Documento 11 Online Dataset
1 - Descargar a local el dataset online.csv (en GitHub ClassRoom - directorio Ficheros).
library(knitr)
library(ggplot2)
library(arules)
library(arulesViz)
online <- read.csv("datasets/online.csv", head=FALSE)
2 - Analizar la estructura, tipo,… del dataset.
## 'data.frame': 22343 obs. of 3 variables:
## $ V1: Factor w/ 603 levels "2000-01-01","2000-01-02",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ V2: int 1 1 1 1 1 1 1 1 1 1 ...
## $ V3: Factor w/ 38 levels "all- purpose",..: 38 25 27 20 1 12 31 5 36 4 ...3 -Analizar significado, estructura, tipo,… de cada columna.
Data frame con 22343 filas y 3 columnas:
- V1 de tipo factor, indica la fecha de compra.
- V2 de tipo entero, indica el ID del comprador.
- V3 de tipo factor, indica el producto comprado.
4 - Comandos para ver las primeras filas y las últimas.
## V1 V2 V3
## 1 2000-01-01 1 yogurt
## 2 2000-01-01 1 pork
## 3 2000-01-01 1 sandwich bags
## 4 2000-01-01 1 lunch meat
## 5 2000-01-01 1 all- purpose
## 6 2000-01-01 1 flour## V1 V2 V3
## 22338 2002-02-25 1138 vegetables
## 22339 2002-02-26 1139 soda
## 22340 2002-02-26 1139 laundry detergent
## 22341 2002-02-26 1139 vegetables
## 22342 2002-02-26 1139 shampoo
## 22343 2002-02-26 1139 vegetables5 - Cambiar los nombres de las columnas: Fecha, IDcomprador,ProductoComprado.
## [1] "Fecha" "IDcomprador" "ProductoComprado"6 - Hacer un resumen (summary) del dataset y analizar toda la información detalladamente que devuelve el comando.
## Fecha IDcomprador ProductoComprado
## 2001-02-08: 196 Min. : 1.0 vegetables: 1702
## 2001-02-20: 155 1st Qu.: 292.0 poultry : 640
## 2000-03-06: 148 Median : 582.0 soda : 597
## 2000-03-01: 136 Mean : 576.4 cereals : 591
## 2000-05-17: 134 3rd Qu.: 863.0 ice cream : 579
## 2001-01-09: 133 Max. :1139.0 cheeses : 578
## (Other) :21441 (Other) :17656La función summary() muestra la media, mediana, cuartiles, valor mínimo y valor máximo, para variables cuantitativas y la frecuencia absoluta para variables cualitativas.
Apunte:Los cuartiles son valores que dividen una muestra de datos en cuatro partes iguales.
7 - Implementar una función que usando funciones vectoriales de R (apply, tapply, sapply,…) te devuelva si hay valores NA en las columnas del dataset, si así lo fuera devolver sus índices y además sustituirlos por el valor 0.
sihayNA <- function(dataset){
n <- sum(sapply(dataset, is.na)) # Contador de NAs
if(n!=0){
posiciones <- which(is.na(dataset))
dataset[posiciones] <- 0
} else {
posiciones <- 0
}
return(dataset)
}
online <- sihayNA(online)No hay ningún nulo.
8 - Calcular número de filas del dataset.
## [1] 223439 - Calcula en cuántas fechas distintas se han realizado ventas.
## [1] 60310 - Calcula cuántos compradores distintos hay en el dataset.
## [1] 113911 - Calcula cuántos producto distintos se han vendido.
## [1] 3812 - Visualiza con distintos gráficos el dataset.
Visualizamos el ID del comprador respecto a la fecha.
