29 반복
29.1 들어가기
27 장에서는 복사하여 붙여넣기 대신 함수를 작성하여 코드의 복제를 줄이는 것이 얼마나 중요한지에 대해 살펴보았다. 코드 중복을 줄이면 크게 세 가지 이점이 있다.
동일한 부분이 아니라, 차이가 나는 부분이 잘 보이기 때문에 코드의 의도를 확인하기 쉽다.
요구사항이 바뀌었을 때 쉽게 대응할 수 있다. 요구사항이 변경되면 복사하고 붙여넣은 모든 장소를 기억해가며 변경하는 대신, 한 곳만 변경하면 된다.
코드 라인이 여러 곳에 사용되었기 때문에 버그가 발생할 확률이 줄어든다.
중복을 줄일 수 있는 첫번째 방법은 함수를 사용하는 것이다. 함수는 코드의 반복패턴을 식별하여 독립적인 조각을 재사용하고 업데이트할 수 있게 코드를 추출한다. 중복을 줄일 수 있는 다른 방법은 반복(iteration) 을 사용하는 것이다. 반복이 유용한 경우는 다양한 입력에 대해 동일한 작업을 수행해야 하는 경우, 즉 다른 열이나 다른 데이터셋에 동일한 연산을 반복해야 하는 경우이다. 이 장에서는 명령형 프로그래밍과 함수형 프로그래밍이라는 두 가지 중요한 반복 패러다임에 대해 학습한다. 명령형에서는 대표적으로 for 루프와 while 루프가 있다. 이것들은 반복작업이 명시적이어서 작업내용이 명확하므로, 이것들부터 배우는 것이 좋다. 그러나 for 루프는 장황하고 모든 for 루프마다 부수적인 코드(bookkeeping code)가 중복된다. 함수형 프로그래밍(Functional Programming, FP) 은 이 중복된 코드를 추출하는 도구를 제공하므로, 루프 패턴마다 공통된 함수를 갖는다. 함수형 프로그래밍의 어휘에 익숙하게 되면 짧은 코드로, 쉽게 그리고 오류발생 확률을 낮추면서, 많은 반복 문제를 해결할 수 있다.
29.2 For 루프
다음과 같이 간단한 티블이 있다고 하자:
각 열의 중앙값을 계산하고자 한다. 복사하여 붙여넣기로 할 수 있다:
median(df$a)
#> [1] -0.246
median(df$b)
#> [1] -0.287
median(df$c)
#> [1] -0.0567
median(df$d)
#> [1] 0.144그러나 이는 “절대 두 번 이상 복사하여 붙여넣지 말 것”이라는 우리의 원칙을 위반하는 것이다. 대신 for 루프를 사용하면 된다:
output <- vector("double", ncol(df)) # 1. output
for (i in seq_along(df)) { # 2. sequence
output[[i]] <- median(df[[i]]) # 3. body
}
output
#> [1] -0.2458 -0.2873 -0.0567 0.1443for 루프는 모두 세가지 요소가 있다:
-
output:
output <- vector("double", length(x)). 루프를 시작하기 전에 항상 출력을 위해 충분한 공간을 할당해야 한다. 이는 효율성을 높이기 위해 매우 중요하다. 예를 들어c()를 사용하여 각 반복마다 for 루프를 늘리면 매우 느려진다.주어진 길이의 빈 벡터를 만드는 일반적인 방법은 vector() 함수를 사용하는 것이다. 두 가지 인수가 있다. 벡터의 유형(“논리형”, “정수형”, “더블형”, “문자형” 등)과 벡터의 길이이다.
-
sequence:
i in seq_along(df). 시퀀스는 무엇을 따라가며 반복해야 하는지를 결정한다. 즉, for 루프의 각 실 행차수에서i에set_along(df)의 값을 할당한다.i를 “그것”과 같이 대명사로 생각하면 편리하다.전에
seq_along()를 보지 못했을 수도 있다. 익숙한1:length(l)보다 안전한 버전인데, 중요한 차이점이 있다. 길이가 0인 벡터가 있을 때,seq_along()은 다음과 같이 바르게 작동한다:고의적으로 길이가 0 인 벡터를 생성하지 않겠지만, 의도치 않게 생성하기 쉽다.
seq_along(x)대신1:length(x)를 쓰면 해석하기 힘든 오류 메시지를 얻기 쉽다. body:
output[[i]] <- median(df[[i]]). 실행되는 코드이다. 각 차수마다 다른i값으로 반복 수행된다. 첫번째 반복은output[[1]] <- median(df[[1]])이, 두번째는output[[2]] <- median(df[[2]])가 실행되는 식이다.
이것이 for 루프의 전부이다! 이제 다음 연습문제를 통하여 기본적인(그리고 기본이 아닌) for 루프를 작성하는 연습을 시작하기 좋은 시점이다. 그런 다음 실무에서 발생할 수 있는 다른 문제들을 해결할 수 있는 for 루프의 변형으로 넘어가자.
29.2.1 Exercises
-
Write for loops to:
- Compute the mean of every column in
mtcars. - Determine the type of each column in
nycflights13::flights. - Compute the number of unique values in each column of
palmerpenguins::penguins. - Generate 10 random normals from distributions with means of -10, 0, 10, and 100.
Think about the output, sequence, and body before you start writing the loop.
- Compute the mean of every column in
-
Eliminate the for loop in each of the following examples by taking advantage of an existing function that works with vectors:
out <- "" for (x in letters) { out <- stringr::str_c(out, x) } x <- sample(100) sd <- 0 for (i in seq_along(x)) { sd <- sd + (x[i] - mean(x)) ^ 2 } sd <- sqrt(sd / (length(x) - 1)) x <- runif(100) out <- vector("numeric", length(x)) out[1] <- x[1] for (i in 2:length(x)) { out[i] <- out[i - 1] + x[i] } -
Combine your function writing and for loop skills:
- Write a for loop that
prints()the lyrics to the children’s song “Alice the camel”. - Convert the nursery rhyme “ten in the bed” to a function. Generalise it to any number of people in any sleeping structure.
- Convert the song “99 bottles of beer on the wall” to a function. Generalise to any number of any vessel containing any liquid on any surface.
