1 서문
데이터 과학은 원데이터(raw data)로부터 이해와 통찰과 지식을 찾아내는 재미있는 분야이다. 이 책은 R 에 있는 도구들을 배워 데이터 과학 작업을 할 수 있도록 도와준다. 이 책을 읽은 후에는 데이터 과학 문제를 해결할 수 있는 도구를 손에 넣게 된다.
1.1 무엇을 배우게 될까
데이터 과학은 광대한 분야이기 때문에, 단 한 권의 책을 읽어서 통달할 수는 없다. 이 책의 목표는 주요 도구를 사용할 수 있게 기초를 튼튼히 다지는 것이다. 일반적인 데이터 과학 프로젝트에 필요한 도구를 도식화해 보면 대략 다음과 같다.
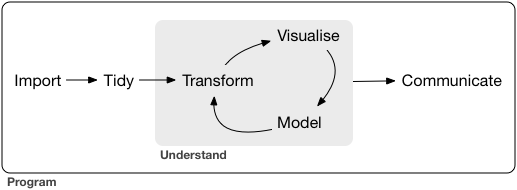
먼저 데이터를 R로 불러와야(import) 한다. 이는 일반적으로 파일, 데이터베이스 또는 웹 API에 저장된 데이터를 가져와서 R의 데이터프레임으로 로드하는 것을 말한다. R로 가져올 수 없는 데이터가 있다면 그 데이터로는 데이터 과학 작업을 할 수 없다!
데이터를 가져온 후에는 타이디하게(tidy) 만드는 것이 좋다. 타이디하게 한다는 것은, 데이터셋이 의미하는 바와 저장된 방식이 일치하도록 일관된 형식으로 저장한다는 의미이다. 간단히 말해, 데이터가 타이디하다면 각 열은 변수이고 각 행은 관측값이 된다. 타이디한 데이터는 중요하다. 왜냐하면 데이터 구조가 이렇게 일관되면 여러 함수에 적합한 형태로 만드느라 애쓸 필요 없이, 데이터에 대한 문제에 노력을 쏟을 수 있기 때문이다.
타이디한 데이터를 얻었다면 첫 번째 단계는 데이터를 변형(transform)하는 것이다. 관심 있는 관측값의 범위를 좁히고(예, 어떤 도시의 모든 사람, 또는 작년부터 모든 데이터), 기존 변수의 함수꼴인 새로운 변수를 작성하고(예, 거리와 시간으로부터 속도를 계산), 요약 통계량들(예, 빈도나 평균) 을 계산하는 것 등이 데이터 변환에 속한다. 데이터 정리와 데이터 변형을 묶어서 데이터를 길들인다(wrangling)고 부르는데, 작업하기에 자연스러운 형태로 데이터를 만드는 것이 종종 싸움처럼 느껴지기 때문이다!
필요한 변수들이 있는 타이디 데이터가 되었다면 이제 시각화와 모델링이라는 두 가지 도구를 사용하여 지식을 생성할 수 있다. 이 둘에는 상호보완적인 강점과 약점이 있기 때문에, 실제 분석에서는 여러 번 번갈아 사용된다.
시각화는 근본적으로 인간의 활동이다. 좋은 시각화는 예상치 못한 것을 보여주거나, 주어진 데이터에 대해 새로운 문제를 제기한다. 또한 좋은 시각화는 현재 탐구하고 있는 문제가 잘못되었다거나, 다른 데이터를 수집할 필요가 있다는 것을 알려주기도 한다. 시각화는 여러분을 놀라게 할 수 있지만, 인간이 해석해야 하기 때문에 확장 적용(scale)이 아주 잘 되지는 않는다.
데이터 과학의 마지막 단계는 데이터 분석 프로젝트에서 절대적으로 중요한 부분인 의사소통이다. 결과 내용을 다른 사람들에게 전달할 수 없다면 여러분이 모델과 시각화를 통해 데이터를 얼마나 잘 이해하게 되었는지는 중요하지 않다.
이 모든 도구를 둘러싸고 있는 것이 프로그래밍이다. 프로그래밍은 프로젝트의 모든 부분에서 사용되는 다용도 도구이다. 데이터 과학자가 되기 위해 전문 프로그래머가 될 필요는 없지만, 더 나은 프로그래머가 되면 반복 작업을 자동화하고 새로운 문제를 좀 더 쉽게 해결할 수 있다는 점에서 프로그래밍에 대해 배우면 언제나 도움이 된다.
