8 Basic: read and write
进入互联网时代以后,数据的读取和写入就越来越频繁地进入到日常生活中。最常见的读取数据情境就是各种各样的“loading”——加载动画。加载动画实际上就是开发者为了解决读取数据需要时间,而这段时间内用户无法进行任何操作,只能干等的问题。加载动画一方面将读取数据的进度以进度条的方式告诉用户,让用户可以大致预期剩余的等待时间,另一方面也不至于太无聊。
虽然 R 的使用场景更多是与数据统计分析打交道,可能不会用到加载动画,但是数据读取是绝对高频的任务类型。可以说数据的读取和写入在 R 中是一项必不可少的技能。
如果是使用现成的统计分析软件分析数据,在导入数据的时候会是如下所示(视频截取自spss之问卷数据导入分析(基于问卷星)):
使用 R ,就是把上面鼠标点击各种菜单的操作改成写代码而已,每一个操作在使用 R 写代码时都有对应的概念,例如:
- 工作路径;
- 文件后缀名;
- 文件路径;
- 从第一行数据读取变量名,等等。
8.1 working directory
工作路径(working directory, wd),是 R 中与本地数据的读取和写入操作紧密联系的概念。
Working directory 可以简单理解为 R 工作时默认使用的文件路径,使用getwd()可以查看。
getwd()#> [1] "F:/Nutstore backup/R/codes/RBA"根据日常使用计算机的经验可以知道,想要打开任何文件都需要知道这个文件存储在计算机中的具体位置,哪个盘、哪个文件夹下、叫什么名字,这就是文件路径。同样的,如果通过使用读取和写入 function 的方式“指挥” R 来完成相应操作时,也需要知道读取和写入的目标文件的文件路径。正是因为 R 有 Working directory 这一概念,使得读取和写入时所需的文件路径有两种写法,绝对路径和相对路径:
read.table(file = "F:/Nutstore backup/R/codes/RBA/data/m1.txt") # absolute path
# equivalent to
read.table(file = "data/m1.txt") # the missing part will be automatically supplied by R using working directory
read.table(file = "/data/m1.txt") # for 2nd order subfolder, start relative path with / won't work8.1.1 Setworking directory
R 在每次打开时(打开 Rstudio 时,Rstudio 会自动打开 R )都会设定一个 working directory,根据具体情况的不同,working directory 不一样:
- Rstudio 默认 working directory。通过双击 Rstudio 的快捷方式打开 R 时,会自动将 Rstudio 的安装路径作为默认 working directory,