- Write a for loop that
-
It’s common to see for loops that don’t preallocate the output and instead increase the length of a vector at each step:
output <- vector("integer", 0) for (i in seq_along(x)) { output <- c(output, lengths(x[[i]])) } outputHow does this affect performance? Design and execute an experiment.
29.3 For 루프 변형
기초적인 for 루프를 습득했다면 이제 알아야 할 몇 가지 변형이 있다. 이 변형들은 반복 수행 방법에 관계없이 중요하므로 다음 절에서 배우게 될 함수형 프로그래밍 기법을 익힐 때까지 잊어버리면 안된다.
for 루프의 기초적인 테마에는 네 가지 변형이 있다.
- 새 객체를 생성하는 대신 기존 객체를 수정하기.
- 지수(index) 대신 이름이나 값을 따라 루프하기.
- 길이가 알려지지 않은 출력 다루기.
- 길이가 알려지지 않은 시퀀스 다루기.
29.3.1 기존 객체 수정
때로는 기존 객체를 수정하기 위해 for 루프를 사용하려고 할 수 있다. 예를 들어 함수에 관한 27장의 문제를 기억해보라. 데이터프레임의 모든 열을 리스케일하려고 했었다:
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
df$a <- rescale01(df$a)
df$b <- rescale01(df$b)
df$c <- rescale01(df$c)
df$d <- rescale01(df$d)for 루프로 해결하기 위해 이번에도 세 가지 구성요소에 대해 생각해보자:
Output: 출력은 입력과 같으므로 출력은 이미 정해졌다.
Sequence: 데이터프레임을 열의 리스트로 생각할 수 있으므로,
seq_along(df)로 각 열을 따라 반복하면 된다.Body:
rescale01()를 수행하라.
따라서 다음과 같이 된다:
for (i in seq_along(df)) {
df[[i]] <- rescale01(df[[i]])
}이와 같은 루프로 리스트나 데이터프레임을 수정하는 작업에서 [ 가 아닌 [[ 를 사 용해야 한다는 것을 주의해야 한다.
앞서 모든 for 루프에서 [[ 를 사용했다는 것 을 알아챘는가? 원자 벡터에서도 [[ 를 사용하는 것이 더 좋은데, 이렇게 하면 단일 요소를 다룬다는 것을 명확하게 하기 때문이다.
29.3.2 루프 패턴
벡터를 따라 반복하는 세 가지 기본 방법이 있다. 지금까지는 가장 일반적인 것을 보았다.
즉, for (i in seq_along(xs)) 를 사용하여 숫자 지수를 따라 반복하고 x[[i]] 로 값을 추출했다.
다음은 두 가지 다른 형태이다:
요소를 따라 반복:
for (x in xs). 이 방법은 플롯을 생성하거나 파일을 저장하는 것과 같은 부수효과만 관심이 있는
경우에 매우 유용한 방법인데, 일반적으로 이러한 출력을 효율적으로 저장하기가 어렵기 때문이다.-
이름을 따라 반복:
for (nm in names(xs)). 이렇게 하면 이름을 사용하여x[[nm]]로 값에 접근할 수 있다. 이름을 플롯 제목이나 파일 이름에 사용하려는 경우 유용하다. 명명된 출력을 생성하려면 다음과 같이 results 벡터를 명명해야 한다:
숫자 지수를 따라 반복하는 것은 위치가 주어지면 이름과 값 모두 추출할 수 있기 때문에 가장 일반적인 형태이다:
29.3.3 길이를 모르는 출력
력의 길이가 얼마나 될지 모르는 경우가 종종 있다. 예를 들어 임의 길이의 임의 벡터를 시뮬레이션해야 하는 문제가 있다. 여러분들은 벡터를 점진적으로 늘려가는 방법으로 이 문제를 해결하려고 할 것이다.
means <- c(0, 1, 2)
output <- double()
for (i in seq_along(means)) {
n <- sample(100, 1)
output <- c(output, rnorm(n, means[[i]]))
}
str(output)
#> num [1:138] 0.912 0.205 2.584 -0.789 0.588 ...그러나 이 방법은 그다지 효율적이지 않은데, R은 각 차수마다 이전 차수의 데이터를 모두 복사해야 하기 때문이다. 기술적인 용어로 “2차(quadratic)”(\(O(n^2)\)) 동작이 된다. 즉, 요소가 3배 많은 루프는 실행하는 데 9(\(3^2\))배의 시간이 소요된다.
조금 더 나은 해결책으로는, 결과를 리스트에 저장한 다음, 루프가 완료된 후 단일 벡터로 결합하는 방법이 있다:
out <- vector("list", length(means))
for (i in seq_along(means)) {
n <- sample(100, 1)
out[[i]] <- rnorm(n, means[[i]])
}
str(out)
#> List of 3
#> $ : num [1:76] -0.3389 -0.0756 0.0402 0.1243 -0.9984 ...
#> $ : num [1:17] -0.11 1.149 0.614 0.77 1.392 ...
#> $ : num [1:41] 1.88 2.46 2.62 1.82 1.88 ...
str(unlist(out))
#> num [1:134] -0.3389 -0.0756 0.0402 0.1243 -0.9984 ...여기에서 unlist() 를 사용하여 벡터의 리스트를 단일 벡터로 플랫하게 만들었다. 더 엄격한 방법은 purrr::flatten_dbl() 을 사용하는 것이다. 입력이 더블형의 리스트가 아닌 경우 오류를 발생시킬 것이다.
이러한 패턴은 다른 곳에서도 나타난다:
긴 문자열을 생성하는 경우이다. 각 반복을 이전과 함께
paste()하는 대신 출력을 문자형 벡터에 저장한 다음paste(output, collapse = "")를 사용하여 단일 문자열로 결합한다.큰 데이터프레임을 생성하는 경우이다. 각 차수에 순차적으로
rbind()하는 대신 출력을 리스트에 저장한 후dplyr::bind_rows(output)을 사용하여 데이터프레임 하나로 결합한다.
이러한 패턴이 있는지 잘 살펴보라. 이 패턴을 발견하면, 좀 더 복잡한 결과 객체로 바꾼 다음, 마지막에 한번에 결합하라.
