33 그래프를 통한 의사소통
33.1 들어가기
탐색적 데이터 분석 에서 우리는 플롯을 탐색 도구로 사용하는 방법을 배웠다. 탐색용 플롯을 만들 때는 어떤 변수가 플롯에 표시될지 (플롯을 보기도 전에) 알고 있다. 우리는 목적에 따라 플롯을 하나씩 만들었고, 빨리 파악하고, 다음 플롯으로 넘어갔다. 대부분의 분석 과정에서 수십 또는 수백 개의 플롯을 그려보고, 즉시 대부분을 폐기할 것이다.
데이터를 이해했다면 이제 이해한 바를 다른 사람들과 의사소통이탤릭>해야 한다. 의사소통 대상자들은 배경 지식이 없고 해당 데이터를 깊이 살펴보지 않는 경우가 많다. 다른 사람들이 데이터를 신속하게 이해할 수 있게 하려면, 플롯이 최대한 스스로 설명 가능할 수 있게 노력을 많이 기울여야 한다. 이 장에서는 ggplot2가 제공하는 도구에 대해 학습한다.
이번 장에서는 좋은 그래픽을 만드는 데 필요한 도구를 중점적으로 살펴본다. 나는 여러분이 자신이 하고자 하는 바가 무엇인지 알고 있지만, 어떻게 하는 지를 모른다고 가정한다. 이런 경우 시각화 개론 책을 이 장과 함께 읽는 것이 좋다. 나는 특히 앨버트 카이로(Albert Cairo)의 The Truthful Art 를 좋아한다. 이 책은 시각화를 만드는 메커니즘을 가르쳐 주지 않지만 효과적인 그래프를 만들기 위해 무엇을 생각해야하는지를 중점적으로 다룬다.
33.1.1 준비하기
이 장에서는 다시 한번 ggplot2를 집중하여 볼 것이다. 또한 dplyr을 사용하여 데이터를 처리하고 ggrepel과 viridis를 포함한 몇 가지 ggplot2 확장 패키지를 사용할 것이다. 이 확장 패키지들을 여기에서 로드하지 않고, :: 표기법을 사용하여 함수를 명시적으로 참조할 것이다. 이렇게 하면 어떤 함수가 ggplot2에 내장되어 있는지, 또 어떤 함수가 다른 패키지에서 온 것인지를 명확히 알 수 있다. 설치되지 않은 패키지는 install.packages() 로 설치해야 한다는 것을 기억하라.
33.2 라벨
탐색그래픽을 해설그래픽으로 전환할 때 라벨을 잘 만드는 것을 쉽게 해볼 수 있습니다.
labs() 함수로 라벨을 추가합니다.
플롯 타이틀을 추가하는 예입니다:
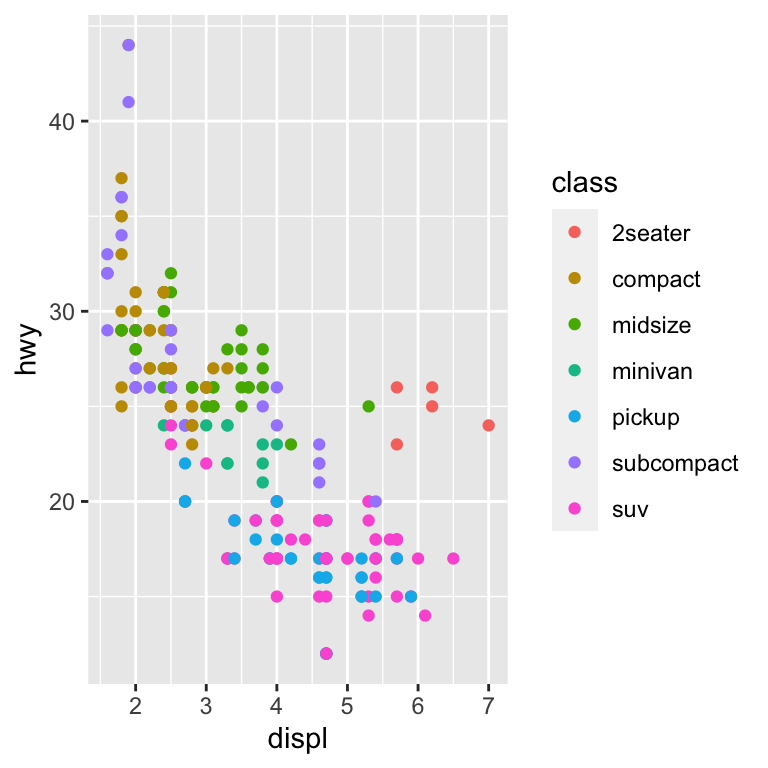
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(title = "Fuel efficiency generally decreases with engine size")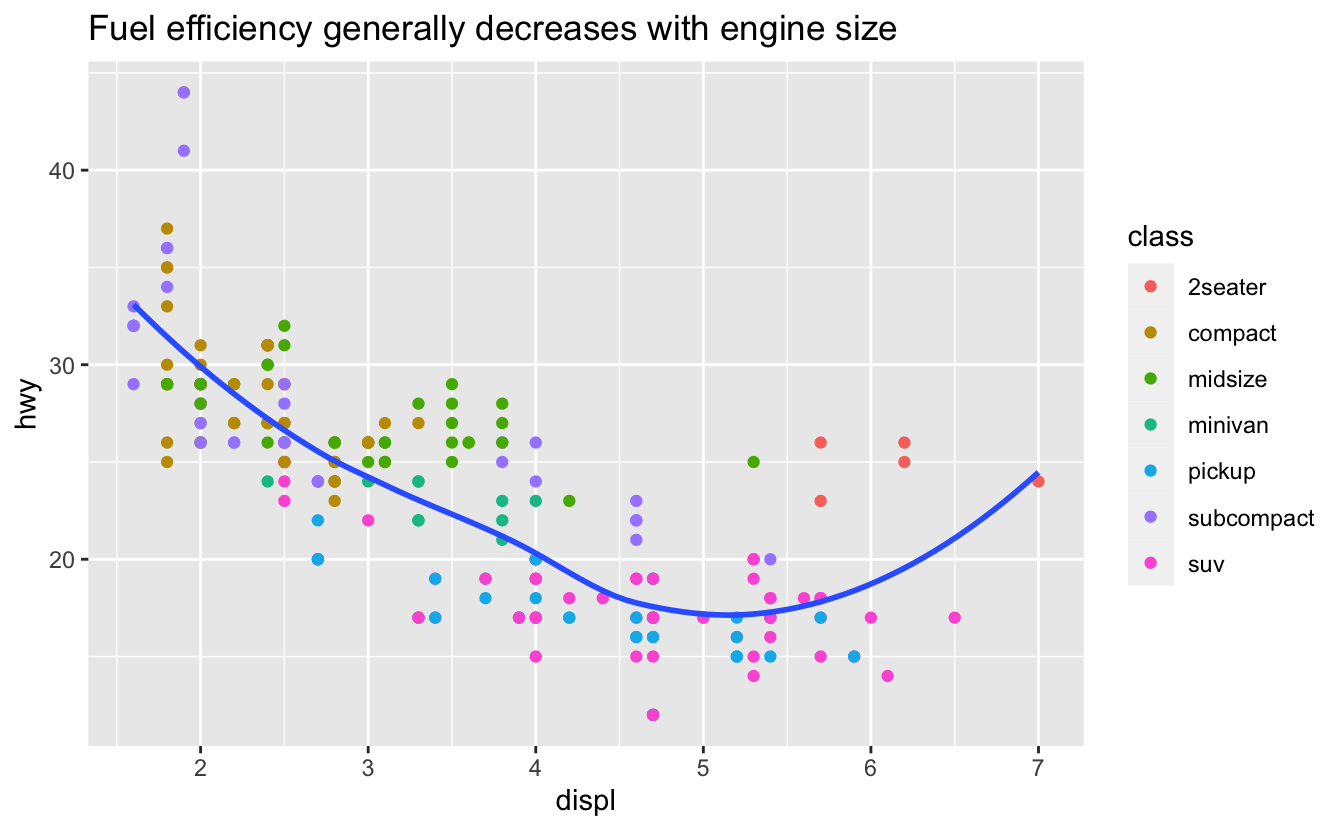
플롯 타이틀의 목적은 주요 발견 사항을 요약하는 것이다. 플롯이 무엇인지 설명 하는 제목 (예: “배기량 대 연비의 산점도”)은 피하라.
더 많은 텍스트를 추가하려면 ggplot2 2.2.0 이상에서 사용할 수 있는 두가지 라벨이 유용합니다:
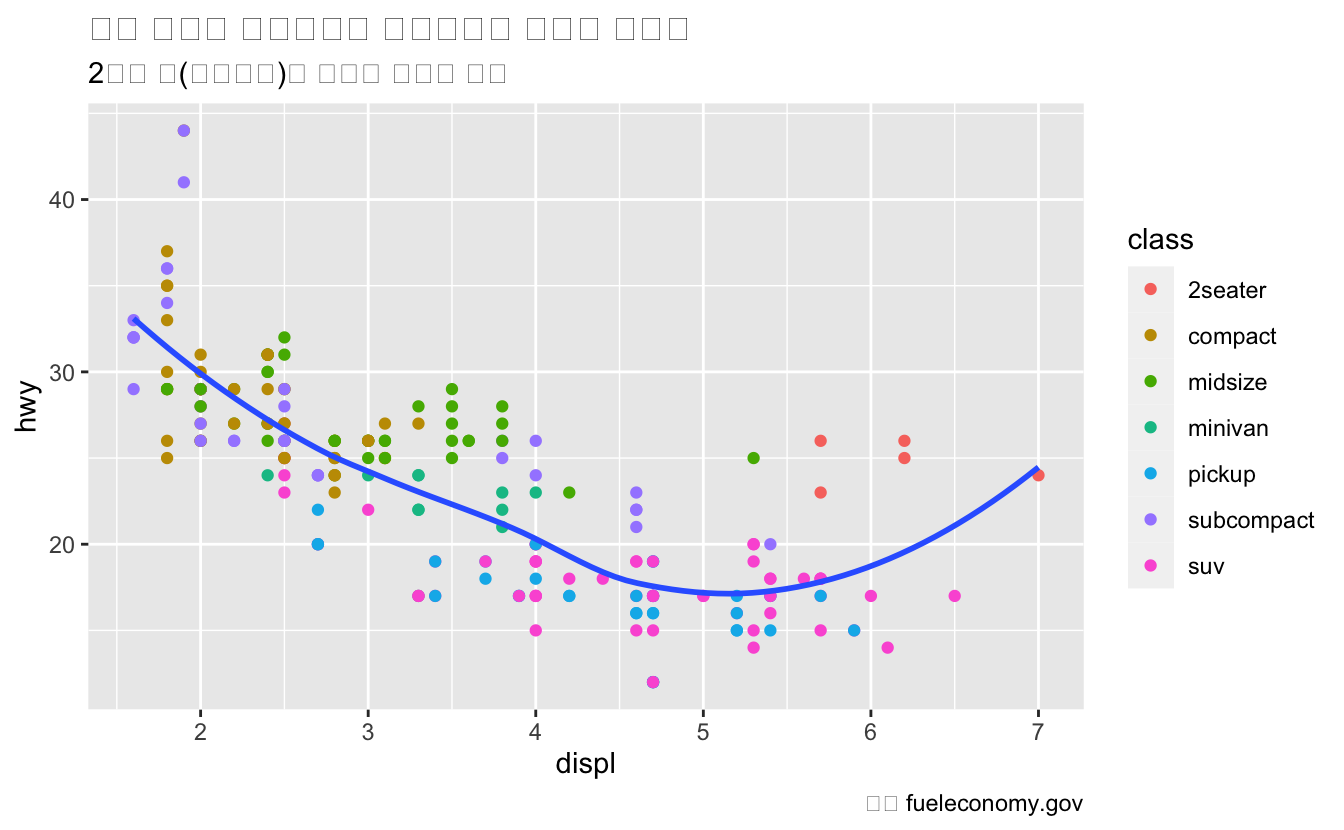
subtitle은 제목 아래에 작은 글꼴로 세부사항을 추가한다.caption은 플롯의 오른쪽 하단에 텍스트를 추가한다. 이 텍스트는 종종 데이 터 소스를 설명하는 데 사용된다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(
title = "엔진 크기가 증가할수록 일반적으로 연비는 감소함",
subtitle = "2인승 차(스포츠카)는 중량이 작아서 예외",
caption = "출처 fueleconomy.gov"
)
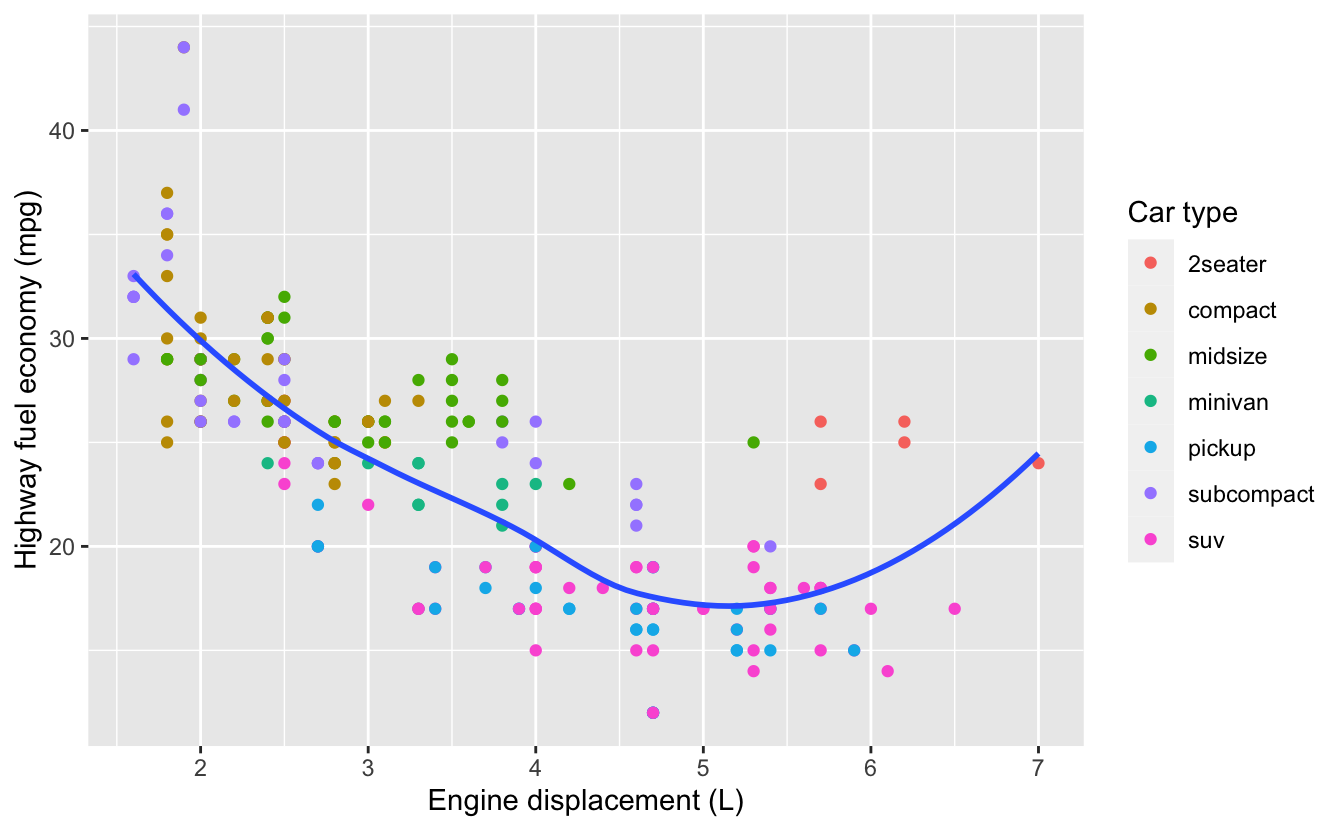
또한 labs() 를 사용하여 축과 범례 제목을 바꿀 수 있다.
