5 Basic: element type
由于 R 是以统计分析见长的一门计算机编程语言,所以处理变量类的 object 是 R 的日常。在变量中储存的通常是统计分析所使用的数据信息。根据日常生活经验可知,数据信息可以是不同类型,数字(比如被试在五点计分量表上的作答,数字 1-5),也可以是文字(例如被试的背景信息,学历、出生地、性别、毕业院校,等等)。

如果将日常处理的数据中每一个单独的记录视作是元素,那么这些不同数据信息类型在 R 中就对应着不同的元素类型(element type)。
element type之所以重要是因为不同的element type在处理的时候适用的操作有所不同,数字类型的元素适用于数学计算,字符串类型的元素适用于分割、拼接等操作。
R 有 4 种基础和 4 种特殊的 element types:
| 基础 | 特殊 |
|---|---|
logical(逻辑) |
NA(缺失值) |
integer(整型) |
NULL(空) |
double(双整) |
raw(原始型) |
character(字符串) |
expression(表达式) |
5.1 Four basic types
分别是logical,integer,double,还有character,其中integer和double均是numeric(数值型)。
numeric对应着数值类型的数据信息,character对应着文本类型的数据信息。logical则是专门用来储存“是或否”类型的 2 值数据信息,比如“10月21日是否核酸检测(是或否)”。
一般情况下,使用读取数据的 function 将本地数据文件读入 R 时,function 会自动根据读进来的数据信息来判断哪一部分是numeric、哪一部分是character、哪一部分是logical,不太需手动指定。那么什么情况下才需要?按需。听起来像是废话,看几个例子。
生成 4 种 element type 下的常量 scalar(单个元素)。
# 现有一张核酸检测情况登记表,记录了 9 位同学的核酸情况,
# 将该表读入 R 中,命名为 data_covid_test
# 得知又新增了一位同学,需要记录 ta 的姓名、是否检测、体温等信息
data_covid_test$name[10] <- "小明" # character
data_covid_test$is_covid_test[10] <- TRUE # logical
data_covid_test$temperature[10] <- 36L # integer