29.3.4 길이를 모르는 시퀀스
때로는 입력 시퀀스의 길이를 알지 못하는 경우도 있다. 시뮬레이션을 할 때 이런 일이 자주 생긴다. 예를 들어 앞면을 세 번 연속으로 얻기까지 반복하는 문제가 있다. for 루프로는 이러한 반복을 할 수 없다. 대신 while 루프를 사용하면 된다. while 루프는 조건과 본문, 두 가지 구성요소만 있기 때문에 for 루프보다 간단하다:
while (condition) {
# body
}while 루프는 for 루프보다 더 범용적이다. 어떤 for 루프도 while 루프로 다시 작성할 수 있지만, 모든 while 루프를 for 루프로 작성할 수 있는 것은 아니기 때문이다:
for (i in seq_along(x)) {
# body
}
# Equivalent to
i <- 1
while (i <= length(x)) {
# body
i <- i + 1
}연속으로 앞면을 세 번 얻을 때까지 걸린 시도 횟수를 while 루프를 사용하여 구하는 방법은 다음과 같다:
flip <- function() sample(c("T", "H"), 1)
flips <- 0
nheads <- 0
while (nheads < 3) {
if (flip() == "H") {
nheads <- nheads + 1
} else {
nheads <- 0
}
flips <- flips + 1
}
flips
#> [1] 21while 루프를 간략하게만 이야기했는데, 개인적으로 거의 사용하지 않기 때문이다. 시뮬레이션할 때 가장 자주 사용되는데, 이는 이 책의 범위를 벗어난다. 하지만 이런 것이 있다는 것을 알아두면 반복 수를 미리 알지 못하는 문제에 대비할 수 있어서 좋다.
29.3.5 Exercises
Imagine you have a directory full of CSV files that you want to read in. You have their paths in a vector,
files <- dir("data/", pattern = "\\.csv$", full.names = TRUE), and now want to read each one withread_csv(). Write the for loop that will load them into a single data frame.What happens if you use
for (nm in names(x))andxhas no names? What if only some of the elements are named? What if the names are not unique?-
Write a function that prints the mean of each numeric column in a data frame, along with its name. For example,
show_mean(mpg)would print:show_mean(mpg) #> displ: 3.47 #> year: 2004 #> cyl: 5.89 #> cty: 16.86(Extra challenge: what function did I use to make sure that the numbers lined up nicely, even though the variable names had different lengths?)
-
What does this code do? How does it work?
29.4 For 루프 vs. 함수형
R이 함수형 프로그래밍 언어이기 때문에, R에서 for 루프는 다른 언어에서만큼 중요하지는 않다. 즉, for 루프를 직접 사용하는 대신, 이를 함수에 포함시키고 이 함수를 호출할 수 있다.
이것이 중요한 이유를 보기 위해 다음의 간단한 데이터프레임을 (다시) 보자:
각 열의 평균을 연산한다고 가정하자. for 루프로 할 수 있다:
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[[i]] <- mean(df[[i]])
}
output
#> [1] -0.326 0.136 0.429 -0.250모든 열의 평균을 자주 계산해야 해서 다음과 같이 함수로 추출한다:
col_mean <- function(df) {
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[i] <- mean(df[[i]])
}
output
}그러고 나면 이제 중앙값과 표준편차를 계산할 수 있다면 편리하겠다고 생각할 것이다. col_mean() 함수를 복사하여 붙여넣고, mean() 을 median() 및 sd() 로 바꾼다:
col_median <- function(df) {
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[i] <- median(df[[i]])
}
output
}
col_sd <- function(df) {
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[i] <- sd(df[[i]])
}
output
}이런! 복사하여 붙여넣기를 두 번 했으므로 일반화를 고민해야 할 시점이다. 이 코드의 대부분은 for 루프 상용구이며 함수들 사이에 다른 부분(mean(), median(), sd())을 알아보기가 쉽지 않다.
다음과 같은 함수군이 있다면 어떻게 할 것인가?
f1 <- function(x) abs(x - mean(x)) ^ 1
f2 <- function(x) abs(x - mean(x)) ^ 2
f3 <- function(x) abs(x - mean(x)) ^ 3아마도 중복이 많다는 것을 알아채고 이를 추가 인수로 추출할 것이다:
버그가 발생할 가능성을 줄였고(코드가 1/3로 짧아짐) 새로운 상황에 맞추어 일반화하기 쉬워졌다.
똑같은 작업을 col_mean(), col_median(), col_sd() 에 할 수 있다. 각 열에 적용 시킬 함수를 인수로 제공하자:
col_summary <- function(df, fun) {
out <- vector("double", length(df))
for (i in seq_along(df)) {
out[i] <- fun(df[[i]])
}
out
}
col_summary(df, median)
#> [1] -0.5185 0.0278 0.1730 -0.6116
col_summary(df, mean)
#> [1] -0.326 0.136 0.429 -0.250함수를 다른 함수로 전달하는 것은 매우 강력한 개념이며, R이 함수형 프로그래밍 언어가 되는 동작 중 하나이다. 이 개념에 대해 잘 이해하는 데 시간이 좀 걸리겠지만, 노력해볼 가치가 있다.
이 장의 남은 부분에서는 purrr 패키지에 대해 배우고 사용해볼 것인데, 이 패키지의 함수들을 사용하면 일반적인 for 루프를 사용할 필요가 없다. 베이스 R의 apply 함수 계열(apply(), lapply(), tapply() 등) 도 비슷한 문제를 해결하지만, purrr은 좀 더 일관성이 있고 이로 인해 배우기도 더 쉽다.
for 루프 대신 purrr 함수들을 사용하면 리스트 조작 문제를 독립적인 조각들로 나눌 수 있다.
리스트의 단일 요소에 대해서만 문제를 푼다면 어떻게 해결하겠는가? 이 문제를 해결했다면 리스트의 모든 요소들에 이 해답을 일반화하는 것은 purrr이 해결해준다.
복잡한 문제를 해결하는 경우, 해결책으로 한 걸음 나아가기 위해 문제를 쉬운 크기로 분해하는 방법은 무엇일까? purrr을 사용하면 파이프와 함께 작성할 수 있는 작은 조각 여러 개로 만들 수 있다.
