6 Basic: structure type
数据分析任务中处理的数据通常都是以某种结构的形式呈现的,例如矩阵,所有的元素都是储存在这样一种结构里,那么将这个数据读进 R 时,就自然会保持原有的结构。除了实际数据中常见的行+列的矩阵式结构, R 还有其它几种常用的结构,即不同的结构类型(structure type)。
structure type之所以重要是因为不同的structure type在结构上有其各自的特点,在操作的时候需要注意,否则就容易出错。
structure type 可以分为两类,向量(vector)和其他类型,其中 vector 最为基础。
6.1 Vector
vector 是 R 中最重要、也是最基础的一种 structure type,除此之外其他的 structure type 可以视作是有更多属性(attribute)的 vector。有关 vector 的详细信息可以使用?vector查看。
vector 有 3 种:atomic(原子型),list(列表),expression(表达式)。
6.1.1 Atomic vector
Atomic vector 中的所有 element 必须是同一种 element type(不可以是 expression)。
var_lgl <- c(TRUE, FALSE)
var_int <- c(1L, 6L, 10L)
var_dbl <- c(1, 2.5, 4.5)
var_chr <- c("these are", "some strings")
var_na <- c(NA, 1, 2)
var_null <- c(NULL, 1, 2)
var_exp <- expression(1 + 2)
is.vector(var_lgl)#> [1] TRUE
is.vector(var_int)#> [1] TRUE
is.vector(var_dbl)#> [1] TRUE
is.vector(var_chr)#> [1] TRUE
is.vector(var_na)#> [1] TRUE
is.vector(var_null)#> [1] TRUE
is.vector(var_exp)#> [1] TRUE
is.atomic(var_lgl)#> [1] TRUE
is.atomic(var_int)#> [1] TRUE
is.atomic(var_dbl)#> [1] TRUE
is.atomic(var_chr)#> [1] TRUE
is.atomic(var_na)#> [1] TRUE
is.atomic(var_null)#> [1] TRUE
is.atomic(var_exp)#> [1] FALSE检测某个对象是否是 vector 或某个 vector 是否是 atomic 可以使用is.vector()和is.atomic(),但因为这两个function返回的结果指向性并不明确,往往需要进一步查验到底是哪一种元素类型。如果返回TRUE,其实并不知道具体是哪一种 element type 的 vector。更建议直接使用typeof()
typeof(var_lgl)#> [1] "logical"
typeof(var_int)#> [1] "integer"
typeof(var_dbl)#> [1] "double"
typeof(var_chr)#> [1] "character"
typeof(var_na)#> [1] "double"
typeof(var_null)#> [1] "double"
typeof(var_exp)#> [1] "expression"6.1.2 List
List 虽然本质上是一种 vector,但相较于 atomic vector 从形式上差异很大,所以通常会把 list 当作是一种独立的 structure type,在6.2这一小节中会有专门论述。
6.1.3 Expression (optional)
在5一章中讲到可以使用expression()创建 expression 的object,如果提供给expression()的 argument 有多个,那么产生出来的就是一个 expression vector,例如:
var_exp <- expression(1 + 2, a, (y == sqrt(x)))
var_exp#> expression(1 + 2, a, (y == sqrt(x)))