data_covid_test$temperature[10] <- 36 # double在上面的例子中,数字包括10和36,一个是该同学在列表中的位置排序信息,另一个是该同学的体温信息。这两个信息根据常识判断肯定是数字,所以在代码中涉及到这两个信息的地方需要手动生成numeric的 anonymous object。类似的,因为该同学的姓名必然是character,所以涉及到姓名的地方需要手动生成character的 anonymous object。而该同学是否检测只有两种情况,检测或未检测,属于天然logical信息,所以涉及到检测情况的地方需要手动生成logical的 anonymous object。以上,即为在写代码的过程中按需手动生成指定element type的 anonymous object。
其中,integer和double型的 object 在 Console 输出时没有区别。例如:
var_int <- 1L
var_dbl <- 1
var_int#> [1] 1
var_dbl#> [1] 1只有在 Environment 里面可以看得出来区别:
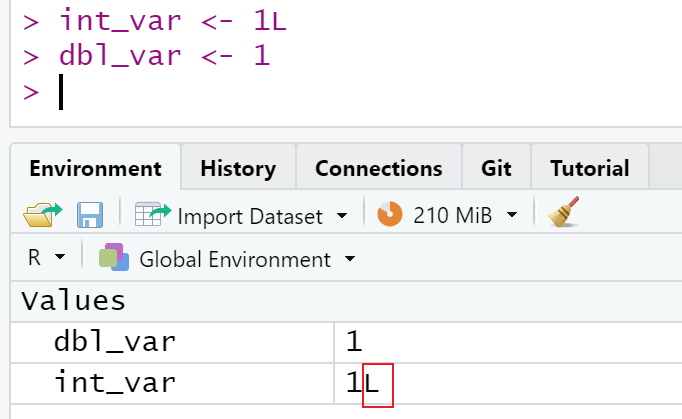
因此,绝大多数场景下,使用double就够了,如data_covid_test$temperature[10] <- 36。
5.1.1 Caveats
-
logicalobejct 必须使用全部大写的TRUE、FALSE,或首字母简写T、F; -
double既可以是日常生活中常用的 10 进制小数,也可以是科学计数法(scientific notation,1.99E10==1.99*10^10==19900000000),除此之外,double还有 3 种特殊的值,Inf(正无穷),-Inf(负无穷),NaN(非数);
1/0#> [1] Inf
0/0#> [1] NaN
1/0 + 1/0#> [1] Inf
1/0 - 1/0#> [1] NaN
sin(Inf) # sin() 为正铉函数#> Warning in sin(Inf): NaNs produced#> [1] NaN
log(-1) # log() 为自然对数函数#> Warning in log(-1): NaNs produced#> [1] NaN当看到Inf、-Inf、NaN时,就要反应过来,是数据可能存在问题,导致出现了违背计算规律的事情发生,此时最好是检查一下原始数据,看看问题出在哪。
- 手动生成
integer型的 anonymous object 时必须以L结尾,并且不能包括小数;
a <- 1.1L
#> Warning: integer literal 1.1L contains decimal; using numeric value考虑到绝大多数情况下都建议使用double类型,并且出现这种错误时会有明确的警告warning,所一般不用担心。
- 字符串请一定要用双引号
""包括起来,否则会被识别为object的name;
