28 벡터
28.1 들어가기
지금까지 이 책은 티블이라는 데이터 유형, 또 이와 함께 작동하는 패키지들을 중점적으로 살펴보았다. 그러나 자신만의 함수를 작성하고 R 을 더 깊이 파기 시작하려면 티블의 기초 객체인 벡터에 대해 알아야 한다. R 을 전통적인 방법으로 배운 사람은 이미 벡터가 익숙할 것이다. 대부분의 R 리소스가 벡터로 시작하여 티블에까지 동작하기 때문이다. 배우고 나면 바로 유용하게 사용할 수 있는 티블부터 시작한 다음, 기본 구성요소로 나아가는 것이 더 바람직하다고 생각한다.
작성하는 함수의 대부분은 벡터에 작동할 것이기 때문에 벡터는 매우 중요하다. ggplot2, dplyr, tidyr 에서와 같이 티블에 작동하는 함수를 작성할 수도 있지만, 이러한 함수 작성에 필요한 도구는 아직 일반화되거나 성숙되지 않았다. 나는 더 나은 접근법(https://github.com/hadley/lazyeval)을 만들고 있지만, 이 책이 출판되기 전까지 준비되지 않을 것이다. 설령 완료되더라도 여전히 벡터를 이해해야 한다. 새로운 접근법은 사용자 친화적 레이어를 맨 위에 만드는 것만 수월하게 해주기 때문이다.
28.2 벡터 기본 사항
벡터는 두 가지 유형이 있다.
원자 벡터: 여섯 가지 유형, 논리형(logical), 정수형(integer), 더블형(double), 문자형(character), 복소수형(character), 원시형(raw) 이 있다. 정수형 및 더블형 벡터는 합쳐서 수치형(numeric) 벡터라고 한다.
리스트: 재귀적 벡터라고 할 수 있는데, 한 리스트가 다른 리스트를 포함할 수 있기 때문이다.
원자 벡터와 리스트의 가장 큰 차이점은 원자 벡터가 동질적인 반면, 리스트는 이질적이 될 수 있다는 것이다. 이와 관련한 또 다른 객체는 NULL 이다. NULL 은 벡터가 없는 것을 나타내기 위해 종종 사용된다 (반면, NA는 벡터의 값이 없음을 나타내는데 사용됨). NULL 은 일반적으로 길이가 0 인 벡터처럼 동작한다. 28.1 에는 상호 관계가 요약되어 있다.
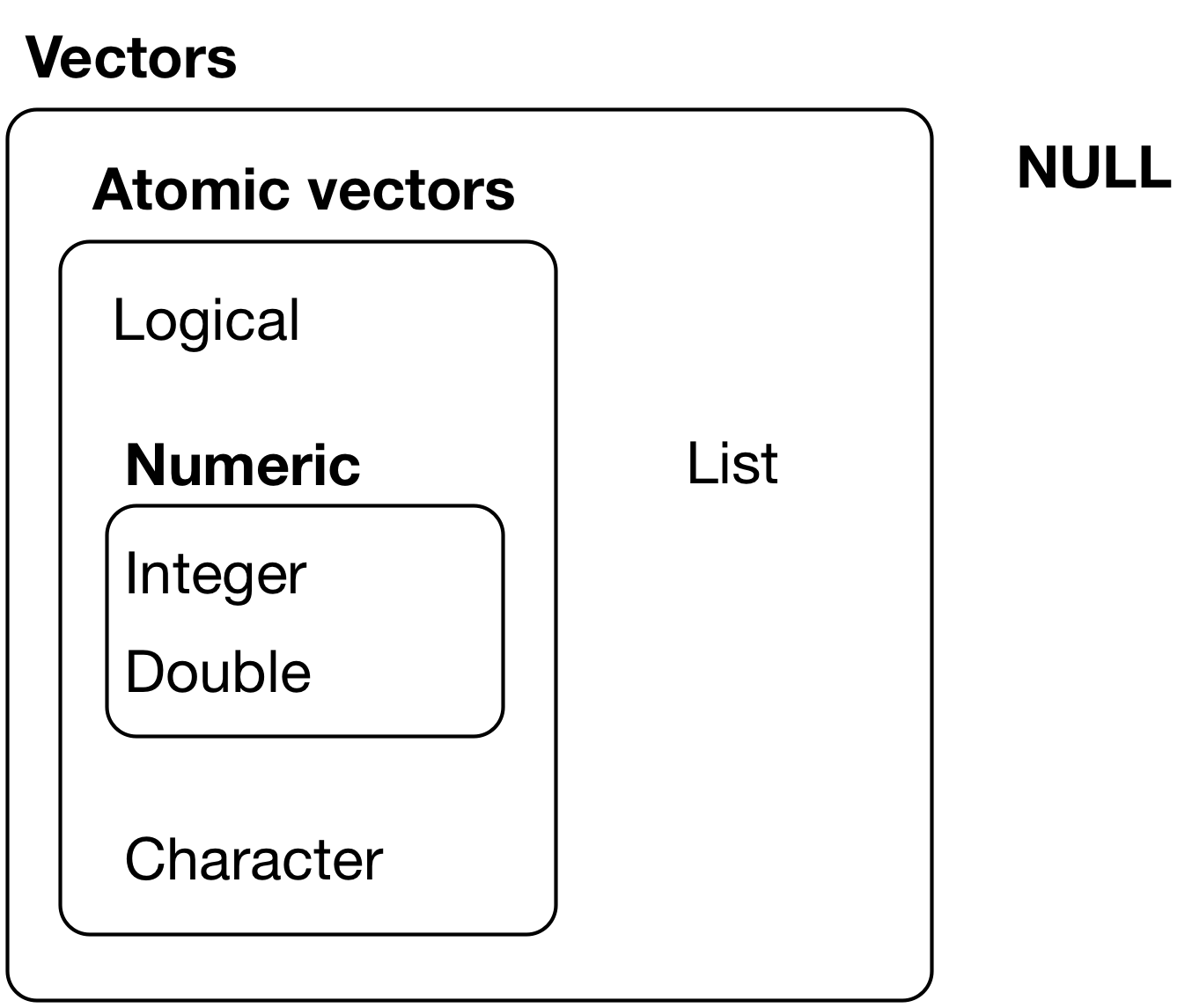
Figure 28.1: R 벡터 유형의 체계
모든 벡터는 두 가지 주요 속성이 있다.