이 구조를 사용하면 새로운 문제를 쉽게 해결할 수 있다. 또한 이전 코드를 다시 읽을 때 문제를 어떻게 해결했는지 더 쉽게 이해할 수 있다.
29.4.1 Exercises
Read the documentation for
apply(). In the 2d case, what two for loops does it generalise?Adapt
col_summary()so that it only applies to numeric columns You might want to start with anis_numeric()function that returns a logical vector that has a TRUE corresponding to each numeric column.
29.5 map 함수들
벡터를 따라 루프를 돌며, 각 요소에 어떤 작업을 하고, 결과를 저장하는 패턴은 매우 일반적이다. purrr 패키지에는 이런 작업을 수행하는 함수 모음이 있다. 각 출력 형식마다 함수가 있다:
-
map()은 리스트를 출력한다. -
map_lgl()은 논리형 벡터를 출력한다. -
map_int()는 정수형 벡터를 출력한다. -
map_dbl()는 더블형 벡터를 출력한다. -
map_chr()은 문자형 벡터를 출력한다.
각 함수는 벡터를 입력으로, 각 조각에 함수를 적용한 후, 입력과 길이가 같고 이름들이 같은 새로운 벡터를 반환한다. 반환 벡터의 유형은 맵(map) 함수의 접미사에 의해 결정된다.
이러한 함수들을 습득하면 반복 문제들을 해결하는 데 시간이 훨씬 적게 걸리는 것을 알 수 있다. 그러나 맵 함수 대신 for 루프를 사용하는 것에 대해 부끄러워해서는 안 된다. 맵 함수들은 추상화로 한 단계 나아간 것이다. 이들이 작동하는 방식에 대해 충분히 이해하려면 오랜 시간이 걸릴 수도 있다. 가장 간결하고 우아하게 코드를 작성하고 싶겠지만, 중요한 점은 이것이 아니라 작업하고 있는 문제를 해결하는 것이다.
for 루프는 느리기 때문에 피해야 한다고 이야기하는 사람도 있다. 틀린 이야기다! (for 루프는 느리지 않게 된 것이 벌써 수 년 전의 일이기 때문에, 이러한 이야기는 최소한 옛날 이야기이다.) map() 과 같은 함수들을 사용하는 주된 이점은 속도가 아니라 명확성이다. 즉, 이 함수들은 코드를 쓰고 읽기 쉽게 만든다.
이 함수들을 사용하여 마지막으로 보았던 for 루프와 동일한 계산을 수행할 수 있다. 요약 함수들은 더블형을 반환했으므로 map_dbl() 을 사용해야 한다:
map_dbl(df, mean)
#> a b c d
#> -0.326 0.136 0.429 -0.250
map_dbl(df, median)
#> a b c d
#> -0.5185 0.0278 0.1730 -0.6116
map_dbl(df, sd)
#> a b c d
#> 0.921 0.485 0.982 1.156for 루프를 사용했을 때와 비교하면 모든 요소를 따라 반복하고 결과를 저장하는 단순작업이 아닌, 수행되는 연산(예, mean(), median(), sd())이 부각된다.
파이프를 사용하면 이점이 더 명백해진다:
df %>% map_dbl(mean)
#> a b c d
#> -0.326 0.136 0.429 -0.250
df %>% map_dbl(median)
#> a b c d
#> -0.5185 0.0278 0.1730 -0.6116
df %>% map_dbl(sd)
#> a b c d
#> 0.921 0.485 0.982 1.156map_*() 과 col_summary() 사이에 몇가지 차이점이 있다:
모든 purrr 함수는 C로 구현되었다. 가독성이 희생되었지만, 약간 빨라지게 되었다.
적용할 함수를 나타내는 두 번째 인수
.f로 공식, 문자형 벡터나 정수형 벡터를 지정할 수 있다. 다음 절에서 이러한 편리한 단축어들을 배울 것이다.-
map_*()은.f가 호출이 될 때마다 추가 인수를 … ([dot dot dot])을 사용하여 전달할 수 있다:map_dbl(df, mean, trim = 0.5) #> a b c d #> -0.5185 0.0278 0.1730 -0.6116 -
맵함수는 또한 이름을 유지한다:
29.5.1 단축어
타이핑을 덜하기 위해 .f 와 함께 사용할 수 있는 단축어가 몇개 있다.
데이터셋 각 그룹에 선형 모형을 적합하고 싶다고 하자.
다음 예제에서는 mtcars 데이터셋을 (각 cylinder 값마다 하나씩) 세 조각으로 나누어 각 조각마다 선형 모형을 동일하게 적합한다.
R 에서 익명 함수를 생성하는 문법은 장황하다. 따라서 purrr 에는 편리한 단축어인 한쪽 공식(one-sided formula)이 있다.
여기에서 . 를 대명사로 사용하였는데, 현재 리스트 요소를 가리킨다.
for 루프에서 i 가 현재 지수를 가리키는 것과 같다.
많은 모형을 보다보면 \(R^2\) 와 같은 요약 통계량을 추출하고 싶은 경우가 있다.
이를 위해서는 먼저 summary() 를 실행한 뒤 r.squared 라는 요소를 추출해야 한다.
익명 함수를 위한 단축어를 사용해서 할 수도 있다.
그러나 명명된 구성요소를 추출하는 것은 자주하는 연산이므로 purrr 에는 더 짧은 단축어가 있는데, 바로 문자열을 사용할 수도 있다.
정수형을 사용하여 위치로 요소를 선택할 수도 있다.
