T
t.test() {}| Descripción | Argumentos |
|---|---|
| Realiza pruebas t de una y dos muestras en vectores de datos |
|
Inferencia de la comparación de dos medias a partir de grupos no apareados con varianzas homogéneas, cuando se desconoce 𝜎.
# Datos
A = c(0.05, 0.04, 0.06, 0.06, 0.04, 0.05, 0.05, 0.04)
B = c(0.05, 0.05, 0.05, 0.06, 0.04, 0.06, 0.04, 0.06)
# Prueba bilateral de homogeneidad de varianzas
var.test(A,B)##
## F test to compare two variances
##
## data: A and B
## F = 1, num df = 7, denom df = 7, p-value = 1
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.2002038 4.9949092
## sample estimates:
## ratio of variances
## 1##
## Two Sample t-test
##
## data: A and B
## t = -0.59914, df = 14, p-value = 0.5586
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.011449369 0.006449369
## sample estimates:
## mean of x mean of y
## 0.04875 0.05125Inferencia de 𝜇 basada en una muestra, cuando se desconoce 𝜎.
# Datos
N = c(0.50, 0.48, 0.39, 0.41, 0.43, 0.49, 0.54, 0.48, 0.52, 0.51,0.49, 0.47, 0.44, 0.45, 0.40, 0.38, 0.50, 0.51, 0.52, 0.45)
# Parámetro mu
mu = 0.5
# t.test
t.test(x = N,
mu = mu,
alternative="two.sided")##
## One Sample t-test
##
## data: N
## t = -3.0395, df = 19, p-value = 0.006745
## alternative hypothesis: true mean is not equal to 0.5
## 95 percent confidence interval:
## 0.4459643 0.4900357
## sample estimates:
## mean of x
## 0.468table() {base}| Descripción |
|---|
| Devuelve una matriz con el recuento de elementos en cada categoría o factor. Como argumento, se utiliza el nombre del objeto |
## insectos
## 0 1 2 3 4 6 8
## 1 5 3 1 2 2 1#La primera fila indica el nombre del objeto
#La segunda fila indica los valores que asume el objeto
#La tercera fila indica las frecuencias absolutas
class(a) ## [1] "table"tail() {utils}| Descripción | Argumentos |
|---|---|
| Permite leer las últimas n filas de un conjunto de datos | Se indica entre paréntesis () el objeto R |
## Departamento Variedad Brix pH AT PT Caracterización
## 12 Humahuaca Cara sucia 12.0 3.42 7.53 1.41 Acido-amargo
## 13 Humahuaca Rojita 9.0 3.28 6.28 0.83 Acido
## 14 Humahuaca Amarilla deliciosa 12.0 3.49 6.52 0.98 Acido
## 15 Humahuaca Desconocida roja I 14.5 3.74 2.99 0.64 Dulce
## 16 Humahuaca Desconocida roja II 12.0 4.73 0.87 1.18 Dulce
## 17 Humahuaca Criolla chata 16.0 3.95 4.71 2.05 Amargo-aciduladoPor defecto muestra los últimos 6 registros del set datos.
tapply() {base}| Descripción | Argumentos |
|---|---|