임의의 추가 메타 데이터를 속성(attributes) 형식으로 벡터에 포함시킬 수 있다. 이러한 속성은 추가 동작을 기반으로 하는 확장 벡터 (augmented vector)를 만드는 데 사용된다. 확장 벡터에는 네 가지 중요한 유형이 있다.
- 팩터형은 정수형 벡터를 기반으로 만들어졌다.
- 데이트형과 데이트-타임형은 수치형 벡터를 기반으로 만들어졌다.
- 데이터프레임과 티블은 리스트를 기반으로 만들어졌다.
이 장에서는 이러한 중요한 벡터를 가장 단순한 것에서부터 가장 복잡한 것까지 소개한다. 원자 벡터로 시작한 다음 리스트로 나아가고, 확장 벡터로 마무리 지을 것이다.
28.3 원자 벡터의 주요 유형
가장 중요한 네 가지 유형의 원자 벡터는 논리형, 정수형, 더블형 및 문자형이다. 원시형과 복소수형은 데이터 분석 중에 거의 사용되지 않으므로 여기서 논의하지 않겠다.
28.3.1 논리형
논리형 벡터는 FALSE, TRUE 및 NA의 세 가지 값만 사용할 수 있기 때문에 가장 단순한 유형의 원자 벡터이다. 논리형 벡터는 비교 에 설명된 것과 같이, 대개의 경우 비교 연산자로 생성된다. c()를 사용하여 직접 생성할 수도 있다.
28.3.2 수치형
정수형 및 더블형 벡터는 합쳐서 수치형 벡터로 알려져 있다. R 에서 숫자는 기본값으로 더블형이다. 정수형으로 만들려면 숫자 뒤에 L을 붙이면 된다.
정수형과 더블형을 구분하는 것은 일반적으로 중요하지 않지만 두 가지 중요한 차이점을 알고 있어야 한다.
-
더블형은 근사값이다. 더블형은 부동 소수점수를 나타내는데, 고정된 양의 메모리를 사용하여 항상 정확하게 표현할 수는 없다. 즉, 더블형 값은 모두 근사치로 간주해야 한다. 예를 들어 2의 제곱근의 제곱은 무엇일까?
x <- sqrt(2) ^ 2 x #> [1] 2 x - 2 #> [1] 4.44e-16이런 동작은 부동 소수점수로 작업시 자주 일어난다. 즉, 대부분의 계산에는 근사 오차가 포함된다.
==를 사용하여 부동 소수점수를 비교하는 대신dplyr::near()를 사용해야 한다. 그러면 수치상 오차(tolerence)가 허용된다. -
정수형에는 특수한 값이
NA한 개가 있으며, 더블형에는NA, NaN, Inf및-Inf네 개가 있다. 이 모든 특수한 수치들은 나눗셈에서 발생할 수 있다.c(-1, 0, 1) / 0 #> [1] -Inf NaN InfAvoid using
==to check for these other special values. Instead use the helper functionsis.finite(),is.infinite(), andis.nan():0 Inf NA NaN is.finite()x is.infinite()x is.na()x x is.nan()x
28.3.3 문자형
문자형 벡터는 각 요소가 문자열이고 문자열에 임의의 양의 데이터가 포함될 수 있기 때문에 가장 복잡한 유형의 원자 벡터이다.
