9 Basic: subsetting
subsetting 是把想要的部分取出来,方便后续操作。在 R 中,subsetting 就是取指定 object 的一部分 elements 出来。Subsetting 恐怕是 R 中最常用的操作之一了,需熟练掌握。
9.1 What is element
在 R 中,一般会把 object 中存储的信息视作是数据,通常会将 element 视作是数据中的最小单位,但这个理解在不同的 structure types 中有所不同。
vector, matrix, array, factor 类型的 object 中 element 指的是 object 内容上的单个记录。例如:
m1 # 4 个元素的矩阵#> [,1] [,2]
#> [1,] 1 3
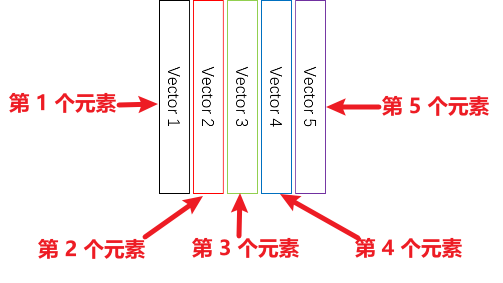
#> [2,] 2 4list 和 data.frame 这两种类型的 object,element 指结构上的单个记录。例如:
- list
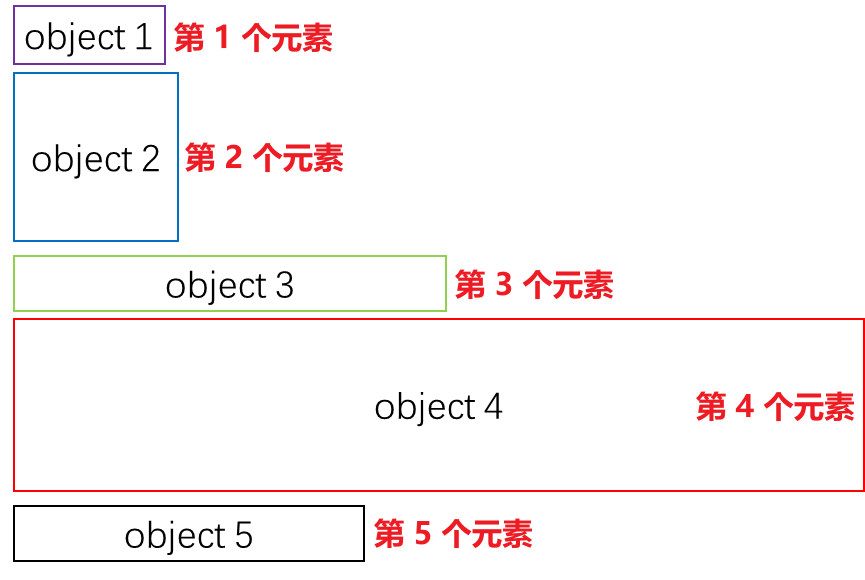
data.frame
9.2 Subsetting operators
subsetting 在 R 中被视作是一种操作(operation),所以是通过操作符(operator)来实现。用于 subsetting 的 operators 共有 4 种,可分为 2 种类型。
| 取单个元素 | 取多个元素 |
|---|---|
[[]],$,@
|
[] |
其中,$和@但只能作用于 list 和 data.frame 这两种 structure type,可以视作是与[[]]等价的一种特殊写法。$和@的作用方式相同,只是针对不同的 object 系统,$适用于 S3,@适用于 S4。关于object系统的知识涉及到面向对象编程(Object-oriented programming),超出了本课程的讲解范围,在此不作展开。
Subsetting 的两种索引(index)分别是位置和名字(name),其中位置是绝对会有的,而 name 则不一定,这也是符合常识的。例如军训队伍方阵,教官第一次训练时,是不知道每个同学叫什么名字的,但是绝对可以通过该同学在方阵中所处的位置(第几行第几列)让该同学出列。同样的,在 R 中,要取出一个 object 的一部分,此时该 object 肯定是已经存在于 global environment 中,它有几个元素,分别是什么都是确定的,元素的位置信息就一定会有,但 name 则不一定(data.frame 是一个例外)。所以取子集时,位置是最为常用的 index。
注意:取多个 elements 时,通常会保留所取 elements 中与 name 相关的 attribute,有些情况下会保留 dim,其他的 attribute 一般都会被丢弃。这一点在本节后续使用的例子中可以得到体现。
9.3 Basic usage of subsetting operators
9.3.1 Subset single element
[[]]
无维度
用来取出 object 中的指定单个 element。例如:
# atomic vector
vec_dbl <- c(0, 1, 2.5, 4.5)
vec_dbl[[1]]#> [1] 0
vec_dbl[[2]]#> [1] 1
vec_dbl[[3]]#> [1] 2.5
vec_dbl[[4]]#> [1] 4.5上述写法也同样适用于 factor 和 expression。
有维度
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
m1[[1]]#> [1] 1
m1[[2]]#> [1] 2
m1[[3]]#> [1] 3
m1[[4]]#> [1] 4
# 上述代码分别等价于
m1[[1, 1]]#> [1] 1
m1[[2, 1]]#> [1] 2