library(ggplot2)
library(dplyr)
onlinePlot <- online
onlinePlot$Fecha <- as.Date(onlinePlot$Fecha)
ggplot(onlinePlot, aes(Fecha, IDcomprador)) +
ggtitle("Con ggplot") +
geom_point()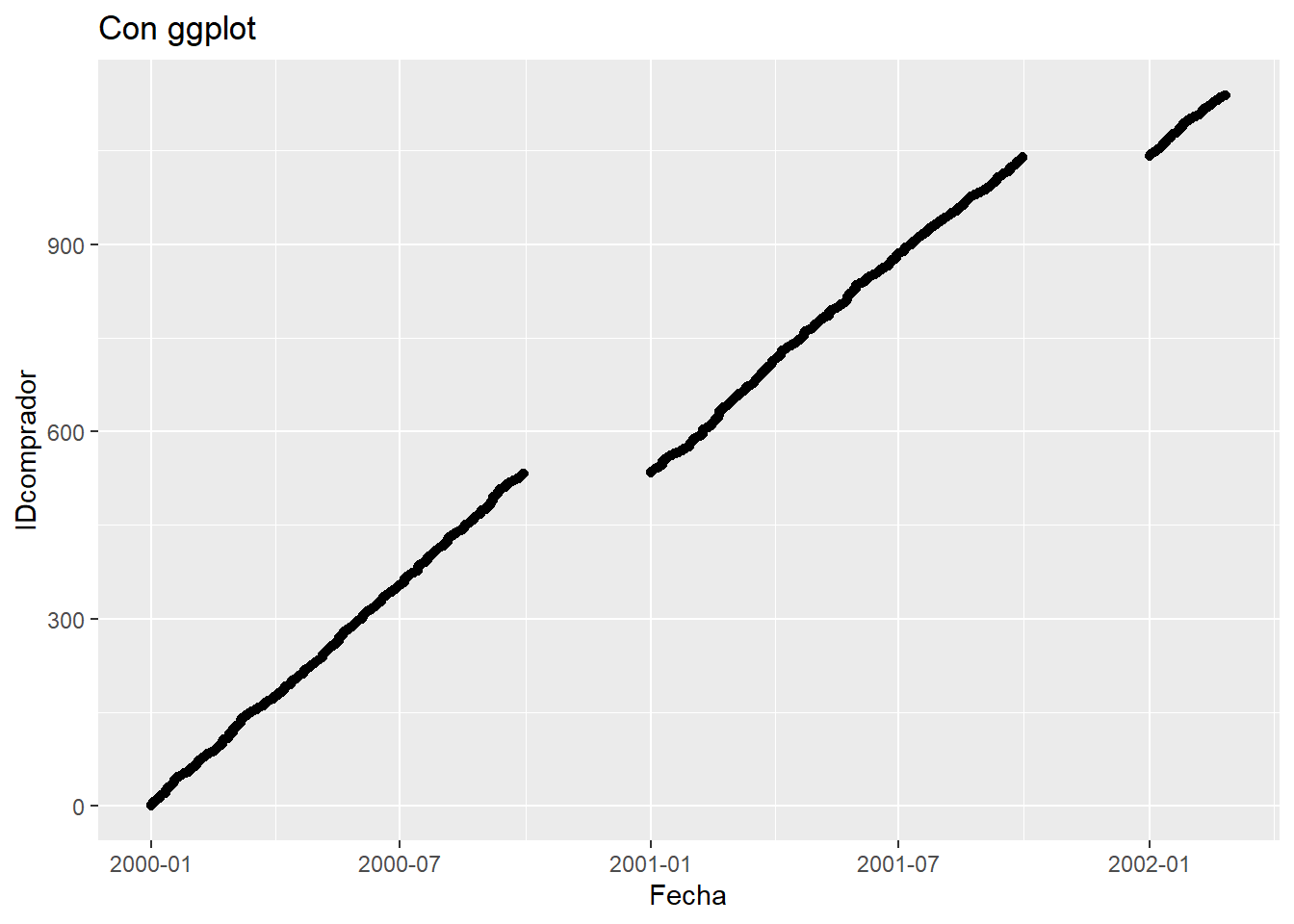
Aquí vemos en qué fechas ha sido comprado el producto ketchup:
onlinePlot %>%
filter(ProductoComprado == "ketchup") %>%