짧은 변수 이름을 좀 더 자세한 설명으로 바꾸고, 단위를 포함하는 것이 좋다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
labs(
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
colour = "Car type"
)
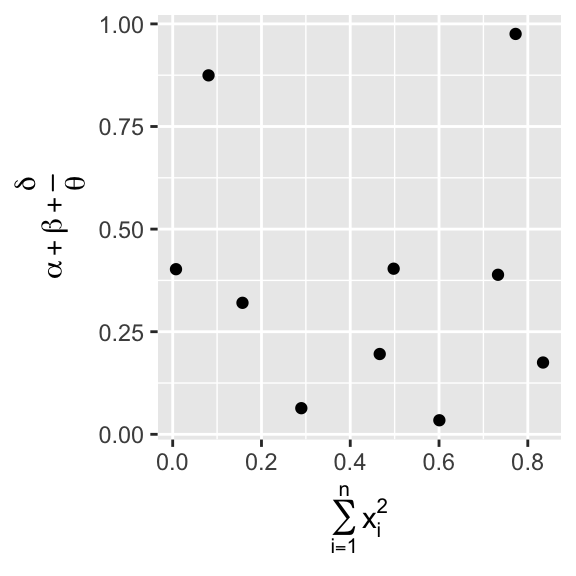
텍스트 문자열 대신 수식을 사용할 수 있다.
"" 를 quote() 으로 바꾸고 옵션에 대해서는 ?plotmath 를 하여 읽어보라:
df <- tibble(
x = runif(10),
y = runif(10)
)
ggplot(df, aes(x, y)) +
geom_point() +
labs(
x = quote(sum(x[i] ^ 2, i == 1, n)),
y = quote(alpha + beta + frac(delta, theta))
)
33.2.1 Exercises
Create one plot on the fuel economy data with customised
title,subtitle,caption,x,y, andcolourlabels.The
geom_smooth()is somewhat misleading because thehwyfor large engines is skewed upwards due to the inclusion of lightweight sports cars with big engines. Use your modelling tools to fit and display a better model.Take an exploratory graphic that you’ve created in the last month, and add informative titles to make it easier for others to understand.
33.3 주석
플롯의 주요 구성요소에 라벨을 붙이는 것 외에도 개별 관측값이나 관측값 그룹에 라벨을 붙이면 유용한 경우가 많다.
첫 번째 도구는 geom_text() 이다.
geom_text() 는 geom_point() 와 비슷하지만 추가 심미성인 label 이 있다.
이를 이용하여 플롯에 텍스트 라벨을 추가할 수 있다.
라벨의 출처로는 두 가지가 있다. 첫째, 티블이 라벨을 제공할 수 있다. 다음 그림은 매우까지는 아니지만 유용한 접근법을 보여준다. 각 차종에서 가장 경제 적인 모델을 dplyr로 뽑은 다음 라벨로 지정한다:
best_in_class <- mpg %>%
group_by(class) %>%
filter(row_number(desc(hwy)) == 1)
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_text(aes(label = model), data = best_in_class)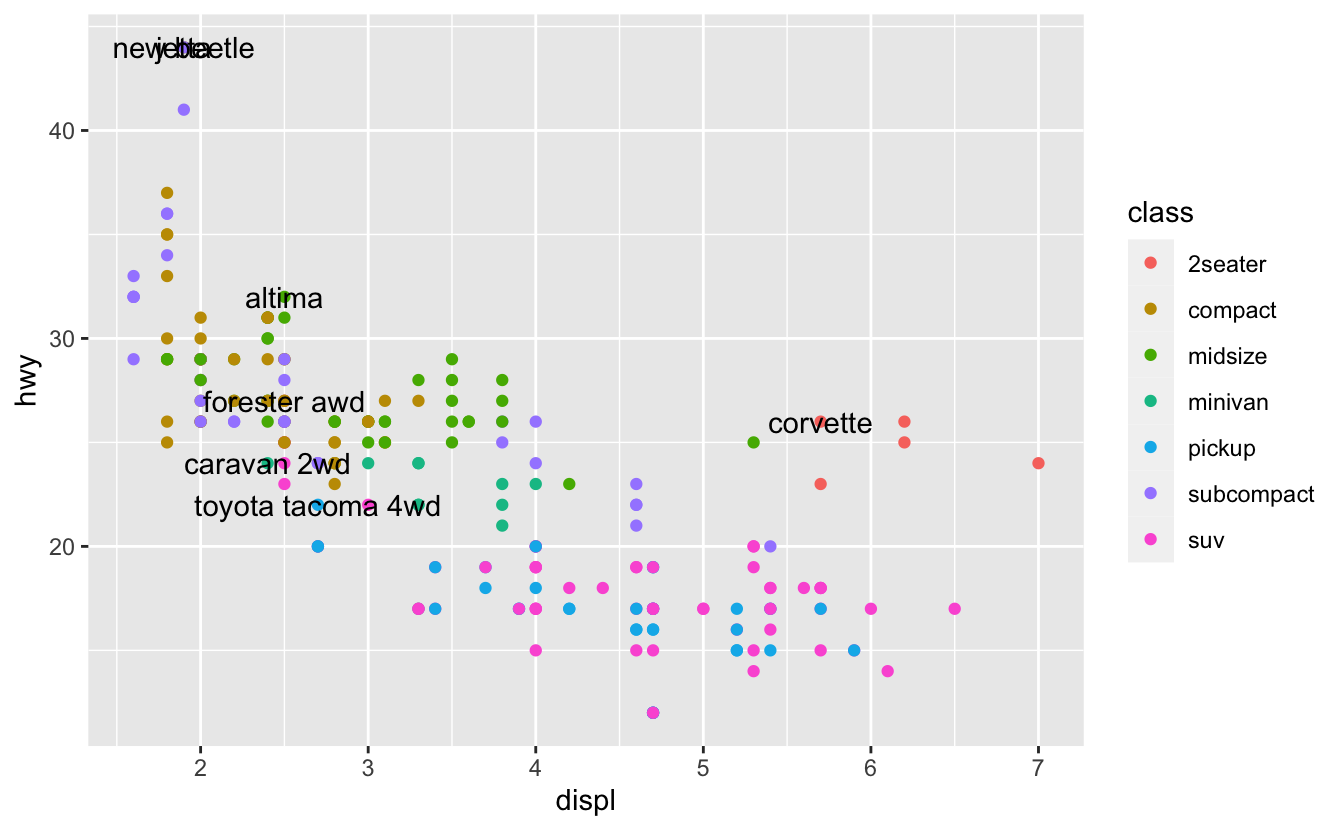
이 방법은 라벨이 서로 겹치거나 점들과 겹치기 때문에 읽기가 어렵다.
geom_ label() 로 전환하면 텍스트 뒤에 사각형이 그려져서 조금 나아진다.
또한 nudge_ y 파라미터를 사용하여 라벨을 해당 점의 위치보다 약간 위로 이동시킨다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_label(aes(label = model), data = best_in_class, nudge_y = 2, alpha = 0.5)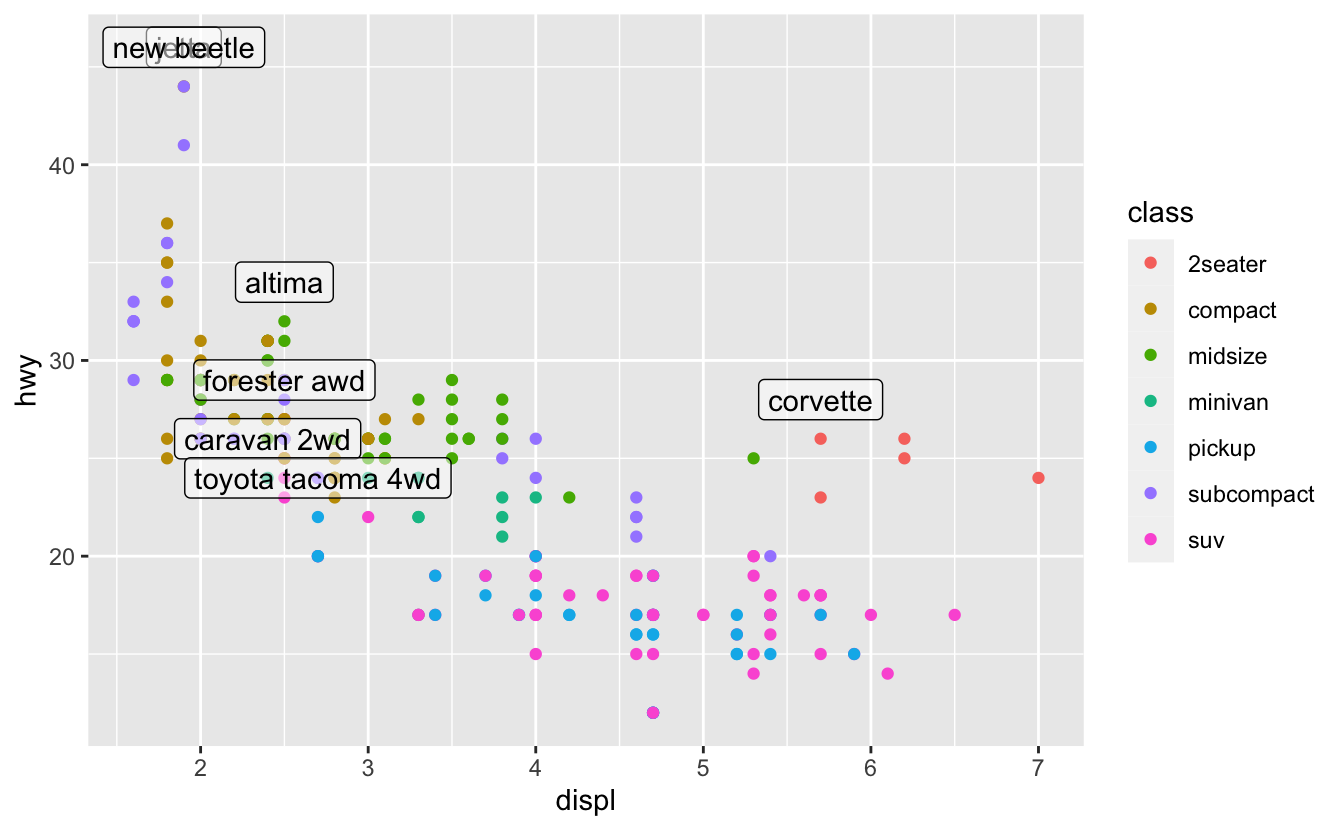
이 방법으로 약간 나아졌지만 맨 위 왼쪽 모서리를 면밀히 살펴보면 사실은 두 개의 라벨이 겹쳐 있음을 알 수 있다. 소형(compact)과 경차(subcompact) 범주 에서 각각 뽑힌 차의 고속도로 연비와 배기량이 정확히 같기 때문에 발생했다. 모든 라벨에 대해 같은 변형을 적용하는 방법으로는 이를 바로잡을 수 없다. 대신 카밀 슬로비코프스키(Kamil Slowikowski)의 ggrepel 패키지를 사용할 수 있다. 이 패키지는 라벨이 겹치지 않도록 라벨을 자동으로 조정한다:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_point(size = 3, shape = 1, data = best_in_class) +
ggrepel::geom_label_repel(aes(label = model), data = best_in_class)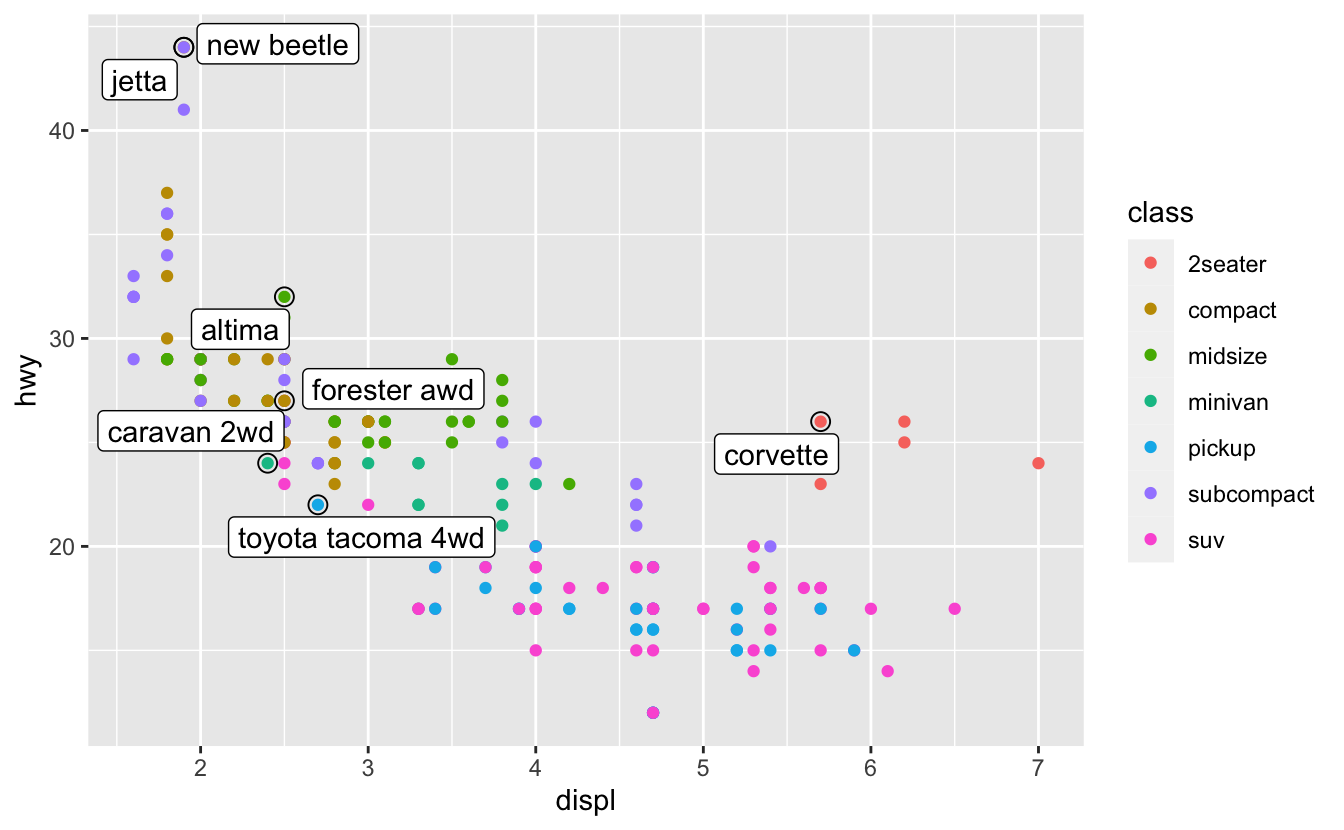
여기에 다음의 편리한 기술이 추가로 사용된 것을 주목하라. 라벨이 붙은 점을 강조하기 위해 속이 빈, 큰 점의 레이어를 추가했다.
같은 방식으로 플롯에 라벨을 직접 위치시켜 범례를 대체할 수 있다.