| Aplica una función a una variable numérica teniendo en cuenta un criterio |
|
## [1] "Departamento" "Variedad" "Brix" "pH"
## [5] "AT" "PT" "Caracterización"## Humahuaca Tumbaya
## 12.65385 9.87500text() {graphics}| Descripción | Argumentos |
|---|---|
| Permite añadir texto a un gráfico existente |
|

theme() {ggplot2}¡Atención!
Instalar el paquete ggplot2 para hacer uso de la función theme.
Para ello utilizar el siguiente código:
install.packages("ggplot2")| Descripción | Argumentos |
|---|---|
| Modifica los componentes de un tema | legend.position = posición por defecto de las leyendas ("none", "left", "right", "bottom", "top", "insidide") |
Ejemplo práctico disponible en letra G, función ggboxplot() {ggpubr}title() {graphics}| Descripción | Argumentos |
|---|---|
| Permite añadir etiquetas a un gráfico |
|
# Construcción del gráfico
# Gráfico para el modelo planteado en bar.group()
library(agricolae)
bar.group(x = Tukey.A$groups,
horiz = FALSE,
decreasing = TRUE,
ylim=c(0,15),
border="#710F99",
col = "#E9B2FF",
las = 1)
title(cex.main = 2,
main = "Título",
xlab = "Eje x",
ylab = "Eje y")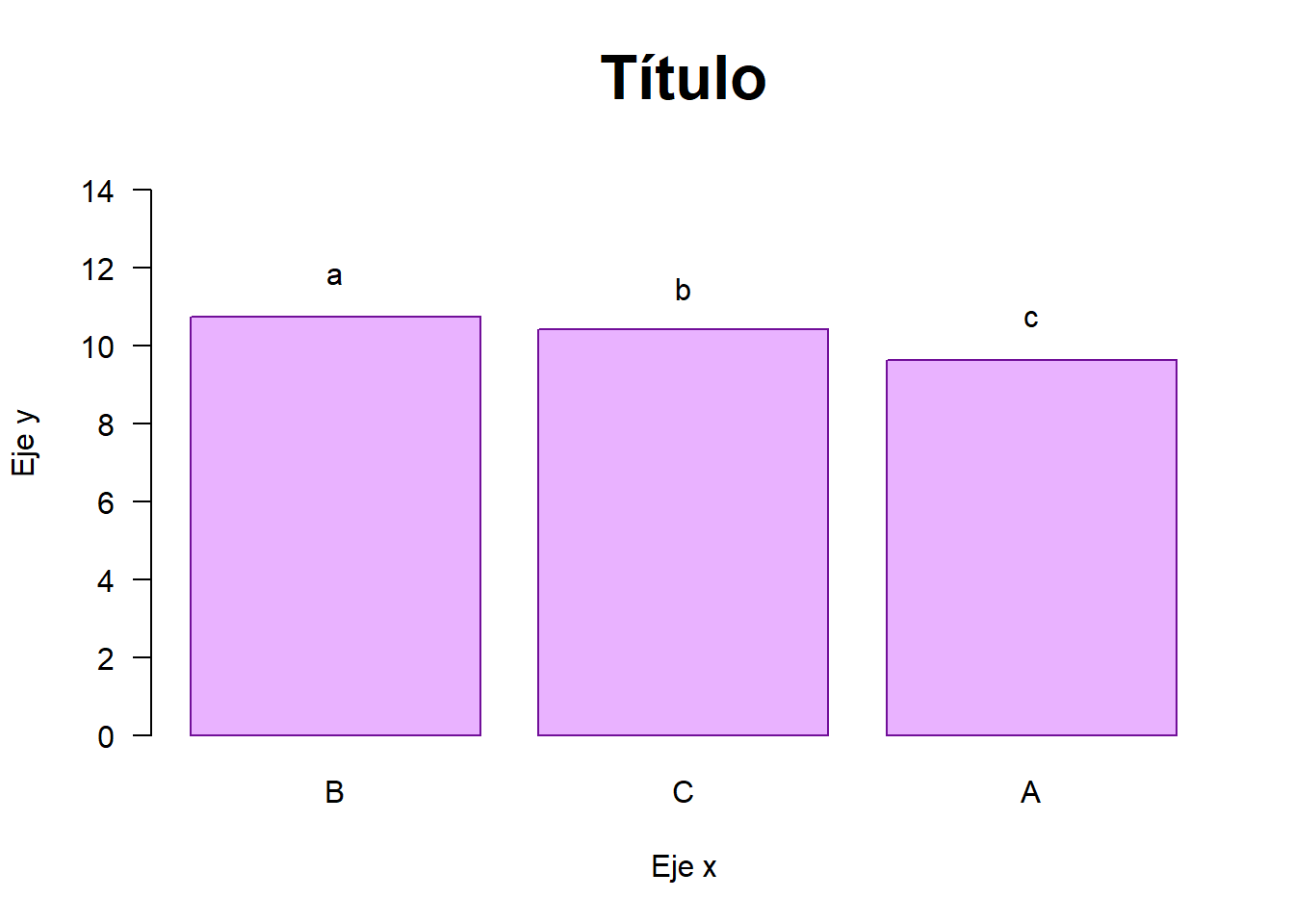
transform() {base}| Descripción | Argumentos |
|---|---|
| Permite agregar nuevas columnas calculadas a un marco de datos basadas en columnas existentes | Indicar el set de datos a utilizar |
## Departamento Variedad Brix pH AT PT Caracterización ph.2
## 1 Tumbaya Granny Smith 10.5 2.97 6.05 1.02 Acidulado 5.94
## 2 Tumbaya Red Delicius 10.0 3.72 2.32 1.03 Dulce 7.44
## 3 Tumbaya Red Delicius 11.0 3.70 2.18 1.30 Dulce 7.40
## 4 Tumbaya Red Delicius 8.0 3.59 3.08 0.77 Dulce 7.18
## 5 Humahuaca O'Henry 17.0 3.38 4.83 0.90 Acidulado 6.76
## 6 Humahuaca Gran Delicius 10.0 3.40 6.52 1.27 Acido 6.80
## 7 Humahuaca Red Delicius 12.0 4.71 1.06 0.95 Dulce 9.42
## 8 Humahuaca Amarilla tempranera 15.0 4.86 0.96 0.33 Amargo 9.72
## 9 Humahuaca Gran Delicius 9.0 3.17 5.61 1.01 Acidulado 6.34
## 10 Humahuaca Melona 16.0 4.79 2.12 1.79 Dulce-amargo 9.58
## 11 Humahuaca Verde deliciosa 10.0 3.94 3.31 0.86 Dulce 7.88
## 12 Humahuaca Cara sucia 12.0 3.42 7.53 1.41 Acido-amargo 6.84
## 13 Humahuaca Rojita 9.0 3.28 6.28 0.83 Acido 6.56
## 14 Humahuaca Amarilla deliciosa 12.0 3.49 6.52 0.98 Acido 6.98
## 15 Humahuaca Desconocida roja I 14.5 3.74 2.99 0.64 Dulce 7.48
## 16 Humahuaca Desconocida roja II 12.0 4.73 0.87 1.18 Dulce 9.46
## 17 Humahuaca Criolla chata 16.0 3.95 4.71 2.05 Amargo-acidulado 7.90