
Visualizing geographic data
- Learning outcomes: Learn…
- …how to visualize geographic data in R with ggplot2.
- …about different types of geographic data.
Sources: Original material; Wickham (2010)
- Material mostly based on Wickham (2016, chap. 3.7)
- Objective:
- Show variation across geographic entities
- Show location of particular places or where data originated
- Illustrate comparative strategy
- Usage: Often to illustrate were data was collected or how it varies across geographic units
- Map data is tedious… :-S
- Types of data: vector boundaries, point metadata, area metadata, raster images (Wickham 2016, 55f)
- Challenges: Map data may change (e.g., changes of administrative boundaries)
1 Geographic data: Vector boundaries & Area metadata
- Vector boundaries (polygons)
- Data frame with one row for each ‘corner’ of a geographical region
latandlong: location of a pointgroup: a unique identifier for each continuous regionid: the name of the region- Separate
groupandidare necessary because geographical unit isn’t necessarily one polygon (e.g., islands of Hawaii)
- Shape files contain vector boundary data (read them with e.g.,
st_read())
- Data frame with one row for each ‘corner’ of a geographical region
- Area metadata
- Sometimes metadata is associated with an area (rather than a point), e.g., census data on the county level
- We’ll see an example further below
2 Geographic data: Point metadata
- Point metadata
- Connect locations (defined by lat and lon) with other variables
# library(rnaturalearth)
# library(sf)
cities <- c("MUNICH", "BERLIN", "MANNHEIM", "REGENSBURG", "HAMBURG")
germany_cities <- bind_cols(name = cities, geocode(cities))
head(germany_cities)| name | lon | lat |
|---|---|---|
| MUNICH | 11.58198 | 48.13513 |
| BERLIN | 13.40495 | 52.52001 |
| MANNHEIM | 8.46604 | 49.48746 |
| REGENSBURG | 12.10162 | 49.01343 |
| HAMBURG | 9.98717 | 53.54883 |
worldmap <- ne_countries(scale = 'medium', type = 'map_units',
returnclass = 'sf')
Germany <- worldmap[worldmap$name == 'Germany',]
ggplot() + geom_sf(data = Germany) + theme_bw()+
geom_point(data = germany_cities, aes(x = lon, y = lat),
colour ="red")
3 Geographic data: Raster image
- Raster image
- Draw a traditional image underneath some data you want to show
- e.g., get raster map of given area from ggmap package (e.g., relying GoogleMaps)1
- Download may be timeconsumg so better cache it as
rdsfile. - Define area by specifying
bbox - API key: See
?get_googlemap()and?register_google()[You will need an API key]
p1 <- ggmap(get_googlemap(center = c(10.329930, 51.296475), zoom = 3))
p2 <- ggmap(get_googlemap(center = c(10.329930, 51.296475), zoom = 4))
p3 <- ggmap(get_googlemap(center = c(10.329930, 51.296475), zoom = 5))
p4 <- ggmap(get_googlemap(center = c(10.329930, 51.296475), zoom = 6))
grid.arrange(p1, p2, p3, p4, ncol=2)
4 Packages & functions
- Major recent overhaul in R packages for spatial data
- Packages: There are plenty of packages
sf: A package that provides simple features access for R- sf = [simple features]
st_read(): Read simple features from file or database- See explanation of necessary files (
.shp,.shx,.dbf)
- See explanation of necessary files (
st_as_sf(): Convert foreign object to an sf objectaggregate(): aggregate an sf object, possibly unioning geometriesst_bbox(): Return bounding of a simple feature or simple feature setgeom_sf(): geoms to visualise simple feature (sf) objects.st_geometry(): Get, set, or replace geometry from an sf object
cowplotpackage andggdraw(): Set up a drawing layer on top of a ggplot
- Other tutorials:
5 Graph
- Here we’ll reproduce Figure Figure 2 (shorter session) or Figure 3 (longer session)
- Questions:
- What does it show? What does the underlying data probably look like? What kind of variables are we dealing with?