ggplot(aes(Fecha, ProductoComprado)) +
ggtitle("Con ggplot") +
geom_point()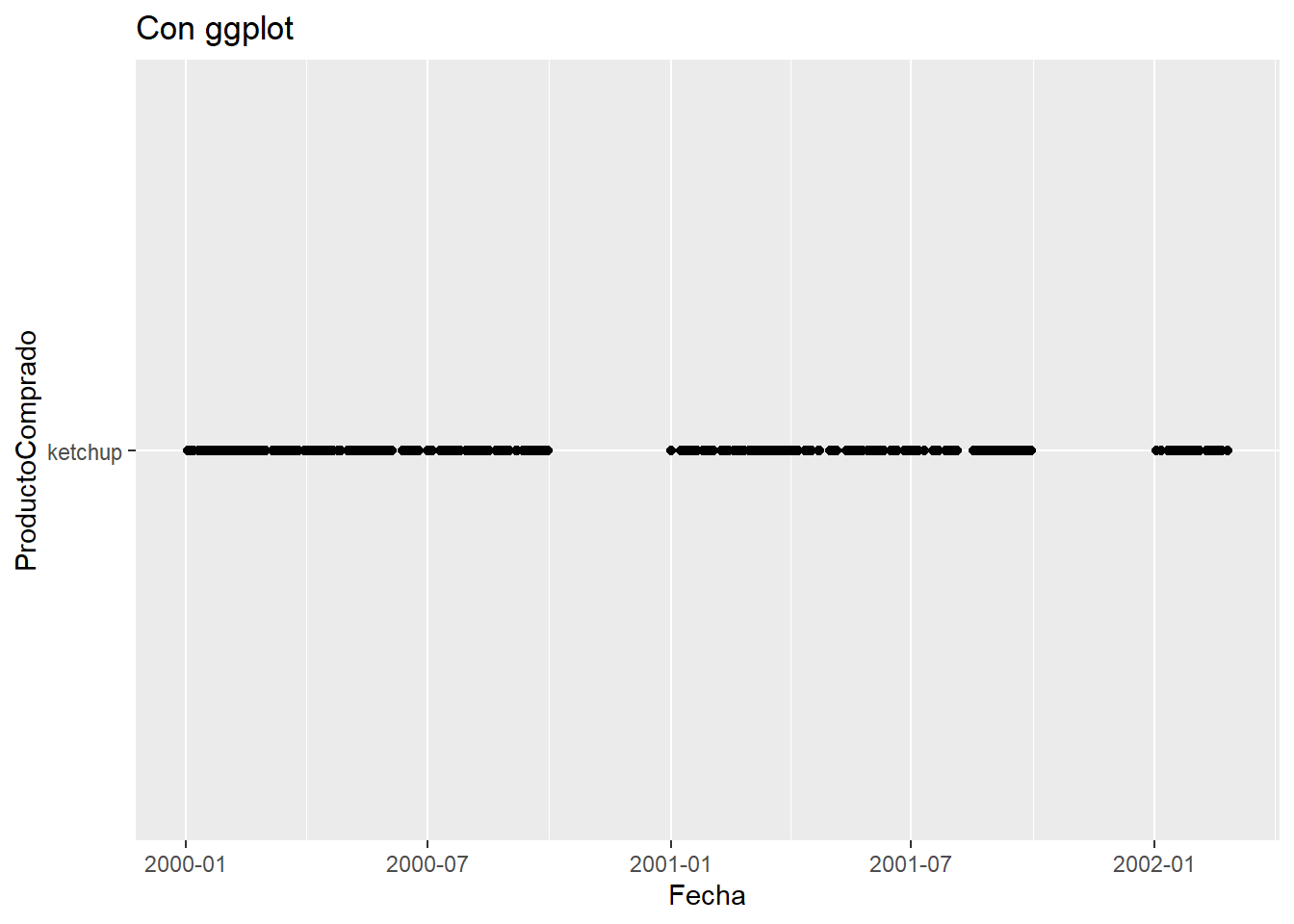
13 - Usa split para construir a partir de dataset una lista con nombre lista.compra.usuarios en la que cada elemento de la lista es cada comprador junto con todos los productos que ha comprado.