m1[[1, 2]]#> [1] 3
m1[[2, 2]]#> [1] 4注:[[2, 2]]这种有,的写法表示 subsetting 时考虑了维度的信息,一个,表示有两个维度,两个,表示有三个维度,依此类推。这种写法只能用于有 dim 这个 attribute 的 object,也就是 array 和 matrix,以及特例—— data.frame:
#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 2
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 3 4
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 5 6
a1[[1]]#> [1] 1
a1[[2]]#> [1] 2
a1[[3]]#> [1] 3
a1[[4]]#> [1] 4
a1[[5]]#> [1] 5
a1[[6]]#> [1] 6
# 上述代码分别等价于
a1[[1, 1, 1]]#> [1] 1
a1[[1, 2, 1]]#> [1] 2
a1[[1, 1, 2]]#> [1] 3
a1[[1, 2, 2]]#> [1] 4
a1[[1, 1, 3]]#> [1] 5
a1[[1, 2, 3]]#> [1] 6
# data.frame
df <- data.frame(x = c(1, 2), y = c(3, 4))
df
attributes(df)#> $names
#> [1] "x" "y"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2
df[[1, 2]]#> [1] 3
# list
l1 <- list(
list(1, 2, 3),
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
str(l1)#> List of 7
#> $ :List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ : int [1:3] 1 2 3
#> $ : chr "a"
#> $ : logi [1:3] TRUE FALSE TRUE
#> $ : num 2.3
#> $ : logi [1:3] NA NA NA
#> $ : num [1:2, 1:2] 1 2 3 4
l1[[1]]#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3
l1[[2]]#> [1] 1 2 3
l1[[3]]#> [1] "a"
l1[[4]]#> [1] TRUE FALSE TRUE
l1[[5]]#> [1] 2.3
l1[[6]]#> [1] NA NA NA
l1[[7]] # 该元素本身是 matrix,有 dim attribute,所以得到保留#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
is.matrix(l1[[7]])#> [1] TRUE
# 取 list object 的单个元素中的单个 element
l1[[2]][[2]]#> [1] 2
l1[[7]][[4]]#> [1] 4
# 等价于
l1[[7]][[2, 2]]#> [1] 4
# data.frame
gender <- factor(c("male", "male", "female", "male", "female", "female"))
school <- factor(c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"))
age <- c(18, 20, 19, 19, 21, 20)
df <- data.frame(gender, school, age)
