595451 Kohärenz
## 3 4 8.584749 Exklusivität
## 4 6 8.849567 Exklusivitätlibrary("ggplot2")
ggplot(plot, aes(K, Metrik, color = Beschreibung)) +
geom_line(size = 1.5, show.legend = FALSE) +
facet_wrap(~Beschreibung,scales = "free_y") +
labs(x = "Anzahl der Themen K",
title = "Semantische Kohärenz und Exklusivität der Themen")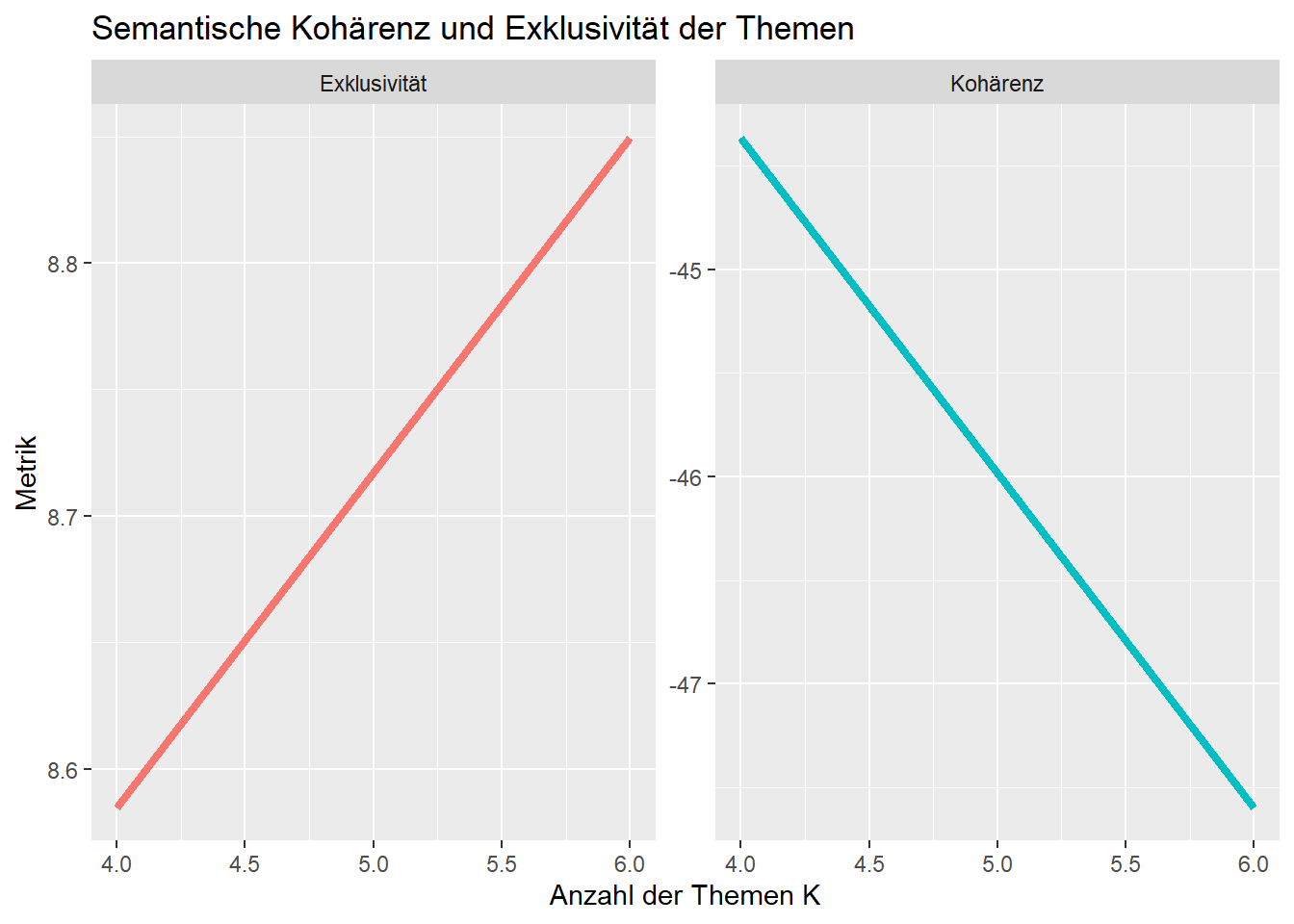
Sie sehen also: Die Exklusivität der Themen steigt, je mehr Themen wird R berechnen lassen. Dagegen sinkt die Kohärenz der Themen, je mehr Themen wir haben. Wir würden also auf Basis dieser statistischen Kriterien nicht genau entscheiden können, ob ein Modell mit 4 oder 6 Themen “besser” ist: Beim einen Modell sind die Themen exklusiver, d.h. unterschiedlicher, aber weniger kohärent, d.h. ggf. weniger sinnvoll interpretierbar. Beim anderen Modell ist es genau andersherum.