모든 데이터과학 프로젝트에서 이 도구들을 사용하겠지만, 대부분의 프로젝트에서 이것들만으로는 충분하지 않다. 실무에서는 대략 80-20 규칙이 있다. 모든 프로젝트의 80% 정도는 이 책에서 배울 도구들을 사용해서 해결할 수 있지만, 남은 20%를 처리하려면 다른 도구가 필요하다. 이 책을 따라가다 보면 더 배울 수 있는 곳들을 안내 받을 수 있다.
1.2 이 책의 구성
앞에서는 데이터과학 도구들을 분석에서 사용되는 대략의 순서대로 (물론 도구들을 여러 번 반복하겠지만) 구성하여 설명했다. 그러나 우리의 경험에 비추어 볼 때, 이것이 최선의 방법은 아니다. 왜냐하면 데이터 수집과 정리부터 시작하는 것은 차선책이고, 80%의 시간은 지루하고, 나머지 20%는 어색하고 힘들기 때문이다. 새로운 주제를 배우는 시작점으로는 좋지 않다! 대신 이미 불러와서 정리된 데이터의 시각화 및 변환부터 시작하겠다. 그렇게 하면 여러분이 직접 데이터를 밀어 넣고 정리할 때, 이 작업들이 힘들지만 가치 있다는 것을 알기 때문에, 동기를 잃지 않을 것이다.
이 책에선 각 장에서 다음의 패턴을 가능한 한 사용하려고 한다. 동기 부여하는 예제로 시작해서 보다 큰 그림을 볼 수 있도록 한 다음, 세부 사항으로 들어간다. 이 책의 각 절마다 학습한 내용을 실습할 수 있는 연습 문제가 있다. 연습 문제를 건너 뛰고 싶겠지만, 실제 문제로 실습하는 것보다 더 좋은 학습 방법은 없다.
1.3 배우지 않는 것
이 책에서 다루지 않는 중요한 주제가 몇몇 있다. 우리는 독자들이 가능한 한 빨리 일어서서 달릴 수 있게, 꼭 필요한 내용에만 철저하게 집중하는 것이 중요하다고 믿는다. 즉, 중요한 주제 모두를 이 책에서 다룰 수는 없다.
1.3.2 빅데이터
이 책은 ‘자랑스럽게도’ 스몰, 인메모리(in-memory) 데이터셋에 초점을 맞추고 있다. 스몰데이터를 다루어 본 경험이 없으면 빅데이터도 처리할 수 없기 때문에, 스몰데이터부터 시작하는 것이 바람직하다. 이 책에서 배우는 도구를 사용해서 수백 메가 바이트의 데이터를 쉽게 처리 할 수 있으며, 조금만 신경을 쓰면 일반적으로 1-2Gb 데이터까지 작업할 수 있다. 더 큰 데이터(말하자면 10- 100Gb) 를 일상적으로 사용한다면 data.table에 대해 자세하게 알아야 한다. 이 책에서는 data.table 을 배우지 않는다. 왜냐하면 data.table은 아주 간결한 인터페이스로 인해 인간언어를 더 적게 사용하여, 배우기가 더 어렵기 때문이다. 그러나 대용량 데이터 작업하는 경우에는, 따로 더 노력하여 data.table 을 익히면 성능향상을 얻을 수 있다.
데이터가 이보다 더 크다면 이 빅데이터 문제가, 실제로는 스몰데이터 문제가 둔갑한 것인지 신중하게 생각해보라. 전체 데이터는 클 수도 있지만, 특정 문제에 답을 얻는 데 필요한 데이터는 작은 경우가 많다. 관심있는 문제를 풀기 위해서는, 메모리에 들어가는 데이터셋 일부, 샘플 일부 또는 요약값만 사용해도 충분할 수 있다. 여기에서의 어려운 점은 적절한 스몰데이터를 찾는 것인데, 이는 수많이 반복해야 하는 경우가 많다.
빅데이터 문제가 실제로 많은 수의 스몰데이터 문제인 경우도 있다. 각각의 개별적인 문제는 메모리에 들어갈 지 모르지만 이런 문제가 수백만 개인 경우이다. 예를 들어 데이터셋의 각 사람에게 모델을 적합하고자 할 수 있다. 만약 10명이나 100명이 있다면 문제되지 않겠지만, 대신에 백만 명이 있는 경우이다. 다행스럽게도 각 문제는 다른 것들과 독립적이다 (이런 상황을 때로는 부끄러운 병렬(embarrasingly parallel)이라고도 함). 그래서 처리를 위해 다른 컴퓨터에 다른 데이터셋을 보낼 수 있는 하둡이나 스파크 같은 시스템이 필요하다. 이 책에서 설명하는 도구를 사용하여 subset 에 대한 문제에 대답하는 방법을 파악한 후, sparklyr, rhipe, ddr 과 같은 새로운 도구를 통해 전체 데이터셋에 대해 해결할 수 있다.