우리는 문자열 에서 문자열 작업에 대해 이미 많은 것을 배웠다. 여기서는 문자열 구현에 있어서 중요한 특징 중 하나를 말하고자 한다. R은 전역 문자열 풀을 사용한다. 즉, 각 고유 문자열은 메모리에 한 번만 저장되며 문자열을 사용할 때마다 해당 표현을 포인트한다. 이렇게 하면 중복 문자열에 필요한 메모리 양이 줄어 든다. pryr::object_size()를 사용하여 이 동작을 직접 볼 수 있다.
x <- "적당히 긴 문자열입니다."
pryr::object_size(x)
#> 152 B
y <- rep(x, 1000)
pryr::object_size(y)
#> 8,144 By의 각 요소는 같은 문자열에 대한 포인터이기 때문에 y는 x의 메모리의 1000배를 차지하지 않는다. 포인터는 8 바이트이므로, 136 B 문자열에 대한 포인터 1000개는 8 * 1000 + 136 = 8.13 kB 이다.
28.3.4 결측값
각 유형의 원자 벡터에는 고유한 결측값이 있다.
NA # 논리형
#> [1] NA
NA_integer_ # 정수형
#> [1] NA
NA_real_ # 더블형
#> [1] NA
NA_character_ # 문자형
#> [1] NA이러한 여러 유형에 대해 알 필요가 없다. 일반적으로 NA를 사용하면 되는데, 왜냐하면 다음에 설명할 암시적 강제 변환 규칙으로 올바른 유형으로 변환되기 때문이다. 그러나 입력에 대해 엄격한 함수가 몇몇 있으므로 이 내용을 미리 알고 있으면 필요한 경우 구체적으로 지정할 수 있어 도움이 될 것이다.
28.3.5 연습문제
is.finite(x)와!is.infinite(x)의 차이점을 설명하라.dplyr::near()의 소스 코드를 읽으라 (힌트: 소스 코드를 보기 위해서는()을 빼라). 어떻게 작동하는가?논리형 벡터는 세 가지 값을 가질 수 있다. 정수형 벡터는 몇 개의 값을 가질 수 있는가? 더블형은 몇 개의 값을 가질 수 있는가? 구글을 사용하여 조사해보라.
더블형을 정수형으로 변환하는 최소 네 개의 함수를 브레인스토밍 해보라. 이들은 어떻게 다른가? 정확하게 설명하라.
readr 패키지의 어떤 함수들로 문자열을 논리형, 정수형, 더블형 벡터로 바꿀 수 있는가?
28.4 원자벡터 이용하기
여러 유형의 원자 벡터를 이해했으므로, 이제 함께 사용할 수 있는 도구들을 검토하는 것이 좋다. 여기에는 다음이 포함된다.
한 유형에서 다른 유형으로 변환시키는 법. 자동으로 변환되는 조건.
한 객체가 특정 유형 벡터인지 알아보는 법.
다른 길이의 벡터들로 작업할 때 발생하는 일.
벡터의 요소를 이름 짓는 법.
관심 있는 요소를 추출하는 법.
28.4.1 강제변환
한 유형 벡터에서 다른 유형으로 강제 변환하는 두 가지 방법이 있다.
명시적 강제 변환은
logical(),as.integer(),as.double(),as.character()와 같은 함수를 호출할 때 발생한다. 명시적 강제 변환이 필요한 경우, 앞 단계를 고쳐서 처음부터 벡터가 잘못된 유형을 갖지 않도록 할 수 있는지 항상 확인해야 한다. 예를 들어 readr 의col_types명세를 조정해야 할 수도 있다.암묵적 강제 변환은 특정 유형의 벡터가 필요한 상황에서 어떤 벡터를 사용하는 경우 발생한다. 예를 들어 수치형 요약 함수에 논리형 벡터를 사용하거나 정수형 벡터가 예상되는 곳에 더블형 벡터를 사용하는 경우이다.
명시적 강제 변환은 상대적으로 거의 사용되기 않고, 이해하기 쉽기 때문에 여기서는 암묵적 강제 변환에 대해서 초점을 맞춘다.
우리는 이미 가장 중요한 형식의 암묵적 강제 변환을 보았다. 수치형 문맥에서 논리형 벡터를 사용했었다. 이 경우 TRUE는 1로 변환되고 FALSE는 0으로 변환된다. 즉, 논리형 벡터의 합계는 참값의 개수이고 논리형 벡터의 평균은 참값의 비율이다.
x <- sample(20, 100, replace = TRUE)
y <- x > 10
sum(y) # 10 보다 큰 것의 개수는?
#> [1] 38
mean(y) # 10 보다 큰 것의 비율은?
#> [1] 0.38반대 방향, 즉, 정수형에서 논리형으로의 암시적 강제 변환에 의존하는 코드(일반적으로 과거 방식)도 볼 수 있다.
if (length(x)) {
# do something
}이 경우 0은 FALSE로 변환되고 나머지는 TRUE로 변환된다. 이렇게 하면 코드를 이해하기가 더 어렵게 된다고 생각하기 때문에 이를 권장하지 않는다. 이 방법보다는 다음과 같이 명시적일 필요가 있다(length(x) > 0).