- What do you like, what do you dislike about the figure? What is good, what is bad?
- What kind of information could we add to this figure?
- How would you approach the figure if you want to replicate it?
- How many scales/mappings does it use? Could we reduce them?

5.1 Lab: Data & Code
- Learning objectives
- Creating maps with ggplot2
- Learn how to plot shape files (polygons) with ggmaps
- Understand
sfdata.frames(s) - Learn how to plot subets of maps
- Learning how to plot several maps together
- Learn how to colour particular polyhons (longer session)
- Learn how to aggregate maps (longer session)
We start by importing the data, namely a shape file of Germany (you can get that here) as well as some voting data on the level of municipalities. You need to download the shape files from this link: https://drive.google.com/drive/folders/1LGm-kBDZhFc01ncBBvtFHPfC2eXXdooT?usp=sharing and change the path to the folder where you store them below.
# library(sf)
# Load vote share data on the municipality level: data_votes_municipalities.csv
# data_voteshares <- read_csv(
# sprintf("https://docs.google.com/uc?id=%s&export=download",
# "1f3ZKXEzg-vpDL37hietMsnpSDXFw4zgG"),
# col_types = cols())
data_voteshares <- read_csv("data/data_votes_municipalities.csv",
col_types = cols())
kable(head(data_voteshares))| AGS | Wahlkreis | municipality | state | share.cdu_csu2017 | share.cdu2017 | share.csu2017 | share.spd2017 | share.fdp2017 | share.dielinke2017 | share.greens2017 | share.afd2017 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 01001000 | 1 | Flensburg, Stadt | Schleswig-Holstein | 0.2884122 | 0.2884122 | 0 | 0.3137588 | 0.0681140 | 0.1137327 | 0.1148574 | 0.0753335 |
| 01002000 | 5 | Kiel, Landeshauptstadt | Schleswig-Holstein | 0.2767015 | 0.2767015 | 0 | 0.3203291 | 0.0715934 | 0.0799988 | 0.1388073 | 0.0681959 |
| 01003000 | 11 | Lübeck, Hansestadt | Schleswig-Holstein | 0.3259105 | 0.3259105 | 0 | 0.3457753 | 0.0638918 | 0.0000000 | 0.1238492 | 0.0935190 |
| 01004000 | 6 | Neumünster, Stadt | Schleswig-Holstein | 0.3611685 | 0.3611685 | 0 | 0.3071194 | 0.0715285 | 0.0623480 | 0.0692789 | 0.1053928 |
| 01051001 | 3 | Albersdorf | Schleswig-Holstein | 0.4439733 | 0.4439733 | 0 | 0.2392489 | 0.1211387 | 0.0448213 | 0.0539067 | 0.0763174 |
| 01051002 | 3 | Arkebek | Schleswig-Holstein | 0.5000000 | 0.5000000 | 0 | 0.1636364 | 0.1363636 | 0.0181818 | 0.1181818 | 0.0636364 |
# Load shape files
# Download the shape files: https://drive.google.com/drive/folders/1LGm-kBDZhFc01ncBBvtFHPfC2eXXdooT?usp=sharing
# Adapt the folder "www/data" to your file location
data_map <- st_read(dsn = "www/data", layer = "VG250_GEM", options = "ENCODING=ASCII", quiet = TRUE)
# See column geometry
data_map$AGS <- as.character(data_map$AGS)Since, the map data is now stored as a sf dataframe (?class(data_map)) we can simply join it with other the data data_voteshares.
The identifer we use to match the map data with out vote share data is called AGS (Amtlicher Gemeindeschlüssel), a standard identifer for municipalities in Germany.