- xxx.R。在没有打开 Rstudio 和 R 的情况下,通过双击 xxx.R 的方式打开 Rstudio 时,会将该脚本所在文件目录作为默认 working directory,例如在 D 盘的根目录下有一个 R 的脚本 Hello World.R,双击后会自动打开 Rstudio,此时的 Working directory 就是
D:/
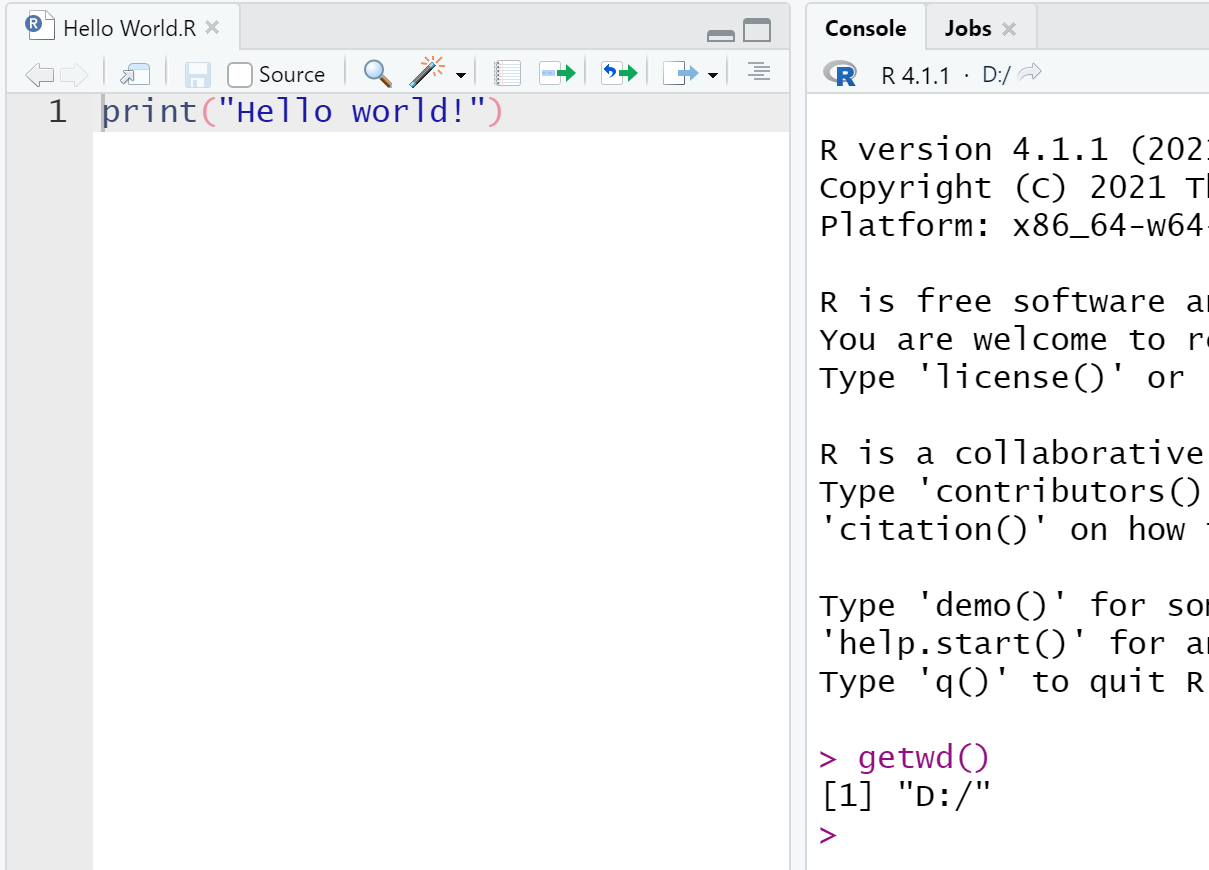
- xxx.Rproj(推荐)。通过双击 xxx.Rproj 的方式打开 Rstudio,会默认将该 .Rproj 文件所在文件目录作为默认 working directory,xxx.Rproj 对应一个 project,例如在 D:/Hello World 文件夹下创建一个 project,Rstudio 就会自动创建一个 Hello World.Rproj,双击该文件会自动打开 Rstudio
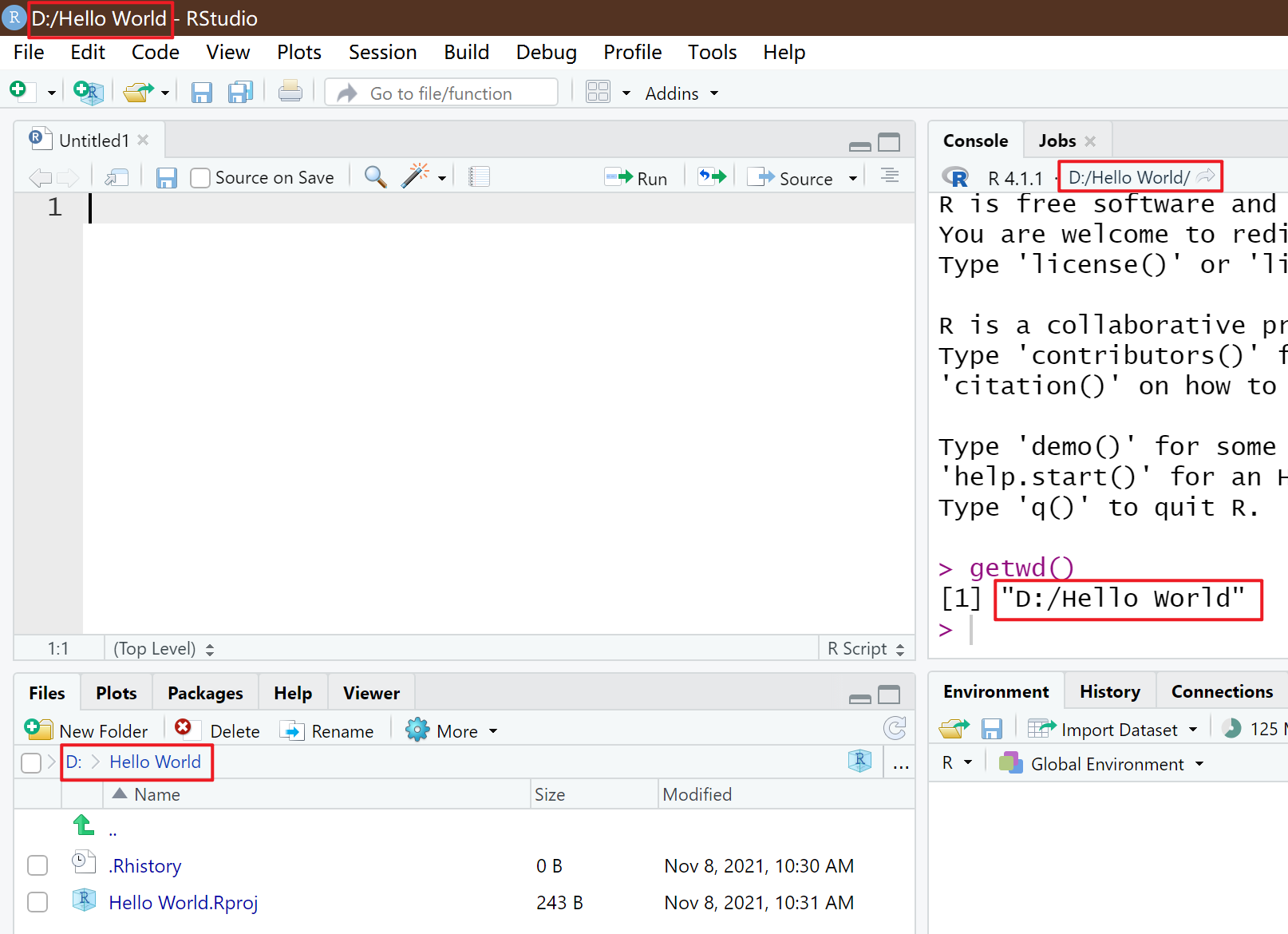
在已经打开的 Rstudio 中,也可以通过setwd()改变当前的 working directory(不推荐):
# wd_old <- getwd()
wd_new <- "D:/data"
setwd(wd_new)
read.table("test/what/m1.txt")
# getwd()
# setwd(wd_old)
# getwd()8.1.2 Recommended combo for collaboration: Working directory + relative path
可以看到,如果是使用相对路径, R 就一定会使用 working directory 来补全出一个完整的文件路径。这样可以方便写代码时偷懒。使用绝对路径的好处是只要给出准确的路径信息, R 就一定能找到对应的文件,但是缺点是代码在其他计算机上运行的时候就可能会报错。但如果使用相对路径,就可以实现在不同的计算机上运行同一个读取\写入本地文件的代码时不会报错。
# Coder A
setwd("D:/R")
read.table(file = "data/m1.txt")
# will work as long as the file is stored in the "data" folder
# in the working directory, no matter what the working directory is
# Coder B
setwd("F:/Rfiles/project202201")
read.table(file = "data/m1.txt")
# will work as long as the file is stored in the "data" folder
# in the working directory, no matter what the working directory is8.2 Read and write regular data
在日常生活中处理的数据大多数都是以矩阵的形式呈现的,姑且称具有矩阵形式的数据为常规数据,代表性的 structure types 有 vector,matrix,data.frame;称非矩阵形式的数据为非常规数据,代表性的 structure types 有 list 和 array。本小节先学习常规数据的读取和写入。