var_name <- "fruit"
var_name <- fruit#> Error: object 'fruit' not found- 一些特殊的字符,则需要使用
\来转义,如换行符(\n),详细的特殊字符列表请使用?Quotes查看。
x <- "1\n1"
cat(x)#> 1
#> 15.2 Four special types
5.2.1 NA(not available)
missing data 是数据收集过程中经常会碰到的事情,所以大多数统计分析方法中会有专门针对缺失数据的处理。首先需要知道在 R 中,缺失数据有专门的标记,NA。NA是一个长度为 1 的logical常数,包含一个缺失值(missing value)指示指标(indicator)。
NA # there should be something here but no, let's mark it#> [1] NA
length(NA) # length() 会返回 object 的长度#> [1] 1大多数运算中如果有NA,通常会返回NA,NaN、Inf和-Inf也是如此。
NA + 5#> [1] NA
NA - 10#> [1] NA
#---
NaN + 5#> [1] NaN
NaN - 10#> [1] NaN
#---
Inf + 5#> [1] Inf
Inf - 10#> [1] Inf
#---
-Inf + 5#> [1] -Inf
-Inf - 10#> [1] -Inf也有一些例外:
NA ^ 0#> [1] 1
NA | TRUE#> [1] TRUE
NA & FALSE#> [1] FALSE
#---
NaN ^ 0#> [1] 1
NaN | TRUE#> [1] TRUE
NaN & FALSE#> [1] FALSE
#---
Inf ^ 0#> [1] 1
Inf | TRUE#> [1] TRUE
Inf & FALSE#> [1] FALSE
#---
-Inf ^ 0#> [1] -1
-Inf | TRUE#> [1] TRUE
-Inf & FALSE#> [1] FALSE正是因为大多数统计方法的 function 中都会有处理缺失数据的部分,且通常都是通过 function 的某个 argument 来控制的。只不过,不同的统计方法的 function 对于缺失值的处理可能会有区别,argument 也可能会不同,但与缺失数据有关的 argument 通常都会包含na的关键词,可以通过 Help 界面的 Find in Topic 快速查找某个 function 中与缺失数据有关的信息。例如:
#> [1] NA
mean(vec_with_missing, na.rm = TRUE)#> [1] 2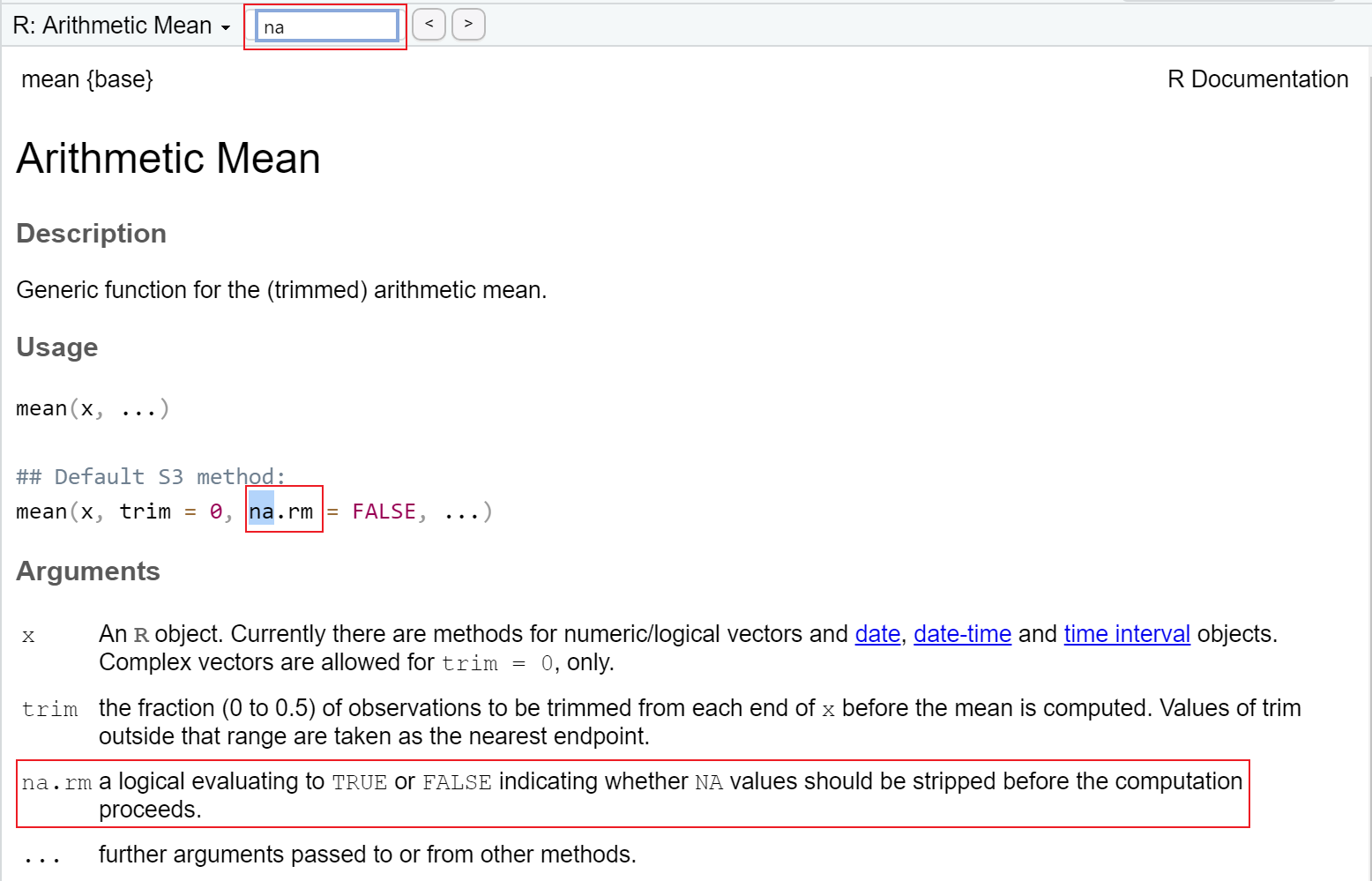
