12 Basic: control flow
到目前为止,本课程中写过的所有代码都是线性执行的,即按从头到尾的顺序执行所有语句。只使用这种线性执行的代码,可以编写一些非常简单的程序,这种写法可以视作是不对代码的执行顺序做任何人为的控制。
简单来讲,控制流(control flow)就是控制代码的流程,通过一定方式人为控制代码执行的顺序。Control flow 能够极大地增加代码的功能性,是现代编程语言的经典成分,绝大多数编程语言中都有控制流的模块。
Control flow 可以分为 conditional flow (条件流)和 loop (循环)两大类。
(本节内所有的流程图都来自GeeksforGeeks)
12.1 Conditional flow
12.1.1 if else
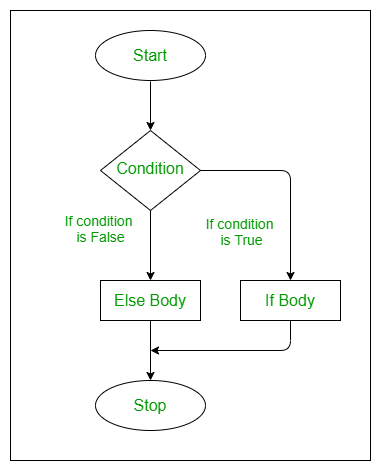
基本语法结构
if (cond) {
cons.expr
} else {
alt.expr
}如果cond的结果是TRUE,执行cons.expr,反之则执行alt.expr。cond通常都是 relational operator 的结果,或者是is.xxx()类 function 的结果。cond的执行结果要求是长度为 1 的 logical vector,如果长度超过 1,执行时会得到一个 error,详见12.1.1.3。
age <- 12
# age <- c(11, 12)
if (age < 12) {
"elementary school"
} else {
"middle school"
}#> [1] "middle school"当expr很简短时,{}可省略不写:
if (cond) cons.expr else alt.expr例如:
input <- 1
if (input == 2) "yes" else "no"#> [1] "no"在 Rstudio 中可以通过 Snippets 的功能快速输入if else结构:
有一个小细节是需要额外注意的,在if结构中,cond必须是长度为 1 的logical vector(即TRUE或FALSE),或者是可以被强制转换成logical的atomic vector。
if (1) "1"#> [1] "1"
if ("1") "1 as character"#> Error in if ("1") "1 as character": argument is not interpretable as logical
if (NULL) "NULL"#> Error in if (NULL) "NULL": argument is of length zero
if (Inf) "Inf"#> [1] "Inf"
if (-Inf) "-Inf"#> [1] "-Inf"
if (NaN) "NaN"#> Error in if (NaN) "NaN": argument is not interpretable as logical
if (NA) "NA"#> Error in if (NA) "NA": missing value where TRUE/FALSE needed所以,一个容错率更高的写法是使用isTRUE()来处理cond:
if (isTRUE("1")) "1 as charecter"
if (isTRUE(NULL)) "NULL"
if (isTRUE(NaN)) "NaN"
if (isTRUE(NA)) "NA"if else 有以下 4 种情况:
12.1.1.1 Single cond without else
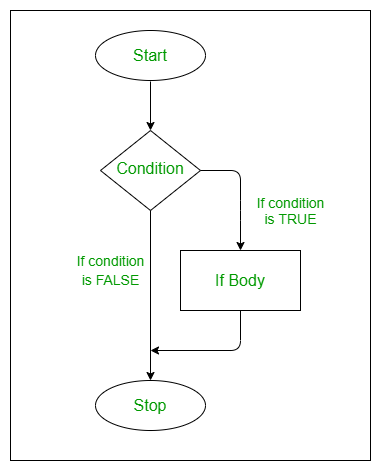
如果不需要else部分,可以简化为:
if (cond) {
expr
}当expr很简短时,省略{}:
if (cond) cond.expr例如:
input <- 1
if (input == 1) "yes"#> [1] "yes"
12.1.1.2 Multiple conds with else if