1.3.3 Python, Julia
이 책에서는 파이썬(Python), 줄리아(Julia) 또는 데이터 과학에 유용한 어떤 프로그래밍 언어에 대해서도 배우지 않는다. 이 도구가 좋지 않기 때문이 아니다. 이들은 훌륭하다! 실제로, 대부분의 데이터 과학팀은 종종 R과 파이썬을 포함한 언어들을 혼합하여 사용한다.
하지만 한 번에 하나의 도구를 완전히 학습하는 것이 확실히 가장 좋다. 많은 주제를 넓고 얕게 살펴보기다는 깊게 파면 더 빨리 할 수 있을 것이다. 한 가지만 알면 된다는 말이 아니라, 한 번에 한 가지에 몰두하면 빨리 배우게 된다는 의미이다. 여러분은 경력과정에서 새로운 것을 배우려고 노력해야하지만, 재미있는 것으로 넘어가기 전에 확실히 이해했는지 확인하는 것이 좋다.
R 은 처음부터 데이터 과학을 지원하도록 설계된 환경이기 때문에 여기에서부터 데이터과학 여정을 시작하는 것이 좋다고 생각한다. R 은 프로그래밍 언어일 뿐만 아니라 데이터 과학을 수행하는 대화식 환경이기도 하다. R 은 상호작용을 지원하는데 있어서 다른 것들보다 훨씬 유연하다. 이러한 유연성은 단점이 따라오지만 큰 장점은 데이터 과학 과정의 특정 부분에 맞게 맞춤형 문법을 쉽게 전개할 수 있다는 것이다. 이 미니 언어는 두뇌와 컴퓨터 간의 상호작용을 유창하게 지원하여, 문제에 대해 데이터 과학자로서 사고하게 도와준다.
1.4 준비하기
이 책에서는 여러분이 이미 몇 가지를 알고 있다고 가정을 했다. 독자는 일반적으로 수학을 알고 있을 것이다. 이미 프로그래밍 경험이 있다면 도움이 된다. 이전에 프로그래밍을 해본 적이 없다면 개럿의 Hands on Programming with R 책이 유용한 보조책이 될 것이다.
이 책에 나오는 코드를 실행하는 데는 네 가지가 필요하다. R, RStudio, tidyverse라 불리는 R 패키지 모음, 그리고 다른 패키지들이다. 패키지는 재현 가능한 R 코드의 기초 단위이다. 재사용 가능한 함수, 사용법을 설명하는 문서, 그리고 샘플 데이터가 패키지에 포함된다.
1.4.1 R
R 을 다운로드하려면 CRAN (comprehensive R archive network) 로 가면 된다. CRAN은 전세계에 분산되어 있는 미러 서버의 집합으로 구성되어 있으며, R 및 R 패키지를 배포하는 데 사용된다. 가장 가까운 미러를 선택하지 말고 자동으로 미러를 찾아주는 클라우드 미러https://cloud.r-project.org를 사용하라.
새로운 메이저 버전의 R 은 일 년에 한 번 나오고, 매년 2-3 번의 마이너 릴리스가 있다. 정기적으로 업데이트하는 것이 좋다. 업그레이드는 약간 번거롭다. 메이저 버전의 경우 특히 더 그러한데 모든 패키지를 재설치해야 하기 때문이다. 하지만 그렇다고 미루면 업그레이드가 더 어려워질 뿐이다. 이 책에서는 R 4.1.0 이상 버전이 필요하다.
1.4.2 RStudio
RStudio는 R 프로그래밍을 위한, 통합개발환경(integrated development environment), 줄여서 IDE이다. http://www.rstudio.com/download에서 다운로드하여 설치하라. RStudio는 1 년에 두어 번 업데이트 된다. 새 버전이 있으면 RStudio가 알려준다. 최신의 강력한 기능을 활용할 수 있도록 정기적으로 업그레이드하는 것이 좋다. 이 책에서는 최소한 RStudio 1.6.0 이 필요하다.
RStudio를 시작하면 인터페이스에 두 개의 주요 영역이 보일 것이다.