lista.compra.usuarios <- split(x=online[,"ProductoComprado"], f=factor(online$IDcomprador))
class(lista.compra.usuarios)## [1] "list"## $`1`
## [1] yogurt pork sandwich bags lunch meat
## [5] all- purpose flour soda butter
## [9] vegetables beef aluminum foil all- purpose
## [13] dinner rolls shampoo all- purpose mixes
## [17] soap laundry detergent ice cream dinner rolls
## 38 Levels: all- purpose aluminum foil bagels beef butter cereals ... yogurt
##
## $`2`
## [1] toilet paper shampoo
## [3] hand soap waffles
## [5] vegetables cheeses
## [7] mixes milk
## [9] sandwich bags laundry detergent
## [11] dishwashing liquid/detergent waffles
## [13] individual meals hand soap
## [15] vegetables individual meals
## [17] yogurt cereals
## [19] shampoo vegetables
## [21] aluminum foil tortillas
## [23] mixes
## 38 Levels: all- purpose aluminum foil bagels beef butter cereals ... yogurt14 - Hacer summary de lista.compra.usuarios
15 - Contar cuántos usuarios hay en la lista lista.compra.usuarios
## [1] 113916 - Detectar y eliminar duplicados en la lista.compra.usuarios
17 - Contar cuántos usuarios hay en la lista después de eliminar duplicados.