13.2.3 Kriterium 2: Interpretierbarkeit und Relevanz der Themen
Ein zweites - und oft wichtigeres Kriterium - ist die Interpretierbarkeit und Relevanz von Themen. Speziell sollten Sie sich für ausgewählte Modelle anschauen, wie viele der identifizierten Themen sinnvoll interpretierbar sind und welche eher als Hintergrundthemen zu verstehen sind. Je mehr Hintergrundthemen ein Modell aufweist, desto eher ist dieses vmtl. unpassend, um Themen in Ihrem Korpus sinnvoll zu schreiben.
Dabei bieten sich mehrere Kriterien an, die wir hier beispielhaft für das Modell mit 4 und 6 Themen anschauen, nämlich die Interpretierbarkeit von Themen (anhand von Top Features und Top Dokumenten) wie auch die Relevanz von Themen (anhand der Rank-1 Metrik).
Zunächst berechnen wir ein Modell mit K = 4 und K = 6 Themen.
model_4K <- stm(documents = dfm_stm$documents,
vocab = dfm_stm$vocab,
K = 4,
verbose = TRUE)
model_6K <- stm(documents = dfm_stm$documents,
vocab = dfm_stm$vocab,
K = 6,
verbose = TRUE)Um Themen zu interpretieren (und damit ggf. daraus zu schliessen, welche Modelle mehr sinnvolle Themen im Vergleich zu anderen Modellen enthalten), können Sie sich u.a. drei Aspekte anschauen.
1: Top Features je Thema
Sie haben bereits gelernt, wie Sie sich die Top Features je Thema ausgeben lassen. Anhand dieser können Sie bereits sehen, wie sinnvoll bzw. stimmig sich Themen interpretieren lassen. Sie können darüber auch sehen, wie sich Themen bei Modellen mit kleinerem oder grösseren K verändern.
Schauen wir uns die Top Features, hier die Top 20 Frex Features, einmal für die Themenmodelle mit 4 und 6 Themen an:
#für 4 Themen
Themen_4 <- labelTopics(model_4K, n=10)
Themen_4 <- data.frame("features" = t(Themen_4$frex))
colnames(Themen_4) <- paste("Topics", c(1:4))
Themen_4## Topics 1 Topics 2 Topics 3 Topics 4
## 1 police migration book farage
## 2 nanny net prince ukip
## 3 asylum numbers story voters
## 4 court restrictions film party
## 5 deportation increase music clegg
## 6 deported merkel theatre nigel
## 7 illegal growth features miliband
## 8 judge migrants america lib
## 9 passport countries american vote
## 10 arrested benefit parents farages#für 6 Themen
Themen_6 <- labelTopics(model_6K, n=10)
Themen_6 <- data.frame("features" = t(Themen_6$frex))
colnames(Themen_6) <- paste("Topics", c(1:6))
Themen_6## Topics 1 Topics 2 Topics 3 Topics 4 Topics 5 Topics 6
## 1 scotland net film court farage indeed
## 2 nanny migration son police ukip society
## 3 scottish numbers theatre judge party thatcher
## 4 brokenshire restrictions music investigation nigel bbc
## 5 cable figures america criminals elections prince
## 6 cheap increase facebook criminal farages margaret
## 7 ms merkel novel arrested voters might
## 8 wealthy bulgarians love officers poll ukraine
## 9 metropolitan financial father passengers dems global
## 10 mrs ft art serco miliband hitlerSie sehen: Die Modelle mit 4 und 6 Themen beinhalten de facto 4 mehr oder weniger gleiche Themen.
- Thema 1 im Modell mit K = 4 und Thema 2 mit Modell K = 6 scheinen sich um Deportationen und Asylpolitik zu drehen.