Let’s have a quick look at the map. Figure 4 plots the shape file with gray borders around the areas. It’s a bit convoluted since there are a lot of polygons defined in the map data (11435 municipalities):

In Figure Figure 5 we add geographic area metadata, namely the vote share of the green party in 2017 share.greens2017 (this is simple as we add it to the dataframe beforehand):
ggplot() +
geom_sf(data = data_map,
aes(fill = share.greens2017), colour = NA) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkgreen", na.value = NA) 
Potentially, it could help to add a few cities for the interpretation of the map as in Figure 6.
# City data (latitude, longitude) converted
# to sf object
cities <- data.frame(name = c("MUNICH", "BERLIN", "MANNHEIM", "REGENSBURG", "FREIBURG", "HAMBURG"),
lon = c(11.5819806, 13.404954, 8.4660395, 12.1016236, 7.8421043, 9.99),
lat = c(48.1351253, 52.5200066, 49.4874592, 49.0134297, 47.9990077, 53.5)) %>%
st_as_sf(coords = c("lon", "lat"), crs = "WGS84")
# Add cities
ggplot() +
geom_sf(
data = data_map,
aes(fill = share.greens2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkgreen", na.value = NA) +
geom_sf(
data = cities,
colour = "black"
)
6 Exercise
- In this little exercise the idea is to recreate the fine-grained map in Figure 6 and below you find the code to do so. Make sure to download the necessary files and place them in the right folder (also adapting the paths).
- Use the same code but now generate a map the visualizes the share of the AFD in blue coloring (see
share.afd2017). Go through the code step-by-step to inspect what happens. - Once you have done this please zoom into Bavaria and provide a map thereof (you will need to filter
data_mapfor thestateof"Bayern"and create a new objectdata_map_bayern). Either omit the cities or only visualize Munich by creating a new dataframecities_bayernthat only includes Munich. - Can you find out how to add a text label to the city of Munich and label the x- and y-axis (see
geom_sf_text())?
library(sf)
# Load vote share data on the municipality level: data_votes_municipalities.csv
# data_voteshares <- read_csv(
# sprintf("https://docs.google.com/uc?id=%s&export=download",
# "1f3ZKXEzg-vpDL37hietMsnpSDXFw4zgG"),
# col_types = cols())
data_voteshares <- read_csv("data/data_votes_municipalities.csv",
col_types = cols())
# Load shape files
# Download the shape files: https://drive.google.com/drive/folders/1LGm-kBDZhFc01ncBBvtFHPfC2eXXdooT?usp=sharing
# Adapt the folder "www/data" to your file location
# Use "." for working directory
data_map <- st_read(dsn = "www/data", layer = "VG250_GEM", options = "ENCODING=ASCII", quiet = TRUE)
# See column geometry
data_map$AGS <- as.character(data_map$AGS)
data_map <- left_join(data_map, data_voteshares, by="AGS")
# to sf object
cities <- data.frame(name = c("MUNICH", "BERLIN", "MANNHEIM", "REGENSBURG", "FREIBURG", "HAMBURG"),
lon = c(11.5819806, 13.404954, 8.4660395, 12.1016236, 7.8421043, 9.99),
lat = c(48.1351253, 52.5200066, 49.4874592, 49.0134297, 47.9990077, 53.5)) %>%
st_as_sf(coords = c("lon", "lat"), crs = "WGS84")
# Add cities
ggplot() +
geom_sf(
data = data_map,
aes(fill = share.greens2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkgreen", na.value = NA) +
geom_sf(
data = cities,
colour = "black"