length(var_exp)#> [1] 36.2 Other type
除了 vector之外, R 还有很多 structure types,如 matrix,array,factor,list,data.frame,这些 structure type 都可以近似理解为在 atomic vector 的基础上添加 属性(attribute) 。
6.2.1 Attribute
在 R 中,object 通常会有属性(attribute)。attribute 储存的是用来诠释 object 的一些元信息,通过attributes()查看。
对于 atomic vector,有且只能有一个 attribute,就是names。如果没有指定,则为NULL。例如:
scores <- c(90, 100, 98)
scores#> [1] 90 100 98
attributes(scores)#> NULL使用names()给scores添加names的 attribute`,
scores <- c(90, 100, 98)
scores#> [1] 90 100 98#> test1 test2 test3
#> 90 100 98
attributes(scores)#> $names
#> [1] "test1" "test2" "test3"names()除了可以给 object 赋予names的 attribute,还可以用来提取 object 的names,例如:
scores <- c(90, 100, 98)
attributes(scores)#> NULL#> [1] "test1" "test2" "test3"可以用NULL清空names,例如:
#> test1 test2 test3
#> 90 100 98
names(scores) <- NULL如果希望通过c()生成 atomic vector 时就直接被赋予names,代码示例如下:
scores <- c(test1 = 90, test2 = 100, test3 = 98)
attributes(scores)#> $names
#> [1] "test1" "test2" "test3"注意,和 atomic vector 一样,expression vector 也可以有names属性,例如
var_exp <- expression(
exp1 = 1 + 2,
exp2 = a,
exp3 = (y == sqrt(x))
)
var_exp#> expression(exp1 = 1 + 2, exp2 = a, exp3 = (y == sqrt(x)))
attributes(var_exp)#> $names
#> [1] "exp1" "exp2" "exp3"所有的 structure type,基本上都可以有与 name 相关的 attribute ,姑且称之为通用 attribute。除此之外,还有一些特殊 attribute。接下来介绍其他 structure type 时,均会按照先介绍该 structure type 的特殊 attribute,再介绍通用 attribute 的顺序行文。
6.2.2 Matrix and array
可以通过添加dim(dimension,维度)的 attribute,将 atomic vector 转换为 matrix(2 维)和 array(2 维及以上),用到的 function 为dim()。
6.2.2.1 Special attribute: dim
- matrix
#> [1] TRUE
dim(a)#> NULL#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
attributes(a)#> $dim
#> [1] 2 2
is.vector(a)#> [1] FALSE
is.matrix(a)#> [1] TRUER 中, dimension 始终都是先从行开始。
#> [1] TRUE#> [,1] [,2] [,3] [,4]
#> [1,] 1 2 3 4- array
#> [1] TRUE
dim(a)#> NULL#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 9 11
#> [2,] 10 12
attributes(a)#> $dim