- Thema 2 im Modell mit K = 4 und Thema 2 mit Modell K = 6 scheinen sich um Migration zu drehen.
- Thema 3 im Modell mit K = 4 und Thema 3 mit Modell K = 6 scheinen sich um Kultur und Kunst zu drehen.
- Thema 4 im Modell mit K = 4 und Thema 4 mit Modell K = 6 scheinen sich um den Politiker Farage und die Partei UKIP zu drehen.
Beim Modell mit 6 Themen kommen noch zwei weitere Themen hinzu: Thema 1 und Thema 6. Sie könnten also inhaltlich entscheiden, ob die neuen Themen im Modell mit 6 Themen (hier Thema 1 und 6) inhaltlich so relevant sind, dass Sie das Modell mit K = 6 gegenüber dem Modell mit K = 4 bevorzugen würden.
2: Top Dokumente je Thema
Zudem sollten Sie sich immer beispielhaft Dokumente durchlesen, die für ein spezifische Thema eine hohe Wahrscheinlichkeit ausweisen, d.h. in denen dieses Thema mit vergleichsweise hoher Wahrscheinlichkeit prävalent ist. Diese Dokumente repräsentieren dieses Thema beispielhaft.
Mit dem findThoughts-Befehl lassen sich Artikel ausgeben, in denen ein ausgewähltes Thema sehr prävalent ist - hier z.B. das erste Thema im Modell mit vier Themen (bei Ihrer Analyse sollten Sie das mit mehr Artikeln, z.B. den ersten 10 Artikeln, tun):
##
## Topic 1:
## yashika bageerathis final appeal against deportation rejected by judge mark tran theguardiancom 596 words 3 april 2014 guardiancouk grultd english c 2014 guardian news & media limited all rights reserved lord justice richards refuses to grant emergency injunction as mauritian student 19 is taken to airport a judge has rejected a final appeal against the deportation of a 19-year-old mauritian student hours before she was due to depart heathrow lawyers for yashika bageerathi lodged papers with a judge at the high court seeking an emergency injunction to block her removal and give her time to take her case to the court of appeal as she was being driven to heathrow on wednesday to await her flight at 9pm lord justice richards refused to order a stay of deportation in a telephone hearing a spokesman for the oasis academy hadley in north london where bageerathi has been studying said she was set to fly out of terminal 4 on an air mauritius flight this will be the third attempt to send her back to mauritius in little over a week bageerathi was very distressed and worried the spokesman added he said she is on her way in the van but i really hope we can keep her here were encouraging everyone to tweet air mauritius and to phone them to stop this she was supposed to have gone on sunday but her supporters said air mauritius had refused to fly her out following an earlier refusal by british airways but despite a vocal campaign for bageerathi to stay so she can finish her a-levels the home office is adamant that she should return to mauritius on monday james brokenshire the immigration minister told the house of commons that the home office would not intervene he said her case had been through the proper legal process and the home offices decision that she did not need protection from violence or persecution in her homeland had been upheld brokenshire said that given the extent and level of judicial and other scrutiny the home secretary theresa may had decided not to intervene bageerathi has been held at yarls wood immigration removal centre near bedford since 19 march she came to the uk with her mother sister and brother in 2011 to escape a relative who was physically abusive and they claimed asylum last summer but the family were told they all faced the threat of deportation bageerathi is being deported without her mother and two siblings because as an adult her case was considered separate to theirs a petition calling on authorities to stop the deportation has gathered more than 175000 signatures on the website changeorg campaigners who include her schoolmates and the school principal said yashika bageerathi arrived in the uk along with her mother and brother in 2012 to escape abuse and danger in that time yashika has proved herself a model student and valuable member of the co
## mauritian student deported on flight from heathrow after judge refuses to grant emergency injunction to allow her to appeal her case tara brady and damien gayle 1196 words 3 april 2014 0024 mail online damonl english © 2014 associated newspapers all rights reserved * yashika bageerathi boarded a flight at heathrow airport at 9pm * the 19-year-old was being held at yarls wood immigration removal centre * ms bageerathi was studying at oasis academy hadley in enfield london * immigration minister james brokenshire said she had to be deported * a petition with 175000 signatures called for her to be allowed to sit exams an a-level student has been deported to mauritius after a last-ditch bid to let her stay in the country was denied a judge at londons law courts refused to grant an emergency injunction to block the removal of mauritian teenager yashika bageerathi from britain the 19-year-old has now