df
df[[1]]#> [1] male male female male female female
#> Levels: female male
df[[2]]#> [1] jxnu ncu jxnu jxnu jxufe jxau
#> Levels: jxau jxnu jxufe ncu
df[[3]]#> [1] 18 20 19 19 21 20
# 取 data.frame object 的单个元素中的单个 element
df[[3]][[5]]#> [1] 21
# 等价的写法应该是什么?如果使用了不存在的位置作为 index 取单个 element 会怎么样?
list:
l1 <- list(
list(1, 2, 3),
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
l1[[8]]#> Error in l1[[8]]: subscript out of boundsdata.frame:
df1 <- data.frame(number = c(1, 2, 3), letter = c("a", "b", "c"))
df1[[3]]#> Error in .subset2(x, i, exact = exact): subscript out of bounds其他 structure type:
vec_dbl <- c(0, 1, 2.5, 4.5)
vec_dbl[[5]]#> Error in vec_dbl[[5]]: subscript out of bounds-
$和@
只能作用于有names这一 attribute 的 list 和 data.frame ,用来取出对应某名字下的单个 element。例如,
l1 <- list(
t = list(1, 2, 3),
u = c(1L, 2L, 3L),
v = "a",
w = c(TRUE, FALSE, TRUE),
x = c(2.3),
y = c(NA, NA, NA),
z = matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
df1 <- data.frame(number = c(1, 2, 3), letter = c("a", "b", "c"))
str(l1)#> List of 7
#> $ t:List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ u: int [1:3] 1 2 3
#> $ v: chr "a"
#> $ w: logi [1:3] TRUE FALSE TRUE
#> $ x: num 2.3
#> $ y: logi [1:3] NA NA NA
#> $ z: num [1:2, 1:2] 1 2 3 4
df1
# subsetting using $
l1$t#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3
df1$letter#> [1] "a" "b" "c"
# 等价于
l1[[1]]#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3
df1[[2]]#> [1] "a" "b" "c"如果名字是中文,可能会出现编码的问题,导致报错,不建议使用。如果碰到中文名字的情况,需要加"",例如:
df1 <- data.frame(number = c(1, 2, 3), letter = c("a", "b", "c"))
names(df1) <- c("数字", "字母")
df1
df1$"数字"#> [1] 1 2 3如果将$用于除 list 和 data.frame 以外的 structure types,都会报错,例如
a <- c(x = 1, y = 2)
a#> x y
#> 1 2
a$x#> Error in a$x: $ operator is invalid for atomic vectors除了 list 和 data.frame 之外,其他的 structure types 能用 name 为 index 取单个 element 吗?
# atomic vector
a <- c(x = 1, y = 2)
a[[2]]#> [1] 2
a[["y"]]#> [1] 2#> a b
#> c 1 3
#> d 2 4
m1[[4]]#> [1] 4
m1[[2, 2]]#> [1] 4
m1[[2, "b"]]#> [1] 4
m1[["d", 2]]#> [1] 4
m1[["d", "b"]]#> [1] 4
# array
a1 <- array(c(1, 2, 3, 4, 5, 6), dim = c(1, 2, 3))
dimnames(a1) <- list(NULL, c("a", "b"), c("c1", "c2", "c3"))
a1#> , , c1
#>
#> a b
#> [1,] 1 2
#>
#> , , c2
#>
#> a b