)Exercise solution
# 1.
library(sf)
# Load vote share data on the municipality level: data_votes_municipalities.csv
# data <- read_csv(
# sprintf("https://docs.google.com/uc?id=%s&export=download",
# "1f3ZKXEzg-vpDL37hietMsnpSDXFw4zgG"),
# col_types = cols())
data <- read_csv("data/data_votes_municipalities.csv",
col_types = cols())
# Load shape files
# Download the shape files: https://drive.google.com/drive/folders/1LGm-kBDZhFc01ncBBvtFHPfC2eXXdooT?usp=sharing
# Adapt the folder "www/data" to your file location
data_map <- st_read(dsn = "www/data", layer = "VG250_GEM", options = "ENCODING=ASCII", quiet = TRUE)
# See column geometry
data_map$AGS <- as.character(data_map$AGS)
data_map <- left_join(data_map, data_voteshares, by="AGS")
# to sf object
cities <- data.frame(name = c("MUNICH", "BERLIN", "MANNHEIM", "REGENSBURG", "FREIBURG", "HAMBURG"),
lon = c(11.5819806, 13.404954, 8.4660395, 12.1016236, 7.8421043, 9.99),
lat = c(48.1351253, 52.5200066, 49.4874592, 49.0134297, 47.9990077, 53.5)) %>%
st_as_sf(coords = c("lon", "lat"), crs = "WGS84")
# Add cities
ggplot() +
geom_sf(
data = data_map,
aes(fill = share.afd2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkblue", na.value = NA) +
geom_sf(
data = cities,
colour = "black"
)
# 2.
data_map_bayern <- data_map %>% filter(state=="Bayern")
cities_bayern <- cities %>% filter(name == "MUNICH")
ggplot() +
geom_sf(
data = data_map_bayern,
aes(fill = share.afd2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkblue", na.value = NA) +
geom_sf(
data = cities_bayern,
colour = "black"
)
# 3.
ggplot() +
geom_sf(
data = data_map_bayern,
aes(fill = share.afd2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkblue", na.value = NA) +
geom_sf(
data = cities_bayern,
colour = "black"
) +
geom_sf_text(data = cities_bayern,
aes(label = name),
hjust = 0) +
labs(x = "Longitude",
y = "Latitude",
fill = "Share AfD (2017)")
7 Combinations of maps (longer session)
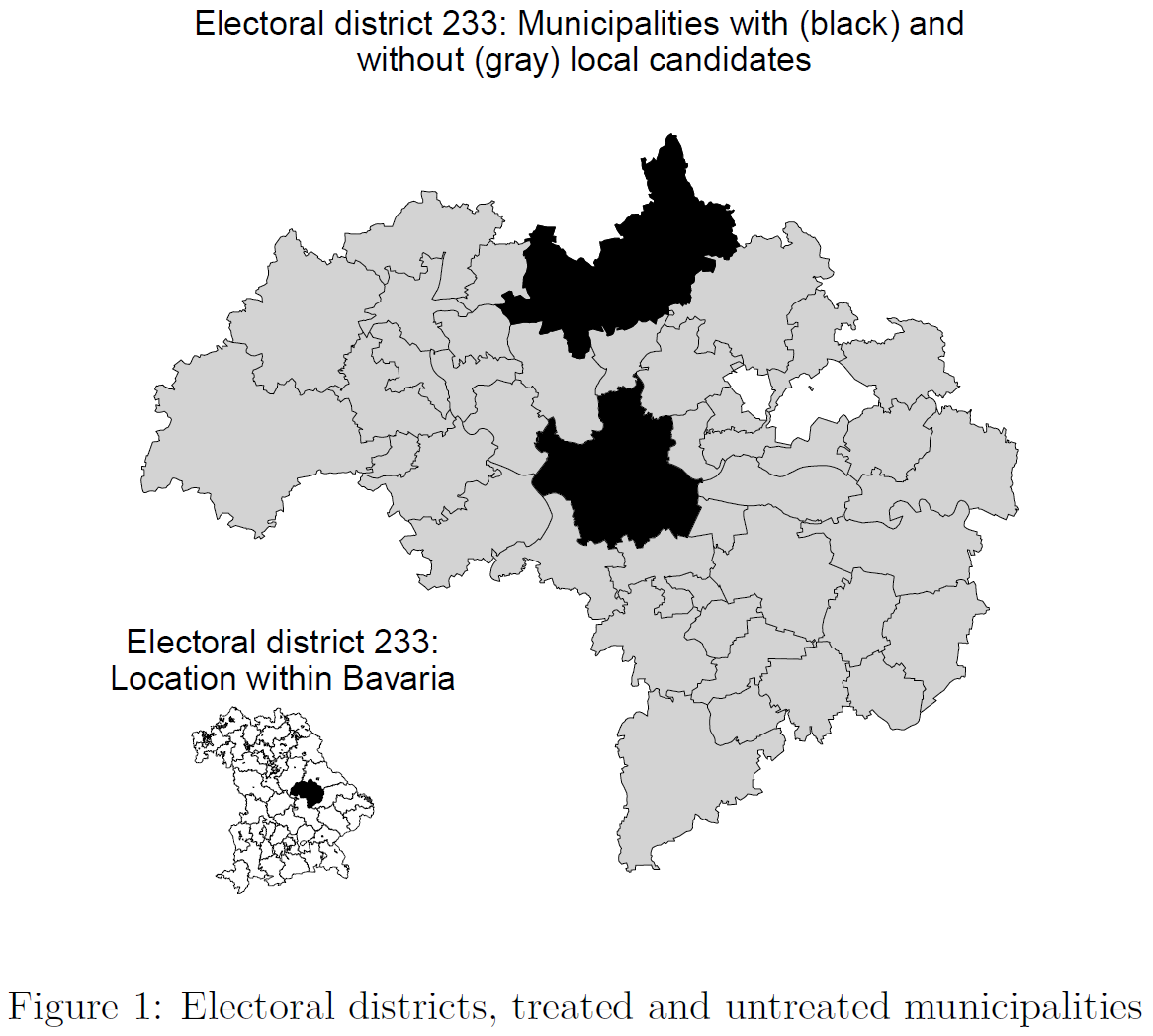
Now let’s try visualizing Figure 3. In contrast, to Figure Figure 4 and Figure 5, it doesn’t show all of Germany. Rather it is used to illustrate a comparative strategy.