# t test
x <- c(1, 2, NA, 4, 5, 6, 7, 8, 9, 10)
y <- c(7, 8, 9, NA, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20)
t.test(x, y) # ?t.test, the "na.action" argument kicks in with default#>
#> Welch Two Sample t-test
#>
#> data: x and y
#> t = -5.1338, df = 19.909, p-value = 5.127e-05
#> alternative hypothesis: true difference in means is not equal to 0
#> 95 percent confidence interval:
#> -11.239510 -4.743396
#> sample estimates:
#> mean of x mean of y
#> 5.777778 13.769231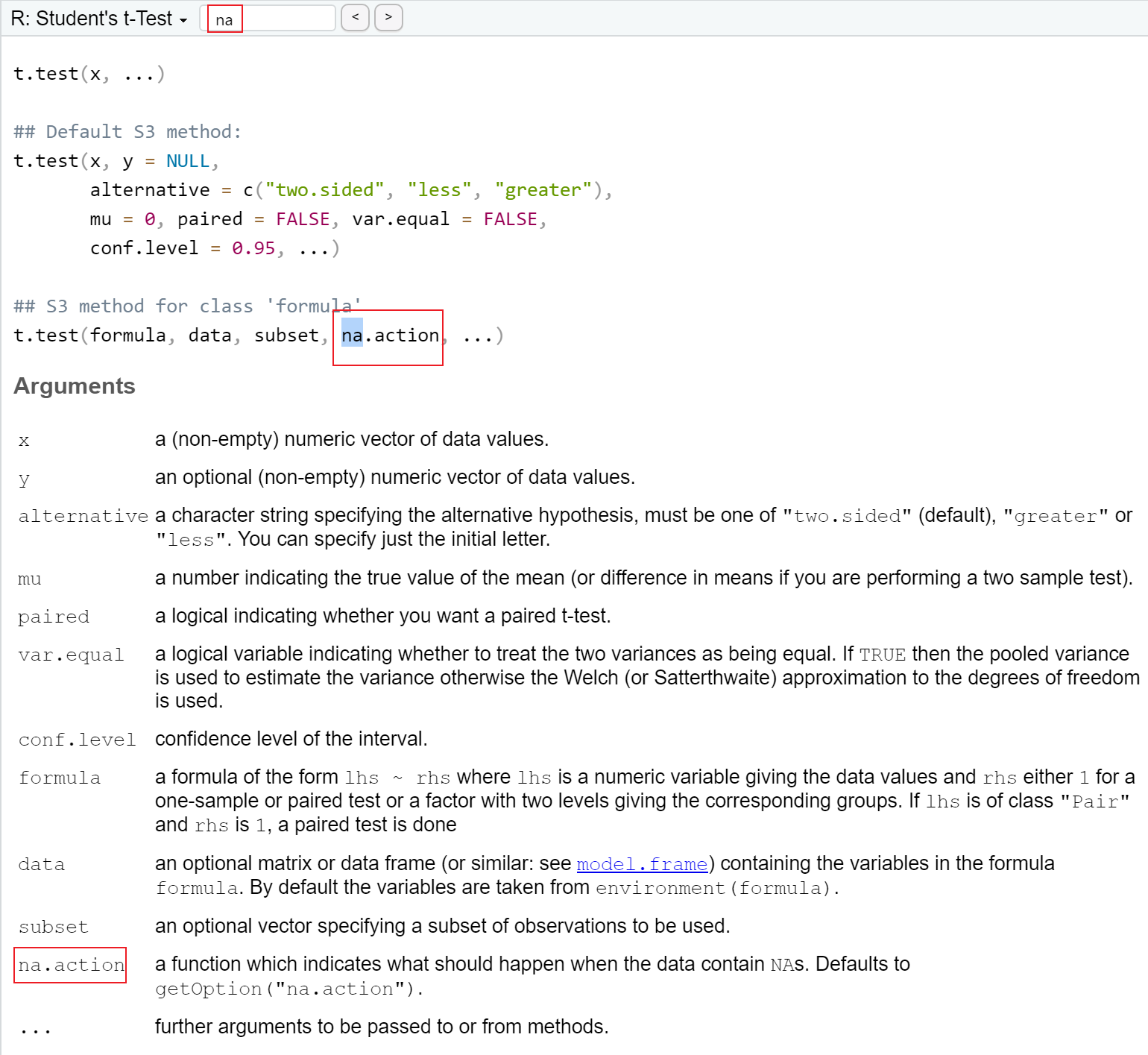
5.2.2 NULL
NULL表示一个长度为 0 的 vector,可以理解为“空”。
NULL#> NULL
length(NULL)#> [1] 0大多数情况下,涉及到NULL的运算,都会输出一个长度为 0 的相应结果(取决于所使用 function 定义),例如:
NULL * 1L#> integer(0)
NULL + 1#> numeric(0)
NULL | TRUE#> logical(0)NULL的 3 种常见用法
- 初始化某个对象(不推荐)
test[1] <- 1 #> Error: object 'test' not found
# 在环境空间(environment)中并没有叫 test 的 object 时,就无法与其交互。
test <- NULL # 初始化,创建一个 NULL object,取名 test
test[2] <- 1 # 将 test 的第 2 个位置上的元素替换为 1
test#> [1] NA 1和test <- NULL等价的写法是test <- c()。但是由于这种初始化的写法一定会导致test的大小发生变化(例子中由 0 变为 2), R 在处理的时候会需要不断在内存中复制test,运行效率低下,不推荐这样的初始化写法。更建议的初始化写法详见控制流的for循环小节。
作为 function 的可选 argument 的默认值(default setting),在自编 function 的章节会具体讲。例如,可以使用