#> [1,] 3 4
#>
#> , , c3
#>
#> a b
#> [1,] 5 6
a1[[6]]#> [1] 6
a1[[1, 2, 3]]#> [1] 6
a1[[1, 2, "c3"]]#> [1] 6
a1[[1, "b", 3]]#> [1] 6
a1[[1, "b", "c3"]]#> [1] 6如果使用了不存在的 name 作为 index 取单个 element 会怎么样?
list 和 data.frame:
# list
l1 <- list(
t = list(1, 2, 3),
u = c(1L, 2L, 3L),
v = "a",
w = c(TRUE, FALSE, TRUE),
x = c(2.3),
y = c(NA, NA, NA),
z = matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
l1$h#> NULL
l1[["h"]]#> NULL
# 注意:
# 使用不存在的 name 作为 index,[[]]不会报错,且与$的结果一致,
# 但使用不存在的位置作为 index,[[]]会直接报错
# data.frame
df1 <- data.frame(number = c(1, 2, 3), letter = c("a", "b", "c"))
df1$numbar#> NULL
df1[["numbar"]]#> NULL
# cbind(df1, df1$numbar)其他 structure types:
# atomic vector
a <- c(x = 1, y = 2)
a[["z"]]#> Error in a[["z"]]: subscript out of bounds9.3.2 Subset multiple elements
[]表示用来取多个 elements(包括单个)。
当取单个 element 时,绝大多数情况下,[]和[[]]效果一致。例如:
# atomic vector
a <- c(1, 2, 3)
a[3]#> [1] 3
a[[3]]#> [1] 3#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
m1[4]#> [1] 4
m1[[4]]#> [1] 4
m1[2, 2]#> [1] 4
m1[[2, 2]]#> [1] 4#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 2
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 3 4
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 5 6
a1[6]#> [1] 6
a1[[6]]#> [1] 6
a1[1, 2, 3]#> [1] 6
a1[[1, 2, 3]]#> [1] 6只有在 list 和 data.frame 的情况下,取单个 element 用[]和[[]]的结果有所不同,不同的根本原因是:如果是 list(data.frame 本质上是 list),那么[]返回的结果永远是一个 list。例如
l1 <- list(
t = list(1, 2, 3),
u = c(1L, 2L, 3L),
v = "a",
w = c(TRUE, FALSE, TRUE),
x = c(2.3),
y = c(NA, NA, NA),
z = matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
str(l1)#> List of 7
#> $ t:List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ u: int [1:3] 1 2 3
#> $ v: chr "a"
#> $ w: logi [1:3] TRUE FALSE TRUE
#> $ x: num 2.3
#> $ y: logi [1:3] NA NA NA
#> $ z: num [1:2, 1:2] 1 2 3 4
l1[[7]]#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
is.matrix(l1[[7]])#> [1] TRUE
l1[7] # 名字得以保留,且取出的结果是 list#> $z
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
is.matrix(l1[7])#> [1] FALSE
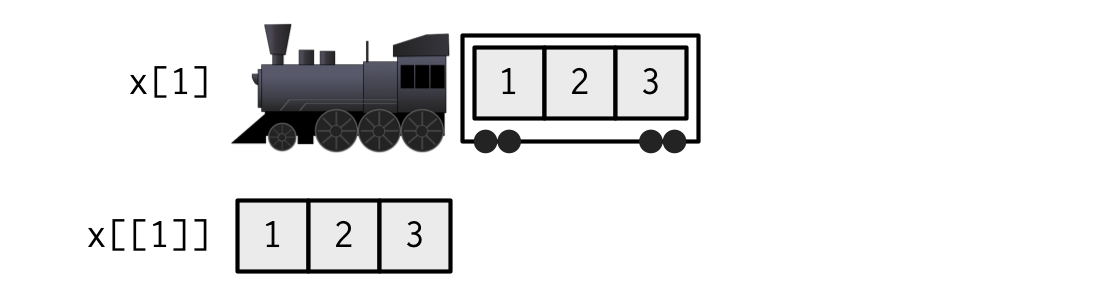
is.list(l1[7])#> [1] TRUE这里借用Advanced R(Hadley Wickham)中的比喻和图例来形象地解释这一现象的原因。比喻的原作者:
If list x is a train carrying objects, then x[[5]] is the object in car 5; x[4:6] is a train of cars 4-6.