#> [1] 2 2 3
is.vector(a)#> [1] FALSE
is.array(a)#> [1] TRUE#> , , 1
#>
#> [,1] [,2] [,3] [,4]
#> [1,] 1 2 3 4
#>
#> , , 2
#>
#> [,1] [,2] [,3] [,4]
#> [1,] 5 6 7 8
#>
#> , , 3
#>
#> [,1] [,2] [,3] [,4]
#> [1,] 9 10 11 12当然,通常产生 matrix 和 array 并不需要通过上述较为麻烦的方式,而是直接使用对应的 function 一步生成,例如:
- matrix
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4- array
#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 9 11
#> [2,] 10 12注意事项
#> [,1]
#> [1,] 1
#> [2,] 2
#> [3,] 3
#> [4,] 4#> [,1] [,2] [,3] [,4]
#> [1,] 1 2 3 4
matrix(1:6, nrow = 3, ncol = 2)#> [,1] [,2]
#> [1,] 1 4
#> [2,] 2 5
#> [3,] 3 6
matrix(1:6, byrow = TRUE, nrow = 3, ncol = 2)#> [,1] [,2]
#> [1,] 1 2
#> [2,] 3 4
#> [3,] 5 6#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 4
#> [2,] 2 5
#> [3,] 3 6
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 7 10
#> [2,] 8 11
#> [3,] 9 126.2.2.2 Generic attribute: dimnames
- matrix
a <- matrix(data = c(1, 2, 3, 4), nrow = 2, ncol = 2)
attributes(a)#> $dim
#> [1] 2 2
colnames(a) <- c("a", "b")
attributes(a)#> $dim
#> [1] 2 2
#>
#> $dimnames
#> $dimnames[[1]]
#> NULL
#>
#> $dimnames[[2]]
#> [1] "a" "b"
rownames(a) <- c("c", "d")
attributes(a)#> $dim
#> [1] 2 2
#>
#> $dimnames
#> $dimnames[[1]]
#> [1] "c" "d"
#>
#> $dimnames[[2]]
#> [1] "a" "b"- array
a <- array(data = c(1, 2, 3, 4, 5, 6), dim = c(1, 2, 3))
attributes(a)#> $dim
#> [1] 1 2 3#> , , 1
#>
#> [,1] [,2]
#> c 1 2
#>
#> , , 2
#>
#> [,1] [,2]
#> c 3 4
#>
#> , , 3
#>
#> [,1] [,2]
#> c 5 6
attributes(a)#> $dim
#> [1] 1 2 3
#>
#> $dimnames
#> $dimnames[[1]]
#> [1] "c"
#>
#> $dimnames[[2]]
#> NULL
#>
#> $dimnames[[3]]
#> NULL#> , , 1
#>
#> a b
#> c 1 2
#>
#> , , 2
#>
#> a b
#> c 3 4
#>
#> , , 3
#>
#> a b
#> c 5 6
attributes(a)#> $dim
#> [1] 1 2 3
#>
#> $dimnames
#> $dimnames[[1]]
#> [1] "c"
#>
#> $dimnames[[2]]
#> [1] "a" "b"
#>
#> $dimnames[[3]]
#> NULL#> , , a1
#>
#> a b
#> c 1 2
#>
#> , , a2
#>
#> a b
#> c 3 4