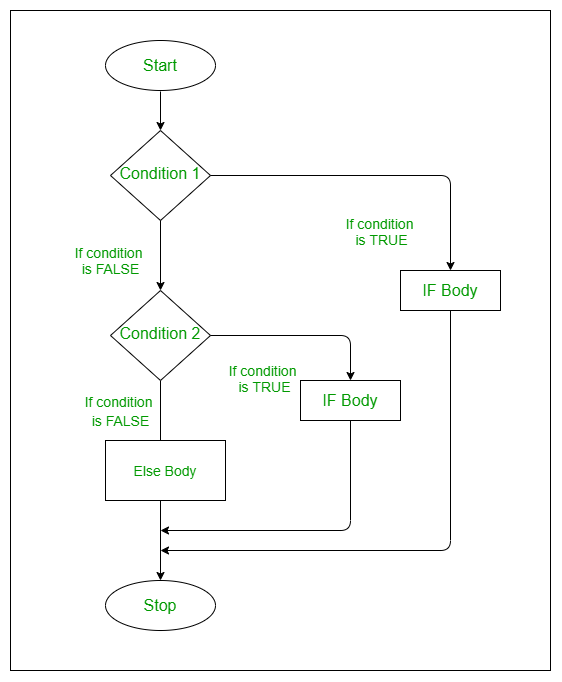
if (cond1) {
cond1.expr
} else if (cond2) {
cond2.expr
} else if (cond3) {
cond3.expr
}例如:
input <- 1
if (input == 1) {
"a"
} else if (input == 2) {
"b"
} else if (input == 3) {
"c"
}#> [1] "a"但要注意,上面这段代码,如果input不是1,2,3这 3 个互斥条件中的任意一个,执行时不会有任何的提示,这种情况属于没有考虑到所有的可能,存在漏洞,容易出问题,建议改成以下写法:
input <- 4
if (input == 1) {
"a"
} else if (input == 2) {
"b"
} else if (input == 3) {
"c"
} else {
stop(paste("Exception encountered,", input, "does not satisfy any condition!"))
}#> Error: Exception encountered, 4 does not satisfy any condition!同样,也可以通过 Snippets 快速输入if else if结构:
12.1.1.3 Complex cond
if结构中的cond可以是比较复杂的关系 + 逻辑运算的结果,具体又分为两种情况:
- 结果是长度为 1 的 logical vector
a <- 0
if (a > -3 & a < -1 || a > 1 & a < 3) {
"yes"
}- 结果是长度大于 1 的 logical vector
当cond的结果是长度大于 1 的 logical vector,在 4.2.0 以下版本的 R 中会得到一个 warning,例如
rnd <- runif(3)
rnd
if (rnd > 0.95) {
"you are awfully lucky"
}运行结果为
[1] 0.5021010 0.8256499 0.1971661
Warning message:
In if (rnd > 0.95) { :
the condition has length > 1 and only the first element will be used相同的代码在 4.2.0 及以上版本的 R 中,会得到一个 error,例如
因此,如果是需要依据cond中所有元素的对比结果来作出最终判断,那么正确的做法是运用all(cond)和any(cond)。如果cond中所有的值都是TRUE,那么all(cond)的结果为TRUE,反之则是FALSE。如果cond中所有的值都是FALSE,any(cond)的结果才是FALSE,反之都是TRUE。
rnd <- runif(3)
rnd#> [1] 0.1196355 0.3150620 0.6038464
if (all(rnd > 0.95)) {
"you are awfully lucky"
} else if (any(rnd > 0.95)) {
"you are lucky"
} else {
"sorry, you are out of luck"
}#> [1] "sorry, you are out of luck"
12.1.1.4 Vecterized if else: ifelse()
当需要针对一个 vector、matrix、array 或 data.frame 中的所有元素按照是否符合某种条件为依据统一处理时,建议使用ifelse(),是if else的向量化版本,其基本语法结构为:
ifelse(test, yes, no)其中,test是对某个输入 object 所有元素是否符合某种条件的检验(通常是 relational operation,详见 10.2.1,或isxx()),检验的结果是和该 object 同样大小的一个 logical object;yes是该 logical object 中TRUE对应的ifelse()返回值;no是FALSE对应的ifelse()返回值。yes和no必须和输入的 object 同样大小;如果不是,则会触发 recycling rule,(详见7.2.2),直至满足该限制。