또한, c()로 여러 유형을 포함하는 벡터를 만들려고 할 때, 다음과 같은 일이 일어난다는 것을 이해하는 것도 중요하다. 가장 복잡한 유형으로 변환된다.
typeof(c(TRUE, 1L))
#> [1] "integer"
typeof(c(1L, 1.5))
#> [1] "double"
typeof(c(1.5, "a"))
#> [1] "character"벡터의 유형은 개별 요소가 아닌 전체 벡터의 특성이므로, 한 원자벡터의 유형이 여러 개일 수는 없다. 동일한 벡터에서 여러 유형을 혼합해야 하는 경우에는 리스트를 사용하면 된다. 이에 대해서는 곧 배울 것이다.
28.4.2 테스트 함수
벡터 유형에 따라 다른 작업을 수행해야 하는 때가 종종 있다. 한 방법은 typeof()를 사용하는 것이다. 다른 하나는 TRUE 또는 FALSE를 반환하는 테스트 함수를 사용하는 것이다. 베이스 R에는 is.vector() 및 is.atomic()과 같은 함수가 많이 있지만, 이들은 종종 예상과 다른 결과를 반환한다. 대신, purrr이 제공하는 is_* 함수를 사용하는 것이 더 안전하다. 다음 표에 요약되어 있다.
| lgl | int | dbl | chr | list | |
|---|---|---|---|---|---|
is_logical() |
x | ||||
is_integer() |
x | ||||
is_double() |
x | ||||
is_numeric() |
x | x | |||
is_character() |
x | ||||
is_atomic() |
x | x | x | x | |
is_list() |
x | ||||
is_vector() |
x | x | x | x | x |
위의 각 함수마다 is_scalar_atomic()과 같은 ’스칼라‘ 버전이 있는데, 이는 길이가 1인지 확인한다. 예를 들어 함수에 대한 인수가 단일 논리형 값인지 확인하려는 경우에 유용하다.
28.4.3 스칼라와 재활용 규칙
R 은 호환성을 위해 벡터의 유형을 암묵적으로 강제 변환할 뿐만 아니라, 벡터의 길이도 암묵적으로 강제 변환한다. 짧은 벡터가 긴 벡터의 길이로 반복되거나 재활용되므로 이를 벡터 재활용이라고 한다.
벡터 재활용은 벡터와 ’스칼라’를 혼합할 때 매우 유용하다. 스칼라를 따옴표로 묶은 이유는 R에는 사실 스칼라가 존재하지 않고, 숫자 하나는 길이가 1인 벡터이기 때문이다. 스칼라가 없으므로 대부분의 내장 함수는 벡터화 (즉, 수치 벡터에서 작동)된다. 따라서 예로 든 다음의 코드가 실행된다.
sample(10) + 100
#> [1] 107 104 103 109 102 101 106 110 105 108
runif(10) > 0.5
#> [1] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUER에서 기초적인 수학 연산은 벡터에 작동한다. 즉, 간단한 수학 계산을 수행할 때 명시적 반복을 수행할 필요가 없다.
같은 길이의 두 벡터 또는 벡터와 ’스칼라’를 더할 경우 일어나야 하는 일은 직관적이다. 그러나 길이가 다른 두 개의 벡터를 더하면 어떻게 되는가?
1:10 + 1:2
#> [1] 2 4 4 6 6 8 8 10 10 12여기에서 R은 가장 짧은 벡터를 가장 긴 벡터 길이로 확장하는데, 소위 재활용이라고 부른다. 길이가 더 긴 길이의 정수배가 아닌 경우를 제외하고는 침묵한다.
1:10 + 1:3
#> Warning in 1:10 + 1:3: longer object length is not a multiple of shorter object
#> length
#> [1] 2 4 6 5 7 9 8 10 12 11벡터 재활용을 사용하면 매우 간결하고 영리한 코드를 작성할 수 있지만, 문제가 조용하게 숨겨질 수도 있다. 이러한 이유로 tidyverse의 벡터화된 함수는 스칼라가 아닌 다른 것을 재활용할 때 오류를 발생시킨다. 재활용하고 싶다면 rep()으로 직접 처리해야 한다.
tibble(x = 1:4, y = 1:2)
#> Error: Tibble columns must have compatible sizes.
#> * Size 4: Existing data.
#> * Size 2: Column `y`.
#> ℹ Only values of size one are recycled.
tibble(x = 1:4, y = rep(1:2, 2))
#> # A tibble: 4 × 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 2
#> 3 3 1
#> 4 4 2
tibble(x = 1:4, y = rep(1:2, each = 2))
#> # A tibble: 4 × 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 1
#> 3 3 2
#> 4 4 228.4.4 벡터 이름 짓기
모든 유형의 벡터는 이름을 지정할 수 있다. c()를 사용하여 생성 시 이름을 지정할 수 있다.
c(x = 1, y = 2, z = 4)
#> x y z
#> 1 2 4또는 생성 이후에 purrr::set_names()으로 이름을 지정할 수도 있다.