been sent back alone to her home country separated from her mother and her siblings after immigration authorities refused her claim for asylum the decision slaps down a high-profile campaign which had sought to reverse the decision to deport ms bageerathi a promising student before she was able to take her a-level exams it has been reported by itv that shortly before boarding the plane the teenager spoke to her mother asking her what to do when she landed and if there would be anyone there to meet her a spokesman for oasis a campaign group which is fighting for miss bageerath to stay said the last we we heard is that the flight was taxiing on the runway the teenager had been held at yarls wood immigration removal detention centre in hertfordshire since march 19 a spokesman for the oasis academy hadley in enfield north london where ms bageerathi was a student earlier said that the youngster was very distressed and worried at the prospect of her deportation ms bageerathi has earlier sobbed as she told her school friends she feared for her life when she was suddenly told at 330pm that she was due to board a plane in less than six hours two previous attempts to deport her were stopped when airlines reportedly refused to let her board their aircraft her deportation was branded outrageous by her headteacher who said ms bageerathi was an exceptional case that should stop her being kicked out of the country the teenager fled from mauritius in 2011 and claimed asylum last summer alleging she suffered physical abuse from a relative she was living in the uk with her mother younger sister and brother the gifted schoolgirl was due to take her a levels next month ms bageerathi was allowed one phone call before being made to leave and broke down as she told her teacher at oasis academy in enfield north london what was going on lynne dawes headteacher of the school said she was crying and just d
## news student given late reprieve on deportation as ba refuse to take her by tom whitehead security editor 355 words 31 march 2014 2001 the telegraph online teluk english the telegraph online © 2014 telegraph media group ltd yashika bageerathi's mp said the flight operator had refused to fly her back to mauritius as he urges home office to reconsider a student fighting deportation has had a last minute reprieve - after british airways refused to take her on a flight according to her mp the home office and ba have refused to say why yashika bageerathi's planned removal was postponed yesterday but it came amid a high profile campaign to stop it plane operators have previously refused to take deportees when they have become disruptive shortly before take-off but miss bageerathi was not being a nuisance and was not even on board when the decision was taken the 19-year-old from mauritius was at gatwick airport awaiting deportation when she was returned to a detention centre the teenager who lost an appeal last wednesday fled mauritius with her mother and brother in 2012 to escape a relative who had been physically abusing her she was due to fly back this afternoon having been in detention at yarls wood immigration removal centre bedfordshire since wednesday it came after extensive campaigning by her fellow pupils who used social media and demonstrations to protest against the decision to send ms bageerathi back a petition by the students calling on immigration minister james brokenshire and home secretary theresa may to stop the deportation and allow the student to complete her a-levels garnered nearly 23000 signatures on changeorg model cara delevingne also made a plea on twitter to mrs may not to send the aspiring maths teacher back the teenager's mp david burrowes has made representations to the home office to delay her deportation he said the home office tod him british airways ba refused to take ms bageerathi on the plane but neither ba nor the home office would comment the mp for enfield southgate added that the decision to remove the teenager would have had to be delayed regardless because the minister has to consider my representation before removal document teluk00020140325ea3p0050lWir sehen also: Im ersten Thema scheint es recht klar um Deportationen zu gehen, zumindest lässt der Beispielartikel dies vermuten.
3: Rank-1 Metrik
Um zu beurteilen, welche Anzahl von Themen K berechnet werden sollten und welche Themen besonders relevant und stabil sind, ist es oft hilfreich, sich auch die Rank1-Metrik anzusehen. Diese beschreibt, in wie vielen Dokumenten ein Thema das wichtigste Thema ist.
Dabei wird jedem Dokument genau ein Hauptthema zugeordnet, nämlich das Thema, das laut Dokument-Topic-Matrix in diesem Dokument am prävalensten ist.
Wir erinnern uns: Wir konnten uns mit dieser Matrix ausgeben lassen, mit welcher bedingten Wahrscheinlichkeit jedes Thema in jedem Dokument vorhanden ist.
Zunächst lassen wir uns die Dokument-Topic-Matrix für beide Modelle ausgeben.