#>
#> , , a3
#>
#> a b
#> c 5 6
attributes(a)#> $dim
#> [1] 1 2 3
#>
#> $dimnames
#> $dimnames[[1]]
#> [1] "c"
#>
#> $dimnames[[2]]
#> [1] "a" "b"
#>
#> $dimnames[[3]]
#> [1] "a1" "a2" "a3"因为 matrix 可以视作是一个\(2\times2\)的 array,所以dimnames()同样也适用于matrix,例如:
a <- matrix(data = c(1, 2, 3, 4), nrow = 2, ncol = 2)
dimnames(a) <- list(c("c", "d"), c("a", "b"))
a#> a b
#> c 1 3
#> d 2 4
attributes(a)#> $dim
#> [1] 2 2
#>
#> $dimnames
#> $dimnames[[1]]
#> [1] "c" "d"
#>
#> $dimnames[[2]]
#> [1] "a" "b"但dimnames()不能用于 vector,会报错,例如
#> NULL#> NULL
names(a)#> [1] "a" "b"#> Error in dimnames(a) <- list(NULL, c("c", "d")): 'dimnames' applied to non-array用NULL清空dimnames
NULL的第三种用法是“清空 object 的值”,套用在dimnames上,也是一样的效用。例如:
a <- matrix(data = c(1, 2, 3, 4), nrow = 2, ncol = 2)
dimnames(a) <- list(c("c", "d"), c("a", "b"))
a#> a b
#> c 1 3
#> d 2 4
attributes(a)#> $dim
#> [1] 2 2
#>
#> $dimnames
#> $dimnames[[1]]
#> [1] "c" "d"
#>
#> $dimnames[[2]]
#> [1] "a" "b"#> a b
#> [1,] 1 3
#> [2,] 2 4
attributes(a)#> $dim
#> [1] 2 2
#>
#> $dimnames
#> $dimnames[[1]]
#> NULL
#>
#> $dimnames[[2]]
#> [1] "a" "b"6.2.2.3 Are matrix and array suitable for data presenting?
在日常使用中,通过“行”和“列”的方式审视数据是十分常见的,例如实验数据记录时,通常一行是一个实验对象在所有实验记录上的数据,一列是某个实验记录下所有实验对象的数据。例如iris是 Fisher 采集的关于 50 种花的一些信息:
iris同时,matrix 和 array 是数学和统计中比较重要的概念,特别是 matrix 与线性代数的紧密联系,代码中涉及到 matrix 的处理如果都能借助线性代数的一些运算来处理,代码的执行效率会高很多,所以 matrix 的运用较为广泛。
但是 matrix 和 array 都要求内部的 element 必须是同一种 type,但是实际上不同的数据可能是完全不一样的 element type。这时候就要用到 data.frame。data.frame 可以视作是 2 维的数据矩阵,和 matrix 有着同样的维数,但是 data.frame 的每一列都是一个 atomic vector ,不同列的element type可以不同。data.frame 是 R 中使用非常广泛的一种结构类型,稍后会重点讲解。但在讲 data.frame 之前,要先讲 list,因为 data.frame 本质上是 list。
6.2.3 List
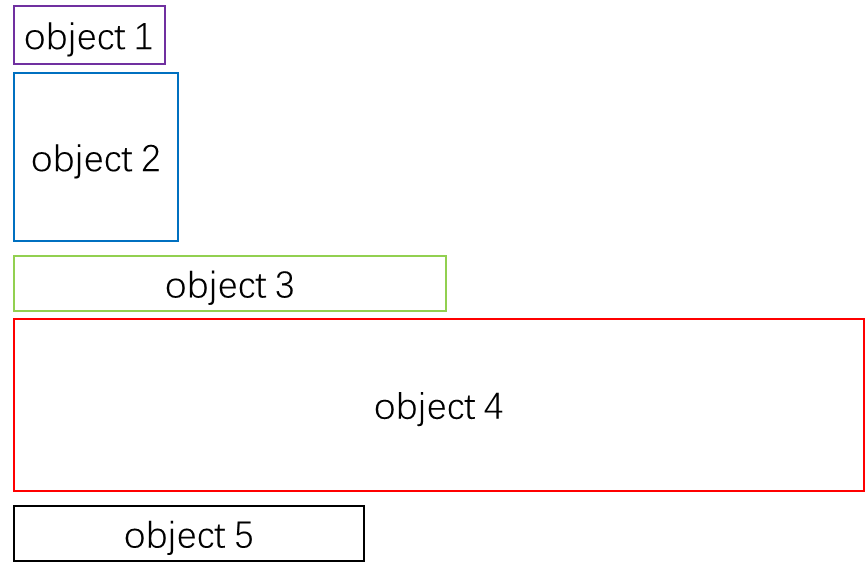
list 本质上是 vector,相当于把各种不同 structure type 的 object 作为 list 这个大 vector 的各个 element,如下图所示:
可以通过list()来构建。例如:
l1 <- list(
list(1, 2, 3),
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