이 플롯에서는 썩 훌륭하지 않지만 그렇게 나쁘지는 않다. (theme(legend.position = "none") 은 범례를 없애는데 이에 관해서는 곧 살펴본다.)
class_avg <- mpg %>%
group_by(class) %>%
summarise(
displ = median(displ),
hwy = median(hwy)
)
ggplot(mpg, aes(displ, hwy, colour = class)) +
ggrepel::geom_label_repel(aes(label = class),
data = class_avg,
size = 6,
label.size = 0,
segment.color = NA
) +
geom_point() +
theme(legend.position = "none")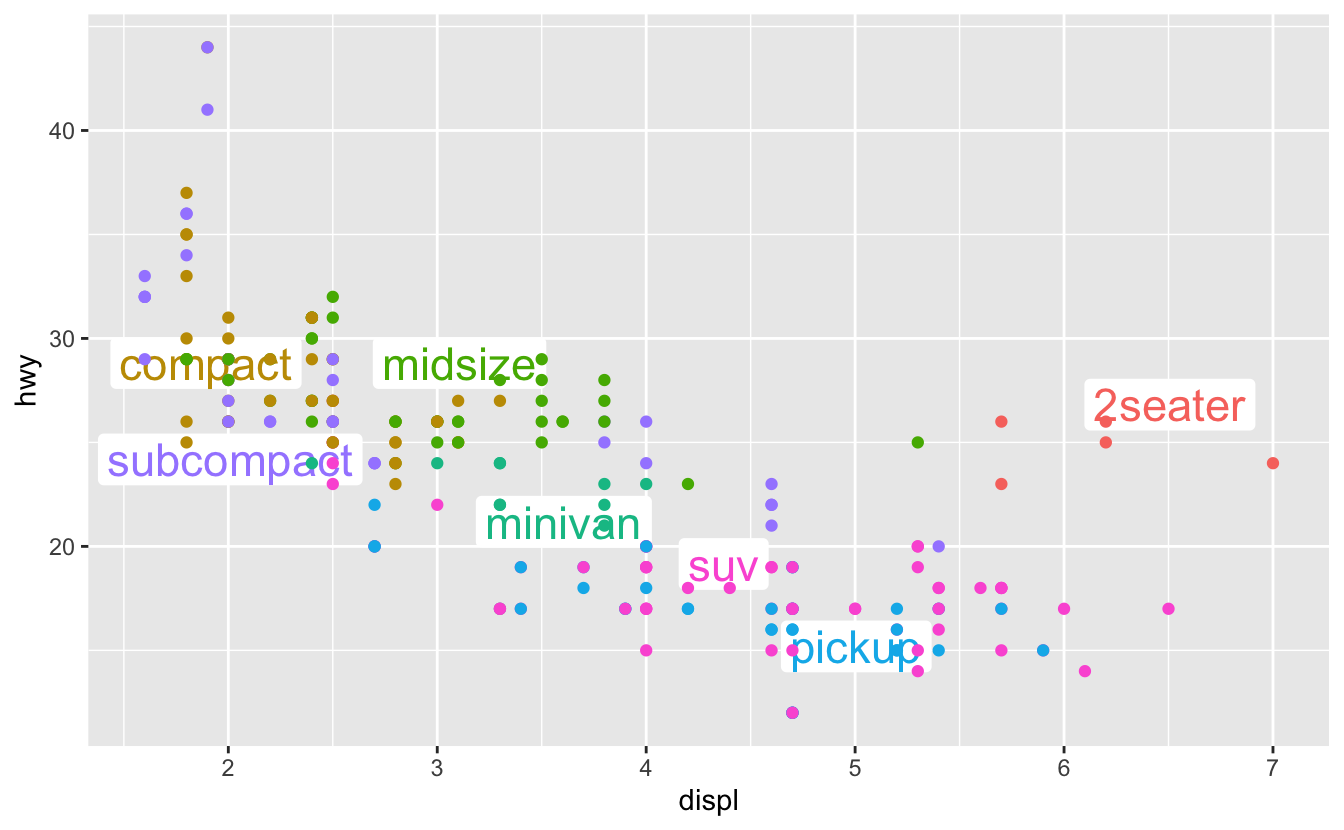
하나의 라벨을 플롯에 추가하고 싶을 수도 있지만 여전히 데이터프레임을 만들 어야 한다. 플롯의 모서리에 라벨을 위치시키고자 하는 경우가 많은데 이 경우 summarize() 를 사용하여 x와 y의 최댓값을 계산하는 데이터프레임을 새로 만드는 것이 편리하다.
label <- mpg %>%
summarise(
displ = max(displ),
hwy = max(hwy),
label = "Increasing engine size is \nrelated to decreasing fuel economy."
)
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_text(aes(label = label), data = label, vjust = "top", hjust = "right")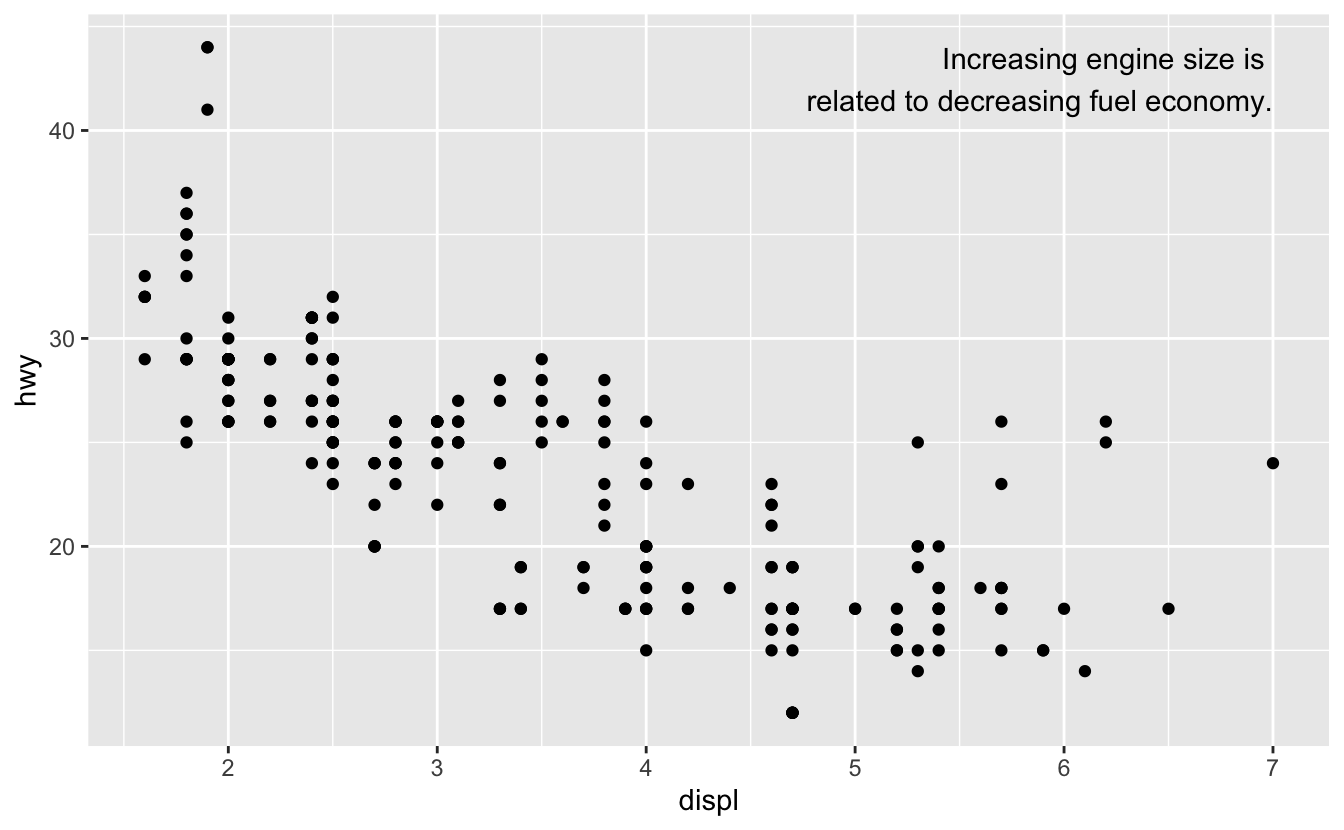
텍스트를 플롯의 테두리에 정확히 배치하려면 +Inf 와 -Inf 를 사용하면 된다. mpg 에서 위치를 더는 계산하지 않으므로 tibble() 을 사용하여 데이터프레임을 만들 수 있다:
label <- tibble(
displ = Inf,
hwy = Inf,
label = "Increasing engine size is \nrelated to decreasing fuel economy."
)
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_text(aes(label = label), data = label, vjust = "top", hjust = "right")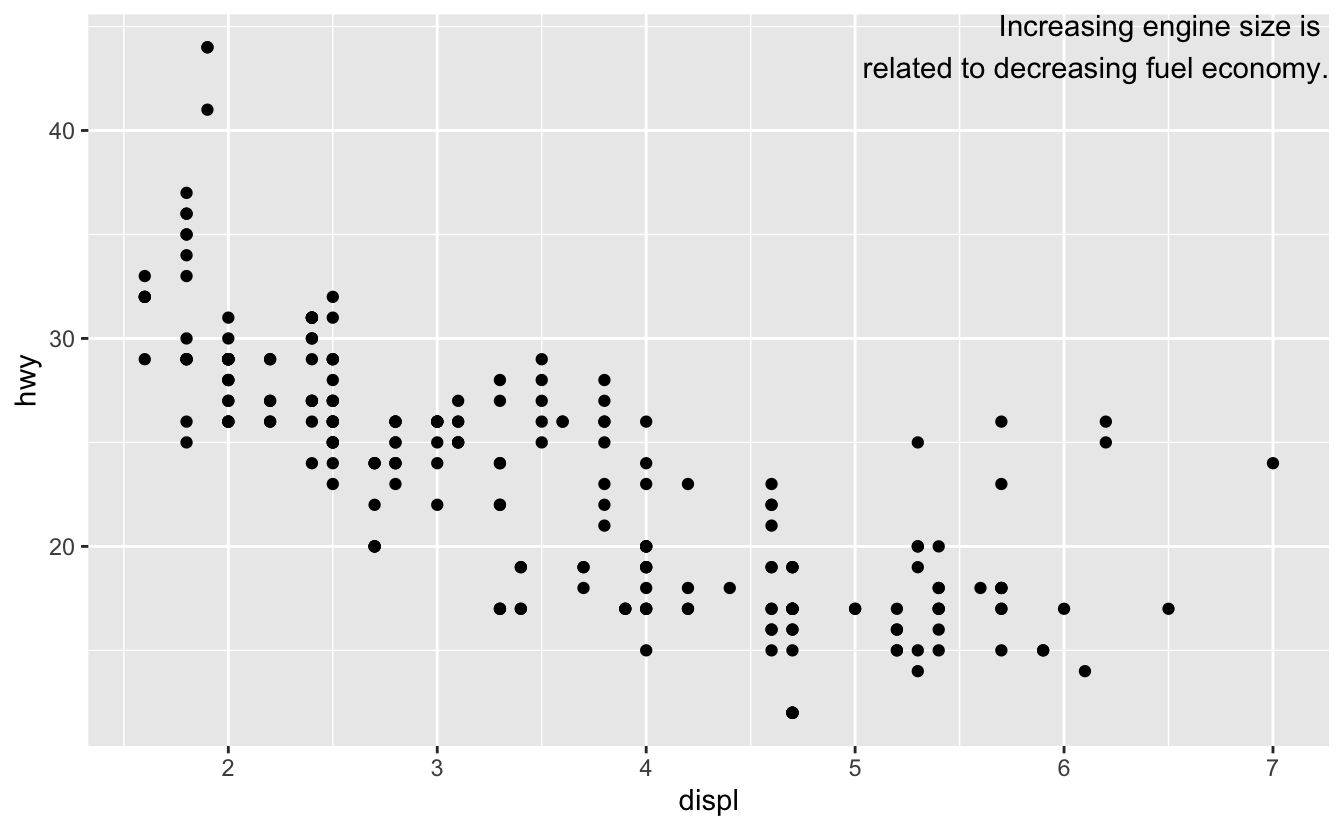
이 예제에서는 "\n" 을 사용하여 라벨을 수동으로 줄바꿈했다.
또 다른 방법은 stringr::str_wrap() 을 사용하여 한 줄에 원하는 문자 수만큼 줄바꿈을 자동으로 추가하는 것이다:
"Increasing engine size is related to decreasing fuel economy." %>%
stringr::str_wrap(width = 40) %>%
writeLines()
#> Increasing engine size is related to
#> decreasing fuel economy.hjust 와 vjust 를 사용해서 라벨 정렬을 제어하는 것을 주목하여 보라.
그림 33.1 에서 가능한 9가지 조합 전체를 볼 수 있다.

Figure 33.1: All nine combinations of hjust and vjust.
geom_text() 외에도 ggplot2 의 여러 지옴을 사용하여 플롯에 주석을 달 수 있음을 기억하라.
몇 가지 아이디어는 다음과 같다:
geom_hline()과geom_vline()을 사용하여 참조선을 추가하라. 참조선을 두껍게(size = 2) 흰색(color = white)으로 만들어 기본 데이터 레이어 아래에 그린다. 이렇게 하면 데이터로부터 시선을 빼앗지 않고도 쉽게 눈에 띈다.geom_rect()를 사용하여 관심 지점 주위에 사각형을 그린다. 직사각형의 경계는xmin,xmax,ymin,ymax심미성으로 정의된다.geom_segment()를arrow인수와 함께 사용하여 화살표로 점에 주의를 집중시킨다.x와y심미성를 사용하여 시작 위치를 정의하고xend와yend로 끝위치를 정의한다.
유일한 한계는 상상력(그리고 심미적으로 만족할 때까지 주석을 위치시키는 끈기)이다!
33.3.1 Exercises
Use
geom_text()with infinite positions to place text at the four corners of the plot.Read the documentation for
annotate(). How can you use it to add a text label to a plot without having to create a tibble?How do labels with
geom_text()interact with faceting? How can you add a label to a single facet? How can you put a different label in each facet? (Hint: think about the underlying data.)What arguments to
geom_label()control the appearance of the background box?What are the four arguments to
arrow()? How do they work? Create a series of plots that demonstrate the most important options.
33.4 스케일
의사소통을 위해 플롯을 더 잘 만들 수 있는 세 번째 방법은 스케일을 조정하는 것이다. 스케일은 데이터값에서 인식할 수 있는 것으로의 매핑을 조정한다. 일반적으로, ggplot2는 자동으로 스케일을 추가한다. 예를 들어 다음을 작성했다고 하자:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))ggplot2는 다음과 같이 뒤에서 기본 스케일들을 추가한다:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
scale_x_continuous() +
scale_y_continuous() +
scale_colour_discrete()스케일의 명명 규칙을 주목하라: scale_ 다음에 심미성의 이름, 그다음 _, 그다음엔 스케일의 이름이 온다.
기본 스케일은 정렬되는 변수의 유형(연속형(contin- uous), 이산형(discrete), 데이트-타임형(date-time), 데이트형(date))에 따라 명명된다.
기본이 아닌 스케일이 많이 있는데, 다음에서 배워보자.
기본 스케일은 다양한 입력에 맞추어 잘 작동하도록 신중하게 선택되었다. 그럼에도 불구하고 두 가지 이유로 기본값을 덮어쓰고자 할 것이다:
기본 스케일의 파라미터 일부를 조정하고자 할 수 있다. 이렇게 하면 축의 눈금이나 범례의 키라벨을 바꾸는 것과 같은 일을 할 수 있다.
스케일을 완전히 대체하고 완전히 다른 알고리즘을 사용하고자 할 수 있다. 데이터에 대해 더 많이 알고 있기 때문에 기본값보다 더 잘 할 수 있는 경우가 종종 있다.
33.4.1 축눈금, 범례키
축의 눈금(tick)과 범례의 키 모양에 영향을 주는 두 가지 주요 인수는 breaks 와 labels 이다.
Breaks 는 눈금의 위치 또는 키와 관련된 값을 제어한다.
