H
head() {utils}| Descripción | Argumentos |
|---|---|
| Se utiliza para ver las primeras filas de un objeto en R, como un marco de datos, matriz o vector |
|
## Departamento Variedad Brix pH AT PT Caracterización
## 1 Tumbaya Granny Smith 10.5 2.97 6.05 1.02 Acidulado
## 2 Tumbaya Red Delicius 10.0 3.72 2.32 1.03 Dulce
## 3 Tumbaya Red Delicius 11.0 3.70 2.18 1.30 Dulce
## 4 Tumbaya Red Delicius 8.0 3.59 3.08 0.77 Dulce
## 5 Humahuaca O'Henry 17.0 3.38 4.83 0.90 Acidulado
## 6 Humahuaca Gran Delicius 10.0 3.40 6.52 1.27 Acido
## 7 Humahuaca Red Delicius 12.0 4.71 1.06 0.95 Dulce
## 8 Humahuaca Amarilla tempranera 15.0 4.86 0.96 0.33 Amargo
## 9 Humahuaca Gran Delicius 9.0 3.17 5.61 1.01 Acidulado
## 10 Humahuaca Melona 16.0 4.79 2.12 1.79 Dulce-amargoEn este caso se muestran las primeras 10 filas de la Tabla 1: datos.
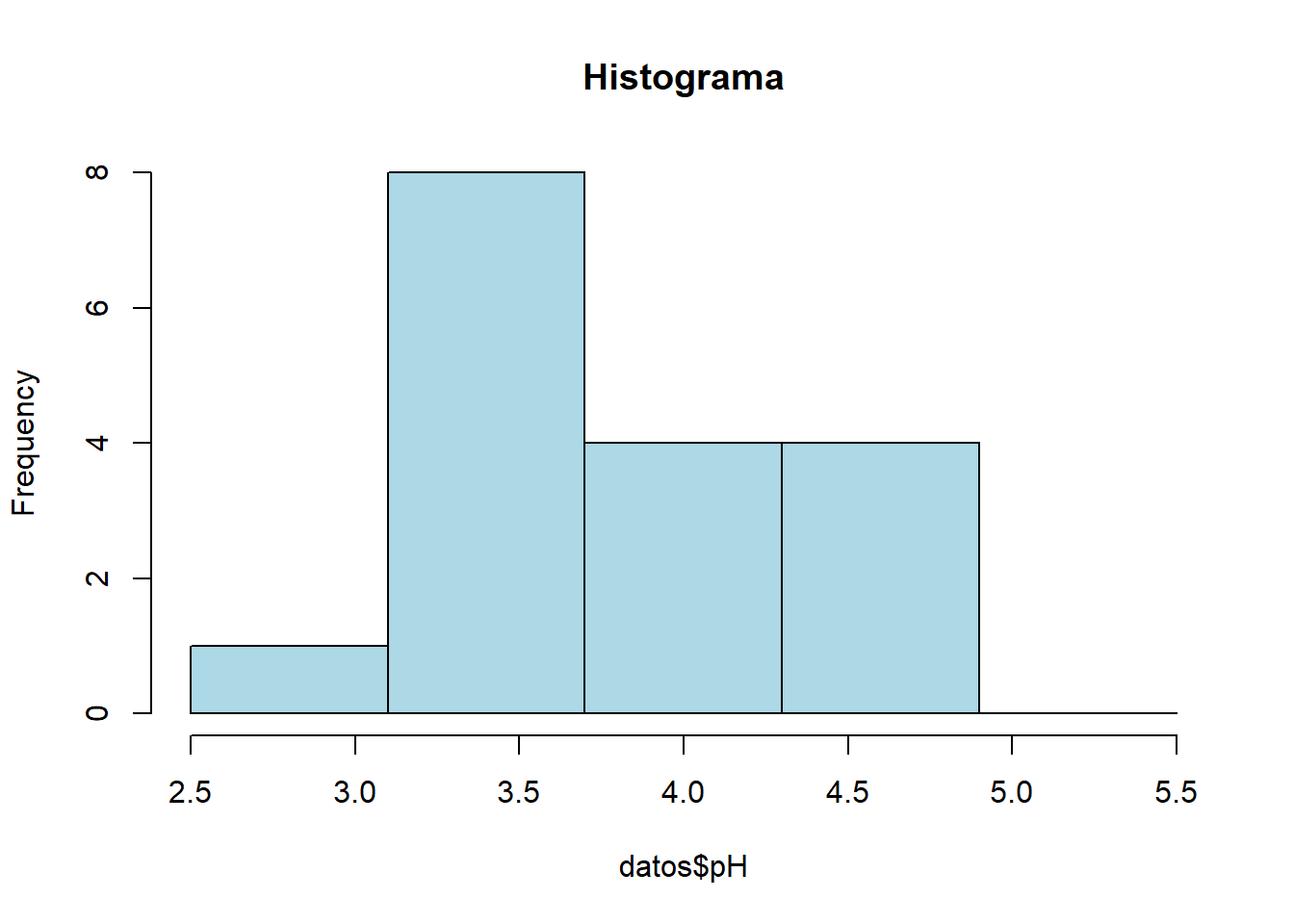
hist() {graphics}| Descripción | Argumentos |
|---|---|
| Se utiliza para crear histogramas a partir de un conjunto de datos numéricos. |
Un número entero: Indica la cantidad de contenedores en los que se dividirán los datos. Un vector numérico: Especifica los límites de los contenedores. Por ejemplo, breaks = c(0, 10, 20, 30) creará contenedores para los valores entre 0 y 10, entre 10 y 20, y entre 20 y 30. Tambien se puede usar una función para calcular los límites de los contenedores. Por ejemplo, breaks = “Sturges” utiliza el método de Sturges para determinar la cantidad de contenedores.