- It zooms into German to show Bavaria on the lower right.
- It zooms into Bavaria to show the electoral district in the middle.
- It colours municipalities within the electoral district 233.
- It adds titles.
We’ll start by showing the different maps separatedly in a grid. Then we put them together.
# MAP 1: Bavaria within Germany
data_map_states <- aggregate(data_map, by = list(data_map$SN_L), mean) # SN_L = STATE
p1 <- ggplot() +
# Draw Germany
geom_sf(data = data_map_states,
fill = "white", color = "black", size = 0.1) +
# Draw Bavaria (filled black)
geom_sf(data = data_map_states %>% filter(Group.1 == "09"), fill = "black", color = "black") +
theme_void() +
ggtitle("Bavaria:\nLocation within Germany") +
theme(plot.title = element_text(color = "black", size = 10, hjust = 0.5))
# MAP 2: Elector district within Bavaria
# Take out map of Bavaria
data_map_bavaria <- data_map %>%
filter(SN_L == "09") %>%
dplyr::select("Wahlkreis")
# Aggregate the map data to the level of electoral districts
data_map_bav_elec_dist <- aggregate(data_map_bavaria,
by = list(data_map_bavaria$Wahlkreis),
mean
) %>% select(Wahlkreis)
# Create a new object that only contains electoral district 233
data_map_bav_elec_dist_233 <- data_map_bav_elec_dist %>%
filter(Wahlkreis == 233)
p2 <- ggplot() +
# Draw bavaria
geom_sf(
data = data_map_bav_elec_dist, fill = "white", color = "black",
size = 0.1
) +
# Draw electora district 233
geom_sf(data = data_map_bav_elec_dist_233, fill = "black", color = "black") +
# geom_sf(data = map_electoral_district_233_bb, fill = NA, color = "red", size = 0.8) +
theme_void() +
ggtitle("Electoral district 233:\nLocation within Bavaria") +
theme(plot.title = element_text(color = "black", size = 10, hjust = 0.5))
# MAP 3:
# Take out map of electoral district 233
data_map_mun_dist_233 <- data_map %>% filter(Wahlkreis == 233)
# Take out map subsets that we want to color black later
map_color_black <- data_map_mun_dist_233 %>%
filter(Wahlkreis == 233, municipality == "Regensburg")
map_color_black2 <- data_map_mun_dist_233 %>%
filter(Wahlkreis == 233, municipality == "Regenstauf, M")