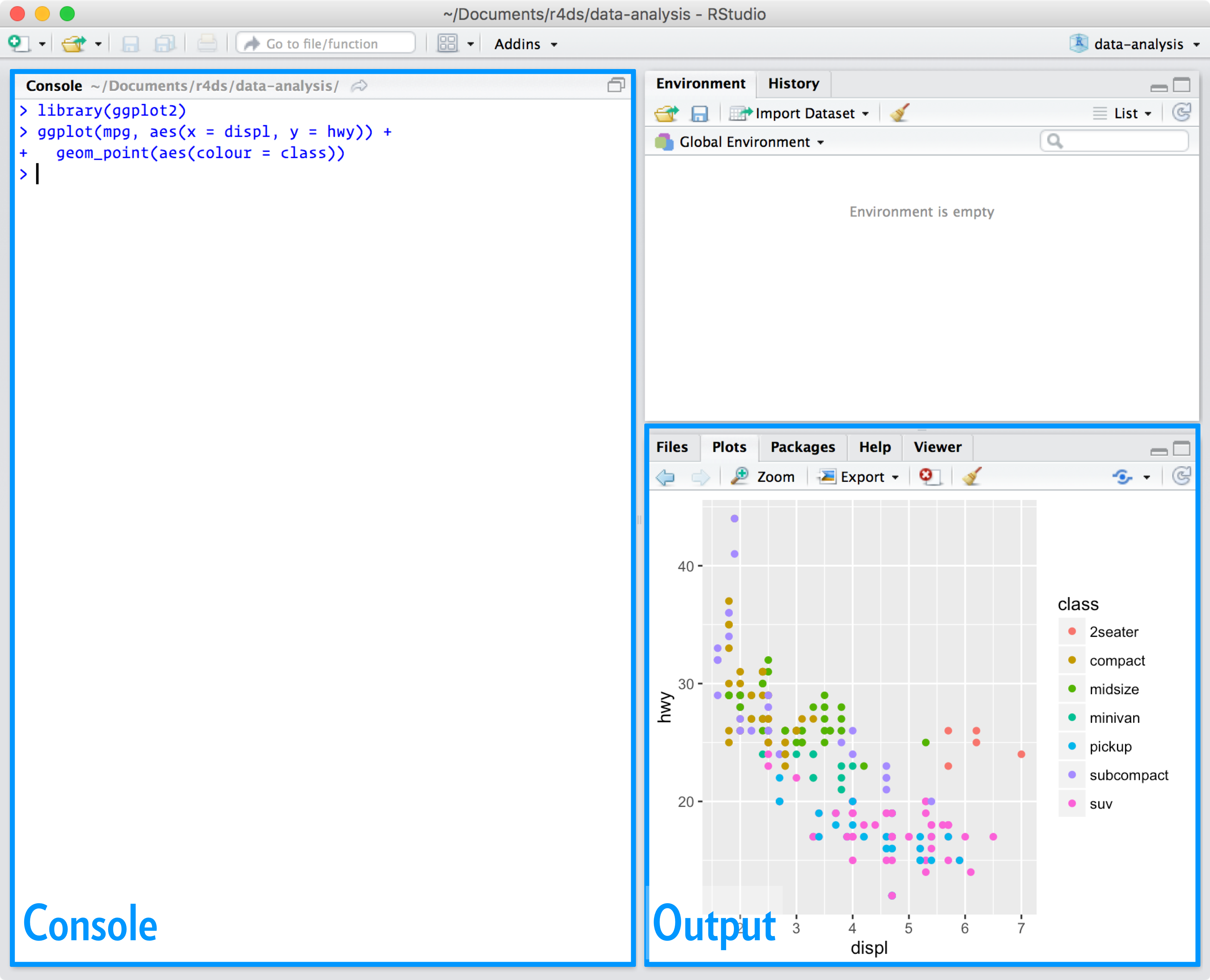
지금은 콘솔 창에 R 코드를 입력하고 엔터 키를 눌러 실행시키는 것만 알면 된다. 앞으로 더 배우게 될 것이다!
1.4.3 Tidyverse
R 패키지 몇 개도 설치해야 한다. R 패키지 란 베이스 R 의 기능을 확장시키는 함수, 데이터, 문서의 집합체를 말한다. R 을 성공적으로 사용하려면 패키지 사용이 핵심이다. 이 책에서 배우게 될 패키지의 대부분은 소위 tidyverse 라고 하는 패키지집합에 들어있다. tidyverse 의 패키지들은 데이터 및 R 프로그래밍에 관해 같은 철학에 기반하고 있으며, 자연스럽게 함께 작동되도록 설계되었다.