명명된 벡터는 서브셋할 때 매우 유용하며, 이는 다음에 설명된다.
28.4.5 서브셋하기
지금까지 dplyr::filter()를 사용하여 티블의 행을 필터링했다. filter()는 티블에서만 작동하기 때문에 벡터용 도구가 새로 필요한데, 바로 [이다. [은 서브셋하는 함수이며 x[a]와 같이 호출된다. 벡터를 하위 집합으로 지정할 수 있는 네 가지 유형의 항목이 있다.
양의 정수로 서브셋하면 해당 위치의 요소가 유지된다.
-
정수형만 포함하는 수치형 벡터. 포함된 정수형은 모두 양수이거나 음수이거나 0이어야 한다.
양의 정수로 서브셋하면 해당 위치의 요소가 유지된다.
위치를 반복하면 실제로 입력보다 긴 출력을 만들 수 있다.
x[c(1, 1, 5, 5, 5, 2)] #> [1] "one" "one" "five" "five" "five" "two"음수값은 해당 위치의 요소를 누락시킨다.
x[c(-1, -3, -5)] #> [1] "two" "four"양수값과 음수값을 혼합하면 오류이다.
x[c(1, -1)] #> Error in x[c(1, -1)]: only 0's may be mixed with negative subscripts다음의 오류 메세지는 0으로 서브셋했기 때문에 아무 값도 반환하지 않았음을 나타낸다.
x[0] #> character(0)이는 매우 유용하지는 않지만, 함수를 테스트하기 위해 이상한 데이터 구조를 만들고 싶다면 도움이 될 수 있다.
-
논리형 벡터로 서브셋하면
TRUE값에 해당하는 모든 값이 유지된다. 이는 대개 비교 함수와 함께 사용하면 유용하다. -
명명된 벡터가 있다면 이를 문자형 벡터로 서브셋할 수 있다.
양의 정수 경우와 같이, 개별 요소를 복제할 때 문자형 벡터를 사용할 수도 있다.
가장 간단한 서브셋 동작은
x[]이며, 전체x를 반환한다. 이것은 벡터를 서브셋하는 데는 유용하지 않지만, 지수(index)를 공백으로 남겨 두어서 모든 행이나 열을 선택할 수 있기 때문에 행렬 (및 다른 고차원 구조)을 서브셋할 때 유용하다. 예를 들어x가 2차원이면x[1, ]은 첫 번째 행과 모든 열을 선택하고x[, -1]은 모든 행과 첫 열을 제외한 모든 열을 선택한다.
서브셋 동작을 활용하는 법에 대해 더 배우려면 Advanced R의 ’Subsetting‘ 장 http://adv-r.had.co.nz/Subsetting.html#applications 을 보라.
[ 의 중요한 변형이 있는데 바로 [[이다. [[은 오직 하나의 요소만 추출하고 항상 이름을 누락시킨다. for 루프에서와 같이 단일 항목을 추출한다는 것을 명확하게 밝히고 싶을 때 사용하는 것이 좋다. [과 [[의 차이점은 리스트에서 가장 두드러지는데, 이를 곧 살펴볼 것이다.
28.4.6 연습문제
mean(is.na(x))을 하면 벡터x에 관해 어떤 것을 알려주는가?sum(!is.finite(x))는 어떤가?is.vector()의 도움말을 주의 깊게 읽어라. 이 함수가 실제로 테스트하는 것은 무엇인가?is.atomic()이 위의 원자 벡터의 정의를 따르지 않는 이유는 무엇인가?setNames()와purr::set_names()를 비교∙대조하라.-
벡터를 입력으로 하고 다음을 반환하는 함수를 작성하라.
마지막 값.
[과[[중 어떤 것을 써야 할까?짝수 위치의 요소
마지막 값을 제외한 모든 요소
짝수만(결측값은 제외)
x[-which(x > 0)]이x[x <= 0]과 같지 않은 이유는 무엇인가?벡터의 길이보다 큰 양의 정수로 서브셋하면 어떻게 되는가? 존재하지 않는 이름으로 서브셋하면 어떻게 되는가?
28.5 재귀 벡터 (리스트)
리스트는 다른 리스트를 포함할 수 있기 때문에, 원자 벡터보다 한 단계 더 복잡하다. 이런 이유로 리스트는 계층적 또는 나무 같은(tree-like) 구조를 표현하는 데 적합하다. 리스트는 list()를 사용하여 생성된다.
x <- list(1, 2, 3)
x
#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3str()은 리스트를 다루는 도구인데, 내용이 아닌 구조에 초점을 맞추기 때문에 매우 유용하다.
str(x)
#> List of 3
#> $ : num 1
#> $ : num 2
#> $ : num 3
x_named <- list(a = 1, b = 2, c = 3)
str(x_named)
#> List of 3
#> $ a: num 1
#> $ b: num 2
#> $ c: num 3원자벡터와 다르게 lists()는 객체들을 혼합하여 포함할 수 있다.