str(l1)#> List of 7
#> $ :List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ : int [1:3] 1 2 3
#> $ : chr "a"
#> $ : logi [1:3] TRUE FALSE TRUE
#> $ : num 2.3
#> $ : logi [1:3] NA NA NA
#> $ : num [1:2, 1:2] 1 2 3 4
typeof(l1)#> [1] "list"
attributes(l1)#> NULL
is.vector(l1)#> [1] TRUE从这个例子中可以看出,list 中的 element 可以是任意 type,甚至可以是 list 套 list,无限嵌套。这使得 list 的处理可以异常灵活。一些常见统计方法的 function 的输出结果就是 list,因为可以把很多不同的信息放在一个 list里面同时输出,非常方便。例如:
#> [1] TRUE
str(result_t)#> List of 10
#> $ statistic : Named num -5.43
#> ..- attr(*, "names")= chr "t"
#> $ parameter : Named num 22
#> ..- attr(*, "names")= chr "df"
#> $ p.value : num 1.86e-05
#> $ conf.int : num [1:2] -11.05 -4.95
#> ..- attr(*, "conf.level")= num 0.95
#> $ estimate : Named num [1:2] 5.5 13.5
#> ..- attr(*, "names")= chr [1:2] "mean of x" "mean of y"
#> $ null.value : Named num 0
#> ..- attr(*, "names")= chr "difference in means"
#> $ stderr : num 1.47
#> $ alternative: chr "two.sided"
#> $ method : chr "Welch Two Sample t-test"
#> $ data.name : chr "1:10 and c(7:20)"
#> - attr(*, "class")= chr "htest"
attributes(result_t)#> $names
#> [1] "statistic" "parameter" "p.value" "conf.int"
#> [5] "estimate" "null.value" "stderr" "alternative"
#> [9] "method" "data.name"
#>
#> $class
#> [1] "htest"因为 list 本质上是 vector,所以也可以通过vector()产生指定长度的 list。
exam_sumary_all_class <- vector(mode = "list", length = 4)
exam_sumary_all_class#> [[1]]
#> NULL
#>
#> [[2]]
#> NULL
#>
#> [[3]]
#> NULL
#>
#> [[4]]
#> NULL6.2.3.1 Generic attribute: names
因为 list 是 vector,所以 list 也只能有一个 attribute,就是names,并且只能使用names()来改动该 attribute,而不能使用dimnames()。例如:
l1 <- list(
a = list(1, 2, 3),
b = c(1L, 2L, 3L),
c = "a",
d = c(TRUE, FALSE, TRUE),
e = c(2.3),
f = c(NA, NA, NA),
g = matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
attributes(l1)#> $names
#> [1] "a" "b" "c" "d" "e" "f" "g"
str(l1)#> List of 7