다음 한 줄의 코드로 tidyverse 를 설치할 수 있다.
install.packages("tidyverse")자신의 컴퓨터에서 콘솔에 해당 코드를 입력한 다음 엔터 키를 눌러 실행하라. R 이 CRAN에서 패키지들을 다운로드해서 여러분의 컴퓨터에 설치한다. 설치에 문제가 있으면 인터넷에 연결되어 있는지, 방화벽이나 프록시에 의해 https://cloud.r-project.org/가 차단되어 있지 않은지 확인하라.
library()를 사용하여 패키지를 로드하기 전에는, 해당 패키지의 함수, 객체 및 도움말 파일을 사용할 수 없다. 패키지를 설치하면 library() 함수를 사용하여 로드할 수 있다.
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
#> ✓ ggplot2 3.3.5 ✓ purrr 0.3.4
#> ✓ tibble 3.1.6 ✓ dplyr 1.0.7
#> ✓ tidyr 1.1.4 ✓ stringr 1.4.0
#> ✓ readr 2.1.0 ✓ forcats 0.5.1
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> x dplyr::filter() masks stats::filter()
#> x dplyr::lag() masks stats::lag()이것은 tidyverse 가 ggplot2, tibble, tidyr, readr, purrr, dplyr 패키지를 로드하고 있음을 나타낸다. 이 패키지들은 거의 모든 분석에서 사용될 것이기 때문에 tidyverse 의 코어 라 할 수 있다.
tidyverse 의 패키지는 상당히 자주 변경된다. tidyverse_update()를 실행하여 업데이트가 가능한지 확인할 수 있다.
1.4.4 기타 패키지들
많은 훌륭한 패키지가 도메인이 다르거나 설계된 원칙이 달라서 tidyverse 에 포함되지 않았다. 그 패키지들은 더 좋거나 나쁜 것이 아니라 단순히 다른 것뿐이다. 다른 말로 표현하자면 tidyverse 가 아닌 패키지는 messyverse(지저분한 패키지)가 아니라 엄청나게 많은 서로 연관된 패키지들이다. R로 더 많은 데이터과학 프로젝트를 수행하면 새로운 패키지와 데이터에 대한 새로운 사고 방식을 배우게 될 것이다. 이 책에서 우리는 tidyverse에 없는 다음의 데이터 패키지 세 개를 사용할 것이다.
install.packages(c("nycflights13", "gapminder", "Lahman"))이 패키지들은 각각 항공기, 세계개발, 야구에 대한 데이터를 제공한다. 이를 이용하여 데이터과학 아이디어를 설명하겠다.
1.5 R 코드 실행하기
이전 절에서 R 코드를 실행하는 몇 가지 예를 보았다. 책의 코드는 다음과 같다.
1 + 2
#> [1] 3로컬 콘솔에서 동일한 코드를 실행하면 다음과 같이 표시된다.
> 1 + 2
[1] 3두 가지 주요 차이점이 있다. 콘솔에서 자판입력은 프롬프트이탤릭>라고 부르는 > 뒤에 한다. 이 책에서는 프롬프트를 표시하지 않는다. 이 책에서 출력은 #>로 주석 처리한다. 콘솔에서 출력은 코드 바로 뒤에 나타난다. 전자책 버전으로 작업하는 경우, 이 점 때문에, 코드를 책에서 콘솔로 쉽게 복사할 수 있다.
이 책 전체에서 우리는 코드를 참조하기 위해 일관된 규칙을 사용한다.
다른 R 객체(예: 데이터 또는 함수 인수)는 코드 글꼴로 되어 있으며
flights혹은x와 같이 코드 글꼴로 괄호 없이 나타낸다.객체가 어떤 패키지로부터 온 것인지를 보여주고자 할 때는,
dplyr::mutate(), 혹은nycflights13::flights처럼 패키지 이름과 그 뒤 두 개의 콜론을 사용한다. 이것도 유효한 R 코드이다.
1.6 도움받기, 더 배우기
이 책은 외딴 섬이 아니다. 단 하나의 자료로 R 을 완전히 습득할 수는 없다. 이 책에서 설명한 기술을 자신의 데이터에 적용하기 시작할 때, 답을 찾을 수 없는 문제가 곧 나타날 것이다. 이 절에서는 도움을 얻고 학습을 돕는 방법에 대한 몇 가지 팁을 설명한다.
문제가 발생하면 구글 검색부터 시작하라. 일반적으로 검색어에 ‘R’ 을 추가하면 관련된 결과로 한정할 수 있다. 검색이 유용하지 않은 경우 R에 해당하는 결과가 없다는 의미일 경우가 많다. 구글은 오류 메시지에 특히 유용하다. 오류 메시지가 나타나서 그것이 무슨 뜻인지 잘 모를 경우 구글 검색해 보라! 과거에 이미 궁금해했을 누군가가 있어서, 웹 어딘가에 도움글이 있을 가능성이 있다. (오류 메시지가 영어가 아니라면 >Sys.setenv(LANGUAGE = "en")를 실행하고 코드를 다시 실행하라. 영어 오류 메시지에 대한 도움말을 찾을 가능성이 더 높다.)