Diese Information können wir jetzt nutzen, um jedem Dokument genau ein Thema, nämlich das, was für ein Dokument die höchste Wahrscheinlichkeit aufweist, zuzuordnen.
Sie sollten dabei kritisch im Hinterkopf behalten, dass es sich bei Themenmodelle um sogenannten Mixed-Membership-Modelle handelt, d.h. jedes Thema mit einer bestimmten Wahrscheinlichkeit in jedem Dokument auftaucht (auch wenn diese ggf. nur sehr gering ist). In dem Sie jedem Dokument nur ein Thema zuordnen, verlieren Sie also eine ganze Menge an Informationen über die Relevanz, die andere Themen für dieses Dokument spielen (könnten).
Trotzdem liefert die Rank1-Metrik, d.h. die absolute Anzahl an Dokumenten, in denen ein Thema das prävalenteste ist, Hinweise darauf, wie häufig oder wenig häufig diese sind und zT auch, wie sich das Vorkommen von Themen über Modelle mit verschiedenen K hinweg verändert.
Wir lassen uns jetzt die Rank1-Metrik ausgeben. Dabei weisen wir jedem Dokument das Thema zu, das für dieses Dokument die höchste bedingte Wahrscheinlichkeit hat:
#Wir erstellen zunächst im Datensatz einen Plathalter für die Rank1-Metriken
data$Rank1_K4 <- NA #für Modell mit 4 Themen
data$Rank1_K6 <- NA #für Modell mit 6 Themen
#speichere Rank1 für Modell mit 4 Themen
for (i in 1:nrow(data)){
column <- theta_4K[i,-1]
maintopic <- colnames(column)[which(column==max(column))]
data$Rank1_K4[i] <- maintopic
}
table(data$Rank1_K4)##
## Topic1 Topic2 Topic3 Topic4
## 461 730 800 842#speichere Rank1 für Modell mit 6 Themen
for (i in 1:nrow(data)){
column <- theta_6K[i,-1]
maintopic <- colnames(column)[which(column==max(column))]
data$Rank1_K6[i] <- maintopic
}
table(data$Rank1_K6)##
## Topic1 Topic2 Topic3 Topic4 Topic5 Topic6
## 203 505 530 417 780 398Wir sehen also: Die Themen sind sowohl beim Modell mit K = 4 Themen und K = 6 Themen alle verhältnismässig gross, d.h. recht viele Dokumente werden den einzelnen Themen zugeordnet. Hätten wir hier z.B. ein Thema, bei dem nur sehr wenig Dokumente diesen zuzuordnen sind, wäre das ggf. ein Hinweis dafür, dass es sich bei um ein Hintergrundthema handelt, das für die Interpretation eher aussortiert wird.
13.3 Wie beziehe ich unabhängige Variablen ein?
Sobald wir uns für ein Modell mit K Themen entschieden haben, können wir die Analyse durchführen und die Ergebnisse interpretieren. Der Einfachheit halber nehmen wir jetzt beispielhaft das Modell mit K = 6 Themen, obwohl weder der statistische Fit noch die inhaltliche Interpretierbarkeit uns hier eindeutige Hinweise darauf liefert, ob eines der beiden Modelle mit 4 oder 6 Themen gute oder bessere Ergebnisse liefert.
Wie vorab erwähnt, bietet Structural Topic Modeling den Vorteil, dass wir den Einfluss von unabhängigen Variablen auf die Prävalenz von Themen berechnen können. Nehmen wir einmal an, dass uns interessiert, ob bestimmte Themen mehr oder weniger über Zeit vorkommen. Wir hatten in unserem Data-Frame bereits abgespeichert, in welchem Monat eine Variable vorkommt:
##
## april february january march may
## 827 248 1 908 849Um zu schauen, ob sich der Publikationsmonat, d.h. ob ein Artikel eher zu Beginn des Untersuchungszeitraum oder Ende des Untersuchungszeitraums publiziert wurde, auf die Prävalenz von Themen auswirkt, nutzen wir hier den Publikationsmonat. Dieser ist aktuell noch als nominale Variable abgespeichert, da die Variable den jeweiligen Namen des Monats enthält.