#> $ a:List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ b: int [1:3] 1 2 3
#> $ c: chr "a"
#> $ d: logi [1:3] TRUE FALSE TRUE
#> $ e: num 2.3
#> $ f: logi [1:3] NA NA NA
#> $ g: num [1:2, 1:2] 1 2 3 4
l1 <- list(
list(1, 2, 3),
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
names(l1) <- c("a", "b", "c", "d", "e", "f", "g")
attributes(l1)#> $names
#> [1] "a" "b" "c" "d" "e" "f" "g"
str(l1)#> List of 7
#> $ a:List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ b: int [1:3] 1 2 3
#> $ c: chr "a"
#> $ d: logi [1:3] TRUE FALSE TRUE
#> $ e: num 2.3
#> $ f: logi [1:3] NA NA NA
#> $ g: num [1:2, 1:2] 1 2 3 4unlist()可以把一个 list 平铺展开为一个 atomic vector,有一些情况下会用得到,例如:
str(l1)#> List of 7
#> $ a:List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ b: int [1:3] 1 2 3
#> $ c: chr "a"
#> $ d: logi [1:3] TRUE FALSE TRUE
#> $ e: num 2.3
#> $ f: logi [1:3] NA NA NA
#> $ g: num [1:2, 1:2] 1 2 3 4
unlist(l1)#> a1 a2 a3 b1 b2 b3 c
#> "1" "2" "3" "1" "2" "3" "a"
#> d1 d2 d3 e f1 f2 f3
#> "TRUE" "FALSE" "TRUE" "2.3" NA NA NA
#> g1 g2 g3 g4
#> "1" "2" "3" "4"6.2.4 Factor
在讲 data.frame 之前,还要再讲一个十分常用的 structure type——factor,常用于类别型数据(既可以是文本,又可以是数值)。matrix 和 array 相对于 vector 而言是多了dim这一个 attribute,而 factor 则是在 atomic vector 的基础上加了两个 attributes,分别是水平(levels)和类(class)。
6.2.4.1 Special attribute: levels and class
class是一种比较特殊的 attribute,一个 object 如果被赋予了class,就意味着这个对象变成了一个S3 object。此部分内容涉及到面向对象编程的知识,不掌握并不会影响正常使用 R ,故跳过此部分内容。
#> [1] 2 1 3 2 1 1 1 3
#> Levels: 1 2 3
attributes(f1)#> $levels
#> [1] "1" "2" "3"
#>
#> $class
#> [1] "factor"其中,levels有 3 种,分别是1,2,3,class是factor。关于levels有两点需要注意:
- factor 的
levels是有顺序的,默认排序规则是升序:
- 如果是 double,integer 或 logical,则是由小到大;
- 如果是 character,则是首字母升序排列,如果首字母一样,就按找第二个字母升序排列,以此类推。
#> [1] 2 1 3 2 e x a d
#> Levels: 1 2 3 a d e x
attributes(f2)#> $levels
#> [1] "1" "2" "3" "a" "d" "e" "x"
#>
#> $class
#> [1] "factor"- R 的很多读取数据的 function 默认会将数据中的 character vector 自动转换为 factor,此时的