구글 검색이 도움이 되지 않으면 stackoverflow에 가 보라. 기존 답변을 검색하는 데 시간을 조금 투자해 보라. [R]을 포함하면 R 사용과 관련된 질문과 답변으로 검색을 제한한다. 유용한 정보가 없으면 최소한의 재현 가능한 예 (reproducible example, 줄임말로 reprex) 를 준비하라. 좋은 reprex는 다른 사람들이 여러분을 도울 수 있게 해 주며, 이를 만드는 과정에서 문제의 답을 스스로 찾는 경우가 많다.
예제를 재현 가능하게 만들기 위해 포함해야 할 세 가지는 필요한 패키지, 데이터, 코드이다.
패키지는 스크립트 맨 위에 로드해야 어떤 패키지가 예제에 필요한지 쉽게 볼 수 있다. 각 패키지의 최신 버전을 사용하고 있는지 확인해 보자. 즉, 발견한 버그가 패키지 설치 이후 이미 해결되었을 가능성이 있다. tidyverse 에 있는 패키지의 경우
tidyverse_update()를 실행하는 것이 가장 쉬운 방법이다.-
질문에 데이터를 포함시키는 가장 쉬운 방법은
dput()을 사용하여 재현되는 R 코드를 생성하는 것이다. 예를 들어, R에서mtcars데이터셋을 다시 만들려면 다음 단계로 수행하라.- R 에서
dput(mtcars)를 실행한다.
- 출력을 복사한다.
- 재현가능한 스크립트에서,
mtcars <-를 입력하고 붙여 넣는다.
동일한 문제가 나타나는 데이터의 가장 작은 서브셋을 찾아보라.
- R 에서
-
다른 사람들이 코드를 쉽게 읽을 수 있도록 시간을 조금 투자하라.
공백을 사용했는지 변수 이름은 간결하지만 정보성이 있는지 확인하라.
주석을 사용하여 문제점이 있는 곳을 표시하라.
문제와 관련 없는 것은 모두 제거하라. 코드가 짧을수록 이해하기 쉽고 수정하기가 쉽다.
새로운 R 세션을 시작하고 스크립트를 복사-붙여넣기하여 실제로 재현할 수 있는 예제를 만들었는지 확인하는 것으로 마무리하라.
문제가 발생하기 전에 문제를 해결할 수 있게 스스로 준비시키는데 시간을 써야 한다. 매일 R 을 배우는 데 약간의 시간을 투자하면 결국에는 보상받을 것이다. 한 가지 방법은 RStudio 의 해들리, 개럿 및 다른 모든 사람들이 RStudio 블로그에서 수행하는 작업을 팔로우하는 것이다. RStudio 블로그는 우리가 새로운 패키지, 새로운 IDE 기능 및 직접 진행하는 수업에 대한 공지 사항을 게시하는 곳이다. 트위터에서 해들리 @hadleywickham 또는 개럿 @statgarrett 을 팔로우하거나 @rstudiotips 를 팔로우해서 IDE 의 새로운 기능을 계속 전달받을 수 있다.
R 커뮤니티를 보다 폭넓게 소통하기 위해서는 http://www.r-bloggers.com 을 읽는 것이 좋은데 여기에는 전세계로부터 R 에 대한 500개 이상의 블로그가 모여있다. 트위터 유저인 경우 #rstats 해시 태그를 팔로우하라. 트위터는 해들리가 커뮤니티의 새로운 발전을 따라가기 위해 사용하는 핵심 도구이다.
1.7 Acknowledgements
This book isn’t just the product of Hadley and Garrett, but is the result of many conversations (in person and online) that we’ve had with the many people in the R community. There are a few people we’d like to thank in particular, because they have spent many hours answering our dumb questions and helping us to better think about data science:
Jenny Bryan and Lionel Henry for many helpful discussions around working with lists and list-columns.
The three chapters on workflow were adapted (with permission), from http://stat545.com/block002_hello-r-workspace-wd-project.html by Jenny Bryan.
Genevera Allen for discussions about models, modelling, the statistical learning perspective, and the difference between hypothesis generation and hypothesis confirmation.
Yihui Xie for his work on the package, and for tirelessly responding to my feature requests.
Bill Behrman for his thoughtful reading of the entire book, and for trying it out with his data science class at Stanford.
The #rstats twitter community who reviewed all of the draft chapters and provided tons of useful feedback.