29.5.2 베이스 R
베이스 R 의 apply 함수 계열에 익숙하다면 다음과 같은 유사점이 있음을 발견했을 것이다:
lapply()은map()과 기본적으로 같다. 차이점은map()은 purrr 의 다른 모든 함수와 일관성이 있고.f에 단축어를 사용할 수 있다는 것이다.-
베이스
sapply()는lapply()의 출력을 자동으로 단순하게 만드는 래퍼이다. 이 함수는 대화식 작업에서는 유용하지만, 함수 안에서는 다음과 같이 어떤 출력을 얻게 될지 모르기 때문에 문제가 된다:x1 <- list( c(0.27, 0.37, 0.57, 0.91, 0.20), c(0.90, 0.94, 0.66, 0.63, 0.06), c(0.21, 0.18, 0.69, 0.38, 0.77) ) x2 <- list( c(0.50, 0.72, 0.99, 0.38, 0.78), c(0.93, 0.21, 0.65, 0.13, 0.27), c(0.39, 0.01, 0.38, 0.87, 0.34) ) threshold <- function(x, cutoff = 0.8) x[x > cutoff] x1 %>% sapply(threshold) %>% str() #> List of 3 #> $ : num 0.91 #> $ : num [1:2] 0.9 0.94 #> $ : num(0) x2 %>% sapply(threshold) %>% str() #> num [1:3] 0.99 0.93 0.87 vapply()는 유형을 정의하는 추가 인수를 제공하기 때문에sapply()의 안전한 대체함수이다.vapply()의 유일한 문제는 타이핑을 길게 해야 한다는 것이다.vapply(df, is.numeric, logical(1))은map_lgl(df, is.numeric)과 동일하다.vapply()가 purrr의 맵 함수보다 좋은 점은 행렬을 만들 수도 있다는 것이다. 맵 함수는 벡터만 만들 수 있다.
purrr 함수들에 대해 살펴보았는데, 이름과 인수가 좀 더 일관성이 있고 편리한 단축어가 있다. 앞으로는 용이한 병렬처리, 진행률 막대가 제공될 예정이다.
29.5.3 Exercises
-
Write code that uses one of the map functions to:
- Compute the mean of every column in
mtcars. - Determine the type of each column in
nycflights13::flights. - Compute the number of unique values in each column of
palmerpenguins::penguins. - Generate 10 random normals from distributions with means of -10, 0, 10, and 100.
- Compute the mean of every column in
How can you create a single vector that for each column in a data frame indicates whether or not it’s a factor?
What happens when you use the map functions on vectors that aren’t lists? What does
map(1:5, runif)do? Why?What does
map(-2:2, rnorm, n = 5)do? Why? What doesmap_dbl(-2:2, rnorm, n = 5)do? Why?Rewrite
map(x, function(df) lm(mpg ~ wt, data = df))to eliminate the anonymous function.
29.6 실패 다루기
맵 함수를 사용해 많은 연산을 반복할 때, 연산 중 하나가 실패할 확률이 매우 높다. 이 경우 오류 메시지가 표시되고 출력은 표시되지 않는다. 이는 성가신 일이다. 한번 실패했다고 해서 왜 다른 모든 성공 결과에 접근하지 못하게 되는가? 썩은 사과 한 개가 통 전체를 망치지 않는다고 어떻게 확신할 수 있겠는가?
이 절에서는 새로운 함수인 safely() 를 사용하여 이러한 상황을 다루는 법을 배울 것이다.
safely() 는 부사이다. 함수(동사)를 사용하고 수정된 버전을 반환한다.
이 경우 수정된 버전은 오류를 발생시키지 않는다.
대신 항상 다음의 두 요소로 이루어진 리스트를 반환한다:
result: 원 결과. 오류가 있다면 이는NULL이 될 것이다.error: 오류 객체. 연산이 성공적이었다면 이는NULL이 될 것이다.
(베이스 R의 try() 함수에 익숙한 사람도 있을 것이다. 유사하지만 이 함수는 원 결과를 반환하기도 하고 오류 객체를 반환하기도 하기 때문에 작업하기 더 힘들다.)
단순한 예제인 log() 로 이를 살펴보자.
safe_log <- safely(log)
str(safe_log(10))
#> List of 2
#> $ result: num 2.3
#> $ error : NULL
str(safe_log("a"))
#> List of 2
#> $ result: NULL
#> $ error :List of 2
#> ..$ message: chr "non-numeric argument to mathematical function"
#> ..$ call : language .Primitive("log")(x, base)
#> ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"함수가 성공한 경우 result 요소는 결과를 포함하게 되고 error 요소는 NULL 이 된 다.
함수가 실패한 경우, result 요소는 NULL 이 되고 error 요소는 오류 객체를 포함하게 된다.
safely() 는 다음과 같이 map과 함께 수행되도록 설계되었다:
x <- list(1, 10, "a")
y <- x %>% map(safely(log))
str(y)
#> List of 3
#> $ :List of 2
#> ..$ result: num 0
#> ..$ error : NULL
#> $ :List of 2
#> ..$ result: num 2.3
#> ..$ error : NULL
#> $ :List of 2
#> ..$ result: NULL
#> ..$ error :List of 2
#> .. ..$ message: chr "non-numeric argument to mathematical function"
#> .. ..$ call : language .Primitive("log")(x, base)
#> .. ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"리스트가 두 개(모든 오류를 담는 하나와 모든 출력을 담는 하나) 있으면 작업하기가 더 쉬울 것이다.
purrr::transpose() 를 사용하면 쉽게 얻을 수 있다.
y <- y %>% transpose()
str(y)
#> List of 2
#> $ result:List of 3
#> ..$ : num 0
#> ..$ : num 2.3
#> ..$ : NULL
#> $ error :List of 3
#> ..$ : NULL
#> ..$ : NULL
#> ..$ :List of 2
#> .. ..$ message: chr "non-numeric argument to mathematical function"
#> .. ..$ call : language .Primitive("log")(x, base)
#> .. ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"나름대로 오류를 처리하는 법이 있겠지만, 일반적으로 y 값이 오류인 x 값을 보거나, 정상인 y 값을 살펴볼 것이다:
is_ok <- y$error %>% map_lgl(is_null)
x[!is_ok]
#> [[1]]
#> [1] "a"
y$result[is_ok] %>% flatten_dbl()
#> [1] 0.0 2.3purrr 에는 이 밖에도 유용한 형용사 두 개가 있다:
-
safely()와 같이,possibly()는 항상 성공한다. 오류시 반환할 기본값을 지정할 수 있기 때문에safely()보다 단순하다. -
quietly()는safely()와 비슷한 역할을 수행하지만 오류를 캡쳐하는 대신
인쇄되는 출력, 메시지, 경고를 캡쳐한다:
29.7 다중 인수로 매핑
지금까지 우리는 단일 입력을 따라 반복했다.
그런데 다중의 연관된 인풋을 따라가며 병렬로 반복해야 하는 경우가 종종 있다. map2() 와 pmap 이 바로 이 작업을 한다.