levels很有可能需要调整(详见下方调整levels来分组画图的例子), R 版本 4.0.0 以上已经关闭了这种默认行为,4.0.0 以下可以通过stringsAsFactors = FALSE设定来关闭这种默认行为。
6.2.4.2 Generic attribute: names
factor 也可以有names的 attribute,添加方式和 vector 一样,并且和 vector、list 一样,不能用dimnames(),只能用names(),就不在此赘述。
6.2.4.3 When to use factor
Factor 天然地适合于类别数据,比如说性别、班级、学校等,因为这些类别数据的值的种类\水平是已知的,正好匹配上levels这个 attribute。例如使用类别数据作为分组标签来画图:
gender <- factor(c("female", "male", "female", "male", "female", "female"))
school <- factor(c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"))
age <- c(18, 20, 19, 19, 21, 20)
df2 <- data.frame(gender, school, age)
df2
ggplot(data = df2, aes(x = gender, fill = gender)) +
geom_bar() +
facet_grid(.~ school)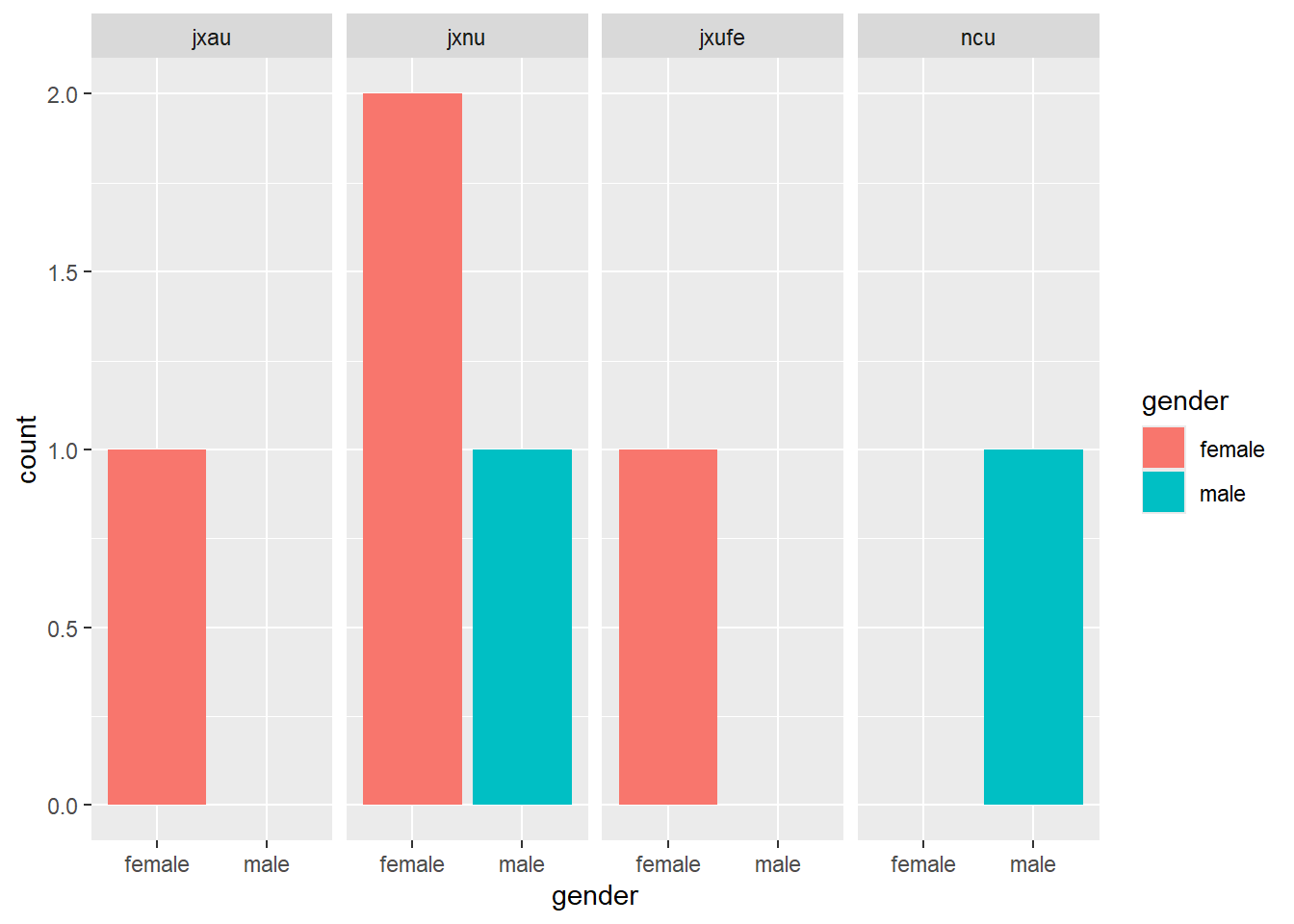
通过调整 factor 对象的levels顺序可以实现对图像的快速重新排序:
gender <- factor(c("female", "male", "female", "male", "female", "female"))
school <- factor(c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"))
age <- c(18, 20, 19, 19, 21, 20)
df2 <- data.frame(gender, school, age)
df2$school <- factor(df2$school, levels = c("jxnu", "ncu", "jxufe", "jxau"))
df2
ggplot(data = df2, aes(x = gender, fill = gender)) +
geom_bar() +
facet_grid(.~ school)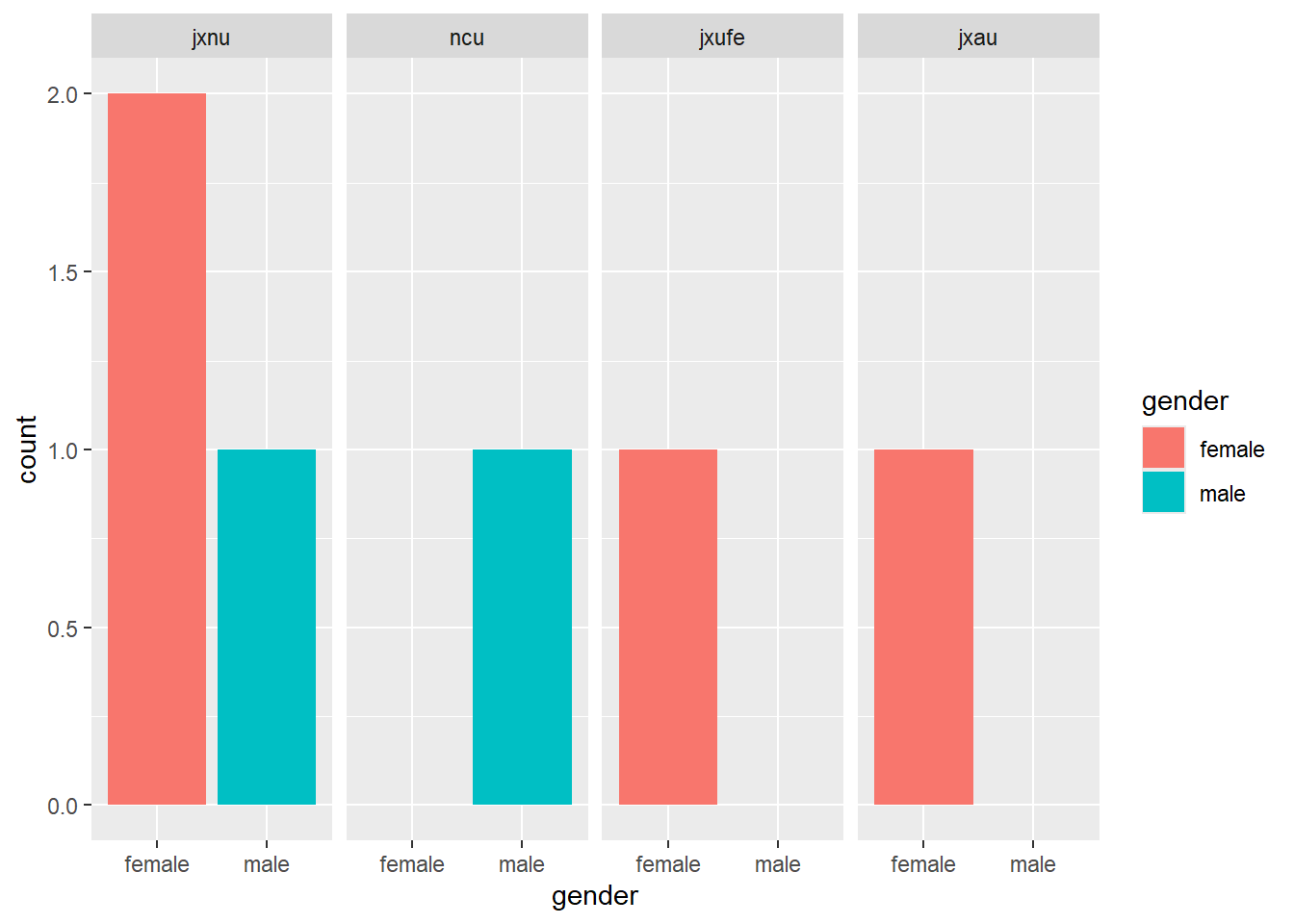
6.3 Data frame
Data.frame 在 R 中的运用非常之广,原因就在于它既符合我们对于数据的矩阵式(行、列)呈现方式的直觉理解,又具备 list 同时储存 element type 不同的 atomic vector 的灵活性。data.frame可以视作是多个同样长度、但 element type 不尽相同的 atomic vector 横向合并在一起,如下图所示:
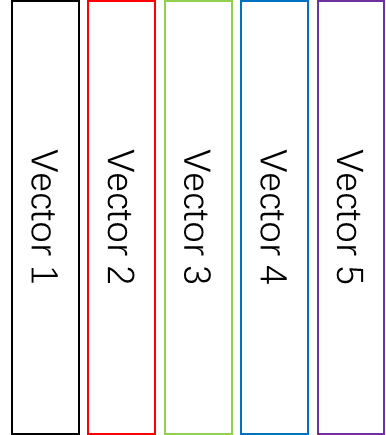
data.frame 相比于 vector,多了(col)names,row.names,class3 个 attributes。
6.3.2 Generic attributes: names and row names
例如使用data.frame()创建 data.frame object:
df2 <- data.frame(
c("female", "male", "female", "male", "female", "female"),
c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"),
c(18, 20, 19, 19, 21, 20)
)
df2
attributes(df2)#> $names
#> [1] "c..female....male....female....male....female....female.."
#> [2] "c..jxnu....ncu....jxnu....jxnu....jxufe....jxau.."
#> [3] "c.18..20..19..19..21..20."