Tal Galili for augmenting his dendextend package to support a section on clustering that did not make it into the final draft.
1.8 Colophon
An online version of this book is available at http://r4ds.had.co.nz. It will continue to evolve in between reprints of the physical book. The source of the book is available at https://github.com/hadley/r4ds. The book is powered by https://bookdown.org which makes it easy to turn R markdown files into HTML, PDF, and EPUB.
This book was built with:
devtools::session_info(c("tidyverse"))
#> ─ Session info 🚭 🛸 🕝 ─────────────────────────────────────────────────
#> hash: no smoking, flying saucer, two-thirty
#>
#> setting value
#> version R version 4.1.1 (2021-08-10)
#> os macOS Big Sur 10.16
#> system x86_64, darwin17.0
#> ui X11
#> language (EN)
#> collate en_US.UTF-8
#> ctype en_US.UTF-8
#> tz Asia/Seoul
#> date 2021-12-04
#> pandoc 2.11.4 @ /Applications/RStudio.app/Contents/MacOS/pandoc/ (via rmarkdown)
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> askpass 1.1 2019-01-13 [1] CRAN (R 4.1.0)
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.1.0)
#> backports 1.4.0 2021-11-23 [1] CRAN (R 4.1.0)
#> base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.1.0)
#> bit 4.0.4 2020-08-04 [1] CRAN (R 4.1.0)
#> bit64 4.0.5 2020-08-30 [1] CRAN (R 4.1.0)
#> blob 1.2.2 2021-07-23 [1] CRAN (R 4.1.0)
#> broom 0.7.10 2021-10-31 [1] CRAN (R 4.1.0)
#> callr 3.7.0 2021-04-20 [1] CRAN (R 4.1.0)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.1.0)
#> cli 3.1.0 2021-10-27 [1] CRAN (R 4.1.0)
#> clipr 0.7.1 2020-10-08 [1] CRAN (R 4.1.0)
#> colorspace 2.0-2 2021-06-24 [1] CRAN (R 4.1.0)
#> cpp11 0.4.2 2021-11-30 [1] CRAN (R 4.1.1)
#> crayon 1.4.2 2021-10-29 [1] CRAN (R 4.1.0)
#> curl 4.3.2 2021-06-23 [1] CRAN (R 4.1.0)
#> data.table 1.14.2 2021-09-27 [1] CRAN (R 4.1.0)
#> DBI 1.1.1 2021-01-15 [1] CRAN (R 4.1.0)
#> dbplyr 2.1.1 2021-04-06 [1] CRAN (R 4.1.0)
#> digest 0.6.29 2021-12-01 [1] CRAN (R 4.1.1)
#> dplyr * 1.0.7 2021-06-18 [1] CRAN (R 4.1.0)
#> dtplyr 1.1.0 2021-02-20 [1] CRAN (R 4.1.0)
#> ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.1.0)
#> evaluate 0.14 2019-05-28 [1] CRAN (R 4.1.0)
#> fansi 0.5.0 2021-05-25 [1] CRAN (R 4.1.0)
#> farver 2.1.0 2021-02-28 [1] CRAN (R 4.1.0)
#> fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.1.0)
#> forcats * 0.5.1 2021-01-27 [1] CRAN (R 4.1.0)
#> fs 1.5.0 2020-07-31 [1] CRAN (R 4.1.0)
#> gargle 1.2.0 2021-07-02 [1] CRAN (R 4.1.0)
#> generics 0.1.1 2021-10-25 [1] CRAN (R 4.1.0)
#> ggplot2 * 3.3.5 2021-06-25 [1] CRAN (R 4.1.0)
#> glue 1.5.1 2021-11-30 [1] CRAN (R 4.1.1)
#> googledrive 2.0.0 2021-07-08 [1] CRAN (R 4.1.0)
#> googlesheets4 1.0.0 2021-07-21 [1] CRAN (R 4.1.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.1.0)
#> haven 2.4.3 2021-08-04 [1] CRAN (R 4.1.0)
#> highr 0.9 2021-04-16 [1] CRAN (R 4.1.0)
#> hms 1.1.1 2021-09-26 [1] CRAN (R 4.1.0)
#> htmltools 0.5.2 2021-08-25 [1] CRAN (R 4.1.0)
#> httr 1.4.2 2020-07-20 [1] CRAN (R 4.1.0)