8.2.1 Read
读取常规数据的 function 遵循 3 条普遍规律:
- 大多数都是
read.xxx()或read_xxx()这种命名方式,其中xxx为所读取数据文件的扩展名。
在 win 10 中可以通过如下方式开启显示文件的扩展名选项,如下图所示:

主流数据文件类型及其对应扩展名如下:
| 文件类型 | 扩展名 |
|---|---|
| 纯文本型数据文件 | .txt .dat |
| 逗号分隔值文件 | .csv |
| Excel 工作表 | .xls .xlsx |
- 大多数读取常规数据的 function 的使用格式都是
read.xxx(filepath, arg)。其中filepath是文件路径,例如要读取的数据文件是”1.txt”,放在 D 盘根目录下的 data 文件夹,那么filepath = "D:/data/1.txt( R 的文件路径中不同层级文件夹之间用的是“/“,而 Windows 10 中用的是“//”,注意区别);arg是一些额外的 argument,可以视作是读取数据时增加的一些限制,以保证读进来的数据和预期是一样的。 - R 中绝大部分读取常规数据的 function 会将读取的数据自动转换成 data.frame。
下面将通过一些例子来分别演示如何使用 function 来读取不同文件类型,以及这些 function 是如何遵顼上述三条规律的。
- .txt 和 .dat
数据如下:

读取代码为:
data_txt <- read.table(file = "F:/Nutstore backup/R/codes/RBA/data/txt_example.txt")
data_txt
is.data.frame(data_txt)#> [1] TRUE
data_dat <- read.table(file = "F:/Nutstore backup/R/codes/RBA/data/txt_example.dat")
data_dat
is.data.frame(data_dat)#> [1] TRUE- .xls 和 .xlsx
数据如下:
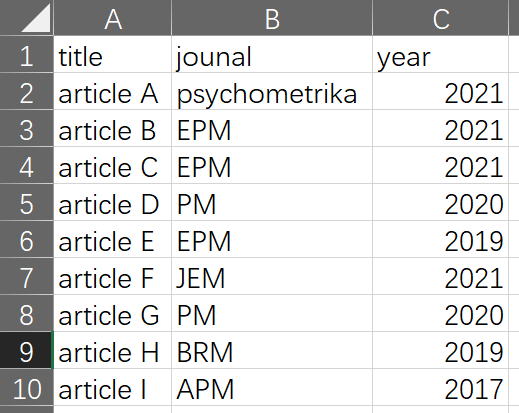
读取代码为:
#> Warning: package 'openxlsx' was built under R version 4.3.3
data_xlsx <- read.xlsx(xlsxFile = "F:/Nutstore backup/R/codes/RBA/data/xlsx_example.xlsx")
data_xlsx
is.data.frame(data_xlsx)#> [1] TRUE- .csv
.csv 是一种通用的纯文本文件格式,可以将 .xlsx 文件通过另存为的方式转存成 .csv 文件,如下图:
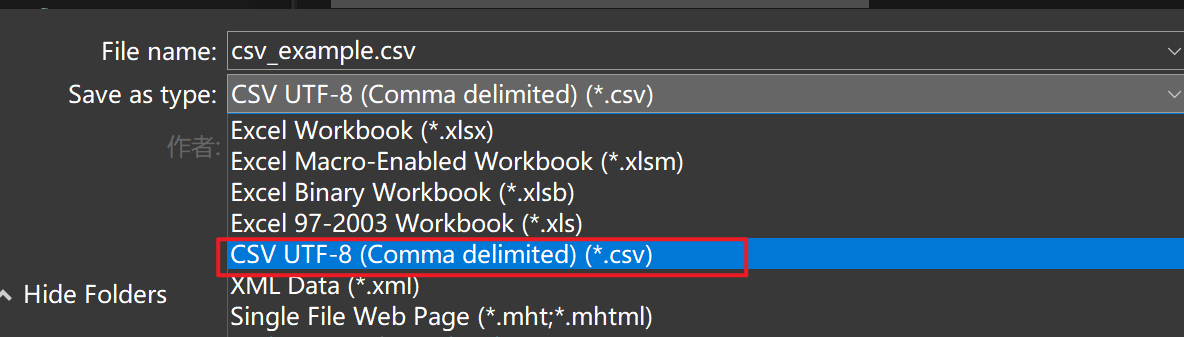
由于 .csv 是纯文本文档,所以读取和写入速度要比 .xlsx 文档更快,通常会将 .xlsx 文件通过另存为的方式转存成 .csv 文件再处理。下面是读取 .csv 文档示例,数据和上面 .xlsx 的例子是一样的,代码如下:
data_csv <- read.csv(file = "F:/Nutstore backup/R/codes/RBA/data/csv_example.csv")
data_csv
is.data.frame(data_csv)#> [1] TRUE8.2.2 Read: extra arguments
上面是读取常规数据 function 的最基本用法。如果数据本身的情况比较复杂,就需要在读取的时候给 function 提供额外的 argument,来保证读取进来的数据符合预期,下面来看两个例子。
- 有明确分隔符的纯文本数据文件
数据如下图所示,可以看出,每一行中每个值之间是通过,来分隔的,
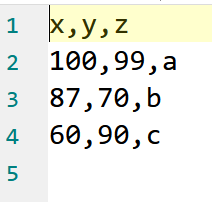
# 不加任何额外 argument
data_txt_com <- read.table(file = "F:/Nutstore backup/R/codes/RBA/data/txt_example_complicated.txt")
data_txt_com
# 增加一个额外 argument, header = TRUE,意即数据文件中第一行为变量名
data_txt_com <- read.table(
file = "F:/Nutstore backup/R/codes/RBA/data/txt_example_complicated.txt",
header = TRUE
)
data_txt_com
# 在 header = TRUE 的基础上再增加一个额外argument, sep = ",",意即数据文件中每一行的元素是由“,”分隔
data_txt_com <- read.table(
file = "F:/Nutstore backup/R/codes/RBA/data/txt_example_complicated.txt",
header = TRUE,
sep = ","
)
data_txt_com- 固定长度的纯文本数据文件
从之前介绍读取 .txt 和 .dat 文件的 function 时使用的例子可以看出,read.table()不加任何 argument 时读取的结果和预期并不一样,比如把变量名读作了数据,又比如本该分开的三列数据都合在了一起,那么该怎么办?让我们顺着上一个例子的思路,试试给read.table()增加额外的 argument,
data_txt <- read.table(
file = "F:/Nutstore backup/R/codes/RBA/data/txt_example.dat",
header = TRUE,
sep = ""
)
data_txt还是不行,难道是sep = ""没有发挥作用么?去看看read.table()的帮助文档,如下图所示:
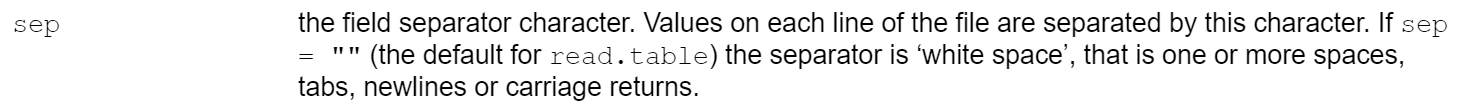
原来sep = ""发挥了作用,但是和我们想象的不一样。所以,可以判定read.table()这条路是走不通的。那该怎么办?我的尝试步骤如下:
- 观察一下原始数据文件,里面每一列的宽度都是固定的,那么可不可以考虑按照宽度来读取数据?