Um zu analysieren, ob Themen im Zeitverlauf mehr/weniger vorkommen, wandeln wir den Monat in eine metrische Variable um:
data$month[data$month=="january"] <- 1
data$month[data$month=="february"] <- 2
data$month[data$month=="march"] <- 3
data$month[data$month=="april"] <- 4
data$month[data$month=="may"] <- 5
data$month <- as.numeric(data$month)
table(data$month)##
## 1 2 3 4 5
## 1 248 908 827 849Jetzt berechnen wir das Modell mit 6 Themen. Dabei beziehen wir die von uns gewählte unabhängige Variable, den Publikationsmonat, ein (wollen Sie keine unabhängige Variable benutzen, könnten Sie auch einfach auf das bereits abgespeicherte Objekt model_6K zurückgreifen).
Dabei benötigen wir für den stm-Befehl zwei neue Parameter im Vergleich zur Formel zuvor:
- prevalence: Hier geben wir die Formel ein, mittels derer die Prävalenz von Themen modelliert werden soll. Dabei weisen wir R an, dass die Prävalenz aller Themen anhand des Publikationsmonats modelliert werden soll, d.h. wir schauen wollen, wie sich der Monat eines Artikels darauf auswirkt, wie prävalent Themen sind. Wir modellieren hier also eine lineare Beziehung zwischen der Prävalenz von Themen (abhängige Variable) und dem Publikationsmonat (unabhängige Variable).
- data: Hier weisen wir R an, in welchem Objekt die unabhängigen Variablen zu finden sind. In unserem Fall ist das der ursprüngliche Dataframe data, indem wir die Texte und zugehörige Meta-Informationen zu diesen abgespeichert hatten.
model <- stm(documents = dfm_stm$documents,
vocab = dfm_stm$vocab,
K = 6,
prevalence = ~month,
data = data,
verbose = TRUE)Wie bereits in dem Abschnitt Kriterium 2: Interpretierbarkeit und Relevanz der Themen diskutiert, könnten Sie sich nun anschauen, welche Inhalte in den einzelnen Themen diskutiert werden, d.h. welche Themen (wie oft) vorkommen.
Ein weiterer Analyseschritt wäre, sich das Vorkommen von Themen in Abhängigkeit von unabhängigen Variablen ausgeben zu lassen.
Mit dem Befehlt estimateEffect lassen sich die Effekte der Variable “Monat” auf die Prävalenz von Themen aufzeigen:
Die Ergebnisse dieses Regressions-Modells lassen sich folgendermassen inspizieren, wobei wir uns hier nur die Zu- oder Abnahme der ersten drei Themen über Monate hinweg, d.h. in Abhängigkeit von Zeit, ausgeben lassen:
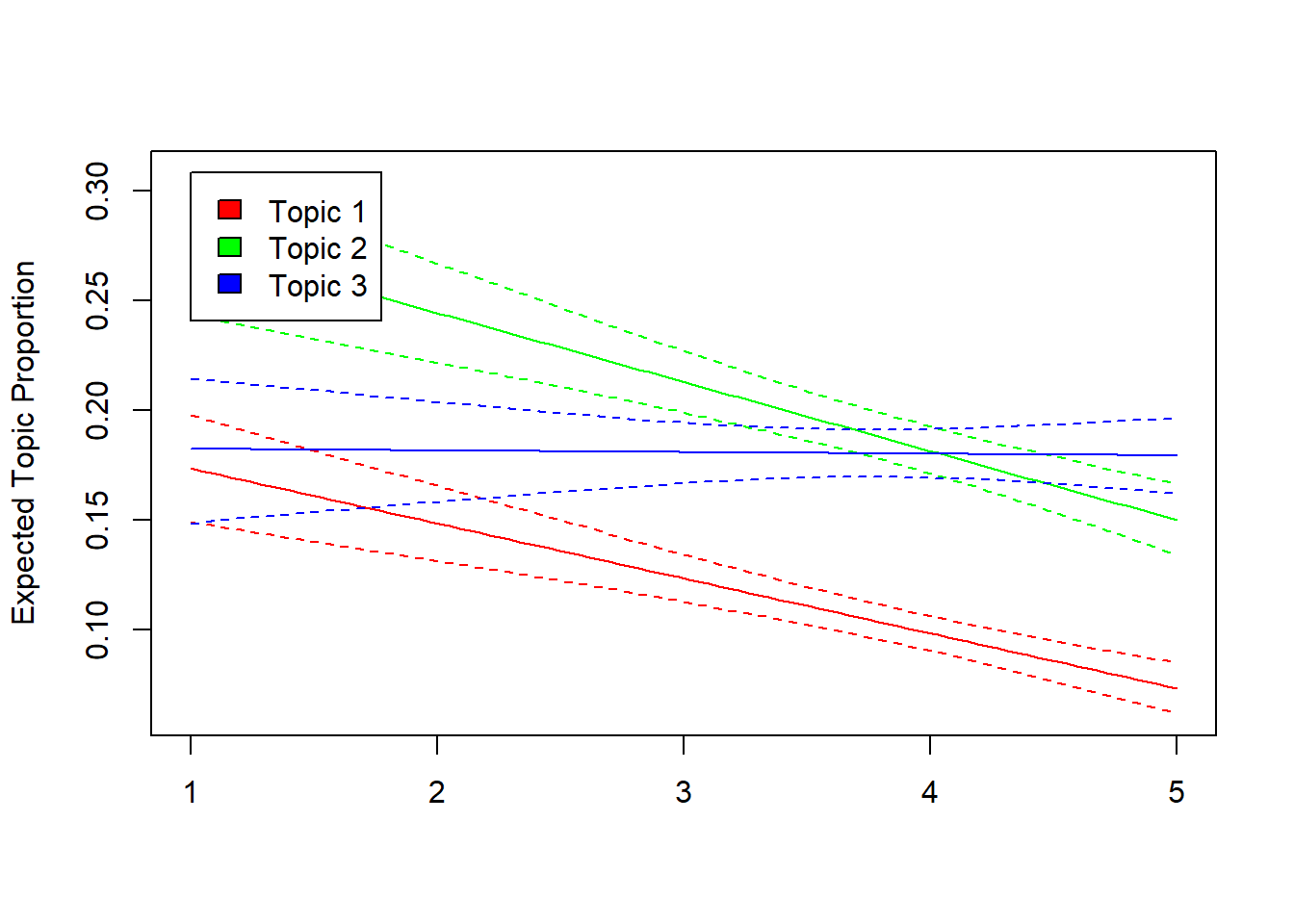
Wir sehen also, dass Thema 1 und 2 über Zeit hinweg eher weniger vorkommen, Zeit also einen negativen Einfluss hat, während sich für Thema 3 kein konsistenter Trend zeigt, es also keine konsistente, lineare Assoziation zum Publikationsmonat gibt.
Ein nächster Schritt wäre dann die Validierung der gefundenen Themen. Zur Validierung automatisierter Inhaltsanalyse kommen wir anschliessend im letzten Tutorial des Seminars.
13.4 Take Aways
Vokabular:
- Topic Modeling: Verfahren des unüberwachten maschinellen Lernens, bei dem explorativ Themen in einem Korpus identifiziert werden. Oft handelt es sich dabei um sogenannte Mixed-Membership-Modelle.
- K: Anzahl an Themen, die in einem Themenmodell berechnet werden sollen.
- Wort-Topic-Matrix: Matrix, welche die bedingte Wahrscheinlichkeit beschreibt, mit der ein Feature in einem bestimmten Thema prävalent ist.
- Dokument-Topic-Matrix: Matrix, welche die bedingte Wahrscheinlichkeit beschreibt, mit der ein Thema in einem bestimmten Dokument prävalent ist.
Befehle:
- STM-Analyse durchführen: convert(), stm
- Anzahl von Themen K bestimmen: searchK()
- STM-Modell inspizieren: plot(), labelTopics(), make.dt(), findThoughts(), estimateEffect()
13.5 Weitere Tutorials zu diesen Schritten
Sind Fragen offen geblieben? Folgende Tutorials & Paper helfen zu den hier genannten Schritten weiter:
- Computational Methods in der politischen Kommunikationsforschung von J. Unkel, Tutorial 121
- Automatisierte Inhaltsanalyse mit R von C. Puschmann, Tutorial “Themenanalyse”
- Training, evaluation and interpreting topic models von Julia Silge
- Unsupervised Learning Methods von Theresa Gessler
- Fitting LDA Models in R von Wouter van Atteveldt
Wir machen weiter: mit Tutorial 14: Validierung automatisierter Analysen