예를 들어 다른 평균을 가진 랜덤 정규분포 샘플을 생성하고 싶다고 하자.
map() 으로 하는 법은 알고 있다:
mu <- list(5, 10, -3)
mu %>%
map(rnorm, n = 5) %>%
str()
#> List of 3
#> $ : num [1:5] 5.63 7.1 4.39 3.37 4.99
#> $ : num [1:5] 9.34 9.33 9.52 11.32 10.64
#> $ : num [1:5] -2.49 -4.75 -2.11 -2.78 -2.42표준편차도 변경시키고 싶다면 어떻게 할까? 한 가지 방법은 다음과 같이 지수를 따라 반복하고, 평균과 표준편차 벡터에 인덱싱하는 것이다:
sigma <- list(1, 5, 10)
seq_along(mu) %>%
map(~rnorm(5, mu[[.x]], sigma[[.x]])) %>%
str()
#> List of 3
#> $ : num [1:5] 4.82 5.74 4 2.06 5.72
#> $ : num [1:5] 6.51 0.529 10.381 14.377 12.269
#> $ : num [1:5] -11.51 2.66 8.52 -10.56 -7.89그러나 코드의 의도가 모호하게 되었다.
대신 map2() 를 사용할 수 있다. 이는 두 개의 벡터를 따라 병렬로 반복한다.
map2(mu, sigma, rnorm, n = 5) %>% str()
#> List of 3
#> $ : num [1:5] 3.83 4.52 5.12 3.23 3.59
#> $ : num [1:5] 13.55 3.8 8.16 12.31 8.39
#> $ : num [1:5] -15.872 -13.3 12.141 0.469 14.794map2() 는 다음과 같은 일련의 함수를 호출했다:
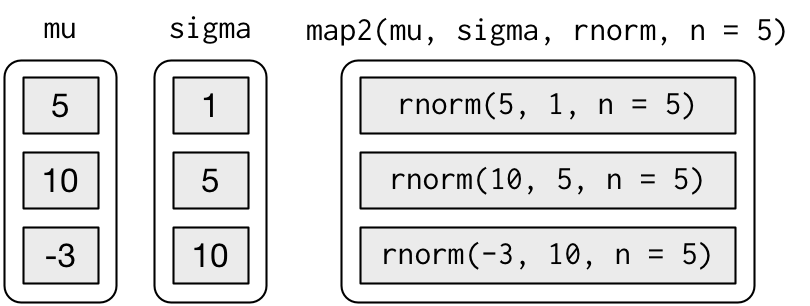
매 호출마다 변하는 인수는 함수 앞에 오고, 매 호출마다 동일한 인수는 뒤에 온 다는 것을 주목하라.
map() 과 같이 map2() 는 for 루프를 감싸는 래퍼일 뿐이다:
map2 <- function(x, y, f, ...) {
out <- vector("list", length(x))
for (i in seq_along(x)) {
out[[i]] <- f(x[[i]], y[[i]], ...)
}
out
}마찬가지로 map3(), map4(), map5(), map6() 등을 생각해볼 수도 있겠지만 금방 귀찮아질 것이다.
대신 purrr에는 인수 리스트를 취하는 pmap() 이 있다.
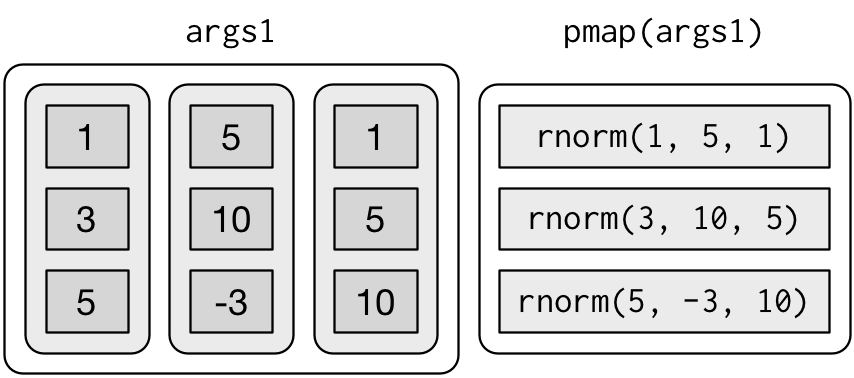
평균, 표준편차, 표본의 개수를 변경하려는 경우 사용할 수 있다:
n <- list(1, 3, 5)
args1 <- list(n, mu, sigma)
args1 %>%
pmap(rnorm) %>%
str()
#> List of 3
#> $ : num 5.39
#> $ : num [1:3] 5.41 2.08 9.58
#> $ : num [1:5] -23.85 -2.96 -6.56 8.46 -5.21다음과 같게 된다:
리스트 요소의 이름이 없다면 pmap() 이 호출될 때, 위치 매칭을 사용할 것이다. 이 경우 오류가 발생하기 쉽게 되고 코드를 읽기 더 어렵게 만들기 때문에, 인수를 명명하는 것이 좋다:
호출문이 더 길어지지만 더 안전하게 된다:
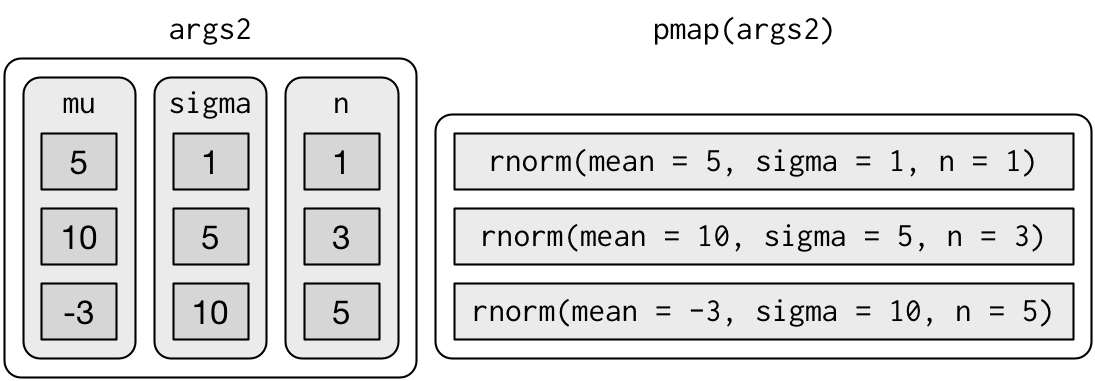
인수의 길이가 모두 같기 때문에 데이터프레임으로 저장하는 것이 좋다:
params <- tribble(
~mean, ~sd, ~n,
5, 1, 1,
10, 5, 3,
-3, 10, 5
)
params %>%
pmap(rnorm)
#> [[1]]
#> [1] 6.02
#>
#> [[2]]
#> [1] 8.68 18.29 6.13
#>
#> [[3]]
#> [1] -12.24 -5.76 -8.93 -4.22 8.80코드가 복잡해지기 시작하면 바로 데이터프레임을 사용하는 것이 더 좋은 방법 일 것이다. 각 열에 이름이 있고 모든 열의 길이가 같기 때문이다.