Labels 는 각 눈금·키와 연관된 텍스트 라벨을 제어한다.
breaks 는 기본 선택을 덮어쓰는 데에 가장 일반적으로 사용된다:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(breaks = seq(15, 40, by = 5))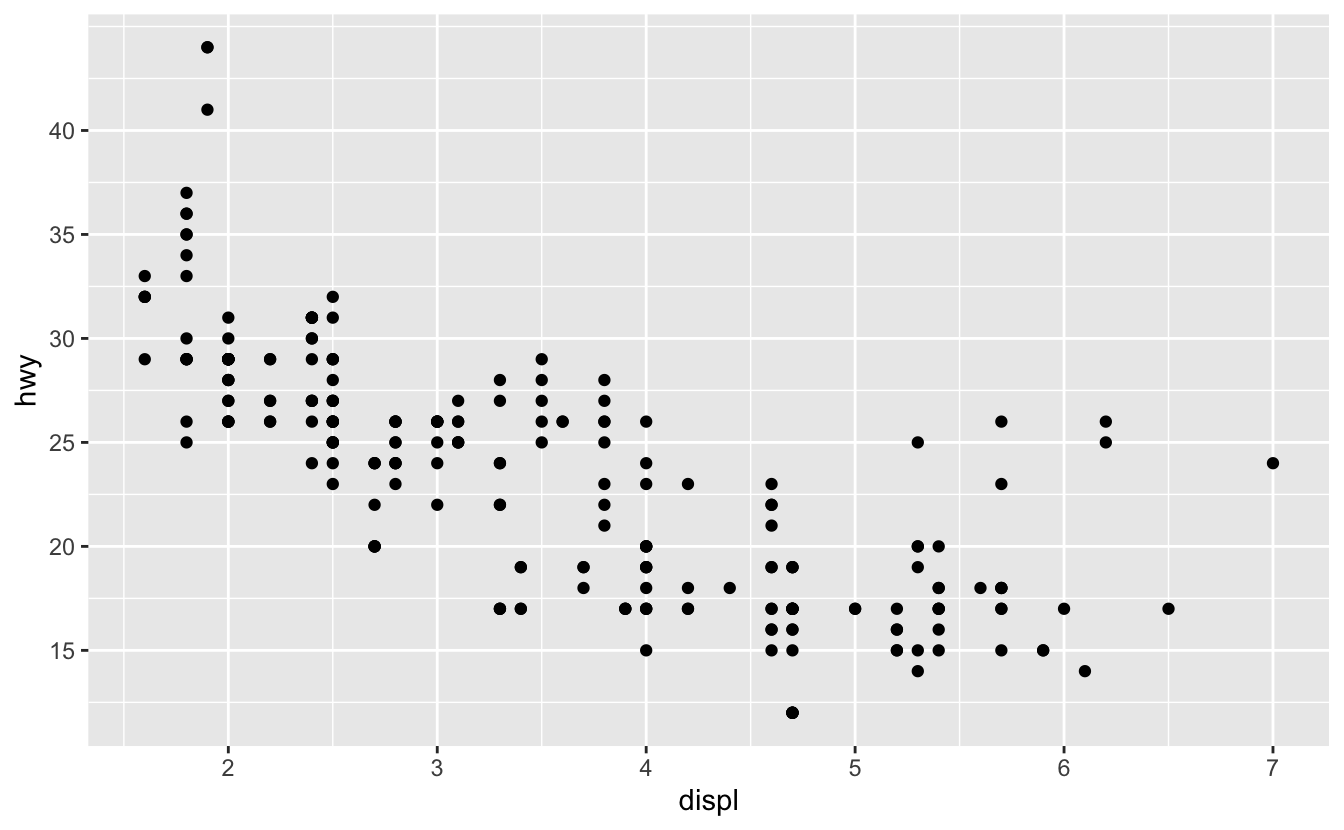
labels 를 같은 방법으로 사용할 수 있지만(breaks 와 같은 길이의 문자형 벡터) NULL 로 설정하여 라벨을 모두 표시하지 않을 수도 있다.
지도 또는 절대 숫자를 공유할 수 없는 플롯을 그릴 때 유용하다.
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(labels = NULL)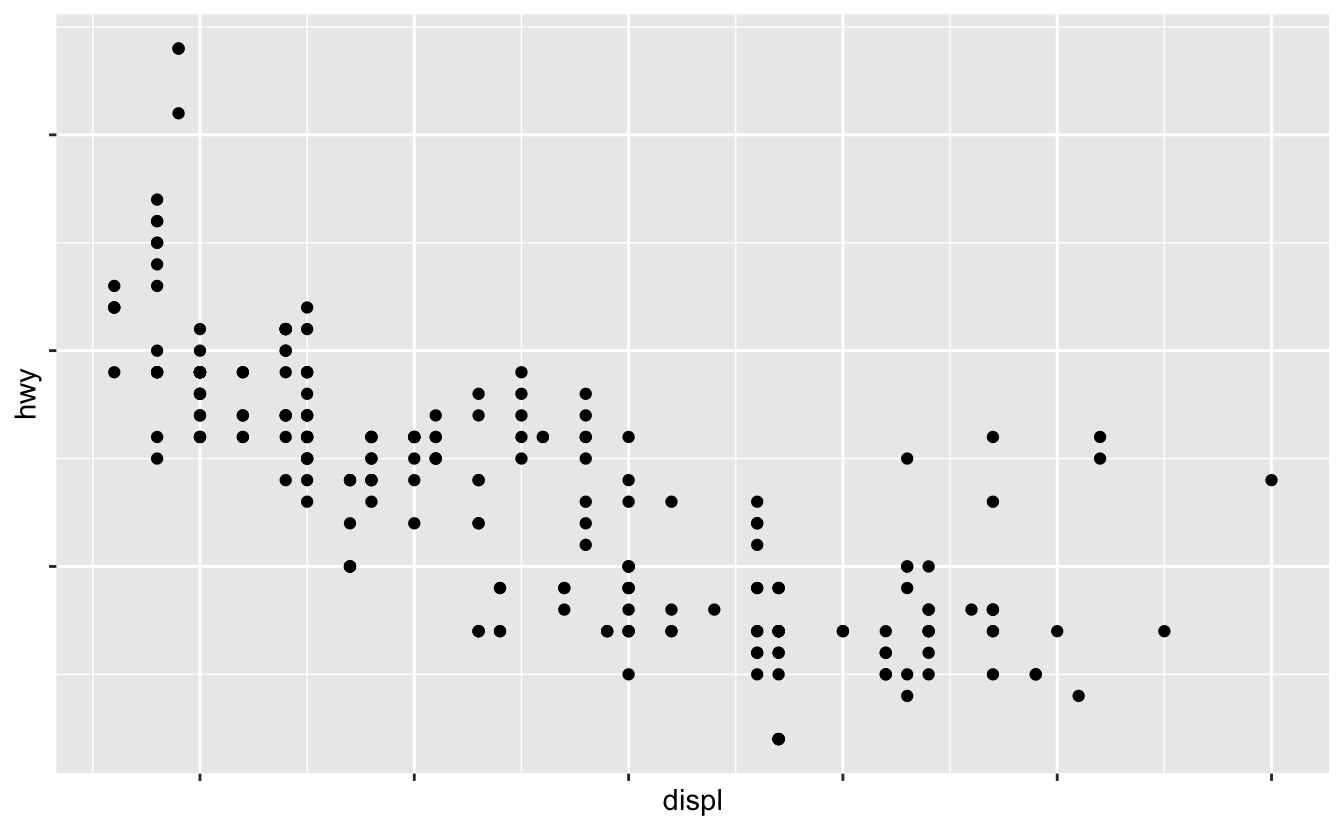
breaks 와 labels 를 사용하여 범례의 외관을 조정할 수도 있다.
축과 범례를 guides 라고 부른다.
축은 x 와 y 심미성에 사용되고, 범례는 다른 모든 것에 사용된다.
데이터 포인트가 상대적으로 적은 경우 관측값이 발생한 정확한 위치를 강조하고 싶을 때도 breaks 를 사용할 수 있다.
예를 들어 각 미국 대통령의 임기가 시작하고 끝난 때를 보여주는 다음의 플롯을 보자.
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_x_date(NULL, breaks = presidential$start, date_labels = "'%y")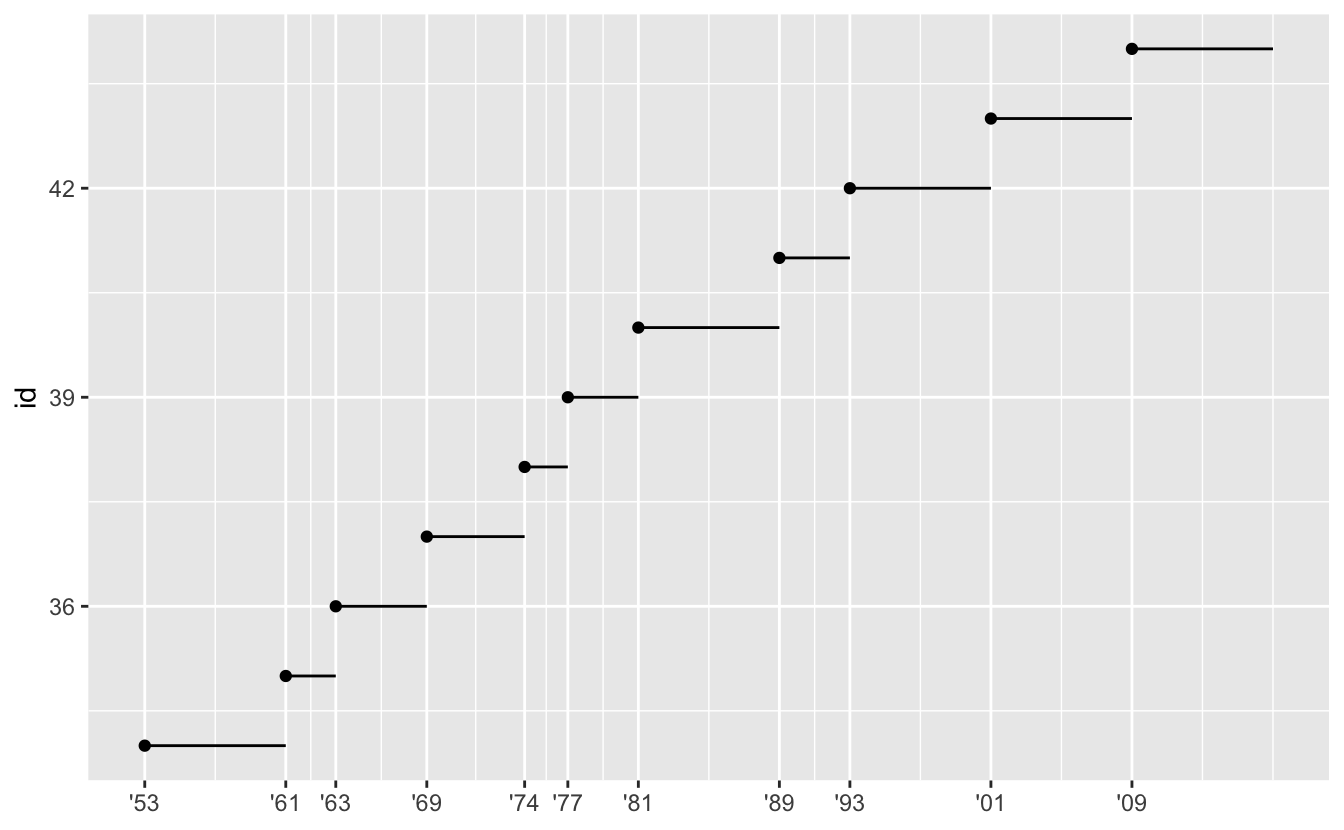
데이트형과 데이트-타임형의 breaks와 labels의 명세가 약간 다른 것을 주의하라:
date_labels는parse_datetime()과 같은 형식으로 형식지정을 사용한다.(여기에 사용되지 않은)
date_breaks는 “2일” 이나 “1개월” 과 같은 문자열을 입력으로 한다.
33.4.2 범례 레이아웃
축을 조정하는 데 breaks 와 labels 를 가장 자주 이용할 것이다.
이 둘은 범례에도 적용할 수 있지만, 사용하기 쉬운 다른 기술 몇 가지가 있다.
범례의 전체 위치를 제어하려면 theme() 설정을 사용해야 한다.
이 장의 마지막 부분에서 다시 돌아와 테마를 보겠지만 간단히 말하면, 이는 플롯의 데이터가 아닌 부분을 조정한다.
legend.position theme 설정은 범례가 배치될 위치를 조정한다:
base <- ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))
base + theme(legend.position = "left")
base + theme(legend.position = "top")
base + theme(legend.position = "bottom")
base + theme(legend.position = "right") # the default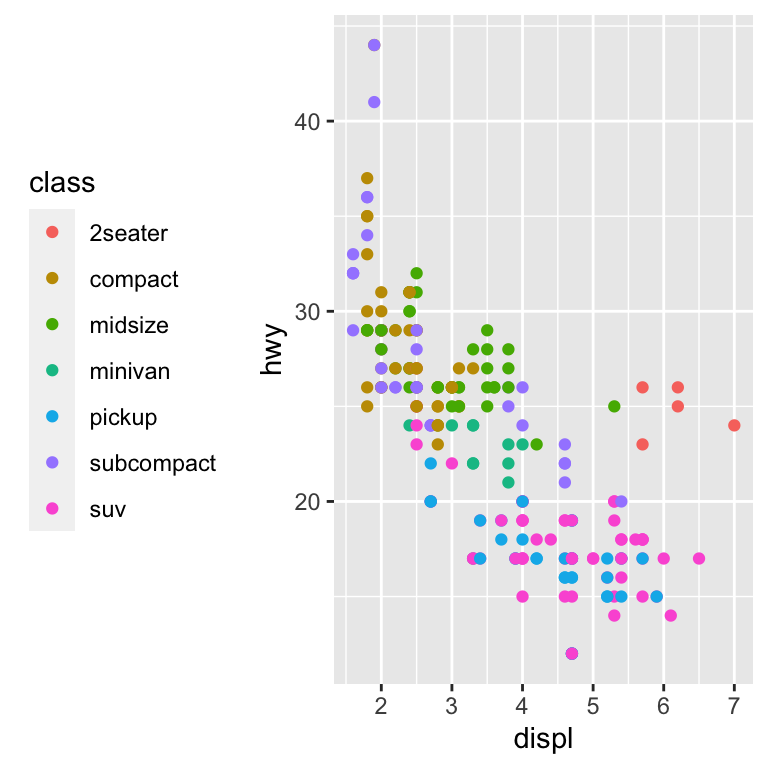
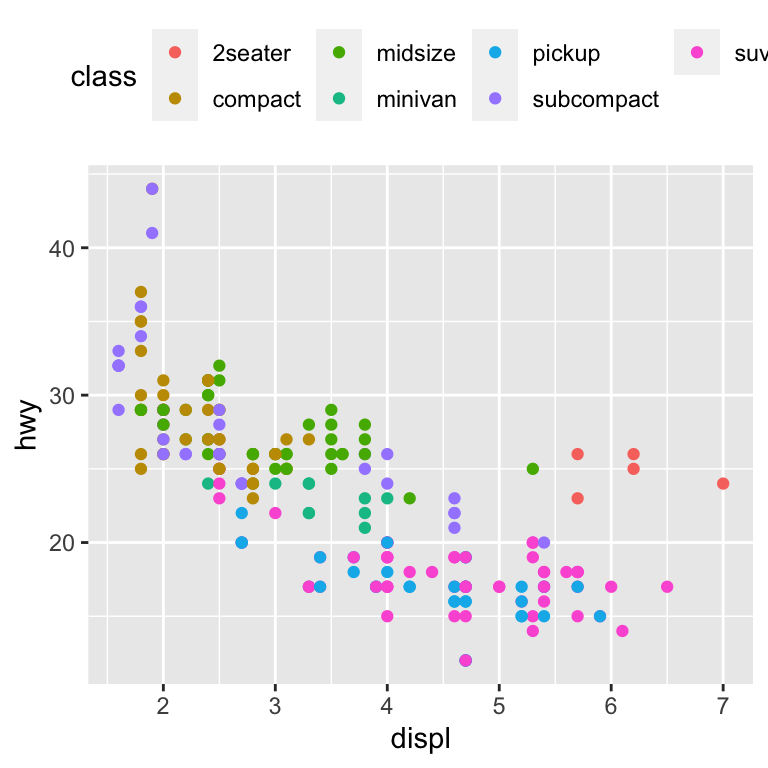
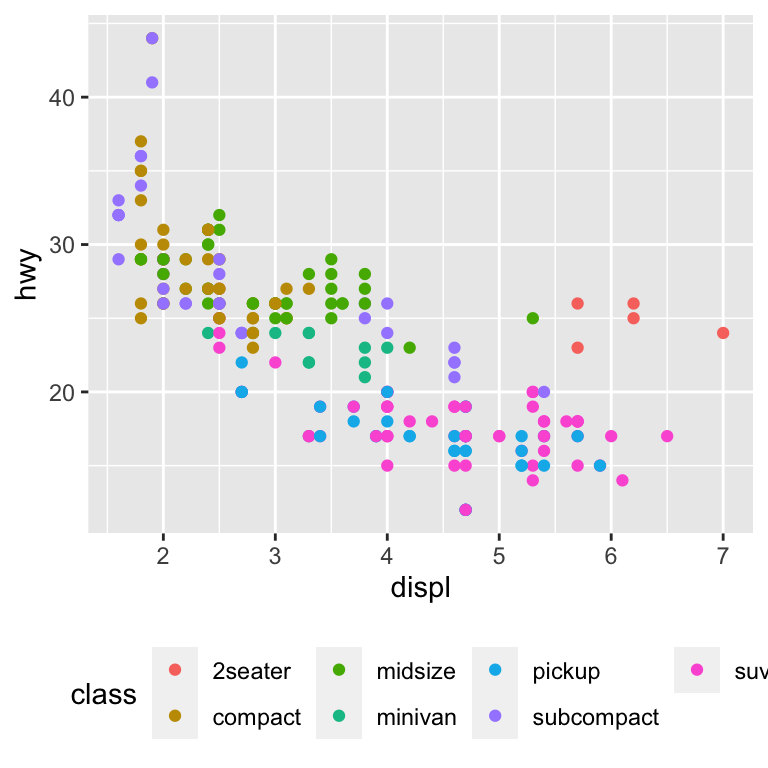
legend.position = "none" 을 사용하여 범례 표시를 모두 취소할 수도 있다.