- 在
read.table()的帮助文档里面搜素一下,有没有和宽度(width)相关的内容,只有一处,提到了read.fwf(),如下图所示:
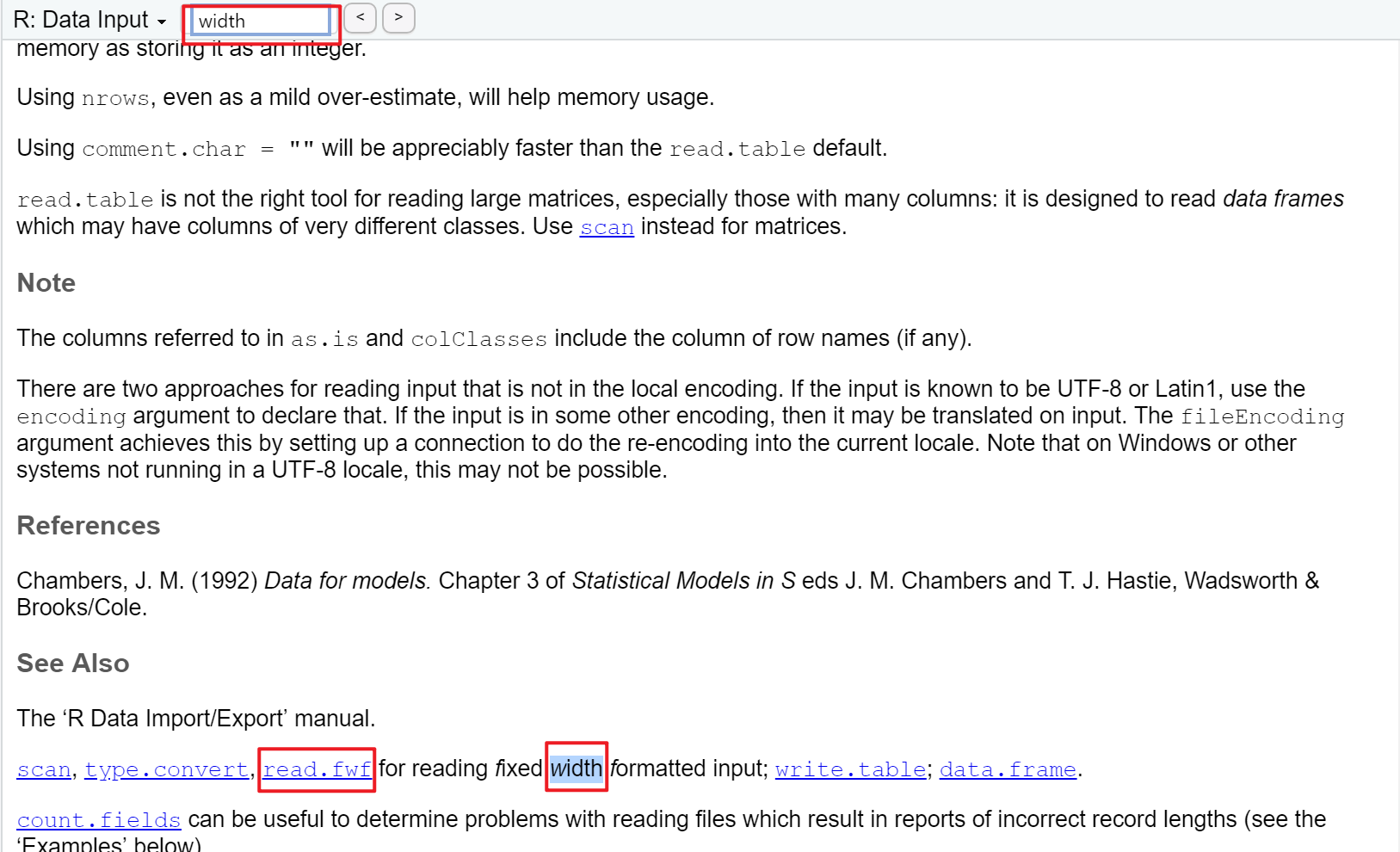
- 但我还是不死心,不想去学新的 function,就想用
read.table()搞定,去网上搜一下试试看,关键词为“read.table width”打开一个 stackoverflow 上的回答:Read fixed width text file,大意是提问者想请高人帮忙写代码读取如下数据(截取前几行展示):
Weekly SST data starts week centered on 3Jan1990
Nino1+2 Nino3 Nino34 Nino4
Week SST SSTA SST SSTA SST SSTA SST SSTA
03JAN1990 23.4-0.4 25.1-0.3 26.6-0.0 28.6 0.3
10JAN1990 23.4-0.8 25.2-0.3 26.6 0.1 28.6 0.3
17JAN1990 24.2-0.3 25.3-0.3 26.5-0.1 28.6 0.3
24JAN1990 24.4-0.5 25.5-0.4 26.5-0.1 28.4 0.2
31JAN1990 25.1-0.2 25.8-0.2 26.7 0.1 28.4 0.2高赞回答如下:
x <- read.fwf(
file = url("http://www.cpc.ncep.noaa.gov/data/indices/wksst8110.for"),
skip = 4,
widths = c(10, 9, 4, 9, 4, 9, 4, 9, 4)
)其中,skip = 4表示读取时跳过头 4 行,widths = c(10, 9, 4, 9, 4, 9, 4, 9, 4)表示一共有 9 列数据,数字对应当前列数据的宽度。把读取固定宽度的数据想象成切菜,宽度的计算就好理解了。
下面截取一行数据来讲解宽度的计算,如下图所示:
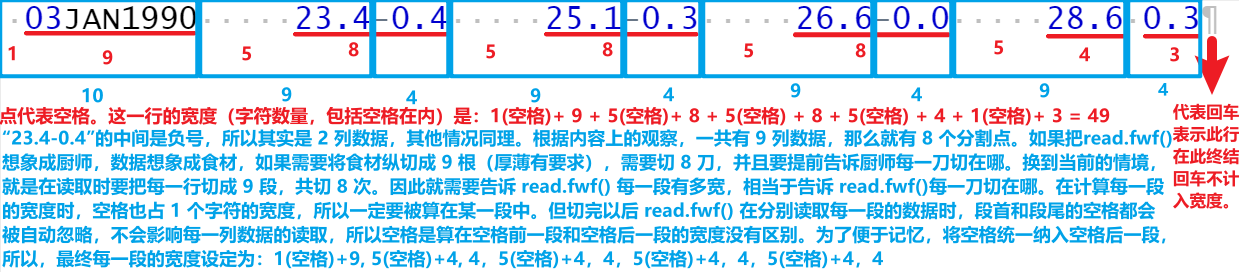
所以,搜索的结论是,必须彻底抛弃read.table(),转向read.fwf()。模仿高赞回答,尝试使用如下代码:
data_txt <- read.fwf(
file = "F:/Nutstore backup/R/codes/RBA/data/txt_example.dat",