RLangTip, https://twitter.com/RLangTip/status/268375867468681216
假定一个 list 是一个火车,每一个 element 就是一节车厢,车厢里可以是各种各样 structure type 的 object。那么,[[]]取出来的就是某节车厢里的 object,[]取出来的就是火车+指定车厢+指定车厢里面的 object。
例如:
x <- list(1:3, "a", 4:6)就好比

当从x中取单个 element 时,[]表示创建一个小型的火车拉着某个车厢,[[]]表示把某个车厢里的东西取出来。
由于 data.frame 本质上是 list,所以也会出现上述现象:
df <- data.frame(x = 1:3, y = 4:6)
df[1]
df[[1]]#> [1] 1 2 3
is.data.frame(df[1])#> [1] TRUE
is.atomic(df[1])#> [1] FALSE
is.data.frame(df[[1]])#> [1] FALSE
is.atomic(df[[1]])#> [1] TRUE结合上述细节就会发现,在取 list 的单个 element 时,如果 index 出错,[]和[[]]的结果完全不同:
l1 <- list(
a = list(1, 2, 3),
b = c(1L, 2L, 3L),
c = "a",
d = c(TRUE, FALSE, TRUE),
e = c(2.3),
f = c(NA, NA, NA),
g = matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
l1["h"] # 不报错,list#> $<NA>
#> NULL
l1[8] # 结果同上,不报错,list#> $<NA>
#> NULL
l1[["h"]] # 结果不同,但也不报错,vector#> NULL
l1[[8]] #报错#> Error in l1[[8]]: subscript out of bounds忽略上述所有细节会导致在写代码的时候,如果使用[]取 list 和 data.frame 的单个 element,后续基于该取出的单个 element 的操作很容易出错:
#> List of 10
#> $ statistic : Named num -8.74
#> ..- attr(*, "names")= chr "t"
#> $ parameter : Named num 29
#> ..- attr(*, "names")= chr "df"
#> $ p.value : num 1.28e-09
#> $ conf.int : num [1:2] -17.9 -11.1
#> ..- attr(*, "conf.level")= num 0.95
#> $ estimate : Named num [1:2] 10.5 25
#> ..- attr(*, "names")= chr [1:2] "mean of x" "mean of y"
#> $ null.value : Named num 0
#> ..- attr(*, "names")= chr "difference in means"
#> $ stderr : num 1.66
#> $ alternative: chr "two.sided"
#> $ method : chr "Welch Two Sample t-test"
#> $ data.name : chr "1:20 and 20:30"
#> - attr(*, "class")= chr "htest"
# wrong approach, subsetting a single element of a list object using []
results_ttest[4][1]#> $conf.int
#> [1] -17.89186 -11.10814
#> attr(,"conf.level")
#> [1] 0.95
results_ttest[4][2]#> $<NA>
#> NULL
# correct approach, subsetting a single element of a list object using [[]]
results_ttest[[4]][1]#> [1] -17.89186
results_ttest[[4]][2]#> [1] -11.10814
# correct approach, subsetting a single element of a list object using $
results_ttest$conf.int[1]#> [1] -17.89186
results_ttest$conf.int[2]#> [1] -11.10814当使用[]同时取出多个 elements 时,就有很多几种不同的基本用法,并且可以根据需要灵活组合使用。这些基本用法可以分为两类:以位置为 index和以名字为 index。其中,位置为 index 时[]的使用最为灵活。