개별 범례 표시를 제어하려면 guide_legend() 나 guide_colorbar() 와 함께 guides() 를 사용하면 된다.
다음 예제에서는 nrow 로 범례가 사용하는 열의 개수를 조정하는 것과 점을 크게 하기 위해 심미성 하나를 재정의하는 것을 보여준다.
작은 alpha 값을 사용하여 하나의 플롯에 많은 점을 표시한다면 이것이 특별히 유용합니다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
theme(legend.position = "bottom") +
guides(colour = guide_legend(nrow = 1, override.aes = list(size = 4)))
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'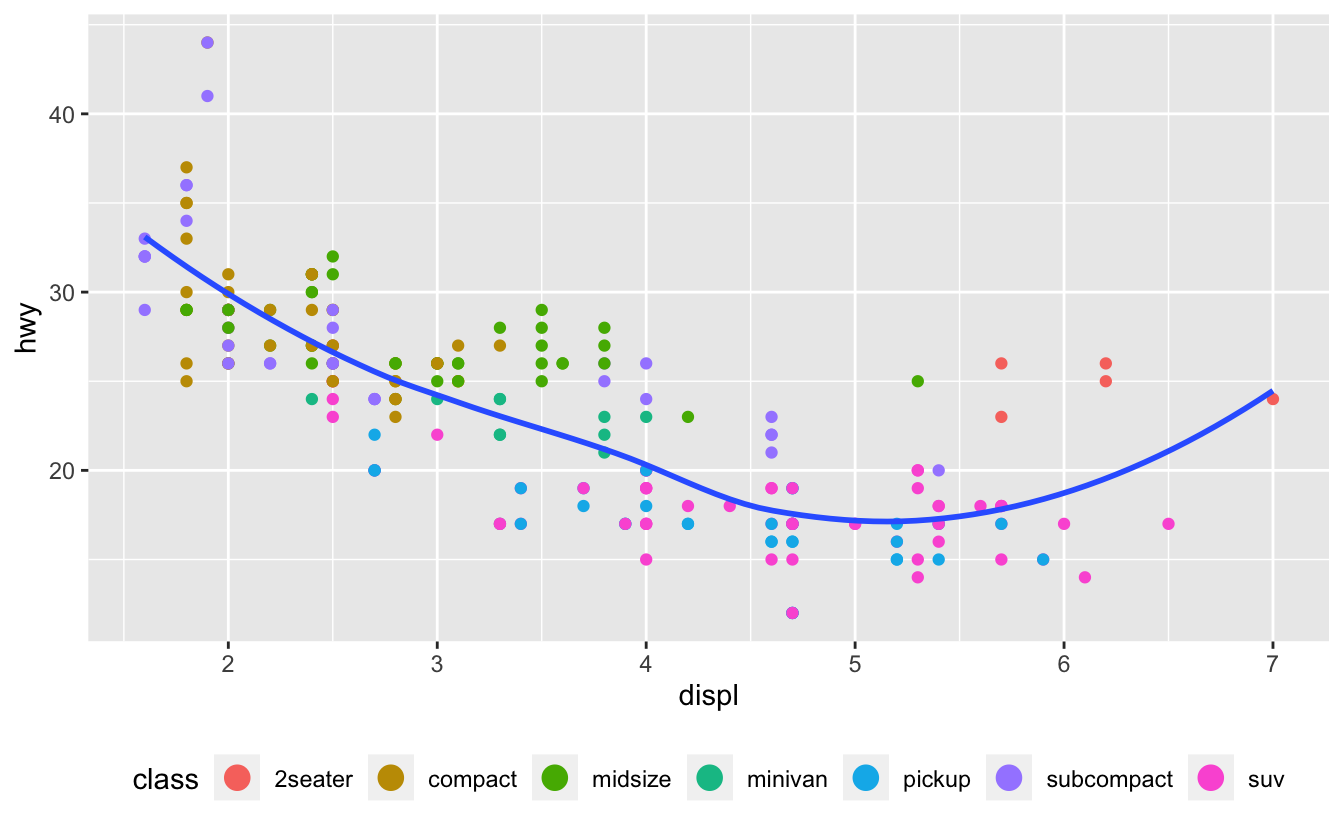
33.4.3 스케일 교체하기
세부사항을 조금만 조정하는 대신 스케일을 모두 교체할 수 있다. 자주 교체되는 두 가지 유형의 스케일은 연속형 위치 스케일과 색상 스케일이다. 다행히도 다른 모든 심미성에 같은 원칙이 적용되므로 위치와 색상을 배우면 다른 스케일 대체물을 신속하게 이해할 수 있다.
변수를 변형 후 플롯하면 매우 유용하다.
예를 들어 diamond prices에서 보았듯이, carat 과 price 를 로그변환하면 이들의 정확한 관계를 확인하기 쉽다:
ggplot(diamonds, aes(carat, price)) +
geom_bin2d()
ggplot(diamonds, aes(log10(carat), log10(price))) +
geom_bin2d()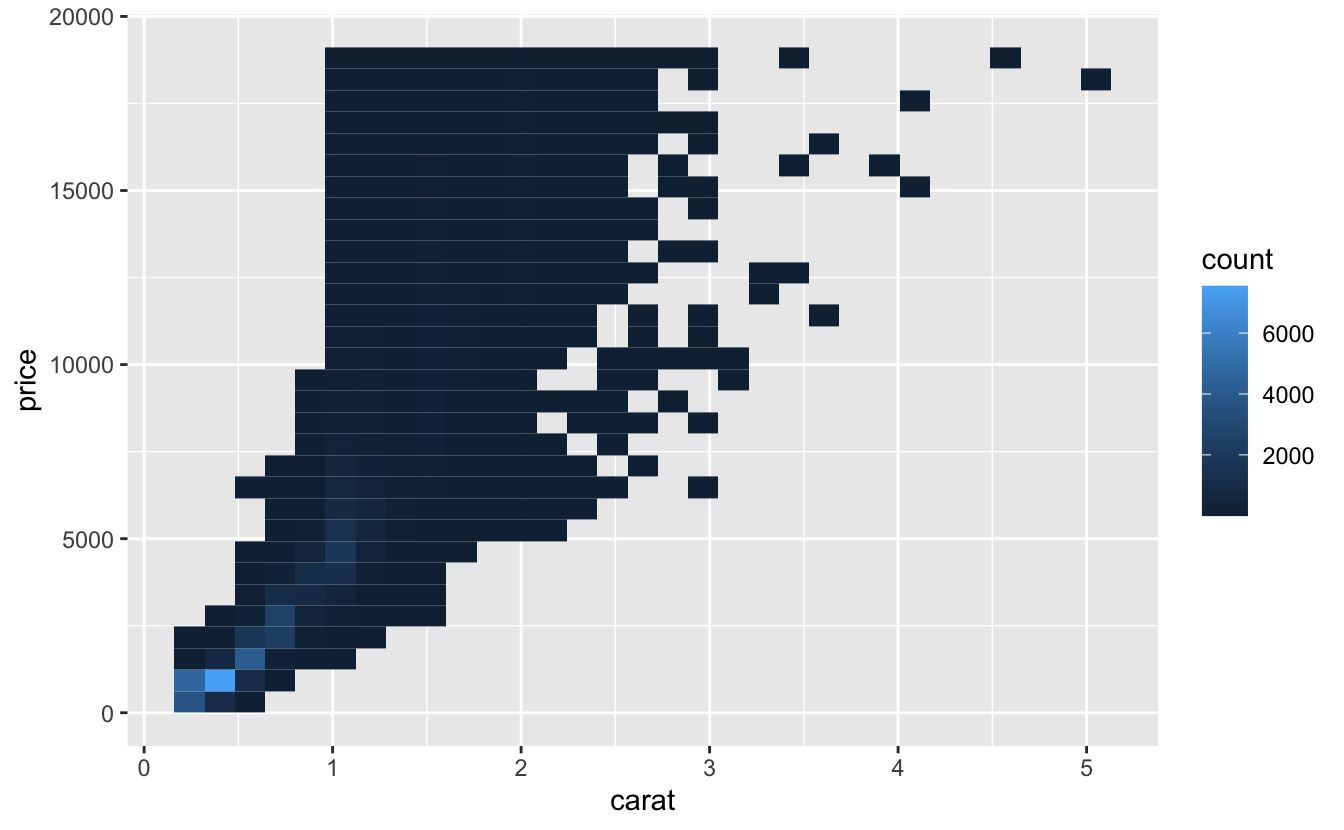
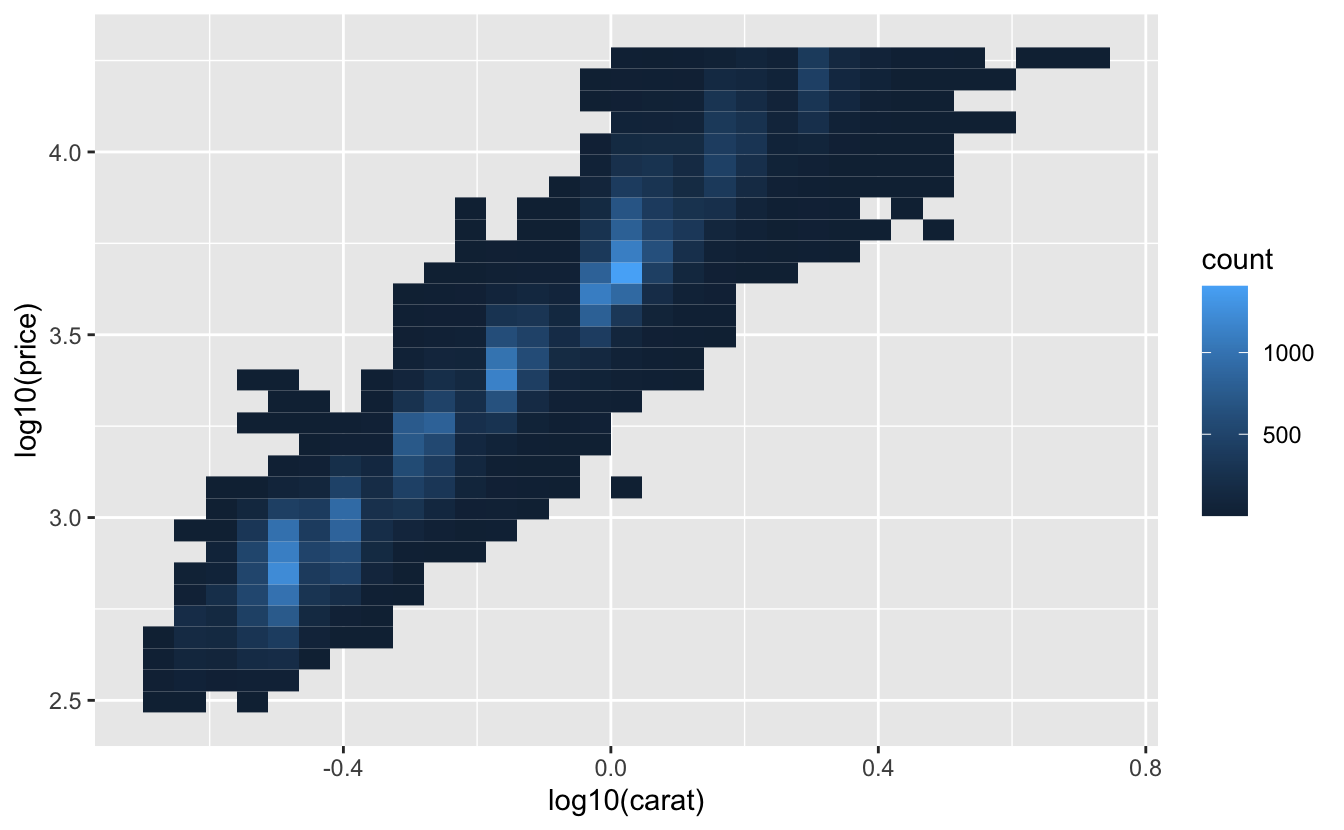
그러나 이 변환의 단점이 있는데, 축의 라벨이 변환된 값으로 지정되어 플롯을 해석하기 어렵게 된다는 것이다. 변환을 심미성 매핑에서 수행하는 대신, 스케일을 이용해서 할 수 있다. 이 방법은 축이 원래 데이터 스케일로 라벨링된다는 점을 제외하고는 시각적으로 동일하다.