y <- list("a", 1L, 1.5, TRUE)
str(y)
#> List of 4
#> $ : chr "a"
#> $ : int 1
#> $ : num 1.5
#> $ : logi TRUE리스트는 심지어 다른 리스트를 포함할 수도 있다!
z <- list(list(1, 2), list(3, 4))
str(z)
#> List of 2
#> $ :List of 2
#> ..$ : num 1
#> ..$ : num 2
#> $ :List of 2
#> ..$ : num 3
#> ..$ : num 428.5.1 리스트 시각화
복잡한 리스트 조작 함수를 설명하기 위해 리스트를 시각적으로 표현하는 것이 편리하다. 예를 들어 다음 세 가지 리스트를 살펴보자.
이들을 다음과 같이 나타낼 수 있다.
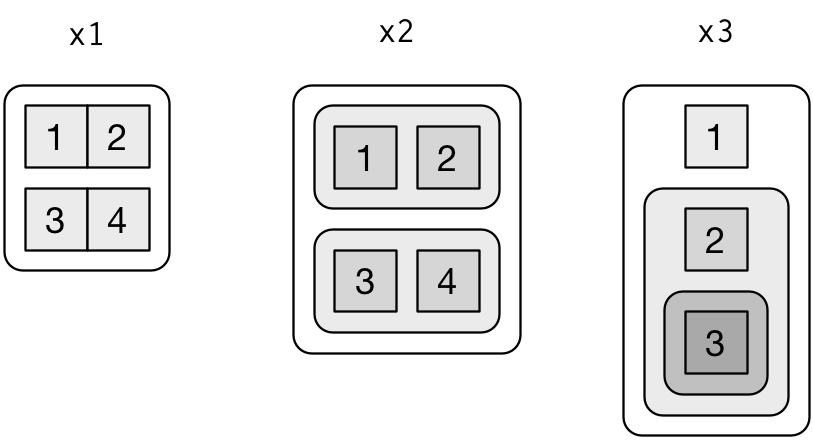
세 가지 원칙이 있다.
리스트는 모서리가 둥글다. 원자 벡터는 모서리가 사각이다.
자식은 부모 내부에 그려지며 계층을 쉽게 볼 수 있게 배경이 약간 더 어둡다.
자식의 방향 (즉, 행 또는 열)은 중요하지 않으므로 공간을 절약하거나 예제에서 중요한 속성을 잘 설명할 수 있는 행 또는 열 방향을 선택한다.
28.5.2 서브셋하기
리스트를 서브셋하는 방법은 세 가지이다. 어떤 리스트를 a라 하자.
-
[은 부분 리스트를 추출한다. 결과는 항상 리스트이다.
```r
str(a[1:2])
#> List of 2
#> $ a: int [1:3] 1 2 3
#> $ b: chr "a string"
str(a[4])
#> List of 1
#> $ d:List of 2
#> ..$ : num -1
#> ..$ : num -5
```
벡터에서와 같이 논리형, 정수형, 문자형 벡터로 서브셋할 수 있다. -
[[는 리스트의 단일 구성요소를 추출한다. 리스트의 계층구조에서 한 레벨을 제거한다. -
$은 리스트의 명명된 요소를 추출하는 단축문자이다. 이는 따옴표가 필요 없다는 것을 제외하고는[[와 유사하게 동작한다.a$a #> [1] 1 2 3 a[["a"]] #> [1] 1 2 3
[과 [[의 차이는 리스트에 있어서 정말 중요하다. [[은 리스트 안으로 내려가는 반면 [은 더 작은 새 리스트를 반환하기 때문이다. 앞의 코드와 출력을 Figure 28.2 의 시각화 표현과 비교하라.
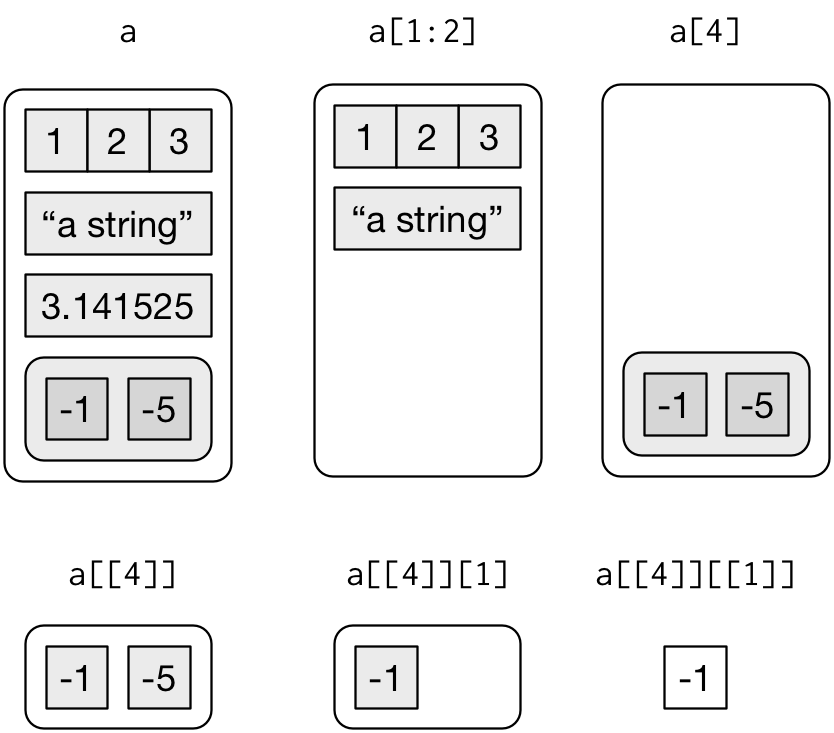
Figure 28.2: Subsetting a list, visually.