## [1] 113918 - Convertir a tipo de datos transacciones. Guardar en Tlista.compra.usuarios.
## transactions in sparse format with
## 1139 transactions (rows) and
## 38 items (columns)19 - Hacer inspect de los dos primeros valores de Tlista.compra.usuarios.
## items transactionID
## [1] {all- purpose,
## aluminum foil,
## beef,
## butter,
## dinner rolls,
## flour,
## ice cream,
## laundry detergent,
## lunch meat,
## mixes,
## pork,
## sandwich bags,
## shampoo,
## soap,
## soda,
## vegetables,
## yogurt} 1
## [2] {aluminum foil,
## cereals,
## cheeses,
## dishwashing liquid/detergent,
## hand soap,
## individual meals,
## laundry detergent,
## milk,
## mixes,
## sandwich bags,
## shampoo,
## toilet paper,
## tortillas,
## vegetables,
## waffles,
## yogurt} 2
## [3] {bagels,
## cereals,
## cheeses,
## dinner rolls,
## eggs,
## hand soap,
## ice cream,
## ketchup,
## laundry detergent,
## lunch meat,
## milk,
## pork,
## poultry,
## sandwich loaves,
## shampoo,
## soap,
## soda,
## spaghetti sauce,
## toilet paper,
## vegetables} 320 - Buscar ayuda de itemFrequencyPlot para visualizar las 20 transacciones más frecuentes.
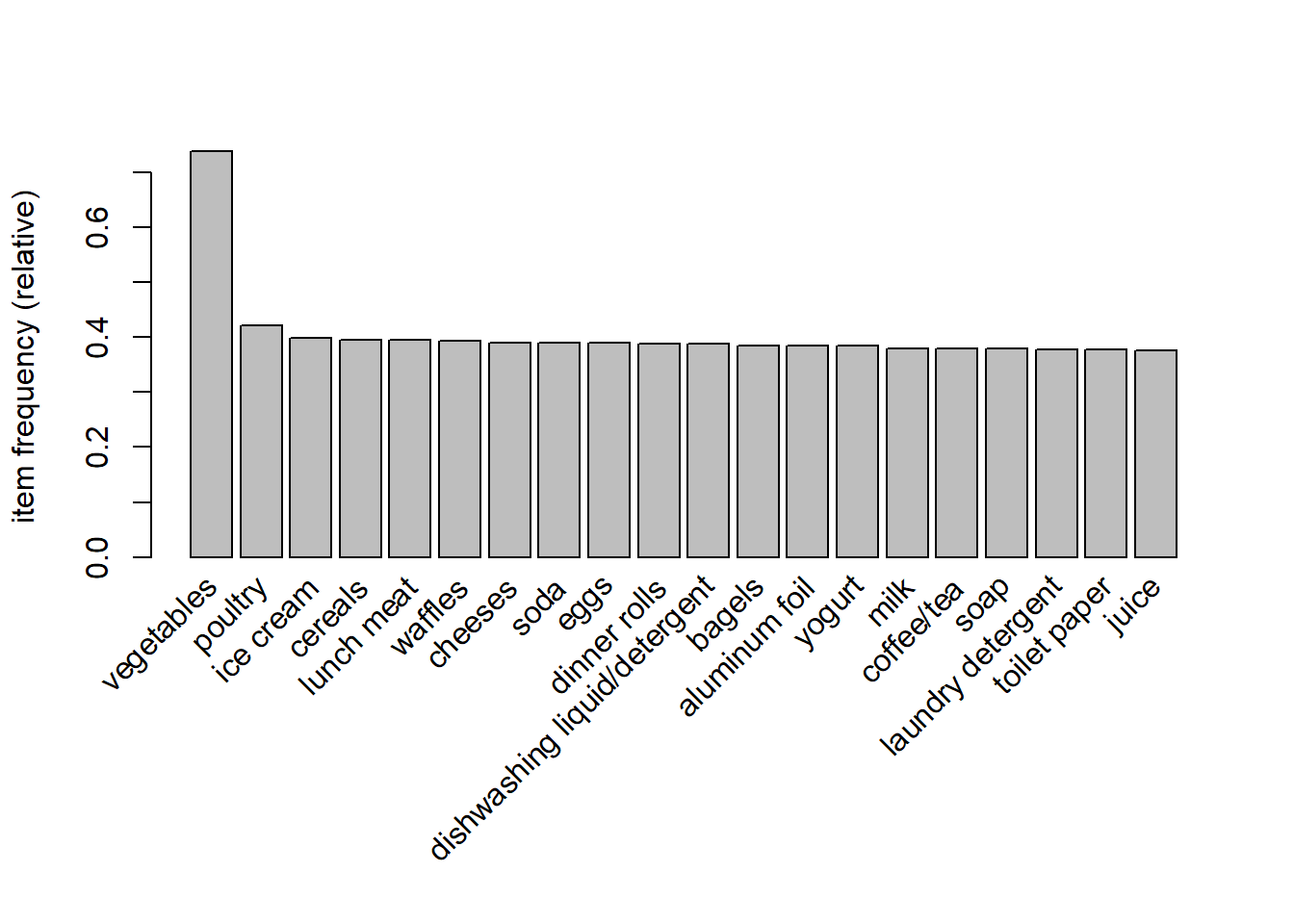
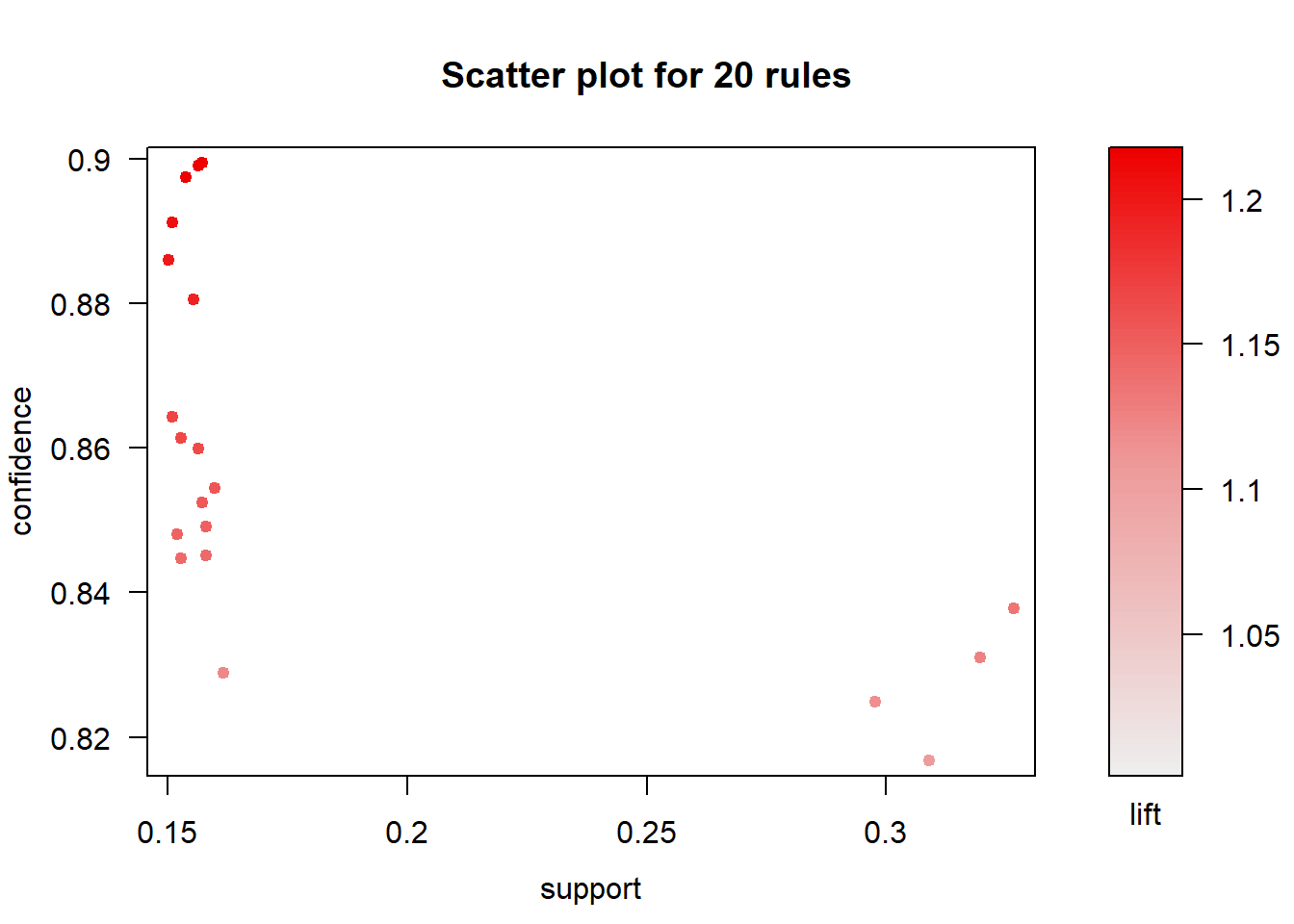
21 - Generar las reglas de asociación con 80% de confianza y 15% de soporte.
## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.8 0.1 1 none FALSE TRUE 5 0.15 1
## maxlen target ext
## 10 rules FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 170
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[38 item(s), 1139 transaction(s)] done [0.00s].
## sorting and recoding items ... [38 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 done [0.00s].
## writing ... [22 rule(s)] done [0.00s].
## creating S4 object ... done [0.00s].## set of 22 rules22 - Ver las reglas generadas y ordenalas por lift. Guarda el resultado en una variable nueva.
## lhs rhs support confidence
## [1] {eggs,yogurt} => {vegetables} 0.1571554 0.8994975
## [2] {dinner rolls,eggs} => {vegetables} 0.1562774 0.8989899
## [3] {dishwashing liquid/detergent,eggs} => {vegetables} 0.1536435 0.8974359
## lift count
## [1] 1.216779 179
## [2] 1.216092 178
## [3] 1.213990 17523 - Elimina todas las reglas redundantes. Calcula el % de reglas redundantes que había.
## set of 22 rules## [1] 024 - Dibuja las reglas ordenadas y no redundantes usando paquete arulesViz. Si son muchas visualiza las 20 primeras.