29.7.1 다른 함수 불러오기
한 단계 더 복잡한 것도 있다. 인수를 변경하는 것뿐만 아니라 함수 자체도 변경하고 싶을 수 있다.:
f <- c("runif", "rnorm", "rpois")
param <- list(
list(min = -1, max = 1),
list(sd = 5),
list(lambda = 10)
)invoke_map() 을 사용하여 이 경우를 다룰 수 있다:
invoke_map(f, param, n = 5) %>% str()
#> List of 3
#> $ : num [1:5] 0.479 0.439 -0.471 0.348 -0.581
#> $ : num [1:5] 2.48 3.9 7.54 -9.12 3.94
#> $ : int [1:5] 6 11 5 8 9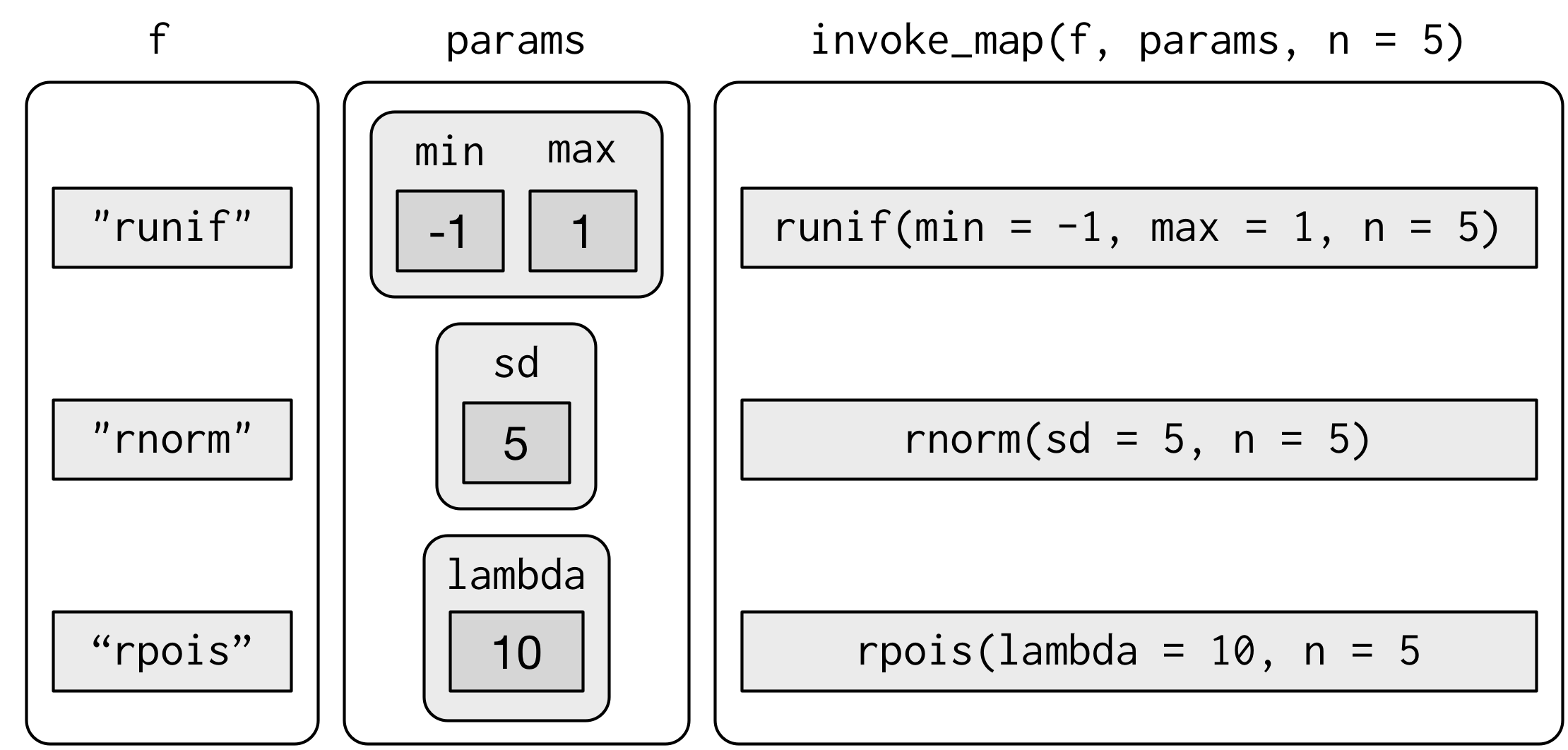
첫 번째 인수는 함수의 리스트 또는 함수 이름의 문자형 벡터이다. 두 번째 인수는 각 함수마다 변경되는 인수 리스트의 리스트이다. 그 다음 인수는 모든 함수에 전달된다.
또한, 이번에도 tribble() 을 사용하여 이렇게 일치하는 쌍을 좀 더 쉽게 만들 수 있다:
29.8 Walk
Walk 는 반환값이 아닌 부작용을 위해 함수를 호출하고자 할 경우 맵 함수의 대안으로 사용할 수 있다. 결과를 스크린에 렌더링하거나 디스크에 파일을 저장하는 것과 같이, 반환값이 아니라 동작이 중요하기 때문에 이를 사용한다. 다음은 매우 간단한 예제이다:
walk() 는 walk2() 나 pwalk() 에 비해 일반적으로 그다지 유용하지 않다.