#> ids 1.0.1 2017-05-31 [1] CRAN (R 4.1.0)
#> isoband 0.2.5 2021-07-13 [1] CRAN (R 4.1.0)
#> jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.1.0)
#> jsonlite 1.7.2 2020-12-09 [1] CRAN (R 4.1.0)
#> knitr 1.36 2021-09-29 [1] CRAN (R 4.1.0)
#> labeling 0.4.2 2020-10-20 [1] CRAN (R 4.1.0)
#> lattice 0.20-44 2021-05-02 [1] CRAN (R 4.1.1)
#> lifecycle 1.0.1 2021-09-24 [1] CRAN (R 4.1.0)
#> lubridate 1.8.0 2021-10-07 [1] CRAN (R 4.1.0)
#> magrittr 2.0.1 2020-11-17 [1] CRAN (R 4.1.0)
#> MASS 7.3-54 2021-05-03 [1] CRAN (R 4.1.1)
#> Matrix 1.3-4 2021-06-01 [1] CRAN (R 4.1.1)
#> mgcv 1.8-36 2021-06-01 [1] CRAN (R 4.1.1)
#> mime 0.12 2021-09-28 [1] CRAN (R 4.1.0)
#> modelr 0.1.8 2020-05-19 [1] CRAN (R 4.1.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.1.0)
#> nlme 3.1-152 2021-02-04 [1] CRAN (R 4.1.1)
#> openssl 1.4.5 2021-09-02 [1] CRAN (R 4.1.0)
#> pillar 1.6.4 2021-10-18 [1] CRAN (R 4.1.0)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.1.0)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.1.0)
#> processx 3.5.2 2021-04-30 [1] CRAN (R 4.1.0)
#> progress 1.2.2 2019-05-16 [1] CRAN (R 4.1.0)
#> ps 1.6.0 2021-02-28 [1] CRAN (R 4.1.0)
#> purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.1.0)
#> R6 2.5.1 2021-08-19 [1] CRAN (R 4.1.0)
#> rappdirs 0.3.3 2021-01-31 [1] CRAN (R 4.1.0)
#> RColorBrewer 1.1-2 2014-12-07 [1] CRAN (R 4.1.0)
#> Rcpp 1.0.7 2021-07-07 [1] CRAN (R 4.1.0)
#> readr * 2.1.0 2021-11-11 [1] CRAN (R 4.1.0)
#> readxl 1.3.1 2019-03-13 [1] CRAN (R 4.1.0)
#> rematch 1.0.1 2016-04-21 [1] CRAN (R 4.1.0)
#> rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.1.0)
#> reprex 2.0.1 2021-08-05 [1] CRAN (R 4.1.0)
#> rlang 0.4.12 2021-10-18 [1] CRAN (R 4.1.0)
#> rmarkdown 2.11 2021-09-14 [1] CRAN (R 4.1.0)
#> rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.1.0)
#> rvest 1.0.2 2021-10-16 [1] CRAN (R 4.1.0)
#> scales 1.1.1 2020-05-11 [1] CRAN (R 4.1.0)
#> selectr 0.4-2 2019-11-20 [1] CRAN (R 4.1.0)
#> stringi 1.7.5 2021-10-04 [1] CRAN (R 4.1.0)
#> stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.1.0)
#> sys 3.4 2020-07-23 [1] CRAN (R 4.1.0)
#> tibble * 3.1.6 2021-11-07 [1] CRAN (R 4.1.0)
#> tidyr * 1.1.4 2021-09-27 [1] CRAN (R 4.1.0)
#> tidyselect 1.1.1 2021-04-30 [1] CRAN (R 4.1.0)
#> tidyverse * 1.3.1 2021-04-15 [1] CRAN (R 4.1.0)
#> tinytex 0.35 2021-11-04 [1] CRAN (R 4.1.0)
#> tzdb 0.2.0 2021-10-27 [1] CRAN (R 4.1.0)
#> utf8 1.2.2 2021-07-24 [1] CRAN (R 4.1.0)
#> uuid 1.0-3 2021-11-01 [1] CRAN (R 4.1.0)
#> vctrs 0.3.8 2021-04-29 [1] CRAN (R 4.1.0)
#> viridisLite 0.4.0 2021-04-13 [1] CRAN (R 4.1.0)
#> vroom 1.5.6 2021-11-10 [1] CRAN (R 4.1.0)
#> withr 2.4.3 2021-11-30 [1] CRAN (R 4.1.1)
#> xfun 0.28 2021-11-04 [1] CRAN (R 4.1.0)
#> xml2 1.3.2 2020-04-23 [1] CRAN (R 4.1.0)
#> yaml 2.2.1 2020-02-01 [1] CRAN (R 4.1.0)
#>
#> [1] /Library/Frameworks/R.framework/Versions/4.1/Resources/library
#>
#> ──────────────────────────────────────────────────────────────────────────────