?t.test查看t.test()的帮助文档,其中的一个可选argument——y的默认值就是NULL,如果不提供y,就默认执行单样本 t 检验,结合mu = 0可知,此时\(H_0:\mu=0\)。清空某 object 的 value
test <- c(1, 2, 3)
test <- NULL
test#> NULL
5.2.3 raw
raw因为很少用,所以就不介绍了,感兴趣的同学请使用?raw查看。
5.2.4 expression (optional)
expression是一种特殊的 element type,单独的一个expression存储的是一个没有执行的 R 代码。使用expression()来产生expression类型的 object,例如:
1 + 3#> [1] 4
expression(1 + 3)#> expression(1 + 3)
length(expression(1 + 3))#> [1] 1expression的用途
expression常用于作图时在图片中添加数学公式,例如:
x <- c(
1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, 20
)
y <- sqrt(x)
plot_title <- expression(y == sqrt(x))
plot(x, y, main = plot_title)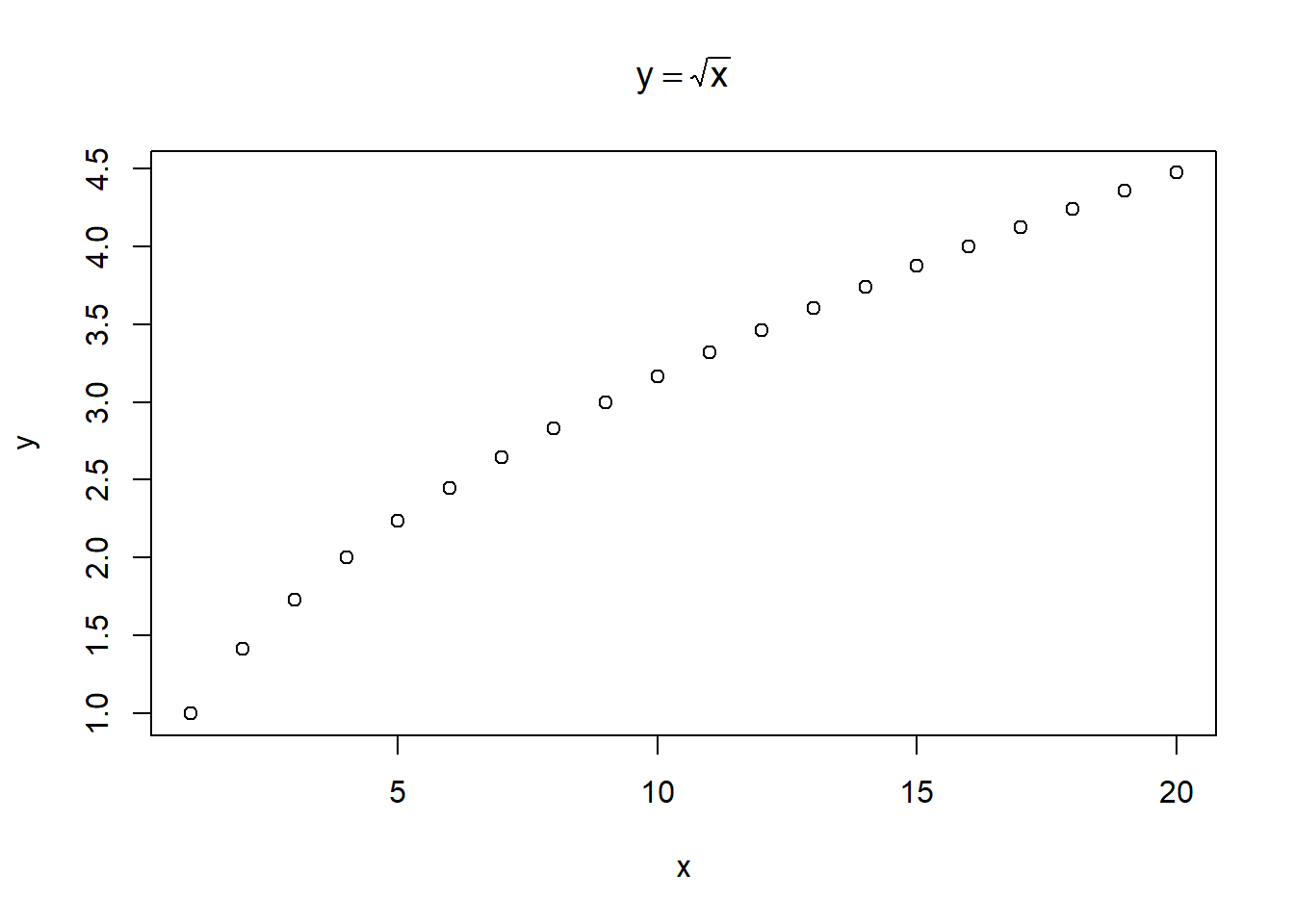
更多支持的公式符号可以使用?plotmath查看。
5.3 Element type detection
在一些情况下,需要检测 object 的element type到底是哪一种,需要使用typeof():
var_lgl <- c(TRUE, FALSE)
var_int <- c(1L, 6L, 10L)
var_dbl <- c(1, 2.5, 4.5)
var_chr <- c("these are", "some strings")
var_inf <- c(1.3, Inf, -Inf)
var_NaN <- c(1.3, NaN, -Inf)
var_na <- c(NA, NA, NA)
var_null <- c(NULL, NULL, NULL)
typeof(var_lgl)#> [1] "logical"
typeof(var_int)#> [1] "integer"
typeof(var_dbl)#> [1] "double"
typeof(var_chr)#> [1] "character"
typeof(var_inf)#> [1] "double"
typeof(var_NaN)#> [1] "double"
typeof(var_na)#> [1] "logical"
typeof(var_null)#> [1] "NULL"