예를 들어 플롯 리스트와 파일명 벡터가 있는 경우 pwalk() 를 사용하여 디스크의 해당 위치에 각 파일을 저장할 수 있다:
library(ggplot2)
plots <- mtcars %>%
split(.$cyl) %>%
map(~ggplot(.x, aes(mpg, wt)) + geom_point())
paths <- stringr::str_c(names(plots), ".pdf")
pwalk(list(paths, plots), ggsave, path = tempdir())walk(), walk2(), pwalk() 는 모두 첫 번째 인수 . 를 보이지 않게 반환한다.
따라서 이 함수들을 파이프라인 중간에서 사용하기 적절하다.
29.9 For 루프의 기타 패턴
purrr 에는 for 루프의 기타 유형을 추상화하는 함수들이 많이 있다. 이 함수들은 맵 함수보다 드물게 사용되지만 알고 있으면 유용하다. 여기서의 목표는 각 함수를 간략히 설명하여, 비슷한 문제를 볼 경우 기억날 수 있게 하는 것이다. 그러면 설명서에서 자세한 내용을 찾아보면 된다.
29.9.1 Predicate 함수
많은 함수는 단일 TRUE나 FALSE를 반환하는 논리서술자(predicate) 함수와 함께 작동한다.
keep() 과 discard() 는 입력에서 논리서술이 각각 TRUE 이거나 FALSE 인 요소를 반환한다:
gss_cat %>%
keep(is.factor) %>%
str()
#> tibble [21,483 × 6] (S3: tbl_df/tbl/data.frame)
#> $ marital: Factor w/ 6 levels "No answer","Never married",..: 2 4 5 2 4 6 2 4 6 6 ...
#> $ race : Factor w/ 4 levels "Other","Black",..: 3 3 3 3 3 3 3 3 3 3 ...
#> $ rincome: Factor w/ 16 levels "No answer","Don't know",..: 8 8 16 16 16 5 4 9 4 4 ...
#> $ partyid: Factor w/ 10 levels "No answer","Don't know",..: 6 5 7 6 9 10 5 8 9 4 ...
#> $ relig : Factor w/ 16 levels "No answer","Don't know",..: 15 15 15 6 12 15 5 15 15 15 ...
#> $ denom : Factor w/ 30 levels "No answer","Don't know",..: 25 23 3 30 30 25 30 15 4 25 ...
gss_cat %>%
discard(is.factor) %>%
str()
#> tibble [21,483 × 3] (S3: tbl_df/tbl/data.frame)
#> $ year : int [1:21483] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
#> $ age : int [1:21483] 26 48 67 39 25 25 36 44 44 47 ...
#> $ tvhours: int [1:21483] 12 NA 2 4 1 NA 3 NA 0 3 ...some() 과 every() 는 논리서술이 일부 혹은 모든 요소가 참인지를 확인한다.
x <- list(1:5, letters, list(10))
x %>%
some(is_character)
#> [1] TRUE
x %>%
every(is_vector)
#> [1] TRUEdetect() 는 논리서술이 참인 첫 번째 요소를 찾는다. detect_index() 는 해당 위치를 반환한다.
x <- sample(10)
x
#> [1] 10 6 1 3 2 4 5 8 9 7
x %>%
detect(~ .x > 5)
#> [1] 10
x %>%
detect_index(~ .x > 5)
#> [1] 1head_while() 과 tail_while() 은 벡터의 시작 혹은 끝에서부터 논리서술자가 참인 요소들을 반환한다:
x %>%
head_while(~ .x > 5)
#> [1] 10 6
x %>%
tail_while(~ .x > 5)
#> [1] 8 9 729.9.2 Reduce 와 Accumulate
쌍을 객체 하나로 줄이는 함수를 반복 적용하여, 복잡한 리스트를 간단한 리스트로 줄이고 싶을 때도 있을 것이다. 테이블 두 개를 입력으로 하는 dplyr 동사를 여러 테이블에 적용할 때 유용하다. 예를 들어 데이터프레임 리스트가 있을 때, 리스트의 요소를 조인해서 하나의 데이터프레임으로 만들려면 다음과 같이 하면 된다:
dfs <- list(
age = tibble(name = "John", age = 30),
sex = tibble(name = c("John", "Mary"), sex = c("M", "F")),
trt = tibble(name = "Mary", treatment = "A")
)
dfs %>% reduce(full_join)
#> Joining, by = "name"
#> Joining, by = "name"
#> # A tibble: 2 × 4
#> name age sex treatment
#> <chr> <dbl> <chr> <chr>
#> 1 John 30 M <NA>
#> 2 Mary NA F A또는 벡터의 리스트가 있을 때, 교집합을 구하는 방법은 다음과 같다:
vs <- list(
c(1, 3, 5, 6, 10),
c(1, 2, 3, 7, 8, 10),
c(1, 2, 3, 4, 8, 9, 10)
)
vs %>% reduce(intersect)
#> [1] 1 3 10reduce() 함수는 “이진” 함수(즉, 기본 입력이 두 개인 함수)를 입력으로, 이를 하나의 요소만 남아있을 때까지 반복적으로 리스트에 적용한다.
accumulate() 은 비슷하지만 중간 결과를 모두 유지한다. 누적 합계를 구현할 때 사용할 수 있다:
x <- sample(10)
x
#> [1] 7 5 10 9 8 3 1 4 2 6
x %>% accumulate(`+`)
#> [1] 7 12 22 31 39 42 43 47 49 5529.9.3 Exercises
Implement your own version of
every()using a for loop. Compare it withpurrr::every(). What does purrr’s version do that your version doesn’t?Create an enhanced
col_summary()that applies a summary function to every numeric column in a data frame.-
A possible base R equivalent of
col_summary()is:col_sum3 <- function(df, f) { is_num <- sapply(df, is.numeric) df_num <- df[, is_num] sapply(df_num, f) }But it has a number of bugs as illustrated with the following inputs:
df <- tibble( x = 1:3, y = 3:1, z = c("a", "b", "c") ) # OK col_sum3(df, mean) # Has problems: don't always return numeric vector col_sum3(df[1:2], mean) col_sum3(df[1], mean) col_sum3(df[0], mean)What causes the bugs?