ggplot(diamonds, aes(carat, price)) +
geom_bin2d() +
scale_x_log10() +
scale_y_log10()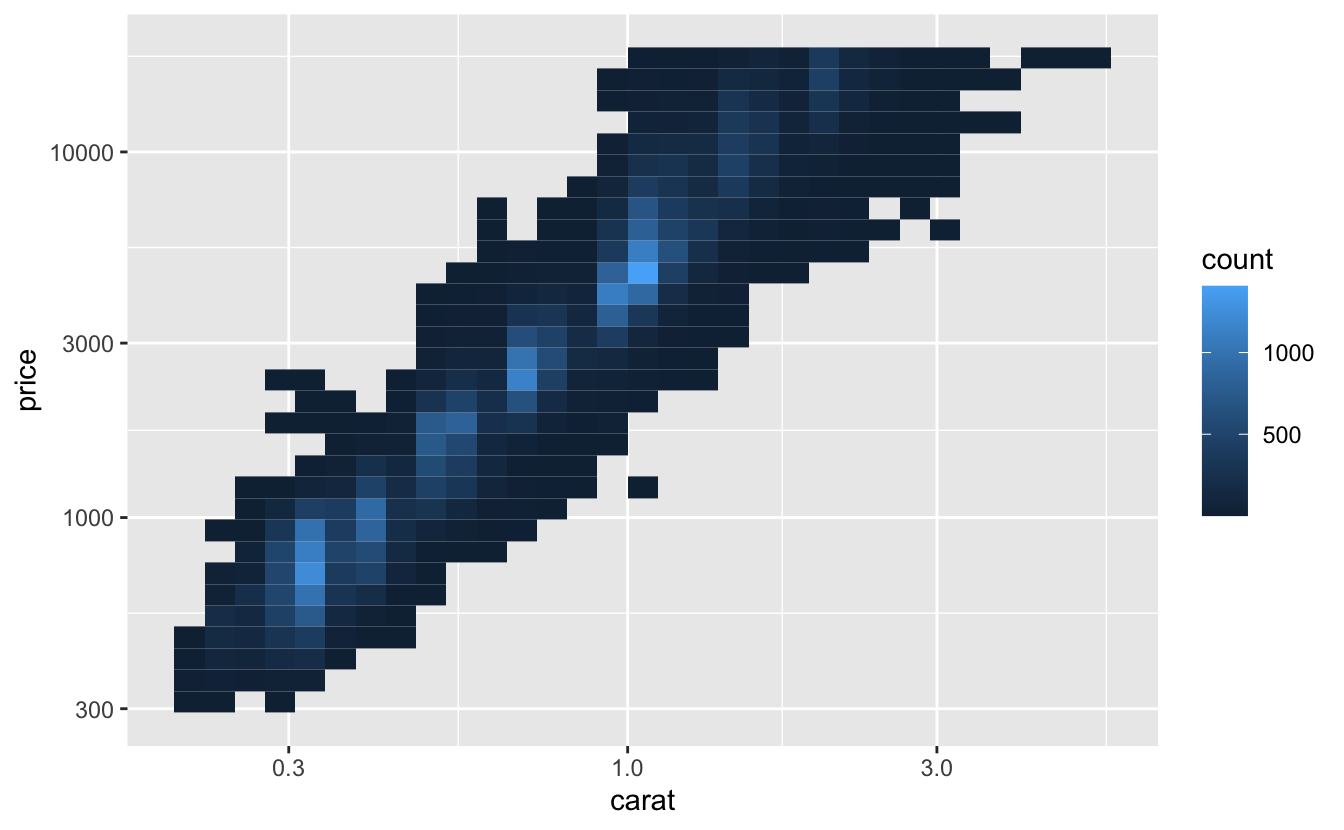
자주 사용자 정의되는 또 다른 스케일은 색상이다. 기본 범주형 스케일에서는 컬러휠 주위에 등간격에 위치한 색상이 선택된다. 흔히 나타나는 유형의 색맹인 사람들도 볼 수 있도록 조정된 ColorBrewer 스케일도 유용한 대안이다. 아래의 두 플롯은 비슷하게 보이지만, 적-녹 색맹 사람들도 구분할 수 있게 오른쪽의 빨간색과 녹색 점의 색깔에 큰 차이가 있다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv))
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv)) +
scale_colour_brewer(palette = "Set1")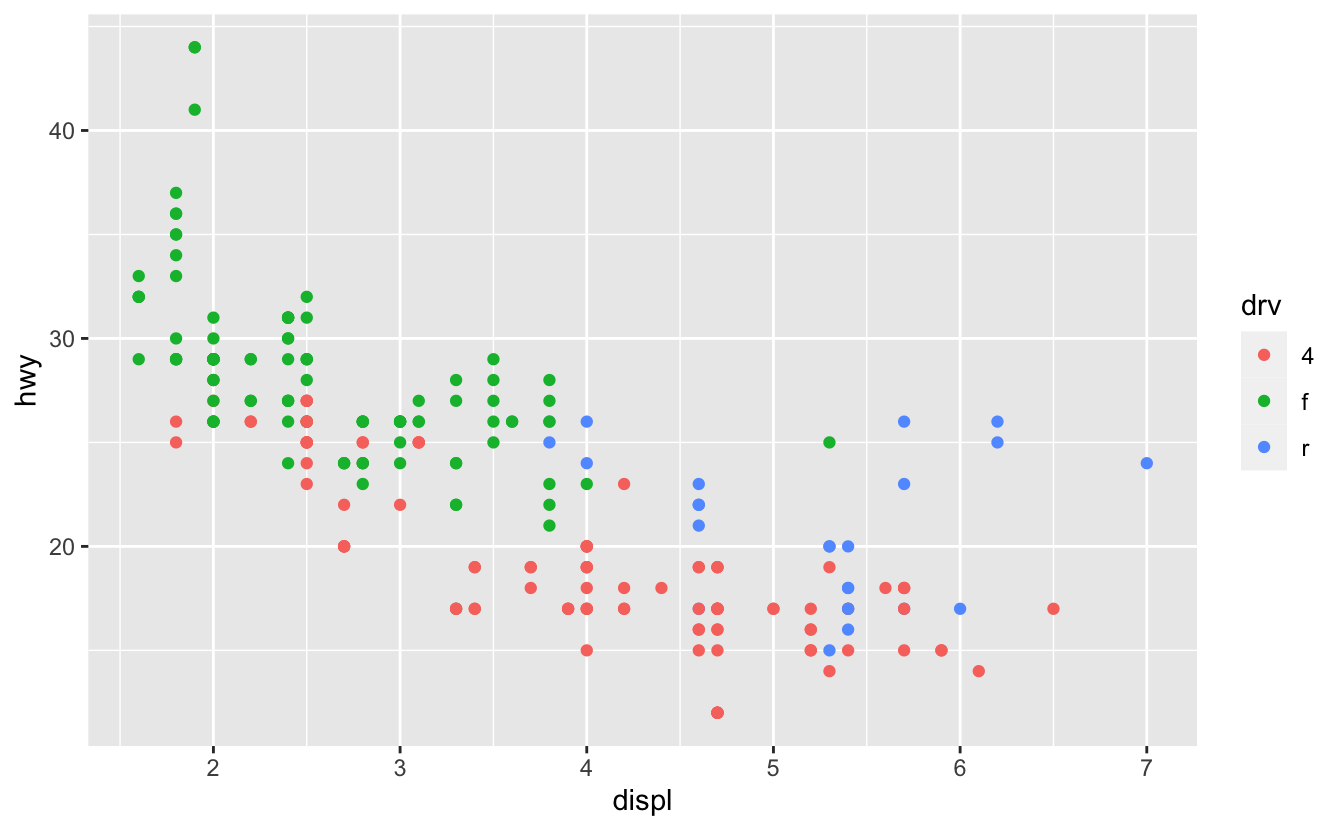
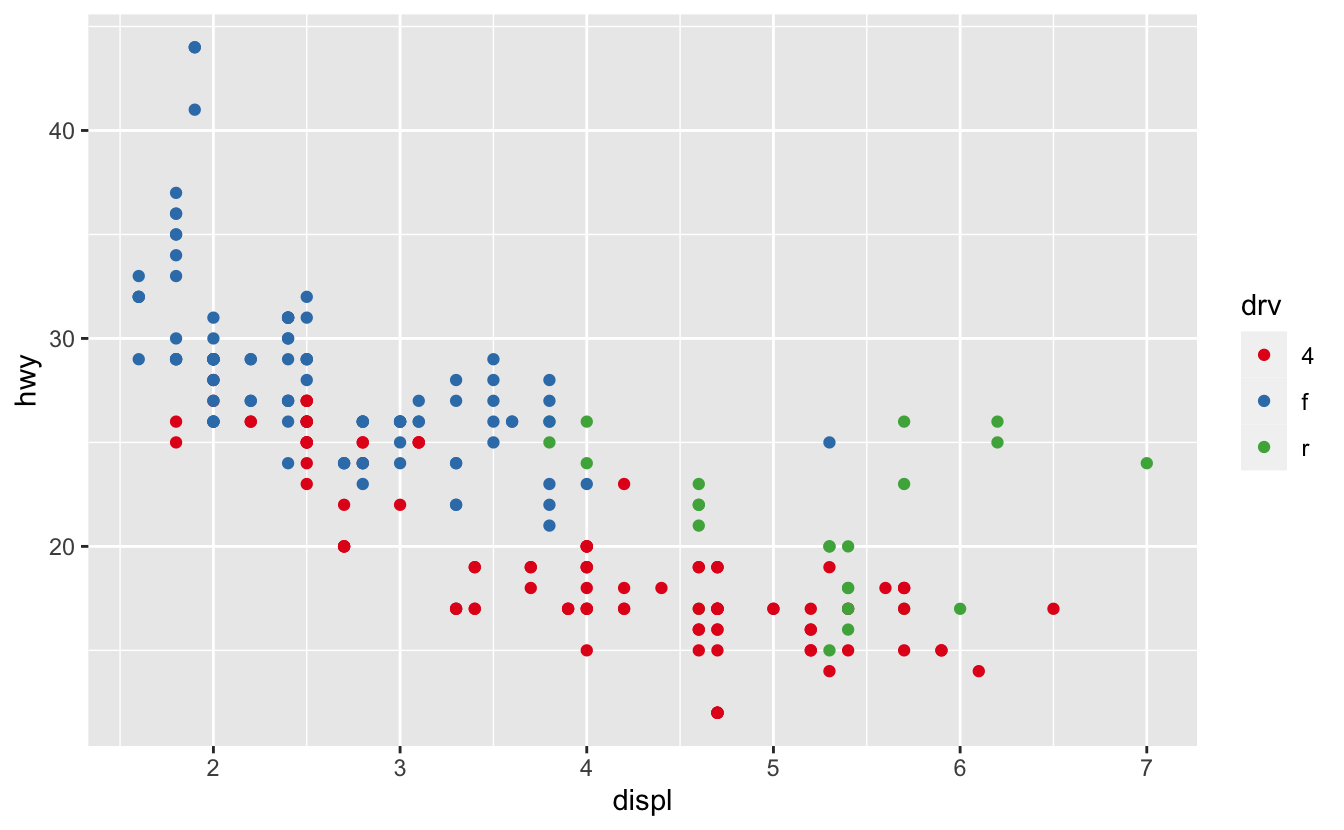
더 간단한 기술을 잊으면 안 된다. 색상의 개수가 많지 않으면 모양(shape) 매핑 을 중복 추가할 수 있다. 이 방법은 플롯이 흑백에서도 구분될 수 있도록 도와주기도 한다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv, shape = drv)) +
scale_colour_brewer(palette = "Set1")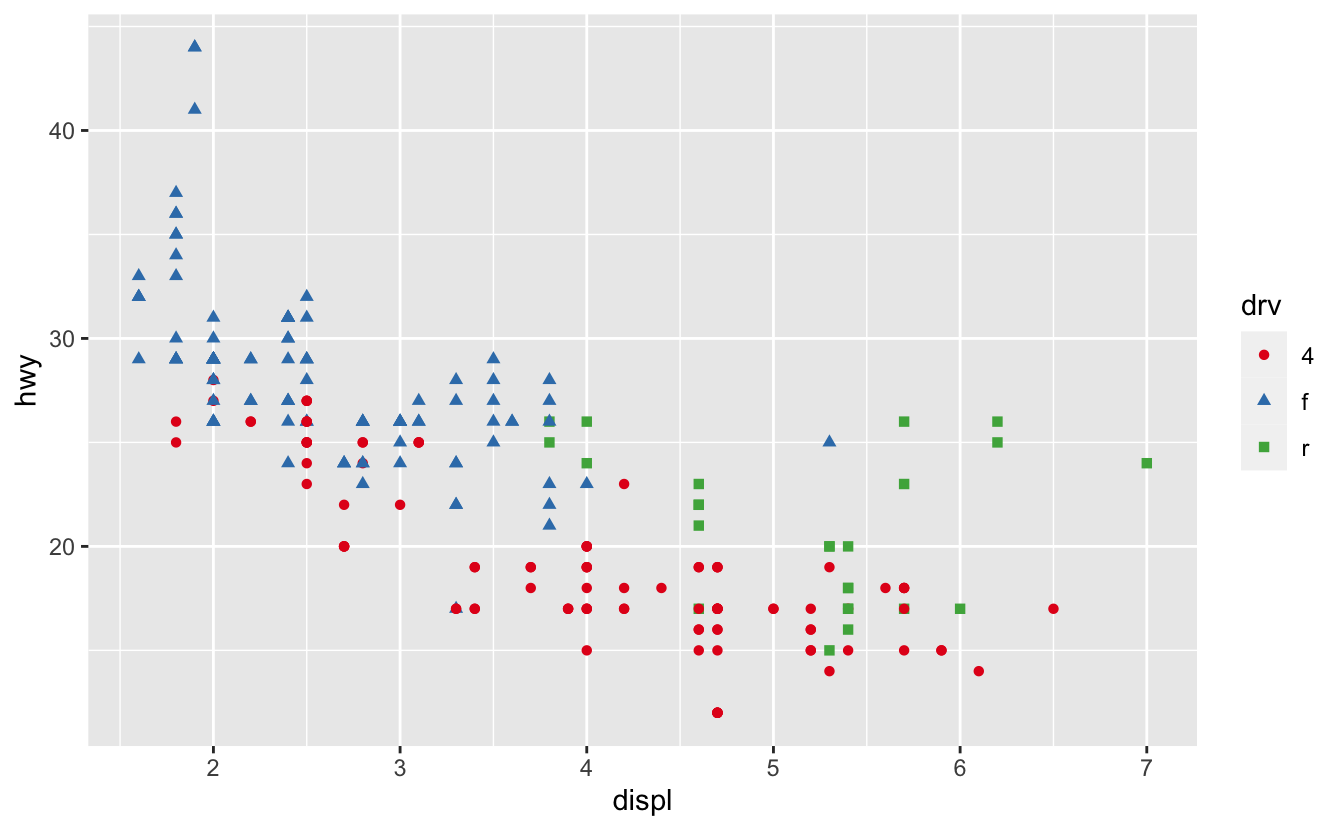
ColorBrewer 스케일은 http://colorbrewer2.org/ 에 온라인 문서화되어 있으며 이리히 노얼스(Erich Neu- wirth)의 RColorBrewer 패키지를 통해 R 에서 제공된다.
그림 33.2는 팔레트 전체 목록을 보여준다.
점진적(상단) 및 발산적(하단) 팔레트는 범주형 값이 정렬되거나 “중간”이 있는 경우에 특히 유용하다.
연속 변수를 범주형 변수로 만들기 위해 cut() 을 사용했을 때 자주 이 같은 경우가 된다.

Figure 33.2: All ColourBrewer scales.
값과 색상 사이에 미리 정의된 매핑이 있다면 scale_color_gradient() 를 사용하라.
예를 들어 대통령 소속 정당을 색상에 매핑한다면 빨간색을 공화당, 파란색을 민주당으로 하는 표준 매핑을 사용하고자 할 것이다:
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue"))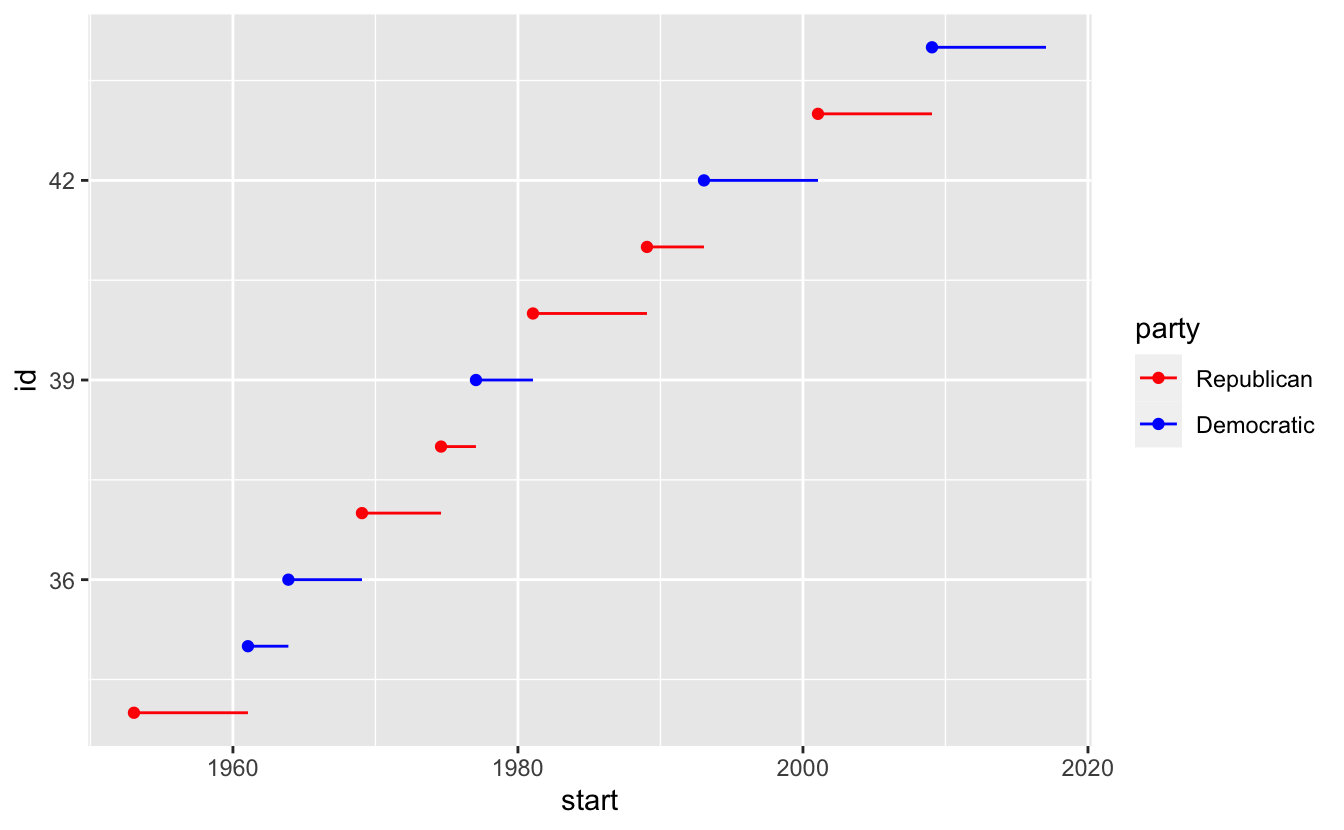
연속형 색상의 경우, 기본적으로 제공된 scale_color_gradient() 나 scale_fill_gradient() 를 사용할 수 있다.