例如:
#> [,1] [,2] [,3] [,4]
#> [1,] 51 94 6 53
#> [2,] 45 9 77 24
#> [3,] 1 68 60 81
#> [4,] 22 62 65 33#> [,1] [,2] [,3] [,4]
#> [1,] "odd" "even" "even" "odd"
#> [2,] "odd" "odd" "odd" "even"
#> [3,] "odd" "even" "even" "odd"
#> [4,] "even" "even" "odd" "odd"
# 等价于
# ifelse(
# m1 %% 2 == 0,
# matrix("even", nrow = 4, ncol = 4),
# matrix("odd", nrow = 4, ncol = 4)
# )
# 将所有奇数变成偶数,偶数维持不变
ifelse(m1 %% 2 == 0, m1, m1 + 1)#> [,1] [,2] [,3] [,4]
#> [1,] 52 94 6 54
#> [2,] 46 10 78 24
#> [3,] 2 68 60 82
#> [4,] 22 62 66 34
12.1.2 switch
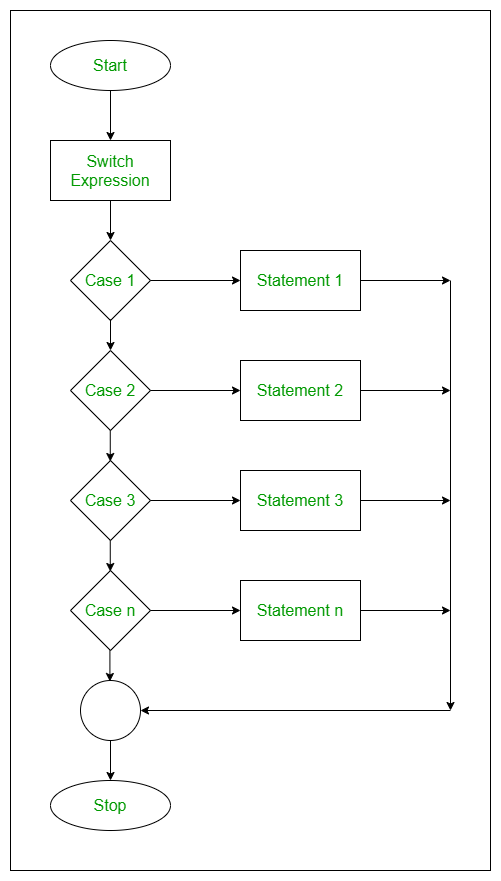
switch可以视作是多个cond的if结构的等价写法,其基本语法结构如下:
switch (
object,
case1 = expr1,
case2 = expr2,
...
)其中,object是一个长度为 1 的 vector,其不同的值对应不同的case。根据object究竟是不是 character string 又分成两种情况:
-
object是 character string,那么object的值会精确匹配case,swtich会执行匹配的case对应的expr,此时,所有的expr必须提供case作为 argument name,例如:
input <- "b"
switch(
input,
a = 1,
b = 2,
c = 3
)#> [1] 2此时,所有的expr必须提供case作为 argument name,否则就会报错,
input <- "b"
switch(
input,
1 + 1,
b = 2 + 2,
3 + 3
)#> Error: duplicate 'switch' defaults: '1 + 1' and '3 + 3'如果匹配到的case没有提供expr,则会顺延,直到下一个有expr的case,
input <- "b"
switch(
input,
a = 1,
b = ,
c = ,
d = 4
)#> [1] 4-
object是非 character string,会先被强制转换为 integer ,称之为object_int,转换的同时会输出一个 warning。假定一共有 n 个cases,如果object_int\(\in[1,n-1]\),那么swtich会执行第object_int个case对应的expr,不论该expr是否有提供case作为 argument name。
这种转换一般会发生在 element type 为 factor 的 object 上。要特别注意的是,factor 转换为 integer 时是根据 levels 来执行的,例如:
input <- factor(c("a", "b", "c"), levels = c("c", "b", "a"))
switch(
input[1],
a = "yo",
b = "hey",
c = "ha"
)#> Warning in switch(input[1], a = "yo", b = "hey", c = "ha"): EXPR is a "factor", treated as integer.