widths = c(1,1,1),
skip = 1,
col.names = c("x", "y", "z")
)
data_txt8.2.3 Fun fact: read table is everywhere
read.csv()和read.fwf()最终都是调用read.table(),相当于read.table()加了个壳。
8.2.4 Write
与读取 function 类似,绝大多数写入数据的 function 也遵循 2 条普遍规律:
- 都以
write.xxx()或write_xxx()的方式命名,其中xxx是文件扩展名; - 使用格式都是
write.xxx(data, filepath, arg),其中data是 R 中将要写入文件的object,filepath和arg与读取function中的理解一致。
- .txt
#> Tom Jerry
#> [1,] 99 97
#> [2,] 98 96
write.table(m1, file = "F:/Nutstore backup/R/codes/RBA/data/m1.txt")写入的文件内容如下图所示:
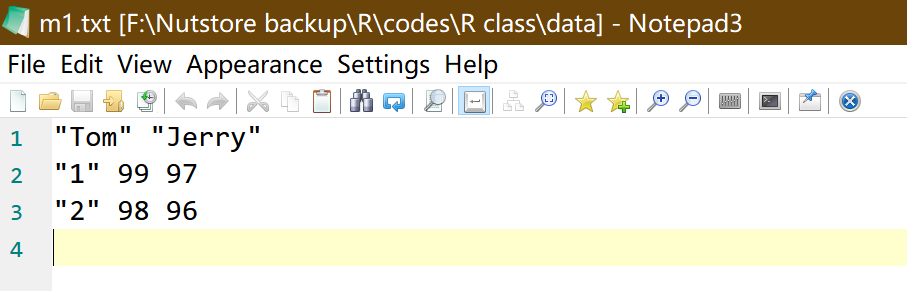
- .xlsx
library(openxlsx)
m1 <- matrix(c(99, 98, 97, 96), nrow = 2, ncol = 2)
colnames(m1) <- c("Tom", "Jerry")
m1#> Tom Jerry
#> [1,] 99 97
#> [2,] 98 96
write.xlsx(m1, file = "F:/Nutstore backup/R/codes/RBA/data/m1.xlsx")写入的文件内容如下图所示:
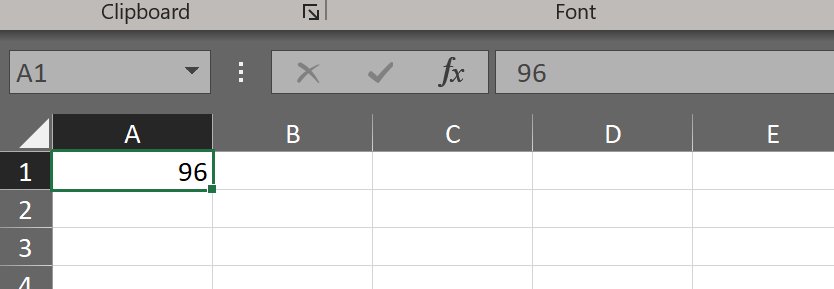
结果有问题,去write.xlsx()的帮助文档找找线索,如下图所示,

原来write.xlsx()要求数据必须是data.frame,那把数据转换成data.frame再试试看,代码如下:
library(openxlsx)
m1 <- matrix(c(99, 98, 97, 96), nrow = 2, ncol = 2)
colnames(m1) <- c("Tom", "Jerry")
write.xlsx(
as.data.frame(m1),