|
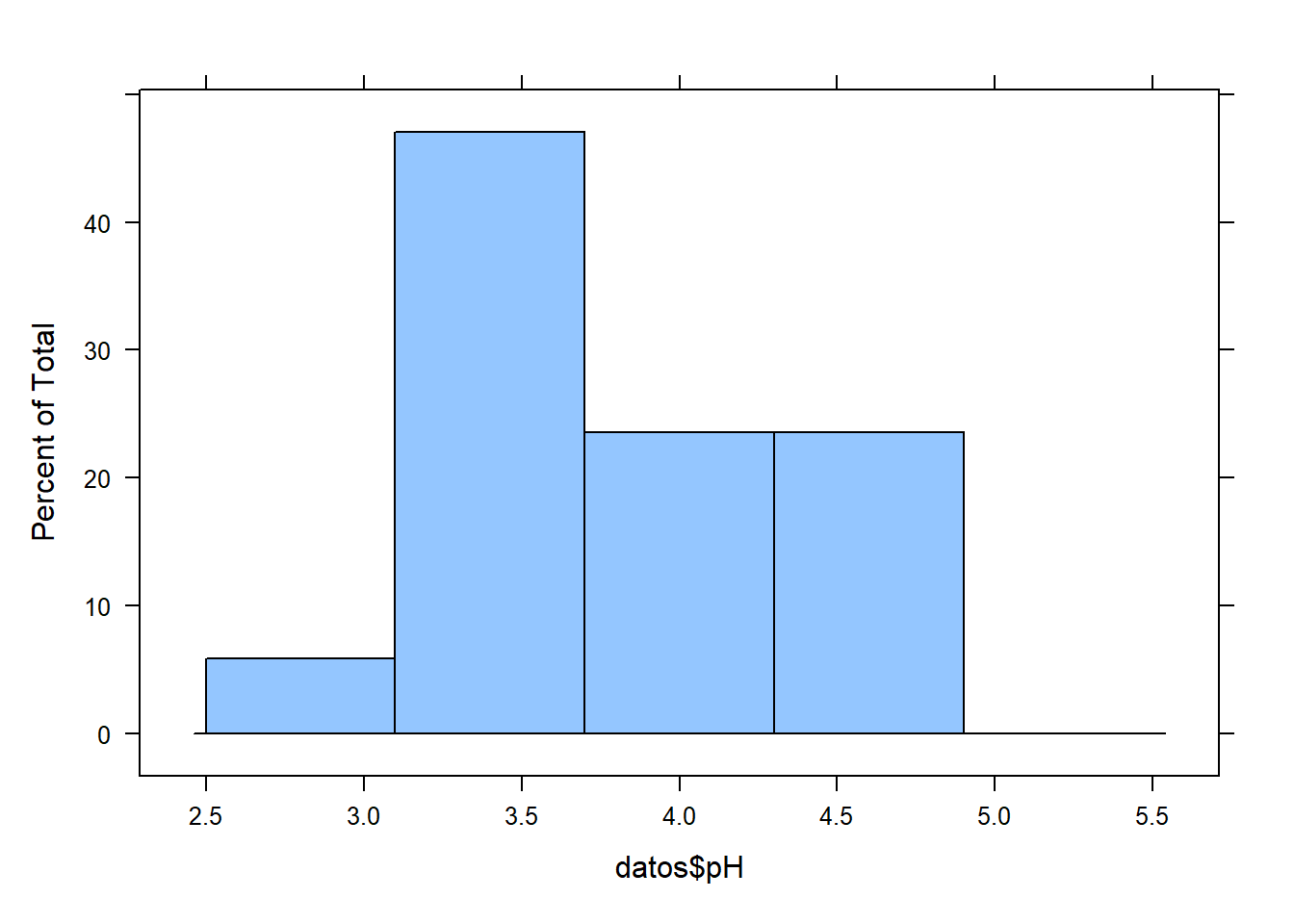
histogram() {lattice}¡Atención!
Instalar el paquete lattice para hacer uso de la función histogram.
Para ello utilizar el siguiente código:
install.packages("lattice")| Descripción | Argumentos |
|---|---|
| Realiza histogramas usando valores de fri |
|
HSD.test() {agricolae}¡Atención!
Instalar el paquete agricolae para hacer uso de la función HSD.test.
Para ello utilizar el siguiente código:
install.packages("agricolae")| Descripción | Argumentos |
|---|---|
| Realiza la prueba de Tukey |
|
#El modelo corresponde al planteado en la función duncan.test()
library(agricolae)
tukey = HSD.test(
y = modelo.d,
trt = "Tratamiento",
alpha = 0.05,
group = TRUE,
console = TRUE)##
## Study: modelo.d ~ "Tratamiento"
##
## HSD Test for Duración
##
## Mean Square Error: 0.08227
##
## Tratamiento, means
##
## Duración std r se Min Max Q25 Q50 Q75
## defilippii 0.916 0.2859371 10 0.09070281 0.56 1.45 0.7525 0.825 0.9750
## loyca 1.323 0.3469246 10 0.09070281 0.86 1.86 1.0350 1.370 1.4450
## superciliaris 1.194 0.2114080 10 0.09070281 0.82 1.46 1.0600 1.210 1.3725
##
## Alpha: 0.05 ; DF Error: 27
## Critical Value of Studentized Range: 3.506426
##
## Minimun Significant Difference: 0.3180427
##
## Treatments with the same letter are not significantly different.
##
## Duración groups
## loyca 1.323 a
## superciliaris 1.194 ab
## defilippii 0.916 b