#> Consider using 'switch(as.character( * ), ...)' instead.#> [1] "ha"
# no argument name for all 3 exprs
input <- factor(c("a", "b", "c"), levels = c("c", "b", "a"))
switch(
input[1],
"yo",
"hey",
"ha"
)#> Warning in switch(input[1], "yo", "hey", "ha"): EXPR is a "factor", treated as integer.
#> Consider using 'switch(as.character( * ), ...)' instead.#> [1] "ha"
# equivalent to
input <- factor(c("a", "b", "c"), levels = c("c", "b", "a"))
switch(
input[1],
"1" = "yo",
"2" = "hey",
"3" = "ha"
)#> Warning in switch(input[1], `1` = "yo", `2` = "hey", `3` = "ha"): EXPR is a "factor", treated as integer.
#> Consider using 'switch(as.character( * ), ...)' instead.#> [1] "ha"
# number can not be directly used as argument name, has to be quotedswitch结构也可以通过 Snippets 快速键入:
12.2 Loop
Loop 结构包括三种,for,while和repeat。
12.2.1 for
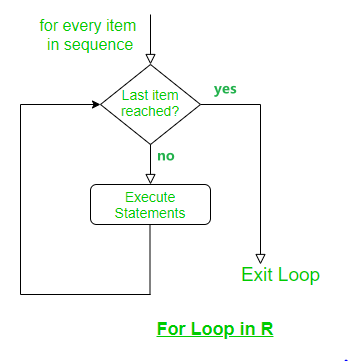
基本语法结构:
for(var in seq) {
expr
}例如:
#> [1] 3
#> [1] 100
#> [1] 10其中seq为c(3, 100, 10),表示一个长度为 3 的 vector,所有 elements 会根据位置上的先后顺序被 loop,第 1 次 loop 时会创建var,然后把seq的第 1 个 element (例子中为3)取出来赋值给var(例子中为i),再执行expr(例子中为print(i))。依次 loop 下去,直到seq的所有 elements 都被 loop 完毕(上述例子的seq长度为 3,所以会 loop 3 次)。
for结构也可以通过 Snippets 快速键入:
for结构有以下使用技巧\注意事项:
12.2.1.1 seq can be any subsettable object
# character vector
df <- data.frame(
score_last = c(100, 88, 93),
score_current = c(99, 96, 77)
)
for (i in names(df)) {
print(i)
print(mean(df[, i]))
}#> [1] "score_last"
#> [1] 93.66667
#> [1] "score_current"
#> [1] 90.66667
# numeric vector
df <- data.frame(
score_last = c(100, 88, 93),
score_current = c(99, 96, 77)
)
for (i in 1:length(df)) {
print(i)
print(mean(df[, i]))
}#> [1] 1
#> [1] 93.66667
#> [1] 2
#> [1] 90.66667
# data.frame
df <- data.frame(
score_last = c(100, 88, 93),
score_current = c(99, 96, 77)
)
for (i in df) {
print(i)
print(mean(i))
}#> [1] 100 88 93
#> [1] 93.66667
#> [1] 99 96 77
#> [1] 90.66667
# numeric matrix
m1 <- matrix(1:16, nrow = 4, ncol = 4)
cumsum_m1 <- 0
for (i in m1) {
print(i)
cumsum_m1 <- cumsum_m1 + i
}#> [1] 1
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5
#> [1] 6
#> [1] 7
#> [1] 8
#> [1] 9
#> [1] 10
#> [1] 11
#> [1] 12
#> [1] 13
#> [1] 14
#> [1] 15
#> [1] 16
print(cumsum_m1)#> [1] 136#> [1] 1 2
#> [1] "a"
#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3
12.2.1.2 seq is a fixed anonymous object within for
seq的本质是一个短暂存在的anonymous object,随着for结构的开始而出现,随着for结构的结束而消亡。这也就意味着,如果使用一个已经存在的 object 作为seq,一旦for结构开始执行,所使用的seq就固定了,在for结构的内部改动该 object 不会改变seq,因为二者是两个完全不同的 objects。
vec_num <- 1:5