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5 6从例子里可以看出,data.frame 有别于其他 structure type,只要生成一个 data.frame 的 object,就一定会有与 name 有关的 attribute ——names和row.names,其他 structure type 不指定就为NULL。并且,如果不指定,就会自动生成,其中row.names使用的是行数,names使用的是转换成 character 后的原始value(转换时,所有非字母内容都会被转换成.)。
# 1
df2 <- data.frame(
gender = c("female", "male", "female", "male", "female", "female"),
school = c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"),
age = c(18, 20, 19, 19, 21, 20)
)
df2
attributes(df2)#> $names
#> [1] "gender" "school" "age"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5 6
# 2
# 1
df2 <- data.frame(
c("female", "male", "female", "male", "female", "female"),
c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"),
c(18, 20, 19, 19, 21, 20)
)
names(df2) <- c("gender", "school", "age")
df2
attributes(df2)#> $names
#> [1] "gender" "school" "age"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5 6
# 3
gender <- c("female", "male", "female", "male", "female", "female")
school <- c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau")
age <- c(18, 20, 19, 19, 21, 20)
df2 <- data.frame(gender, school, age)
df2
attributes(df2)#> $names
#> [1] "gender" "school" "age"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5 6因为 data.frame 有着和 matrix 一样的数据呈现方式,所以,也可以使用dimnames(),
df2 <- data.frame(
c("female", "male", "female", "male", "female", "female"),
c("jxnu", "ncu", "jxnu", "jxnu", "jxufe", "jxau"),
c(18, 20, 19, 19, 21, 20)
)
dimnames(df2) <- list(
c("1", "2", "3", "4", "5", "6"),
c("gender", "school", "age")
)注意,当创建 data.frame 时使用的 vectors 长度不一致时,回收法则(recycling rule,详见“值、结构类型的转换”章节中的注意事项部分)会发挥作用,例如:
data.frame(x = c(1, 2), y = c("a", "b", "c", "d"))当长 vector 的长度不是短 vector 的长度的整数倍时,无法创建 data.frame,例如:
data.frame(x = c(1, 2, 3), y = c("a", "b", "c", "d"))#> Error in data.frame(x = c(1, 2, 3), y = c("a", "b", "c", "d")): arguments imply differing number of rows: 3, 46.3.3 List in data.frame (optional)
因为 data.frame 可以视作多个独立且等长的 vectors 横向拼接起来,而 list 本质是 vector,所以 data.frame 中的 column 也可以是 list:
records <- data.frame(ID = 1:2, gender = c("female", "male"))
records$scores <- list(
data.frame(
t1 = sample(5, 10, replace = TRUE),
t2 = sample(5, 10, replace = TRUE),
t3 = sample(5, 10, replace = TRUE)
),
data.frame(
t1 = sample(5, 10, replace = TRUE),
t2 = sample(5, 10, replace = TRUE),
t3 = sample(5, 10, replace = TRUE)
)
)
str(records)#> 'data.frame': 2 obs. of 3 variables:
#> $ ID : int 1 2
#> $ gender: chr "female" "male"
#> $ scores:List of 2
#> ..$ :'data.frame': 10 obs. of 3 variables:
#> .. ..$ t1: int 2 3 2 5 1 4 3 1 2 5
#> .. ..$ t2: int 2 1 4 1 2 4 2 5 2 1
#> .. ..$ t3: int 3 5 1 1 3 2 5 4 2 1
#> ..$ :'data.frame': 10 obs. of 3 variables:
#> .. ..$ t1: int 3 3 3 4 3 4 4 2 4 2
#> .. ..$ t2: int 3 3 5 1 4 3 4 1 5 2
#> .. ..$ t3: int 5 2 4 5 2 1 1 5 5 4
records
# try View(records) in console6.4 Recap
- vector 是 R 最基础的 structure type;
- 各种 structure type 的 attribute :
| attributes | vector | matrix | array | list | factor | data.frame |
|---|---|---|---|---|---|---|
| 与 name 有关的 | 可有names
|
可有dimnames
|
可有dimnames
|
可有names
|
可有names
|
必有(col)names和row.names
|
操作与 name 有关attributes时使用的function
|
names() |
colnames()和rownames(),或dimnames()
|
dimnames() |
names() |
names() |
names()和row.names(),或 dimnames(),或 colnames()和rownames()
|
| 与 dimension 有关 | 必有dim
|
必有dim
|
||||
与 class有关 |
必有factor
|
必有data.frame
|
||||
| 独有的 | 必有levels
|
-
names(),dimnames(),colnames(),rownames(),row.names()都可以用来获取和更改 object 与 name 有关的 attribute; - 使用
NULL清空某与 name 有关 attribute(data.frame 则是恢复默认 name); - 各种 structure type 的生成 function:
| 生成 function | vector | matrix | array | list | factor | data.frame |
|---|---|---|---|---|---|---|
c(), vector()
|
matrix() |
array() |
list(),vector()
|
factor() |
data.frame() |
- data.frame 和 list 中的 element 可以是不同的 element type;
- list 的本质是 vector;
- data.frame 的本质是 list;
- factor 的
levels是有大小顺序的,只要是需要调整统计分析结果中不同组别的呈现顺序,第一时间要想到用 factor。