발산 스케일이 있다면 scale_color_gradient2() 를 사용할 수 있다.
이 방법으로, 예를 들어 양수와 음수에 다른 색깔을 줄 수 있다.
이는 평균 이상이나 이하 점을 구분하고자 할 때 사용할 수 있는 유용한 방법이다.
viridis 패키지에서 제공하는 scale_color_viridis() 도 또 다른 방법이다.
이는 범주형 ColorBrewer의 연속형 버전이다.
두 디자이너, Nathaniel Smith 와 Stéfan van der Walt 는 인지 속성이 좋은 연속형 색상 구성표를 신중하게 만들었다.
다음은 viridis 비네트에 가져온 예시이다.
df <- tibble(
x = rnorm(10000),
y = rnorm(10000)
)
ggplot(df, aes(x, y)) +
geom_hex() +
coord_fixed()
#> Warning: Computation failed in `stat_binhex()`:
#> The `hexbin` package is required for `stat_binhex()`
ggplot(df, aes(x, y)) +
geom_hex() +
viridis::scale_fill_viridis() +
coord_fixed()
#> Warning: Computation failed in `stat_binhex()`:
#> The `hexbin` package is required for `stat_binhex()`

모든 색상 스케일은 두 가지 형태가 있음을 기억하라. scale_color_x() 와 scale_fill_x() 는 각각 색상과 채우기 심미성이다 (색상 스케일은 영국식 스펠링과 미 국식 스펠링이 가능하다).
33.4.4 Exercises
-
Why doesn’t the following code override the default scale?
ggplot(df, aes(x, y)) + geom_hex() + scale_colour_gradient(low = "white", high = "red") + coord_fixed() #> Warning: Computation failed in `stat_binhex()`: #> The `hexbin` package is required for `stat_binhex()` What is the first argument to every scale? How does it compare to
labs()?-
Change the display of the presidential terms by:
- Combining the two variants shown above.
- Improving the display of the y axis.
- Labelling each term with the name of the president.
- Adding informative plot labels.
- Placing breaks every 4 years (this is trickier than it seems!).
-
Use
override.aesto make the legend on the following plot easier to see.ggplot(diamonds, aes(carat, price)) + geom_point(aes(colour = cut), alpha = 1/20)
33.5 확대 축소
플롯 범위를 조정하는 방법은 세 가지가 있다:
- 플롯할 데이터 조정하기
- 각 스케일에서 범위 설정하기
-
coord_cartesian()의xlim과ylim설정하기
플롯 영역을 확대·축소하려면 coord_cartesian() 을 사용하는 것이 일반적으로 제일 좋다. 다음의 두 플롯을 비교해서 보라:
ggplot(mpg, mapping = aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth() +
coord_cartesian(xlim = c(5, 7), ylim = c(10, 30))
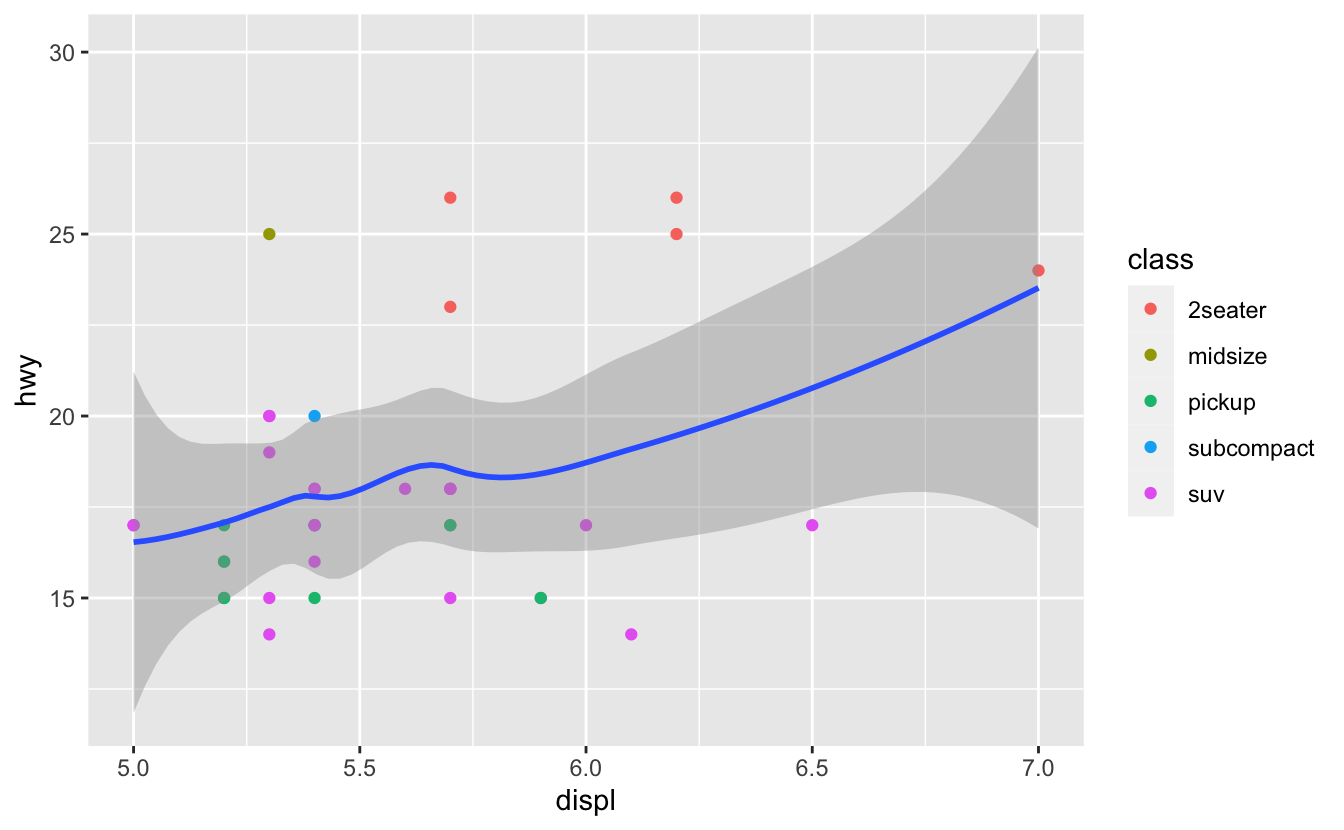
mpg %>%
filter(displ >= 5, displ <= 7, hwy >= 10, hwy <= 30) %>%
ggplot(aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth()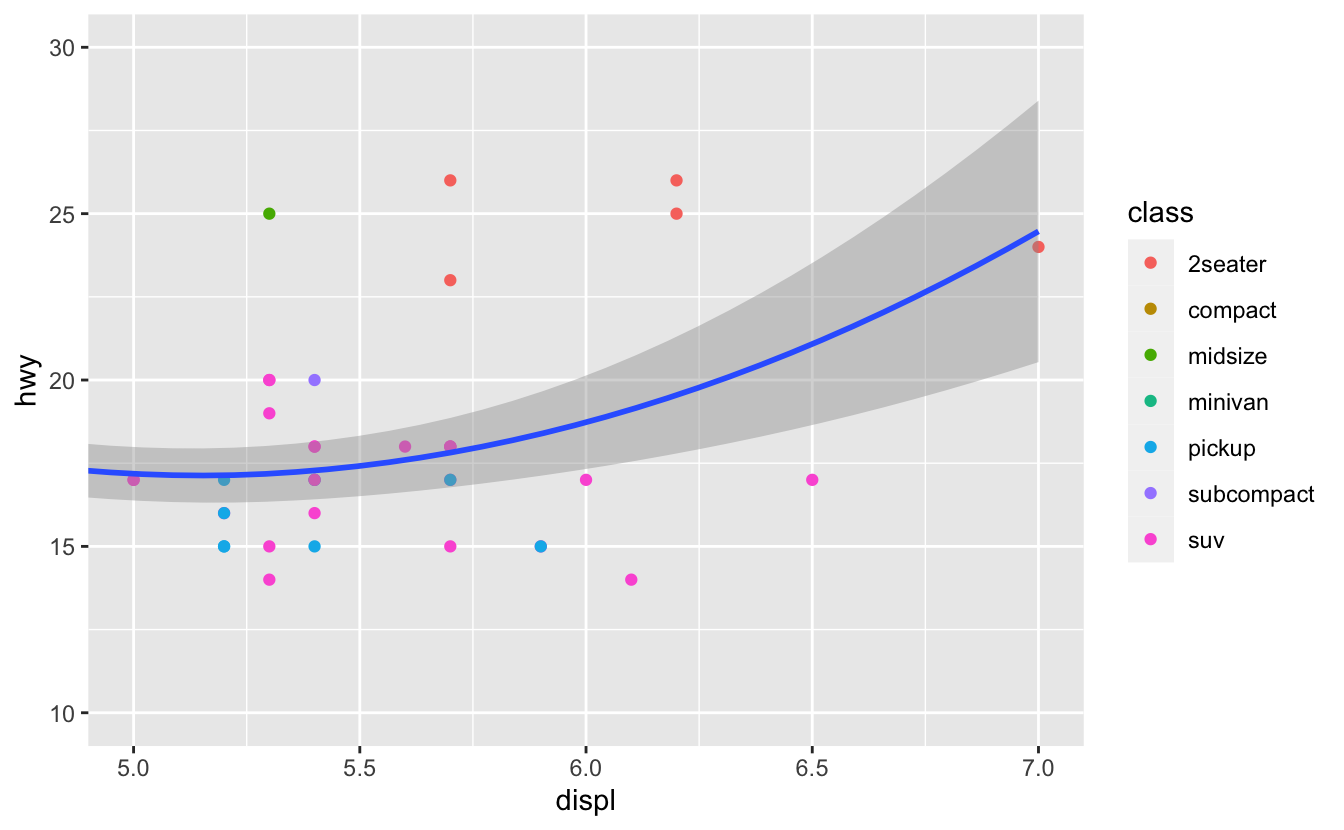
개별 스케일에 대한 limits(범위) 를 설정할 수도 있다.
범위를 줄이는 방식은 기본적으로 데이터를 서브셋하는 것과 같다.
플롯들 사이에 스케일을 일치시키는 등의 목적으로 범위를 _확장_하려는 경우에 일반적으로 유용하다.
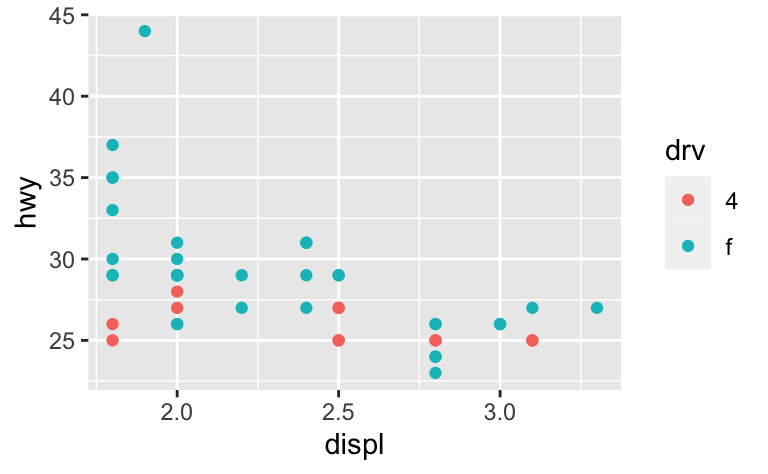
예를 들어 두 차종을 추출하여 각각 플롯을 그리면 세 가지 스케일(x축, y축, 색상 심미성)의 범위가 서로 다르기 때문에 플롯을 비교하기가 어렵다.
suv <- mpg %>% filter(class == "suv")
compact <- mpg %>% filter(class == "compact")
ggplot(suv, aes(displ, hwy, colour = drv)) +
geom_point()
ggplot(compact, aes(displ, hwy, colour = drv)) +
geom_point()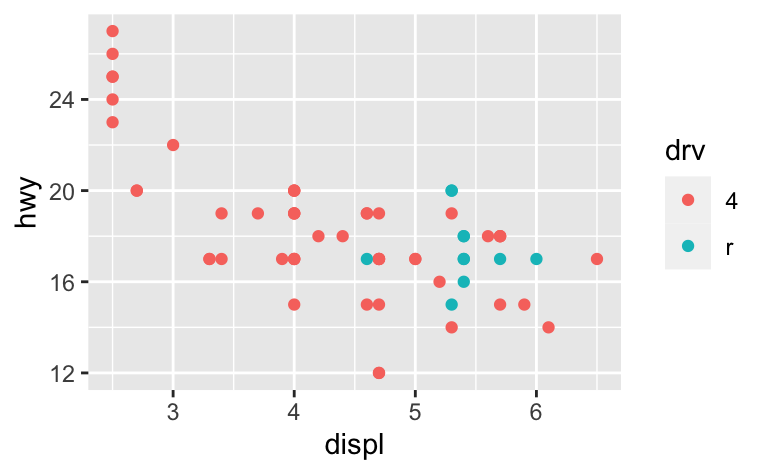
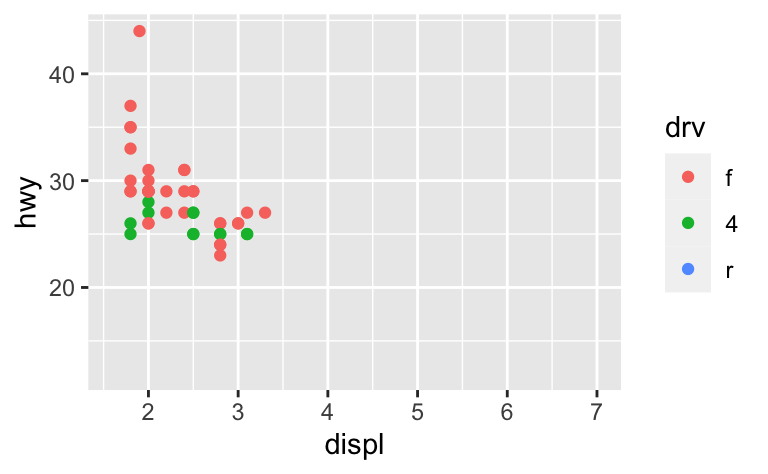
이 문제를 해결하는 방법 중 하나는, 여러 플롯 사이에 스케일을 공유하고, 전체 데이터의 limits 로 스케일을 학습하는 것이다.
x_scale <- scale_x_continuous(limits = range(mpg$displ))
y_scale <- scale_y_continuous(limits = range(mpg$hwy))
col_scale <- scale_colour_discrete(limits = unique(mpg$drv))
ggplot(suv, aes(displ, hwy, colour = drv)) +
geom_point() +
x_scale +
y_scale +
col_scale
ggplot(compact, aes(displ, hwy, colour = drv)) +
geom_point() +
x_scale +
y_scale +
col_scale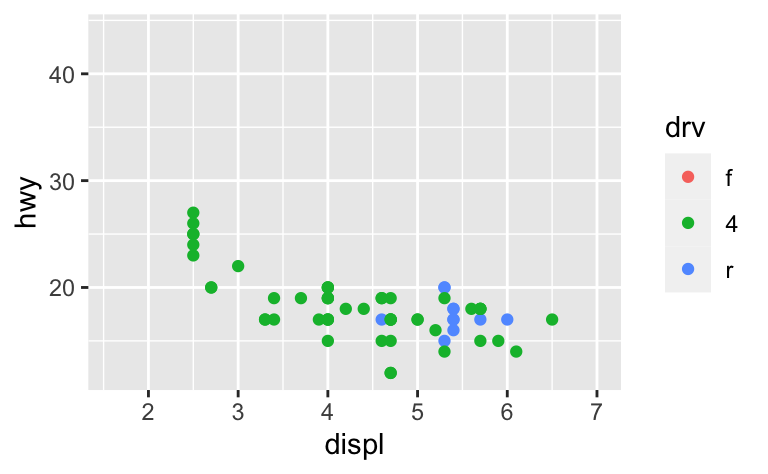
이 예제에서는 간단히 면분할을 사용할 수도 있지만, 위의 방법은 플롯이 보고서의 여러 페이지에 걸쳐 있는 경우 등에서 일반적으로 더 편리하다.