for (i in vec_num) {
vec_num <- 100
cat("i =", i, "vec_num =", vec_num, "\n")
}#> i = 1 vec_num = 100
#> i = 2 vec_num = 100
#> i = 3 vec_num = 100
#> i = 4 vec_num = 100
#> i = 5 vec_num = 100
12.2.1.3 Use seq_along()
使用seq_along()而非:生成for结构中的seq。
seq_along(x)产生一个和x等长的自然数序列,起点为 1,终点为x的长度。
#> [1] 1 2 3
vec <- NULL
seq_along(vec)#> integer(0)for结构的常见用途是重复某个操作一定次数,并且将这些重复操作所得结果储存,例如
means <- c(80, 90, 100)
out_colon <- vector("list", length(means))
for (i in 1:length(means)) {
out_colon[[i]] <- rnorm(10, means[[i]])
}
out_colon#> [[1]]
#> [1] 80.04716 79.20709 81.26221 79.95269 81.03219 79.23850
#> [7] 81.70574 79.35281 80.16277 77.85528
#>
#> [[2]]
#> [1] 89.11734 89.12146 89.96124 89.64316 91.25663 88.88313
#> [7] 90.35865 89.51667 90.03727 90.20365
#>
#> [[3]]
#> [1] 101.06599 98.19210 98.99052 101.61419 102.02002
#> [6] 99.89834 98.62401 99.58791 98.00569 101.34090当length(x)中的x长度大于 0 时,使用1:length(x)和使用seq_along()效果一样,
means <- c(80, 90, 100)
out_seqalong <- vector("list", length(means))
for (i in seq_along(means)) {
out_seqalong[[i]] <- rnorm(10, means[[i]])
}
out_seqalong#> [[1]]
#> [1] 79.53942 80.49454 79.92455 80.31126 80.04983 79.17019
#> [7] 79.22031 80.21609 79.31013 79.03127
#>
#> [[2]]
#> [1] 90.36364 90.07227 90.80362 89.57821 87.97759 90.03771
#> [7] 89.90745 90.81163 91.04440 89.89928
#>
#> [[3]]
#> [1] 100.60409 99.97703 100.64444 100.83583 100.83942
#> [6] 100.11807 99.09283 101.58352 99.09768 99.98992但当length(x)中的x长度为 0 时,使用1:length(x)会有问题,
means <- c()
out_seqalong <- vector("list", length(means))
for (i in 1:length(means)) {
out_colon[[i]] <- rnorm(10, means[[i]])
}#> Error in rnorm(10, means[[i]]): invalid arguments
out_colon#> [[1]]
#> [1] 80.04716 79.20709 81.26221 79.95269 81.03219 79.23850
#> [7] 81.70574 79.35281 80.16277 77.85528
#>
#> [[2]]
#> [1] 89.11734 89.12146 89.96124 89.64316 91.25663 88.88313
#> [7] 90.35865 89.51667 90.03727 90.20365
#>
#> [[3]]
#> [1] 101.06599 98.19210 98.99052 101.61419 102.02002
#> [6] 99.89834 98.62401 99.58791 98.00569 101.34090原因是在于:既可以生成升序自然数序列,又可以生成降序自然数序列,
#> [1] 0#> [1] 1 0但显然,当想要循环的对象长度为 0 时,应该是不循环才更符合逻辑,所以使用seq_along()会使得代码的执行结果更符合预期,
#> integer(0)#> list()
12.2.1.4 var is a named object
和seq不同,var不是一个 anonymous object,它随着for结构的开始而出现,但不会随着for结构的结束而消亡,所以有两个特点:
-
var在当次 loop 内可以更改,但是下次 loop 时会被 for 结构自动更新。
for (i in 1:5) {
cat("the var used in the current loop is", i, "\n")
i <- i + 5
cat("the var now has been changed to", i, "\n")
}#> the var used in the current loop is 1
#> the var now has been changed to 6