file = "F:/Nutstore backup/R/codes/RBA/data/m1.xlsx"
)写入的文件内容如下图所示:
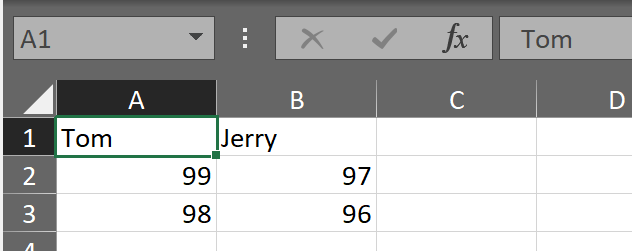
实际使用的过程中,常常是面临一个数据读取或写入的任务,文件格式已知,该怎么办?解决思路:
- 搜索:以“R” + “read”或“write” + “文件格式”或“软件名”为关键词,搜索合适的 function,如“R read SPSS”或“R write SPSS”通常能够搜索到带例子的解答;
- 通常第一步就能解决问题,如果觉得还不够清楚,可以仔细读 function 的帮助文档,里面有关于搜到的 function 的所有说明。
这种简单的问题,也可以直接问 ChatGPT 类工具。
8.2.5 Recap
- 读取数据的 function 常为
read.xxx()或read_xxx(),使用格式为read.xxx(filepath, arg),读取结果通常为 data.frame; - 写入数据的 function 常为
write.xxx()或write_xxx(),使用格式为write.xxx(data, filepath, arg); - 文件格式及对应的读取和写入 function 如下:
| 文件格式 | 读取 function | 写入 function |
|---|---|---|
| .txt .dat |
read.table() read.fwf()
|
write.table() |
| .xls .xlsx, | 如openxlsx包的read.xlsx()
|
write.xlsx() |
| .csv | read.csv() |
write.csv() |
-
filepath最好使用工作路径+相对路径,便于与他人协作,并且一定要在路径中包含目标文件的扩展名; - 根据数据的实际情况决定到底要不要在读取或写入的 function 中使用额外的 argument,可以通过搜索网上的示例或查看所使用 function 的帮助文档来确定。
8.3 Read and write irregular data
以上读取和写入 function 都是适用于常规数据,但是非常规数据该怎么办?例如:
- 在 R 中,像 list 这种包罗万象的 structure type 十分常用,该怎么读取和写入 list object?
- array 通常是三维甚至更高的维度,也不是二维矩阵形式,又该怎么读取和写入 array object?