33.6 테마
마지막으로, 테마를 사용하여 플롯의 데이터가 아닌 요소를 사용자 정의할 수 있다:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
theme_bw()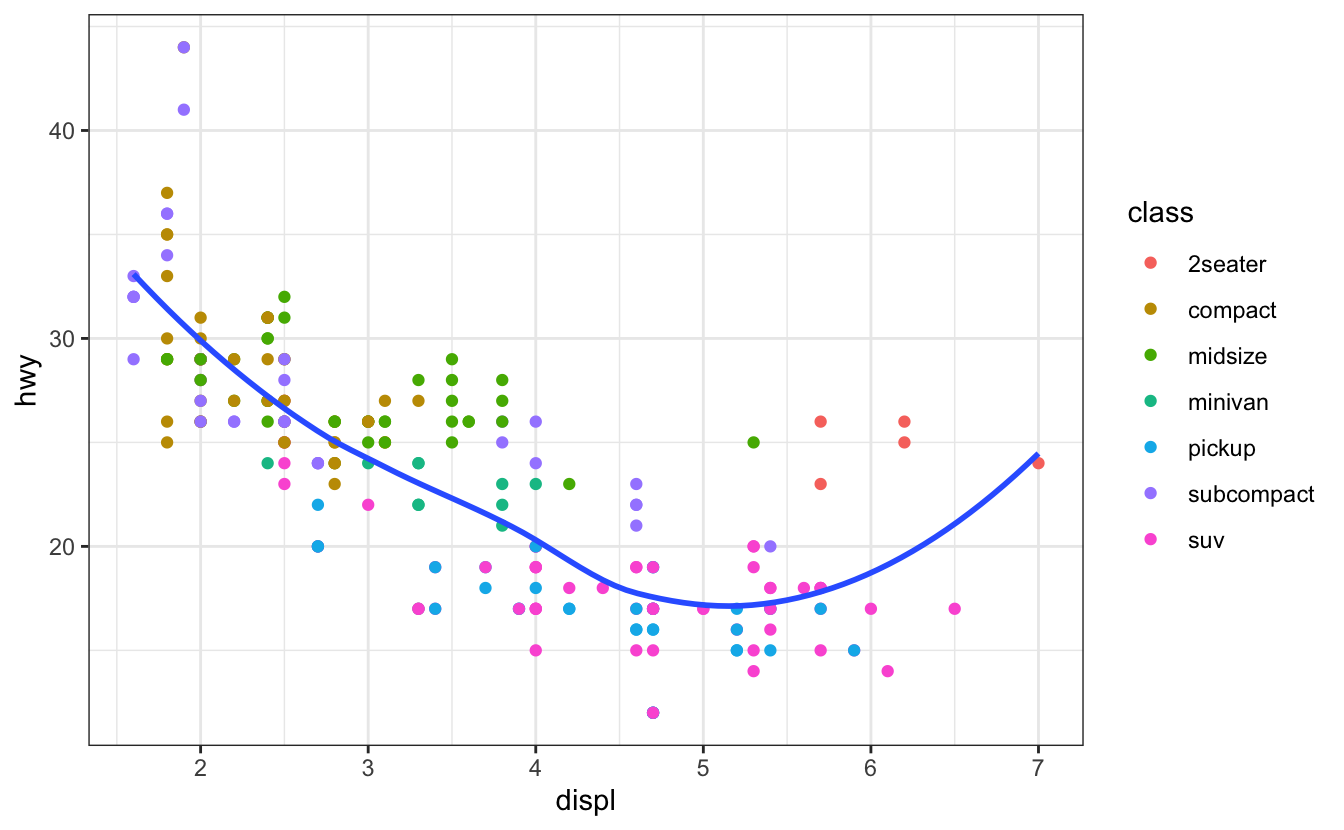
그림 33.3과 같이 ggplot2 는 기본적으로 8개의 테마를 가지고 있다. Jeffrey Arnold 가 만든 ggthemes(https://github.com/jrnold/ggthemes) 와 같은 애드온 패키지에는 더 많은 테마가 포함되어 있다.
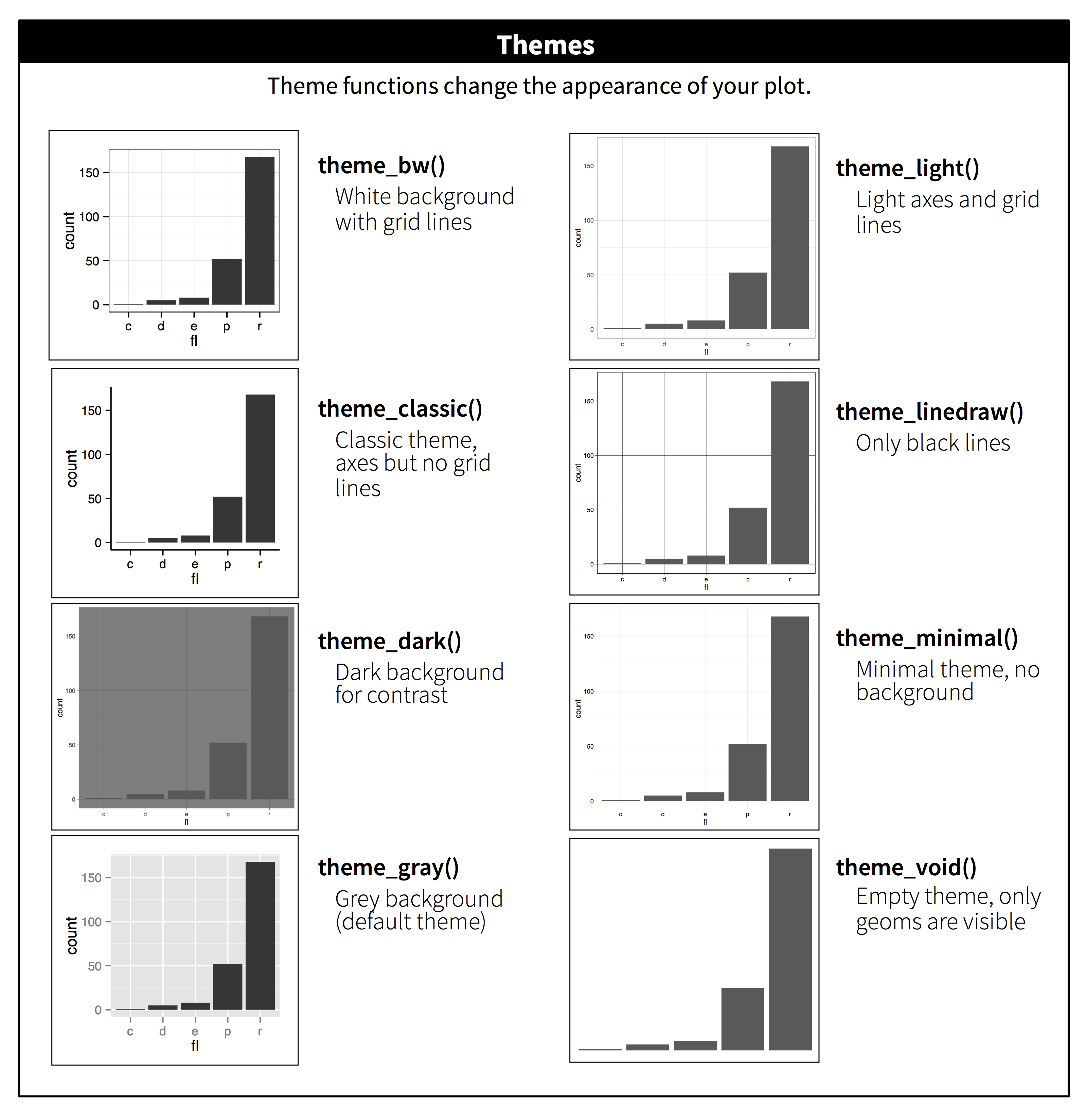
Figure 33.3: The eight themes built-in to ggplot2.
기본 테마의 배경이 회색인 이유를 궁금해 하는 사람들이 많다. 격자선은 표시 되면서 데이터는 앞으로 놓여지기 때문에, 의도적으로 선택한 방법이다. 격자선은 흰색으로 표시되는데, 이는 위치 판단을 크게 도와주기 때문에 중요하다. 하지만 시각적 효과는 거의 없어서 거슬리지 않는다. 회색 바탕을 사용하면 플롯이 텍스트와 유사한 색상을 갖기 때문에 문서의 흐름에 녹아들게 된다. 밝은 흰색 배경에서는 그래프가 튀어나온다. 마지막으로 회색 배경은 이어진 색상 공간을 생성하여 플롯이 하나의 시각적 요소로 인식되게 만든다.
또한 각 테마의 개별 구성요소(예: y축에 쓰인 글꼴의 크기와 색상)를 조정할 수도 있다. 안타깝게도 이와 같은 세부사항은 이 책의 범위를 벗어나므로 ggplot2 책을 읽어봐야 할 것이다. 사내 스타일이나 학술지 스타일을 따르려고 하는 경우, 자신만의 테마를 만들 수도 있다.
33.7 플롯 저장하기
플롯을 R 외부에 최종적으로 저장하는 방법은 크게 두 가지가 있다: ggsave() 와 knitr 이다.
ggsave() 는 가장 최근 플롯을 디스크에 저장합니다:
ggplot(mpg, aes(displ, hwy)) + geom_point()
ggsave("my-plot.pdf")
#> Saving 7 x 4.33 in image너비(width)와 높이(height)를 지정하지 않았다면 현재 플롯 장치의 치수에서 가져올 것이다.
코드가 재현 가능하려면 너비와 높이를 지정하는 것이 좋다.
그러나 일반적으로 최종 보고서를 R 마크다운을 이용하여 조합해야 한다고 생각한다. 따라서 그래프에 관해 알아야 하는 중요한 코드 청크에 대해 집중하고자 한다.
도움말에서 ggsave() 에 대해 찾아볼 수 있다.
33.7.1 그림 크기 조정
R 마크다운 그래프에서 가장 어려운 점은 그림이 올바른 크기와 모양을 갖도록 하는 것이다.
다음은 그림 크기를 조정할 수 있는 다섯 가지 주요 옵션이다: fig. width, fig.height, fig.asp, out.width, out.height.
두 가지의 크기 (R 이 생성한 그림의 크기와 출력문서에 삽입되는 크기)가 있고 이 크기를 지정하는 방법은 여러 개가 있으므로 (즉, 높이, 너비, 가로세로 비율, 이 세 개 중 두 개 선택) 이미지 크기 조정은 쉬운 문제가 아니다.
나는 다섯 가지 옵션 중 세 가지만 사용한다:
플롯의 너비를 일정하게 했더니 미적으로 가장 보기 좋았다. 이렇게 강제하기 위해, 기본값으로
fig.width = 6(6인치)과fig.asp = 0.618(황금율)을 설정한다. 그러고 나서 개별 청크에서fig.asp만 조정한다.out.width로 출력 크기를 조정하고 줄너비에 대한 비율로 설정한다. 기본값으로
out.width = "70%"와fig.align = "center"로 한다. 이렇게 하면 플롯이 너무 많은 공간을 차지하지 않고 여백을 갖도록 한다.하나의 행에 여러 플롯을 넣기 위해서는 두 개의 플롯은
out.width를50%, 세 개는33%, 네 개는25%로 설정하고,fig.align = "default"로 설정하면 된다. 설명하려는 것에 따라(예: 데이터를 보여주기 위한 것인지 아니면 분산을 플롯하기 위한 것인지)fig.width도 다음에서 설명하는 것처럼 조정한다.
플롯에서 텍스트가 잘 안 보이면 fig.width 를 조정해야 한다.
fig.width 가 최종 문서에서 렌더링되는 크기보다 크면 텍스트가 너무 작을 것이고, 반대로 fig. width 가 더 작으면 텍스트가 더 클 것이다.
fig.width 와 문서에서 최종 너비 사이에 올바른 비율을 찾기 위해 실험을 좀 해봐야 한다.
이 원칙을 설명하기 위해 다음 세 플롯의 fig.width 를 각각 4, 6, 8 로 설정했다:
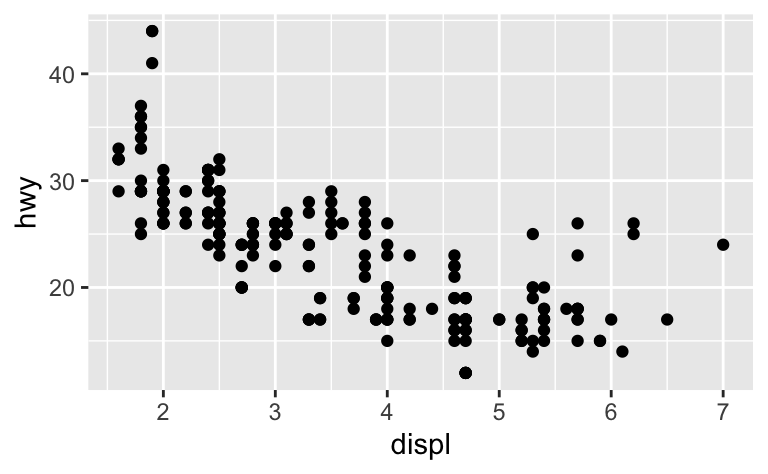
글꼴 크기가 모든 그림에서 일정한지 확인하려면 out.width 를 설정할 때마다 fig.width 를 조정하여 기본 out.width 와 비율이 같도록 해야 한다.
예를 들어 fig. width 가 6이고 out.width 가 0.7이면 out.width = "50%" 로 설정할 때, fig.width 를 4.3 (6 * 0.5 / 0.7)으로 설정해야 한다.
33.7.2 기타 중요한 옵션
이 책에서와 같이 코드와 텍스트가 섞여있을 경우 코드 뒤에 플롯이 표시되도록 fig.show = "hold" 로 설정하는 것이 좋다.
이 설정의 부수효과를 이용하여 코드 블록과 코드 설명을 강제로 나눌 수 있어서 유용하다.
플롯에 캡션을 추가하려면 fig.cap 을 사용하면 된다. R마크다운에서 인라인 그림으로부터 “떠다니는” 그림으로 바뀌게 된다.
PDF 출력을 생성하는 경우 기본 그래픽 유형은 PDF이다.
PDF 는 고품질 벡터 그래픽이기 때문에, 이 유형은 기본값으로 적절하다.
하지만 수천 개의 점을 표시하는 경우 PDF 는 플롯들이 매우크고 느릴 수있다.
이 경우에는 dev = "png" 로 설정하여 PNG 를 사용하라.
PNG 는 약간 저품질이지만 훨씬 컴팩트하다.
보통 청크에 라벨을 붙이지 않는 사람도 그림을 생성하는 코드 청크에는 이름을 붙이는 것이 좋다. 이 청크 라벨은 디스크에 그래프 파일 이름을 생성하는 데 사용되므로 청크 이름을 붙이면 플롯을 선택하여 다른 환경 (예: 이메일이나 트위터에 플롯을 첨부하고 싶은 경우)에서 재사용하기가 훨씬 쉬워진다.
33.8 더 배우기
좀 더 자세한 내용을 배우려면 ggplot2 책인 ggplot2: Elegant graphics for data analysis 를 보는 것이 가장 좋다. 이 책은 기본 이론에 대해 훨씬 깊이 들어가고, 개별 요소를 결합하여 어떻게 실제적인 문제를 해결하는지에 대한 예제가 많이 포함되어 있다. 안타깝게도 이 책은 온라인에서 무료로 볼 수 없지만 다음에서 소스 코드를 구할 수 있다. https://github.com/hadley/ggplot2-book
다른 훌륭한 자료는 ggplot2 확장 갤러리http://www.ggplot2-exts.org/이다. 이 사이트에서는 새로운 지옴 과 스케일로 ggplot2를 확장한 패키지들의 목록을 볼 수 있다. ggplot2 로 원하는 것이 잘 되지 않으면 찾아볼 수 있는 곳이다.