#> the var used in the current loop is 2
#> the var now has been changed to 7
#> the var used in the current loop is 3
#> the var now has been changed to 8
#> the var used in the current loop is 4
#> the var now has been changed to 9
#> the var used in the current loop is 5
#> the var now has been changed to 10-
var在for结构执行完毕后会储存在该for结构所在的 environment 里,其 value 为seq的最后一个 element。
for (i in 1:5) {
}
i#> [1] 5
12.2.1.5 Use var as subscript
使用var作为位置下标(subscript),用作 subsetting 的 index,可以实现遍历的效果。
n_ob <- 1000
medians_col <- vector(mode = "integer", length = 3)
df <- data.frame(
c1 = sample(10000, size = n_ob),
c2 = sample(10000, size = n_ob),
c3 = sample(10000, size = n_ob)
)
for (r in 1:3) {
medians_col[r] <- median(df[, r])
}
medians_col#> [1] 5132.0 4975.5 4979.5但凡是采用这个使用技巧时,如果for结构里发现有语句是通过subcript取子集,但又没使用该for结构中的var作为下标,很有可能就是出错了。
例 1:
rm(list=ls())
set.seed(1)
J <- 1000
I <- 30
K <- 30
D <- 1.7
X <- matrix(NA, J, I)
P <- matrix(NA, J, I)
theta<-rnorm(J, 0, 1)
b<-rnorm(I, 0, 1)
theta[theta>3] <- 3
theta[theta<-3] <- -3
b[b > 3] <- 3
b[b < -3] <- -3
for(j in 1:J){
for(i in 1:I){
P[j, i] <- 1/(1 + exp(-D*(theta[j] - b[i])))
r <- runif(1, 0, 1)
if(P[j,i] < r){
X[j, i] <- 0
}else{
X[j, i] <- 1
}
}
}
theta_k<-seq(-3, 3, length.out = K)
theta_end<-matrix(NA, J, 1)
L_k<-matrix(NA, K, 1)
for(j in 1:J){
for(k in 1:K){
p_k <- 1/(1 + exp(-D*(theta_k[k] - b)))
for(i in 1:I){
p_k[i] <- ifelse(
X[j,i] == 0,
1-p_k[i],
p_k[i]
)
L_k[k] <- prod(p_k)
}
fenzi <- sum(theta_k*L_k*((1/sqrt(2*pi))*exp(-(theta_k)^2/2)))
fenmu <- sum(L_k*((1/sqrt(2*pi))*exp(-(theta_k)^2/2)))
}
theta_end[j] <- fenzi/fenmu
}
print(mean(abs(theta_end - theta)))例 2:
# Hello everyone : )
#
#
#
# I was trying to write a function for evaluating the p-values of the t-test of a lm model, I know is a little bit silly and probably useless but I want to practice.
#
# The issue here is that it only evaluates the first variable.
#
# Here is the code:
#Data
library(ISLR2)
Auto = tibble(Auto)
#Model
lm.fit = lm(mpg ~ horsepower, data = Auto)
#Function for evaluate p-values
tStest = function(x) {
x = as.numeric(x)
a = rep(0,length(x))
for(i in seq_along(x)) {
if (x[i] > 0.025) {
a[i] = 'Accept Ho'
} else {
a = 'Reject Ho'
}
}
print(a)
}
pv = summary(lm.fit)$coefficients[, 4] #p-values
tStest(pv) #only returns one value
#But it works with a simple vector
v = c(1,2,3)
tStest(v)
# Does anyone know where is the problem? Also I'm interested in other approaches to achieve the same objective
#
# Sorry about my broken english, and thank you in advance12.2.1.6 Initialize output object
结果 object (for结构中每次循环改动的 object)需提前初始化。