9.3.2.1 Position
有四种具体的用法:
- positive integer(取出指定位置的 element)。
不考虑维度
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
m1[c(4, 3, 2, 1)]#> [1] 8 7 6 5
m1[c(1, 3)]#> [1] 5 7#> [1] FALSE可以看出,m1[c(4, 3, 2, 1)]取出来的子集中 elements 的顺序和提供的 positive integers 完全一致,相当于取出子集的同时,也对子集的位置顺序做了调整。这意味着可以按照任务需求随意排列子集。这一理解在“取子集操作符的进阶用法”小节的讲解中会得到运用。
df <- data.frame(
number = c(1, 2, 3, 4),
letter = c("a", "b", "c", "d"),
direction = c("north", "east", "south", "west")
)
df
df[c(1, 2, 3)]
df[c(1, 3)]
is.data.frame(df[c(1, 3)])#> [1] TRUE考虑维度
相当于对原始的 object 切块。
#> [,1] [,2] [,3]
#> [1,] 1 4 7
#> [2,] 2 5 8
#> [3,] 3 6 9#> [,1] [,2]
#> [1,] 4 7
#> [2,] 6 9#> [1] TRUE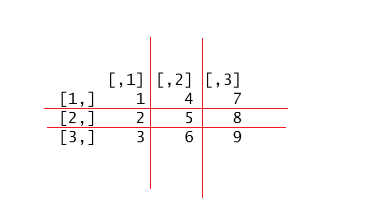
df <- data.frame(number = c(1, 2, 3, 4), letter = c("a", "b", "c", "d"), direction = c("north", "east", "south", "west"))
df
is.data.frame(df[c(2, 3), c(1, 3)])#> [1] TRUE重复的 positive integers,可以提取相同的内容并拼接:
df <- data.frame(
number = c(1, 2, 3, 4),
letter = c("a", "b", "c", "d"),
direction = c("north", "east", "south", "west")
)
df和位置序号一致但顺序不同的 positive integers,可以用来重新排列原始数据:
df <- data.frame(
number = c(1, 2, 3, 4),
letter = c("a", "b", "c", "d"),
direction = c("north", "east", "south", "west")
)
df
df[, c(3, 1, 2)]- negative integer(排除指定位置的 element)。
不考虑维度
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
m1[-4]#> [1] 5 6 7
m1[c(-1, -3)]#> [1] 6 8考虑维度
m1 <- matrix(1:16, nrow = 4, ncol = 4)
m1#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16#> [,1] [,2]
#> [1,] 2 14
#> [2,] 3 15和 positive integer 一样,negative integer 也支持一个数字重复多次的用法,相当于多次排除相同的指定 element,但无意义。
m1 <- matrix(1:16, nrow = 4, ncol = 4)
m1#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16#> [,1] [,2] [,3]
#> [1,] 2 10 14
#> [2,] 3 11 15
#> [3,] 4 12 16此外,negative integer 不可以和 positive integer 一起混用。
m1 <- matrix(1:16, nrow = 4, ncol = 4)
m1#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16#> Error in m1[c(1, -4), c(2, -3)]: only 0's may be mixed with negative subscripts- logical(取出指定位置的 element)。
不考虑维度
使用一个和 object 相同长度的 logical vector,TRUE表示将 object 该位置上的 element 取出来,FALSE则相反。
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