28.6 속성
벡터에 임의의 추가 메타 데이터를 속성(attribute) 을 통해 포함시킬 수 있다. 속 성은 어떤 객체에 첨부할 수 있는 벡터의 명명된 리스트로 생각할 수 있다.
개별 속성값은 attr() 로 가져오거나 설정할 수 있으며 attributes() 로 한번에 모두 볼 수 있다.
x <- 1:10
attr(x, "greeting")
#> NULL
attr(x, "greeting") <- "Hi!"
attr(x, "farewell") <- "Bye!"
attributes(x)
#> $greeting
#> [1] "Hi!"
#>
#> $farewell
#> [1] "Bye!"R의 기본 부분을 구현하는 데 세 가지 매우 중요한 속성이 사용되었다.
- Names 는 벡터 요소의 이름을 지정하는 데 사용된다.
- Dimensions (줄여서 dims)는 벡터를 행렬이나 어레이 같이 동작하도록 만든다.
- Class 는 S3 객체지향 시스템을 구현하는 데 사용된다.
우리는 앞서 names는 보았고, 이 책에서는 행렬을 사용하지 않기 때문에 dimension은 다루지는 않을 것이다. class가 남았는데, 이는 제네릭 함수 의 작동 방식을 제어한다. 제네릭 함수는 입력의 클래스에 따라 함수가 다르게 동작하도록 만들기 때문에, R의 객체지향 프로그래밍의 핵심이다. 객체지향 프로그래밍에 대한 자세한 설명은 이 책의 범위를 벗어나지만, Advanced R (http://adv-r.had.co.nz/OO-essentials.html#s3) 에서 이에 대해 더 자세히 읽을 수 있다.
일반적인 제네릭 함수는 다음과 같다.
as.Date
#> function (x, ...)
#> UseMethod("as.Date")
#> <bytecode: 0x7f9d582f0d10>
#> <environment: namespace:base>“UseMethod” 호출은 이 함수가 제네릭 함수임을 의미하며 첫 번째 인수의 클래스를 기반으로, 특정 함수(메서드)를 호출한다. (모든 메서드는 함수이지만, 모든 함수가 메서드인 것은 아니다.) methods() 를 사용하여 제네릭의 모든 메서드를 나열할 수 있다.
methods("as.Date")
#> [1] as.Date.character as.Date.default as.Date.factor
#> [4] as.Date.numeric as.Date.POSIXct as.Date.POSIXlt
#> [7] as.Date.vctrs_sclr* as.Date.vctrs_vctr*
#> see '?methods' for accessing help and source code예를 들어 x 가 문자형 벡터이면 as.Date() 는 as.Date.character() 를 호출하고, 팩터형이면 as.Date.factor() 를 호출한다.
getS3method() 로 메서드의 구현을 구체적으로 볼 수 있다.
getS3method("as.Date", "default")
#> function (x, ...)
#> {
#> if (inherits(x, "Date"))
#> x
#> else if (is.null(x))
#> .Date(numeric())
#> else if (is.logical(x) && all(is.na(x)))
#> .Date(as.numeric(x))
#> else stop(gettextf("do not know how to convert '%s' to class %s",
#> deparse1(substitute(x)), dQuote("Date")), domain = NA)
#> }
#> <bytecode: 0x7f9d39116070>
#> <environment: namespace:base>
getS3method("as.Date", "numeric")
#> function (x, origin, ...)
#> {
#> if (missing(origin)) {
#> if (!length(x))
#> return(.Date(numeric()))
#> if (!any(is.finite(x)))
#> return(.Date(x))
#> stop("'origin' must be supplied")
#> }
#> as.Date(origin, ...) + x
#> }
#> <bytecode: 0x7f9d1f931148>
#> <environment: namespace:base>가장 중요한 S3 제네릭은 print() 인데, 이는 콘솔에서 이름이 타이핑되었을 때, 객체가 출력되는 방식을 조정한다. 다른 중요한 제네릭은 서브셋 동작 함수들인 [, [[, $ 이다.