# Take out subset that we want to color gray (not Regensburg!)
map_color_gray <- data_map_mun_dist_233 %>%
filter(Wahlkreis == 233, municipality != "Regensburg")
p3 <- ggplot() +
# draw electoral district 233
geom_sf(data = data_map_mun_dist_233, fill = NA, colour = "black", size = 0.1) +
# draw all municipalities (not Regensburg) in light gray
geom_sf(data = map_color_gray, fill = "lightgray", colour = "black", size = 0.1) +
# Draw municipalites Regensburg/Regenstauf in black
geom_sf(data = map_color_black, fill = "black", colour = "black", size = 0.1) +
geom_sf(data = map_color_black2, fill = "black", colour = "black", size = 0.1) +
theme_void() +
ggtitle("Electoral district 233: Municipalities with (black) and\nwithout (gray) local candidates") +
theme(
legend.position = "none",
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
plot.margin = unit(c(0, 0, 0, 0), "cm"),
plot.title = element_text(color = "black", size = 10, hjust = 0.5)
)
library(patchwork)
p1 + p2 + p3
Subsequently, we plot all three maps together in Figure Figure 8:
gg_inset_map <- ggdraw() +
draw_plot(p3) +
draw_plot(p1, x = 0.015, y = 0.05, width = 0.25, height = 0.25) +
draw_plot(p2, x = 0.25, y = 0.05, width = 0.25, height = 0.25)
gg_inset_map
Or use grid.arrange() in Figure Figure 9:

8 Side-by-side & interactive maps
Below we use the code from above to recreate to maps for Bavaria visualizing the shares of both the greens and the AFD next to each other using the patchwork package. Then we use the ggplotly function to make one of the maps interactive. We add aes(label = municipality) in the ggplot() function so that they are recognized by plotly for the interactive graph.
library(patchwork)
library(plotly)
library(sf)
# Load vote share data on the municipality level: data_votes_municipalities.csv
# data_voteshares <- read_csv(
# sprintf("https://docs.google.com/uc?id=%s&export=download",
# "1f3ZKXEzg-vpDL37hietMsnpSDXFw4zgG"),
# col_types = cols())
data_voteshares <- read_csv("data/data_votes_municipalities.csv",
col_types = cols())
# Load shape files
# Download the shape files: https://drive.google.com/drive/folders/1LGm-kBDZhFc01ncBBvtFHPfC2eXXdooT?usp=sharing
# Adapt the folder "www/data" to your file location
data_map <- st_read(dsn = "www/data", layer = "VG250_GEM", options = "ENCODING=ASCII", quiet = TRUE)
# See column geometry
data_map$AGS <- as.character(data_map$AGS)
data_map <- left_join(data_map, data_voteshares, by="AGS")
# Filter for Bavaria
data_map_bayern <- data_map %>% filter(state=="Bayern")
p1 <- ggplot(data = data_map_bayern,
aes(label = municipality)) +
geom_sf(
data = data_map_bayern,
aes(fill = share.greens2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkgreen", na.value = NA) +
theme_light(base_size = 8) +
theme(legend.position = "bottom")
p2 <- ggplot(data = data_map_bayern,
aes(label = municipality)) +
geom_sf(
data = data_map_bayern,
aes(fill = share.afd2017), colour = NA
) + # fill but turn of borders
scale_fill_gradient(low = "white", high = "darkblue", na.value = NA) +
theme_light(base_size = 8) +
theme(legend.position = "bottom")
p3 <- p1 + p2
p3