m1[c(TRUE, FALSE, TRUE, FALSE)]#> [1] 5 7和 integer 的情况不同,如果object[]中 logical vector 的长度比 object 短,就会触发 recycling rule,(详见7.2.2),导致取出预期之外的 element,这一点需要特别注意,容易导致代码出错:
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
m1[TRUE] # 等价于 m1[c(TRUE, TRUE, TRUE, TRUE)]#> [1] 5 6 7 8考虑维度
m1 <- matrix(1:16, nrow = 4, ncol = 4)
m1#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16#> [,1] [,2]
#> [1,] 5 9
#> [2,] 7 11- 空白(取出所有 elements)。
不考虑维度
m1 <- matrix(1:16, nrow = 4, ncol = 4)
m1#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16
m1[]#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16考虑维度(取出指定维度下的所有 elements)
m1 <- matrix(1:16, nrow = 4, ncol = 4)
m1#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 14
#> [3,] 3 7 11 15
#> [4,] 4 8 12 16
m1[c(1, 2), ]#> [,1] [,2] [,3] [,4]
#> [1,] 1 5 9 13
#> [2,] 2 6 10 149.3.2.2 Few caveats
- 取子集时和 name 有关的 attribute 会保留。
#> 1 2 3 4
#> 1 1 5 9 13
#> 2 2 6 10 14
#> 3 3 7 11 15
#> 4 4 8 12 16
m1[c(4, 3, 2, 1), ]#> 1 2 3 4
#> 4 4 8 12 16
#> 3 3 7 11 15
#> 2 2 6 10 14
#> 1 1 5 9 13- data.frame 由于其 element 是列,所以按行 subsetting 出来是 data.frame,可能会导致无法进行部分数值运算,如
mean():
df <- data.frame(score_last = c(99, 100, 87), score_current = c(96, 98, 77))
mean(df[2, ])#> Warning in mean.default(df[2, ]): argument is not numeric
#> or logical: returning NA#> [1] NA
is.numeric(df) # is.numeric returns TRUE if its argument is of mode "numeric" (type "double" or type "integer") and not a factor, and FALSE otherwise. #> [1] FALSE
typeof(df)#> [1] "list"
is.numeric(df[1, ])#> [1] FALSE9.3.2.3 Name
- 无维度
vector:
#> v1 v2 v3 v4
#> 1 2 3 4
v1[c("v1", "v3", "v4")]#> v1 v3 v4
#> 1 3 4- 有维度
matrix:
m1 <- matrix(1:16, nrow = 4, ncol = 4)
dimnames(m1) <- list(c("r1", "r2", "r3", "r4"), c("c1", "c2", "c3", "c4"))
m1#> c1 c2 c3 c4
#> r1 1 5 9 13
#> r2 2 6 10 14
#> r3 3 7 11 15
#> r4 4 8 12 16#> c2 c3
#> r1 5 9
#> r4 8 12重复某一个名字,和重复 positive integer 是一样的效果,提取相同的内容然后拼接,就不展示例子了。
取多个 elements 时,以上 4 种 index 可以根据需要任意组合使用,例如:
m1 <- matrix(1:16, nrow = 4, ncol = 4)
dimnames(m1) <- list(c("r1", "r2", "r3", "r4"), c("c1", "c2", "c3", "c4"))
m1#> c1 c2 c3 c4
#> r1 1 5 9 13
#> r2 2 6 10 14
#> r3 3 7 11 15
#> r4 4 8 12 16
m1[c(TRUE, TRUE, FALSE, FALSE), ]#> c1 c2 c3 c4
#> r1 1 5 9 13
#> r2 2 6 10 14#> c2 c4
#> r2 6 14