28.7 확장벡터
원자 벡터와 리스트는 팩터형 및 데이트형과 같은 주요 벡터 유형을 구성하는 기본 요소이다. 이들은 클래스를 포함하여 추가 __속성__이 있는 벡터이기 때문에 우리는 이들을 확장벡터(augmented vector) 라고 부른다. 확장 벡터는 클래스를 가지므로, 원자 벡터와 다르게 동작한다. 이 책에서는 네 가지 중요한 확장 벡터를 사용한다.
- 팩터형
- 데이트형
- 데이트-타임형
- 티블
다음은 이에 대한 설명이다.
28.7.1 팩터형
팩터형은 가질 수 있는 값이 고정된 범주형 데이터를 표현하기 위해 설계되었 다. 팩터형은 정수형을 기반으로 만들어졌고, 레벨 속성을 갖는다.
x <- factor(c("ab", "cd", "ab"), levels = c("ab", "cd", "ef"))
typeof(x)
#> [1] "integer"
attributes(x)
#> $levels
#> [1] "ab" "cd" "ef"
#>
#> $class
#> [1] "factor"28.7.2 데이트형과 데이트-타임형
R의 데이트형은 1970년 1월 1일부터 지난 일 수를 나타내는 수치형 벡터이다.
x <- as.Date("1971-01-01")
unclass(x)
#> [1] 365
typeof(x)
#> [1] "double"
attributes(x)
#> $class
#> [1] "Date"데이트-타임형은 1970년 1월 1일부터 지난 초 수를 나타내는 POSIXct 클래스를 가진 수치형 벡터이다. (“POSIXct”가 무엇일까? 이는 “Portable Operating System Interface calendar time”을 의미한다.)
x <- lubridate::ymd_hm("1970-01-01 01:00")
unclass(x)
#> [1] 3600
#> attr(,"tzone")
#> [1] "UTC"
typeof(x)
#> [1] "double"
attributes(x)
#> $class
#> [1] "POSIXct" "POSIXt"
#>
#> $tzone
#> [1] "UTC"tzone 속성은 선택사항이다. 이것은 시간이 출력되는 방식을 제어하는 것이지, 절대 시간을 제어하는 것이 아니다.
attr(x, "tzone") <- "US/Pacific"
x
#> [1] "1969-12-31 17:00:00 PST"
attr(x, "tzone") <- "US/Eastern"
x
#> [1] "1969-12-31 20:00:00 EST"데이트-타임형의 또 다른 유형은 POSIXlt라고 부르는 것이다. 이는 명명된 리스트를 기반으로 만들어졌다.
y <- as.POSIXlt(x)
typeof(y)
#> [1] "list"
attributes(y)
#> $names
#> [1] "sec" "min" "hour" "mday" "mon" "year" "wday" "yday"
#> [9] "isdst" "zone" "gmtoff"
#>
#> $class
#> [1] "POSIXlt" "POSIXt"
#>
#> $tzone
#> [1] "US/Eastern" "EST" "EDT"POSIXlt는 tidyverse 내부에서 거의 쓰지 않는다. POSIXlt는 연 또는 월 같은 날 짜의 특정 구성요소를 추출하는 데 필요하기 때문에 베이스 R에서 한 번씩 사용 된다. lubridate가 이 작업을 대신 수행하는 도우미를 제공하므로 POSIXlt가 필 요하지는 않다. POSIXct가 어느 경우에나 사용하기 쉽기 때문에 POSIXlt가 주어 졌을 때는 항상 lubridate::as_date_time() 을 사용하여 일반적인 데이트-타임형으 로 변환하는 것이 좋다.
28.7.3 티블
티블은 확장 리스트이다. “tbl_df” + “tbl” + “data.frame” 클래스를 갖고 두 가지 속성인 names(열이름)와 row.names(행이름)를 갖는다.
tb <- tibble::tibble(x = 1:5, y = 5:1)
typeof(tb)
#> [1] "list"
attributes(tb)
#> $class
#> [1] "tbl_df" "tbl" "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5
#>
#> $names
#> [1] "x" "y"티블/데이터프레임과 리스트의 차이점은 티블/데이터프레임의 모든 요소는 같은 길이의 벡터이어야 한다는 것이다. 티블에 작용하는 모든 함수는 이 제약조건을 강제한다.
전통적인 데이터프레임은 매우 유사한 구조를 가지고 있다.
df <- data.frame(x = 1:5, y = 5:1)
typeof(df)
#> [1] "list"
attributes(df)
#> $names
#> [1] "x" "y"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5주된 차이점은 클래스이다. 티블의 클래스는 “data.frame”을 포함하는데, 이는 티블이 기본값으로 일반적인 데이터프레임 동작을 상속받음을 의미한다.
28.7.4 Exercises
What does
hms::hms(3600)return? How does it print? What primitive type is the augmented vector built on top of? What attributes does it use?Try and make a tibble that has columns with different lengths. What happens?
Based on the definition above, is it ok to have a list as a column of a tibble?