在实训 3-3 中的第 4 题第 1 小问的例子中,ave_kill_2就是for循环的结果 object,ave_kill_2 <- rep(0, length(type_hero))就是初始化,即在for循环开始前创建ave_kill_2并赋值,并且大小也根据预期提前设定好,这样for循环可以顺利执行,并且执行效率最高。反之,如果不提前初始化结果 object,那么在for循环执行时,Global environment里是没有ave_kill_2的,报错并终止:
rm(medians_col)
n_ob <- 1000
# medians_col <- vector(mode = "integer", length = 3)
df <- data.frame(
c1 = sample(10000, size = n_ob),
c2 = sample(10000, size = n_ob),
c3 = sample(10000, size = n_ob)
)
for (r in 1:3) {
medians_col[r] <- median(df[, r])
}#> Error: object 'medians_col' not found12.2.1.7 Alter the process of loop structure
通常在 loop 结构中,会使用if结构来实现满足条件时改动 loop 结构的执行过程。有 2 种改动,next和break。
-
next:跳过当前 loop
for (i in 1:3) {
if (i == 2) next
print(i)
}#> [1] 1
#> [1] 3-
break:跳出当前执行的for结构
for (i in 1:3) {
if (i == 3) break
print(i)
}#> [1] 1
#> [1] 2
12.2.1.8 The recommended way of using for
for适合于多次重复相同的操作,这也就意味着写for 结构之前必须想清楚,需要重复的操作究竟有哪些,即for结构中expr到底要写什么,否则就会出现额外多写代码、整个代码结构不简洁的情况,
# column-wise centering
n_stu <- 30
df <- data.frame(
math = sample(1:150, n_stu, replace = TRUE),
chinese = sample(1:150, n_stu, replace = TRUE),
english = sample(1:150, n_stu, replace = TRUE),
history = sample(1:100, n_stu, replace = TRUE),
geography = sample(1:100, n_stu, replace = TRUE),
politics = sample(1:100, n_stu, replace = TRUE)
)
# calculate mean then subtract mean from raw data
n_col <- ncol(df)
mean_col <- vector(mode = "numeric", length = n_col)
for (r in 1:n_col) {
mean_col[r] <- mean(df[[r]])
}
df_centered_verbose <- df
for (r in 1:n_col) {
df_centered_verbose[[r]] <- df[[r]] - mean_col[r]
}
# more compact
df_centered_compact <- df
for (r in 1:n_col) {
mean_col <- mean(df[[r]])
df_centered_compact[[r]] <- df[[r]] - mean_col
}
identical(df_centered_verbose, df_centered_compact)#> [1] TRUE
12.2.1.9 The best scenario to use for
for最适合的任务情境应当是前一次 loop 和后一次 loop 有依赖关系,这种情况只有按顺序执行的 loop 结构才能够处理。不同次 loop 之间没有任何联系彼此独立的任务可以有替代 loop 结构的写法。
Loops 间存在联系:
num_ite <- 20
a <- rep(0, num_ite)
for (i in 1:num_ite) {
if (i != 1) {
a[i] <- a[i - 1] + i
}
}
a#> [1] 0 2 5 9 14 20 27 35 44 54 65 77 90 104
#> [15] 119 135 152 170 189 209Loops 间不存在联系:
# column-wise centering
set.seed(123)
n_col <- 10
n_element <- 1e4
rnd_norm <- matrix(
rnorm(n_element),
nrow = n_element/n_col,
ncol = n_col
)
# solution using for loop
time_begin <- Sys.time()
rnd_norm_center_loop <- rnd_norm
for (i in 1:n_col) {
rnd_norm_center_loop[, i] <- rnd_norm[, i] - mean(rnd_norm[, i])