#> r4 8 169.3.3 Recap
list 和 data.frame 中 element 指结构上的单个记录,其他 structure types 中 element 指内容上的单个记录;
取多个 elements 时,和 name (如行名、列名、维度名等)有关的 attribute 会保留;
- Subsetting operators 的总结如下图所示:
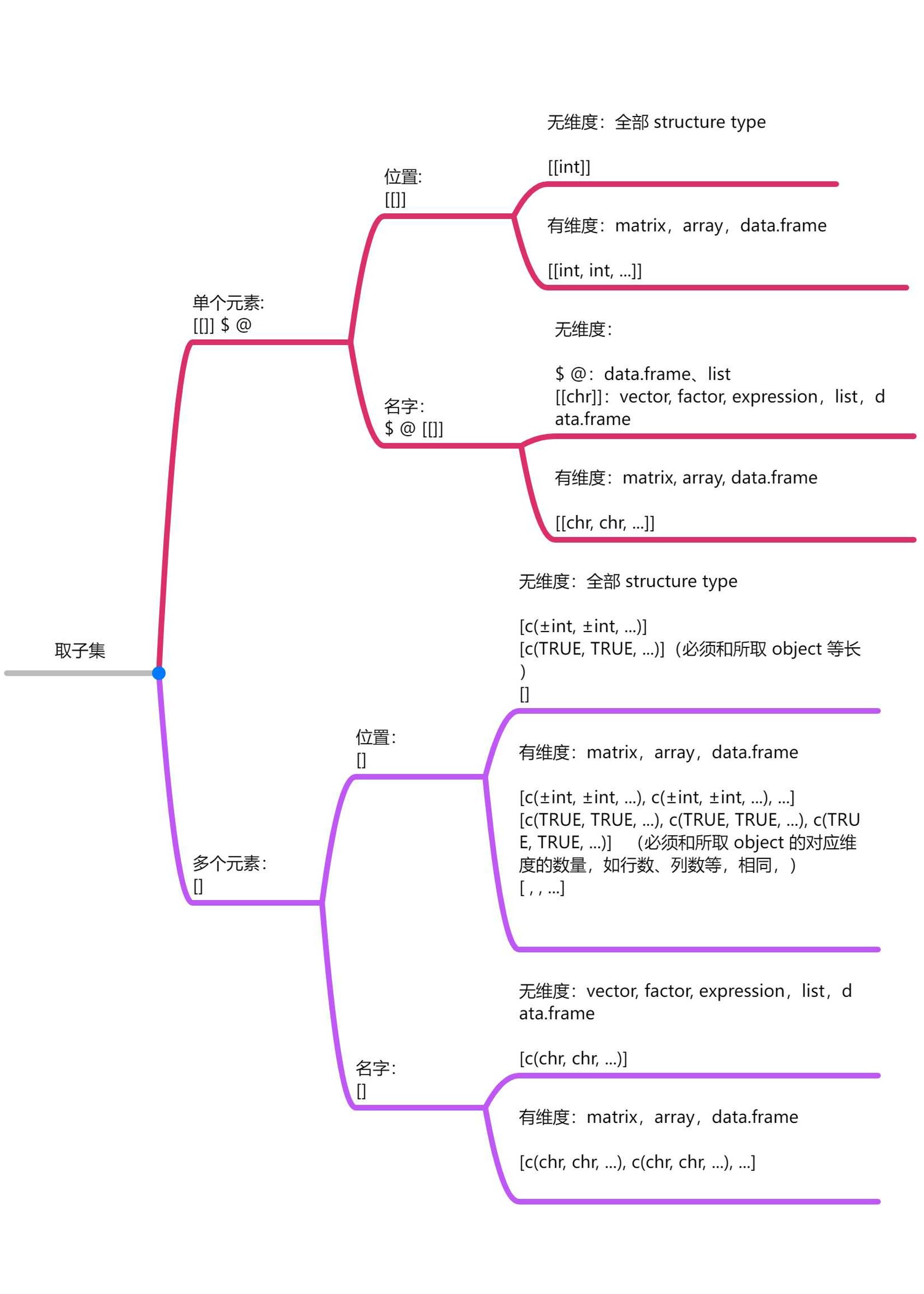
list 和 data.frame 取单个元素时,
[[]]和$或@的结果一致,但[[]]和[]的结果不一致;使用 logical vector 来取多个元素时,一定要注意:
- 不考虑维度,logical vector 的长度要和 object 一致;
- 考虑维度,logical vector 的长度要和对应维度的数量(如行数、列数)一致。
9.4 Advanced usage of subsetting operators
Subsetting 的基本用法很好掌握,但如果只会写基本用法,代码就会很冗长,不够简洁。例如需要把矩阵中所有大于 1 的数找出来:
#> [,1] [,2]
#> [1,] 0.5 0.80
#> [2,] 0.1 0.25
is_larger_than_3 <- m1 > 0.3
m1_larger_than_3 <- m1[is_larger_than_3]
m1_larger_than_3#> [1] 0.5 0.8熟悉了基本用法后,可以使用进阶写法,即将多个操作写在同一行的方式简化代码:
#> [,1] [,2]
#> [1,] 0.5 0.80
#> [2,] 0.1 0.25
m1_larger_than_3 <- m1[m1 > 0.3]
m1_larger_than_3#> [1] 0.5 0.89.4.1 Basic formula
进阶用法主要体现在灵活运用[]上。[]的使用语法为object[index],即对象[索引],容易看出,这个结构里面可以改动的部分实际上就只有object和index,进阶用法的基本思路就体现在如何改动这两个部分上。
-
object[index]中的object
基本用法:
进阶用法:object可以是语句,代表一步或多步操作,执行结果是一个 anonymous object:
df <- data.frame(
number = c(1, 2, 3, 4),
letter = c("a", "b", "c", "d"),
direction = c("north", "east", "south", "west")
)
df#> [1] "letter" "direction"
df[c(2, 3), ][-1]-
object[index]中的index(重点)
基本用法:positive integer,negative integer,logical vector,空白,character
进阶用法:通过代码生成符合要求的 index,主要是 positive integer 和 logical vector。
例如,将下面的数据中所有非缺失值取出来:
#> [,1] [,2] [,3] [,4]
#> [1,] NA 5 9 13
#> [2,] 2 NA 10 14
#> [3,] 3 7 NA 15
#> [4,] 4 8 12 NA
is.na(m1)#> [,1] [,2] [,3] [,4]
#> [1,] TRUE FALSE FALSE FALSE
#> [2,] FALSE TRUE FALSE FALSE
#> [3,] FALSE FALSE TRUE FALSE
#> [4,] FALSE FALSE FALSE TRUE
!is.na(m1)#> [,1] [,2] [,3] [,4]
#> [1,] FALSE TRUE TRUE TRUE
#> [2,] TRUE FALSE TRUE TRUE
#> [3,] TRUE TRUE FALSE TRUE
#> [4,] TRUE TRUE TRUE FALSE
m1[!is.na(m1)]#> [1] 2 3 4 5 7 8 9 10 12 13 14 15#> [,1] [,2] [,3] [,4]
#> [1,] 2 5 9 13
#> [2,] 3 7 10 14
#> [3,] 4 8 12 15这种写法的本质,是通过使用一些 function 操作来产生目标 index,然后再使用这些 index 完成 subsetting。上述例子中需要完成的操作:
- 判断每一个 element 是不是缺失值(
is.na()), - 然后把不是缺失值的 element 找出来
!,并生成最终的 logical vector,其中,TRUE代表非缺失,FALSE代表缺失, - 最后使用该 logical vector 作为 index ,结合
[]取出符合条件的所有 elements。
将所有这些步骤糅合到一起写,实现了 1 行代码搞定相对复杂的任务。
一旦熟悉了这种写法,只要掌握一些常用操作所对应的 function,多加练习就可以灵活运用,写出非常简洁高效的代码。