非常规数据的读取和写入,是本小节的重点。请注意,此处说到的读取和写入,特别是写入,是指在保留 object 原始数据结构的条件下的读取和写入。这是因为,任何的 list object 都可以将每个元素拆分独立的、矩阵形式的数据,然后分别写入,但这样做原始的数据结构就被打乱了,并且读取的时候也会更麻烦。例如:
l1 <- list(
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
write.table(l1[[1]], file = "F:/Nutstore backup/R/codes/RBA/data/l1_1.txt")
write.table(l1[[2]], file = "F:/Nutstore backup/R/codes/RBA/data/l1_2.txt")
write.table(l1[[3]], file = "F:/Nutstore backup/R/codes/RBA/data/l1_3.txt")
write.table(l1[[4]], file = "F:/Nutstore backup/R/codes/RBA/data/l1_4.txt")
write.table(l1[[5]], file = "F:/Nutstore backup/R/codes/RBA/data/l1_5.txt")保留非常规数据原始数据结构的读取和写入 function 如下:
| 写入 | 读取 |
|---|---|
saveRDS(), save(), save.image()
|
readRDS(), load()
|
其中,saveRDS()和readRDS()是用于写入和读取单个 object,剩下的都是用于读取和写入多个 object。
8.3.1 Single object
l1 <- list(
list(1, 2, 3),
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
str(l1)#> List of 7
#> $ :List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ : int [1:3] 1 2 3
#> $ : chr "a"
#> $ : logi [1:3] TRUE FALSE TRUE
#> $ : num 2.3
#> $ : logi [1:3] NA NA NA
#> $ : num [1:2, 1:2] 1 2 3 4
# 注意文件扩展名 .rds
saveRDS(l1, file = "F:/Nutstore backup/R/codes/RBA/data/l1.rds")
file.exists("F:/Nutstore backup/R/codes/RBA/data/l1.rds")#> [1] TRUE
file.size("F:/Nutstore backup/R/codes/RBA/data/l1.rds")#> [1] 1328.3.2 Multiple objects
l1 <- list(
list(1, 2, 3),
c(1L, 2L, 3L),
"a",
c(TRUE, FALSE, TRUE),
c(2.3),
c(NA, NA, NA),
matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
)
str(l1)#> List of 7
#> $ :List of 3
#> ..$ : num 1
#> ..$ : num 2
#> ..$ : num 3
#> $ : int [1:3] 1 2 3
#> $ : chr "a"
#> $ : logi [1:3] TRUE FALSE TRUE
#> $ : num 2.3
#> $ : logi [1:3] NA NA NA
#> $ : num [1:2, 1:2] 1 2 3 4#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 9 11
#> [2,] 10 12
# 注意,文件扩展名是 .RData
save(l1, a1, file = "F:/Nutstore backup/R/codes/RBA/data/l1_a1.RData")
file.exists("F:/Nutstore backup/R/codes/RBA/data/l1_a1.RData")#> [1] TRUE
file.size("F:/Nutstore backup/R/codes/RBA/data/l1_a1.RData")#> [1] 185从上述两个例子就可以看出非常规数据的读取和写入 function 之间的细微区别:
-
saveRDS()和save():saveRDS()只保存了单个 object 的 value,而save()保留了指定 object 的完整信息,包括 name 和 value。 -
readRDS()和load():readRDS()读取的是一个没有 name 的 value,如果不使用x <- value的语句给读取进来的 anonymous object 取名字,那么读取的结果只会呈现在 Console 中,不会进入 global environment;load()读取的是完整的 name + value 的一个 object,读取的结果不会呈现在 Console 中,会直接进入 global environment。
注意:使用load()时,如果读取的 object 和 global environment 中的某个 object 同名,那么读取进来的 object 会覆盖掉原有的 object,例如:
#> [1] "not the same"
load(file = "F:/Nutstore backup/R/codes/RBA/data/a.RData")
a#> [1] 1 2 3save.image()可以视作是save()的一种特殊写法,保存的是当前整个工作空间(working space)或工作环境(working environment)中所有的 object,即 global environment。与save.image()匹配的读取 function 也是load()。
# need to be copied to Rstudio for testing due to environment issue in learnr::tutorial
a <- 1
b <- 2
c <- 3
ls() # 列出 Global environment 里面所有的 object#> [1] "a" "a1" "b"
#> [4] "c" "data_csv" "data_dat"
#> [7] "data_txt" "data_txt_com" "data_xlsx"
#> [10] "df" "df1" "l1"
#> [13] "m1" "var_chr" "var_dbl"
#> [16] "var_exp" "var_int" "var_lgl"
#> [19] "var_na" "var_null"#> [1] 20
name_objects <- ls()
# 注意,文件扩展名和 save() 一样,都是 .RData
save.image(file = "F:/Nutstore backup/R/codes/RBA/data/current_workspace.RData")
file.exists("F:/Nutstore backup/R/codes/RBA/data/current_workspace.RData")#> [1] TRUE
file.size("F:/Nutstore backup/R/codes/RBA/data/current_workspace.RData")#> [1] 3559
rm(list = ls())
load(file = "F:/Nutstore backup/R/codes/RBA/data/current_workspace.RData")
name_objects_recover <- ls()
name_objects == name_objects_recover#> Warning in name_objects == name_objects_recover: longer
#> object length is not a multiple of shorter object length#> [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [10] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
#> [19] FALSE FALSE FALSE当然,不难看出,上面介绍的非常规数据的读取和写入 function 实际上可以用于 R 中任意 object,既可用于非常规数据(list,高维 array),又可用于常规数据(vector,matrix,data.frame)。只是针对常规数据,用read.xxx()和write.xxx()要比用save()和load()更自然、更普遍。