}
time_end <- Sys.time()
print(time_end - time_begin)#> Time difference of 0.005012035 secs
# solution, vectorized, using subsetting only, faster
time_begin <- Sys.time()
rnd_norm_mean <- matrix(
colMeans(rnd_norm),
nrow = 1,
ncol = n_col
)[rep(1, times = nrow(rnd_norm)), ]
rnd_norm_center_vectorize <- rnd_norm - rnd_norm_mean
time_end <- Sys.time()
print(time_end - time_begin)#> Time difference of 0.001793146 secs
identical(rnd_norm_center_loop, rnd_norm_center_vectorize)#> [1] TRUE
12.2.2 while
while结构可以视作是for+if。
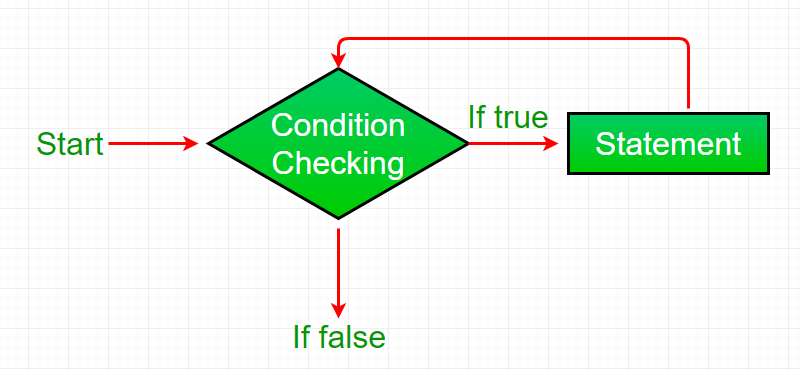
基本语法结构:
while(cond) {
expr
}while结构执行时会检测cond的执行结果是否为TRUE,只有是TRUE才会开始一次 loop 并执行expr,执行完毕后当次 loop 结束,开始下次 loop,又会检查cond的执行结果是否为TRUE,是TRUE则继续下一次 loop,是FALSE则跳出while结构。
在使用while结构的时候要注意,一定要确保在expr中cond会被更改,并酌情设定退出机制,否则非常容易陷入 forever loop。
# forever loop
i <- 1
while (i <= 5) {
print(i)
}
# make sure:
# 1. cond is modified within each loop
# 2. loop can always be jumped out of
set.seed(123)
rnd_unif <- runif(1, -1, 1)
cum_sum_rnd_unif <- 0
count <- 1
while (cum_sum_rnd_unif <= 1) {
cum_sum_rnd_unif <- cum_sum_rnd_unif + rnd_unif
print(cum_sum_rnd_unif)
count <- count + 1
if (count > 20) break
}#> [1] -0.424845
#> [1] -0.8496899
#> [1] -1.274535
#> [1] -1.69938
#> [1] -2.124225
#> [1] -2.54907
#> [1] -2.973915
#> [1] -3.39876
#> [1] -3.823605
#> [1] -4.24845
#> [1] -4.673295
#> [1] -5.09814
#> [1] -5.522984
#> [1] -5.947829
#> [1] -6.372674
#> [1] -6.797519
#> [1] -7.222364
#> [1] -7.647209
#> [1] -8.072054
#> [1] -8.496899
print(count)#> [1] 21while结构也可以通过 Snippets 快速键入:
12.2.3 repeat
repeat可以视作是不同写法的for。
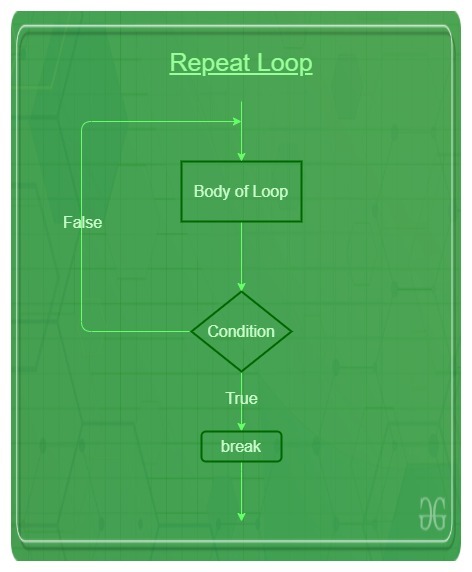
基本语法结构:
repeat {
expr
}在使用repeat结构的时候要注意,一定要确保expr中有带break的if结构,保证不会陷入 forever loop:
i <- 1
repeat {
print(i)
i <- i + 1
if (i > 5) {
break
}
}#> [1] 1
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5考虑到while和repeat结构在不够谨慎的情况下都有陷入 forever loop 的风险,而二者的本质作用都是执行多次 loop,和for结构并无差异,因此,在绝大多数情况下都建议使用for结构。
例如前文展示在使用while结构时避免 forever loop 的代码完全可以用如下for结构替代:
set.seed(123)
rnd_unif <- runif(1, min = -1, max = 1)
cum_sum_rnd_unif <- 0
n_loop <- 20
for (i in 1:n_loop) {
cum_sum_rnd_unif <- cum_sum_rnd_unif + rnd_unif
print(cum_sum_rnd_unif)
}#> [1] -0.424845
#> [1] -0.8496899
#> [1] -1.274535
#> [1] -1.69938
#> [1] -2.124225
#> [1] -2.54907
#> [1] -2.973915
#> [1] -3.39876
#> [1] -3.823605
#> [1] -4.24845
#> [1] -4.673295
#> [1] -5.09814
#> [1] -5.522984
#> [1] -5.947829
#> [1] -6.372674
#> [1] -6.797519
#> [1] -7.222364
#> [1] -7.647209
#> [1] -8.072054
#> [1] -8.496899